企业数据架构
QQ群
视频号

微信

微信公众号

知识星球
- 559 次浏览
【业务架构】如何创建BPMN图?
想要可视化您的流程/工作流吗?我们将向您介绍BPMN,并让您了解如何使用我们的BPMN软件为流程和工作流设计创建BPMN。
BPMN是什么?
业务流程模型和符号(BPMN)是在业务流程建模中使用的著名建模标准。它通常用于帮助业务流程分析、业务流程改进或再造。BPMN从头到尾可视化业务流程,显示流程活动的顺序和参与者之间的信息流。
BPMN图的用途
BPMN符号是如此简单,他们可以被理解为,每个人,包括业务分析师创建和改进业务流程,技术开发人员实现过程变化,业务经理监视变化,甚至非技术人员像涉众想了解未来的过程。BPMN是一种有效的通信工具,因为它提供了用于指定业务流程的通用且简单的可视化语言,这消除了不同方面之间的错误通信。
理解BPMN图
在BPMN中,使用带有一系列图形元素的图来描述流程。这样的可视化表示使用户很容易理解流程的逻辑。BPMN主要用于设计和读取简单和复杂的业务流程关系图。
为此,BPMN标准将图形元素按类别分类:因此,使用业务流程图的用户很容易识别这些元素。
BPMN符号
BPMN元素有五个基本类别。它们中的每一个都代表了业务流程的一个独特方面。
泳道
泳道是表示流程参与者的图形化容器。有两种泳道——游泳池和泳道。
流元素
流元素是连接到形成业务工作流的元素。流元素是定义流程行为的主要元素。有三种流元素:事件、活动和网关。
连接对象
流对象不是孤立的,而是连接起来形成一个流。连接流对象的连接器称为连接对象。有四种类型的连接对象:序列流、消息流、关联和数据关联。
数据
数据主要是在执行业务流程时需要或产生的信息。数据有四种:数据对象、数据输入、数据输出和数据存储。
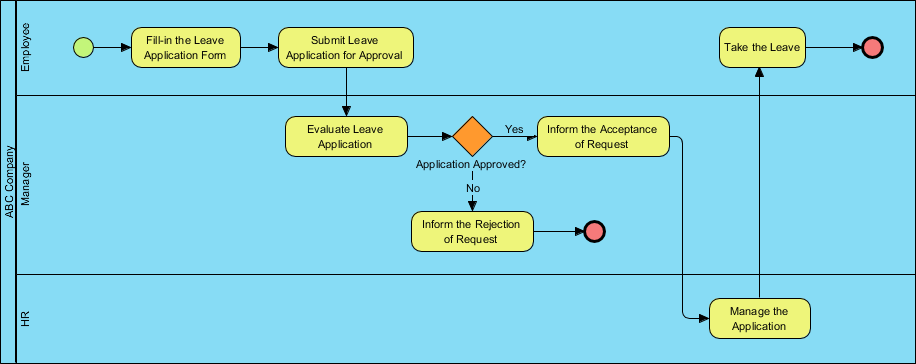
如何绘制BPMN?
- 从主菜单中选择Diagram > New。
- 在New Diagram窗口中,选择Business Process Diagram并单击Next。
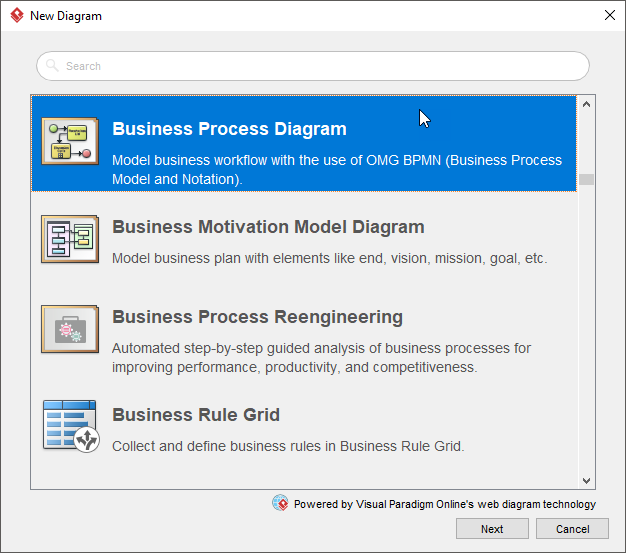
- 选择现有的BPMN关系图模板,或者选择Blank从零开始创建。单击Next。
- 输入图表名称并单击OK。
- 从关系图工具栏中拖放形状。
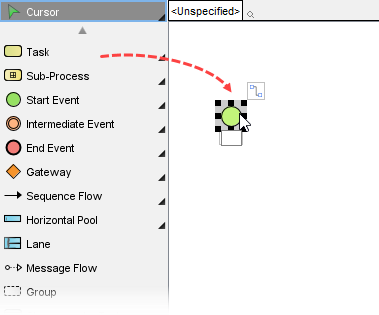
- 使用资源目录来完成图表。将鼠标指针移动到一个形状上。按下资源图标并将其拖出,然后选择要创建的形状。将自动为您创建一个连接器。
- 完成后,您可以将关系图导出为图像(JPG、PNG、PDF、SVG等),并与您的朋友或同事共享(Project >将>活动关系图导出为图像…)。
原文:https://www.visual-paradigm.com/tutorials/how-to-create-bpmn-diagram/
本文:http://jiagoushi.pro/node/860
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 108 次浏览
【企业架构】什么是数据架构? 管理数据的框架
QQ群
视频号
微信
微信公众号
知识星球
数据架构将业务需求转化为数据和系统需求,并寻求管理数据及其在企业中的流动。
数据架构定义
根据 The Open Group Architecture Framework (TOGAF),数据架构描述了组织的逻辑和物理数据资产和数据管理资源的结构。 它是企业架构的一个分支,包括管理组织中数据的收集、存储、排列、集成和使用的模型、策略、规则和标准。 组织的数据架构是数据架构师的职权范围。
数据架构目标
数据架构的目标是将业务需求转化为数据和系统需求,并管理数据及其在企业中的流动。 如今,许多组织都在寻求对其数据架构进行现代化改造,以此作为充分利用 AI 和实现数字化转型的基础。 咨询公司 McKinsey Digital 指出,由于流程复杂性而非技术复杂性,许多组织未能实现其数字化和 AI 转型目标。
数据架构原则
根据 Splunk 产品管理、核心产品副总裁、AtScale 前产品管理副总裁 Joshua Klahr 的说法,六项原则构成了现代数据架构的基础:
- 数据是共享资产。现代数据架构需要消除部门数据孤岛,并为所有利益相关者提供公司的完整视图。
- 用户需要足够的数据访问权限。除了打破孤岛之外,现代数据架构还需要提供接口,使用户能够使用适合其工作的工具轻松使用数据。
- 安全是必不可少的。现代数据架构必须针对安全性进行设计,并且必须支持直接对原始数据的数据策略和访问控制。
- 共同的词汇确保共同的理解。共享数据资产(例如产品目录、会计日历维度和 KPI 定义)需要通用词汇表来帮助避免分析过程中的争议。
- 应该整理数据。投资于执行数据管理的核心功能(建模重要关系、清理原始数据以及管理关键维度和度量)。
- 应针对敏捷性优化数据流。减少必须移动数据的次数,以降低成本、提高数据新鲜度并优化企业敏捷性。
数据架构组件
据 IT 咨询公司 BMC 称,现代数据架构由以下组件组成:
- 数据管道。数据管道是收集、移动和优化数据的过程。它包括数据收集、提炼、存储、分析和交付。
- 云储存。并非所有数据架构都利用云存储,但许多现代数据架构使用公共、私有或混合云来提供敏捷性。
- 云计算。除了使用云进行存储之外,许多现代数据架构还利用云计算来分析和管理数据。
- 现代数据架构使用 API 来轻松公开和共享数据。
- 人工智能和机器学习模型。 AI 和 ML 用于实现数据收集、标记等任务的系统自动化。同时,现代数据架构可以帮助组织解锁大规模利用 AI 和 ML 的能力。
- 数据流。数据流将数据连续地从源流向目标,以进行实时或近实时的处理和分析。
- 容器编排。诸如开源 Kubernetes 之类的容器编排系统通常用于自动化软件部署、扩展和管理。
- 实时分析。许多现代数据架构的目标是提供实时分析,即在新数据到达环境时对其执行分析的能力。
数据架构与数据建模
根据数据管理知识手册 (DMBOK 2),数据架构定义了管理数据资产的蓝图,方法是与组织战略保持一致,建立战略数据需求和满足这些需求的设计。另一方面,DMBOK 2 将数据建模定义为“以称为数据模型的精确形式发现、分析、表示和传达数据需求的过程”。
虽然数据架构和数据建模都试图弥合业务目标和技术之间的差距,但数据架构是关于寻求理解和支持组织功能、技术和数据类型之间关系的宏观视图。数据建模更专注于特定系统或业务案例。
数据架构框架
有几种企业架构框架通常用作构建组织数据架构框架的基础。
- DAMA-DMBOK 2. DAMA International 的数据管理知识体系是专门用于数据管理的框架。它提供了数据管理功能、可交付成果、角色和其他术语的标准定义,并提出了数据管理的指导原则。
- Zachman 企业架构框架。 Zachman 框架是 1980 年代由 IBM 的 John Zachman 创建的企业本体。 Zachman 框架的“数据”列包含多个层次,包括对业务重要的架构标准、语义模型或概念/企业数据模型、企业/逻辑数据模型、物理数据模型和实际数据库。
- 开放组架构框架 (TOGAF)。 TOGAF 是一种企业架构方法,为企业软件开发提供高级框架。 TOGAF 的 C 阶段包括开发数据架构和构建数据架构路线图。
现代数据架构最佳实践
现代数据架构的设计必须能够利用人工智能 (AI)、自动化、物联网 (IoT) 和区块链等新兴技术。 Protiviti 技术咨询高级总监 Dan Sutherland 表示,现代数据架构应遵循以下最佳实践:
- 云原生。现代数据架构的设计应支持弹性扩展、高可用性、动态数据和静态数据的端到端安全性,以及成本和性能可扩展性。
- 可扩展的数据管道。为了利用新兴技术,数据架构应支持实时数据流和微批量数据突发。
- 无缝数据集成。数据架构应使用标准 API 接口与遗留应用程序集成。它们还应该针对跨系统、地域和组织共享数据进行优化。
- 实时数据启用。现代数据架构应支持部署自动化和主动数据验证、分类、管理和治理的能力。
- 解耦和可扩展。现代数据架构应设计为松耦合,使服务能够独立于其他服务执行最少的任务。
数据架构角色
根据 PayScale 的数据,以下是与数据架构和每个职位的平均工资相关的一些最受欢迎的职位:
- Data architect: $79K-$160K
- Project manager: $58K-$129K
- Solutions architect: $76K-$163K
- Data engineer: $66K-$132K
- Data analyst: $45K-$87K
- Data scientist: $68K-$136K
原文:https://www.cio.com/article/190941/what-is-data-architecture-a-framewor…
- 180 次浏览
【企业架构工具】Excel、Python和Graphviz的企业架构
QQ群
视频号
微信
微信公众号
知识星球
企业体系结构是信息技术中的一个重要主题,因为它提供了当前企业体系结构的愿景,并简化了对满足企业战略所需的技术变化的分析。
Excel、Python和Graphviz提供了一个全面的架构愿景,帮助企业架构师进行企业开发的设计和规划。维基百科提供了企业架构的定
义,强调了企业架构在架构变更管理中的重要性,以确保战略的执行:
企业体系结构(EA)“一种定义明确的实践,用于进行企业分析、设计、规划和实施,始终使用全面的方法,以成功地制定和执行战略。企业体系结构应用体系结构原则和实践,指导组织完成执行战略所需的业务、信息、流程和技术变革特吉。这些实践利用企业的各个方面来识别、激励和实现这些变化。”
TOGAF®是IT服务管理中的一个标准,专注于企业体系结构。TOGAF®允许设计一个结构良好的体系结构,以保证企业的高效和有效运营。
TOGAF®定义了四个用于表示和管理企业体系结构的域:
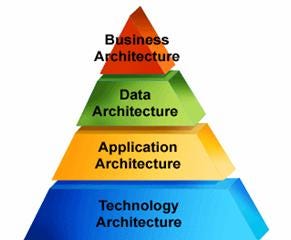
- 业务体系结构:它描述了业务流程及其交互,以便使业务流程与业务目标保持一致
- 数据体系结构:它定义了应用程序体系结构域中包含的应用程序之间的数据清单和数据流。它允许验证应用程序是否具有以正确方式执行业务流程所需的数据信息
- 应用程序体系结构:它包含与企业相关的应用程序库,并显示应用程序和由这些应用程序执行的流程之间的链接
- 技术体系结构:它包含企业体系结构中可用的技术服务和组件及其与应用程序的关联。它有助于为企业定义技术路线图和战略选择
企业体系结构实践包括三项主要活动,在前面提到的四个领域中执行:体系结构资产的维护(体系结构资产管理)、新体系结构变更的设计(体系结构开发)以及战略和企业路线图的定义(体系结构战略)。
在体系结构开发活动中,新体系结构的设计需要对业务需求有全面的理解,通常从定义业务和应用程序领域的体系结构更改开始。识别哪些流程和应用程序受到体系结构更改的影响是上述领域中体系结构开发活动的输出,也是数据和技术领域开发的输入。
在此阶段,建议企业架构师最好地了解参考数据体系结构(也称为基线数据体系结构)以及业务和应用程序体系结构中的体系结构更改,以便定义连贯的数据体系结构更改。有可能绘制数据体系结构和数据流可以提高对参考体系结构的理解,并简化数据体系结构中进化的设计。因此,在技术会议期间,绘制运行时数据体系结构的一部分是非常有用的:它允许分析体系结构数据方面,为思考提供额外的食物。
市场为企业架构师提供了很多工具,比如Gartner建议的(企业架构(EA)软件评论),但正如首席数据官告诉我的那样,一个结构良好的Excel可能会满足我们的需求。
Excel与Python和Graphviz的结合可以满足我们绘制数据体系结构和数据流的需求,从而提高对数据体系结构的理解。
Excel
为了方便起见,我们创建了一个Excel,它只包含以下列的表:
- ID数据流:数据流的唯一标识符
- 数据实体:源和目标应用程序之间交换的实体的名称
- Source:发送信息的源应用程序
- 目的地:接收信息的目的地应用程序
- 集成样式:数据流中使用的集成样式。可用的样式有消息、远程过程调用、文件传输和共享数据库。有关集成样式的更多详细信息,您可以在此处找到信息。
文件名为Enterprise_Architecture.xlsx,图纸名为Data Architecture。
在这里,您可以找到本文中使用的示例文件。
Graphviz
Graphviz是一款开源的图形可视化软件。图形可视化是将结构信息表示为抽象图形和网络的图形的一种方式。

Graphviz是一款开源的图形可视化软件。它有几个主要的图形布局程序。它还具有web和交互式图形界面,以及辅助工具、库和语言绑定。
Graphviz布局程序以简单的文本语言对图形进行描述,并以有用的格式制作图形,如网页的图像和SVG;用于包含在其他文档中的PDF或Postscript;或者在交互式图形浏览器中显示。Graphviz为具体的图表提供了许多有用的功能,例如颜色、字体、表格节点布局、线条样式、超链接和自定义形状的选项。
我们将在Windows上安装2.38版本,从这里下载软件包。对于安装步骤,您将执行安装包。
我们将使用点语言来创建有向图的“层次”或分层图形。如果边具有方向性,则这是要使用的默认工具。
Python
我们将在Windows环境中使用Python v2.7和各种库。您在这里找到了我们需要的清单:
- xrld:读取和写入Excel文件
- numpy:使用数组简化数据操作
- pandas:利用xrld库,允许在数据帧中导入xlsx,并简化数据帧的数据操作
- graphviz:为graphviz绘图软件提供一个简单的纯Python接口
您可以使用Anaconda安装所有东西,Anaconda是一种针对开源和私人项目的强大协作和包管理功能,您还可以使用Jupyter Notebooks运行Python代码,Jupyter记事本是一种开源网络应用程序,允许您创建和共享包含实时代码、公式、可视化和叙述文本的文档。
对于安装步骤,您可以使用该段落中提供的链接。
Put It All Together
Python脚本在Colab Notebook Code中提供。Python脚本包括三个特定步骤,不包括工具和库安装:
- 借助xlrd库导入数据架构Excel
- 使用panda和numpy为Graphviz解释器操作和准备数据
- 使用graphviz库绘制带有图例的数据架构图
在下面的代码中,数据架构Excel是由pandas库导入的。指定Excel文件的文件系统路径、工作表名称(sheet_name)以及数据帧标题(header)(如果需要)(选择所需的行号)和数据帧索引(index_col)(选择行列)是至关重要的。
import pandas
dfin = pd.read_excel('Enterprise_Architecture.xlsx',sheet_name='Data Architecture', header=0,index_col=0)
在Colab笔记本代码中,该文件先前已上载。
在数据操作阶段,首先使用以下颜色表的数据映射来处理数据帧dfin
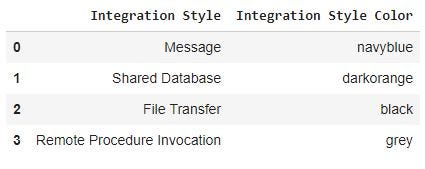
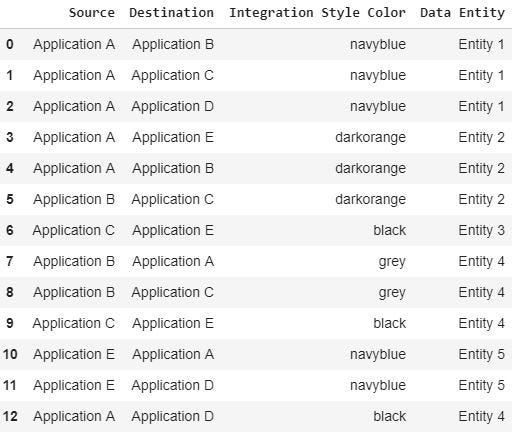
此操作的结果是一个新的numpy数组np_tmp,如下图所示(出于可视化需要,np_tmparray在数据帧中转换)
The color mapping is performed by the following statement:
colormap_i = colormap.loc[colormap['Integration Style'] == dfin.iloc[i]['Integration Style']].values[0][1]
Thecolormap_iis obtained with following logical steps: for each row in the dfin dataframe, the Integration Style is mapped and replaced with Integration Style Color in thecolormap dataframe, using Integration Style as key.
Then, the np_tmparray is processed in order to merge all rows that have the same source and destination. The result is a new numpy array np_pro , which is converted in thedf_graph dataframe in order to simplify the graph plotting.
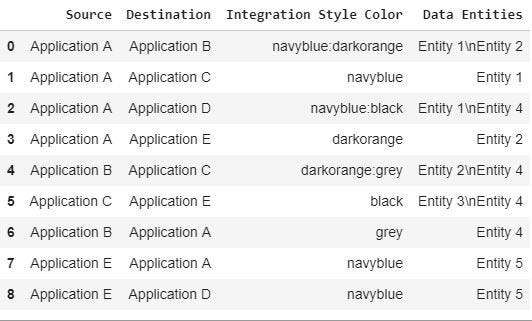
在行合并期间,集成样式颜色与:连接,而数据实体与连接。Graphviz语法需要这两个字符:在Integration Style Color中,:character允许用两种或多种颜色为链接着色;\n允许创建一个实体列表,其中每个项目都包装在下一行,并且可以正确地绘制在应用程序链接的顶部。
现在,为了方便起见,定义了一个名为dmakegraph的函数,用于从以前的数据帧(df_graph,df_grap)开始绘制图形。该函数的输出是一个图形的绘图,其中对于每个耦合源目的地,它绘制了一个唯一的链接(Graphviz语言中的边),该链接由集成样式颜色着色,并伴有数据实体。因此,包含Integration Style颜色的子图被插入到图中。
在该函数中,相关语句如下。有关graphviz-python库和语句的更多详细信息,您可以在这里看到;相反,graphviz节点、图和边属性的sintax在这里可用。
名为“企业体系结构”的图由图属性定义,如标题“企业体系架构”('label':'Enterprise Architecture')、标题在顶部的位置('labelloc':'t' , top)、默认字体大小('fontsize':'24.0')和图布局的方向('rankdir':'TB' , Top Bottom)),以及节点属性,如节点形状('shape':'box')。
graph = graphviz.Digraph(name='Enterprise Architecture',graph_attr={'labelloc':'t','label':'Enterprise Architecture','fontsize':'24.0','rankdir':'TB'},node_attr={'shape': 'box'})
对于f_graph数据帧中的每一行,都会创建两个具有固定大小(fixedsize='true')和特定宽度(width='2.5')的节点。如果刚刚创建了一个节点,Graphviz解释器不会在图中添加新节点。然后,两个节点之间的链接使用特定颜色(颜色=颜色样式,潜在颜色样式值可以是蓝色:红色)和从df_graph数据帧中收集的标签(标签=实体,潜在实体值可以是实体1\n实体2)绘制。
graph.node(appsource,fixedsize='true',width='2.5') graph.node(appdest,fixedsize='true',width='2.5') graph.edge(appsource,appdest,color=colorstyle,label=entities)
图例定义为子图。在这种情况下,将名称定义为cluster_0(具有前缀:cluster的特定值)以将子图放在图中的框中是至关重要的。因此,我们必须用语句图来解释子图的定义。子图(图例)。
legend = graphviz.Digraph(name='cluster_0',node_attr={'shape': 'box'},graph_attr={'label':'Legend','fontsize':'12.0'})
graph.subgraph(legend)
使用df_graph和colormap数据帧启动函数makegraph,输出图与此类似。

结论
Excel、Graphviz和Python(与Jupyter)的结合有助于Enterprise Architect的工作获得良好的体系结构和运行时图形,并简化EA分析以定义新的更改。
特别是,Python Numpy和Pandas库的潜力允许操作和过滤数据,以便根据EA需求生成图:数据架构中特定实体的路径(数据流)知识,或应用程序输入或输出中所有连接的可视化,等等。
Graphviz语法允许定义图形的不同版本,以丰富图形(例如使用图例或不同风格的边)或优化图形,从而提供最佳可视化效果。
如果您需要快速设置和管理企业体系结构工作,Excel、Graphviz和Python的组合可能适合您。
- 10 次浏览
【信息架构】EA874:信息架构基本组件
数据建模和数据架构:
信息建模描述了理解与企业相关的数据、流程和规则所需的元数据(图1)。信息建模有三个主要领域:
- 数据建模-逻辑数据模型是对业务术语和数据元素使用上下文的定义。例如,可以将客户和潜在客户实体分组的参与方数据。
- 流程建模-企业使用的企业业务流程的定义。流程建模使用数据模型实体,并描述如何通过业务流程创建或转换数据。例如,潜在客户成为客户的过程。
- 规则建模-描述整个组织的数据治理和遵从性策略。规则描述了数据必须遵循的质量和管理规则,以便与公司政策保持一致。例如,客户必须大于21岁,或者任何超过5年的数据项都需要存档。

图1
数据建模是IT和业务就业务术语(实体)的通用列表达成一致的过程,这些术语或属性的限定条件,以及这些术语之间的关系。维护和记录数据模型的能力成为组织跨业务关键项目服务不同数据采购需求能力的关键部分。
存在多种形式的数据模型:
- 关系模型——用于创建在线事务处理(OLTP)系统。通常,OLTP模型保持第三种标准形式,以确保没有冗余。
- 维度模型-用于创建联机分析处理(OLAP)系统。仓库的设计可以基于Kimball或Inmon方法。有时它可以是一种混合方法。
主数据管理
主数据管理(MDM)包括流程、治理、策略、标准和工具,它们一致地定义和管理组织的关键数据,以提供单一的参考点。
掌握的数据可以包括:
- 参考数据-事务的业务对象和分析的维度
- 分析数据——支持决策
考虑到MDM的原则是为了确保主数据保持统一和一致的状态,MDM和企业信息体系结构(EIA)有一个共同点:需要对主数据有一个一致的定义。归根结底,架构主数据的过程在MDM、企业信息管理(EIM)和EIA之间是通用和共享的。相对于MDM,最终目标是创建支持整个信息体系结构的信息管理环境,同时添加结构和过程,以减少管理主数据的工作量。
以下是MDM、EIA和EIM之间的关系。

图2
元数据管理
元数据为数据提供了一个参考框架。Forrester Research将元数据定义为“描述或提供支持组织信息系统的数据、内容、业务流程、服务、业务规则和策略的上下文的信息”。例如,苹果公司的App Store在线销售软件应用程序。本例中的数据是应用程序。元数据是关于这些应用程序的信息,应用程序的描述、价格、用户评级、评论和开发公司。
在数据管理环境中,有几种相关类型的元数据:
- 技术元数据提供有关数据的技术信息,例如源表的名称、源表的列名和数据类型(例如,字符串、整数)
- 业务元数据提供围绕数据的业务上下文,例如业务术语的名称、定义、所有者或管理者,以及相关的引用数据
- 操作元数据提供有关数据使用的信息,例如上次更新的日期、访问的次数或上次访问的日期
元数据管理是一个端到端的过程,用于创建、增强和维护元数据存储库和相关的过程。元数据管理包括建立过程、思维模式、组织和能力,以构建元数据环境。与BI和主数据管理一样,元数据管理面临的更大挑战是相关的业务流程规程和文化。
下图显示了元数据存储库可以包含哪些内容

图3
数据质量管理
数据质量可视为
- 数据显示的与实际场景描述相关的卓越程度。
- 使数据适合特定用途的完整性、有效性、一致性、及时性和准确性的状态。
- 数据的特征和特性的总和,这些特征和特性关系到它们满足给定目的的能力;与数据有关的因素的优秀程度的总和。
- 确保数据值符合业务需求和验收标准所涉及的过程和技术。
- 完整、基于标准、一致、准确、有时间戳。
数据质量管理包括建立和部署与数据的获取、维护、传播和处置有关的角色、职责、政策和程序。业务组和技术组之间的伙伴关系对于任何数据质量管理工作的成功都至关重要。业务领域负责建立管理数据的业务规则,并最终负责验证数据质量。信息技术(IT)小组负责建立和管理获取、维护、传播和处置本组织电子数据资产的总体环境(架构、技术设施、系统和数据库)。
这是显示数据质量管理过程的图表

图4
本文:http://jiagoushi.pro/node/1058
讨论:请加入知识星球【首席架构师智库】或者小编小号【jiagoushi_pro】
- 70 次浏览
【信息架构】EA874:信息架构治理概述
信息治理是一个程序,它实现决策权和支持机制,以确保整个企业信息的准确性、完整性、一致性、可访问性和安全性。为了维持信息治理,需要在业务(而不是IT)中确定和建立几个角色。这三个角色可能单独存在,也可能不单独存在;有些组织将足够小,因此它们可以存在于一两个人中。将这些角色作为业务人员(而不仅仅是IT人员)日常操作工作的一部分来建立,对于采用企业信息管理至关重要。
三个关键角色是:
- ·数据管理委员会。
- ·数据管理员。
- ·数据维护。
在最高级别,治理委员会代表策略创建,管理者代表策略/规则执行,维护涉及导致公司系统中数据更改的所有执行活动。
信息治理必须包括一个组织组件,该组件通过对业务中的总体数据质量评估和改进来关注数据的保真度,并体现特定个人对数据质量保证的责任。此外,信息治理还解决了数据保留/处置、安全、隐私和标准方面的要求。一个组织的信息治理计划可以解决所有这些方面,或者一个子集。许多组织从关注数据质量开始。
通常由数据治理委员会确定范围,包括信息治理的哪些方面以及哪些数据资产将被处理。该组由来自整个组织的业务端利益相关者组成,每个利益相关者都共享有关策略和范围界定决策的决策权。信息技术组织经常在与理事会接触方面发挥促进作用,并就技术机会和对信息治理的影响提供投入。理事会共同商定了一项任务说明,并随后商定了具体的信息管理政策,这些政策成为数据管理员的责任。
组织可以关注数据质量或组织防火墙内数据的一致性(即主数据),也可以从关注“动态”数据开始。数据位于何处(本地、云中)并不重要;数据治理和管理的原则是一致的。
数据管理员的主要职责
数据管理员的主要职责包括:
- 评估其职责范围内的数据保真度、安全性、隐私和保留的现状。
- 执行活动,以确保提高数据保真度的目标,并遵守所有其他类型的数据治理策略。
- 确定解决数据质量或一致性问题以实现目标的最佳方法。
- 在其直接领域内外开展工作,实施变革,以支持采用数据治理政策。
- 监控和跟踪持续的数据保真度(例如,质量和一致性)级别和其他衡量标准,以评估数据和人员对数据治理策略的遵守情况。
- 在需要跨数据域和业务功能的数据管理员时,向数据管理委员会报告,个别地(根据他们的直接职责)同时作为一个团队(例如,一个数据管理员组)。
信息治理中的关键程序和过程
·确定数据治理指标并执行审计,以对数据质量、保留、安全性等状态及其对预期业务结果的影响进行基准测试。
- 通过标准报告机制(例如,数据质量记分卡或仪表板)定期公开数据治理指标。
- 与业务领导层(关键业务经理、业务部门主管、执行管理团队等)合作,量化和阐明违反政策的业务影响。
- 向数据管理委员会授权的商定和签署的政策报告,并通过执行予以支持。
- 遵循规定的数据保真度方法来执行数据质量改进项目。
- 积极参与应用程序和数据集成流程的设计和部署,以确保标准和控制,确保按照数据治理策略实施高质量的数据。
- 宣传成功,最好是以量化的商业利益的形式,以进一步吸引组织各级人员的参与。
信息治理与公司整体治理和IT治理的关系
善政的总体目标是提高决策和流程(效率)的速度和效力,最大限度地利用信息创造价值,并降低业务或组织的成本和风险。信息治理是公司治理的一个子集。换句话说,信息治理不应该被看作是“IT治理”的一部分,为什么?因为这样的观点强化了信息是信息的责任的观念。不是的。虽然有些信息当然是It部门的责任,但很多信息不属于It部门的权限。为了实现预期的目标,直接参与信息治理是必要的。
这里展示了公司治理、信息治理和业务规划之间的关系。

图1
治理决策
良好的治理将其重点缩小到对业务在风险、效率或价值方面重要的方面。一个成功的EIM项目的一个特点是能够确定哪些信息是最有价值的,并专注于它,而不是试图控制环境中的一切,这是一个不可能完成的任务,如果曾经有过的话。
图2从业务决策的角度描述了信息治理的组件。

图2
所有的组织,无论大小,都有一个巨大的潜在信息空间需要管理。只有缩小重点,组织才能取得任何进展。选择重点领域将有助于组织将项目范围缩小到可管理的范围。焦点将决定您稍后将处理哪些问题。通常,组织会考虑以下一个或多个方面:
- 业务战略和一致性—此领域需要业务和信息目标的总体一致性、工作优先级和平衡以及争议解决。
- IT体系结构、标准和集成—该领域涉及信息、元数据、存储、传输和系统标准。
- 数据或信息质量-该领域涉及数据或信息质量的标准、测量和维护。
- 数据或信息访问-信息来源、访问权限、权限和使用。
- 报告-定期评估商业决策信息源的可用性和质量。
- 安全和隐私-规划、控制和响应安全和隐私需求和指令。
- 法律和法规遵从性—规划、控制和响应信息风险因素,以及法律和法规对信息的保留和处置。
需要注意的是,其中一些重点领域最好由业务线来解决——质量是一个很好的例子,隐私是另一个例子。仅将重点领域视为IT关注点是一个错误,它将确保更少的业务参与,从而导致治理计划不太成功。在许多情况下,重点领域需要业务和IT专业知识的结合。安全就是一个很好的例子。企业必须识别安全风险,但必须实施安全控制。
本文:http://jiagoushi.pro/node/1059
讨论:请加入知识星球【首席架构师圈】或者小编小号【jiagoushi_pro】
- 50 次浏览
【分析应用】什么是分析应用程序?
QQ群
视频号
微信
微信公众号
知识星球
分析应用程序或分析应用程序是预打包的商业智能(BI)功能,如自助式仪表板、报告和数据可视化,可帮助最终用户在人们日常工作使用的事务系统中衡量和提高运营性能。
这些捆绑的分析工具有助于组织在特定运营领域(如财务、营销和销售)的普通业务用户中促进和增加自助BI实践的采用。它通过改进重要的、相关的历史数据的可用性和测量来实现这一点,以供最终用户决策。
分析应用程序不限于一个部门或行业;它们可以构建、部署并应用于许多不同类型的事务系统和业务用例。当与深层领域知识相结合时,它们的效果最好,因为它们解决了组织采取行动所需的工作流程或数据中的差距。
无论是由您的团队内部构建,还是由第三方开箱即用地交付,分析应用程序基本上都是作为一个专门策划的分析平台提供给您的业务用户的。
分析应用程序是如何工作的?
分析应用程序设计为可访问、即用即用的BI体验,适用于广泛的用户,以用户为中心的设计提供了专注于关键指标的逻辑、一致的布局。这些应用程序实现了简化的自助探索,以更好地发现和分解见解,并且通常包括直观的最佳实践向导,帮助指导用户在给定区域分析他们想要分析的内容。
对于开发人员来说,分析应用程序包还包括用于简化与标准业务应用程序集成的预制连接器、预定义的数据模型,以及无代码或低代码应用程序开发环境,以使构建量身定制的BI体验变得更容易。
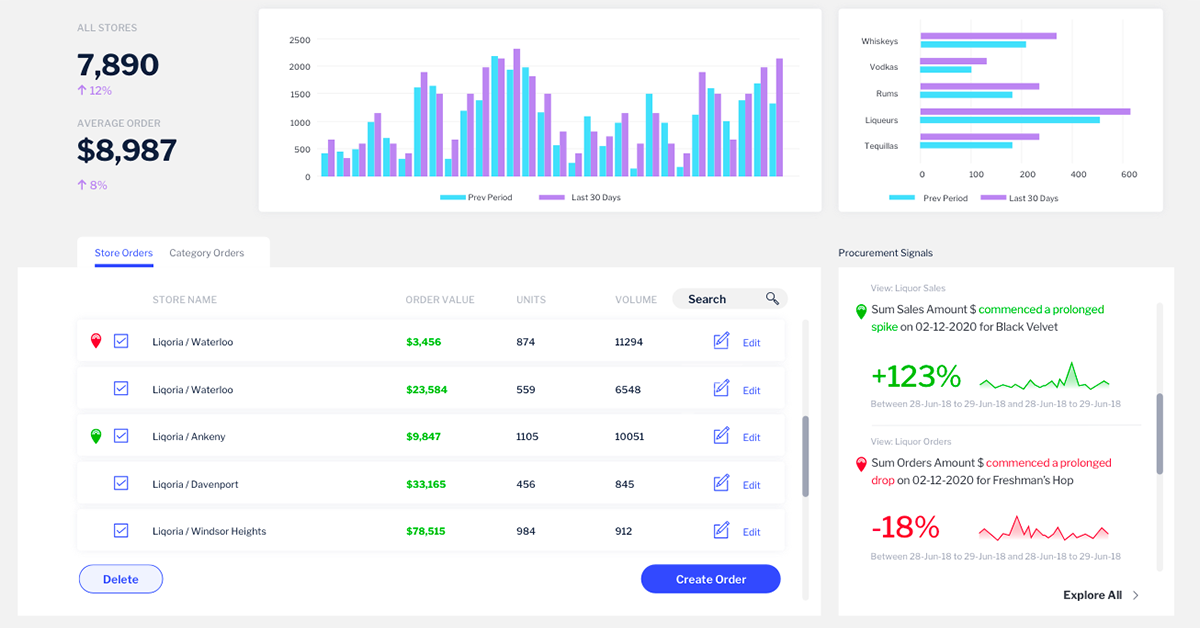
例如,招聘经理可能会得到一个量身定制的分析应用程序,向他们提供数据,显示企业与招聘公司的互动次数。他们可以查看公司在12个月内招聘了多少人,在哪里招聘,以及每个业务部门的保留率。
上述实例中的分析应用程序旨在为用户和他们需要做的工作提供深思熟虑的用户体验。最终用户没有提供数百份报告和仪表板,而是受益于高度针对性的分析体验,确保他们从现有数据中获得更多价值,从而做出更好的决策。
分析应用程序适合哪里?
分析应用程序通常填补典型操作应用程序中的三个空白:
- 如果运营应用程序中缺少决策所需的数据
- 应用程序没有采取适当操作所需的工作流
- 应用程序中的数据需要额外处理才能做出有效决策
这些应用程序往往支持功能性很强的决策或特定的操作工作流,因此具有大量的领域专业知识。它们也往往不是通用的商业智能类型的应用程序。
从本质上讲,如果需要来自多个来源系统的数据来使最终用户能够采取行动,那么分析应用程序可以提供很大帮助。
例如,营销分析可能需要HubSpot等内容管理系统和谷歌分析等流量监控软件的数据,而销售预测可能需要Salesforce和用户财务系统的数据。在这两个例子中,在同一界面中将两个数据集合并在一起可以为最终用户提供更大的画面,并有助于改进他们以数据为主导的决策过程。
什么时候最适合使用分析应用程序?
当用户日常工作所依赖的主要操作应用程序没有以便于决策的格式提供数据,或者没有允许用户采取行动的必要内部工作流程时,最好使用分析应用程序。
构建一个供最终用户使用的分析应用程序,以及他们用于日常运营任务的普通核心应用程序,填补了这些空白,是确保最终用户在做出决策时仍能适当使用数据的有效解决方案。
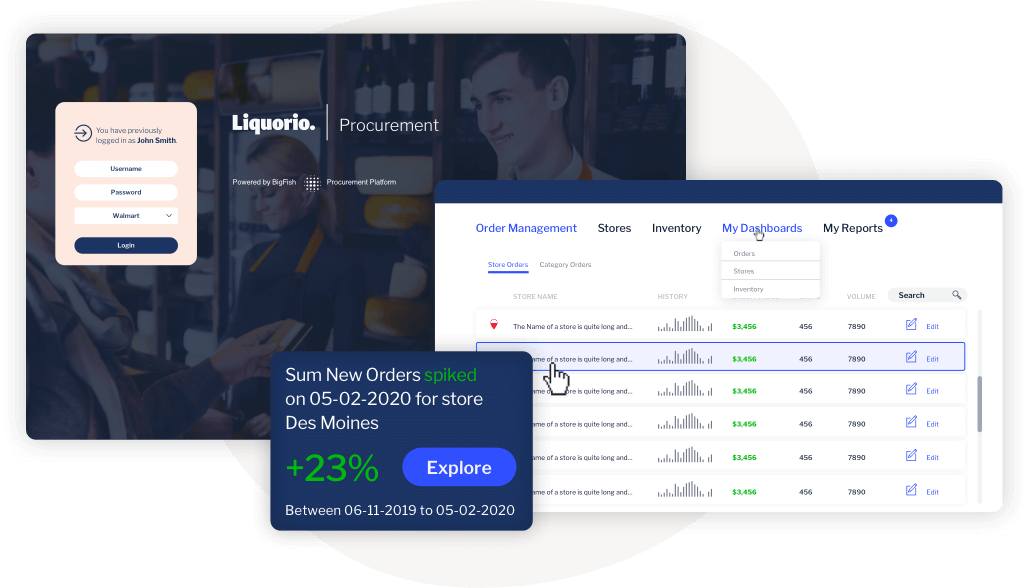
在这种情况下,您将从源系统中提取数据,并将操作工作流构建到应用程序中。使用前面的营销和销售示例,尽管您可以在CMS或CRM(如HubSpot和Salesforce)中构建仪表板,但该仪表板并不便于用户直接从仪表板中操作机会。事实上,最终用户必须首先找到这样做的机会。这会在操作工作流中产生摩擦,可以通过直接在仪表板中构建操作来解决。
有时,应用程序中的数据需要额外的处理——例如,您希望对数据运行数据科学模型来预测结果。在这种情况下,通过原始应用程序将结果返回给最终用户可能很困难。
再一次,您可以通过分析应用程序来解决这个问题。因此,如果你想预测哪些客户可能会购买升级,你可以提取Salesforce数据,运行你的模型,并在仪表板中向销售部门提供结果,然后销售部门可以对最有可能的买家采取行动,并向他们提供报价-所有这些都直接来自分析应用程序。
哪些解决方案最适合构建分析应用程序?
最强大的现代商业智能平台提供了全方位的工具,使组织能够将各种复杂度的独特数据驱动应用程序原型化、开发、扩展和部署到客户和用户的运营应用程序中。
旨在构建定制的分析应用程序,以适应企业和嵌入式分析用例。无论复杂程度、性能或规模如何,您都可以为各种行业构建多种类型的数据、事件驱动和相邻应用程序:
- 数据应用程序-具有持续更新数据的复杂仪表板,其中可能嵌入了操作工作流,使用户能够更新第三方应用程序。
- 实时故事-当您在一段时间内跟踪某个事件并希望在事件展开时向用户提供最新数据和解释时,可以使用仪表板和报告,让用户了解特定事件的最新情况。
- 时间点故事-用于解释更改和/或提供更新的仪表板和报告。就像数据新闻文章一样,它们是关于某个主题领域或事件的数据故事。
- 独立应用程序-分析应用程序,其外观和行为类似于独立应用程序,能够完全控制最终用户的BI体验。这些可以作为服务托管并提供给您的客户,并且可以完全贴上白色标签并重新命名,将其作为您自己的解决方案进行销售。您可以将用户的功能访问限制为Yellowfin的其余功能,并且通过自定义导航,您可以围绕应用程序创建自己的自定义导航。
分析应用程序:为什么需要它们
分析应用程序的高度策划、量身定制的体验之所以存在,是因为IT主导的BI解决方案并不总是能引起当今普通业务用户的共鸣。它们专注于提供根据用户特定需求构建的现成分析,是确保用户从数据中获得更多价值的理想选择。它们甚至可以被贴上白色标签!
通过在一个方便的捆绑软件解决方案中提供BI基本功能的所有构建块,分析应用程序有助于简化BI的采用,可以更快地提供见解以推动行动,并可以更快地向客户提供价值。
花点时间选择正确的解决方案,并使用应用程序开发生命周期中所需的所有工具,这样您就可以开始构建高度定制的分析体验。
- 5 次浏览
【参考数据架构】创建参考数据架构…
QQ群
视频号
微信
微信公众号
知识星球
我想在创建参考数据架构的同时分享我的思考过程。希望它能帮助你定义你的,我们通过提供反馈来帮助我改进我的。
我认为参考架构是一个需要努力的目标,而不是简单地反映当前的状态。在我看来,参考架构应该与供应商无关,但要强调重要/强制性的技术功能。参考架构可能(也应该)包括当前未使用的组件,以便从我们当前的位置有更广泛的视角。
我的参考架构是基于多年来在各种公司和技术中积累的实践经验。我将我的实践经验与阅读社区出版物的时间结合在一起。这个参考架构也构成了我在Simplics工作的基础,我已经开始在Medium上描述它,从我的帖子开始。。。
为什么我觉得有必要发布这篇描述我的参考数据架构的帖子?
好吧,这是我描述我的信仰以及简单主义是如何构成的一种方式。我还没有真正找到很多类似的(公共)著作,它们将数据架构作为所有数据消耗学科的通用架构,强调没有供应商标志的需求和功能…
此外,从供应商的产品开始并以此为基础进行构建真的很难,所以这确实会有所帮助。

The 2023 MAD, brought to you by Matt Turck,
要获得高分辨率,请访问以下任何链接。
MAD 2023-版本1.0(matttturck.com)
2023年MAD(机器学习、人工智能和数据)前景-Matt Turck
简单地看一眼数据技术地图就会得出一些结论。
- 任何人如何评估和选择适合这份工作的工具?不用花很多时间评估!评估和评估每种产品所需的各个方面实际需要多长时间?
- 我们不能满足于使用一些工具来完成任务,这会导致团队的学习曲线陡峭。。。
- 我们需要构建一些可以改变和采用/替换工具的东西,因为一切都在发展,我们可能还没有完成任务的最佳工具,但…
那么,我们可以从社区共享的东西开始吗?
我决定花几个小时浏览其他人是如何定义和描述他们的数据架构的?我把一堆图表复制到下面的幻灯片中。
Lots and lots of data architecture diagrams grabbed from the Internet

My reference data architecture
我们现在有了一个充满学科和能力的图表,作为一种多层次的方法绘制。使用您记录在案的需求,并详细说明每一个重要的学科,既作为需求,也作为对您需求的回答…
好的,那么我们如何看待这张照片呢?
从左到右,穿过中间,然后向上。处于较高位置的部件比处于较低位置的部件更重要。然而,对于一个装备精良的“生态系统”来说,所有组件都是有效且重要的(每个图标所代表的内容将在本文中进一步描述)。
在最左边,我们有各种类型的来源,所有这些来源都有特定的特征需要考虑。这些通常是;内部遗留系统、ERP、SAAS、定制、微服务、数据库、日志、设备和社交媒体等。。
为了将数据传输到中间,我们需要以拉、推和流的形式进行某种形式的源摄取。数据被接收并存储在着陆区,然后被组织到一个原始的“无缓冲”存储器中,以便进行审计和再处理。
从那里,我们将数据调整为选定的格式和上下文,并使其可访问。我们进一步将数据集成到实体和扩展上下文中,使其更易于访问。稍后将数据公开为特定业务用例所需的格式,以便进行简单准确的访问。并非所有数据都必须“穿越”所有五个丰富层。根据我们的实际需求,消费可以从后面三个层(对齐、集成和业务)中的任何一个进行。
从源接收到业务调整,我们创建需要编排和调度的程序和/或数据流。我们强调内部流程的自动化,因此它涵盖了所有层,在我们的图表中具有更高的重要性。
我们的第二要务是数据质量,这是一个贯穿我们所有层面的实践。另一方面,我们的最高优先级是我们的最终用途;我们的消费和运营。我们应该专注于我们的最终用途,让它驱动其他一切。我们的内部数据操作(或数据治理或数据操作)与任何其他用户或应用程序一样重要。这导致元数据成为一个关键组件,它必须捕获有关所有模式、模型、定义、数据、流程、事件和用法的数据。
如果你对每个图标所代表的每个功能感兴趣,请继续阅读,否则请随意到此为止…也许你没有找到“基于图标的”图表,所以如果你愿意,这里有一个文本替代方案…

My reference architecture
这是相同的架构,但没有图标,绘制有点不同。它由与前面的图表完全相同的层和功能组成。以下部分与我的流程有关,描述了我用作参考架构基础的功能和需求…
步骤1:收集、列出并描述你想要的能力。
这些应该包括已知驱动用例的特定功能,以及未来未知用例的更通用的功能。我通常将这些能力分组,并将描述保持在高水平,但驾驶计划除外。让我使用下面的详细列表进行说明。
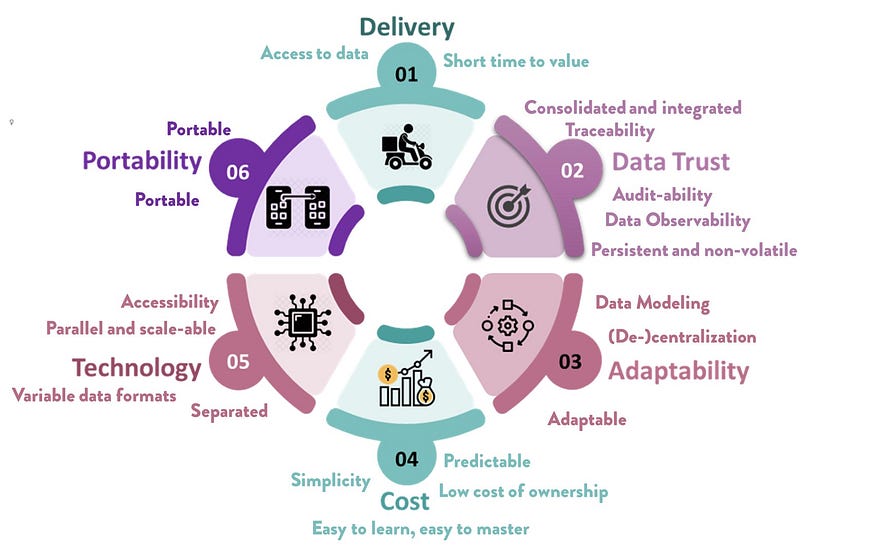
数据采集

data acquisition capabilities
- 我们需要一种推送数据模式来允许系统发送数据。
- 我们需要一种从系统中获取数据的拉取数据模式。
- 我们需要一种流式数据模式,以便能够即时、连续地访问数据。
- 我们需要一个到达数据的占位符、一个交付区域或上传区域。
- 我们需要一个长期的档案,用于可追溯性、再处理和审计。
数据可观测性

capabilities for data observability
- 我们需要能够观察和测试我们的数据质量;完整性、一致性、有效性和新鲜性。
- 我们需要收集并显示所有数据点/产品的踪迹。起源,它是如何生成的,如何随着时间的推移进行处理和转换,以及它为哪些用户/应用程序提供服务。
- 我们需要确保数据不会被滥用或歪曲,并且只提供给那些可能担心的人。
数据集成
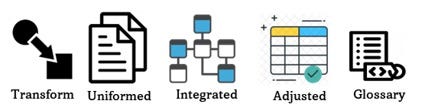
data integration capabilities
- 我们需要具备转换能力,以便实现如下所述的新状态和新形式的数据。
- 我们需要统一我们的数据,以便简化访问并使其成为可能。
- 我们需要整合数据,以整合数据,提供更广泛的视角,创造相似性,并定义可以共享的概念和定义。
- 我们需要将数据调整为适合其应用的形式。
- 我们需要定义一个包含定义、术语和概念的术语表
编程访问
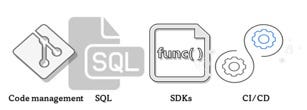
- 我们需要启用公司代码管理标准,如git或类似标准
- 到目前为止,人们和技术人员最常用的数据处理和操作语言是SQL。因此,目前启用SQL对数据的访问至关重要。
- 我们需要为各种工具开放数据访问,并通过为我们的数据创建SDK或为各种编程语言提供模板来避免技术锁定。
- 对于需要在不同技术设置之间保存、跟踪和移动的任何代码,纳入CI/CD流程非常重要,以提高代码质量、共享和开发速度。
日常运营

day to day operation capabilities
- 我们需要尽可能地实现流程自动化。
- 我们需要能够通过排序、扇入和扇出功能来协调我们的数据流/管道。
- 我们需要安排某些数据流和任务。
- 我们需要能够监控我们的技术环境、数据管道、资源消耗、财务支出和数据质量。
- 我们需要能够针对关键事件创建警报。
- 我们需要设置一系列控制措施,以确保我们的数据环境持续发展,并为最终用户和消费应用程序维护高质量的服务。
- 我们需要能够审计数据是如何被访问的,被谁以及何时修改的。
数据消费

data consumption capabilities
- 我们需要运营情报能力,以便将数据转化为可操作的见解,帮助我们的组织优化运营并提高底线。
- 我们需要BI和报告,以便以描述和报告业务进展的方式呈现数据,并帮助我们的组织做出更好的决策,改进运营,实现竞争优势。
- 我们需要仪表板功能,以便使数据具有相关性,并将正确的信息呈现给正确的利益相关者。
- 我们需要某种笔记本电脑功能,以便我们的高级用户能够在彼此之间精心设计、开发、处理、呈现和共享数据和程序。
- 我们需要一套工具和流程来对我们的数据运行人工智能和ML计划。模型培训、评估、验证、审计和出版,也许还有一些特定的商业图书馆
- 我们需要为数据应用程序开放我们的数据环境。使用数据并为另一个目的生成“新的”丰富数据的应用程序。
- 我们需要为用户提供一种使用搜索方法发现数据的方法。
- 我们需要允许我们的用户在彼此之间共享数据和代码。
这很可能是您将详细介绍自己能力的领域。对于具体的需求,请详细说明,否则请接受我的高级定义。例如,您可能需要针对用例的NLP功能,可能还需要一些用于并行处理的基础设施,以及针对ML功能的某种注册表和编排。
第2步:了解您的要求
许多数据架构要求都很一般,但考虑起来非常重要。
我最近写了一篇关于底层总体需求的文章,这些需求应该影响整个架构,并体现在所有组件和功能中。我觉得这些很重要!
Requirements for data architectures
当然,链接帖子中列出的要求还不够,你还会有其他更实用的要求,比如延迟、外观、资金限制、员工技能、绩效、分配、法律和政策等等。
第3步:总结和定义
总结所有需求和功能,并定义您的参考架构。我们有一系列的能力,需要结合实际情况进行组织。我们有一套总体要求需要考虑。我们的需求有助于我们将我们的能力置于上下文中,相互限制或启用。很可能你最终会创建一个类似于我的多层架构。
我的参考架构既可以用于经典的集中式实现#datawarehouse,也可以用作现代的去中心化实现#datamesh。
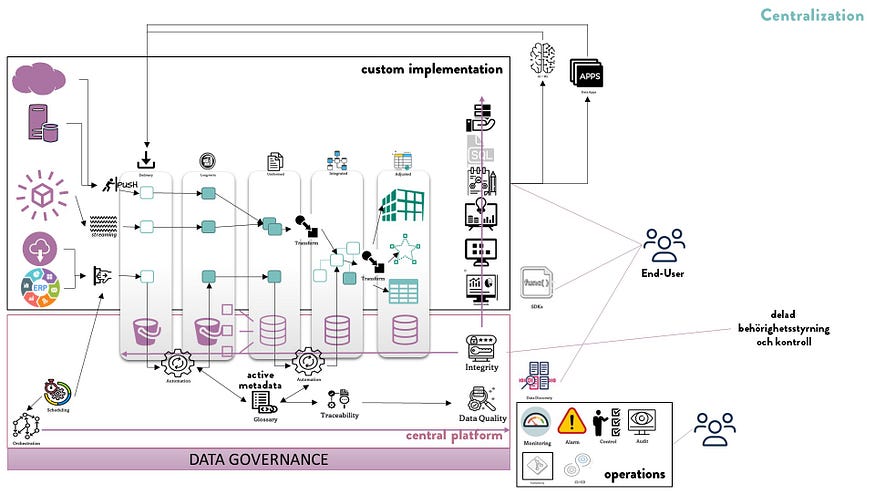
Classic Centralized Data Warehouse Architecture
我们的经典集中式数据仓库在这种架构中可以完美地工作。例如,我们可以将数据收集到云存储桶中,配置云数据仓库来访问存储桶并自动加载数据。我们努力定义一个集中的数据模型,并创建加载自动化和数据可观察性的功能。我们在星形模式、表格和多维多维数据集中创建基于用例的数据集。我们为适当的数据集配置消费工具,并集中我们的安全性、完整性和访问功能。一切都由一个中央跨职能团队负责。集成和重用能力是这些设置的重点。

Decentralization using streamline architecture, hybrid mesh :)
在这个架构中,我们希望实现去中心化,以便团队提高生产力,并将复杂性保持在领域边界内。然而,我们仍然希望实现在各个实现中遵循相同的指导方针、框架和方法。在这些场景中,我们从精心规划的架构和策略中受益匪浅。成功的关键在于;流程、结构、流程和元数据的自动化。有了这些东西,我们可以很容易地启用中央数据目录,并使用户能够找到和访问他们所需的数据,也许可以使用虚拟化工具。在我上面的参考图中,我们有相同的架构布局(和组件),但有几个实例。我们集中数据访问、发布和发现。

Data mesh and my reference architecture
拥有自主团队的去中心化也可以受益于精心规划的架构和政策。这一次,我们将架构表现为一种通用的数据基础设施即服务,具有数据发布、可观察性、完整性、发现和访问的自动化过程。每个域都将能够独立地处理它们的工作负载,并使用任何东西来解决它们的需求。然而,如果一个域想要发布数据集或产品,他们必须使用我们的通用数据基础结构服务来发布。因此,基本上,我们的通用数据参考架构只提供用于共享的数据,这被认为是伟大的数据发现服务的理想选择…
我的参考架构的每一个变体都可以而且应该用伟大的技术进行实例化。以下步骤可以指导您进行选择。
第四步:与技术产品相匹配。
因此,即使我说这是技术不可知论,这也是我们试图将每个功能图标与一些技术进行映射的时候。例如。
- 我们拉…
- 我们推送使用…
- 对于流式数据,我们使用…
- 我们在…将数据写入并组织到存储桶中…。
- 我们将数据整合到实体中,并将其发布为…in…
- 将数据集成到…中…。在…上…。
- 创建…并在…中发布…。
- 使用…编排流/程序…。
- 我们使用…。作为我们的日程安排工具
- 对于数据验证,我们使用…
- 所有数据质量控制都是使用…创建和监控的…
- 我们将我们的数据谱系记录在…
- 让我们将定义和术语表存储在…
- 我们使用…存储和发布元数据…
- 我们用…监控我们的系统…。
- 我们使用…创建警报和警告…
- 对于资源和消费计划,我们使用…
- 为了运行和监控我们的操作,我们使用…
- 我们喜欢的笔记本是…
- 我们使用…进行SQL访问
- 我们使用…进行编程访问
- 对于数据发现,我们使用…
- 我们使用创建仪表板…
- 我们使用…构建和发布报告…
- 我们使用…将数据集成到…中…
- 我们精心安排了我们的模特训练…
- 我们在…中发布我们的模型…
- 我们与…共享数据…
- 我们使用…集成MA…
- 我们的工具和数据访问由…控制…
因此,30步后,我们有了一堆技术和他们的责任/目的。我们现在可以开始连接并构建我们的精细数据环境了!
- 33 次浏览
【可组合数据和分析】可组合数据和分析-拉斯维加斯制造
QQ群
视频号
微信
微信公众号
知识星球
作为一个数据专家组织,我们必须随时了解行业和技术趋势。根据Gartner最近(2022年4月5日)撰写的一篇关于2022年顶级数据和分析趋势的文章,我被要求对商业组合式D&A的主题发表评论,或者更具体地说是“可组合式R&A”。
考虑到趋势的性质,我必须承认,我不是这一特定主题的专家,但我确实进行了相当多的研究,以确保我对这一概念有足够的了解,并在这里提出我的观点。同样不幸的是,IT行业以不断为现有主题引入新术语而闻名,尽管其风格略有不同。
什么是可组合数据和分析?
可组合数据和分析的概念与具有技术头脑的业务用户通过低代码和无代码解决方案实现分析能力的模块化方法有关。这将利用基于微服务的架构,在该架构中,现有的、已经构建的数据资产可以在需要时重新使用。然后,这些构建块可以在需要时使用,也可以在应用程序开发过程中使用。另一个例子使用了“乐高”的比喻,任何人都可以通过模块化、自主性、编排和发现来消费乐高。从这种可组合的见解中受益的一些业务用户是对其投资组合进行实时更改的投资公司分析师,或者是在没有IT团队任何帮助的情况下,在疫情期间协调医院利用的医院经理。
拉斯维加斯似曾相识
大约20年前,我很幸运地被选中参加在拉斯维加斯举办的Business Objects用户会议,此前我在当地的一次活动上做了演讲。虽然这与特定技术的成功用例有关,但重点是自助服务分析功能(当时被称为商业智能,是我最近一篇文章的主题)。大约两年后,我被要求参加另一个用户会议,再次在拉斯维加斯举办。会议是关于SOA(面向服务的体系结构)的,虽然你可能想知道我的旅行体验与可组合的数据和分析是如何相关的,但我正在思考这些“可组合”体系结构的相似之处😊.我毫不怀疑,我的同事和同行可能会纠正我的技术细节,但模块化架构的想法已经存在了几十年。
一个明智而有价值的概念
我相信我们都同意,我们的数据架构师应该始终考虑模块化方法和最大限度地支持业务用户,尤其是在支持技术开始使这成为可能的情况下。Gartner的观点认为,组织不仅仅是数据和分析,而是将“变得可组合”视为持续快速变革的必要条件,因此必须在组织的业务架构中采用这种思维。
任何架构良好的数据和分析平台都应将消费者利用率和可用性作为关键目标。数据仓库或数据集市的“真相的一个价值”(one value of the truth)意图是为商业用户社区的可重用性和最大限度的消费而设计的。业务规则和计算只应用一次,自助服务分析提供了在需要时使用此类度量、KPI等的机会——这是一种固有的模块化形式,而不是Gartner所指的。
我的预测
可组合分析的潜在价值不言自明。业务用户越来越“懂IT”,低代码和无代码解决方案提供了巨大的机会,支持微服务等技术,基于云的工具是这一概念的催化剂。
正如本地和国外的组织仍在努力建立或现代化其数据平台,开始云迁移,采用“数据驱动的文化”,吸引和保留专业技能,所有这些都是在经营企业的同时,至少在可预见的未来,很多重点仍将放在……简单地做好基础工作!
- 7 次浏览
【数据与分析】我在2023年GARTNER数据与分析峰会上的五大收获
QQ群
视频号
微信
微信公众号
知识星球
内容呈现得很好,通常很有煽动性,而且总是很有见地。最棒的是,与在数据世界中生活和呼吸的专业人士建立了新的友谊,这使得每年前往佛罗里达州奥兰多的旅行非常值得门票。
话虽如此,以下是我从今年的数据与分析峰会中得到的五大收获。由于全球疫情,这是过去七个月来的第二次峰会,而不是通常的年度盛会。

Profisee’s Malcolm Hawker (right) presenting at the summit with Nestlé Purina’s VP of Data Science, Brian Zenk (right), on business value and innovation.
1.会议主题:时间机器
和往常一样,开幕式主题演讲是一场高度精炼和激动人心的活动,在一个挤满了4000多名数据专业人士的房间里进行。尽管开幕式的主题演讲令人兴奋,但我还是有一些严重的似曾相识,因为我确信我以前已经听过大多数主题演讲了——这是因为我听过。
回顾过去十年Gartner商业智能/数据和分析会议,忽略闪亮的新事物、关注商业价值以及团队发展和领导力的重要性等关键主题正在反复出现——在另一个新的商业价值框架的情况下,发言者承认他们重复了这些主题。
公平地说,在经营企业时,许多成功的关键驱动因素往往不会改变。然而,主题演讲的核心信息本可以在10年前由这些确切的演讲者传达,也同样重要。
除了一些引人注目的重复过去活动的主题内容之外,我觉得演讲者错过了一个绝佳的机会,将另一个会议主题融入他们的演讲中:可持续性。
作为一个主题,“目标导向”似乎是一个绝佳的机会,可以讨论如何使用数据来支持更深层次的社会或环境问题。但相反,“目的”的概念与新的商业价值框架(并非如此)直接相关。
换言之,就主旨而言,“目的”和“利润”本质上是同义词。从好的方面来看,新的价值框架似乎在很大程度上是从以前类似的价值框架努力中回收的——所以至少它是使用可持续实践创建的。
2.战略与实施之间明显且日益扩大的差距
虽然听到多位Gartner分析师承认,数据编制( data fabrics)、数据可观察性和其他概念数据管理框架——包括可组合性,更多内容如下——实际上不能从任何一家供应商那里购买,我感到非常耳目一新,但这也带来了一点问题。
根据Gartner的数据,我们知道许多组织在整体数据和分析成熟度方面面临着严峻的挑战。这意味着这些新框架的复杂性——跨越人员、流程和技术——远远超出了大多数公司的掌握范围。
因此,尽管数据领导者了解市场的发展方向可能有助于为他们的长期数据战略提供信息,但事实是,大多数CDO无法从这些新框架中受益——至少在目前的状态下不会。
换言之,Gartner在这些活动中提供的战略见解与他们提供的关于如何实施这些见解的见解之间存在着明显且日益扩大的差距。许多分析人士在发言中经常强调战略与执行之间的差距。例如,从众多以人工智能为中心的演示中可以看出:“操作人工智能仍然是最大的挑战。”
Gartner非常善于建立“基础”(周一上午充满了关于基础数据管理问题的内容),而且他们在帮助制定长期数据和分析战略方面非常有效。
但是,如果你是一个脚踏实地的数据领导者,并且你试图了解从你现在的位置到你想去的位置所需的所有步骤,那么你可能会在离开奥兰多会议时想要更多。更多。
战略和运营之间的这种洞察力差距很大程度上是由于Gartner分析师队伍中缺乏实际操作的数据从业者——至少是那些积极参与这些研发峰会的分析人员。Gartner的知名度较高的分析师往往都是职业思想领袖,很少有人长期在战壕中领导他们巧妙定义的战略框架和概念的任何实际应用。
因此,如果你是一个急于吸引和留住顶尖人才的CDO,并且你想知道在这个世界上你会如何在数据结构上执行,那么你肯定不是唯一一个。
3.生成式AI龟兔之争
周一主题演讲中的一句话引起了我的共鸣:“ChatGPT有趣吗?是的。这是你现在应该投入大量资金的东西吗?可能不是。”虽然这对许多公司来说可能是真的,但对我来说,将ChatGPT和Hadoop等同于“闪亮的新事物”的描述似乎是鲁莽的
记录在案,在我们的数据和分析世界里,过度关注技术总是一件坏事。
然而,我不记得有多少青少年使用Hadoop来完成家庭作业。Generative AI的大规模采用是基于它为超过一亿活跃用户提供的变革价值,而Hadoop允许一小群数据科学家回答业内无人提出的问题。将它们进行比较毫无意义。
因此,尽管在Gartner活动上有一些关于人工智能和机器学习的精彩基础演讲,但Gartner似乎没有跟上市场的步伐。
微软的一篇演讲完全集中在生成性人工智能是如何深入融入他们的数据和分析产品中的——现在——真正巩固了主题演讲中所支持的“观望”与一家更专注于加快上市速度和整合一项已经显示出明确而有意义的价值主张的公司之间的脱节。
4.那次演讲让一切都变得有价值
尽管上面提到了Gartner回收旧内容和行动太慢的问题,但他们仍然坚持进行一两次令人难以置信的前瞻性和发人深省的会议演示,这可能会让你想继续回来看更多。
在这次活动中,这是Mark Beyer关于他所说的“活动元数据双螺旋”(The Active Metadata Double Helix)的演讲,这是马克试图描述他认为从“设计”数据到“观察”数据的必要变化。
从表面上看,这似乎是我们一直以来的做法,我们观察,然后根据观察结果设计或建模。新技术的加入正在从根本上改变这种模式。
更深入地讨论“激活”的元数据将如何帮助转变数据管理业务,即使不是更多,也值得一篇独立的博客文章。但长话短说,人工智能和图形的进步将有助于使数据能够对其使用和治理进行分类。
随着时间的推移,数据本身将定义和管理其治理和管理,而不是让人类定义和管理数据的“规则”。这包括从数据质量规则到数据集成模式的所有内容,但也扩展到业务应用程序和工作流中数据的操作使用。
所以,当马克谈到“观察”数据时,并不是人类进行所有的观察,而是人工智能驱动的知识图。这些技术在企业数据管理中的规模和自动化将真正改变游戏规则。
这一主题是使用先进技术实现从规则或模式定义的数据管理到更多元数据和概念/上下文定义数据管理的缓慢过渡,在其他演示中也得到了重复,包括关于自然语言处理、应用数据可观察性,当然还有数据编制(data fabric)的会议。
在过去,Gartner会将这一更广泛的趋势描述为“增强数据管理”,但截至本次会议,这一新的数据管理学科或方法似乎不再有自己的名字。也许这是一个有意识的决定,但我怀疑不是。
5.GARTNER仍然是会议的黄金标准(尽管有些小问题)
Gartner知道如何办好大型行业会议。与拉斯维加斯的其他大型会议相比,在那里,你的酒店房间和会议厅之间通常需要步行两英里,迪士尼度假区的物流很容易导航,对与会者也很友好。
有很多选择可以偷偷溜出去给设备通电或找一个安静的地方,有几种食物和饮料的选择不需要你每次感到口渴时都向供应商挑战。食物的质量仍然很高——如果你问我的话——考虑到要养活的人的数量,它的质量高得惊人。
这里唯一真正的问题是周一和周二早上的一些反常的凉爽温度,导致军用餐厅帐篷的温度徘徊在40多度和50多度之间。
这使得原本会是一次积极的早餐体验变成了一次相当于北极熊游泳的会议。Gartner会议移动应用程序坚固且易于使用,但在会议期间实现任何形式的社区/同行互动或反馈方面存在显著差距。
奖金回合:经济衰退?什么样的衰退?
我们可能生活在一个高度不确定的时代,全球和国家经济形势仍然非常混乱,但如果我们处于任何形式的全球衰退的边缘,你都不会从与会者的出席人数或情绪中知道这一点。
在三天的时间里,我在我们的展厅展位上与数据领导者进行了一百多次对话,在早餐、午餐和晚餐时,我想不起有人对经济放缓表示担忧。
相反,公司仍然专注于以数据为中心的基础举措,其中许多举措是在2020-2022年启动的。我听说过许多情况,公司将主数据和数据治理计划置于其他优先事项之上,因为他们认识到,值得信赖和可操作的数据是所有下游工作的关键,无论是运营还是转型。
值得注意的添加和遗漏
附加–ESG/可持续性
2022年,由于新冠肺炎和欧洲战争,环境、社会和治理(ESG)倡议短暂中断,但本周在奥兰多又回来了。我预测,到2024年,人们将更加关注消除“暗数据”和其他导致数据中心过度消费的研发驱动因素,而数据中心作为一个行业,其温室气体排放量超过了航空业。
遗漏——可组合D&A
在过去的两年里,Gartner在研发活动中一直在大力宣扬“可组合性”,这与Gartner IT研讨会上发出的类似鼓点如出一辙。然而,这一鼓点在此次活动中几乎没有引起轰动,这通常意味着——由于缺乏市场采用——Gartner将缩减炒作机器,让之前的“顶级趋势”逐渐被遗忘。
遗漏——数据即产品
虽然会议演示中提到了这一点,但LinkedIn和其他社交渠道上围绕数据产品/数据作为一种产品的热议与Gartner在此次活动中的报道程度之间存在明显的脱节。我认为这在很大程度上是由于数据产品和数据网格之间的紧密联系,Gartner避免推广这种联系,因为许多人认为它是数据结构(data fabric) 的竞争对手。
遗漏——增强数据管理
在两年的大部分时间里,Gartner将图形和人工智能等新技术在传统数据管理中的应用称为“增强数据管理”。然而,这个标签似乎已经失宠了,可能是因为大多数讨论它的演示都严重倾向于数据自动化,而不仅仅是增强。正如我在上面提到的,Gartner很乐意在这里提出一个新名称来描述这个充满主动元数据的数据管理世界。如果数据结构(Data Fabric)就是架构,那么这门学科叫什么?
- 19 次浏览
【数据和人工智能趋势】2024年十大数据和人工智能趋势
QQ群
视频号
微信
微信公众号
知识星球
从LLM将现代数据堆栈转换为向量数据库的数据可观察性,以下是我对2024年顶级数据工程趋势的预测。
“数据和人工智能领域发展迅速。如果你不偶尔停下来环顾四周,你可能会错过它。”
2023年是GenAI的一年。2024年将成为GenAI的又一年。
但在2023年,团队争先恐后地点名,2024年,团队将优先考虑人工智能模型的实际业务问题。随着新的关注,出现了新的优先事项。
当谈到数据的未来时,上涨的浪潮会让所有的船只都振奋起来。GenAI将在2024年继续崛起,同时提高数据行业的标准和优先事项。
以下是我对数据和人工智能团队下一步的十大预测,以及你的团队如何保持领先。
1.LLM将变革技术堆栈
这是一个既定的。
可以毫不夸张地说,在过去的12个月里,大型语言模型(LLM)已经改变了技术的面貌。从拥有合法用例的公司到拥有技术寻找问题的夜间飞行团队,每个人和他们的数据管理员都试图以这样或那样的方式使用生成人工智能(GenAI)。
LLM将在2024年及以后继续这一转变——从推动对数据的需求增加和需要向量数据库(也称为“人工智能堆栈”)等新架构,到改变我们为最终用户操纵和使用数据的方式。
自动化数据分析和激活将成为每个产品和数据堆栈各个级别的预期工具。问题是:我们如何确保这些新产品在2024年提供真正的价值,而不仅仅是公关信贷的一点新闪光?
2.数据团队看起来像软件团队
最复杂的数据团队将他们的数据资产视为真正的数据产品——包括产品需求、文档、冲刺,甚至最终用户的SLA。
因此,随着组织开始将越来越多的价值映射到其定义的数据产品中,越来越多的数据团队将开始像他们的关键产品团队一样寻找并被管理。
3.软件团队将成为数据从业者
当工程师试图在不考虑数据的情况下构建数据产品或GenAI时,结果并不好。问问联合医疗就知道了。
随着人工智能继续吞噬世界,工程和数据将成为一体。如果没有对人工智能的关注,任何主要的软件开发都不会进入市场——如果没有某种程度的真实企业数据为其提供动力,任何主要人工智能也不会进入市场。
这意味着,当工程师们寻求提升新的人工智能产品时,他们需要着眼于数据——以及如何使用数据——以构建增加新的持续价值的模型。
4.RAG将是所有的RAGe
在一系列备受瞩目的GenAI失败之后,对干净、可靠和精心策划的上下文数据的需求变得越来越明显,以增强人工智能产品。
随着人工智能领域的不断发展,普通LLM培训中的盲点变得非常明显,拥有专有数据的团队将转向RAG(检索增强生成)和大规模微调,以增强其企业人工智能产品,并为其利益相关者提供可证明的价值护城河。
RAG在市场上仍然相对较新(它于2020年由Meta AI首次引入),各组织尚未开发出关于RAG的经验或最佳实践,但它们正在到来。
5.团队将运营适合企业的人工智能产品
保持趋势的数据工程趋势——数据产品。毫无疑问,人工智能是一种数据产品。
如果说2023年是人工智能的一年,那么2024年将是人工智能产品投入运营的一年。无论是出于需要还是胁迫,各行业的数据团队都将采用适合企业的人工智能产品。问题是,他们真的会为企业做好准备吗?
(希望)当董事会提出要求时,创建随机聊天功能来表示你正在集成人工智能的日子已经一去不复返了。2024年,团队可能会变得更加复杂,如何开发人工智能产品,利用更好的培训实践来创造价值,并识别需要解决的问题,而不是推出技术来制造新问题。
6.数据可观察性将支持人工智能和向量数据库
在亚马逊网络服务公司(AWS)2023年的CDO Insights调查中,受访者被问及他们的组织在实现生成人工智能的潜力方面面临的最大挑战是什么。
最常见的答案是什么?数据质量。
生成型人工智能的核心是一种数据产品。和任何数据产品一样,没有可靠的数据,它就无法正常工作。但在LLM的规模上,手动监测无法提供使任何人工智能可靠所需的全面有效的质量覆盖。
为了真正取得成功,数据团队需要一种针对人工智能堆栈量身定制的活的、呼吸式的数据可观察性策略,使他们能够在不断增长的动态环境中始终如一地检测、解决和防止数据停机。而且,这些解决方案需要优先考虑分辨率、管道效率和支持人工智能的流媒体/向量基础设施,才能成为2024年现代人工智能可靠性之战的竞争者。
7.大数据会变小
30年前,个人电脑还是个新奇事物。现在,随着现代Macbook拥有与2012年Snowflake推出MVP仓库的AWS服务器相同的计算能力,硬件正在模糊商业和企业解决方案之间的界限。
由于大多数工作负载都很小,数据团队将开始使用进程内和内存/进程内数据库来分析和移动数据集。
特别是对于需要快速扩展的团队来说,这些解决方案起步很快,可以通过商业云产品提升到企业级功能。
8.优先选择合适的尺寸
今天的数据领导者面临着一项不可能完成的任务。使用更多的数据,创造更多的影响力,利用更多的人工智能——但要降低这些云成本。
正如《哈佛商业评论》所言,首席数据官和人工智能官注定会失败。IDC报告称,截至2023年第一季度,云基础设施支出增至215亿美元。麦肯锡表示,许多公司的云支出每年增长30%。
低影响的方法,如元数据监控和允许团队查看和适当规模利用率的工具,在2024年将是非常宝贵的。
9. Iceberg将升起(Apache Iceberg)
Apache Iceberg是一种开源数据lakehouse表格式,由Netflix的数据工程团队开发,旨在提供一种更快、更容易的大规模处理大型数据集的方法。它被设计为可以使用SQL轻松查询,即使是对于数据量为PB的大型分析表也是如此。
在现代数据仓库和湖畔小屋将同时提供计算和存储的地方,Iceberg专注于提供经济高效的结构化存储,这些存储可以由许多不同的引擎访问,这些引擎可能会同时在您的组织中使用,如Apache Spark、Trino、Apache Flink、Presto、Apache Hive和Impala。
最近,Databricks宣布,Delta表元数据也将与Iceberg格式兼容,Snowflake也一直在积极与Icebeberg集成。随着lakehouse成为许多组织的实际解决方案,Apache Iceberg和Iceberg替代品也可能继续受欢迎。
10.为某人返回办公室
RTO——每个人最不喜欢的缩写。或者可能是他们最喜欢的!老实说,我现在跟不上了。虽然团队在这个问题上似乎存在分歧,但越来越多的团队被召回他们的隔间/开放式平面图/灵活的工作环境,每周至少有几天。
根据Resume Builder2023年9月的一份报告,90%的公司计划在2024年底前执行重返办公室的政策,这距离2020年那个致命的春天已经过去了近四年。
事实上,在过去几个月里,包括亚马逊的Andy Jassy、OpenAI的Sam Altman和谷歌的Sundar Pichai在内的几位有权势的首席执行官已经制定了重返办公室的政策。在办公室工作(至少是兼职)与完全在家工作相比,似乎至少有一些好处。
发现自己在永远呆在家里的营地?答案似乎是——就像数据中的情况一样——提供更多的价值。尽管最近的经济逆风及其对就业市场的影响,但数据和人工智能团队的需求量很大。雇主通常会尽一切努力得到他们——并留住他们。虽然一些公司要求所有员工返回办公室,无论其职位如何,但Salesforce等其他公司则要求非远程工程师减少工作时间,每个季度总共工作10天。
- 26 次浏览
【数据团队】数据团队的下一次大危机
QQ群
视频号
微信
微信公众号
知识星球
数据团队比以往任何时候都更重要,但他们需要更接近业务。以下是我们如何纠正这艘船。
在过去的十年里,数据团队一直在水下和乘风破浪。
我们一直在构建现代数据堆栈,迁移到Snowflake,就像我们的生活依赖于它一样,投资于无头BI,并以比反向ETL更快的速度发展我们的团队。然而,很多时候我们并不知道这些工具是否真的为企业带来了价值。
别误会我的意思:我坚信现代数据堆栈。在快速高效地生成分析时,云原生、基于SQL和模块化是最好的选择。但在当今这个预算紧张的时代,精益团队以云的弹性和速度为由,不足以证明对这些工具的投资是合理的。
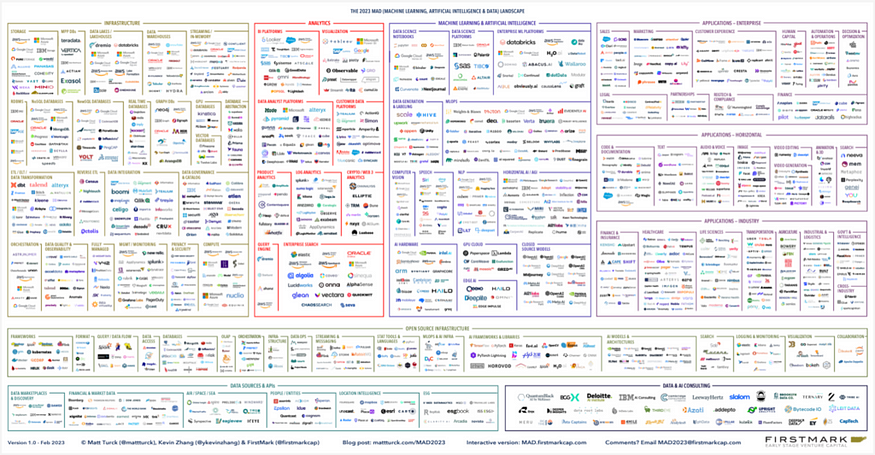
The modern data stack menu. Image courtesy of Matt Turck and Firstmark Capital.
现在,当服务员放下支票时,首席财务官正在调查每一行项目,而不是不假思索地扑通一声放下信用卡。
对于数据团队来说,账单已经到期。本应是一个机会却变成了一场危机,因为组织发现他们离企业不够近,无法解释为什么要订购龙虾。
我们是怎么到这里的?
数据团队作为最早在几乎没有问题的情况下构建8位数技术堆栈的部门之一,创造了历史。
在2010年代中期,数据领导者的任务是“成为数据驱动的”——无论这意味着什么。当然,数据可以帮助优化成本,提高财务绩效,指导产品路线图,提供惊人的客户见解,并获得竞争优势。但成为“数据驱动”是一个不透明的目标,指标模糊,没有明确的投资回报率。
当然,数据团队并没有耍无赖。列车在“不惜一切代价的增长”时代全速前进。高管和决策者着眼于谁在获胜——世界上的谷歌、奈飞和亚马逊——对数据的投资似乎是一件轻而易举的事。
我们这个新生的行业建立了内部黑客入侵的堆栈,或者临时购买以解决特定问题。无论这些系统——以及数据本身——是否与预期的、受软件工程启发的五个9的可靠性相集成,通常都是事后考虑的问题。
在这个阶段仅仅掌握数据就足以推动经济增长。有些数据是有用的,有些数据不是,但我们至少有。到2020年,随着一切都变得数字化并开始排放数据,疫情火上浇油。
Snowflake、Databricks和Fivetran等技术像魔术一样出现,解决了许多与“成为数据驱动”相关的问题。更快的见解?检查更容易摄入?检查更智能的型号?检查
然而,最终,这些解决方案开始将数据量与成本联系起来。快进到今天,您的数据每年都在快速增长,数据量是现在的1000倍,成本是现在的100倍。在这个市场上,这是一粒难以下咽的药丸。
为了提前说明并证明我们的工作是合理的,仅仅提供数据是不够的。它还需要是可靠的和专门建造的。
换句话说,数据团队需要更接近业务。
那么我们该如何到达那里呢?我有一些想法。
通过了解人来了解业务
Who doesn’t love a good stuffed penguin? Photo by Andrea Gradilone on Unsplash
你有没有根据你所知道的一个随机事实(即他们喜欢企鹅),给多年未见的人买过礼物,比如儿时的老朋友或远房表亲?
如果答案是肯定的,那么你肯定不是一个人。数据团队,就像一位远方的朋友送了一份看似周到的礼物一样,希望他们的利益相关者做正确的事情,拥有丰富的见解,可以改善他们的工作,为业务带来价值。但你不能伪造数据的同理心。
如果你不深入了解消费者的需求,你的报告和分析将像一只5英尺高的毛绒企鹅一样有价值。
当涉及到驱动价值时,数据领导者应该做的第一件事就是与消费者和业务利益相关者交谈。这是显而易见的建议,但“需求收集”的任务通常委托给分析师或嵌入式团队。这在一定程度上是有效的,任何玩过电话游戏的人都可以告诉你。
例如,Red Ventures的数据工程总监Brandon Beidel每周都会与每个业务团队会面,以更好地了解他们的用例并创建知情的数据SLA。
他说:“我总是用简单的商业术语来描述对话……我会问:
- 你是怎么使用这张表的?
- 你什么时候看这些数据?你什么时候报告这些数据?这些数据是否需要达到每分钟、每小时、每天?
- 这有什么用?
- 如果数据延迟,谁需要得到通知?”
这种亲自动手的领导方式有什么优势?你可以制定订婚计划。
布兰登说:“如果我被告知数据很重要,但没有人能告诉我它是如何使用的,我也会反驳。对话变得更加复杂,我甚至会得到可以快速转换为查询的描述,比如‘这一列中没有空值’。”。
你也可以像产品团队发起NPS调查一样,对数据消费者进行集体调查,这是捷蓝航空数据团队在最近的网络研讨会上讨论的一项策略。
创建异步反馈回路
你不可能总是在直播中与每个人交谈。异步通信和反馈循环对于数据和业务协调至关重要(尤其是在当今的远程世界中)。
如果你没有一个可广泛访问和活跃的Slack频道来进行这些类型的通信,请考虑立即创建这种类型的通信空间。这是数据和分析总监Priya Gupta如何在超增长初创公司Cribl创建数据文化的关键之一。她说:
“我们的数据团队在过度沟通方面犯了错误,我们试图通过尽可能多的渠道进行沟通。就像我们作为数据工程师对没有充分记录的数据源持怀疑态度一样,业务用户天生会对安静的数据团队持怀疑态度。
Slack或Teams等聊天应用程序在这方面非常有用。我们为所有请求创建一个集中的通道,这有两个目的。它使整个分析团队能够看到请求,并允许其他利益相关者看到他们的同行感兴趣的内容。
你会看到的最令人满意的事情是,有人在你的公共Slack频道上提出请求,然后另一个利益相关者回答了这个问题。”
但也许最重要的反馈循环是如何向消费者展示数据产品的可信度和可靠性。并非所有的数据产品都是或必须是100%可靠的。
一旦您创建了自助服务或发现机制,就要加倍努力,显示可靠性SLA以及产品满足该SLA的时间百分比。这正是罗氏在其数据网格上构建数据产品时所采取的策略。
穿着数据消费者的鞋子走一英里
You probably don’t even need to walk a full mile in their shoes… maybe just a few dashboards-length? Photo by Jose Fontano on Unsplash
如果你感到雄心勃勃,下一步就是从空谈转向散步。毕竟,当涉及到数据时,业务利益相关者并不总是熟悉可能的艺术。
与亨利·福特所说的消费者会要求他买一匹更快的马类似,有时数据消费者只会要求一个更快的仪表板。我们不需要指望商业利益相关者告诉我们什么是重要的,而是需要开始就在哪里寻找、寻找什么以及如何应用这些见解产生我们自己的假设。
要做到这一点,让数据团队的一名成员与利益相关者接触,并用数据生活。
这是Upside的分析工程团队在高级数据分析工程师Jack Willis“……当我真正看到他们在做什么时,意识到为这个团队制作的许多[数据]产品都不合格。”
他们的数据启用框架包括三个步骤:完全嵌入团队,与利益相关者一起规划,并培训团队以确保可持续的所有权。这是一种有效的方式,可以最大限度地发挥新角色的价值,比如分析工程师,他们可以弥合数据工程师和分析师之间的差距。他们可以更深入地了解业务是如何运作的,以及哪些数据会真正起到推动作用。
Jack说:“我们在数据产品中建立了一条信任之路……让我们的利益相关者不怕数据和工程,让我们的数据从业者不怕业务……这让我们登上了数据飞轮。”。
让采纳成为你的向导
你并不总是需要过数据消费者的生活才能理解他们的故事。它还通过他们采用了什么…以及他们没有采用什么来讲述。事实上,“暗数据”和数据竖井可能比采用良好的数据产品更具信息性。
Maybe we should move the path over there? Image courtesy of author.
如果V_GOOD_DASHBARD_48是由您的业务运营团队导出到Excel的文件(即使知道您的Looker技能被低估会让您感到痛苦),那么它比V_GOOD_dASHBARd_49更有价值。
在您从客户数据平台过渡到更云原生的解决方案之前,请了解营销团队是如何使用它的以及为什么使用它。直观的自助服务访问可能会带来与您所能提供的强大客户细分一样多的价值。
要做到这一点,数据团队需要投资于方法和技术,以揭示谁在使用什么数据以及如何使用。
但现代数据堆栈本身并不能让数据团队更清楚地了解他们的数据,也不能提高数据团队和利益相关者之间的透明度。如果说有什么不同的话,那就是现代数据堆栈可能会以较少的清晰度和上下文提供更大的访问权限,从而使这种本已脆弱的关系复杂化。
我们需要在上游表和下游资产之间绘制连接的方法,这种方法可以整合整个数据环境,而不仅仅是仓库、湖泊或转换层。我们需要一种真正的端到端的方法,一直到消费层。
在当今时代,无知不是幸福;这是一个失败的处方。我们数据资产的可见性和透明度将帮助我们确定优先级,保持专注,并真正推动业务发展。
创建语义层
我们的行业在编纂语义层方面正在取得进展,自助数据平台正在将更多的权力交给分析师,让他们以前所未有的方式处理数据。
如果不深入讨论业务如何思考和使用数据,几乎不可能创建一个语义层,有时被称为度量层。
当你正在为“账户”的含义创造一个普遍的真理,并与商业利益相关者交谈,以确定这是否应该包括免费增值用户时,你正在深入探索和巩固你的业务的真正驱动力。
语义层可以成为一个很好的借口,让你在本该知道的问题上进行从未有过的对话。你的高管可能也有同样的感受。他们也不太明白“账户”是什么意思。
随着真正的语义层开始形成,帮助您开发和标准化北极星指标的解决方案,如增强分析平台或数据笔记本,可以提供一个很好的权宜之计。
专注于重要的短期胜利
处理临时请求、调查破裂的数据管道,以及回答《金融》杂志当天的第五个问题中的Bob,都是快速的胜利,但它们并没有起到有意义的作用。
另一方面,在多年时间范围内启动的全公司计划往往在启动电话之前就注定要失败。大型“资本P”项目(数据网格,有人吗?)很重要,也很有价值,但它们不需要“完整”才能有用。最好的办法是专注于具有明确商业价值的小型短期胜利。
同样,收养应该是你的指南。将您的大部分资源集中在优化和构建您的关键用例和数据资产上(您确实了解您的关键数据资产,对吗?)。
Understanding usage of key assets can help you zero in on what data actually matters for your business stakeholders. Image courtesy of author from internal data platform.
你想提高数据信任度吗?关注与最高影响相关的一小部分数据,如客户行为或第三方营销数据。
- 按域划分数据,以便您知道当出现故障时,业务的哪一部分负责
- 尽可能少地花时间在新鲜度、数量和模式检查上(你知道,这些检查很简单),然后专注于编写自定义规则来捕捉分布或字段健康异常。
- 在数据团队和业务利益相关者之间建立Slack、Teams或信鸽渠道,在数据中断时提醒所有相关方,并在血统的帮助下,就哪些报告和仪表盘受到了影响提出建议。
缩小你的注意力是否意味着你不会让每个人都高兴。对缩小你的关注点是否意味着你本季度会更成功?对
危机得以避免?
解决我们的下一次大危机不会一蹴而就。与任何类型的变革一样,让我们的工作更接近业务需要时间、无情的优先级,以及了解我们在哪里可以推动最大价值的能力。
就我个人而言,随着我们采用更多的流程、技术和团队结构,将数据团队从风暴中带到更平静的水域,我对未来的发展感到无比兴奋。
那么,您的团队将如何应对下一次重大危机呢?我洗耳恭听。
- 6 次浏览
【数据平台】浏览数据景观:制定数据平台路线图指南
QQ群
视频号
微信
微信公众号
知识星球

数据已成为数字时代企业最有价值的资产之一。随着生成和存储的数据量不断增加,组织制定明确的管理这些信息的计划至关重要。这就是数据管理路线图发挥作用的地方。数据管理路线图是一个战略计划,概述了组织将如何在指定的时间段内收集、存储、使用和保护其数据。本指南旨在帮助程序员驾驭复杂的数据管理环境,并制定路线图,帮助他们实现数据管理目标。
什么是数据管理?在构建数据平台时应该牢记什么?
数据平台的主要块包括数据接收、数据转换和数据访问。每个区块都有很多挑战和需要学习的技术。在构建数据平台时,您需要加入不仅包括开发人员,还包括开发人员和财务人员的任务。你需要公司的所有部门都参与进来,因为平台会影响公司的各个层面。
所以,让我们试着把不同的层拆开,试着看看每一层的不同方面,以及需要做什么技术和任务。
数据摄入
确定需要摄入数据湖的数据来源很重要。
内部数据
第一批数据通常是公司内部不同流程生成的数据。
标准的公司数据源是一种内部微服务。由于每个微观服务都有自己的数据(使用12因素方法),并且我们通常需要跨微观服务的报告,因此我们需要将所有数据放在一个地方进行报告分析。
每个微服务的数据可以是一个数据库(多种类型:结构化、非结构化)。数据也可以来自服务中的消息队列。所有这些数据都需要同步到你的数据湖(可能使用像debezium这样的CDC工具)。
外部数据
公司通常不仅需要来自内部来源的数据,还需要来自公司使用的外部服务的数据。这可以是crm、外部应用程序等等。
处理摄入

当然,我们可以创建自己的数据管道来获取所有这些数据,但今天有很多工具可以为我们做到这一点。
其中的一小部分是:upsolver、keboola、fiftran、stitch、rivery和其他。一些开放的来源是空气细胞、海底生物和其他。
真相的来源
今天,除了数据湖,我们还有一个数据仓库(BigQuery、Databricks、Snowflake…)。在我看来,数据仓库不是数据湖,您应该将所有数据保存到数据湖(不可变文件)中作为真理的来源,并将数据仓库用于所有其他层。因此,请确保您的接收工具知道如何保存到s3以及同步到您的数据仓库。
文件中的真实性来源背后的原因是数据仓库本质上是可变的存储。这导致了数据发生变化的问题领域,我们无法恢复到原始数据。
数据湖问题
在构建数据湖时,您需要考虑一些问题:
桶与文件夹
- 桶和对象是主要资源
- AmazonS3有一个扁平的结构,而不是像您在文件系统中看到的那样的层次结构
- 您的帐户中最多有100个存储桶
- 在分区内所有AWS区域的所有AWS帐户中,每个bucket名称必须是唯一的
- Buckets-权限、生命周期…
数据存储结构注意事项
- 安全性(每个铲斗)
- 数据传输速率
- 分区
- 制作数据的多个副本(非结构化->暂存->数据库)
- 保留策略(法规遵从性、成本)
- 可读文件格式
- 合并小文件
- 数据治理和访问控制
数据建模

一旦您的数据进入数据仓库,您就需要设置青铜、白银和黄金层。需要通过为表和列创建标准命名约定来管理数据。列可能需要转换为正确的格式。
数据建模的最佳工具是dbt。要为您的数据设置dbt项目,请参阅dbt-项目结构、dbt-数据库模式。
数据建模模式
我们不会讨论所有不同的建模模式,只会提到一些,这样您就可以开始阅读并深入了解它们。
星形模式
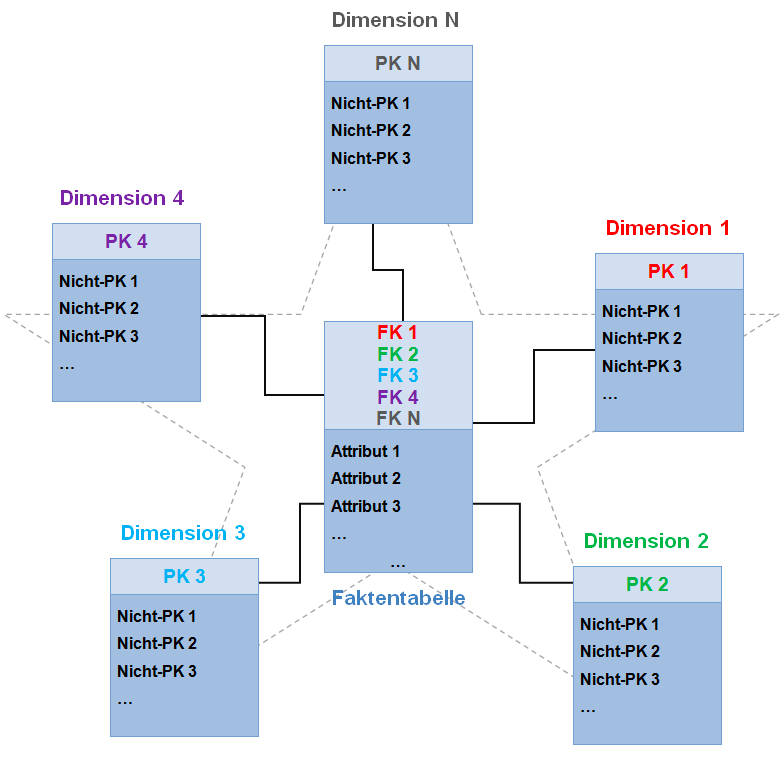
来自维基百科:
星型模式是最简单的数据集市模式,也是最广泛用于开发数据仓库和维度数据集市的方法。星形模式由一个或多个引用任意数量维度表的事实表组成。星形模式是雪花模式的一个重要特例,对于处理更简单的查询更有效。
缓慢变化的维度
缓慢变化维度(SCD)是一种在数据仓库中存储和管理当前和历史数据的维度。它被认为是跟踪维度记录历史的最关键的ETL任务之一。
SCD有三种类型,您应该选择最适合您需求的一种。
类型1 SCD-覆盖

在类型1 SCD中,新数据覆盖现有数据。因此,现有数据丢失,因为它没有存储在其他任何地方。这是您创建的标注的默认类型。创建类型1 SCD不需要指定任何附加信息。
类型2 SCD-创建另一个维度记录
类型2 SCD保留值的完整历史记录。当选定属性的值更改时,当前记录将关闭。将使用更改后的数据值创建一个新记录,该新记录将成为当前记录。每个记录都包含有效时间和过期时间,以标识记录处于活动状态的时间段。
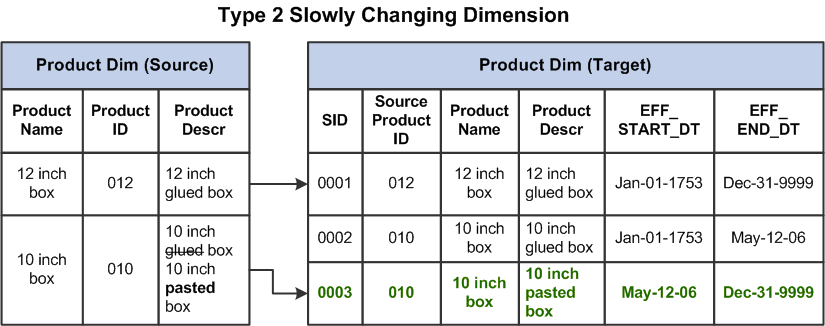
类型3 SCD-创建当前值字段
类型3 SCD为某些选定级别属性存储两个版本的值。每条记录都存储选定属性的上一个值和当前值。当任何选定属性的值发生更改时,当前值将存储为旧值,新值将变为当前值。
数据质量
将数据带到仓库后,您需要验证数据本身。数据的验证包括确保您的数据按时到达,完整准确,并与所有其他数据输入一致。
有多种工具可以帮助您提高数据质量。
你可以从aws-Deequ开始,使用 great expectations,甚至使用机器学习来检查与Monte Carlo等工具的差异。
数据分析

一旦您拥有了所有数据,并且验证了质量,您现在需要一个工具来帮助您创建仪表板和数据分析。有多家供应商将为您提供帮助。
数据治理
一旦你开始,需要解决的一个问题是谁能看到什么数据。你需要将敏感数据限制在需要访问的人身上的工具。有些数据仓库支持acl功能(如雪花和bigquery),有些则不支持。
数据目录
数据目录是一组元数据,与数据管理和搜索工具相结合,帮助分析师和其他数据用户找到他们需要的数据,作为可用数据的清单,并提供信息来评估数据是否适合预期用途。
数据目录非常重要,它们所提供的特征集差异很大。考虑到您有多个数据源和管道,所有这些都应该进入目录。
总结
以下是作为数据平台之旅的一部分所需技术的思维导图。

参考文献
演示文稿的幻灯片可以在数据管理演示文稿中找到。
- 27 次浏览
【数据库架构】隔离水平和脏读物快速入门
重要要点
- 仅凭ACID或非ACID来思考,还需要知道数据库支持的隔离级别。
- 标榜为“最终一致”的某些数据库可能返回与任何时间点不一致的结果。
- 一些数据库提供的隔离级别比您要求的更高。
- 脏读会导致您看到同一记录的两个版本,或者完全错过一条记录。
- 在单个事务中多次重新运行查询时,可能会出现幻像行。
最近,当开发人员David Glasser了解MongoDB默认执行脏读的糟糕方式时,MongoDB再次成为Reddit的佼佼者。 在本文中,我们将解释什么是隔离级别和脏读以及如何在流行的数据库中实现它们。
在ANSI SQL中,有四个标准隔离级别:可序列化,可重复读取,已提交读取和未提交读取。
许多数据库的默认设置为“读取已提交”,它仅保证在进行该事务时您不会看到过渡中的数据。它通过在读取期间短暂地获取锁来实现此目的,同时保持写入锁直到事务被提交。
如果您需要在一个事务中多次重复相同的读取操作,并且想要合理地确定它总是返回相同的值,则需要在整个持续时间内保持读取锁定。使用“可重复读取”隔离级别时,将自动为您完成此操作。
我们说“可重复读”是“合理肯定的”,因为可能存在“幻读”。使用where子句(例如“ WHERE Status = 1”)执行查询时,可能会发生幻像读取。这些行将被锁定,但是没有什么阻止添加符合条件的新行。术语“幻像”适用于第二次执行查询时出现的行。
为了绝对确保同一事务中的两次读取返回相同的数据,可以使用Serializable隔离级别。这使用“范围锁”,如果新行与打开的事务中的WHERE子句匹配,则可以防止添加这些行。
通常,隔离级别越高,由于锁争用而导致的性能越差。因此,为了提高读取性能,某些数据库还支持“读取未提交”。此隔离级别忽略锁(实际上在SQL Server中称为NOLOCK)。结果,它会执行脏读。
脏读问题
在讨论脏读之前,您必须了解表实际上并不存在于数据库中。表只是一个逻辑构造。实际上,您的数据存储在一个或多个索引中。在大多数关系数据库中,主索引被称为“聚集索引”或“堆”。 (对于NoSQL数据库,术语有所不同。)因此,在执行插入操作时,它需要在每个索引中插入一行。执行更新时,数据库引擎仅需要触摸引用正在更改的列的索引。但是,它通常必须对每个索引执行两次操作,即从旧位置删除和向新位置插入。
在下图中,您可以看到一个简单的表和一个执行计划,其中更新了两个对象IX_Customer_State和PK_Customer。由于全名未更改,因此跳过了IX_Customer_FullName索引。


注意:在SQL Server中,PK前缀是指主键,它通常也是用于聚集索引的键。 IX用于非聚集索引。 其他数据库有其自己的约定。
通过这种方式,让我们看一下脏读可能导致数据不一致的多种方式。
未提交的读取最容易理解。 通过忽略写锁定,使用“读未提交”的SELECT语句可以在事务完全提交之前看到新插入或更新的行。 如果该转换然后被回滚,那么从逻辑上讲,SELECT操作将返回从不存在的数据。
在更新操作期间移动数据时,会发生两次读取。 假设您正在按州读取所有客户记录。 如果上述更新语句是在您加州记录的时间与您阅读德克萨斯州记录的时间之间执行的,则您可以看到客户1253两次; 一次使用旧值,一次使用新值。

漏读的发生方式相同。 如果我们将客户1253移到德克萨斯州到阿拉斯加,再按州选择数据,则可能会完全错过该记录。 这就是David Glasser的MongoDB数据库所发生的事情。 通过在更新操作期间从索引读取,查询会丢失记录。

根据数据库的设计方式和特定的执行计划,脏读也会干扰排序。例如,如果执行引擎收集指向所有感兴趣的行的一组指针,然后更新一行,然后执行引擎实际上使用所述指针从原始位置复制数据,则可能发生这种情况。
快照隔离或行级别版本控制
为了提供良好的性能同时避免脏读问题,许多数据库都支持快照隔离语义。在快照隔离下运行时,当前事务无法查看在当前事务之前启动的任何其他事务的结果。
这是通过制作要修改的行的临时副本来完成的,而不是仅仅依靠锁。这通常称为“行级版本控制”。
当请求读取提交隔离时,大多数支持快照隔离语义的数据库都会自动使用它。
SQL Server中的隔离级别
SQL Server支持所有四个ANSI SQL隔离级别以及一个显式的快照级别。取决于使用READ_COMMITTED_SNAPSHOT选项配置数据库的方式,“已提交读”也可以使用快照语义。
在启用此选项之前和之后,请彻底测试数据库。虽然它可以提高读取性能,但可能会减慢写入速度。如果您的tempdb处于慢速驱动器上,则尤其如此,因为这是行的旧版本存储的地方。
臭名昭著的NOLOCK指令(可应用于SELECT语句)与在设置为“读取未提交”的事务中运行具有相同的效果。由于SQL Server 2000和更早版本尚未提供行级版本控制,因此该版本已大量使用。尽管不再需要或不建议使用,但该习惯仍然存在。
有关更多信息,请参见SET TRANSACTION ISOLATION LEVEL(Transact-SQL)。
PostgreSQL中的隔离级别
虽然PostgreSQL正式支持所有四个ANSI隔离级别,但实际上它只有三个。每当查询请求“读取未提交”时,PostgreSQL都会以静默方式将其升级为“读取已提交”。因此PostgreSQL不允许脏读。
当选择级别Read Uncommitted时,您实际上会获得Read Committed,并且在Repeatable Read的PostgreSQL实现中不可能进行幻像读取,因此实际的隔离级别可能比您选择的严格。这是SQL标准所允许的:四个隔离级别仅定义了哪些现象一定不能发生,它们没有定义哪些现象必须发生。
PostgreSQL没有明确提供快照隔离。而是在使用“读取已提交”时自动发生。这是因为PostgreSQL从一开始就设计为具有多版本并发控制。
在9.1版之前,PostgreSQL不提供可序列化的事务,并且会静默地将它们降级为“可重复读”。当前没有支持的PostgreSQL版本仍然具有此限制。
有关更多信息,请参见13.2。事务隔离。
MySQL中的隔离级别
InnoDB默认为“可重复读取”,但提供所有四个ANSI SQL隔离级别。读取已提交使用快照隔离语义。
有关InnoDB的更多信息,请参见15.3.2.1事务隔离级别。
使用MyISAM存储引擎时,根本不支持事务。相反,它在表级别使用一个读写器锁。 (尽管在某些情况下,插入操作可以绕过锁。)
Oracle中的隔离级别
Oracle仅支持3个事务级别:读已提交,可序列化和只读。在Oracle中,“默认值为读已提交”,它使用快照语义。
像PostgreSQL一样,Oracle不提供“读未提交”。绝对不允许脏读。
列表中还缺少“可重复读取”。如果您在Oracle中需要这种行为,则需要将隔离级别设置为Serializable。
Oracle唯一的隔离级别是只读。它没有很好的文档记录,手册只说:
只读事务仅查看那些在事务开始时提交的更改,并且不允许INSERT,UPDATE和DELETE语句。
有关其他两个隔离级别的更多信息,请参阅13数据并发性和一致性。
DB 2中的隔离级别
DB 2具有4个隔离级别,分别称为重复读取,读取稳定性,游标稳定性和未提交读取。但是,它们并不直接映射到ANSI术语。
可重复读是ANSI SQL称为可序列化的。也就是说,幻像读取是不可能的。
读取稳定性映射到ANSI SQL的可重复读取。
默认情况下,“游标稳定性”用于“读取已提交”。从9.7版开始,快照语义已生效。以前,它将使用类似于SQL Server的锁。
未提交读允许进行脏读,就像SQL Server的未提交读一样。该手册仅建议将其用于只读表,或者“在查看其他应用程序未提交的数据没有问题时”。
有关更多信息,请参见隔离级别。
MongoDB中的隔离级别
如前所述,MongoDB不支持事务。从手册中
由于MongoDB仅单文档操作是原子操作,因此两阶段提交只能提供类似于事务的语义。在两阶段提交或回滚期间,应用程序有可能在中间点返回中间数据。
实际上,这意味着MongoDB使用脏读语义,其中包括记录可能翻倍或丢失的可能性。
CouchDB中的隔离级别
CouchDB也不支持交易。但是与MongoDB不同,它确实使用多版本并发控制来防止脏读。
读取请求在请求开始时始终会看到您数据库的最新快照。
这使CouchDB等效于具有Snapshot语义的Read Committed隔离级别。
有关更多信息,请参见最终一致性。
Couchbase服务器中的隔离级别
尽管经常与CouchDB混淆,但Couchbase Server是一个非常不同的产品。对于索引,它没有隔离的概念。
在执行更新时,它仅更新主索引,如果您愿意,也可以更新“真实表”。所有二级索引均会延迟更新。
该文档尚不清楚,但在建立索引时似乎使用快照。如果是这样,脏读应该不是问题。但是由于延迟索引更新,您仍然无法获得真正的“读取已提交”隔离级别。
与许多NoSQL数据库一样,它不直接支持事务。但是,您确实可以使用显式锁。这些只能保留30秒,然后自动丢弃。
有关更多信息,请参阅锁定项目,您需要了解的有关Couchbase体系结构的所有信息以及Couchbase View Engine内部。
Cassandra的隔离级别
在Cassandra 1.0中,甚至没有隔离写入单个行。字段是一一更新的,因此您最终可能会读取包含新旧值的记录。
从1.1版开始,Cassandra提供“行级隔离”。这使其达到与其他数据库称为“读取未提交”的相同隔离级别。更高级别的隔离是不可能的。
有关更多信息,请参见关于事务和并发控制。
了解数据库的隔离级别
从上面的示例中可以看到,仅将数据库视为ACID或非ACID是不够的。 您确实需要知道它支持什么隔离级别以及在什么情况下。
原文:https://www.infoq.com/articles/Isolation-Levels/
本文:http://jiagoushi.pro/node/918
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 32 次浏览
【数据库选型】再见MongoDB,您好PostgreSQL
Olery成立于5年前。随着时间的流逝,最初由Ruby开发机构开发的单一产品(Olery声望)逐渐发展成为一套不同的产品和许多不同的应用程序。今天,我们不仅拥有信誉产品,还拥有Olery反馈,酒店点评数据API,可嵌入网站上的小部件以及不久的将来更多产品/服务。
在应用程序数量方面,我们也有了长足的发展。今天,我们部署了超过25种不同的应用程序(全部为Ruby),其中一些是Web应用程序(Rails或Sinatra),但大多数是后台处理应用程序。
尽管我们可以为迄今为止所取得的成就感到非常自豪,但总会有一些隐患:我们的主数据库。从Olery开始,我们就已经建立了一个数据库设置,其中涉及MySQL来存储关键数据(用户,合同等),而MongoDB则用于存储评论和类似数据(本质上是在数据丢失的情况下我们可以轻松检索的数据)。尽管此设置对我们非常有用,但随着我们的发展,特别是在MongoDB中,我们开始遇到各种问题。这些问题中的一些是由于应用程序与数据库交互的方式所致,有些是由于数据库本身所致。
例如,在某个时间点,我们必须从MongoDB中删除大约一百万个文档,然后在以后重新插入它们。此过程的结果是数据库几乎处于完全锁定状态,持续了几个小时,导致性能下降。直到我们执行数据库修复(使用MongoDB的repairDatabase命令)。由于数据库的大小,此修复程序本身也花费了数小时才能完成。
在另一个实例中,我们注意到应用程序性能下降,并设法将其追溯到我们的MongoDB集群。但是,经过进一步检查,我们无法找到问题的真正原因。无论我们安装了什么度量标准,使用的工具或运行的命令,我们都找不到原因。直到我们替换了集群的主节点,性能才恢复到正常水平。
这只是两个例子,随着时间的流逝,我们遇到了很多这样的情况。这里的核心问题不仅在于我们的数据库正在运行,而且每当我们调查数据库时,都根本没有迹象表明导致问题的原因。
无模式问题
我们面临的另一个核心问题是MongoDB(或任何其他无模式存储引擎)的基本功能之一:缺少模式。缺少模式听起来可能很有趣,并且在某些情况下,它当然可以带来好处。但是,对于许多人而言,无模式存储引擎的使用会导致隐式模式的问题。这些架构不是由您的存储引擎定义的,而是根据应用程序的行为和期望定义的。
例如,您可能有一个页面集合,其中您的应用程序需要一个带有字符串类型的标题字段。尽管没有明确定义,但这里的模式非常多。如果数据的结构随时间而变化,这是有问题的,尤其是如果旧数据没有迁移到新的结构中(在无模式存储引擎中这是很成问题的)。例如,假设您具有以下Ruby代码:
#!ruby post_slug = post.title.downcase.gsub(/\W+/, '-')
这将适用于每个带有标题字段且返回字符串的文档。 对于使用其他字段名称(例如post_title)或根本没有标题的字段的文档,这将不起作用。 要处理这种情况,您需要按以下方式调整代码:
#!ruby if post.title post_slug = post.title.downcase.gsub(/\W+/, '-') else # ... end
解决此问题的另一种方法是在模型中定义架构。例如,Mongoid是流行的Ruby MongoDB ODM,可以让您做到这一点。但是,在使用此类工具定义架构时,应该思考为什么他们没有在数据库本身中定义架构。这样做将解决另一个问题:可重用性。如果只有一个应用程序,那么在代码中定义架构并不是什么大问题。但是,当您有数十个应用程序时,这很快就会变成一团糟。
无模式存储引擎通过消除对模式的担心,有望使您的生活更轻松。实际上,这些系统只是让您自己负责确保数据一致性。在某些情况下,这可能会解决,但我敢打赌,对于大多数情况而言,这只会适得其反。
好的数据库的要求
这使我想到了一个好的数据库的要求,更具体地说是Olery的要求。对于系统,尤其是数据库,我们重视以下方面:
一致性。数据的可见性和系统的行为。正确性和明确性。可扩展性。
一致性很重要,因为它有助于设定对系统的明确期望。如果数据总是以某种方式存储,那么使用该数据的系统将变得更加简单。如果在数据库级别需要某个字段,则应用程序无需检查该字段是否存在。数据库即使在高压下也应该能够保证某些操作的完成。没有什么比仅插入数据而令人沮丧的了,只有在几分钟之后才显示数据。
可见性适用于两件事:系统本身以及从其中获取数据的难易程度。如果系统出现异常,则应易于调试。反过来,如果用户想查询数据,这也应该很容易。
正确性意味着系统的行为符合预期。如果将某个字段定义为数字值,则不应将文本插入该字段。 MySQL的缺点是众所周知的,因为它可以让您准确地做到这一点,结果您可能会得到虚假数据。
可伸缩性不仅适用于性能,而且还适用于财务方面,以及系统如何满足随着时间变化的需求。一个系统的性能可能非常好,但是却不能以大量金钱为代价,也不会减慢依赖于它的系统的开发周期。
远离MongoDB
考虑到以上值,我们着手寻找MongoDB的替代者。上面提到的值通常是传统RDBMS的一组核心功能,因此我们着眼于两个候选对象:MySQL和PostgreSQL。
MySQL是第一个候选对象,因为我们已经在一些关键数据中使用它。但是MySQL并非没有问题。例如,在将字段定义为int(11)时,您可以轻松地插入文本数据,MySQL会尝试对其进行转换。一些例子:
mysql> create table example ( `number` int(11) not null ); Query OK, 0 rows affected (0.08 sec) mysql> insert into example (number) values (10); Query OK, 1 row affected (0.08 sec) mysql> insert into example (number) values ('wat'); Query OK, 1 row affected, 1 warning (0.10 sec) mysql> insert into example (number) values ('what is this 10 nonsense'); Query OK, 1 row affected, 1 warning (0.14 sec) mysql> insert into example (number) values ('10 a'); Query OK, 1 row affected, 1 warning (0.09 sec) mysql> select * from example; +--------+ | number | +--------+ | 10 | | 0 | | 0 | | 10 | +--------+ 4 rows in set (0.00 sec)
值得注意的是,在这种情况下,MySQL会发出警告。 但是,由于警告只是警告,因此常常(即使不是总是)将它们忽略。
MySQL的另一个问题是任何表修改(例如添加列)都会导致表被锁定以进行读取和写入。 这意味着使用此类表的任何操作都必须等待修改完成。 对于具有大量数据的表,这可能需要数小时才能完成,这可能导致应用程序停机。 这已导致SoundCloud等公司开发诸如lhm之类的工具来解决这一问题。
基于上述考虑,我们开始研究PostgreSQL。 PostgreSQL在很多方面做得很好,而MySQL则做不到。 例如,您不能将文本数据插入数字字段:
olery_development=# create table example ( number int not null ); CREATE TABLE olery_development=# insert into example (number) values (10); INSERT 0 1 olery_development=# insert into example (number) values ('wat'); ERROR: invalid input syntax for integer: "wat" LINE 1: insert into example (number) values ('wat'); ^ olery_development=# insert into example (number) values ('what is this 10 nonsense'); ERROR: invalid input syntax for integer: "what is this 10 nonsense" LINE 1: insert into example (number) values ('what is this 10 nonsen... ^ olery_development=# insert into example (number) values ('10 a'); ERROR: invalid input syntax for integer: "10 a" LINE 1: insert into example (number) values ('10 a');
PostgreSQL还具有以各种方式更改表的功能,而无需为每个操作锁定表。例如,添加一个没有默认值并且可以设置为NULL的列可以快速完成,而无需锁定整个表。
PostgreSQL中还有许多其他有趣的功能,例如:基于Trigram的索引和搜索,全文本搜索,对JSON查询的支持,对查询/存储键值对的支持,对发布/订阅的支持等等。
所有PostgreSQL中最重要的是在性能,可靠性,正确性和一致性之间取得平衡。
迁移到PostgreSQL
最后,我们决定与PostgreSQL达成和解,以便在我们关心的各个主题之间取得平衡。从MongoDB迁移整个平台到完全不同的数据库的过程并非易事。为了简化过渡过程,我们将这个过程大致分为3个步骤:
设置PostgreSQL数据库并迁移一小部分数据。
更新所有依赖MongoDB来使用PostgreSQL的应用程序,以及支持此功能所需的任何重构。
将生产数据迁移到新数据库并部署新平台。
迁移子集
在我们甚至考虑迁移所有数据之前,我们需要使用一小部分最终数据来运行测试。如果您知道即使是一小部分数据也会给您带来很多麻烦,那么迁移毫无意义。
虽然存在可以解决此问题的工具,但我们还必须转换一些数据(例如,重命名字段,更改类型等),因此必须为此编写自己的工具。这些工具大部分是一次性的Ruby脚本,每个脚本执行特定的任务,例如移交评论,清理编码,更正主键序列等。
最初的测试阶段并未发现任何可能阻碍迁移过程的问题,尽管我们的某些数据部分存在问题。例如,某些用户提交的内容并非总是正确地编码,因此,如果不先清除它们就无法导入。需要进行的另一个有趣的更改是将评论的语言名称从其全名(“荷兰语”,“英语”等)更改为语言代码,因为我们的新情感分析堆栈使用语言代码代替了全名。
更新应用
到目前为止,大部分时间都花在了更新应用程序上,尤其是那些严重依赖MongoDB聚合框架的应用程序。投入一些测试覆盖率较低的旧版Rails应用程序,您将有数周的工作时间。这些应用程序的更新过程基本上如下:
- 将MongoDB驱动程序/模型设置代码替换为PostgreSQL相关代码
- 运行测试
- 修复一些测试
- 再次运行测试,冲洗并重复直到所有测试通过
对于非Rails应用程序,我们决定使用Sequel,而我们在Rails应用程序中坚持使用ActiveRecord(至少现在是这样)。 Sequel是一个很棒的数据库工具包,它支持我们可能想使用的大多数(如果不是全部)PostgreSQL特定功能。与ActiveRecord相比,其查询构建DSL的功能也要强大得多,尽管有时可能会有些冗长。
例如,假设您要计算使用某个语言环境的用户数量以及每个语言环境的百分比(相对于整个集合)。在普通的SQL中,这样的查询如下所示:
#!sql SELECT locale, count(*) AS amount, (count(*) / sum(count(*)) OVER ()) * 100.0 AS percentage FROM users GROUP BY locale ORDER BY percentage DESC;
在我们的例子中,这将产生以下输出(使用PostgreSQL命令行界面时):
locale | amount | percentage --------+--------+-------------------------- en | 2779 | 85.193133047210300429000 nl | 386 | 11.833231146535867566000 it | 40 | 1.226241569589209074000 de | 25 | 0.766400980993255671000 ru | 17 | 0.521152667075413857000 | 7 | 0.214592274678111588000 fr | 4 | 0.122624156958920907000 ja | 1 | 0.030656039239730227000 ar-AE | 1 | 0.030656039239730227000 eng | 1 | 0.030656039239730227000 zh-CN | 1 | 0.030656039239730227000 (11 rows)
Sequel允许您使用纯Ruby编写上述查询,而无需字符串片段(这是ActiveRecord经常需要的):
#!ruby star = Sequel.lit('*') User.select(:locale) .select_append { count(star).as(:amount) } .select_append { ((count(star) / sum(count(star)).over) * 100.0).as(:percentage) } .group(:locale) .order(Sequel.desc(:percentage))
如果您不喜欢使用Sequel.lit('*'),也可以使用以下语法:
#!ruby User.select(:locale) .select_append { count(users.*).as(:amount) } .select_append { ((count(users.*) / sum(count(users.*)).over) * 100.0).as(:percentage) } .group(:locale) .order(Sequel.desc(:percentage))
虽然这两个查询可能都比较冗长,但它们更易于重用部分查询,而不必诉诸字符串连接。
将来,我们可能还会将Rails应用程序移至Sequel,但是考虑到Rails与ActiveRecord紧密相连,我们尚不确定是否值得花时间和精力。
迁移生产数据
最终,这使我们进入了迁移生产数据的过程。基本上有两种方法可以执行此操作:
- 关闭所有平台,并在所有数据迁移后使其重新联机。
- 在保持运行的同时迁移数据。
选项1有一个明显的缺点:停机时间。另一方面,方法2不需要停机,但是很难处理。例如,在此设置中,您在迁移数据时必须考虑添加的所有数据,否则会丢失数据。
幸运的是,Olery具有相当独特的设置,因为对数据库的大多数写入操作仅在相当固定的时间间隔内进行。确实更改频率更高的数据(例如用户和合同信息)是相当少量的数据,这意味着与我们的评论数据相比,迁移所需的时间要少得多。
这部分的基本流程是:
- 迁移关键数据,例如用户,合同,基本上是我们以任何方式无法承受的所有数据。
- 迁移不太重要的数据(我们可以重新刮擦,重新计算的数据等)。
- 测试是否一切正常并在一组单独的服务器上运行。
- 将生产环境切换到这些新服务器。
- 重新迁移步骤1的数据,确保在此期间创建的数据不会丢失。
第2步花费了迄今为止最长的时间,大约是24小时。另一方面,迁移步骤1和5中提到的数据仅花费了大约45分钟。
结论
自我们完成迁移以来已经快一个月了,到目前为止,我们感到非常满意。到目前为止,所产生的影响不过是积极的,在各种情况下甚至导致我们应用程序的性能大大提高。例如,由于迁移,我们的酒店评论数据API(在Sinatra上运行)最终获得了比以前更低的响应时间:
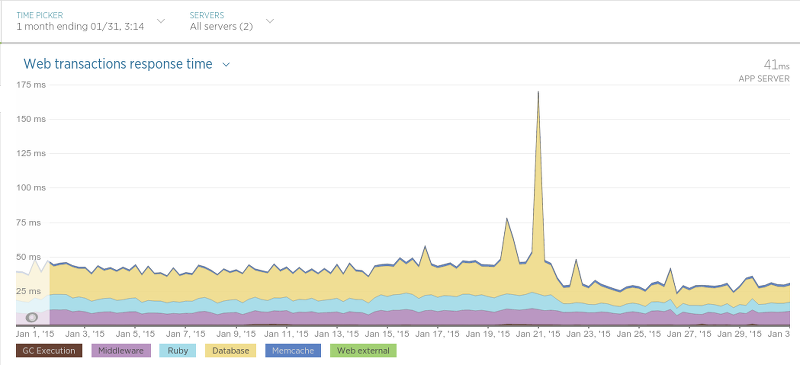
迁移是在1月21日进行的,最大的高峰只是应用程序执行了硬重启(导致该过程中的响应时间稍慢)。 21日之后,平均响应时间几乎缩短了一半。
我们看到性能大幅提高的另一种情况就是所谓的“审查持久性”。 这个应用程序(作为守护程序运行)的目的很简单:保存评论数据(评论,评论等级等)。 尽管我们最终对该应用程序进行了一些非常大的更改以进行迁移,但结果却非常有益:
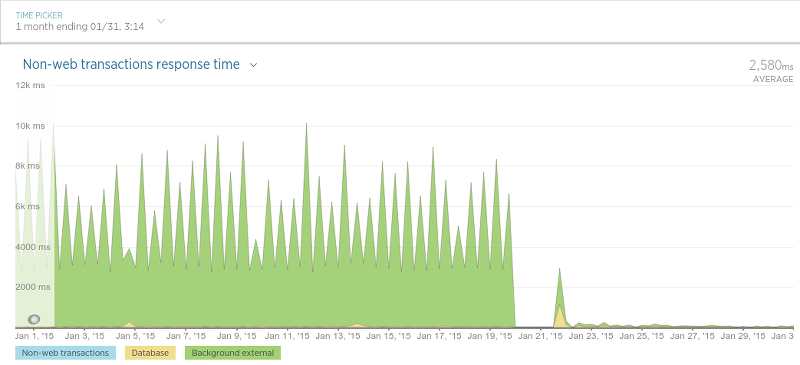
我们的刮板也最终更快了:
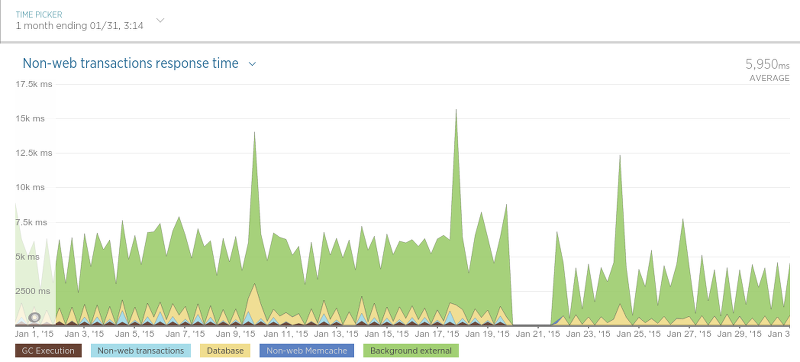
区别并不像复审持久性那么大,但是由于抓取工具仅使用数据库来检查是否存在复审(相对较快的操作),因此这并不奇怪。
最后是计划抓取过程的应用程序(简称为“调度程序”):
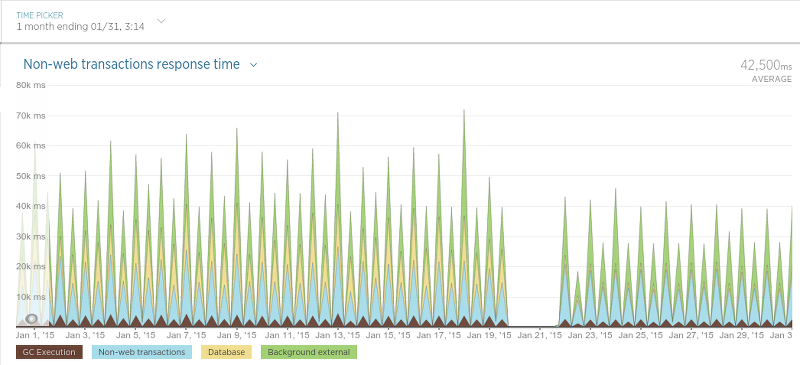
由于调度程序仅按特定的间隔运行,因此该图有些难以理解,但是迁移后的平均处理时间明显减少了。
最后,我们对到目前为止的结果非常满意,我们当然不会错过MongoDB。 性能非常好,与之相比,围绕它的工具使其他数据库显得苍白,与MongoDB相比(尤其是对于非开发人员而言),查询数据要轻松得多。 尽管确实有一个服务(Olery Feedback)仍在使用MongoDB(尽管是一个单独的相当小的集群),但我们打算将来也将其迁移到PostgreSQL。
原文:https://developer.olery.com/blog/goodbye-mongodb-hello-postgresql/
本文:http://jiagoushi.pro/goodbye-mongodb-hello-postgresql
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 150 次浏览
【数据库选型】卫报从MongoDB迁移到Amazon RDS上的PostgreSQL
《卫报》于2018年将其CMS的数据存储区从自我管理的MongoDB集群迁移到Amazon RDS上的PostgreSQL,以提供完全托管的解决方案。该团队进行了基于API的迁移,没有停机时间。
Guardian内部的CMS(称为Composer)用于存储文章,博客内容,照片库和视频,最初是在MongoDB上作为数据存储库构建的。在此之前是由Oracle数据库支持的供应商软件。每当必须迁移架构时,此设置都会停机。作为替代方案,该团队研究了各种NoSQL数据库,选择MongoDB的主要原因之一似乎是灵活性。他们最初托管在自己的数据中心,在中断后将MongoDB移至其AWS服务器。安装和管理脚本必须由Guardian的团队手写。他们选择了一份支持合同,并购买了OpsManager工具,该工具是用于管理MongoDB的前端应用程序。但是,由于不清楚的原因,该团队没有选择MongoDB的Atlas产品(这是一个“完全托管的数据库”)。 OpsManager不管理部署。
迁移到AWS后,该团队面临两次MongoDB中断。其中一些原因是基本的系统管理问题,例如不允许NTP访问时间服务器以保持时钟同步。根据文章,其他问题涉及管理OpsManager本身以及难以获得供应商及时支持的困难。团队认为,迁移到数据库管理最少的解决方案最适合他们。
由于PostgreSQL的成熟性和对jsonb数据类型的支持,该团队选择PostgreSQL作为Amazon RDS上的托管数据库。 jsonb类型允许对JSON对象中的字段进行索引。迁移计划是在Postgres上编写一个新的API,并使用一个代理将向两个API发送流量,以使它们保持同步以接收新的传入数据。现有数据将使用API进行迁移,然后代理将切换到新的API。他们以前从Oracle迁移的过程也使用类似的方法。迁移脚本日志已推送到Elasticsearch,以便可以跟踪迁移。在此过程中,他们还改善了结构化日志记录。
代理将所有流量实时定向到MongoDB API,并异步定向到Postgres API。记录并分析响应中的任何差异。为了确保新的API和后端可以容纳生产流量,运行了GoReplay流程以生成流量。 GoReplay可以捕获流量并针对不同的环境(在这种情况下为预生产环境)重播。在预生产环境中完成了完整的迁移。生产迁移的最后一步是将DNS名称从代理的端点(Amazon ELB)切换到Postgres API(另一个ELB)。这使他们的客户可以正常运行。迁移后,由于尚未将其迁移到新的API,因此它们的集成测试失败。
原文:https://www.infoq.com/news/2019/01/guardian-mongodb-postgresql/
本文:http://jiagoushi.pro/guardians-migration-mongodb-postgresql-amazon-rds
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 21 次浏览
【数据应用】什么是数据应用程序?
QQ群
视频号
微信
微信公众号
知识星球
在过去的几年里,现代数据堆栈(MDS)一直是人们谈论的话题。数据工具的爆炸式增长重新定义了业务数据的功能。尽管MDS仍处于早期开发阶段,但其拓扑结构越来越清晰。

整个顶层基本上可以定义为“数据应用程序”。它们简化了数据密集型操作,因此用户可以收集丰富的见解或使用数据执行操作。你可能也听说过它们被称为“分析应用程序”、“BI应用程序”或简称为“数据应用程序”。在这篇文章中,我们将向您介绍什么是数据应用程序,以及它如何从您的数据中释放更多价值。
虽然数据应用程序可以采取多种形式,如优步的司机跟踪服务或亚马逊的推荐引擎,但贯穿现代数据应用程序的共同主线是它们改变企业生产力的潜力。
数据应用程序通过将工作流程制度化或通过交互式可视化帮助用户理解数据中的复杂关系来提供价值。
为什么我们需要数据应用程序?
数据应用正在兴起。多年来,组织处理数据的方式发生了巨大变化。随着现代数据堆栈的成熟,我们正在超越老式的仪表板和报告。这些老派的仪表盘往往不足以进行分析,也缺乏必要的背景来做出有意义的见解。
我们正在从仪表板和报告转向实时、交互式的数据应用程序。这不仅有助于公司变得更加数据驱动,还减轻了BI和数据团队满足公司数据需求的负担。
应用程序通常是自助服务的,因此最终用户可以快速轻松地定位和分析特定数据,而无需BI或数据团队的深入参与。任何技能水平的用户都可以有效地与数据互动,以影响日常决策和长期战略。
商业智能仪表板与数据应用程序
从表面上看,数据应用程序和BI仪表盘似乎有很多相似之处。毕竟,BI仪表盘还可以从不同的数据集中提取数据,并用于分析目的。然而,数据应用程序可以为组织提供更大的功能和力量。
让我们来看看数据应用程序和BI仪表板之间的一些主要区别。
实时速度
BI仪表板往往显示更多的静态信息显示,因为它们通常不是为了优化速度和并发性而构建的。虽然它们足以分析长期运行的历史数据和显示指标,但在分析实时数据时,仪表板可能会变得迟钝。
数据应用程序的构建考虑到了实时数据。有了实时分析,企业主将能够跟上并领先于市场趋势。他们还能够快速满足甚至预测客户需求,以提高客户满意度和员工生产力。
采取行动
BI仪表板缺乏构建复杂用户交互的能力。虽然大多数仪表板可以深入查看信息或筛选数据,但执行更复杂的用户操作的选项并不多。这限制了仪表板用于分析目的。一旦发现,用户将不得不离开仪表板,根据自己的见解采取行动。
数据应用程序可以执行BI仪表板可以执行的任何操作,以及更多操作。数据应用程序提供了写回和与第三方系统的集成功能,增加了功能,并允许用户更直接地与数据交互。例如,如果我们正在查看一个广告管理应用程序,您不仅可以分析广告数据,还可以直接在该应用程序中暂停或更改活动预算。还可以运行模型并进行预测分析。这简化了从分析到行动的过程。
探索性与解释性
BI仪表板非常适合显示有助于决策的指标。然而,用户已经需要记住要报告的指标,以便仪表板发挥作用。因此,仪表盘主要用于探索目的。用户可以浏览所提供的数据,但几乎没有其他信息可以补充。
另一方面,数据应用程序具有探索性和解释性。数据应用程序专注于回答非常具体的问题,因此它们可以缩小范围以提供额外的价值。用户不仅可以探索自己的数据,还可以利用自己的见解交流发现并激励行动。
分发
BI仪表盘的用户在尝试扩展分布时可能会遇到障碍。他们的数据基础设施往往很难同时很好地支持许多用户,导致使用仪表板时速度减慢和受挫。许多工具还要求您拥有专有软件来查看仪表板,这使得在整个团队、部门或组织中共享这些工具变得困难且昂贵。
数据应用程序可以在不影响性能的情况下广泛分布,因此所有用户都可以从中获得最大价值。没有必要下载额外的软件,因为它们在浏览器中运行。任何拥有正确链接和适当权限的人都可以访问数据应用程序,而不会遇到性能问题。
意图
BI仪表盘主要用作数据可视化和分析工具。他们看起来完全相似。仪表板通常由图形、表格等组成,这些图形、表格有助于传达重要的业务指标和数据点。
由于数据应用程序在内容和交互方面更具可定制性,因此它们的用例也更为多样。
数据应用程序的用途是什么?
构建的数据应用程序类型将在很大程度上取决于公司的行业和运营流程。由于数据应用程序具有高度的可定制性和可扩展性,因此确定您企业的特定需求并构建一个针对您目标的应用程序非常重要。
话虽如此,以下是数据应用程序的几个常见用例
- 异常检测:异常检测对于检测安全漏洞或识别欺诈非常重要。数据应用程序可以提醒用户检查数据以应对事件或异常。然后,团队可以进去确定异常是否是潜在的威胁。这对于应用程序性能监控、预测分析和欺诈检测等用例特别有用。
- 实时推荐:数据应用程序可以结合历史数据和实时数据,向用户提供即时推荐。例如,电子商务商店可以跟踪客户之前的购买以及当前网站活动,以提供最相关的推荐。
- 实时供应链和物流:在管理供应链时,库存、订单、车辆、人员和设备的透明度很重要。保持在交付时间内是保持客户满意的关键。通过实时监控,物流供应商可以查看是否有因交通、天气等原因造成的突然延误,并做出调整。
- 警报和通知:可以构建数据应用程序,以便在触发事件时向用户发送警报或通知。例如,客户支持代表可以在提交新请求时收到警报,以便他们能够迅速采取行动解决问题。
- 工作流自动化:工作流自动化是用可以自动化流程的软件取代手动重复任务的流程。这有助于简化流程并提高生产力。数据应用程序可以帮助自动化众多应用程序的工作,以提高效率并最大限度地减少错误。
- 预测建模:数据应用程序可以使用机器学习和统计技术从数据中提取信息,以发现趋势并预测未来结果。这对于预测未来利润、瞄准潜在客户、防止制造业故障和确定人员需求尤其有用。
- 8 次浏览
【数据应用】什么是数据应用程序?
QQ群
视频号
微信
微信公众号
知识星球
开发人员构建数据驱动应用程序的解释指南
什么是数据应用程序?
数据应用程序分析大规模数据,以快速展现丰富的洞察力或采取自主行动。
数据应用程序有几个名称。一些人称之为“分析应用程序”。另一些人则使用“数据密集型应用程序”或“数据驱动的应用程序”这一术语。我们更喜欢数据应用程序——简短而中肯。
数据应用程序有多种形式。有些作为客户推荐引擎出现在网站上。其他是嵌入Salesforce和其他业务应用程序的丰富数据可视化。还有一些人在幕后运作,做出明智的自主决策,并及时提出见解。
现代数据应用程序的共同点是其颠覆性潜力,使公司能够创建新的商业模式,为其运营注入前所未有的自动化水平,并成为生产力的力量倍增器。如今,在线和社交商务、安全、车队管理、航运和物流以及许多其他行业都在通过数据应用进行转型。

An example of a data application that does real-time ETA predictions and dynamic pricing.
构建数据应用程序的难点
每一个应用程序都使用数据,但并不是每个应用程序都是数据应用程序。为了满足当今数字企业的要求,数据应用程序需要快速并大规模处理数据。构建数据应用程序有几个挑战,包括:
- 提供低延迟、复杂的分析:应用程序必须立即响应。传统的应用程序查询是简单的查找,可以由键值数据库快速处理。实现复杂分析的低延迟非常困难,尤其是在涉及大型聚合和联接的情况下。数据应用程序具有提供亚秒复杂分析的挑战性要求。
- 处理高速流数据:可用数据比以往任何时候都多,而且流媒体速度也越来越高。数据应用程序需要处理来自Apache Kafka或Amazon Kinesis等事件流媒体平台的流媒体数据,以及数据库更改数据捕获(CDC)流,并快速做出决策。对于需要对新数据立即采取行动的数据应用程序来说尤其如此。你通常会在物流、电子商务、航空等行业看到这些类型的应用程序。
- 支持对半结构化数据的分析:设备和应用程序数据本质上是半结构化的,并且越来越多地以JSON和Avro等现代数据格式存储。数据应用程序面临的挑战是能够查询大量的半结构化数据。虽然许多NoSQL系统被设计为接收半结构化数据,但大多数系统无法有效地查询该数据。
- 可靠地处理高并发性:数据应用程序正在成为许多平台的核心。例如,如果新闻推送不再快速加载你朋友的状态更新,你就不会使用Facebook。数据应用程序具有与传统应用程序相同的性能要求。它们必须能够处理高并发性、可用性和可扩展性。
- 无缝的用户体验:对于用户来说,数据应用程序必须是身临其境的,而不是与应用程序的其他部分格格不入。他们应该做出回应,及时提供建议,并能够与数据互动和搜索数据,并获得即时结果。建立这样的体验需要工程师和数据团队之间的紧密合作,而不是他们传统的孤立。
这些都是难以实现的要求。使它们特别具有挑战性的是,传统的数据系统,特别是OLTP数据库和数据仓库,并不是为这组需求而设计的。
数据应用程序与…的区别。。。
事务性应用程序
经典的数据库应用程序是事务性的。它不是分析数据,而是检索和存储数据,通常存储到关系数据库,如Oracle、MySQL或SQL Server。航空公司预订系统、健康记录和会计系统长期以来一直依赖于经典的数据库应用程序来存储和提供简单的数据,而不是洞察力——查找,而不是推荐。
相比之下,现代数据应用程序是分析性的,专注于在不编写或更新数据的情况下从数据中收集见解。它们使用户能够高水平浏览数据,将其与其他数据集结合进行探索,并进行深入搜索。数据应用程序还可以通过监控传入数据、发送警报以及在满足条件时触发操作来实现操作自动化。
商业智能
与数据应用程序一样,BI也是分析性的,利用不同的数据集来产生有用的见解。相似之处到此为止。BI(高管报告和分析师仪表盘)的输出往往是静态的或缓慢的,因为数据仓库的构建没有考虑到速度或并发性。此外,在大多数BI用例中,您看到的是长期运行的历史数据聚合。相比之下,数据应用程序正在分析实时数据,以影响即时决策和行动。
许多数据应用程序提供与个人用户、设备或机器相关的目标数据。例如,客户个性化包括将特定用户的历史见解与他们最新的网站互动联系起来。路线优化包括根据特定车辆和到达目的地的最佳方式设计路线。这需要精通搜索和分析查询,才能以高效计算的方式提供快速见解。
数据应用程序的优点是什么?
数据应用程序提供了丰富、快速的洞察力、自动化和集成,数据驱动的企业正利用这些功能来超越竞争对手。主要用例包括:
- 实时个性化和推荐:数据应用程序结合历史数据和新获取的数据,主动或在与客户互动期间提供即时见解和建议。例如,维生素公司Ritual分析客户购买情况和产品视图,以创建客户的“亲和力档案”。这使得Ritual可以在客户浏览其网站时发送有针对性的横幅广告,或者在结账时发送即时优惠券和捆绑优惠,这两者都推动了Ritual的销售额增长。

Ritual’s cart checkout experience featuring personalized upsell offers.
- 预测性维护:博世电动工具将其工厂中物联网传感器的数据流传输到实时数据库,该数据库可监控制造延迟和缺失零件并自动做出响应。它还可以监控和响应客户手中出现故障的产品发出的警报。使用数据应用程序,博世可以比员工更快、更可靠地做出反应,防止员工倦怠,并让他们腾出时间执行更高价值的任务。
- 欺诈和异常检测:数据应用程序可以提醒用户检查数据,以应对特定事件或异常。例如,安全应用程序可以监视潜在的漏洞和漏洞。如果发现了漏洞,安全团队会收到警报,开始对数据进行钻探,以确定是否发生了漏洞或是否是误报。数据应用程序的类似用例是在信用卡交易中搜索潜在的欺诈行为。
- 实时物流和车队管理:汽车共享、众包食品配送、航运公司和许多其他公司都受益于数据应用程序可以提供的自主功能。Command Alkon基于云的软件跟踪了北美80%以上的混凝土交付情况。混凝土运输对时间很敏感,因为如果出现延误,批次可能会硬化并被破坏。建筑公司使用Command Alkon来跟踪即将到来的混凝土交付,获得潜在延误的警报,并深入研究运输数据以确定延误的根本原因。

Command Alkon's CONNEX platform enables collaboration across the construction materials supply chain.
- 金融投资应用程序:数据应用程序可以成为数据探索的强大工具,使企业能够将历史数据源和实时数据源相结合,以生成新的战略和降低风险的大胆决策。例如,风险投资公司红杉资本(全面披露:Rockset的投资者)建立了一套内部数据应用程序,供其投资团队使用,以探索指导其投资初创公司决策的数据。此外,销售和营销团队可以分析CRM数据以提高销售转化率。
构建数据应用的技术
虽然数据应用程序有一系列具有挑战性的需求,但好消息是,一个生态系统正在出现,可以帮助开发人员构建这些类型的应用程序。您不再拘泥于应用程序的OLTP数据库。更好的消息是,这些组件中的许多也是“现代”的,这意味着它们是云原生的,易于使用,使所有工程团队都可以使用数据应用程序。以下是开发人员为这种新型应用程序所依赖的数据系统的一些组件:
- 实时数据流:随着包括Confluent Kafka和Amazon Kinesis在内的云活动平台的兴起,实时流数据比以往任何时候都更实惠、更容易访问。随着Debezium和亚马逊数据库迁移服务等工具利用数据库日志为下游系统和应用程序提供更新,变更数据捕获已成为越来越主流的工具。
- 实时分析数据库:出现了一类新的数据库,包括Rockset,它们在技术上进行了权衡,以更好地支持实时数据和低延迟分析。其中许多系统起源于网络规模的公司,这些公司需要大规模的分布式分析系统来支持越来越多的数据应用程序。例如,Rockset是由Facebook在线基础设施背后的团队创建的,该基础设施支持Facebook Newsfeed和反垃圾邮件算法等数据应用程序。实时分析数据库通常通过实时摄取和经济高效的数据汇总来支持高速流数据。他们通过汇集搜索引擎和数据仓库技术的最佳实践,提供低延迟分析。
- 数据API:API使将实时数据移交给实现数据应用程序的工程团队变得容易。我们看到越来越多的数据库技术创建数据API、SQL API或GraphQL API,以使切换顺利。这些API有助于确保没有注入错误,允许版本控制并引入标记功能。
- 缓存工具:当您拥有需要数万个并发查询的互联网规模的产品时,我们建议将缓存层与实时分析数据库结合使用。对于大多数用例,我们建议尝试只使用实时分析数据库,因为它比内存缓存系统更便宜、更不复杂。
- 可视化工具:许多数据应用程序都涉及为无缝用户体验而构建的自定义UI。其他使用Grafana或Apache Superset等工具的数据应用程序已成为数据可观察性或操作分析的主流。此外,还有像Vega这样的可视化库,可以轻松地在复杂数据上构建可视化。
结论
环顾四周,你会发现到处都是数据应用程序,为你最喜欢的购物网站供电,加快你的食品配送,并在库存短缺发生之前预测库存短缺。Facebook实时状态更新、优步司机跟踪和亚马逊推荐引擎等数据应用程序一直是数字化转型的核心。
传统上,这些应用程序的构建具有挑战性,因为它们具有苛刻的要求。事务系统已经能够提供快速的简单查询,但不能提供复杂的分析。数据仓库可以容纳数PB的数据,但您需要等待几秒钟到几分钟才能加载分析查询。
- 6 次浏览
【数据应用】什么是数据应用程序?从数据丰富走向信息丰富
QQ群
视频号
微信
微信公众号
知识星球
大数据已经占领了世界。曾几何时,TB是衡量世界数据量的有用指标。现在,这个数量已经扩展到PB甚至ζ字节,其中大部分存在于公司研究和交易系统之外。
事实上,在你阅读本文的几段时间内,超过50个小时的视频将被上传到YouTube,数百万次搜索将在搜索引擎上启动,数百万美元将通过电子商务进行交易。大数据的增长不仅限于科技公司。大量数据正在影响几乎所有行业。
众所周知,有许多大数据应用程序,如更个性化的营销或预测性库存订购,但大多数企业都无法以有用的方式组织大数据。
但大数据究竟是什么?这是一种生成的信息比当前数据管理系统所能处理的信息更多的现象。或者,换句话说,就是当你的公司数据丰富但信息匮乏的时候。
当数据被用来产生突破性见解,为明智的商业决策提供信息时,拥有大量的数据储备可能会改变游戏规则。然而,如果没有解释这些数据的工具,您将面临一个巨大的数据库,它正等待着被利用。
大数据的解决方案是一个新概念:数据应用程序。
数据应用程序究竟是什么?它们是如何工作的?
数据应用程序作为一个概念仍然相对较新。甚至还没有达成一致的定义。从技术上讲,所有应用程序都可以称为数据驱动应用程序,因为它们需要数据才能发挥作用。
然而,在商业智能和分析领域,数据应用程序的特点是图形用户界面(GUI),它向用户显示数据库中可用的资源。它允许像业务分析师这样的用户对数据库运行自定义查询,以帮助他们做出更明智的决策。
更简单地说,数据应用程序(不要与数据库应用程序混淆)是数据可视化和网络应用程序的混合体,因为它们允许最终用户(决策者、主题专家甚至消费者)可视化并有效地操作大型数据集。
旅游预订网站就是一个很好的例子。Orbitz和Kayak等网站处理大量数据,这些数据必须以互动的方式四处移动和可视化,这样消费者就很容易找到他们想要的航班并预订。
想象一下,如果你使用这些网站,只能查看航班信息,然后不得不打电话给旅行社为你预订航班。这将是一项更多的工作,而且不是很方便。
但是,这种情况与许多组织利用自己的大数据库存所做的类似。数据应用程序运动是关于从一个最终用户只查看和报告数据的环境过渡到一个任何人都可以轻松地将大数据可视化、交互和解释为日常工作的一部分的环境。
数据应用程序示例
以下是一些数据应用程序的示例:
- Orbitz:从技术上讲,Orbitz是一个包含元搜索引擎的旅游票价聚合网站。它的操作在基于Red Hat Linux和Solaris的混合平台上运行,并使用集群Java环境。Orbitz与世界各地的品牌合作,因此它必须能够准确地分发来自多个国家、公司和货币的信息,同时为全球的最终用户提供一致和稳定的体验。
- 示例:这家软件开发公司的使命是通过连接数据、工具和人员来推动创新,从而使富有成效和创造性的协作变得更加正常。客户包括医疗保健组织,它们正在使用数据管理应用程序来帮助查找公共卫生数据中的隐藏资源,避免冗余,并加快流行病学知识共享。
- Dataiku:这个一体化的数据集中化数据平台帮助企业聚合、可视化和与大数据交互。无论企业是将其用于大规模分析,还是利用企业级人工智能,Dataiku的自助服务平台都可以帮助企业操作机器学习,从而轻松发现有用的见解并采取行动。
传统基础架构如何阻碍数据应用程序增强业务能力
数据应用程序可以为各种业务提供巨大的好处。不幸的是,许多组织都受到数据移动性低的阻碍,而数据移动性低是由于遗留的IT基础设施(如数据仓库)碎片化造成的。
一个组织要想充分利用其数据应用程序的强大功能,就需要能够访问其所有数据。但是,由于传统IT基础架构中的数据往往由内部部门组织,每个部门都有自己的工作流程、行话和软件,因此收集的大部分数据不容易在整个组织中转换或传输。简言之,传统IT基础设施的孤立性导致整个组织的数据流动性较差。
孤立数据存储的后果包括:
- 管理分散数据生态系统复杂性的成本增加
- 部门数据之间存在不一致、冗余和总体缺乏同步
- 内部部署和云基础设施之间的数据移动性有限
如果您的企业打算有效利用大数据应用程序,您需要对IT基础设施进行现代化改造,并过渡到数据管理应用程序。
- 8 次浏览
【数据应用】用于分析的数据应用程序
QQ群
视频号
微信
微信公众号
知识星球
新一代工具弥补了技术用户和非技术用户之间的差距
2021年,“现代数据堆栈”成为全城的热门话题。正如Tristan Handy去年预测的那样,数据工具正在发生“寒武纪大爆炸”。随着公司和开源项目争相填补空白,见解的开发和交付方式正在重塑。在所有新来者中,有一件事越来越清楚:灵活性为王。仪表板和点击式BI工具在其不灵活的荣耀中,越来越不足以满足数据分析师和消费者的需求。
新一代构建数据应用程序的工具将取代它们,提供类似仪表板的易用性,在后端和前端都具有更大的灵活性。
现状怎么了?
2021年,随着数据堆栈的其余部分以惊人的速度成熟,老式的仪表板不再足以作为数据分析的标准输出。
对于数据分析师来说,它们往往不够,被迫将他们的工作融入一系列缺乏上下文的瓦片中。对于数据科学家来说,它们几乎总是不够的,无法轻松地将建模结果反馈到点击式仪表板工具中。即使对于专业的仪表板构建者来说,它们也可能不够,他们注定要永远尝试从一个充满方形瓷砖和不灵活过滤器的页面中“构思叙事”。
BI工具尽管功能强大,但也有严格的局限性。用户可以轻松读取数据,但用户友好的界面是一把双刃剑,阻碍了报告的灵活性和交互性。它们通常也仅限于基于SQL的分析,从而关闭了数据团队用其他语言完成的大量工作的大门。
仪表板的主要症结在于,通常情况下,它们对仪表板的消费者来说已经足够了——或者至少比可用的替代品更足够了。对于需要对数据采取行动的利益相关者来说,仪表板布局标准,非常易于使用,最重要的是,加载和读取无需任何技术开销。
这与Jupyter Notebook形成了鲜明对比,后者非常适合更复杂的数据分析,但实际上无法与非技术利益相关者共享。提供数据分析的无数其他聪明方法也是如此:你可以构建令人惊叹的东西,但它们没有用处,因为没有人能使用它们。每个人都可以点击一个链接打开一个简单的仪表板。
但每个人也可以使用Excel电子表格、谷歌文档、Powerpoint和PDF。BI工具仪表板作为丰富分析工具的不足并不能阻止这种分析的发生——它只是在大多数组织中创建了一个临时数据工作的“黑市”。亲爱的读者,看着你的网络摄像头,大声发誓你从未发送或接收过ModelOutput final(1).csv,从未从Jupyter笔记本上截取过屏幕截图复制到幻灯片中,也从未从BI工具下载过报告并在Excel中打开,这样你就可以调整它不允许你做的一件事。
我是这么想的。
这就是仅仅依赖仪表板作为数据世界的标准输出的真正问题。这不仅是因为它们本身不足以作为复杂数据分析的工具。这是因为它们的缺点引发了一个混乱的黑社会,其中包含了更糟糕的数据产品,这些产品往往是静态的和过时的。
数据应用程序
那么,还有什么更好的方法呢?事实上,它并没有那么具有开创性。等式中分析方面的每个人都希望有更多的灵活性,消费方面的每一个人都希望简单——尽管不能以牺牲交互性为代价。双方都同意这样一个事实,即未经批准的松散文件如龙卷风般飞来飞去,令人困惑。
“数据应用程序”是各种不同数据产品的总称,这些产品既可以进行丰富的分析,也可以进行简单的演示。数据应用程序可能看起来非常多样化——一个简单的点击式仪表板、一个带有实时图表的故事式文档、一个双按钮转换工具——但它们总是提供简单简洁的输出,掩盖了非常灵活的分析后端。与网站一样,数据应用程序可以独立存在,并且可以轻松地与广泛的受众共享。
Excel电子表格实际上是(初级)数据应用程序的一个很好的例子!技术先进的分析师可以获得丰富的灵活性和复杂性,但最终用户会看到一个极其简单但交互式的界面。也许Excel不是最前沿的例子,但它突出了可以被视为数据应用程序的各种可能性。
一些大型组织通过构建定制的数据应用程序,通过自己的工程团队创建的本土基础设施和框架,解决了这一问题。虽然这些一次性数据应用程序可以定制以满足任何需求,但开发和维护它们的开销非常高。这种方法对99%的团队来说是不值得的。
数据团队不需要访问一大群等待将笔记本电脑变成成熟的网络应用程序的网络开发人员。他们当然不需要自己学习React来将这种能力引入内部。数据团队只需要一个框架来进行分析并自己共享;最有效的解决方案是在数据应用程序工具空间,而不是在手工的一次性web应用程序中。
街区里的新生
这一领域出现了新一代工具,使数据团队能够为其组织的其他部门快速构建数据应用程序。除了允许分析师创建更灵活的数据接口外,这些工具还将分析和输出紧密结合在一起,而不会在多个工具之间产生碎片。这意味着数据从业者可以使用他们想要的任何语言和框架,而无需通过屏幕截图或导出来将他们的工作与现实分离。
Shiny多年来一直帮助R用户做到这一点,允许在不编写一行非R代码的情况下构建交互式应用程序。Streamlight和Dash让用户在不离开Python的情况下做同样的事情,Python已经成为数据世界中最流行的脚本语言。Hex采用了一种混合方法,让用户用Python和SQL进行分析,然后使用drag-n-drop应用程序生成器来构建数据应用程序。
所有这些工具旨在弥合技术数据从业者和技术含量较低的数据消费者之间的共享差距,而无需任何一方做出牺牲。这就是数据应用程序的前景——丰富的分析、易于共享和消耗的输出、低开销。
数据(应用程序)驱动的未来
数据从业者应该继续使用他们熟悉的任何语言和框架,而不必在与利益相关者共享结果时求助于一次性导出、孤立的屏幕截图或不灵活的BI工具。
数据消费者应该能够方便地访问操作上有用的交互式数据产品。他们永远不需要在一个输入发生更改的情况下向数据团队请求新的csv转储。他们也不应该通过同样疲惫的报纸仪表板布局来消费每一份报告!
标准仪表板值得一试!几十年来,我们一直在努力满足每个人对一份好的数据报告的期望。他们可以休息一下,重新开始做他们擅长的基本顶级BI报告(呵呵)。他们当然赢得了这一点。
松散的csv文件和陈旧的幻灯片组值得……不管发生什么。对糟糕的数据毫不留情。
随着现代数据堆栈的不断扩展,数据团队在进行和共享分析方面将比以往任何时候都有更多的选择。数据应用程序和构建它们的工具的兴起将使数据分析保持协作性、交互式,最重要的是:实际上是有用的。
- 5 次浏览
【数据应用程序】Alteryx:什么是数据应用程序?
QQ群
视频号
微信
微信公众号
知识星球
数据应用程序是建立在数据库之上的应用程序,可以解决利基数据问题,并通过可视化界面允许同时进行多个查询,以探索数据并与之交互。数据应用程序不需要编码知识来获取或理解手头的数据,这使得它们非常适合业务用户或消费者。
例如,您可以为您的出租车公司构建一个数据应用程序,该应用程序可以可视化来自出租车车队的所有传入数据,以便实时监控收入。或者,以Zillow或Trulia等房地产公司为例,它们在大量住房市场数据的基础上构建了用户友好的应用程序,供潜在买家搜索和比较。
数据应用程序就像是数据可视化和web应用程序之间的交叉。与数据可视化类似,数据以视觉上吸引人的方式呈现,便于消费和交互。然而,就像网络应用程序一样,随着新数据为应用程序提供动力,这些数据也在不断变化和更新;目标不是一次分析,而是随着时间的推移不断进行数据监控或使用。
数据应用程序的好处是什么?
为消费者开发可盈利的数据应用程序的好处是显而易见的——但内部数据应用程序呢?既然有这么多现成的软件选项,为什么要为您的组织构建自定义数据应用程序?
- 首先,数据应用程序不必完全从头开始构建。市场上的各种平台允许组织构建个性化的数据应用程序,同时控制服务器基础设施和安全等后端流程。
让我们来看看组织选择构建自己的数据应用程序的其他一些原因:
可以根据具体的使用情况进行定制。
每个商业模式和后续的数据用例都是独一无二的,不可能总是硬塞进现成的软件中。构建您自己的数据应用程序提供了更大的灵活性和自定义功能,以最好地满足您的业务需求。
节省成本。
构建自己的数据应用程序并不便宜——通常,组织会投资数据工程和开发资源来构建和管理应用程序。然而,软件也可能会带来巨额账单,而且随着时间的推移,从长远来看,成本会更高。最后,随着越来越多的可访问数据应用程序工具,越来越多的商业用户开始参与数据应用程序的开发过程。
更高效的可视化。
一些组织可能会考虑完全放弃数据应用程序,只需依靠业务用户手动将数据拉入电子表格,然后利用可视化工具创建仪表板。对于一次性分析项目来说,这是一个很好的策略,但如果业务用户每天都在寻找相同的更新,那就没有意义了——这根本不够快。使用数据应用程序,您的所有数据都可以通过易于理解的可视化立即访问。
为最了解数据的人提供更多的控制。
数据开发人员或数据架构师的技术专业知识与业务用户可能拥有的特定领域专业知识之间存在很大差异。当然,您的数据开发人员知道如何使用数据,但她可能不知道数据如何应用于业务。数据应用程序降低了技术壁垒,允许业务用户实时利用其领域专业知识制定更有效的战略。
组织正在构建哪些类型的数据应用程序?
让我们仔细了解构建数据应用程序的业务战略,以了解组织如何应用数据来推动其数据应用程序,以及这些数据应用程序如何支持特定的收入目标。以下是现代数据应用程序的三个示例。
制造缺陷检测的数据应用
想象一下,你是一家大批量汽车零部件制造公司的经理。每小时,你的公司都会生产数百个发动机零件——平衡轴、气缸盖等。由于产量高,你必须准确了解系统缺陷发生的时间,以免它开始成倍增加,导致数百甚至数千个无法使用的产品。
由工厂数据提供动力的数据应用程序能够快速提醒您生产线可能出现的任何缺陷。如果你发现一些奇怪的东西,你可以立即停止生产,以便进一步检查产品。然而,如果分析师必须经常手动争论和可视化数据,那么这种速度将更加困难。
用于定价优化的数据应用程序
随着定价成为差异化的核心杠杆,组织需要能够比以往更快地响应市场变化,这意味着根据上下文(如本地化或特殊场合)优化一系列决策(如标价或促销),以实现多个业务目标(如净收入增长或交叉销售)。
用于数据聚合的数据应用程序
为大型组织提供咨询具有挑战性,原因有很多,但数据是最重要的。了解数据是如何收集的,在哪里找到数据,以及如何提取数据,可以决定顾问的发现——而且,根据数据的规模,他们会耗费大量时间。
德勤建立了一个名为Cortex的数据应用程序,该应用程序可以从整个组织的各个地方提取数据,以便进行整合、标准化,并为分析使用做好准备。该应用程序已成为德勤的与众不同之处,并作为其全球分析平台的关键部分进行营销。
构建数据应用程序的技巧是什么?
数据应用程序是围绕特定类型的数据设计的。但在将这些数据输入数据应用程序之前,必须首先将其摄入并存储在数据平台中,数据平台是所有数据应用程序的基础。
“数据平台”是指允许对数据进行管理、访问并向用户交付的技术、其他技术,当然还有数据应用程序。当大多数人想到数据平台时,他们想到的是排名前三的数据提供商,亚马逊网络服务(AWS)、微软Azure和谷歌云平台(GCP),尽管Snowflake和Databricks等也是突出的参与者。
正确的数据应用程序意味着建立一个强大的数据平台基础。以下是一些确保您的数据应用程序设置成功的提示。
了解您正在处理的数据
记录数据源,包括将用于收集数据的所有应用程序。制定计划,以最有效的方式收集数据而不存在数据损坏风险,并设置标准的数据质量参数。最后,确定您每天要处理的数据量,以及数据量可能更改的频率。
选择合适的平台
也许这是最明显的提示,但如果你的组织从头开始,这一点很重要。选择一个能够支持您的数据应用程序的独特需求的数据平台,以及一个您有信心在部署和管理数据应用程序时成为强大合作伙伴的数据平台。
保持灵活性
你的申请有一个目标;您了解为了达到该目标而要使用的数据类型。然而,保持灵活性很重要。请记住,你可能会发现超出你想象的见解。大数据平台的优势在于,它整合了您的所有数据,与传统数据仓库相比,可以进行更多的探索。
利用数据挖掘
数据挖掘是分析数据的过程,以便建立与数据应用程序所需数据的模式和关系。使用数据挖掘技术,您将能够更好地了解在哪里获取新数据以及在哪里投资资源。
投资于数据准备
数据准备是数据平台中最重要的组成部分之一。数据应用程序的成功取决于它所使用的数据的质量,这意味着数据准备中涉及的所有步骤——清理、标准化、丰富、验证等等——都必须正确完成。正如一句古老的格言所说,“垃圾输入;垃圾输出;”如果低质量的数据被用于数据应用程序,那么它的洞察力也会很差。
迭代、测量和重复
数据应用程序不是一个“设置并忘记”的过程。相反,您应该不断评估是否正在收集正确的数据,是否有新的来源可以添加,或者是否有不相关的数据可以删除。您的业务会发生变化,数据应用程序的需求也会发生变化。确保您的数据应用程序始终是最新的。沿着每一步,衡量你的结果。这可以通过多种不同的方式来实现,例如收集的数据量,但这取决于数据应用程序的目标。
如何为我的数据应用程序做好数据准备?
因为数据准备对于数据应用程序来说是非常重要的一步,所以让我们更深入地了解如何正确地进行数据准备。
首先,让我们谈谈传统上如何大规模地进行数据准备。小型IT团队通常使用手工编码或ETL(提取、转换和加载)工具和流程来维护整个组织的数据质量,从接收到向业务交付需求。然而,今天,正如数据应用程序提高了数据可访问性一样,组织也希望在数据准备过程中投入更多资源。
进入现代数据准备平台。现代数据准备平台为业务用户提供了访问和准备数据的手段,同时仍允许IT监督。首先,这是一种更有效的方法——与其由一个小的工作组来解决数据质量问题,不如让更多的人关注数据——但它也能更好地管理最终分析。IT仍然会策划最好的东西,确保它被批准并重复使用(这确保了真相的单一版本并提高了效率)。但是,在清理和数据准备的最后步骤中,有了业务背景和所有权,这些用户最终可以决定什么是可接受的,什么需要改进,以及何时进行分析。
这种方法为数据应用程序带来了巨大的好处。数据应用程序以更快、更一致的方式为业务利益相关者理解数据。但是,想象一下,如果那些拥有最佳数据背景的人不仅能够相对于数据应用程序快速解释数据,而且能够为这些应用程序策划和准备正确的数据?这些数据应用程序将更有针对性、更健壮,并最终更有效。
面向数据应用的Designer云数据准备平台
Alteryx Designer Cloud被广泛认为是数据准备领域的行业领导者,也是许多数据应用程序的基础数据准备平台。事实上,我们的客户包括上面例子中提到的德勤和TopLineLab。
Designer Cloud的机器学习平台在数据准备过程中充当了一只看不见的手,引导用户实现尽可能好的转换。它的可视化界面自动显示错误、异常值和丢失的数据,并允许用户快速编辑或重做任何转换。最后,它可以与任何数据应用程序集成,并可以从组织内的任何地方提取数据。
了解为什么组织现在将Designer Cloud作为其数据应用程序战略的关键部分。安排我们团队的免费演示,或在您选择的平台上立即开始使用Designer Cloud。
- 6 次浏览
【数据建模】Salesforce数据模型符号
QQ群
视频号
微信
微信公众号
知识星球
介绍
本文档概述了Salesforce实体关系图(ERD)表示法和约定,以帮助您清楚地解释
architecture gallery at architect.salesforce.com.
ERD,也称为数据模型,是信息系统的图形表示。它展示了这个系统中人、物、地、概念和事件之间的关系。它是一个逻辑模型,用于传达数据的功能结构。在Salesforce ERD中,实体通常映射到Salesforce数据库中的对象。
修改后的信息工程符号
Salesforce ERD使用信息工程(IE)表示法的修改形式。信息工程符号是由澳大利亚的克莱夫·芬克尔斯坦和英国的CACI共同发明的,后来由詹姆斯·马丁改编。IE存在不同版本,没有单一的标准,但IE受到许多数据建模工具的支持,是数据库设计中最流行的符号之一。
(Source: Information Modeling and Relational Databases , 2008 by Terry Halpin and Tony Morgan.)
, 2008 by Terry Halpin and Tony Morgan.)
实体
实体是一种重要的事物或对象,无论是真实的还是概念上的,都需要了解或掌握有关信息。

实体在图中表示为带圆角的方框。每个实体框通常提供两个标签(如适用):
- 实体的逻辑名称(例如,此处示例中的“Salesforce实体”)。这可能对应于所表示的Salesforce对象的单数标签,但并不总是如此。
- Salesforce组织中对象的“物理”API名称或开发人员名称(例如示例中的“API名称”)。对于托管包对象,图中列出的API名称通常不包括托管包命名空间(例如“vlocity_ins**”),除非Salesforce或Industry云使用多个托管包。托管包对象的API名称结尾表示使用的自定义对象的类型:“**c”表示常规自定义对象和自定义设置,“**mdt”表示自定义元数据,“**x”表示外部对象。
实体框还可以列出代表该实体的属性的一个或多个属性。属性前面有一个“#”或一个“-”字符。
- “#”表示一个属性,该属性是实体的逻辑唯一键的一部分。在示例图中,“用户密钥属性”被视为实体的用户主键。
- “•”表示非关键属性。
实体格式
每个实体关系图从指定云(如销售云、服务云或营销云)的角度说明Salesforce数据模型。图表的配色方案反映了焦点中的云。金融服务云、健康云和媒体云等所有行业云都使用相同的行业配色方案。
图表上给定实体的颜色也有特定的含义。焦点云的颜色是用Salesforce品牌的颜色表示的,包括下面的一些例子。
以下部分将参考下面的Sales Cloud示例图例来查看不同的实体格式:

云实体
具有焦点云颜色的实体表示该云的许可证附带的对象。
关联实体
具有白色填充和黑色边框的实体表示具有与焦点云不同的许可证并且未由焦点云许可证扩展的对象。例如,销售或服务云ERD上显示的帐户和联系人实体将显示为带黑色边框的白色,因为这些对象具有平台许可证。
扩展相关实体
具有浅灰色填充和黑色边界的实体表示与焦点云具有不同许可证的对象,但焦点云扩展了该对象。例如,Commerce Cloud使用附加字段扩展了基本Product2对象。扩展包括其他字段、关系和记录类型。
外部实体
没有边界的实体是虚拟的。当在图中使用时,这些框确认域的逻辑模型中存在实体,但该实体在Salesforce中未实现为物理对象。此实体的数据预计将通过部署的解决方案中的外部API调用或Salesforce Connect访问。
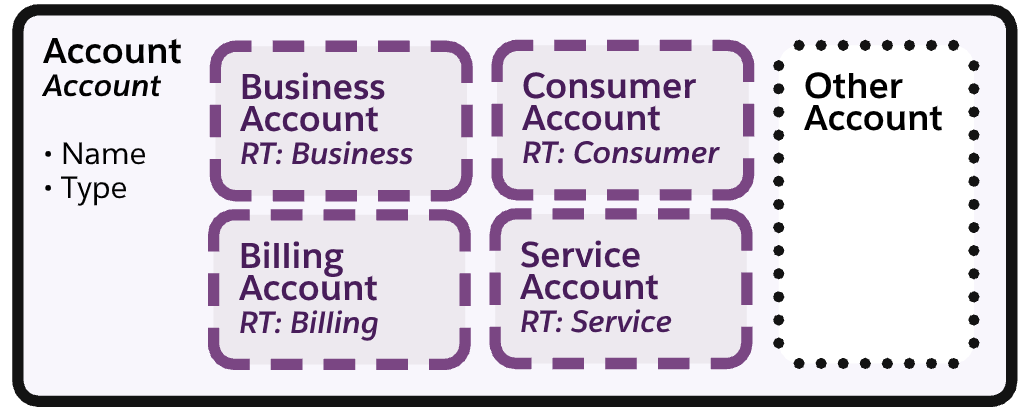
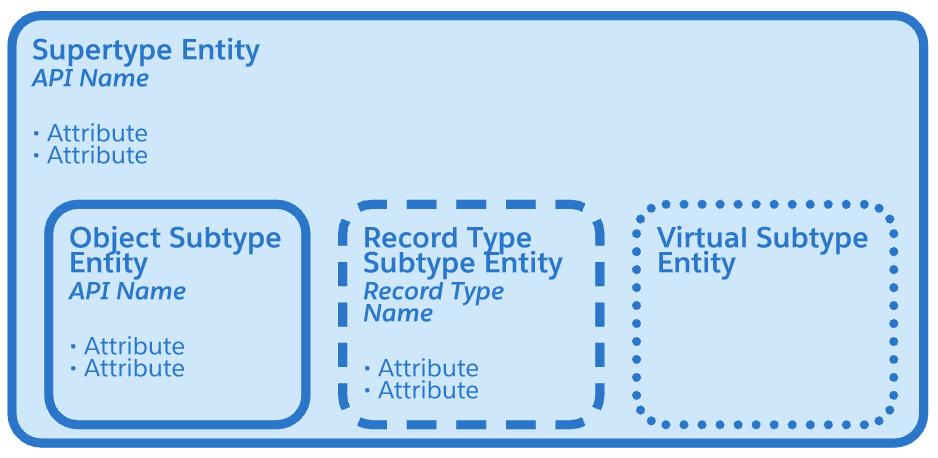
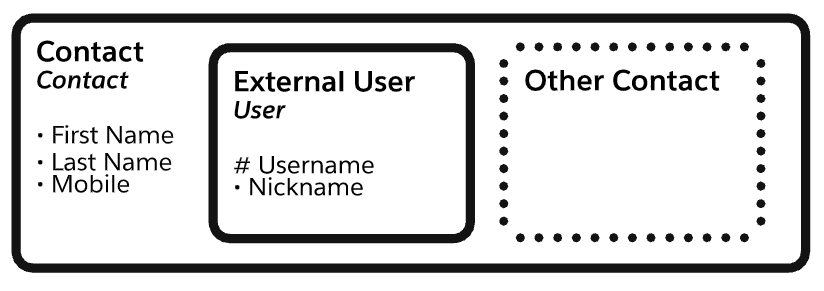
记录类型实体
带有虚线边框的实体在Salesforce中被建模为记录类型。在此处显示的示例中,“业务帐户”、“计费帐户”、消费者帐户和“服务帐户”子类型有一个虚线边框,因为它们映射到使用通信云管理包交付的记录类型。
概念实体
带有虚线边框的实体是虚拟的。在Salesforce解决方案中,既不使用记录类型也不使用单独的对象来区分这些子类型。这些子类型从逻辑上描述了域中的一个概念,该概念有助于说明数据模型的功能。
超类型和子类型实体
实体的子类型是其引用的子集的定义。当在超类型实体中添加一组子类型时,超类型实体描述公共属性和关系,而子类型实体显示特定于该子类型的属性和关系。在图表表示法中,子类型是互斥的,这意味着任何单个记录都必须是单个子类型。
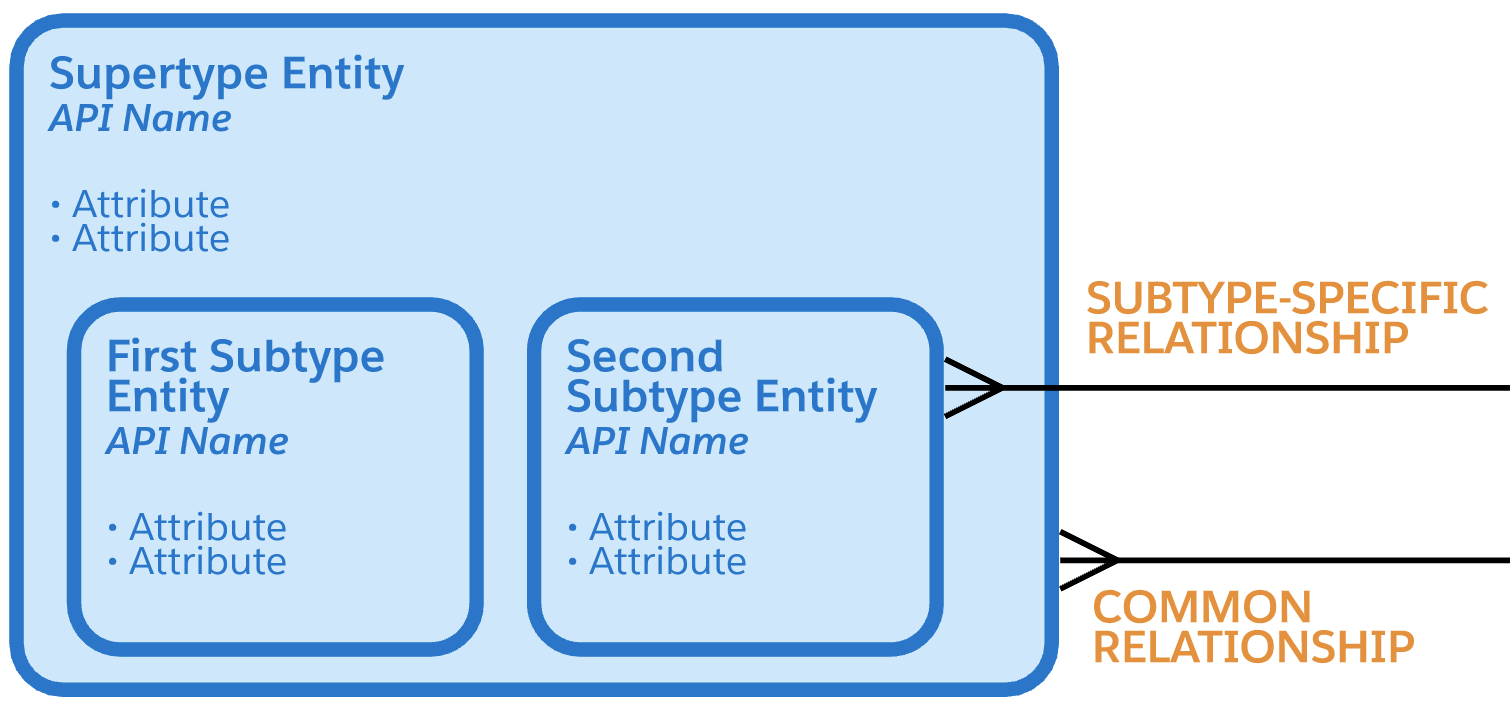
子类型可以具有嵌套的子类型,以进一步区分出现的情况。图表中的子类型是合乎逻辑的,但它们可以通过以下三种方式之一映射到物理表示。子类型实体边界的坚固性定义了如何在Salesforce数据模型中实现子类型。
具有实体边界的子类型实体具有一个实际对象,用于跟踪该子类型的出现。在此处显示的示例中,“联系人”的“外部用户”子类型有一个实心边界,因为注册为“外部用户的联系人”将使用“用户”对象中的记录进行跟踪。
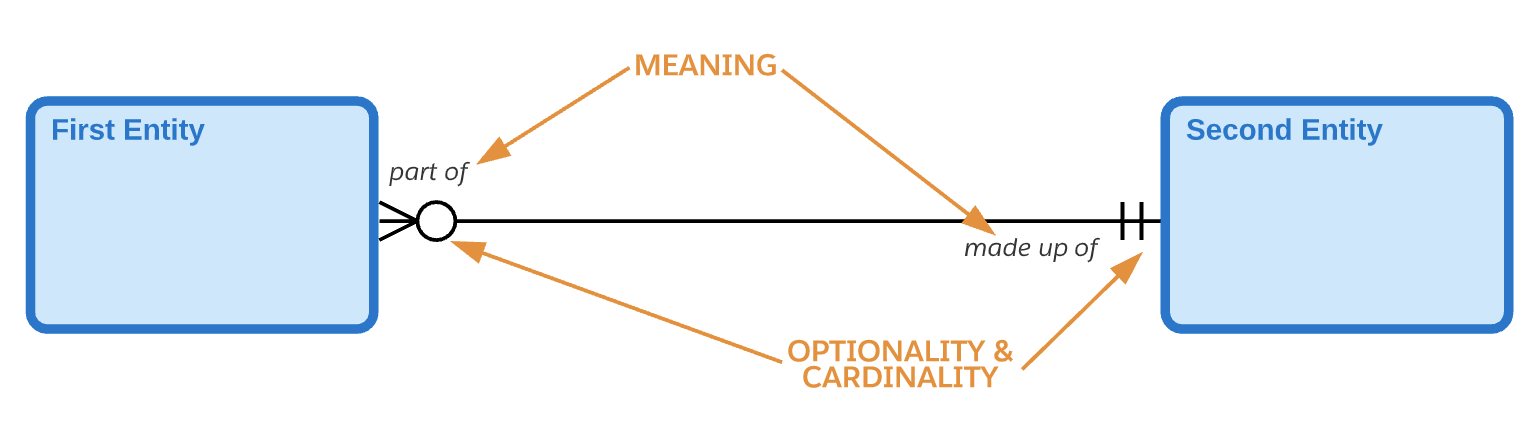
关系
关系是两个实体之间的一种命名的、重要的关联。

线条上或周围的标记和文本描述了关系的基数、可选性和含义。
关系基数
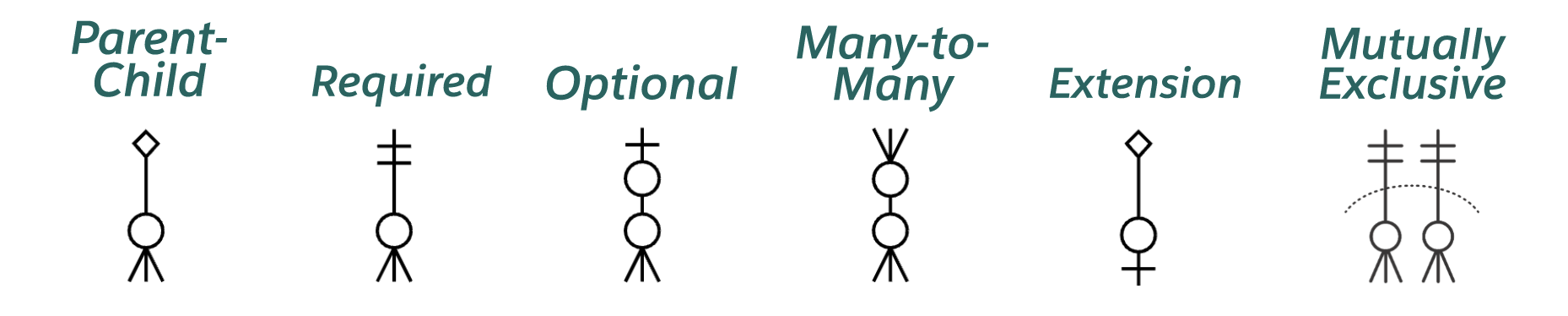
基数表示关系每一侧出现的相对次数。在表示法中,关系线的两端表示该端关系的基数。一端的鱼尾纹表示该端的许多实体出现可以与另一端的每个出现相关。一端没有鱼尾纹表明,该端最多有一个实体发生可以与另一端的给定发生相关。
亲子关系
Salesforce支持两种relationship fields:
查找字段和父子(也称为主细节)字段。父子字段类似于必需的查找,但它们在相关实体之间应用了额外的耦合。当父记录被删除时,关系的许多方面的记录被级联删除。此外,明细记录的可见性由父记录的可见性控制。
为了说明父子关系和查找关系之间的区别,Salesforce ERD借用了UML中的菱形表示法。关系中唯一一方的钻石意味着该方的实体在关系中发挥着主导作用。在这种关系的许多方面的实体是细节或子实体,并且可以被认为包含在父实体中。
关系选择性
可选性表示每端发生的事件是否需要关系。作为一个概念,可选性与基数密切相关,符号反映了这种紧密性。可选性在关系的每一端通过关系另一端直线上的圆圈或条形来表示。为什么在关系的另一端?将可选性标记包括在与基数相同的线上。
在关系的许多方面(也就是鱼尾纹),线上几乎总是有一个圆圈。这意味着对于关系的奇异侧上的每次出现,在关系的多个侧上可以有零到多个出现。
在关系的单数侧,圆圈和条形表示关系鱼尾纹侧实体的可选关系。圆和条形表示,对于多个边上的每一次出现,在关系的奇异边上可以出现零次或一次。
或者,在关系的单数侧,双杠表示关系的多方实体所需的关系。双杠意味着在关系的单数侧,对于多个侧的每一次出现,都必须有一次并且只有一次出现。
即使Salesforce中的基本物理关系是可选的,关系的可选性也可以根据需要显示。例如,Contact上的AccountId字段在物理上是可选关系,但如果忽略Private Contacts,则逻辑上需要Contact与Account的直接关系。期权性指标使用较少。在大多数情况下,ERD中显示的期权性反映了关系的潜在期权性。
关系含义
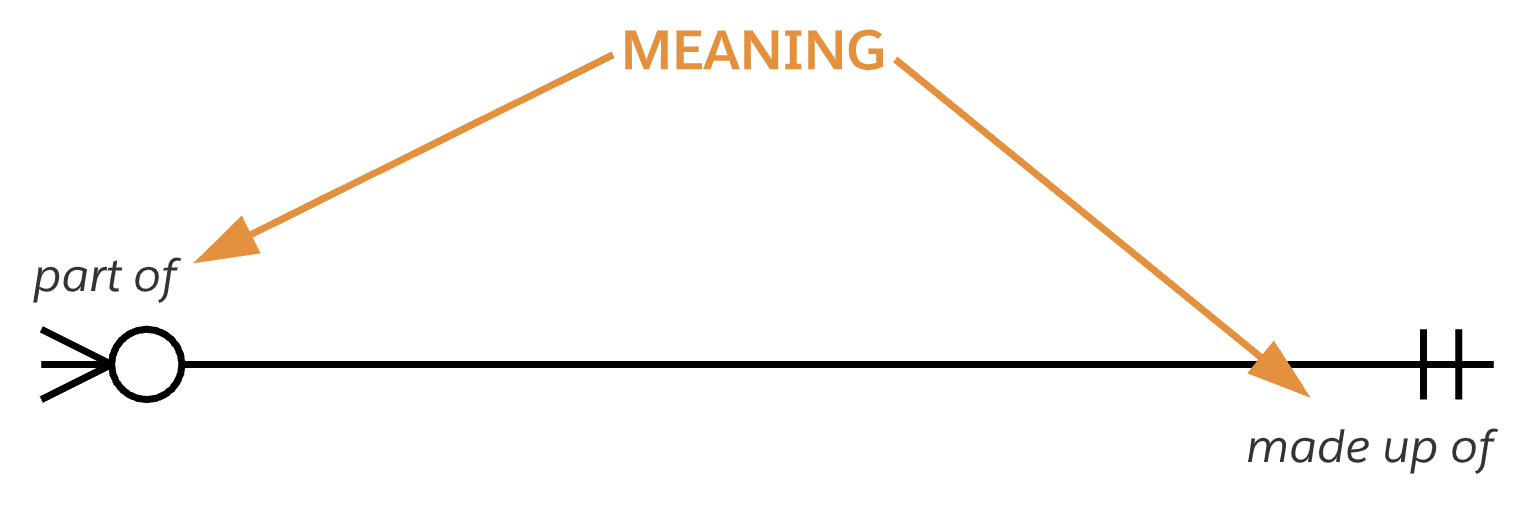
除了基数和可选性之外,两个实体之间的每一种关系都表达了某种意义,将这种关系与同两个实体间的其他关系区分开来。关系端名称,如上图中的“part of”和“composed of”,定义了关系的性质。
当你将关系的基数、可选性和结束名组合在一起时,它们可以用来组成一个描述关系的句子。
从左到右:每个(可能/必须)都是<end name 1>(一个且只有一个/一个或多个)。
从右到左:每个(可能/必须)都是<end name 2>(一个且只有一个/一个或多个)。
例如
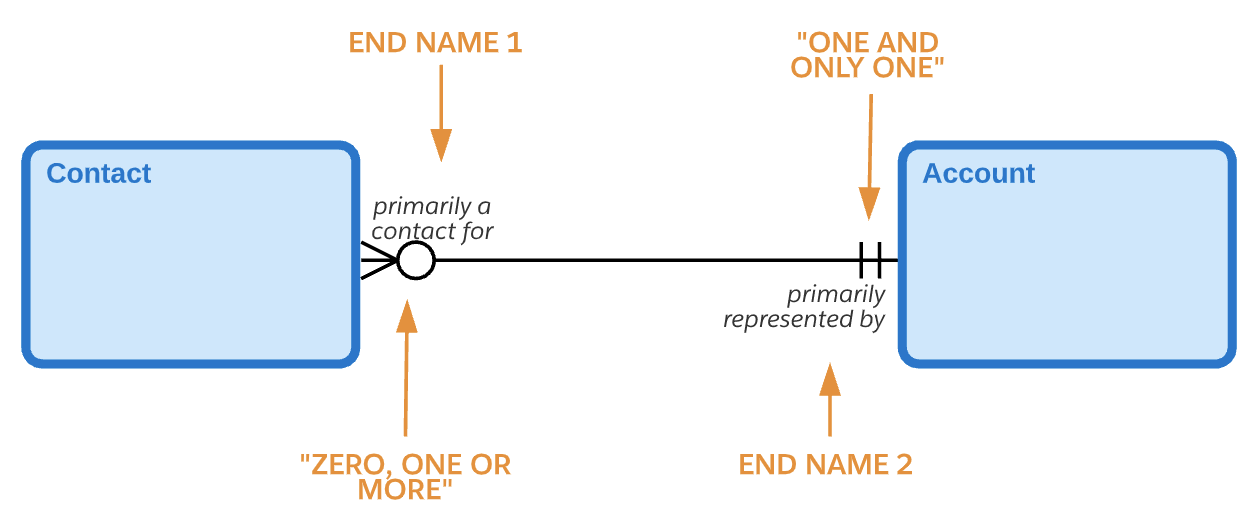
从左到右:“每个联系人必须主要是一个且只有一个帐户的联系人。”从右到左:“每个帐户可能主要由一个或多个联系人代表。”
关系颜色编码
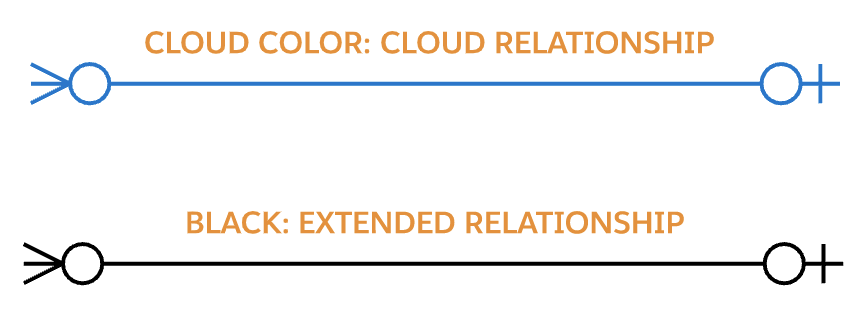
关系线是用颜色编码的。由图的焦点云中添加的关系以颜色绘制。黑线表示与焦点云不同的许可证所附带的关系。
递归关系
关系可以是同一实体的两个实例之间的关系。这被称为递归关系。曲线关系线用于表示递归关系。
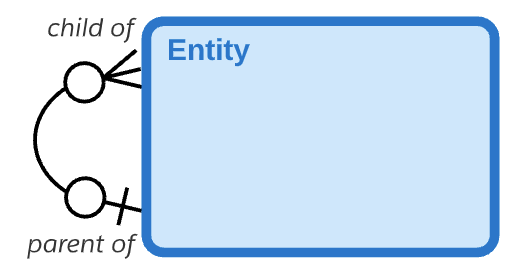
互斥关系
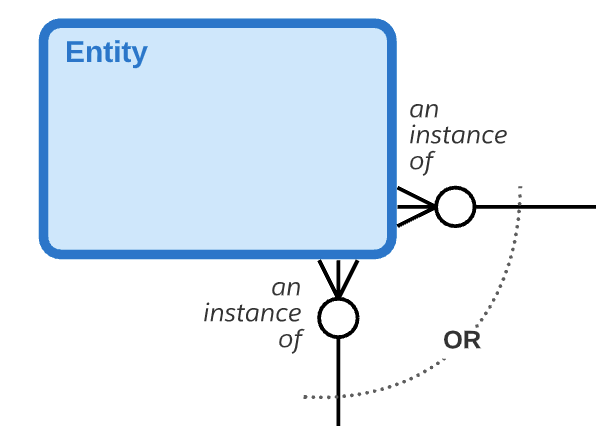
Salesforce ERD通常会排除大多数业务规则,以便专注于数据模型的结构,但互斥关系是一种对结构有信息的业务规则,因此值得注意。互斥关系表示弧中包含的几个关系中只有一个关系将用于任何给定的事件。请注意,两个、三个或更多的关系可以参与同一个互斥关系。描述此处显示的互斥关系的一句话可以是:“每个实体可能是一个且仅一个第一其他实体或一个且仅有一个第二其他实体的实例。”
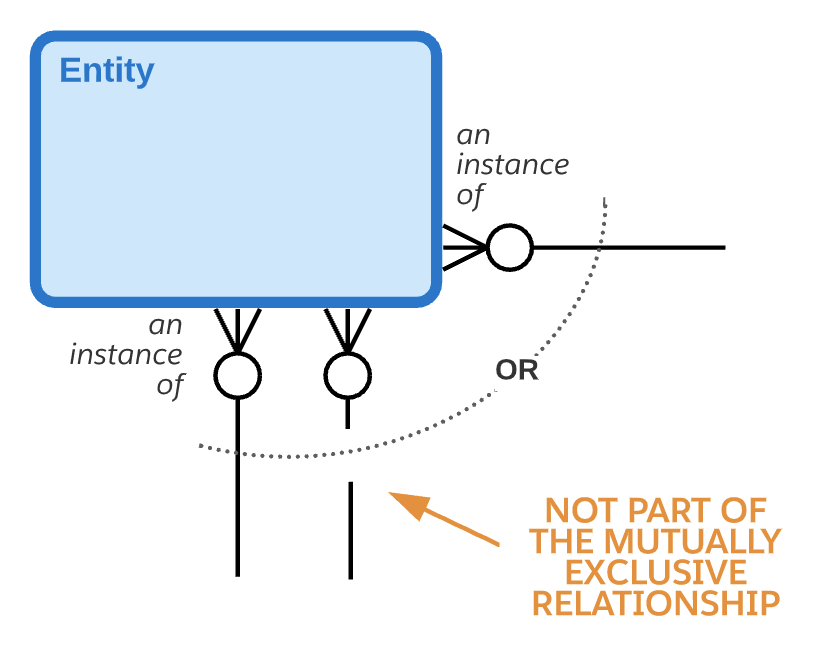
请注意,在Salesforce ERD中,穿过圆弧的断开关系线不是互斥关系的一部分。
布局惯例
Salesforce官方产品ERD遵循布局约定以提高可读性。这些布局约定包括以下内容:
- 关系线应该始终是直的。
- 关系线应垂直或水平绘制。在极少数情况下,如果无法做到这一点,请使用对角线上的直线。
- 为了使关系线保持直线,可以调整实体框的大小(更高或更宽),为两个实体之间的关系提供一个平台。更重要的实体(有更多的关系)在图中显示得更大,从而增强了它们的重要性。
- 在整个ERD中,关系上的鱼尾纹应始终位于关系线的左侧和/或上侧(倒置布局),或始终位于关系线上的右侧和/或下侧(右侧向上布局)。这种约定提供了清晰性,因为它导致类似的实体聚集在图的同一区域,这有助于理解这些实体。使用倒置布局确实会导致图表出现倒置,子实体位于父实体的上方或左侧——然而,这确保了图表中最具体的实体位于图表的左上角,从而使图表易于识别。使用右侧向上布局约定会导致相同的公共实体位于每个图的左上角,但子实体将位于父实体的下方或右侧。
严格遵守这些布局惯例可以得到一个清晰易读的图表。
Be sure to check back regularly on the template gallery at architect.salesforce.com for the latest Salesforce product data models that follow this standard.
Learn More
- 21 次浏览
【数据建模】主题域建模
QQ群
视频号
微信
微信公众号
知识星球
企业数据模型(EDM)的初始级别,它提供了按主题领域组织EDM的结构。
主题领域模型与概念模型( Conceptual Model )和概念实体模型(Conceptual Entity Model)一起构成了企业数据模型(EMD)的完整结构。主题领域建模是企业数据模型的初始级别。
主题区域模型是一种元数据类型,它由许多事实表组成,然后被引用。通常,即使是一个更大的团队,也很难在不将企业数据分解为更易于管理的块的情况下设计、开发和组织企业数据;这里的基本思想是“分而治之”。
主题领域建模使用业务主题领域( business subject areas)而不是通过数据系统或应用程序来塑造EDM。这种类型的建模允许业务用户更容易地访问相关内容,然后他们可以在这些内容上构建自己的见解。
主题领域是指在组织的特定功能领域内,代表一组相关概念的数据的高级组织。
在一般意义上,假设主题区域为房屋中的一个房间。例如,餐厅包含用餐物品(餐桌、餐椅、餐具储藏室、银器、场所设置、装饰等)。类似地,在技术意义上,特定应用上下文的表在逻辑上被分组以形成主题区域。
主题领域的示例包括账户、账单、资源、流程和财务。更深入地说,当主题区域“Accounts”导入到应用程序中时,它下面的所有表也会被导入。
考虑到账户主题区域,它可以包含其下的账户相关表(应付账款或应收账款)。
- 5 次浏览
【数据架构】4项数据架构原则将加速您的数据战略
QQ群
视频号
微信
微信公众号
知识星球
您的数据架构只有与其基本原理一样好。如果没有正确的意图、标准和通用语言,就很难启动您的战略。
因此,在您使用客户数据来推动分析操作之前,先退一步考虑一下您是否奠定了正确的基础。最终,遵循正确的数据架构原则将有助于加强您的数据战略,并使您能够开发加速价值实现和提高数据质量的管道。
强大的数据架构的重要性
正确的数据架构是数据战略成功的核心。它由管理和定义您正在收集的数据类型的所有策略、规则和标准组成,包括:
- 您如何使用数据
- 数据存储位置
- 您如何管理数据并将其集成到整个业务中
完善这一过程是任何成功的数据策略的关键。因此,如果未能实现数据架构最佳实践,往往会导致错位问题,例如业务和技术团队之间缺乏凝聚力。
但是,您的业务如何确保您的数据架构战略跟上现代业务需求?
您需要了解的四个最佳数据架构原则
为了获得对数据的完全控制,您需要以清晰和可访问的方式构建数据架构。要做到这一点,您需要遵循最佳数据架构原则。
根据定义,数据架构原则与围绕数据收集、使用、管理和集成的一组规则有关。最终,这些原则使您的数据架构保持一致、干净和负责任,并有助于改进组织的整体数据战略。
以下是四种数据架构最佳实践,供您遵循。
1.在进入点验证所有数据
你知道吗,糟糕的数据质量会直接影响88%的公司的利润?为了避免常见的数据错误并提高整体运行状况,您需要设计您的架构以尽快标记和更正问题。
然而,当您有大型数据集、复杂的手动过程和很少的支持时,发现错误是很困难的。幸运的是,投资一个数据集成平台,在进入时自动验证您的数据,可以防止未来的损坏,并阻止坏数据在整个系统中扩散。
此外,使用自动化工具过滤异常将有助于最大限度地减少清理和准备所需的时间。由于每天收集的数据如此之多,因此只保留有价值的信息至关重要,从而创建可持续的数据验证和纠错循环。
2.努力保持一致性
为数据架构使用通用词汇表将有助于减少混乱和数据集分歧,使开发人员和非开发人员更容易在同一项目上进行协作。这为您的团队提供了“真相的单一版本”,并允许您创建正确定义实体关系的数据模型,并将其转换为可执行代码。
一致性是关键,因为它可以确保每个人都使用相同的核心定义。例如,无论应用程序或业务功能如何,都应该始终使用相同的列名来输入客户数据。偏离这个通用词汇表的那一刻,就是失去对数据架构和数据治理的控制。
3.记录所有内容
定期的“数据发现”将使您的组织能够检查其正在收集的数据量、哪些数据集已对齐以及哪些应用程序需要更新。为了实现这一点,您需要每个业务功能都具有透明度,以便对数据使用情况进行全面概述。
但是,要获得完全的可见性,您首先需要养成记录数据过程每一部分的习惯。这意味着在整个组织中标准化您的数据。正如我们已经确定的那样,你需要努力在你所做的每件事上保持一致,如果你的公司没有人花时间把事情写下来,这是不可能的。
此文档应与您的数据集成过程无缝配合。一家关联管理系统提供商仅使用Excel电子表格和数据集成平台开发了他们的数据架构,将工作流程从文档加载到生产,并自动定期更新到他们的分析仓库。他们所需要做的就是维护Excel文档。
4.避免重复功能
当您在多个应用程序、函数或系统上工作时,很容易在它们之间复制数据。但从长远来看,这会显著增加开发人员更新重复数据集的时间,并阻止他们在其他更关键的领域增加价值。
相反,您需要投资于一种有效的数据集成架构,该架构可以自动将数据保存在一个通用的存储库和格式中。这不仅使普遍更新数据变得更加简单,还防止了组织筒仓的形成,这些筒仓通常包含冲突甚至过时的数据。现在,每个人都可以从单一版本的真相中进行操作,而无需更新和验证每一条信息。
成功来自于坚持自己的原则
根据Gartner的数据,85%的大数据项目未能启动。但是,为了避免成为这种不必要的统计数据的一部分,您需要遵循正确的数据架构原则,并将其构建到您的战略和文化的核心。
从在进入点验证数据到共享关键实体的通用词汇表,确保您遵守这些原则将加速您的数据战略,并为您提供更快、更高效地满足现代客户需求所需的平台。
- 8 次浏览
【数据架构】Aaron Fuller:即时设计
即时设计是以小增量设计工作软件的实践,支持业务定义的需求或故事。 JIT设计以及JIT测试是敏捷软件方法的一个组成部分。事实上,如果没有及时设计,你就无法真正做到敏捷。
为了帮助我们了解JIT设计的细微差别,我们邀请了Aaron Fuller,他是一位长期数据架构师。在为期11年的保险公司企业数据架构师职业生涯中,他为数据建模,为各种系统创建技术设计,建立治理和管理,并领导建立企业数据仓库,商业智能和企业建筑项目。自2010年起担任高级数据战略的首席顾问和所有者,他领导一支技术精湛的数据专家团队,他们能够独特地规划和执行敏捷数据项目。
关键要点:
- 要想成功实现敏捷,您应该及时设计。
- 敏捷就是从消费者而不是生产者那里看待事物。
- 在包含许多表,报告和可视化的版本中,并不总是提供值。小部件也带来很多价值。
- 修饰您已经触摸过的系统的相同组件并不是一个坏主意。它有助于进一步改善它们。
- JIT设计方法自然会将您推向即时要求,这有助于您与敏捷规划团队保持同步。
- 一个大的设计可能会阻碍敏捷的流动。
- 需要建立数据治理,以便人们可以在业务方面进行协作。
- 企业数据既需要增量战术投资(敏捷),也需要战略投资(数据战略,数据架构等)。
- 您越早开始提供功能,您的战略和架构工作就会越充分。
- 你不需要等待重构,你可以重构为sprint的一部分。
- 在sprint团队之间签订工作协议是一个很好的做法,他们可以决定如何分配资源。
- 当一个团队能够发展出一种独特的文化时,它就会激发组织所追求的“它”因素。
Wayne Eckerson:作为一个团队和团队中的个人,您是否将敏捷过程定义为灵活流程的一部分?
亚伦富勒:是的,绝对的。 将敏捷团队聚集在一起以进行尽可能多的迭代也很重要。 您可以从团队中获得更多价值,并且他们可以更好地进行即时设计。 在不同的环境中,您可能有动态堆叠情况,许多承包商或者其他一些团队设置,但通常情况下,自组织团队通常会在一起出现一段时间。 当一个团队能够发展出一种独特的文化时,它就会激发组织所追求的“它”因素。 它与一支能够一遍又一遍地凝聚并重复成功的团队有关。
- 59 次浏览
【数据架构】Data Model vs Data Dictionary vs Database Schema vs ERD

所有这些数据库设计术语都可能令人困惑。在这篇短文中,我将试着解释它们是什么以及它们之间的区别。
数据模型
组织数据元素及其关系的抽象模型。它与任何实现都没有关系。数据模型可以用多种形式表示,如实体关系图或UML类图。
数据字典
是每个数据元素的引用和说明。它是数据模型的详细定义和文档(进一步了解数据字典)。它可以有两个抽象层次:物理和逻辑。
数据库模式
数据库模式是特定数据库管理系统中数据模型的物理实现。它包括所有实现细节,如数据类型、约束、外键或主键。
实体关系图
ER图是关系数据库中数据模型/模式的图形表示。它是一个建模和数据库文档工具。
比较
舞台(Stage)
- 数据模型:概念系统建模
- 数据库模式:系统实现
- 数据字典(逻辑):详细的系统设计,文档
- 数据字典(物理):系统实现,文档
- 概念系统建模,文档
目的
- 数据模型:数据设计
- 数据库模式:数据库实现
- 数据字典(逻辑):定义数据模型中的每个数据属性-数据模型补充
- 数据字典(物理):数据库模式中每个数据属性的设计和文档
- 关系数据库中的通信数据模型
详细程度
- 数据模型:中下键对象/实体和属性
- 数据库模式:高-定义的每个数据和关系详细信息
- 数据字典(逻辑):高-定义的每个键表和数据属性
- 数据字典(物理):非常高-定义的每个表和列
- 低或中键实体和属性
作者
- 数据模型:数据/系统架构师、业务分析师
- 数据库模式:数据/系统架构师、dba
- 数据字典(逻辑):数据/系统架构师、业务分析师
- 数据字典(物理):数据/系统架构师、DBA
- ERD:数据架构师、DBA
用户
- 数据模型:业务分析师、业务用户、数据/系统架构师
- 数据库模式:开发人员、dba
- 数据字典(逻辑):业务分析师、业务用户、数据/系统架构师
- 数据字典(物理):数据/系统架构师、DBA、开发人员、测试人员、系统管理员
- ERD:业务分析师、业务用户、数据/系统架构师、DBA、开发人员
工具
- 数据模型:案例,图表工具
- 数据库模式:数据库开发和管理工具
- 数据字典(逻辑):Word/Excel
- 数据字典(物理):Word/Excel、扩展属性/注释、数据字典工具
- ERD:案例,图解工具
形式
- 数据模型:图形化UML类图
- 数据库模式:数据库管理系统中的结构:表、列、外键等。
- 数据字典(逻辑):元数据表
- 数据字典(物理):元数据表
- ERD:图表
原文:https://dataedo.com/blog/data-model-data-dictionary-database-schema-erd
本文:
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 104 次浏览
【数据架构】JSON Schema 逐步入门
- 介绍
- 启动纲要
- 定义属性
- 深入了解物业
- 嵌套数据结构
- 纲要之外的引用
- 查看我们定义的JSON模式的数据
介绍
下面的例子并不是JSON模式所能提供的所有值的最终结果。为此,您需要深入了解规范本身–请访问http://json-schema.org/specification.html。
假设我们正在与基于JSON的产品目录交互。此目录中的产品具有:
标识符:productId
产品名称:productName
消费者的销售成本:price
一组可选的标记:tags。
例如:
{
"productId": 1,
"productName": "A green door",
"price": 12.50,
"tags": [ "home", "green" ]
}
虽然通常很简单,但是这个例子留下了一些开放的问题。以下是其中的一些:
- 什么是productId?
- 是否需要productName?
- 价格能为零吗?
- 所有的标签都是字符串值吗?
当你谈论一种数据格式时,你想知道什么是键的元数据,包括那些键的有效输入。JSON模式是一个被提议的IETF标准,如何回答这些数据问题。
启动模型(Schema)
要开始一个模式定义,让我们从一个基本的JSON模式开始。
我们从四个名为keywords的属性开始,这些属性表示为JSON键。
对。该标准使用JSON数据文档来描述数据文档,大多数情况下这些文档也是JSON数据文档,但可以是任何数量的其他内容类型,如text/xml。
- $schema关键字指出,该模式是根据标准的特定草案编写的,并用于各种原因,主要是版本控制。
- $id关键字定义纲要的URI,以及解析纲要中其他URI引用的基URI。
- title和description注释关键字仅具有描述性。它们不会向正在验证的数据添加约束。模式的意图用这两个关键字来表述。
- type validation关键字定义了JSON数据的第一个约束,在本例中它必须是JSON对象。
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product in the catalog",
"type": "object"
}
在启动模式时,我们引入以下术语:
- Schema关键字:$Schema和$id。
- 纲要注释:标题和描述。
- 验证关键字:类型。
定义属性
productId是唯一标识产品的数值。因为这是产品的规范标识符,所以没有标识符的产品是没有意义的,所以它是必需的。
在JSON模式中,我们添加了以下内容:
properties验证关键字。- productId 键。
- 说明模式description和type验证关键字已经注意到了–我们在上一节中讨论了这两个问题。
- 列出productId
required的验证关键字。
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
}
},
"required": [ "productId" ]
}
- productName是描述产品的字符串值。因为没有名字的产品没什么大不了的,所以它也是必需的。
- 由于
required的验证关键字是一个字符串数组,因此我们可以根据需要记录多个键;我们现在包括productName。 - productId和productName之间并没有什么区别,我们把两者都包括进来是为了完整性,因为计算机通常关注标识符,而人类通常关注名称。
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
},
"productName": {
"description": "Name of the product",
"type": "string"
}
},
"required": [ "productId", "productName" ]
}
深入了解properties
据店主说,没有免费的产品。;)
- price键添加了前面介绍的常用描述模式注释和类型验证关键字。它也包含在由所需验证关键字定义的键数组中。
- 我们使用exclusiveMinimum验证关键字指定price的值必须不是零。
- 如果我们想包含零作为有效价格,我们会指定
minimum验证关键字。
- 如果我们想包含零作为有效价格,我们会指定
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
},
"productName": {
"description": "Name of the product",
"type": "string"
},
"price": {
"description": "The price of the product",
"type": "number",
"exclusiveMinimum": 0
}
},
"required": [ "productId", "productName", "price" ]
}
接下来,我们来看看标签键。
店主这样说:
如果有标记,则必须至少有一个标记,所有标签必须是唯一的;在一个产品中不能重复。所有标记必须为文本。标签很好,但不需要出现。
因此:
tags键添加了常用的注释和关键字。这次的类型验证关键字是array。我们引入items validation关键字,以便定义数组中显示的内容。在本例中:通过类型验证关键字的字符串值。minItems validation关键字用于确保数组中至少有一个项。uniqueItems validation关键字说明数组中的所有项都必须彼此唯一。我们没有将此键添加到required的验证关键字数组中,因为它是可选的。
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
},
"productName": {
"description": "Name of the product",
"type": "string"
},
"price": {
"description": "The price of the product",
"type": "number",
"exclusiveMinimum": 0
},
"tags": {
"description": "Tags for the product",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
}
},
"required": [ "productId", "productName", "price" ]
}
嵌套数据结构
到目前为止,我们一直在处理一个非常扁平的模式——只有一个级别。本节演示嵌套数据结构。
dimensions键是使用我们之前发现的概念添加的。因为type validation关键字是object,所以我们可以使用properties validation关键字来定义嵌套的数据结构。为了简洁起见,我们省略了description注释关键字。虽然在这种情况下,最好是对结构和键名进行彻底的注释,但大多数开发人员都非常熟悉它。
您将注意到所需验证关键字的范围适用于维度键,而不是超出范围。
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
},
"productName": {
"description": "Name of the product",
"type": "string"
},
"price": {
"description": "The price of the product",
"type": "number",
"exclusiveMinimum": 0
},
"tags": {
"description": "Tags for the product",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
},
"dimensions": {
"type": "object",
"properties": {
"length": {
"type": "number"
},
"width": {
"type": "number"
},
"height": {
"type": "number"
}
},
"required": [ "length", "width", "height" ]
}
},
"required": [ "productId", "productName", "price" ]
}
纲要之外的引用
到目前为止,我们的JSON模式是完全自包含的。为了重用、可读性和可维护性等原因,在许多数据结构中共享JSON模式是非常常见的。
在本例中,我们引入了一个新的JSON模式资源,并针对其中的两个属性:
我们使用前面提到的最小验证关键字。我们添加了maximum validation关键字。综合起来,这给了我们一个在验证中使用的范围。
{
"$id": "https://example.com/geographical-location.schema.json",
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Longitude and Latitude",
"description": "A geographical coordinate on a planet (most commonly Earth).",
"required": [ "latitude", "longitude" ],
"type": "object",
"properties": {
"latitude": {
"type": "number",
"minimum": -90,
"maximum": 90
},
"longitude": {
"type": "number",
"minimum": -180,
"maximum": 180
}
}
}
接下来,我们添加对这个新模式的引用,以便可以合并它。
{
"$schema": "http://json-schema.org/draft-07/schema#",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
},
"productName": {
"description": "Name of the product",
"type": "string"
},
"price": {
"description": "The price of the product",
"type": "number",
"exclusiveMinimum": 0
},
"tags": {
"description": "Tags for the product",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
},
"dimensions": {
"type": "object",
"properties": {
"length": {
"type": "number"
},
"width": {
"type": "number"
},
"height": {
"type": "number"
}
},
"required": [ "length", "width", "height" ]
},
"warehouseLocation": {
"description": "Coordinates of the warehouse where the product is located.",
"$ref": "https://example.com/geographical-location.schema.json"
}
},
"required": [ "productId", "productName", "price" ]
}
查看我们定义的JSON模式的数据
从最早的示例数据(滚动到顶部)以来,我们肯定已经扩展了产品的概念。让我们看看与我们定义的JSON模式匹配的数据。
{
"productId": 1,
"productName": "An ice sculpture",
"price": 12.50,
"tags": [ "cold", "ice" ],
"dimensions": {
"length": 7.0,
"width": 12.0,
"height": 9.5
},
"warehouseLocation": {
"latitude": -78.75,
"longitude": 20.4
}
}
原文:https://json-schema.org/learn/getting-started-step-by-step.html
本文:http://jiagoushi.pro/node/1096
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 87 次浏览
【数据架构】MIKE2.0方法:一种企业信息管理的开源方法
MIKE2.0方法 : 一种信息开发的开源方法
MIKE2.0是什么?
- MIKE代表集成知识环境的方法
- MIKE2 0是我们的综合方法MIKE2.0是我们企业信息管理的综合方法
- MIKE2.0集合了围绕开源和Web 2.0的重要概念
- MIKE2.0的开源版本可以在http://www.openmethodologology.org找到
MIKE2.0中的关键结构
- SAFE(联邦企业的战略架构)是MIKE2.0方法的未来框架的架构框架
- 信息开发是MIKE2.0的关键概念结构——像开发应用程序一样开发信息
MIKE2.0提供全面的现代方法
- 范围涵盖企业信息管理,但详细介绍了用于更多战术项目的领域
- 从战略概念层面开始的架构驱动方法开始, 进一步到解决方案架构
- 覆盖数据治理,架构和战略信息管理的全面的方法
MIKE2.0提供了一种用于信息开发的协作开源方法
- 通过易于浏览和理解的方法平衡添加新内容和稳定发布
- 允许非其他用户贡献
- 独特的方法,我们希望在信息开发的新领域成为这个“标准”
MIKE2.0方法:阶段概述,MIKE2.0的5个阶段
- 第一阶段: 业务评估
- 第二阶段:技术评估
- 第三阶段:第一个迭代 :
路线图和基础活动->设计->开发->部署->运营
- 第四阶段:第一个迭代 :
路线图和基础活动->设计->开发->部署->运营
- 第五阶段:第一个迭代 :
路线图和基础活动->设计->开发->部署->运营
MIKE2.0方法:EDM策略的活动和典型时间框架
MIKE2.0方法论:任务概述,任务1.4.3评估信息成熟度
MIKE2.0方法论:任务概述,任务1.4.3评估信息成熟度
以下显示的是信息成熟度(IM)QuickScan的示例输出。 IM QuickScan用作评估企业级组织中数据治理级别的第一步。
MIKE2.0方法论:任务概述,任务1.5.10高级解决方案体系结构选项
MIKE2.0方法论:任务概述,任务1.5.10高级解决方案体系架构选项
下面显示的是高级解决方案体系结构选项的示例输出,这些选项将用于此任务。通常,会有一些带有支持文本的体系结构模型。
这个提议的解决方案包括三个可行的选择:
使用供应商模型作为集成操作数据存储的基本逻辑数据模型,通过map- gap练习来完成模型。这个模型与已经在组织范围内采用的现有数据分类/分类模型紧密一致.
开发和构建混合数据模型,该模型由组织内部现有系统中使用的现有数据模型组成。这些基本模型需要与企业应用程序中当前使用的其他模型进行补充和集成.
基于现有的 已经在组织范围内被采用,并且有一套明确的用户需求的数据分类/分类模型,为其内部开发和构建逻辑的、规范化的数据模型.
定义高级解决方案体系结构只是整个体系结构方法的一部分
- 如果需要对当前状态和远景进行初步评估,则修改总体体系结构模型
- 指导原则的定义
- 创建战略概念体系结构
- 定义高级解决方案体系结构选项
- 收集集成和信息的战略需求
- 逻辑体系结构的定义,以理解产品需要什么功能
- 将逻辑架构映射到物理架构以选择供应商
- 收集详细的业务需求
- 解决方案体系结构定义/修订
- 技术和实现体系结构
战略性业务和技术体系结构活动只执行一次,对于每个交付增量都执行更详细的活动.
任务概述:任务概述,任务2.2.2定义基础设施的基础功能
下面是来自QuickScan技术的示例输出。技术快速扫描是一个简单的模型,可以作为定义跨技术背板的战略能力的起点。然后,可以将这些战略能力用于活动2.6中的供应商选择过程.
任务概述:任务概述,任务2.11.3定义能力部署时间表
定义EDM策略,经验教训
定义一个可以执行的策略
- 如果需要,推出一个大规模的自顶向下与自底向上策略(狭窄和详细)
- 使自下而上活动快速赢得和快速ROI:数据质量和元数据管理通常是最好的机会
- 在整个项目计划中总是定义战术战略与重构和持续改进的计划
设计一个对企业来说既灵活又有意义的策略
- 期望业务需求变化——提供一个基础设施来处理动态业务
- 知道你在每个实现的增量风险区域——专注于基础活动
- 注意技术锁定和知道成本并知道出去“退出”的成本——使用一个开放的方法
- 突破遗留技术的限制因素——这是杀鸡儆猴的机会
让业务参与
- 将技术背板功能“放在首位”,同时设计战略,从一开始就提供有意义的商业价值,否则您将在几个月内失去兴趣和关键员工
- 持续沟通战略中定义的计划方法 - 整体蓝图是计划生命周期的沟通文件
- 与用户密切合作,了解他们的数据价值,而不仅仅是系统功能 - 设计一种真正以应有的关注处理数据的方法
- 56 次浏览
【数据架构】TOGAF建模:数据发布图表
数据发布图的目的是显示数据实体、业务服务和应用程序组件之间的关系。该图显示了应用程序组件如何在物理上实现逻辑实体。这样可以进行有效的规模调整和这使得IT足迹得以细化。此外,通过将业务价值分配给数据,可以获得应用程序组件业务临界性的指示。该图可能显示数据复制和数据主引用的系统所有权。在此实例中,它可以显示两个副本以及它们之间的主-副本关系。此图可以包括服务;也就是说,服务封装数据并驻留在应用程序中,或者驻留在应用程序中并访问封装在应用程序中的数据的服务。
UML/BPMN EAP Profile

Show/Hide legend
![]() Entity component: An entity component is frequently derived from business entities, and is responsible for managing the access to the entity, and its integrity.
Entity component: An entity component is frequently derived from business entities, and is responsible for managing the access to the entity, and its integrity.
![]() Interaction component: Represents the top level components that manage the interaction with elements outside the IS. In most cases, it is a GUI component, such as here a web interface.
Interaction component: Represents the top level components that manage the interaction with elements outside the IS. In most cases, it is a GUI component, such as here a web interface.
![]() Process component: A process application component is responsible for a business process execution. It orchestrates the tasks of the process.
Process component: A process application component is responsible for a business process execution. It orchestrates the tasks of the process.
![]() Database component: Represents a repository. In pure SOA architecture, these elements should not appear. However, for legacy analysis or technology architecture, modeling repositories or repository deployment can be useful.
Database component: Represents a repository. In pure SOA architecture, these elements should not appear. However, for legacy analysis or technology architecture, modeling repositories or repository deployment can be useful.
![]() Persistent entity.
Persistent entity.
Archimate

![]() Application component.
Application component.
![]() Data object.
Data object.
在此模型中,数据被本地化到存储库或实体应用程序组件中
原文:https://www.togaf-modeling.org/models/data-architecture/data-dissemination-diagrams.html
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 71 次浏览
【数据架构】TOGAF建模:数据安全图
简单地说,企业数据的安全性和可访问性不应被视为企业的资产。数据安全图的目的是描述哪个参与者(个人、组织或系统)可以访问哪些企业数据。这种关系可以用两个对象之间的矩阵形式表示,也可以用映射表示。该图还可用于证明遵守数据隐私法和其他适用法规(HIPAA、SOX等)。该图还应考虑企业的合作伙伴或其他方可能访问公司系统的任何信任影响,例如信息可能由其他人管理的外包情况,甚至可能托管在不同的国家。
大型图表很难阅读。建议为每个业务实体和/或每个参与者(通常是一个角色)创建一个数据安全关系图。特别是,以参与者及其任务为重点的图表可以提供适应链接。图也可以集中在对系统的外部访问上,即外部参与者可以访问的数据。
或者,可以创建表,如下面的示例所示:
| Client | Individual trip | Order | Travel | Bill | |
| Sales person | CRUD | CRUD | CRUD | CRUD | CRUD |
| Marketing Agent | CRUD | ||||
| Billing person | CRUD | ||||
| Customer | CRUD | CRUD | CRUD | CRUD | CRUD |
仍然需要创建链接,因为它们可以在任何类型的图表中使用。
UML/BPMN EAP Profile

![]() External Actor: Actor that is external to the enterprise.
External Actor: Actor that is external to the enterprise.
![]() Internal actor: Actor which belongs to the enterprise
Internal actor: Actor which belongs to the enterprise
![]() Flow of data: There is one active element on one side (e.g. actor, process) and an element carrying data at the other side (entity, event, product). Habilitation can be expressed on these flows, expressing which access and rights on data the active element has.
Flow of data: There is one active element on one side (e.g. actor, process) and an element carrying data at the other side (entity, event, product). Habilitation can be expressed on these flows, expressing which access and rights on data the active element has.
Archimate

此图表示谁有权访问哪些数据以及使用哪些权限
原文:https://www.togaf-modeling.org/models/data-architecture/data-security-diagrams.html
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 116 次浏览
【数据架构】TOGAF建模:数据生命周期图
数据生命周期图是在业务流程的约束下,在整个生命周期(从概念到处理)中管理业务数据的重要部分。数据被视为独立于业务流程和活动的实体。状态中的每个更改都在图中表示,其中可能包括触发状态更改的事件或规则。数据与流程的分离允许识别公共数据需求,从而实现更有效的资源共享。
标识实体的可能状态(例如,文档可能是“未创建”、“未修改”、“已批准”等等),然后定义每个状态之间可能的转换。状态必须是稳定的数据状态:当没有对其执行任何操作时,数据始终处于已标识的状态之一。
定义业务实体的生命周期可以更好地形式化这些业务实体,并确定对其管理至关重要的步骤。这个非常简单的状态模型将导游业务流程的定义,因为这些过程将自己定义的约束必须尊重状态之间的转换:如果一个业务实体没有通过它所有的州内处理的业务流程,这些都是不完整的。如果业务过程违反了业务实体的生命周期,那么它们是不正确的。
UML/BPMN EAP Profile

“订单”业务实体的生命周期
![]() State: represent one of the main stable situations of a business entity or a product.
State: represent one of the main stable situations of a business entity or a product.
![]() Transition: move from one state to another state due to an action on the owner entity.
Transition: move from one state to another state due to an action on the owner entity.
原文:https://www.togaf-modeling.org/models/data-architecture/data-lifecycle-diagrams.html
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 148 次浏览
【数据架构】TOGAF建模:数据迁移图
数据迁移图的目的是显示从源应用程序到目标应用程序的数据流。该图将提供源/目标分布的可视化表示,并作为数据审核和建立可追溯性的工具。该图可以根据需要进行细化或增强。例如,该图可以只包含迁移环境的总体布局,也可以包含单个应用程序元数据元素的详细信息。
可以在概念级或物理级表达迁移。应用程序通信图也可以用来表示数据迁移。“迁移”依赖关系是正式化迁移的关键元素。
UML/BPMN EAP Profile

![]() Business Entity: Describes the semantics of the entities in the business, independently of any IS consideration (e.g. storage, technology, etc).
Business Entity: Describes the semantics of the entities in the business, independently of any IS consideration (e.g. storage, technology, etc).
![]() Business Entity (developed form): This also presents here one attribute, in other words, one property that the entity may have.
Business Entity (developed form): This also presents here one attribute, in other words, one property that the entity may have.
![]() Migrates link: Migration of elements between two versions of the IS. Generally used between business entities or application components.
Migrates link: Migration of elements between two versions of the IS. Generally used between business entities or application components.
Archimate

迁移依赖项可以在业务实体之间进行,也可以在“属性”级别更精确地定义。
在这个例子中,我们看到前一个数据模型中的几个属性在新的数据模型中被提升为“实体”。
这些图很快就会被链接弄得乱七八糟,它们应该集中在源或目标业务实体上。表格也可在下表中使用:
| Origin | Migrates in | ||
| Element | Nature | Element | Nature |
| transportation | Class | Travel | Class |
| Hotel | Class | ||
| Flight | Class | ||
| Travel | Class | Travel | Class |
| Travel.destination | Attribute | Destination | Class |
| Travel.hotel | Attribute | Hotel | Class |
| Reservation | Class | Roomreservation | Class |
| Hotem | Class | ||
我们看到,新模型的结构更好了,因为它对以前分散的信息进行了分组。它是标准化的。
原文:https://www.togaf-modeling.org/models/data-architecture/data-migration-diagrams.html
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 111 次浏览
【数据架构】TOGAF建模:概念数据模型图
数据类图的主要目的是描述企业内关键数据实体(或类)之间的关系。开发此图是为了清楚地表示这些关系,并帮助理解企业的底层数据模型。
此图处于高层次的表示(概念性的)。在这里,我们感兴趣的是建模主要的业务实体、它们的属性和关系。持久性模型(通常用于RDB)稍后将在应用程序层进行推断。
所定义的TOGAF类图处于早期的概念阶段。最高级允许表示企业的基本业务概念,而不受每个组织特有的组织或历史复杂性的影响。这个概念级别使您能够考虑业务,以便定义与此特定业务相关的理想组织。这些实体将用于定义业务流程(由流程处理的产品),并将派生为定义服务应用程序组件、在服务和存储库数据模式之间交换数据。

旅游折扣领域的主要业务实体及其关系
![]() Business Entity: Describes the semantics of the entities in the business, independently of any IS consideration (e.g. storage, technology, etc.).
Business Entity: Describes the semantics of the entities in the business, independently of any IS consideration (e.g. storage, technology, etc.).
![]() Business Entity (developed form): It also presents here one attribute, that is one property that the entity may have.
Business Entity (developed form): It also presents here one attribute, that is one property that the entity may have.
![]() Association between two classes. An association has a name, and provide at each end the role name, and the cardinalities (possible number of occurrences) of related elements.
Association between two classes. An association has a name, and provide at each end the role name, and the cardinalities (possible number of occurrences) of related elements.
原文:https://www.togaf-modeling.org/models/data-architecture/class-diagrams.html
本文:
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 121 次浏览
【数据架构】adservio 数据架构原则
QQ群
视频号
微信
微信公众号
知识星球
系统的数据资产和数据管理资源的组织被称为其数据架构。现代数据架构在设计时是积极主动的,在考虑可扩展性和灵活性的同时,预测复杂的数据需求。
数据架构原则都是关于设计、结构化和优化数据,用于分析计划,以产生业务价值。
无论您是负责数据、系统、分析、战略还是结果,现代数据架构的原则都可以用来帮助您处理当今时代的大量数据和决策。
您可以将其视为数据架构的框架,使您的公司能够在今天和未来以最佳状态运营。
让我们看看数据原理架构是什么,以及我们如何利用它们来帮助我们在处理数据时高效执行。
数据架构原则
数据架构原则的概念并不是一成不变的,因为数据本身是随着时间的推移而演变的。到目前为止,工程师们认为有一些原则很重要,并认为我们应该掌握这些原则。
下面按重要性降序列出了当今数据驱动市场的现代数据架构的原则,但该列表并不详尽。
使数据成为可共享的资产
拥有数据的目的是利用它,无论是支持决策、提供见解,还是创建更复杂的流程,并超越竞争对手。如果没有正确利用,数据孤岛可能会成为一个有效组织的消亡。
这些组织需要确保各方对公司有全面的了解,而不是允许部门数据孤岛继续存在。
确保组织利益相关者能够访问他们生成见解所需的数据并全面了解业务的最简单方法是删除任何部门数据仓库或介于两者之间的其他业务单元。
确保安全和访问控制
Snowflake、Google BigQuery、Amazon Redshift和Hadoop等统一数据平台的兴起,迫使数据政策和访问限制直接在原始数据上实施,而不是在下游数据存储和应用程序网络中实施。
随着当今世界对可广泛访问的实时数据的需求,高度安全的自助服务访问变得越来越重要。
如今,许多技术解决方案在不牺牲访问控制的情况下,通过提供内置的安全和自助服务功能,实现了数据架构。
始终确保查找能够提供自助访问的技术,同时还提供不会影响控制的内置安全功能。
提供正确的用户界面,方便数据利用
将数据存储在一个位置并不一定意味着消费者可以消费数据。为了使个人能够从共享数据资产中获得有价值的东西,我们必须提供界面,让用户更容易消费这些数据。
关键是让你的员工能够使用他们熟悉的技术,这适用于手头的任务。
这可以通过OLAP(在线分析处理)接口、各种目标系统的实时API、适合数据分析师的SQL接口或数据科学家的R语言来实现。
消除数据拷贝和移动
最好尽可能少地移动数据。每个组织都努力在各个方面做得更好,尤其是在数据部门这样的敏感部门。
如果消除或至少最小化数据传输,就可以避免不愉快的情况,并且可以降低数据架构的成本。
减少数据迁移的另一个效果是,企业的数据灵活性将得到全面提高。
整理数据
产生、排列和管理数据集的过程,以便寻找信息的用户能够访问和使用这些数据集,这被称为数据管理。
如果没有足够的数据管理,最终用户可能会有令人失望的体验,包括建模重要关系、清理原始数据以及管理关键维度和指标。
通过对执行数据管理的关键操作进行投资,您可以增加共享数据资产利益最大化的机会。
数据量的增加和数据源的复杂性可能会使企业不堪重负,数据管理有助于防止这种情况的发生。
我们应该记住,从业务角度来看,数据管理是企业数据战略的重要组成部分,因为它确保组织能够有效地使用其数据,并遵守与数据相关的安全和监管义务。
建立通用词汇
由于数据架构设计旨在具有灵活性和适应性,不同的数据功能和特征可能根据组织上下文具有不同的标签。
通过对数据进行投资,组织可以也应该开发一个标准词汇表,使公司内的广泛用户能够理解数据分析。
无论用户如何使用或评估数据,产品目录、会计日历维度、提供程序层次结构和KPI定义都必须是统一的。
否则,如果没有这个通用术语,您将花费更多的时间争论或解决结果,而不是在组织中提高绩效。
结论
正如与技术相关的一切都需要为未来的趋势和发展进行规划和准备一样,在设计和开发数据架构时,要考虑到技术部门正在出现的创新,也要考虑到一些特点。
现代数据架构应该支持弹性扩展、高可用性、动态数据和静止数据的端到端安全性,以及成本和性能可扩展性。
在开始开发当今的现代数据架构基础设施之前,必须考虑这些和其他细节。
- 4 次浏览
【数据架构】dragon1数据架构原则
QQ群
视频号
微信
微信公众号
知识星球
您知道数据和算法在您的组织中的使用和处理情况吗?
是还是否?
本页提供了一组21种数据架构概念和原则的信息,您可以使用这些概念和原则来衡量、分析、改进和优化公司中数据的使用和处理方式。
首先,它解释了什么是数据概念和数据原理,使用概念和原理的好处是什么。
接下来提供了一系列概念及其原理。
然后,您可以下载数据架构原理的数据集,将自己的数据添加到其中,并开始衡量数据和算法在您的公司中的使用情况。
数据概念
数据概念是一种处理组织外部已识别或存在的数据的方法,这些数据可以在组织中实现。
数据概念的例子有零信任数据、数据共享和数据验证。
一旦一个概念成为数据架构的一部分,我们就称之为数据架构概念。
组织的“当前状态数据架构”是组织中已实现的一组数据概念。
您有已实现的数据概念的列表吗?
如果您将数据概念作为存储库中的资产进行管理,那么您就可以控制您的数据架构。
数据原则
数据原理是数据概念或数据概念的一部分的工作方式。
一个概念可以有很多原则。
例如,零信任数据原则是:通过在用户通过身份验证之前不允许网络上的用户访问数据,可以确保更少的人可以未经授权访问数据,从而减少数据安全事件的发生。
数据原理告诉您以某种方式使用数据、处理数据、存储和检索数据的效果。
一旦您将数据概念作为数据架构的一部分,该概念的原则就是您组织的数据架构原则。
最重要的是,您所实现的数据架构原则告诉您,您在业务中集成数据和算法的效果如何,并让数据和算法在流程和系统中不间断地流动。
你有一份已实施的数据原则清单吗?
管理原则使您能够控制您的数据架构。
算法
算法是一组强大的指令,用于解决问题或完成任务。
今天,算法有许多发展和改进。
实践表明,你拥有的数据越多,你的算法就越有效,你使用的人工智能/机器语言技术越多,你就越能预测未来。
如今,越来越多的IT系统或应用程序具有嵌入式算法,这些算法工作效率很高,可以优化数据、人工智能和ML的使用,并很好地预测人们的行为。
但权力越大,责任越大。
现在,越来越多的组织需要报告、管理和控制他们使用的算法。
为此,我们还可以了解数据概念和数据原理。
算法可以被视为一个数据概念,用数据做各种事情。因此,通过测量实现的数据算法的类型,可以使公司中的任何算法变得可见和可控。
算法就像微小的CRM/BI程序,用于鉴定和解释数据。因此,它们包含变量、输入、指令、输出、条件、规则和循环,我们可以寻找。
一个需要识别的算法原则是算法数据资格和分类原则:通过确定XXX居住在AAA城市,有工作BBB,教育CCC,并且经常购买DDD,可以确保XXX属于目标受众YYY的类别。
示例公式:YYY=XXX*(AAA和BBB和CCC和DDD)。
具有洞察力和概览
因此,了解哪些数据架构原则在您的组织中得到了实施(以及实施得如何),可以揭示出您可以用来更好地创新和竞争的许多信息。
问题还在于,由于您的战略和业务模型,您需要在哪个成熟度级别实现哪些数据概念和原则。这一切都与未来的状态数据架构有关。
您的数据架构(即概念及其原理)与您的战略和业务模型的一致性越好,您就可以更好地执行您的战略并运行您的业务模型。
使用概念和架构原理的好处
一个概念(实现或方法的抽象)总是有一个或多个原则(概念的工作方式,产生结果)。
科学家每天都在发现和发展新的概念和原理。
它们可以帮助您进行创新和竞争。
了解一个概念的原理,可以帮助你决定你的公司是否需要这个概念,因为它会告诉你产生了哪些结果。
数据架构原则列表
以下数据架构原则可帮助您改进数据架构,从而提高组织的实力。
首先,对概念进行命名,然后阐述概念的第一个原理。在可能的情况下,提供文献参考和(设计)指南。
| 概念 | 原则 | 参考 | 指南 | |
| 1 | .数据(资产)管理 | 通过吸收、存储、组织和维护组织通过文件化和成熟的流程创建和收集的数据,可以确保做出更明智的商业决策,改进营销活动,优化业务运营,降低成本,从而增加收入、利润、存在性和业务连续性。。。 | ||
| 2 | 数据验证 | 通过在输入点验证所有数据,可以确保系统中数据的质量得到提高 | ||
| 3 | 数据发现 | 通过自动化定期数据发现,可以确保组织知道它正在获取多少数据,哪些数据集已对齐,哪些应用程序需要更新 | ||
| 4 | 数据共享 | 通过与其他部门共享数据,可以确保消除组织中的竖井,让更多的人拥有360客户端视图 | ||
| 5 | 最佳接口 | 通过向用户提供正确的接口,确保数据可以轻松共享,并可供他人访问 | ||
| 6 | 数据安全和访问控制 | 通过在原始数据级别制定访问策略和数据访问控制,数据更加安全,访问控制得更好 | ||
| 7 | 数据隐私 | |||
| 8 | 通用词汇 | 通过建立一个通用词汇,可以确保实现一致性 | ||
| 9 | 数据管理 | 通过管理数据(如建模正确的数据关系和清理数据),可以确保提高感知和实际数据质量 | ||
| 10 | 数据集成 | 通过以逻辑方式集成数据,可以确保复制的数据更少,以确保数据视图的完整性 | ||
| 11 | 数据消除 | 通过消除数据拷贝和数据移动,可以确保成本更低,数据质量更高,组织更灵活 | ||
| 12 | 数据分析/智能 | |||
| 13 | 数据算法鉴定和分类 | |||
| 14 | 数据预测 | |||
| 15 | 数据可视化 | |||
| 16 | 数据湖 | |||
| 17 | 数据仓库 | |||
| 18 | 数据虚拟化 | |||
| 19 | 数据中心 | |||
| 20 | 数据复杂性 | |||
| 21 | 数据事务 | |||
| 22 | 零信任 | 数据通过在数据经过身份验证之前不向网络上的用户提供对数据的访问,可以确保更少的人未经授权访问数据,从而减少数据安全事件的发生 | ||
| 23 | 搜索查询日志 | 记录[通过]让应用程序和数据库始终详细记录用户的搜索查询(最好是通过通用服务),[确保]欺诈和其他恶意活动可以更好、更快地被识别和发现,[从而]提高环境的安全性、可靠性和稳定性,降低风险和成本。(建议的搜索查询日志记录详细信息:日期时间、用户名、用户角色、上下文:进程/任务/应用程序/功能和搜索文本) | ||
你对这些数据原理感兴趣吗?想一想!
下载数据集
以上列表作为开放数据架构原则集(JSON格式)提供。
访问数据集页面。
在这里你可以下载数据集
接下来,您可以上传数据,在Dragon1 Viewer中观看。
理解数据共享原则
许多组织希望通过跨部门共享数据来打破各自的竖井。
但在他们决定后的1或2年后,组织中仍然存在许多筒仓。各个部门没有共享有意义的数据,而事实上他们可以共享。
注:在业务中,组织竖井是指独立于其他部门运作且不与其他部门共享数据的部门
假设该组织表示,“来自一个业务部门的数据、元数据、产品和信息,应根据国家或国际管辖法律和政策,包括尊重适当的现有限制,并根据国际道德研究行为标准,与其他业务部门充分公开地共享。”
根据Dragon1方法,这种说法不倾向于被标记为一种原则,而是一种一般规则或指南。这一一般规则或指导方针背后的基本原理通常包含Dragon1所支持的原则。
为什么Dragon1没有将上述声明作为一项原则?
如果我们将数据共享视为一个概念,那么我们可以描述数据共享概念是如何工作和实现结果的。我们可以描述关键要素如何协作并产生结果。
我们可以专注于事情如何运作的始终真实的事情。
当我们偶然发现这些东西时,我们正在描述数据共享的原则。
数据共享的一个原则可以是“通过识别所有可以从任何部门共享并具有明确价值的数据,通过消除共享的所有障碍并通过政策强制共享,确保业务部门之间共享更多数据,并打破竖井。”
上面的描述是一种总是正确的工作方式(或者至少很可能总是正确的)。这是一种工作机制。(当然,这个例子还有待进一步研究。)
一旦我们了解了一个原则(关于世界如何运作),它将影响我们如何设计解决方案、系统和政策。
因此,上述原则产生了影响。
例如,数据共享策略的关键元素经常缺失,或者缺少一个有意义共享的已识别数据列表。如果你实现了关键元素,你就增加了实际共享数据和打破竖井的机会。
如果你喜欢上面的内容,请在你的工作中尝试一下。
如果你不喜欢,就继续使用并依靠你现在的习惯。
要做什么-检查表
以下是一份关于如何最好地利用这些原则的清单:
- 对贵公司目前实施的数据概念和数据架构原则进行盘点。
- 使用此处提供的原则列表作为参考或起点。
- 收集业务流程流程图(BPMN)、数据图(DMN)、应用程序组件图(UML和ArchiMate)以及IT基础架构图(Azure、Amazone、Citrix或IBM模型)正在或应该受到数据架构原则的影响。
- 确定流程、数据、应用程序和IT基础架构受到或应该受到这些原则的影响。
- 分析差距。
- 制定一个路线图来填补这一空白。
测量、可视化和合理化
对于任何组织来说,衡量数据架构原则的实现程度以及成熟度是很重要的。
此外,合理化一个人需要和不需要哪些数据架构原则也是很重要的。
这一点非常重要,因为它让你坐在组织战略的驾驶座上。
在许多组织中,数据很快将成为一个无法控制的复杂整体。
您对数据或其复杂性的控制或管理越好,就越能与之竞争。
开始
Dragon1平台支持上述步骤。
创建一个帐户,并在指导下记录、衡量、合理化和改进您的数据架构原则。
- 5 次浏览
【数据架构】五大基本数据架构原则
QQ群
视频号
微信
微信公众号
知识星球
数据架构原则是一组策略,用于管理企业数据框架及其收集、集成、使用和管理数据资产的操作规则。数据体系结构原则的基本目的是保持支持性数据框架的干净、一致和可审计性。整个企业数据战略是围绕这些原则构建的。
近年来,DA原则进行了重大改革,以适应现代数据管理系统、流程和程序。现代DA原则有助于为数据架构奠定基础,该架构支持高度优化的业务流程,并推动最近的数据管理趋势。
以下是迫使全球组织对其现有数据体系结构进行批判性审视的数据管理趋势列表:
- 从内部部署转向基于云的数据平台
- 降低了流处理成本,有利于实时处理而非批量处理
- 预制商业数据平台被可扩展和可定制的模块化解决方案所取代
- 数据重用和用于数据访问的API
- 从数据湖转向基于域的数据存储
- 从预定义的数据模型转向灵活的数据模式
在企业中,每个用户都希望获得干净、易于访问的日常更新数据。有效的数据架构将所有数据管理流程标准化,以便将数据快速交付给需要的人。现有的数据架构设计需要改变,以跟上不断发展的数据管理需求。
正如麦肯锡的一位作者所观察到的,近年来,全球企业“在传统基础设施的基础上部署了许多新的和先进的技术平台”。这些新的技术解决方案,如数据湖、客户分析平台或流处理,给底层数据架构的性能带来了巨大压力。现有的数据体系结构未能提供增强的支持,甚至未能维护现有的数据基础架构。
此外,随着AI和ML平台在商业分析和BI活动中的应用越来越多,现在是对企业数据架构进行彻底改革的时候了。正如任何技术转型一样,当今数据体系结构“开发、尝试和测试”的数据体系结构原则与传统数据体系结构的原则截然不同。
这篇文章回顾了定义人工智能就绪的现代数据架构的一些核心原则。
数据架构的五大基本原则
随着企业数据持续呈指数级增长,全球企业正在通过实施大规模的数据扫盲和数据治理计划来应对这一惊人的数据增长。然而,为了从数据中获得最大的业务价值,组织需要战略思维和先进技术。
为了将数据作为一种有竞争力的资产加以利用,组织现在已经转向基本的DA原则来寻找答案。本帖子的其余部分将重点介绍企业数据活动成功的五个基本数据架构原则:
- 数据质量(DQ)是强大的数据架构的核心组成部分。数据质量对于构建有效的数据架构至关重要。管理良好、高质量的数据有助于建立准确的模型和强大的模式。高质量的数据也有助于提取有价值的见解。DQ是一个好的数据架构的核心原则,经常被忽视。KDNugget的这篇文章提醒我们,数据质量是数据架构中最被遗忘的方面之一。
- 数据治理(DG)是构建数据架构的关键因素。与上述原则密切相关的是,DG策略管理企业数据,无论数据源、类型或数量如何。在数据生命周期的任何时候,用户都必须知道位置、格式、所有权和使用关系,以及与数据相关的所有其他相关信息。因此,数据治理策略对于数据架构的成功至关重要,因为它们在可扩展性、DQ和法规遵从性方面扮演着“看门狗”的角色。
- 定期审计需要数据来源。数据来源是一组关于数据的信息,它跟踪数据从原始来源到处理过程。如果用户不知道数据是如何收集、清理和准备的,那么他们就不会知道底层数据架构的可靠性。
- 上下文中的数据是一个必要的元素。区分属性将一个数据实体与另一个数据主体区分开来。用户首先需要了解数据中存在的实体,以及它们之间的区别。除非完成这一步骤,否则用户将无法理解数据的上下文或其在提取见解方面的作用。区分属性有助于数据架构师理解上下文中的数据,这是数据建模的必要步骤。
- 需要了解每个属性的详细信息的粒度。数据架构师必须确定每个属性所需的详细程度。数据架构需要以正确的细节级别存储和检索每个属性;因此,这是构建高性能数据架构的关键一步。
尽管其他一些DA原则有助于构建企业数据架构,但关于它们的讨论超出了本文的范围。
现代大数据架构原理
任何关于数据架构的讨论如果不提及大数据,肯定会将一个关键方面排除在讨论之外。大数据表示必须管理数PB的多结构、多类型数据才能进行有意义的分析。以下是构建现代大数据架构的一些原则:
- 集中式数据管理:在该系统中,所有数据竖井都被跨功能的业务数据的集中式视图所取代。这种类型的集中式系统还支持360度查看客户数据,并能够将不同业务功能的数据关联起来。
- 自定义用户界面:由于数据是集中共享的,系统提供了多个用户友好的界面。接口类型与目的一致,例如用于BI的OLAP接口、用于分析的SQL接口或用于数据科学工作的R编程语言。
- 数据使用的通用词汇:企业数据中心确保通过通用词汇轻松理解和分析共享数据。该通用词汇表可能包括产品目录、日历维度或KPI定义,而与数据的消费类型或使用类型无关。通用词汇消除了不必要的争端和和解努力。
- 受限的数据移动:频繁的数据移动对成本、准确性和时间有很大影响。云或Hadoop平台为此提供了解决方案;它们都支持用于并行处理数据集的多工作负载环境。这种类型的架构消除了对数据移动的需求,从而优化了成本和时间投资。
- 数据管理:为了减少用户对存储在集群中的数据访问的不满,数据管理是绝对必须的。数据管理步骤,如清理原始数据、关系建模、设置维度和措施,可以增强整体用户体验,并帮助实现共享数据的最大价值。
- 系统安全功能:像Google BigQuery或Amazon Redshift这样的集中式数据管理平台需要严格的原始数据安全和访问控制策略。如今,许多技术解决方案在不影响访问控制的情况下,为具有内置安全性和自助服务功能的数据架构提供了便利。
上述数据架构原则可以显著提高大数据架构的有效性。有关更多信息,您可能希望查看一些DA最佳实践。
- 118 次浏览
【数据架构】什么是实体关系图(ERD)?
QQ群
视频号
微信公众号
知识星球
数据库绝对是软件系统不可分割的一部分。在数据库工程中充分利用ER关系图,可以保证在数据库创建、管理和维护中产生高质量的数据库设计。ER模型还提供了一种通信手段。
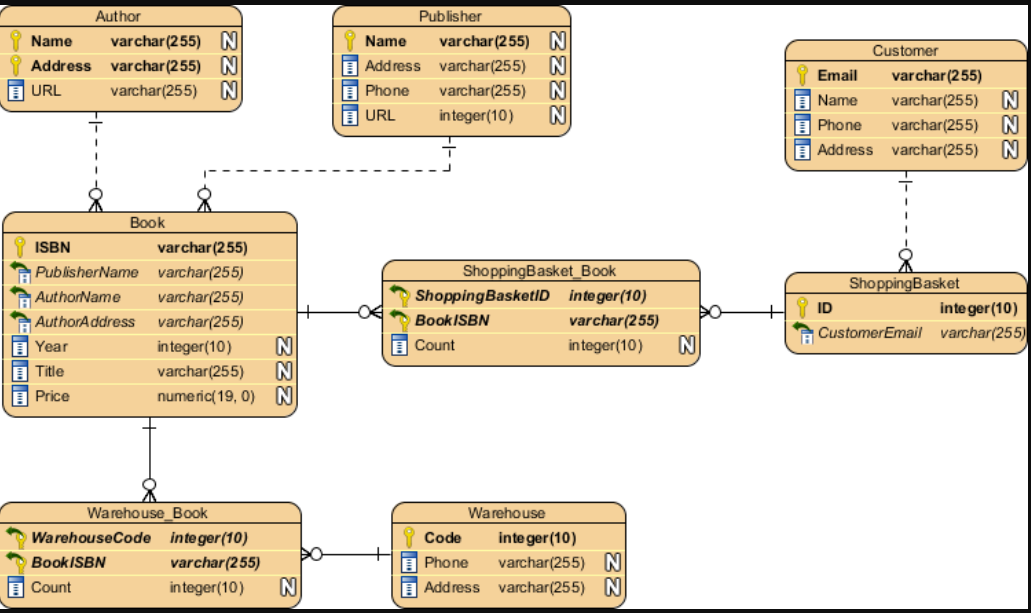
今天我们将带你了解所有你需要知道的关于ER图解的知识。通过阅读ERD指南,您将获得关于ER图和数据库设计的基本知识和技能。你会学到ERD是什么,为什么,ERD符号,如何画ERD,等等,以及一些ERD的例子。
什么是ER图?
首先,什么是实体关系图?
实体关系图,又称ERD、ER图或ER模型,是一种用于数据库设计的结构图。ERD包含不同的符号和连接器,它们可视化两个重要的信息:系统范围内的主要实体,以及这些实体之间的相互关系。
这就是为什么它被称为“实体”“关系”图(ERD)!
当我们在ERD中谈到实体时,我们通常指的是业务对象,例如人员/角色(例如学生)、有形的业务对象(例如产品)、无形的业务对象(例如日志)等。“关系”是关于这些实体如何在系统中相互关联的。

在典型的ER设计中,您可以找到描述实体、实体属性和相互关系的符号,如圆角矩形和连接器(具有不同的端点样式)。
什么时候画ER图?
什么时候画erd ?虽然ER模型主要用于在概念可视化和物理数据库设计方面设计关系数据库,但是在其他情况下,ER图也可以提供帮助。下面是一些典型的用例。
数据库设计
——根据变化的规模,直接在DBMS中更改数据库结构可能有风险。为了避免破坏生产数据库中的数据,仔细计划更改是很重要的。ERD是一个有用的工具。通过绘制ER图来可视化数据库设计思想,您有机会识别错误和设计缺陷,并在数据库中执行更改之前进行更正。
数据库调试
——调试数据库问题很有挑战性,特别是当数据库包含许多表时,需要编写复杂的SQL来获取所需的信息。通过使用ERD可视化数据库模式,您可以全面了解整个数据库模式。您可以轻松地定位实体、查看它们的属性并确定它们与其他实体之间的关系。所有这些都允许您分析现有数据库并更容易地发现数据库问题。
数据库创建和补丁
—Visual Paradigm是一个ERD工具,它支持一个数据库生成工具,可以通过ER图的方式自动创建和补丁数据库。因此,有了这个ER图工具,ER设计就不再是一个静态的图,而是反映物理数据库结构的一面镜子。
帮助收集需求
——通过绘制描述系统高级业务对象的概念性ERD来确定信息系统的需求。这样的初始模型还可以演化为物理数据库模型,以帮助创建关系数据库,或帮助创建流程图和数据流模式。
ERD符号指南
ER图包含实体、属性和关系。在这一节中,我们将详细讨论ERD符号。
实体
ERD实体是一个系统内可定义的事物或概念,例如人/角色(例如学生)、对象(例如发票)、概念(例如概要)或事件(例如交易)(注:在ERD中,术语“实体”经常被用来代替“表”,但它们是相同的)。在确定实体时,将它们视为名词。在ER模型中,实体显示为圆角矩形,其名称位于顶部,其属性列在实体形状的主体中。下面的ERD示例显示了一个ER实体的示例。

实体属性
属性也称为列,是持有它的实体的属性或特征。
属性具有描述属性的名称和描述属性类型的类型,如字符串的varchar和整数的int。在为物理数据库开发绘制ERD时,务必确保使用目标RDBMS支持的类型。
下面的ER关系图示例显示了一个包含一些属性的实体。
主键
主键是一种特殊的实体属性,它惟一地定义了数据库表中的一条记录。换句话说,不能有两个(或多个)记录共享主键属性的相同值。下面的ERD示例显示了具有主键属性“ID”的实体“Product”,以及数据库中表记录的预览。第三条记录无效,因为另一条记录已经使用了ID 'PDT-0002'的值。

外键
外键也称为FK,是对表中主键的引用。它用于标识实体之间的关系。注意,外键不一定是唯一的。多条记录可以共享相同的值。下面的ER关系图示例显示了一个具有一些列的实体,其中外键用于引用另一个实体。
关系
两个实体之间的关系表示这两个实体以某种方式相互关联。例如,一个学生可能注册了一个课程。因此,实体学生与课程是相关的,而一种关系是连接他们之间的连接器。
基数
基数定义一个实体中可能出现的事件数,该实体与另一个实体中可能出现的事件数相关联。例如,一个队有很多队员。当在ERD中出现时,实体团队和玩家以一对多的关系相互连接。
在ER图中,基数表示为连接器两端的鱼尾纹。三种常见的基本关系是一对一、一对多和多对多。
一对一的基数的例子
一对一关系主要用于将一个实体一分为二,以提供简明的信息并使其更易于理解。下图显示了一对一关系的一个示例。
一对多的基数的例子
一对多关系是指两个实体X和Y之间的关系,其中X的一个实例可能链接到Y的多个实例,而Y的一个实例只链接到X的一个实例。

多对多的基数的例子
多对多关系是指两个实体X和Y之间的关系,其中X可以链接到Y的多个实例,反之亦然。下图显示了一个多对多关系的示例。注意,在物理ERD中,多对多关系被分割为一对一对多关系。在下一节中,您将了解什么是物理ERD。
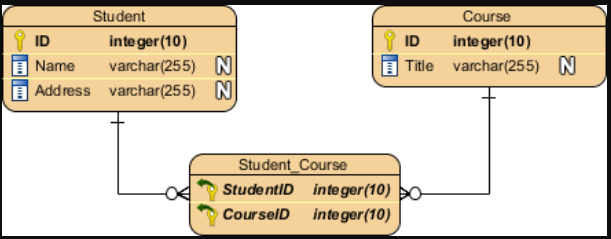
概念、逻辑和物理数据模型
ER模型通常是在三个抽象层次上绘制的:
- 概念ERD /概念数据模型
- 逻辑ERD /逻辑数据模型
- 物理ERD /物理数据模型
虽然ER模型的所有三个级别都包含具有属性和关系的实体,但是它们在创建的目的和目标受众方面有所不同。
一般理解的三个数据模型是业务分析师使用概念模型和逻辑模型系统中的业务对象存在,而数据库设计师或数据库工程师阐述了概念和逻辑ER模型生成物理模型,提出了物理数据库结构准备创建数据库。下表显示了三种数据模型之间的差异。
概念模型vs逻辑模型vs数据模型:
| ERD features | Conceptual | Logical | Physical |
|---|---|---|---|
| Entity (Name) | Yes | Yes | Yes |
| Relationship | Yes | Yes | Yes |
| Columns | Yes | Yes | |
| Column's Types | Optional | Yes | |
| Primary Key | Yes | ||
| Foreign Key | Yes |
概念数据模型
概念性的ERD对系统中应该存在的业务对象及其之间的关系进行建模。开发了一个概念模型,通过识别所涉及的业务对象来呈现系统的总体情况。它定义了哪些实体存在,而不是哪些表。例如,“多对多”表可能存在于逻辑或物理数据模型中,但在概念数据模型中,它们只是作为没有基数的关系显示。
概念数据模型示例

注意:概念性ERD支持在建模两个实体之间的“一种”关系时使用泛化,例如,三角形是一种形状。这种用法类似于UML中的泛化。注意,只有概念性的ERD支持泛化。
逻辑数据模型
逻辑ERD是概念ERD的详细版本。通过显式定义每个实体中的列并引入操作实体和事务实体,可以开发逻辑ER模型来丰富概念模型。虽然逻辑数据模型仍然独立于将要创建数据库的实际数据库系统,但是如果它影响设计,您仍然可以考虑这一点。
逻辑数据模型示例

物理数据模型
物理ERD表示关系数据库的实际设计蓝图。物理数据模型通过为每个列分配类型、长度、可空值等来详细说明逻辑数据模型。由于物理ERD表示在特定DBMS中数据应该如何结构化和关联,因此考虑实际数据库系统的约定和限制是很重要的。确保DBMS支持列类型,并且在命名实体和列时不使用保留字。
物理数据模型示例
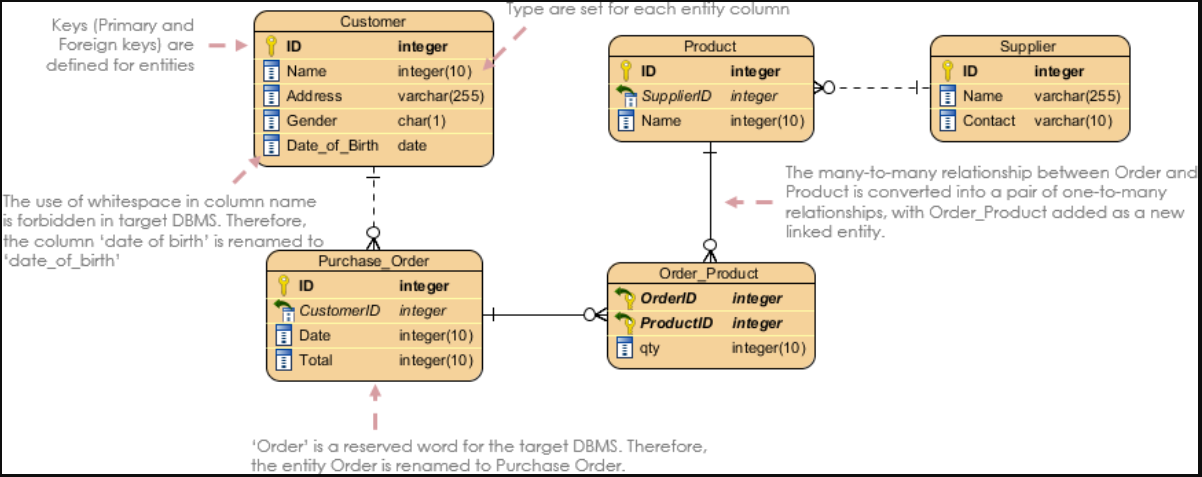
如何绘制ER图?
如果你发现很难开始画ER图,不要担心。在这一节中,我们将为您提供一些ERD技巧。尝试按照下面的步骤来理解如何有效地绘制ER图。
- 确定你清楚绘制ERD的目的。您是否试图呈现涉及业务对象定义的整个系统体系结构?或者您正在开发一个为数据库创建准备好的ER模型吗?您必须清楚在适当的细节级别开发ER关系图的目的(有关更多细节,请阅读“概念、逻辑和物理数据模型”一节)
- 确保您清楚要建模的范围。了解建模范围可以防止在设计中包含冗余实体和关系。
- 绘制范围中涉及的主要实体。
- 通过添加列来定义实体的属性。
- 仔细检查ERD,检查实体和列是否足够存储系统的数据。如果没有,则考虑添加其他实体和列。通常,您可以在此步骤中标识一些事务、操作和事件实体。
- 考虑所有实体之间的关系,并使用适当的基数(e。实体客户和订单之间的一对多关系)。不要担心是否存在孤儿实体。虽然不常见,但却是合法的。
- 应用数据库规范化技术以减少数据冗余和提高数据完整性的方式重构实体。例如,制造商的详细信息最初可能存储在Product实体下。在规范化的过程中,您可能会发现详细信息会重复记录,然后您可以将其作为单独的实体制造商进行拆分,并使用一个外键在产品和制造商之间进行链接。
数据模型的例子
ERD例子-电影租赁系统
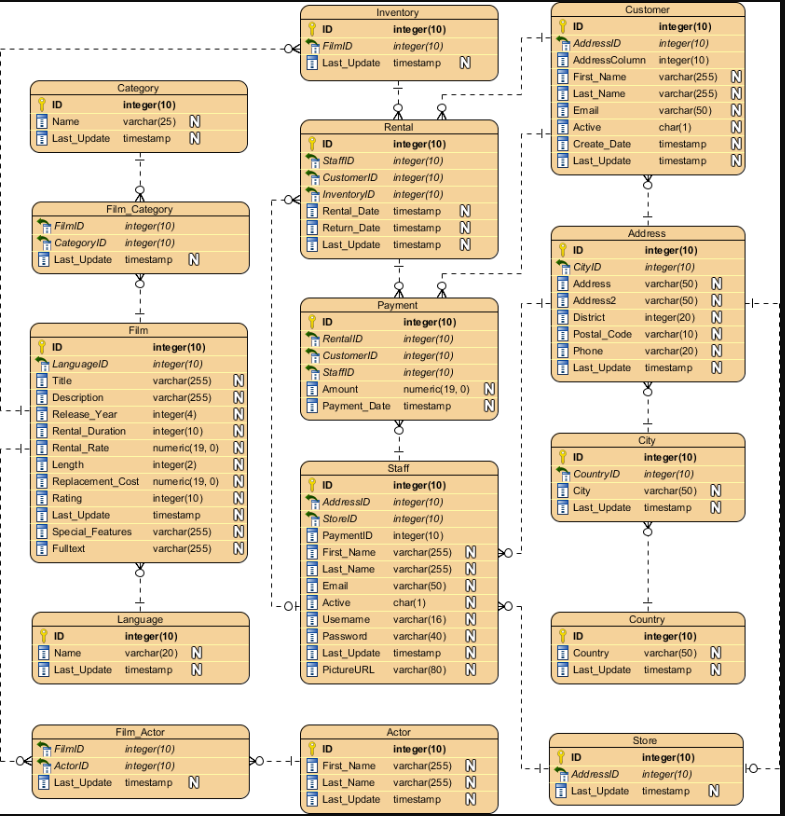
ERD示例-贷款系统

ERD的例子-网上商店

将ERD与数据流图(DFD)结合使用
在系统分析和设计中,可以绘制数据流图来可视化系统过程中的信息流。在数据流图中,有一个称为数据存储的符号,它表示一个数据库表,该表提供系统所需的信息。
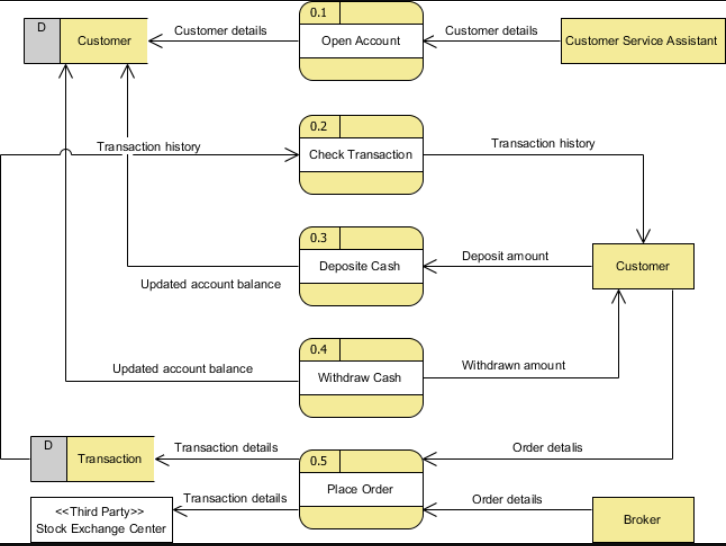
由于物理ER关系图提供了实际数据库的蓝图,所以ERD中的实体与DFD中的数据存储保持一致。您可以通过表示系统内流动的信息结构来绘制ERD,作为对DFD的补充,或者相反,通过显示系统在运行时将如何使用数据来绘制DFD,以补充ERD。

将ERD与BPMN业务流程图(BPD)一起使用
在业务流程映射中,可以绘制BPMN业务流程图(BPD)来可视化业务工作流。在业务流程图中,有一个称为数据对象的符号,它表示流程活动的数据输入/输出。
由于概念和逻辑数据模型提供了系统内业务对象的高级视图,因此此类erd中的实体与BPD中的数据对象是一致的。您可以通过表示业务工作流所需的数据对象的结构来绘制ERD,作为对BPD的补充,或者相反,通过显示如何在整个业务流程中使用数据来绘制BPD,以补充ERD。

选择ERD工具
使用ERD开发数据模型需要时间和精力。一个有用的数据库设计工具应该能够减少您所花费的时间和精力。Visual Paradigm不仅为您提供了ERD工具,还提供了一组可视化建模功能,帮助您更快、更轻松地绘制图形。它支持当今市场上大多数流行的关系数据库管理系统,包括数据库设计、数据库生成和ERD反转。

本文:http://jiagoushi.pro/node/856
讨论:请加入知识星球【首席架构师圈】
- 2951 次浏览
【数据架构】什么是数据架构?
QQ群
视频号
微信
微信公众号
知识星球
什么是数据架构?
数据架构描述了如何管理数据——从收集到转换、分发和使用。它设定了数据的蓝图以及数据在数据存储系统中的流动方式。它是数据处理操作和人工智能(AI)应用的基础。
数据架构的设计应该由业务需求驱动,数据架构师和数据工程师使用这些需求来定义各自的数据模型和支持它的底层数据结构。这些设计通常有助于满足业务需求,如报告或数据科学计划。
随着新的数据源通过物联网(IoT)等新兴技术出现,良好的数据架构确保数据可管理且有用,从而支持数据生命周期管理。更具体地说,它可以避免冗余的数据存储,通过清理和重复数据消除提高数据质量,并启用新的应用程序。现代数据架构还提供了跨域集成数据的机制,例如在部门或地区之间集成数据,打破了数据孤岛,而不会带来将所有内容存储在一个地方所带来的巨大复杂性。
现代数据架构通常利用云平台来管理和处理数据。虽然成本可能更高,但其计算可扩展性使重要的数据处理任务能够快速完成。存储的可扩展性还有助于应对不断增长的数据量,并确保所有相关数据都可用,以提高训练人工智能应用程序的质量。
概念数据模型与逻辑数据模型与物理数据模型
数据架构文档包括三种类型的数据模型
概念数据模型:
它们也被称为领域模型,提供了系统将包含什么、如何组织以及涉及哪些业务规则的全局视图。概念模型通常是作为收集初始项目需求过程的一部分创建的。通常,它们包括实体类(定义业务在数据模型中表示的重要事物的类型)、它们的特性和约束、它们之间的关系以及相关的安全性和数据完整性要求。
逻辑数据模型:
它们不那么抽象,提供了关于所考虑领域中的概念和关系的更多细节。以下是几种形式化数据建模表示系统之一。这些指示数据属性,例如数据类型及其相应的长度,并显示实体之间的关系。逻辑数据模型没有指定任何技术系统要求。
物理数据模型:
它们不那么抽象,提供了关于所考虑领域中的概念和关系的更多细节。以下是几种形式化数据建模表示系统之一。这些指示数据属性,例如数据类型及其相应的长度,并显示实体之间的关系。逻辑数据模型没有指定任何技术系统要求。
流行的数据架构框架
数据架构可以借鉴流行的企业架构框架,包括TOGAF、DAMA-DMBOK 2和企业架构的Zachman框架。
开放式组架构框架(TOGAF)
这种企业架构方法论是由开放集团于1995年开发的,IBM是该集团的白金会员。
架构有四大支柱:
- 业务架构,定义企业的组织结构、业务战略和流程。
- 数据架构,描述概念、逻辑和物理数据资产,以及它们在整个生命周期中的存储和管理方式。
- 应用程序架构,它表示应用程序系统,以及它们与关键业务流程以及彼此之间的关系。
- 技术架构,描述支持关键任务应用程序所需的技术基础设施(硬件、软件和网络)。
因此,TOGAF为设计和实现企业的IT架构(包括数据架构)提供了一个完整的框架。
DAMA-DMBOK 2
DAMA International最初成立于国际数据管理协会,是一个致力于推进数据和信息管理的非营利组织。其数据管理知识体系DAMA-DMBOK 2涵盖数据架构、治理和道德、数据建模和设计、存储、安全和集成。
企业架构的Zachman框架
该框架最初由IBM的John Zachman于1987年开发,使用了一个从上下文到细节的六层矩阵,针对六个问题进行映射,如为什么、如何和什么。它提供了一种正式的方法来组织和分析数据,但不包括这样做的方法。
数据架构和底层组件的类型
数据架构展示了不同数据管理系统如何协同工作的高级视角。其中包括许多不同的数据存储库,如数据湖、数据仓库、数据集市、数据库等。这些可以共同创建数据架构,例如数据结构和数据网格,这些架构越来越受欢迎。这些架构更加注重数据作为产品,围绕元数据创建了更多的标准化,并通过API实现了跨组织数据的民主化。
以下部分将深入研究这些存储组件和数据架构类型中的每一种:
数据管理系统的类型
数据仓库:
数据仓库将企业中不同关系数据源的数据聚合到一个单一、集中、一致的存储库中。提取后,数据流经ETL数据管道,进行各种数据转换以满足预定义的数据模型。一旦加载到数据仓库中,数据就可以支持不同的商业智能(BI)和数据科学应用程序。
数据集市:
数据集市是数据仓库的重点版本,它包含对组织内的单个团队或选定用户组(如人力资源部门)重要且需要的较小数据子集。由于数据集市包含较小的数据子集,因此在使用更广泛的数据仓库数据集时,数据集市使部门或业务线能够更快地发现更集中的见解。数据集市最初是为了应对组织在20世纪90年代建立数据仓库时遇到的困难而出现的。整合当时整个组织的数据需要大量的手动编码,而且耗时不切实际。与集中式数据仓库相比,数据集市的范围更为有限,因此实现起来更容易、更快。
数据湖:
虽然数据仓库存储已处理的数据,但数据湖存储原始数据,通常为数PB。数据湖可以存储结构化和非结构化数据,这使其与其他数据存储库不同。这种存储需求的灵活性对数据科学家、数据工程师和开发人员特别有用,使他们能够访问数据以进行数据发现练习和机器学习项目。数据湖最初是为了应对数据仓库无法处理不断增长的大数据量、速度和多样性而创建的。虽然数据湖比数据仓库慢,但它们也更便宜,因为在摄入之前几乎没有数据准备。如今,它们作为数据迁移到云的努力的一部分继续发展。数据湖支持广泛的用例,因为在数据收集时不需要定义数据的业务目标。然而,主要的两项工作包括数据科学探索以及数据备份和恢复工作。数据科学家可以使用数据湖来证明概念。机器学习应用程序受益于将结构化和非结构化数据存储在同一位置的能力,这在使用关系数据库系统时是不可能的。数据湖还可以用于测试和开发大数据分析项目。当应用程序已经开发完毕,并且已经识别出有用的数据时,可以将数据导出到数据仓库中以供操作使用,并且可以使用自动化来扩大应用程序的规模。数据湖还可以用于数据备份和恢复,因为它们能够以低成本进行扩展。出于同样的原因,数据湖有利于存储“以防万一”的数据,而这些数据的业务需求尚未定义。现在存储数据意味着随着新举措的出现,数据将在以后可用。
数据架构的类型
数据结构:
数据结构是一种架构,专注于数据提供商和数据消费者之间的数据价值链中的数据集成、数据工程和治理的自动化。数据结构基于“主动元数据”的概念,它使用知识图、语义、数据挖掘和机器学习(ML)技术来发现各种类型的元数据(例如系统日志、社交等)中的模式。然后,它将这种见解应用于数据价值链的自动化和协调。例如,它可以使数据消费者能够找到数据产品,然后自动向他们提供该数据产品。数据产品和数据消费者之间的数据访问增加,从而减少了数据孤岛,并提供了组织数据的更完整画面。数据结构是一种具有巨大潜力的新兴技术,可用于增强客户分析、欺诈检测和预防性维护。根据Gartner的数据,数据结构将集成设计时间减少了30%,部署时间减少了30%,维护时间减少了70%。
数据网格:
数据网格是一种去中心化的数据架构,按业务域组织数据。使用数据网格,组织需要停止将数据视为流程的副产品,并开始将其视为产品。数据生产者充当数据产品所有者。作为主题专家,数据生产者可以利用他们对数据主要消费者的理解为他们设计API。这些API也可以从组织的其他部分访问,从而提供对托管数据的更广泛访问。
数据湖和数据仓库等更传统的存储系统可以用作多个分散的数据存储库,以实现数据网格。数据网格也可以与数据结构协同工作,数据结构的自动化使新的数据产品能够更快地创建或实施全球治理。
数据架构的好处
构建良好的数据架构可以为企业提供许多关键好处,其中包括:
减少冗余:
不同来源的数据字段可能重叠,从而导致不一致、数据不准确和错失数据集成机会的风险。一个好的数据架构可以标准化数据的存储方式,并有可能减少重复,从而实现更好的质量和整体分析。
提高数据质量:
设计良好的数据架构可以解决管理不善的数据湖(也称为“数据沼泽”)的一些挑战。数据沼泽缺乏适当的数据质量和数据治理实践,无法提供深入的学习。数据架构可以帮助实施数据治理和数据安全标准,使对数据管道的适当监督能够按预期运行。通过改进数据质量和治理,数据架构可以确保数据的存储方式使其在现在和将来都有用。
实现集成:
由于数据存储的技术限制和企业内部的组织障碍,数据往往是孤立的。今天的数据架构应该旨在促进跨域的数据集成,以便不同的地理位置和业务功能能够访问彼此的数据。这样可以更好、更一致地理解常见指标(如支出、收入及其相关驱动因素)。它还能够更全面地了解客户、产品和地理位置,从而更好地为决策提供信息。
数据生命周期管理:
现代数据架构可以解决如何随时间推移管理数据的问题。数据通常会随着年龄的增长和访问频率的降低而变得不那么有用。随着时间的推移,数据可以迁移到更便宜、更慢的存储类型,因此它仍然可以用于报告和审计,但不需要牺牲高性能存储。
现代数据架构
随着组织为未来的应用程序(包括人工智能、区块链和物联网(IoT)工作负载)制定路线图,他们需要一个能够支持数据需求的现代数据架构。
现代数据架构的七大特点是:
- 云原生和云启用,使数据架构能够受益于云的弹性扩展和高可用性。
- 强健、可扩展和可移植的数据管道,将智能工作流、认知分析和实时集成结合在一个框架中。
- 无缝数据集成,使用标准API接口连接到遗留应用程序。
- 实时数据支持,包括验证、分类、管理和治理。
- 解耦且可扩展,因此服务之间没有依赖关系,开放标准实现了互操作性。
- 基于常见的数据域、事件和微服务。
- 优化以平衡成本和简单性。
- 5 次浏览
【数据架构】什么是数据架构?技术、开发和框架
QQ群
视频号
微信
微信公众号
知识星球
数据架构是用数据实现业务目标的蓝图。良好的数据架构对许多数据管理系统至关重要。它确保所有数据都能正确地传递给正确的用户!
数据架构包括为数据文档、组织、转换和使用创建可靠的框架。对于许多公司来说,数据的增长速度比以往任何时候都快,其复杂性也是如此,这就是为什么理解什么是数据架构很重要。许多公司的常见用例从ML/AI到营销分析,基础设施差异很大,从电子表格到数据仓库。
在这种复杂的环境中,数据架构对于管理、保护和激活整个组织中的数据越来越重要。但这个话题还有很多,这就是我们将在本博客中介绍的内容。
下面,您将了解数据架构到底是什么,它是如何与其他数据管理学科联系在一起的,一流数据架构的例子,最后但并非最不重要的是,这些框架如何改变您的业务。
请继续阅读,全面了解数据架构,包括为什么它对当今数据饱和的公司如此重要。
数据架构定义
数据架构是指一个框架,用于管理IT基础架构如何维护组织的数据战略。
该框架将业务需求转化为数据资产,并管理组织数据流。数据架构还为数据库管理系统、数据仓库、数据湖、BI工具和其他推动数据战略的技术平台提供了蓝图。
数据架构描述了组织的逻辑和物理数据资产以及数据管理资源。它包括模型、标准、策略和规则,以监控和控制各个公司对数据的获取、存储、安排、集成和使用。
该框架将业务需求转换为系统需求,以管理公司中的数据流。
数据架构通常由一组预定义的策略和图表来描述。其中包括:
- 描述系统和应用程序中数据流的数据流图
- 数据模型和数据定义
- 将数据使用情况映射到组织流程的文档
- 数据操作的标准和策略
- 高级建筑蓝图
数据架构文档还描述了业务目标、消费者需求和数据管理功能的核心概念。
数据架构与数据建模
数据架构和数据建模是数据管理这一巨大难题的两个独特部分。数据建模侧重于数据管理的微观方面;它是对数据元素属性及其关系的可视化表示的开发。数据模型应与组织的需求和性质相匹配。
数据架构才是大局。数据架构师创建的框架可以跟踪数据资产及其流,规定其使用、存储和集成,等等——所有这些都为数据处理奠定了坚实的基础。
在这个过程中,数据架构师使用数据模型来创建适当的设计并选择适当的技术。同样,良好的数据架构使创建数据模型的过程变得更容易。
数据架构与信息架构
尽管它们听起来像同义词,但数据架构和信息架构是两个截然不同的概念。如前所述,第一个术语指的是记录数据资产和流的学科,也是数据管理的蓝图。
另一方面,信息架构是一门对数据进行组织和标记的学科,使其变得有意义,也就是说,使其成为信息。现在,数据和信息之间的区别在于,第一个是原始的——无意义的事实单位,而信息是有上下文和意义的数据。
如果没有适当的信息架构,用户将无法访问所需的信息。然而,这种类型的架构取决于数据架构的质量。原因是数据架构框架处理所有的数据组织。
数据架构设计和开发中的不同角色是什么?
在将数据架构作为业务模型的一部分之前,了解更多关于该概念的信息非常重要。例如,学会区分数据架构设计和开发中的不同角色可以改善团队内部的沟通并提高效率。以下是最重要的:
数据建模师——
数据建模师的主要角色是弄清楚如何表示数据。此人还关心数据的准确性。他们创建物理、概念和逻辑模型,因此他们必须精通关系和维度数据建模。
数据科学家——
高素质的专业人员,他们收集和分析所有数据,并借助预测模型和算法从各种数据库中收集数据。他们的目标是识别模式、假设、分析市场趋势和客户行为,并得出准确的结论。
数据架构师——
将数据架构师视为梦想家。他们设计数据库系统和其他数据架构元素。然而,他们也评估数据并管理所需数据技术的购买。简单地说,他们需要确定哪种方法最适合存储和分析数据。他们还负责保护数据的安全。
数据工程师——
如果说建筑师是梦想家,那么工程师就是建设者。它们在大量数据库中创建数据管道、集成和平台。他们的主要任务是找到一种从多个来源传递数据的方法,并确保数据可以进行分析和处理。
数据架构背后的技术
技术将数据架构从文档转换为存在,包括机器学习、自动化、物联网和区块链等各种组件。
现代数据架构的一些关键技术特征包括:
- 云原生:今天的数据架构在云交付模型中托管的分布式计算环境中构建和维护应用程序。这些框架兼容端到端安全性和高数据可用性,并增加了成本和性能可扩展性的功能。
- 可扩展的数据管道:从源到目的地的数据传输应与快速增长的数据量兼容。这就是为什么现代数据架构应该支持即时数据流和微批量数据突发。
- 无缝数据集成:应用程序的新模块或功能必须是可集成的,而不会引起任何明显的复杂性。通常,现代数据架构使用标准API接口与传统应用程序集成。现代数据架构必须能够跨系统和组织共享数据。
- 解耦和可扩展:系统的组件不受同一平台、构建环境和操作系统的约束。现代数据架构是松散耦合的,以执行最小的任务,而不考虑其他服务。
- 实时数据启用:现代数据架构必须参与主动数据管理,以实时遵守强制执行的数据策略。这些框架必须构建和部署自动化的数据验证、管理、分类和治理。
如何开发数据架构
数据管理团队需要与业务主管和消费者保持一致,以开发数据架构。它确保业务策略、数据需求和架构本身相互同步。
以下是开发数据架构的一些示例步骤:
- 与高级管理人员会面,了解他们的支持和要求。
- 与最终用户接触,了解他们的数据需求。
- 根据数据治理策略评估与数据相关的风险和挑战。
- 构建和跟踪数据沿袭、数据生命周期和数据流。
- 评估现有数据管理技术基础设施是否存在任何差异。
- 为数据架构部署项目制定路线图。
使用Rivery,您可以避免使用传统方法构建、管理和监控数据管道的麻烦,Rivery提供180多个预构建的数据连接器和管道模板。Rivery可帮助您在几分钟内开发工作流程,为您的业务和组织节省宝贵时间。
流行的数据架构框架
以下是目前广泛使用的一些最流行的数据架构框架的概述:
- DAMA-DMBOK(DAMA International的数据管理知识体系)是专门为数据管理而开发的。它解释了数据管理的指导原则,还提供了数据管理功能、可交付成果和角色的定义。
- 企业架构的Zachman框架是一个用于组织信息的企业结构框架,由IBM的John Zachman在20世纪80年代创建。数据列包括多个层。此外,它还包括架构标准、企业数据模型、语义模型、物理数据模型和实际数据库。
- 开放式组架构框架(TOGAF)是一种企业架构本体,它为开发企业软件包和应用程序提供了一个高级框架。它采用系统的方法来组织开发过程。这种方法的重点是减少错误,管理时间表,确保成本效益,并使信息技术与业务部门保持一致,以产生理想的结果。
强大的数据架构造就强大的公司
随着数据量和复杂性的不断增长,强大的公司需要强大的数据架构才能蓬勃发展。
现代数据架构允许公司将大量不同的数据转换为可管理的资产,这些资产可用于实现业务目标。
这就是为什么,对于一家数据驱动的公司来说,现代数据架构不再只是一种竞争优势。现代数据架构是数据至上公司的支柱。
- 11 次浏览
【数据架构】什么是数据架构?概述和最佳实践
QQ群
视频号
微信
微信公众号
知识星球
目录
- 什么是数据架构?
- 数据架构理
- 数据架构框架
- 数据架构图工具
- 什么是数据架构师?
查看更多
在当今数据驱动的市场中,数据是领先竞争对手的关键。世界各地的公司都在利用其日益快速增长的数据量来做出战略商业决策。但是,由于数据无处不在,业务领导者必须能够筛选非结构化且往往不稳定的数据,并使其可行,以便解决复杂的业务问题。这使得数据架构变得更加重要。数据架构描述了如何在信息系统中收集、存储和使用数据。
什么是数据架构?
数据架构是有效数据策略的基础。根据数据架构的定义,它是一个由模型、策略、规则和标准组成的框架,组织用来管理数据及其在组织中的流动。在公司内部,每个人都希望数据易于访问,能够很好地清理,并定期更新。成功的数据架构标准化了捕获、存储、转换可用数据并将其交付给需要数据的人的流程。它确定了将使用数据的业务用户及其不同的需求。
数据架构的一个好方法是使数据从数据消费者流向数据源,而不是相反。目标是将业务需求转化为数据和系统需求。公司需要有一个集中的数据架构,该架构与业务流程保持一致,并提供数据各个方面的清晰性。数据架构的各个组成部分是结果、活动和行为。
数据架构是数据架构师的职权范围。数据架构师构建、优化和维护概念数据库模型和逻辑数据库模型。他们决定如何获取能够推动业务发展的数据,以及如何分发这些数据,为决策者提供有价值的见解。
数据架构原理
数据架构原则包括与数据收集、使用、管理和集成相关的一组规则。这些原则构成了数据架构框架的基础,有助于建立有效的数据策略和数据驱动的决策。
在入口点验证所有数据
通过消除坏数据和常见数据错误来改善组织数据的整体健康状况是很重要的。设计您的数据架构,以便尽快标记并更正错误。数据集成平台可以帮助做到这一点——在进入点自动验证数据。这也将有助于最大限度地减少清理和准备数据所需的时间。
努力保持一致性
为数据架构使用通用词汇将帮助同一项目中的用户进行协作。共享数据资产,如产品目录、会计日历维度等,无论应用程序或业务功能如何,都必须使用通用词汇表。此类共享数据的用户必须根据相同的核心定义工作,以保持对数据架构和数据治理的控制。
一切都应记录在案
养成记录数据流程所有部分的习惯,以便在整个组织中保持数据可见性和数据标准化。文档应帮助您记录收集的数据量、对齐的数据集以及需要更新的应用程序。一致的文档应与数据集成无缝配合。
避免数据重复和移动
每次移动数据时,都会影响成本、准确性和时间。现代数据架构应该减少对额外数据移动的需求,以降低成本、提高数据新鲜度并优化数据灵活性。现代数据架构将数据视为共享资产,不允许部门数据孤岛。这使得普遍更新数据变得更简单,并且每个人都可以从单一版本的数据进行操作。
用户需要充分访问数据
数据架构书籍规定,必须为用户提供正确的接口,以便使用指定的工具使用数据。
安全和访问控制至关重要
数据安全项目的出现使得确保统一的数据安全变得更加容易。数据架构必须在不影响对原始数据的访问控制的情况下进行安全设计。
数据架构框架
有多种企业架构框架被用作构建组织的数据架构框架的基础。
DAMA-DMBOK 2
这是指DAMA International的数据管理知识体系——一个专门为数据管理设计的框架。它包括数据管理术语、功能、可交付成果、角色的标准定义,还提出了数据管理原则的指导方针。
企业架构的Zachman框架
20世纪80年代,John Zachman在IBM创建了这个企业本体。该框架的“数据”列包括多层,如业务的关键架构标准、语义模型或概念/企业数据模型、企业或逻辑数据模型、物理数据模型和实际数据库。
开放式组架构框架(TOGAF)
TOGAF是最常用的企业架构方法论,它为设计、规划、实施和管理数据架构最佳实践提供了一个框架。它有助于定义业务目标,并使其与架构目标保持一致。
数据架构图工具
正确和一致的数据流对于成功的数据架构至关重要。为了获得最佳结果,需要定义和结构化数据流和数据关系。这就是数据架构图的用武之地。数据架构图展示了数据是如何以及在哪里流动、处理和利用的。数据架构图可以帮助决定如何更新和优化数据存储资源。由于数据不断被收集和使用,您将需要频繁地修改和更新数据架构图。
数据架构图应包含以下详细信息:
- 说明数据处理是如何进行的
- 显示数据的存储方式和位置
- 显示数据增量的估计速率
- 签署有助于未来增长的组件
专业软件或基于云的智能绘图应用程序可用于高科技数据架构图。用于创建和共享架构模型的著名数据架构工具包括:
- Diagrams.net
- Lucidchart
- Gliffy
- ER/Studio
什么是数据架构师?
数据架构师是将业务需求转化为技术需求并定义数据标准和原则的数据管理专业人员。数据架构师的角色是业务和技术之间的关键联系;因此,合格的数据架构师受到招聘公司的高度追捧。
数据架构师做什么?
作为数据架构背后的主谋,数据架构师为数据流和数据管理创建蓝图。他们评估组织的潜在数据源,并制定计划来集中、集成、保护和维持这些数据源。因此,员工可以随时随地访问关键信息。
数据架构师的角色需要:
- 与IT团队合作制定数据战略
- 建立实施架构所需的数据清单
- 研究数据获取机会
- 识别和评估正在使用的数据管理技术
- 开发数据模型等。
如何成为一名数据架构师?
由于数据架构师是一个不断发展的工作角色,因此没有关于如何成为数据架构师的具体培训或认证课程。通常,数据工程师、数据科学家或解决方案架构师等专业人员专门从事数据设计和数据管理;他们在职业道路上努力成为数据架构师。
全球就业市场对高技能的数据科学专业人员的需求很高。各行各业的公司都在招聘能够跨越商业和IT领域的数据架构师。
如果你想在数据科学或数据架构领域建立职业生涯,或者觉得有必要提高自己的技能,可以考虑由Simplilearn提供的加州理工学院数据科学研究生课程,Simplilearn是世界领先的在线认证培训提供商之一。
- 83 次浏览
【数据架构】什么是数据架构?概述和最佳实践
QQ群
视频号
微信
微信公众号
知识星球
目录
- 什么是数据架构?
- 数据架构原理
- 数据架构框架
- 数据架构图工具
- 什么是数据架构师?
什么是数据架构?数据架构原理数据架构框架数据架构图工具什么是数据架构师?查看更多
在当今数据驱动的市场中,数据是领先竞争对手的关键。世界各地的公司都在利用其日益快速增长的数据量来做出战略商业决策。但是,由于数据无处不在,业务领导者必须能够筛选非结构化且往往不稳定的数据,并使其可行,以便解决复杂的业务问题。这使得数据架构变得更加重要。数据架构描述了如何在信息系统中收集、存储和使用数据。
什么是数据架构?
数据架构是有效数据策略的基础。根据数据架构的定义,它是一个由模型、策略、规则和标准组成的框架,组织用来管理数据及其在组织中的流动。在公司内部,每个人都希望数据易于访问、清理良好并定期更新。成功的数据架构标准化了捕获、存储、转换可用数据并将其交付给需要的人的流程。它确定了将使用数据的业务用户及其不同的需求。
数据架构的一个好方法是使其从数据消费者流向数据源,而不是相反。目标是将业务需求转换为数据和系统需求。公司需要有一个集中的数据架构,该架构与业务流程保持一致,并提供数据各个方面的清晰性。数据架构的各个组成部分是结果、活动和行为。
数据架构是数据架构师的职权范围。数据架构师构建、优化和维护概念和逻辑数据库模型。他们决定如何获取能够推动业务发展的数据,以及如何分发这些数据,为决策者提供有价值的见解。
数据架构原理
数据架构原则包括与数据收集、使用、管理和集成相关的一组规则。这些原则构成了数据架构框架的基础,有助于建立有效的数据策略和数据驱动决策。
在入口点验证所有数据
通过消除坏数据和常见数据错误来改善组织数据的整体健康状况非常重要。设计数据架构以尽快标记和更正错误。数据集成平台可以帮助做到这一点——在进入点自动验证数据。这也将有助于最大限度地减少清理和准备数据所需的时间。
努力保持一致性
为数据架构使用通用词汇将帮助同一项目中的用户进行协作。无论应用程序或业务功能如何,共享数据资产(如产品目录、会计日历维度等)都必须使用通用词汇表。此类共享数据的用户必须根据相同的核心定义工作,以保持对数据架构和数据治理的控制。
一切都应该记录下来
养成记录数据流程所有部分的习惯,以便数据可见性和数据在整个组织中保持标准化。文档应帮助您记录收集的数据量、对齐的数据集以及需要更新的应用程序。一致的文档应与数据集成无缝配合。
避免数据重复和移动
每次移动数据都会影响成本、准确性和时间。现代数据架构应该减少对额外数据移动的需求,以降低成本、提高数据新鲜度并优化数据灵活性。现代数据架构将数据视为共享资产,不允许部门数据孤岛。这使得普遍更新数据变得更简单,并且每个人都可以从单一版本的数据进行操作。
用户需要充分访问数据
数据架构书籍规定,必须为用户提供正确的接口,以便使用指定的工具使用数据。
安全和访问控制至关重要
数据安全项目的出现使得确保统一的数据安全变得更加容易。数据架构必须在不影响对原始数据的访问控制的情况下进行安全设计。
数据架构框架
有多个企业架构框架用作构建组织的数据架构框架的基础。
-
DAMA-DMBOK 2
这是指DAMA International的数据管理知识体系——一个专门为数据管理设计的框架。它包括数据管理术语、功能、可交付成果、角色的标准定义,还介绍了数据管理原则的指导方针。
-
企业架构的Zachman框架
20世纪80年代,John Zachman在IBM创建了这个企业本体论。该框架的“数据”列包括多层,如业务的关键架构标准、语义模型或概念/企业数据模型、企业或逻辑数据模型、物理数据模型和实际数据库。
-
开放式组架构框架(TOGAF)
TOGAF是最常用的企业架构方法论,它为设计、规划、实现和管理数据架构最佳实践提供了一个框架。它有助于定义业务目标并使其与架构目标保持一致。
数据架构图工具
正确和一致的数据流对于成功的数据架构至关重要。为了获得最佳结果,需要定义和结构化数据流和数据关系。这就是数据架构图的用武之地。数据架构图展示了数据如何以及在哪里流动、处理和利用。数据架构图可以帮助决定如何更新和优化数据存储资源。由于数据是不断收集和使用的,因此您需要经常修改和更新数据架构图。
数据架构图应包含以下详细信息:
- 说明数据处理是如何进行的
- 显示数据的存储方式和位置
- 显示数据增量的估计速率
- 签署有助于未来增长的组件
专业软件或基于云的智能绘图应用程序可用于高科技数据架构图。用于创建和共享架构模型的著名数据架构工具包括:
- Diagrams.net
- Lucidchart
- Gliffy
- ER/Studio
什么是数据架构师?
数据架构师是将业务需求转化为技术需求并定义数据标准和原则的数据管理专业人员。数据架构师的角色是业务和技术之间的关键纽带;因此,合格的数据架构师受到招聘公司的高度追捧。
数据架构师做什么?
作为数据架构背后的主谋,数据架构师为数据流和数据管理创建蓝图。他们评估组织的潜在数据源,并制定计划来集中、集成、保护和维持这些数据源。因此,员工可以随时随地访问关键信息。
数据架构师的角色需要:
- 与IT团队合作制定数据战略
- 建立实施架构所需的数据清单
- 研究数据获取机会
- 识别和评估正在使用的数据管理技术
- 开发数据模型等。
如何成为一名数据架构师?
由于数据架构师是一个不断发展的工作角色,因此没有关于如何成为数据架构师的具体培训或认证课程。通常,数据工程师、数据科学家或解决方案架构师等专业人员专门从事数据设计和数据管理;他们在职业道路上努力成为数据架构师。
高技能的数据科学专业人员在全球就业市场上需求量很大。各行各业的公司都在招聘能够跨越商业和IT领域的数据架构师。
如果你想在数据科学或数据架构领域建立自己的职业生涯,或者觉得有必要提高自己的技能,可以考虑由Simplilearn提供的加州理工学院数据科学研究生课程,Simplilearn是世界领先的在线认证培训提供商之一。
- 160 次浏览
【数据架构】什么是数据流程图(DFD)?如何绘制DFD?
什么是数据流程图(DFD)?
一图胜千言。数据流图(DFD)是可视化系统中信息流的传统方法。一个整洁而清晰的DFD可以图形化地描述大量的系统需求。它可以是手动的,自动的,或者两者的结合。
它显示了信息是如何进入和离开系统的,是什么改变了信息,以及信息存储在哪里。DFD的目的是显示整个系统的范围和边界。它可以作为系统分析人员与系统中充当重新设计系统起点的任何人员之间的通信工具。
它通常以一个上下文图作为DFD图的第0级开始,DFD图是整个系统的简单表示。为了进一步详细说明,我们深入到第1层图,其中包含从系统的主要功能分解而来的较低层功能。当需要进一步分析时,这可能会继续发展成一个2级图。升级到3级、4级等等是可能的,但超出3级的情况并不常见。请记住,分解特定函数的细节级别取决于该函数的复杂性。
图中的符号
现在,我们想简要地向您介绍一些您将在下面的教程中看到的图表符号。
外部实体
外部实体可以表示人、系统或子系统。它是某些数据的来源或流向。就业务流程而言,它是我们所研究的系统的外部。由于这个原因,人们习惯于在图的边缘绘制外部实体。
.png)
过程
流程是进行数据操作和转换的业务活动或功能。可以将流程分解为更细的细节级别,以表示如何在流程中处理数据。
.png)
数据存储
数据存储表示进程所需和/或产生的持久数据的存储。下面是一些数据存储的例子:成员表单、数据库表等。
.png)
数据流
数据流表示信息流,其方向由箭头表示,箭头显示在流连接器的末端。
.png)
在本教程中我们将做什么?
在本教程中,我们将向您展示如何绘制上下文关系图以及级别1的关系图。
如何绘制上下文级DFD?
- 要创建新的DFD,从工具栏中选择Diagram > new。
- 在New Diagram窗口中,选择Data Flow Diagram并单击Next。
- 输入上下文作为关系图名称,然后单击OK进行确认。
- 我们现在画出第一个过程。从关系图工具栏中,将流程拖动到关系图上。命名新的过程系统。

- 接下来,让我们创建一个外部实体。将鼠标指针放在系统上。按下并拖出右上角的资源目录按钮。

- 释放鼠标按钮并从资源目录中选择双向数据流->外部实体。
- 将新的外部实体命名为Customer。

- 现在,我们将对系统访问的数据库进行建模。使用资源目录创建来自系统的数据存储,其中包含双向数据流。

- 命名新的数据存储库存。

- 创建另外两个数据存储,Customer和Transaction,如下所示。我们刚刚完成了上下文关系图。

如何绘制一级DFD?
- 我们将分解系统过程以形成一个新的DFD,而不是从头创建另一个图。右键单击System并从弹出菜单中选择分解。

- 连接到所选流程(系统)的数据存储和/或外部实体将在第1级DFD中引用。因此,当提示您将它们添加到新图表中时,单击Yes以确认。
- 注意:新的DFD最初看起来应该与上下文关系图非常相似。每个元素都应该保持不变,除了系统过程(从这个新的DFD分解而来)现在已经没有了,取而代之的是一个空格(待阐述)。
- 重新命名新的DFD。右键点击它的背景并选择Rename…在关系图的名称框中,输入Level 1 DFD并按回车键。
- 在中心创建三个流程(流程订单、发货、收货),如下图所示。那是系统过程的老地方,我们把它们放在那里来阐述系统。
-
连接数据流的连接线
- 本节中的其余步骤是关于连接图中的模型元素的。例如,客户在下订单进行处理时提供订单信息。
- 将鼠标指针放在客户上方。拖出资源目录图标并按进程顺序释放鼠标按钮。
- 从资源目录中选择数据流。

- 新订单信息有流程说明。

- 同时,流程订单流程也从数据库中接收客户信息来处理订单。
- 使用资源目录创建从客户到处理订单的数据流。

- 可选:如果您愿意,可以将数据流标记为“客户信息”。但是,由于这个数据流在视觉上是相当不言自明的,我们将在这里省略它。
- 通过组合来自客户(外部实体)的订单信息和来自客户(数据存储)的客户信息,Process order (Process)然后在数据库中创建一个事务记录。创建从流程顺序到事务的数据流。

- 绘画技巧:
- 若要重新排列连接线,请将鼠标指针置于要添加轴心点的位置。然后你会看到一个气泡在你的鼠标指针。按下并拖动到需要的位置。

- 到目前为止,您的图表应该是这样的。
- 一旦存储了事务,接下来就是传递过程。因此,创建一个来自Process Order (Process)的数据流来交付好(Process)。

- 发货时需要阅读交易信息(即订单号,以便包装正确的产品发货)。从事务(数据存储)创建一个数据流来交付好(流程)。

- 注意:如果缺少空间,请随意移动形状以腾出空间。
- Ship Good还需要读取客户的送货地址信息。从客户(数据存储)创建一个数据流来交付好(流程)。

- Ship Good然后更新库存数据库以反映所运货物。创建一个从发货(流程)到库存(数据存储)的数据流。更新的产品记录。

- 一旦订单到达客户手中,发放收据的过程就开始了。其中,收据是根据存储在数据库中的事务记录准备的。因此,让我们从事务(数据存储)创建一个数据流来发出收据(流程)。

- 然后向客户发出收据。让我们创建一个从问题收据(流程)到客户(外部实体)的数据流。命名数据流接收。

- 您刚刚完成了第一级图的绘制,它应该是这样的。

如何提高DFD的可读性?
- 上面完成的图表看起来有点死板和忙碌。在本节中,我们将对连接器进行一些更改以提高可读性。
- 右键单击图表(级别1 DFD)并选择连接器>曲线。图中的连接器现在用曲线表示。

- 移动图形,使图表看起来不那么拥挤。

更多过程示例
下面的列表向您介绍了涉及不同业务和问题领域的各种数据流图示例。其中一些包括使用多个上下文级别。
- 客户服务系统
- 食品订单系统
- 证券交易
- 超市的应用
- 车辆保养得宝
- 视频租赁存储
资源
- Order-Processing.vpp
- Order-Processing_result.vpp
本教程的读者也可以阅读
- 如何编写有效的用例?
- 数据流程图:实例-订餐系统
- 如何使用ERD对关系数据库设计建模?
- 如何开发现有的和将来的业务流程?
- 数据流程图与实例-客户服务系统
原文:https://www.visual-paradigm.com/tutorials/data-flow-diagram-dfd.jsp
本文:http://jiagoushi.pro/node/857
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 674 次浏览
【数据架构】从“热尔韦原理”看现代数据堆栈
QQ群
视频号
微信
微信公众号
知识星球
在一个组织中,数据不会从左到右移动,而是通过失败者、无线索者和反社会者移动。
去谷歌搜索“现代数据堆栈”一词,然后搜索图像。你看到了什么?这是一个又一个体系结构图,数据从左到右在各个系统中流动,这意味着除了购买5到100个不同的供应商解决方案来帮助移动数据之外,什么都没有。
从根本上说,从左到右的流动是有缺陷的,因为它是技术流动的伪装,而不是组织内的决策流动或资本分配流动。
最终,现代数据堆栈图通常是供应商、风险投资公司或员工扩充公司对当前对他们最经济有利的东西的看法。
今年早些时候,有一次,我把头砸在桌子上,问自己为什么不选择一个更高尚、更诚实的职业,比如土地投机、政治游说或碳抵消管理,我根据谷歌上这些荒谬图表的图像编制了《现代数据堆栈的现代数据堆栈》。
但是,如果我们反过来看看信息和资本实际上是如何在组织中流动的呢?如果我们从垂直轴而不是水平轴上的组织的病理性质来看待数据流,会怎么样?
进入“热尔韦原则”
Hugh MacLeod’s Company Hierarchy
文卡特什·拉奥的六部分《热尔韦原理》为数据堆栈问题提供了完美的背景。数据只是信息的一个子集,信息在组织中上下流动。
根据该范式,公司的组织如下:
- 反社会者是推动组织运作的资本主义奋斗者、权力意志者。这是大多数企业主、创始人和一些高管等。拉奥指出,该办公室的大卫·华莱士和简·莱文森是其成员。
- 无线索者是Kool Aid的饮酒者,他们被企业咒语所束缚,被经营模式所束缚,这些模式给了他们一个小小的帮助,比如承诺忠诚的薪酬或头衔的增加。最有效地将纸张、数据和信息打乱,他们构建叙事和宏大的故事,赋予自己的生活和劳动意义。拉奥指出,Andy Bernard、Dwight Schrute和Michael Scott是“无线索小组”的成员。
- 失败者是那些放弃了资本主义的奋斗,转而在组织层级中选择复选框的人,就像在结账和“我来这里只是为了薪水”的人群中一样。斯坦利·哈德森和凯文·马龙是失败者。
当然,这些标题/分类有些开玩笑。社会病学家不是临床反社会者,尽管人们确实认为这是许多临床反社会者随着时间的推移聚集的地方。失败者并不是不冷静的人,而是那些与雇主讨价还价的人,只要他们勾选了为他们准备的方框,就不会被打扰太多。
正如拉奥所指出的,麦克劳德公司遵循一个自然循环。一个有想法的Sociopath招募了足够多的失败者来启动这个循环并构建版本1。不可避免的是,随着版本1的开始,引入了一个无线索层来管理由越来越多的失败者创造的产量增长。这一无线索层起到了资本持有人/决策者和最接近生产的人之间的缓冲作用。
随着公司在周期中的成长,无线索层变得如此之大,以至于公司无法持续。最终,无线索层接管并摧毁了公司,因为Sociopath和Losers都退出了,因为他们生活得更接近现实,可以在组织之间最自由地流动。
我认为,我们现在看到的云数据仓库/现代数据堆栈和支持它的高员工团队是公司麦克劳德生命周期第四阶段的表现,在这个阶段,Cluless的中间件层变得如此无利可图、如此臃肿,与生产和有意义的决策都相距甚远,在许多科技公司,它已经做好了自我崩溃的准备。
以下是我对麦克劳德公司的现代数据堆栈/团队的看法。
- 失败者是数据生产者——应用程序团队和产品工程团队的任务是运行一组产生数据的应用程序、系统或服务。
- 无线索是现代数据堆栈数据团队,其任务是处理这些数据供Sociopath使用。
- Sociopath是数据消费者,即管理损益表并分配资本以增加或减少增量预算以支持数据在整个组织中的持续移动的商业化数据的高管、部门负责人和买家。
根据供应商的说法,以下是现代数据堆栈的理想工作方式。它有所有的经典标志。
来源->摄入层->多表的存储/仓库->BI或操作或AI/ML。
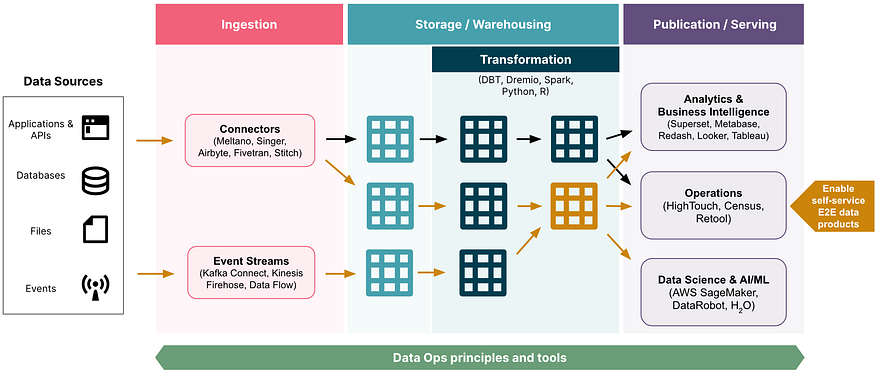
但我还没有在任何供应商/VC/员工aug公司图中看到的是相关人员的细分。
首先,与现代层次结构相比,现代数据堆栈旋转了90度。
恭喜你,你已经建立了一个越来越复杂的人工中间件层,在一个集中的云数据仓库上制作表、表和表,为业务(Sociopath)追求KPI,但依赖于那些没有动机关心他们产生的数据质量的应用程序所有者(失败者)。
一旦数据流被垂直呈现,各阶段与结果相关,组织固有的病理性质就有了很大的揭示。
这些阶段中的每一个都代表着从一个组到另一个组的转移,即数据保管的转移。然而,真正了解膨胀是如何累积的,需要了解这些群体之间的数据传递。
数据合同
理解和检查“失败者到无线索”切换
询问任何一位现代数据堆栈领导者他们的前三大问题,我向你保证,前三大(如果不是第一大的话)之一是应用程序和数据团队之间的切换。
从根本上讲,这是一个垃圾进垃圾出的问题。最简单地说,如果数据源中的数据质量不高,或者它的定义或结构发生了变化——无论是RevOps团队拥有的Salesforce对象,还是应用程序团队拥有的一组Postgres表——这些数据都会被复制、复制、集成或其他任何形式的集中存储,如Snowflake、BigQuery或类似的存储,它将导致不正确的数据,而这些数据并不能反映它应该代表的现实。
失败者,应用程序团队,做出了一个改变,勾选了他们的功能部署框。
Sociopaths的高管们注意到仪表板或数据产品坏了。
Cluless,即集中式数据团队成员,四处奔波,要么在云数据仓库中对SQL进行某种“修补”或“变通”,要么回到应用程序团队,指控他们未能遵守制定的联合问责标准。
后者几乎从未发生过。现代数据堆栈数据团队自然地处于这一动态的中间位置,进行定点并累积技术债务、增加的人力资本和采取这些行动的云成本。
他们在Sociopaths面前失去了部分信誉。
他们成为了修补技术债务的推动者,并在云数据仓库中制作更多的表。编译和运行从源到存储再到仪表板的增量SQL模型的时间增加了。为了在基线上交付,需要消耗更多的计算量。
失败者并不在乎。Sociopaths只想修复他们的仪表盘。
当迭代超过2、3、10、20、50次或更多次时,这会导致在无线索层中雇佣更多的人。正如麦克劳德组织中的中层管理人员膨胀一样,数据团队也膨胀了,出于同样的原因,Sociopath和Losers之间固有的脱节。
这开启了一个永无止境的循环。
工作申请书已经写好了。需要:数据/分析工程师;必须熟悉dbt和Airflow,并了解云数据仓库$每年180000英镑外加福利。
然后,由于仓库中人头和表的数量增加了,无线索层可能需要一个可观察性工具来帮助他们对/at/around中发生的事情不那么一无所知,因为他们已经制作了越来越多的表和SQL。
他们可能还需要一个目录,一个与他们运行DAG的方式分开的沿袭工具,以及一个测试工具,以确保他们创建的PR能够产生经过适当测试的新表。
在某种程度上,根据我的经验,通常早在4-5个人的时候,现在你只是在添加人头和越来越复杂的DAG。每一次招聘都涵盖了之前为在云数据仓库上绘制SQL图而增加的主管所带来的技术债务和通信挑战。
据说,解决方案是强制执行数据合同。这至少限制了从“失败者”到“无线索”切换所导致的停机时间和修补。
许多运行过数据平台团队的人至少已经提出了数据合同的问题,并提供了一些解决方案的框架,包括实际的例子和建议。
James Densmore在这里提出了一个深思熟虑的方法。
Chad Sanderson非常详细地阐述了这个问题,并在这里提供了类似的解决方案。
这些都是朝着正确方向迈出的步骤,我认为它们至少形成了一个可以应用于多个组织的范式。
但这两者都错过了当合同被违反时会发生什么的胡萝卜或大棒。
从根本上说,数据合同是一个中间件无线索团队必须如何激励失败者团队遵守无线索团队希望建立的规则的问题,以便无线索团队安抚Sociopath数据消费者,他们没有时间也没有技术知识来处理同一公司的技术团队之间的合同谈判,其中合同是在Github PR或类似平台上表现为接受标准或“完成定义”的数据模式。
在我的职业生涯中,我多次看到这种情况的发生,我真的相信,只有那些直接出售或以其他方式利用数据的组织,通过向数据经纪人、对冲基金、希望了解其销售的供应链完整销售情况的制造商等提供数据。
如果Loser到Cluless切换导致数据集直接大写或以其他方式反映为资产,那么它可以工作。未能遵守数据合同是对收入的风险,因此责任开始存在。
如果在一个无线索数据团队是纯粹成本中心的组织中存在“失败者到无线索”的切换,请忘记它。
全能的仪表板
理解和审视无线索到社会病态的切换
祝贺
您已制定好数据合同。
但是谁制造仪表盘呢?
在现代数据堆栈上创建仪表板时会发生以下几件事之一,因为必须有人制作或收集仪表板、分析或可视化。
一种途径是分析师(仪表板制造商)向特定的业务部门报告。通过这种方式,这些人向Sociopaths管理的损益表报告。对于许多渴望有朝一日进入Sociopath班的年轻人来说,这是一个巨大的垫脚石机会。
一种方法是让分析师向Cluless报告,该团队正在Snowflake(或其他什么)中制作表、表、表,在SQL上写SQL。对于那些渴望随着时间的推移“获得更多技术”并可能希望与无线索层保持一致的人来说,这是一块很好的垫脚石。
然而,作为一名分析师,如果你想走Sociopath路线,这通常是非常糟糕的职业选择。你的简历将填写供应商和语言的名称,并且不太可能包含有关商业成果的信息。这本身没有错,只是一个根本不同的结果,年轻或新的数据专业人员在评估机会时应该理解这一点,评估他们将向哪种类型的分析师或数据科学家团队报告。
另一条途径是让各种业务人员让他们的操作人员制作仪表板。这通常被认为是“自助分析”,但实际上大多数Sociopath不会做太多自助服务。
这一个很好,通常是最没有意义的。
很多时候,同一个人既是应用程序所有者(例如,Salesforce Ops、Customer Service Ops等),现在也是仪表板制造商,其中一层是Cluess团队,在中间运行数据仓库,应用程序所有者和操作人员兼任数据生产者和数据消费者。
正在扩展的人类中间件层
大多数数据基础设施和数据工程工作的核心是,这些团队和组成他们的人员都被夹在中间,默认情况下,一旦他们在第一天开始新的工作,他们就注定会陷入现代无线索状态。他们通常不是数据生产者,而是为数据消费者服务,数据消费者实际上是负责管理技术中间件的人类中间件,即系统之间的集成、模式、数据合同和互操作性。
事实上,即使是这些团体的领导人也经常失败。许多首席数据官都失败了。哈佛商学院已经写过这方面的文章。Gartner在2019年表示,只有一半成功。
在当今的科技组织中,许多组织没有定义的CDO,但在副总裁或总监头衔中有一些功能性的“数据主管”,我们也看到了许多问题,主要是人类中间件变成了人类膨胀软件。
就在过去的几周里,有几篇文章谈到了现代数据堆栈中的挑战。
这一次来自该领域的供应商dbt实验室,表明在他们自己的dogfooded dbt项目中,他们在Snowflake中有1700多个SQL模型,并且一直在昂贵的云数据仓库计算周期上运行全窗口函数表扫描,每天4次,不必要地每年为他们的云账单增加数万美元,并严重影响吞吐量。此外,他们还拥有一支自己的内部分析工程师团队,随着时间的推移,规模不断扩大。
这张来自忠诚度平台ShopBack的一名数据员工的照片显示,为分析目的创建的头部数量不断增加,从6个月增加到18个,SQL序列数量也在增加,在6个月内增加了约700个。
在这两种情况下,两家公司都不仅仅是风险投资支持的,而且在短时间内经历了几轮大额融资。
这种循环几乎每次都以类似的方式在这类公司中上演。
注入现金。这意味着雇佣了更多的各类员工。更多的员工增加了对更多报告和分析的需求。更多的需求意味着,当您采用现代数据堆栈范式,将所有内容放入您选择的云数据仓库时,将在无线索层中创建更多的人工中间件。
更多无线索的人类中间件创建了更多的表、表、表到更多的报告、KPI和度量。他们不得不购买新产品并雇佣新人来管理复杂性。然后,新一轮融资开始了。数据团队雇佣了更多的人员和产品。组织雇佣了更多的人员,这就产生了对更多KPI和指标的更多需求,并产生了更多的报告、KPI和指标。
这个循环一直重复到钱用完为止。
所有这些有效地做的就是把人体扔到问题上,拼凑出一些解决方案,其中一些可能一开始就不必发生。
这方面的超额成本会转嫁给云供应商及其周围的服务,越来越多的无线索层员工制作了越来越多的表和SQL序列,以根据越来越多的失败者拥有更多的应用程序并生成更多的数据,为越来越多的Sociopath寻找越来越多的指标和KPI以及报告。
在风险资本一次又一次的涨价推动下,麦克劳德周期在时间上压缩了。

组织内部不断增加的人工中间件和中层管理不再需要几年的时间,而是需要数月或一两年的时间。
虽然一家自筹资金或传统企业将员工增长视为盈利能力和潜在债务的函数(“在受伤之前不要雇佣”),但许多风险投资支持的数字公司更快地完成了这一生命周期(“始终在雇佣”)。大量现金一轮又一轮地投向这些企业,有时只需几个月的间隔支票。
在过去几年中,美国延长了量化宽松政策,实际上实现了零利率,这导致一家又一家企业创建了数据功能,并有效地免费提供资金,在组织内拍摄数据。
数据集中实际上是敌人吗?
现代数据堆栈最大的骗局之一是,所有数据都需要通过一个集中的存储库,到达一个集中化的团队,才能产生某种结果。
事实上,大多数业务决策都是在业务线级别做出的,这些数据可能在团队内部保持孤立或“孤立”,并由负责这些数据的应用程序所有权负责。
为什么销售运营团队需要一份通过Snowflake或类似程序运行的报告,而他们所需要报告的只是每个SDR的拨号或活动归属,已经在他们使用的联合集成的Salesforce和Marketo中了?
现在,叙述中说,从每个单独的应用程序或上游数据库中引入所有原始数据,然后在云数据仓库中的SQL中将它们折叠在一起。
然后,雇佣一个团队来管理云数据仓库中的所有SQL联接。
然后,数据在云数据仓库过程结束时被认为是正确的。
然后,聘请分析师进行报告和BI的输出。
这一切都是极其低效的资本。
考虑到许多软件行业面临倒闭和裁员,许多消费/消费金融行业已经承担债务或可能很快不得不承担债务,大多数采用这种运营模式的公司都无法继续大规模为此买单。
员工成本太高,员工追踪第n个KPI或指标、分析或报告所产生的增量云成本太高。
从根本上说,现代数据堆栈/云数据仓库的故事是2010年末/2020年初的故事之一,基本上是免费的,增长-增长-增长的心态,很少关注盈利能力。
就在几年前,dbt还被作为“Casper、InVision、Away Travel等公司”使用的工具进行营销
- 卡斯珀甚至从未盈利过,它以其峰值估值的一半进行了首次公开募股,并最终在首次公开募股后以另一次降价被私有化,正如许多纸上谈兵的MBA在无数视频和文章中所指出的那样。
- InVision今年夏天解雇了50%的员工。
- 在过去的两年里,Away经历了各种各样的戏剧表演。
列表不断。请随时在他们的档案或Wayback Machine上查找您最喜欢的现代数据堆栈点解决方案工具,并查看2018-2019年左右的公司现在的表现。
控制人类中间件膨胀必须成为前进的道路
在我咨询过的任何一家现代数据堆栈公司中,几乎没有一家公司的“数据主管”因其预算管理而获得有意义的补偿。这种情况会发生,但很少发生,尽管这是许多大型企业的经营方式。
市场营销在11月至12月发送的电子邮件和短信数量是原来的10倍,然后人们会挠头,想知道为什么他们的Fivetran(或类似)信用卡被烤了,企业必须再花2万至3万美元才能提前恢复。这是因为Fivetran和类似的基于行的定价模型根据摄入的数据量收费。如果你已经连接了所有的电子邮件系统,并且产生的数量是原来的10倍,那么基于数量的模型的成本就会上升。
新的物联网或日志数据被纳入一个集中的数据仓库,用于新的计划。这些数据被快速地组合、吸收、存储,现在每天都有5亿新行(而且还在增长!)开始填充表格。当然,这也加入了SQL现有的DAG,就像现在一样,云数据仓库的账单在第一个月每月上涨了7000美元,今年可能会增加10万美元,这取决于它在SQL图表中的位置以及由此产生的报告和分析。
所有这些问题(我能说出更多的问题)从根本上讲都是由这些数据团队缺乏财政责任和运作纪律造成的。
作为一种解决方案,为了在即将到来的经济衰退压力面前保持领先,我建议如下:
- 高管领导层围绕其数据团队的支出制定了严格的预算,数据领导层根据其管理的预算进行补偿。如果数据领导者总薪酬的25-30%取决于保持在支出限额内,这将立即建立一种成本管理文化。作为一种权衡,这可能意味着向数据团队提问的人提供的请求更少,也可能意味着进入云数据仓库的系统更少。这是一件好事,因为较低级别的请求将贯穿运营团队,并且只提供方向性的重要请求。
- 确保数据团队的个人贡献者能够理解构建第n个管道或编写额外SQL的财务影响。事实上,我可以说,在我合作过的大约50%的组织中,在云上构建管道、SQL和分析的个人贡献者员工由于角色限制或各种用户权限配置而无法了解他们的操作成本。我认为这是一个错误,我从其中许多人那里听说,他们至少想知道自己努力的代价。如果你的牙齿里有菠菜,最好有人让你知道,而不是你整天带着菠菜走来走去,却不知道。
- 开发一种“解雇”仪表板、DAG节点和管道的文化,这些节点和管道不起作用或服务有限,或在其他方面未使用。事实上,在大多数云成本呈螺旋式上升的组织中,这可能是一个主要的成本节约,尤其是当与提供大量日常查询使用的适当物化DAG节点相结合时。
- 最后,成本的最大驱动因素之一,如果不是员工成本中的云支出,就是通过云数据仓库为财务请求提供服务。我已经一次又一次地看到与VC支持的数字公司合作,而这种“影子金融”以及如何避免它完全值得另一篇文章。不应该有数据工程师、分析工程师或分析师或任何其他有头衔的人将云数据仓库中SQL中的不同事务和订单系统数据连接在一起,然后将这些数据转储到BI仪表板上,供财务人员下载,甚至更糟——当它一开始没有正确进入仓库时,将其反向ETLing到财务记录系统中。这可能是一些公司数据团队成本的主要驱动因素,专门的数据员工在云上使用SQL来清理和连接数据,并创建用于结账、纳税或执行任何其他类型财务操作的数据集。让金融部门在自己的系统中解决自己的实体,然后根据需要将其纳入云数据仓库,而不是相反。
- 最终,将数据从系统A铲到系统B并对其进行规范化和非规范化几乎没有内在价值。随着我们进入经济衰退,数据膨胀持续爆发,请记住,最好的团队是那些推动最直接影响的团队,而不是那些构成配置大绑定的团队。
- 22 次浏览
【数据架构】企业数据架构原则
QQ群
视频号
微信
微信公众号
知识星球
1.数据是一种资产
数据就像任何共享资产一样,对整个部门乃至其他部门都有价值。
为什么?
数据是部门共享资源,具有可衡量的价值。数据是支持无缝、以用户为中心的用户旅程的金线,让用户尽可能自助服务。数据支持各级决策,从一线交付到整个教育部门的决策和治理。需要准确及时的数据来支持准确及时的决策。与所有公司资产一样,必须谨慎管理和维护数据,确保其准确性和可靠性。由于它是我们决策的基础,我们必须清楚地了解它在哪里,它有多好,以及代表国防部拥有它的个人,我们必须能够在需要的地方和时间访问它。
怎样
- 这一原则与“数据共享”和“数据可获取”有关,因此所有团队都应该理解数据的价值、数据共享和数据可访问性之间的关系。
- 所有数据都应在国防部的数据产业地图中登记,该地图记录了我们获取数据的法律依据、我们如何处理和使用数据、谁拥有数据以及适用于数据的政策和隐私声明。这将确保我们明显遵守GDPR等数据保护立法。
- 数据只能用于法律允许的目的,如GDPR所定义,并在数据产业地图中获取。
- 服务必须通过确保流程到位来维护和提高数据质量,从而提高我们共享数据资产的价值。这包括尽可能确保用户在捕获点验证数据,并跟踪用户旅程中数据的变化。
- 服务必须避免通过创建自己版本的资产来稀释我们数据资产的价值——我们必须同意主数据源,并确保始终使用这些数据源
- 我们必须以数据所有者的形式对我们的数据资产承担明确的责任
- 我们的数据资产必须得到妥善管理,由数据管理员负责管理
- 管理人员必须拥有管理其负责的数据的权力和机制
- 数据管理员必须确保数据质量,并应制定程序和计划来纠正数据中的错误,并改进产生缺陷信息的流程。
- 应测量数据质量,并使其对所有数据用户可见。
2.数据安全
将保护所有机密、敏感或个人数据,防止未经授权访问或使用
为什么?
国防部有法律和道德义务保护个人、机密或敏感数据的安全,我们必须确保数据的使用和用户遵守这一义务。特别是在个人数据的情况下,我们只能将其用于收集数据的法律目的。发布前对统计数据的访问也必须受到高度控制,因为在发布前可能共享的数据有严格的法律限制,如果不适当地共享,商业敏感数据可能会阻碍国防部有效管理其合同的能力。该部门还拥有大量儿童数据,必须对这些数据加以保护。
怎样
- 我们遵守我们的数据分类政策,以确保我们根据数据存储所包含的数据的敏感性对其进行正确分类。这将包括参考有关数据分类的跨政府标准,但如果需要,应使用DfE特定的敏感性标签。
- 国防部的数据产业地图必须用作这些政策的中央权威存储库。它还必须记录允许我们处理我们持有的数据的法律依据,以及适用于任何后续共享或其他使用数据的限制。
- 我们的数据分类政策阐明了不同分类级别的数据应如何得到保护的明确标准。我们必须确保我们的所有服务在设计时和服务运营期间都遵守这些标准。我们的处理信息政策决定了谁可以访问不同的分类级别。
- 安全性必须应用于数据级别,而不仅仅是应用程序级别,并且必须同样应用于副本、数据库日志和备份。
- 从服务开发开始,就必须在数据元素中设计安全性。必须保护系统、数据和技术不受未经授权的访问和操纵,并且在任何涉及数据资产的发布之前都应测试这种保护
- 必须建立一个强大的监控系统,以确保我们警惕未经授权访问或使用国防部的数据,无论这些数据是驻留在单个应用程序还是公共数据存储中。
- 数据可以以非匿名形式保存,但在呈现给最终用户或从生产安全级别环境中删除之前,必须进行适当的匿名处理。
- 这一原则也与“数据可获取”有关——我们必须确保可访问性和安全性之间的正确平衡
3.数据共享
所有服务都有对服务边界之外的用户有用的数据
为什么?
在单个服务中维护数据,然后根据业务/服务需求进行共享,这有几个很大的优势:
- 加快数据收集、创建、传输和使用
- 在及时准确的数据基础上提高决策的质量和效率
- 通过消除重复和同步成本降低数据管理成本
- 通过重新使用国防部已经掌握的数据,而不是要求用户重新输入密钥,让用户体验更好的旅程
- 通过重复使用加快服务开发
怎样
- 这一原则与“数据是一种资产”和“数据是可获得的”有关,因此所有团队都应该理解数据价值、数据共享和数据可访问性之间的关系。
- 我们的数字服务和遗留应用程序必须在概念上包括一个单一的“共享环境”,在该环境中,数据可以在服务之间轻松消费。
- 我们必须遵守数据所有者同意并存储在数据庄园地图中的数据管理、发现和访问的通用政策、程序和标准。
- 服务必须为其数据设计适当的接口,以允许其他服务和用户使用其数据。
- 各服务部门应假设国防部将需要分析该服务部门创建/收集的数据,并应使用开发的通用模式,以便能够轻松地将数据传递到企业数据和分析平台。
- 应在整个部门统一定义数据,使用所有用户都能理解和使用的定义。应该创建和维护一个中央数据字典,作为我们数据产业地图的一部分。
- 为了使数据能够被发现,我们必须维护一个可搜索的中央元数据存储库,包括数据元素、数据模型和其他元数据,作为我们数据产业地图的一部分。
- 在法律允许的情况下,数据将从外部获得,以推进政府的业务,并支持公民和企业更广泛地使用部门数据。
4.数据可获取
用户可以获得数据以进行活动
为什么?
对数据的广泛访问意味着可以在整个组织中做出高效和有效的决策,及时响应数据请求和提供服务。数据应该可以由各种各样的用户和服务获得。
怎样
- 这一原则与“数据是一种资产”和“数据是共享的”有关,因此所有团队都应该理解数据的价值、数据的共享和数据的可获得性之间的关系
- 这一原则也与“数据是安全的”有关——我们必须确保可获取性和安全性之间的正确平衡
- 所有用户都应该能够轻松获取数据
- 信息的存储、访问和呈现方式必须适用于广泛的用户及其相应的访问方法
- 可获取的数据还必须包括高质量的元数据,以最大限度地减少基于对数据上下文的误解而做出错误决策的风险。其中大部分将在数据庄园地图中捕获,但也应包括流程/用户旅程元数据,以了解数据最初是如何捕获的
- 必须建立良好的治理,以确保那些能够访问数据的人了解他们在《数据保护法》下的责任,以及他们在发布、共享或修改数据方面所能做的限制。数据庄园地图应用于存储这些信息并将其呈现给用户。
- 必须能够快速方便地确定谁有权访问每个数据资产,并在合理的时间内审计任何时间段内的任何人工或计算机访问。
5.数据可分析
我们的数据从根本上支撑了我们评估政策和交付有效性的能力
为什么?
从所有服务部门和更广泛的教育部门获得及时、准确的数据,大大加强了整个教育部制定合理的政策和支出决策的能力。掌握所有系统、服务、功能和流程的这些数据,将使我们能够就公民互动、管理决策以及我们如何利用资源为纳税人提供最佳服务等问题达成共识。随着国防部越来越注重交付,我们越来越需要在整个行业拥有商业智能和管理信息,以及我们自己的财务、商业和人力资源流程。
怎样
- 应从所有系统、服务和应用程序中收集数据,并将其存储在企业数据与分析平台(EDAP)中,以便分析师能够轻松消费和比较整个DfE的数据,而无需创建多个数据分析副本。
- 所有新的系统和服务都将在能够在EDAP中存储数据的基础上进行采购或开发。
- 将提供可视化和分析软件,以允许以适合用户需求的方式消费数据,包括报告、仪表盘、统计分析等
- 这些数据及其后续使用将纳入英国财政部的数据治理政策和流程以及政府统计服务业务守则
- 数据所有者必须定义政策和流程,以确保在数据到达EDAP后发现的数据质量问题可以报告给相关服务和数据管理员,以便在源头上解决。查看我们的数据治理中心
6.数据使用是合乎道德的
我们必须按照有关数据使用的道德共识处理和存储数据
为什么?
我们必须保持公众的信任,使部门和部门能够有效地提供政府服务。因此,我们必须防止收集公众认为超出道德极限的数据,或对他们的私生活造成过度侵扰的数据。
怎样
- 我们必须维持一系列道德小组,以通过关注高效交付来防止过度扩张。
- 我们必须确保在必要时获得处理数据的同意,并保留该同意的记录。这适用于数据的操作和分析使用。
- 我们收集的所有数据属性都应该是履行部门交付或治理职责所必需的。任何超过这一点都代表着道德上的超越。
- 必须注意避免将每个可能是合法收集的数据集链接起来,但当这些数据集组合在一起时,可能会对公民的私生活产生过度侵入性的见解,除非得到明确同意。
- 16 次浏览
【数据架构】何时不使用数据网格
QQ群
视频号
微信
微信公众号
知识星球
数据用户——数据分析师或科学家——的痛苦是真实存在的;他们都在努力及时获得高质量和值得信赖的数据。
--Zhamak Dehghani,数据网格
最近几周,我在这里和这里发表了几篇开玩笑的文章,以讽刺的边缘概述了数据网格方法中固有的陷阱和问题,然后对博弈论和符号学考虑进行了更复杂的尝试。
在这里,我想用冷静和清醒的语言概述一下什么时候不使用数据网格。这并不是因为我反对数据网格,而是因为我发现数据网格是数据架构发展的必要步骤,并希望看到它做得正确。不多不少。
1.你的组织是拜占庭式的
非常庞大和复杂的组织在尝试数据网格转换之前应该仔细思考。这有三个原因:
- 首先,大型IT项目通常成功率不到10%,那么是什么让你认为自己可以做得更好呢?
- 其次,向外推出数据产品的原则要求全面了解其他地方的需求;只有当网格地平线没有超过某个阈值时,这才有效。
- 第三,引入和管理数据网格文化的额外复杂性是在仓库、湖泊和错综复杂的管道结构的传统动物园之上产生的,因此,最终的累积成本很可能远远超过收益。如果您真的想尝试一下数据网格,请选择组织中每个人都知道所有产品和服务的特定分支,然后从那里开始。记住:从小处入手总是明智的。
2.你的组织太小
考虑一下:如果你是一家拥有少数开发人员和数千用户的小型SaaS初创公司,并且你正在经历稳定但非压倒性的线性增长,你就不会选择全球分布式事件驱动的微服务架构。相反,您可以使用简单的计算实例、普通的MEAN或LAMP堆栈,以及一些有用的AWS或Azure服务。你应该把你的力量集中在提供功能上,而不是追随架构潮流,这是正确的:架构模式有其适当的应用范围,初创公司与生俱来的权利是积累技术债务,破坏僵化的恐龙(或尝试死亡)。数据网格也是如此:如果你忙于产品开发,却没有足够的现金或动机投资于数据产品开发,那么就忽略数据网格的诱惑,只需一两个分析数据库就可以了。
3.你没有数据策略
任何成功的数据转型的基础都是一个好的旧数据策略。试图在没有数据策略的情况下引入数据网格——或者,就这一点而言,任何类型的数据管理改革——无异于在没有适当规划的情况下踏上了多式联运的长途旅程。当然,你会有所收获,但可能并没有达到你的预期,很多事情都会出错。同样,对于数据网格,您需要一个愿景、任务、可衡量的数据战略目标,以及一个比数据网格介绍更广泛、更大的路线图。大规模数据管理的一个很好的参考是Pieterhein Strengholt的《大规模数据管理》。
4.贵组织的数据成熟度较低
每一项数据战略的一部分都是对组织的初始数据成熟度评估,其中领导力、价值观、流程、工具、员工的数字能力等都会受到审查。如果你的成熟度只是低到平均水平,或者分布极不均匀,甚至不要尝试像数据网格这样复杂和多维的东西。成熟是有原因的:成长需要时间和努力;成熟不是你能买到的,也不是你能伪造的。
5.你没有计划多年的转型
数据网格不是可以下载、安装和运行的东西。这是一个管理、组织、文化和技术的转变,所有这些都是一项漫长而艰难的努力。如果你认为你可以在紧张的时间表内获得数据网格,甚至提供足够的现金,那你就大错特错了,会大吃一惊。
6.你的组织不是面向领域的
数据网格假设一个组织是沿着业务能力的接缝组织在跨职能团队中的。另一方面,如果您的组织由硬件开发、软件开发、测试、营销、销售等老式单功能团队组成,那么数据网格对您来说几乎不是合适的选择。当然,你可以研究Eric Evans里程碑式的领域驱动设计,重建你的公司,但在那之前,数据网格就像渔船上的迪斯科球一样适合。
7.你不使用研究或分析数据
最初,开发数据网格是为了解决数据仓库和数据湖在近乎实时的跨域共享、发现和使用分析数据方面的缺点,而这正是其最大之处。
数据网格是为大规模分析用例寻找、管理和访问数据的一种新方法。[…][A]分析数据用于优化业务和用户体验。
--Zhamak Dehghani,数据网格
在以研究为导向的组织中,数据网格可以说同样有效,只是数据的“价值”不是以避免的成本和产生的收入来衡量的,而是以消除知识孤岛、防止重复工作和获得更高层次的见解来衡量的。然而,如果你的组织不是以研究为导向的,甚至还没有开始意识到基于数据的决策和数据驱动的商业模式的重要性,那么数据网格对你来说来得太早了。
8.您不会介绍数据产品开发
数据网格建立在领域数据所有权和数据即产品的双重理念之上。这不仅意味着您需要连接到网格的每个域中的数据产品所有者和数据产品开发人员;您还需要完整的数据开发流程,包括项目管理、预算编制、人员配置、实施、自动化、质量控制、影响测量等。这是一场全新的球赛——将软件工程方法论应用于数据工程不仅仅是一场文字游戏;你需要真正的投资,真正的业务转型,以及比DevOps更深入的文化变革。如果你不能或不想去那里,数据网格不适合你。
9.湖泊和仓库将成为网格的公民
不要那样做。数据网格的全部魅力在于,操作数据库、转换管道和低保真度数据的日常噪音都隐藏在每个域中,对组织的其他部分来说是不可见的。最重要的是,数据网格是一种低信任数据环境的转型,在这种环境中,每一种新的数据资产都需要对来源、谱系和质量进行调查,而在这种环境下,数据产品总是有价值、最新、质量有保证,这是一种可验证的值得信赖的数据文化。如果你将数据湖和数据仓库连接到一个数据网格上——当然,这在技术上是可能的——你就会用来自遗留平台的不可靠、不合时宜、误导性和冗余数据的有毒废物污染网格。你不能通过在上面增加额外的复杂性来修复病态的系统——这也应该写在大多数议会的墙上。
10.你不会建立数据门户
[以领域为中心的数据产品]可能会产生不希望的后果:每个领域的工作重复,运营成本增加,以及跨领域的大规模不一致和不兼容。
--Zhamak Dehghani,数据网格
自助数据门户似乎是一个可以稍后添加的附加主题,在某些情况下,将数据门户开发推迟到一个模糊的稍后时间可能会很有吸引力。这是一个严重的错误。自助门户将所有这些联系在一起——发布、可发现性、策略自动化、质量控制、访问管理等。在缺少数据门户的情况下,您在哪里发布新发布的数据产品?您将在哪里搜索数据产品?在哪里可以跟踪、记录和审计访问、使用和潜在滥用?您如何确保遵守组织范围内的数据策略?不,中央数据门户是一个必要条件。与一些评论家相反,数据网格并不是一盒巧克力,你可以在其中挑选任何你想要的;相反,数据网格是一个完整的社会技术元架构,每个部分都支持其他部分。错过了一个,一切都倒下了。
- 8 次浏览
【数据架构】可组合数据和分析导论
QQ群
视频号
微信
微信公众号
知识星球
首先是运营数据分析。然后是人工智能驱动的大数据分析。迎接数据分析的下一次迭代:可组合分析。
在过去的10年里,我们在数据分析的业务采用方面取得了长足的进步。这不再是使用数据来推动业务决策,而是让数据变得更好、更可用、更相关。它还涉及将分析任务从数据团队转移到业务数据消费者手中。(或者,无论如何,让它们尽可能接近。)我们可以称之为跨部门、全组织的数据分析民主化的一个解决方案是可组合数据分析。
什么是可组合分析?
可组合分析基于两个方面:灵活性和可重用性。从本质上讲,这种范式都是关于使用数据、分析、人工智能和交付组件,这些组件协同工作形成一个解决方案——这些组件使用低代码和无代码工具进行连接。
换言之,将数据分析系统的各个部分视为用户(通常是分析师)可以选择并连接以形成自己的定制工具的组件。因为这些组件可以以不同的方式连接并多次重复使用,所以它们为数据分析过程提供了新的灵活性。
有趣的是,可组合分析有时也被称为“模块化”分析——与传统分析不同,它们可以一块一块地重复使用和重新组装。
是否需要可组合分析?
当企业努力扩展分析时,他们遇到了许多相同的生产瓶颈。但可组合分析可以做嵌入式数据分析无法做的事情。
例如,假设您的公司有一个集中的数据解决方案,组织中的任何人都可以查询该解决方案以获得业务问题的答案。很好。然而,每个团队可能有不同的问题,并需要自己的特定数据子集。这可能会让数据专业人员团队忙碌起来,并导致周转时间过长。但有了可组合的数据分析,每个团队都可以使用无代码应用程序生成器(例如)连接到数据库并运行自己的查询,而无需专门的数据或编程知识。
各种模型和分析是可组合分析中的可重用组件;这增加了可组合分析的灵活性。这也使企业能够在提供灵活性和定制解决方案的同时,扩大其分析范围。
然而,你不能简单地动动手指,期望可组合的分析与现有的基础设施集成。和其他任何事情一样,它需要提前计划。
可组合分析的基础
可组合分析需要相应的灵活和可扩展的基础,这并不奇怪。简而言之,这些基础包括:
数据编制(Data Fabric )
与可组合的数据分析一样,数据结构不是一个单一的工具或设备。相反,这是一种将数据的管理和存储与其可用性“分离”的方式。您可以在我们的博客其他地方阅读更多关于数据结构的信息;只要说数据结构就足够了,无论数据在组织中的位置如何,都可以使用数据。
自动化
如果没有数据处理和交付的自动化等,使数据分析真正实现自助服务是不可能的。
打包业务功能(Packaged Business Capabilities )
PBC构成了可组合的“部分”,用户可以连接这些部分来制作自己的分析工具。Gartner将PBC定义为“代表定义良好的业务能力的软件组件,业务用户在功能上可以识别。从技术上讲,PBC是数据模式和一组服务、API和事件通道的有限集合。”。“这些块的设计必须确保它们既独立(即完全能够执行其功能),又可以通过低代码或无代码工具进行连接。
架构
可组合分析需要可组合的架构:能够支持互连和可重用元素的体系结构。这意味着存储、网络、数据和计算都必须具有灵活性和可扩展性。
数据分析的发展是可组合的
通常,业务发展是由技术发展驱动的。可组合分析使我们能够采取自上而下的方法来解决业务问题:我们从需要了解的内容开始,然后将其连接到可组合分析架构中,使其实现。这在我们提供和消费分析的方式上有很大的潜力;观察它如何推动更大的业务转型将是非常有趣的。
- 10 次浏览
【数据架构】定义主题领域
QQ群
视频号
微信
微信公众号
知识星球
Jules Keeper要求Erin Overview提供当今IT系统管理的关键主题领域的列表。
为了确保她理解,Erin问Jules他所说的“主题领域”是什么意思——Jules说——不同的数据主题。
对Erin来说,“主题领域”听起来像是一个“数据域”(data domain),Jules对此表示赞同。Data Domain可能是一个更正式的名称,但“域”(domain)一词在不同的上下文中使用,这可能会让熟悉数据驱动企业概念的人感到困惑。例如,它被用于术语“治理领域”,这是数据、安全或隐私等治理的重点领域。他倾向于使用主题领域(subject area)这个词,因为它似乎更容易让人们记住。
Erin接着问他们在定义主题领域时应该如何细化——例如,“Address”是一个主题领域,但非常细化。或者,他们可以从一些更广泛的主题领域(比如大约10个)开始,这将使其他团队更容易参与进来,并帮助寻找企业主。
Jules同意他们最终需要非常精细的主题领域,但要开始,更广泛、面向业务的主题领域更有用。他还建议,与其专注于整个业务,不如强调受个性化医疗影响最大的业务领域,如患者、治疗和销售。
关于企业信息模型的思考
Peter提醒Erin,他们几年前开发了一个企业信息模型(EIM),这可能是一个有用的输入。
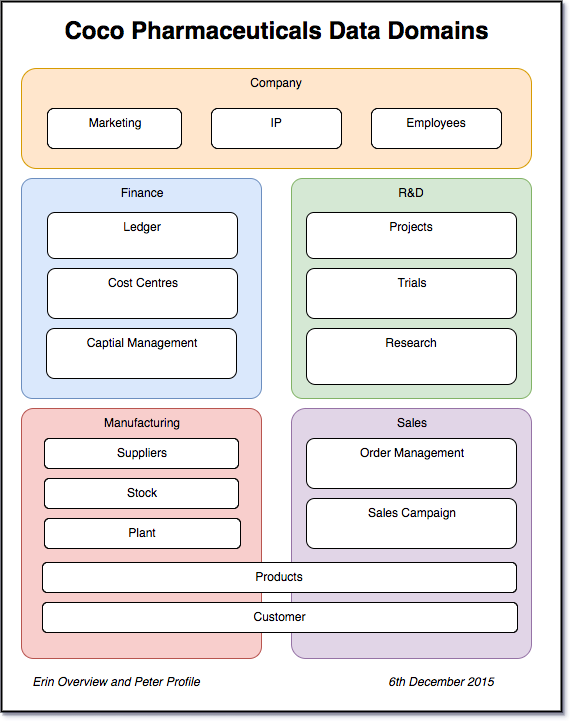
Figure 1: Data domains from Coco Pharmaceutical’s existing EIM
EIM很好地反映了当今的业务,因为Tessa Tube领导的产品开发和研究工作中使用的数据、销售流程、制造和财务之间存在明显的分离。
他们将该模型与Gary Geeke作为IT基础设施治理领导者( IT Infrastructure governance leader)的新角色创建的系统目录(catalog of systems)进行了比较。
同样,在业务的每一部分所拥有的系统和主题领域之间有一个令人惊讶的直接映射。Erin总结道,除了制造业的销售和分销部门共同使用产品目录和客户列表之外,目前几乎没有数据共享。财务团队与业务的其他部分重叠最大,因为收入和费用都流向了他们。
Erin猜测,个性化药物很可能会增加研发团队和医院临床医生之间的数据共享。她不太确定销售和生产是否受到影响。
制造视图
Erin采访了制造业的Stew Faster。他一直在考虑生产线的现代化,为他们的新药品生产线做好准备。他说,他们未来的工厂将使用更多的数据和自动化,因为他们需要能够生产更小的批量生产,甚至可能生产一些药物的单个患者剂量。
他今天说,一旦一种新药获得批准,他们就会有效地从研究团队那里获得配方,并与采购团队合作寻找供应商。然后,他设计了制造和质量控制流程。每种药物都是大批量生产的,一小部分被拉到一边进行质量测试,一旦获得批准,剩下的就打包分发给客户(通常是医院)。
展望未来,他认为他们需要支持更广泛的制成品清单,在短的交付周期内首先实施制造流程,然后根据需求生产小批量产品。分销过程需要进行大的改革,因为由此产生的药物需要在正确的时间送到正确的医院为正确的患者提供正确的临床医生。这与定期向每家医院发送固定订单大不相同。
销售视图
Erin随后与销售部的Harry Hopeful进行了交谈。Harry是一位经验丰富的销售人员,他认识Coco Pharmaceuticals主要业务所在的研究医院的每个人。Erin询问销售流程将如何改变。他说,今天他与顾问们一起工作,并说服他们相信可可制药公司提供的药物的价值。哈里随后与顾问们合作,向采购部门施压,要求其批准所需的产品。采购部随后订购了一批批药物,因为顾问们用完了库存。哈利收到的每一笔订单都会得到报酬。
在与Erin交谈之前,Harry曾预计大部分相同的销售过程将一如既往。然而,他意识到,根据治疗需求,订单需要小批量到货。Coco制药公司现在需要开始与医院的采购团队合作,改变订单的审批流程,因为按照标准采购流程,订单不能延迟。与此同时,采购团队将需要一些控制成本的角色,因此他认为,随着时间的推移,他们将共同监控使用情况,他将更多地参与其中。
结论
Erin从这些对话中了解到,患者、临床医生和治疗的概念需要在主题领域变得更加突出,这与临床测量、症状和结果有关。临床团队将重点放在这些方面,以确定患者的治疗方法。规定的处理方式可配置所需的产品,从而推动生产。财务部为产品订单开具发票,并在供应商交付原材料时向其付款。但随着制造业以患者需求为基础,库存管理变得更加关键。
Erin感到惊讶的是,她将重点转移到他们业务转型的需求上,对主题领域模式产生了如此大的影响。她最初的EIM与企业的组织结构相匹配。它对现状没有任何挑战。新的主题领域模型为业务划出了现在需要关注的最重要的主题领域。
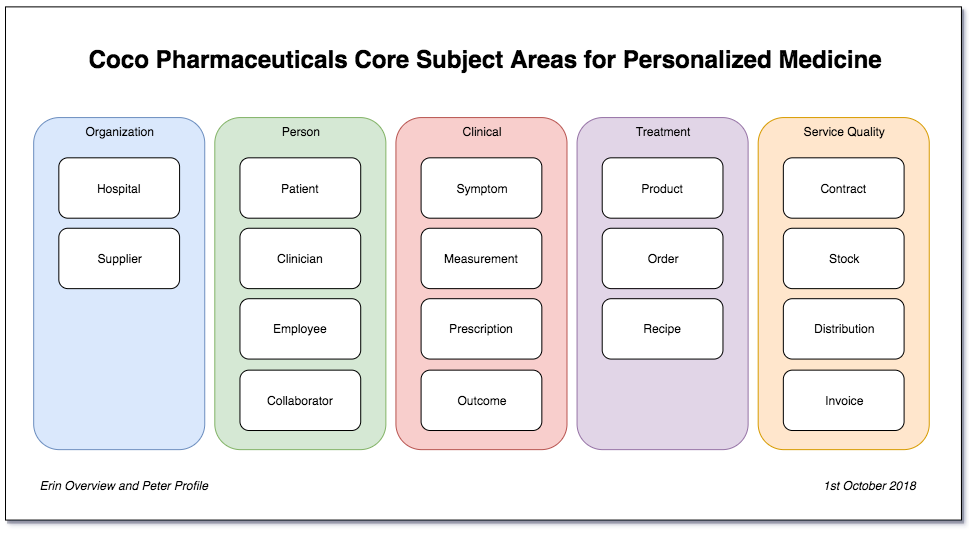
Figure 2: Coco Pharmaceutical’s new candidate subject area model
- 6 次浏览
【数据架构】实体关系模型
实体-关系模型(或ER模型)描述特定知识领域中相关的事物。基本的ER模型由实体类型(对感兴趣的事物进行分类)和指定实体之间可能存在的关系(那些实体类型的实例)组成。
在软件工程中,为了执行业务流程,ER模型通常用于表示业务需要记住的内容。因此,ER模型变成了一个抽象的数据模型,它定义了一个可以在数据库(通常是关系数据库)中实现的数据或信息结构。
实体-关系建模是由Peter Chen开发的数据库和设计,并在1976年发表了一篇论文。然而,这个想法的变体之前就已经存在了。一些ER模型显示由一般化-专门化关系连接的超实体和子类型实体,[3]和ER模型也可用于特定领域本体的规范

使用Chen符号的MMORPG的实体关系图。
介绍
E-R模型通常是系统分析的结果,用于定义和描述业务领域中哪些流程是重要的。它没有定义业务流程;它只以图形形式表示业务数据模式。它通常以图形形式绘制为方框(实体),这些方框由表示实体之间的关联和依赖关系的线(关系)连接。ER模型也可以用口头形式表达,例如:一栋建筑可以分为零个或多个公寓,但一个公寓只能位于一栋建筑内。
实体不仅可以由关系来描述,还可以由附加的属性(属性)来描述,这些属性包括称为“主键”的标识符。为表示属性以及实体和关系而创建的图可以称为实体-属性-关系图,而不是实体-关系模型。
ER模型通常作为数据库实现。在简单关系数据库实现中,表的每一行表示实体类型的一个实例,表中的每个字段表示属性类型。在关系数据库中,实体之间的关系是通过将一个实体的主键作为指针或“外键”存储在另一个实体的表中来实现的
传统上,ER/数据模型是在两个或三个抽象级别上构建的。注意,下面的概念-逻辑-物理层次结构用于其他类型的规范,并且与软件工程的三种模式方法不同。
概念数据模型
这是最高级别的ER模型,因为它包含了最少的粒度细节,但是建立了模型集中所包含内容的总体范围。概念ER模型通常定义了组织通常使用的主引用数据实体。开发企业范围的概念ER模型对于支持组织的数据架构文档化非常有用。
一个概念性的ER模型可以用作一个或多个逻辑数据模型的基础(参见下面)。概念ER模型的目的是在一组逻辑ER模型之间建立主数据实体的结构元数据共性。概念数据模型可用于在ER模型之间形成共性关系,作为数据模型集成的基础。
逻辑数据模型
逻辑ER模型不需要概念ER模型,特别是当逻辑ER模型的范围仅包括开发不同的信息系统时。逻辑ER模型比概念ER模型包含更多的细节。除了主数据实体之外,现在还定义了操作和事务数据实体。开发每个数据实体的详细信息,并建立这些数据实体之间的关系。然而,逻辑ER模型是独立于特定的数据库管理系统开发的,它可以在该系统中实现。
物理数据模型
可以从每个逻辑ER模型开发一个或多个物理ER模型。物理ER模型通常被开发为实例化为数据库。因此,每个物理ER模型必须包含足够的细节来生成数据库,而且每个物理ER模型都依赖于技术,因为每个数据库管理系统有所不同。
物理模型通常在数据库管理系统的结构元数据中实例化,如关系数据库对象(如数据库表)、数据库索引(如惟一键索引)和数据库约束(如外键约束或共性约束)。ER模型通常还用于设计对关系数据库对象的修改和维护数据库的结构元数据。
信息系统设计的第一阶段在需求分析期间使用这些模型来描述信息需求或将存储在数据库中的信息类型。数据建模技术可以用来描述某个兴趣领域的任何本体(即使用术语及其关系的概述和分类)。在设计基于数据库的信息系统时,概念数据模型在后期(通常称为逻辑设计)被映射到逻辑数据模型,例如关系模型;这反过来又在物理设计期间映射到物理模型。注意,有时这两个阶段都被称为“物理设计”。
实体关系模型

两个相关的实体

具有属性的实体

与属性的关系

主键
一个实体可以被定义为一个能够被唯一识别的独立存在的事物。实体是对领域复杂性的抽象。当我们谈到一个实体时,我们通常指的是现实世界的某些方面,这些方面与现实世界的其他方面是不同的
实体是物理上或逻辑上存在的事物。实体可以是一个物理对象,如房子或汽车(它们以物理形式存在),一个事件,如房屋销售或汽车服务,或一个概念,如客户交易或订单(它们以概念的形式逻辑地存在)。虽然“实体”是最常用的一个术语,但在陈之后,我们应该真正区分实体和实体类型。实体类型是一个类别。严格地说,实体是给定实体类型的实例。实体类型通常有许多实例。因为术语实体类型有点麻烦,大多数人倾向于使用术语实体作为该术语的同义词
实体可以被认为是名词。例如:一台电脑,一个雇员,一首歌,一个数学定理,等等。
关系捕获实体之间的关系。关系可以被认为是动词,连接两个或多个名词。例如:a拥有公司和电脑之间的关系,a管理员工和部门之间的关系,a表演艺术家和一首歌之间的关系,a证明数学家和一个猜想之间的关系,等等。
上面描述的模型的语言方面在模仿自然语言构造的声明式数据库查询语言ERROL中得到了利用。ERROL的语义和实现基于重新构造的关系代数(RRA), RRA是一种适应实体-关系模型并捕捉其语言方面的关系代数。
实体和关系都可以有属性。示例:雇员实体可能具有社会保险号(SSN)属性,而已证明的关系可能具有日期属性。
每个实体(除非它是弱实体)必须有一组最小的惟一标识属性,这称为实体的主键。
实体关系图不显示单个实体或单个关系实例。相反,它们显示实体集(同一实体类型的所有实体)和关系集(同一关系类型的所有关系)。例如:一首歌是一个实体;数据库中所有歌曲的集合是一个实体集;孩子和午餐之间被吃掉的关系是单一的关系;数据库中所有这些儿童-午餐关系的集合就是一个关系集合。换句话说,一个关系集合对应于数学上的一个关系,而一个关系对应于关系中的一个成员。
还可以指定关系集上的某些基数约束。
映射自然语言
陈提出了将自然语言描述映射到ER图的“经验法则”:Peter Chen的“英语、汉语和ER图”。
| English grammar structure | ER structure |
|---|---|
| Common noun | Entity type |
| Proper noun | Entity |
| Transitive verb | Relationship type |
| Intransitive verb | Attribute type |
| Adjective | Attribute for entity |
| Adverb | Attribute for relationship |
物理视图显示数据的实际存储方式。
关系、角色和基数
在陈的原始论文中,他给出了一个关系及其作用的例子。他将一段关系描述为“婚姻”,并将其分为“丈夫”和“妻子”两个角色。
一个人在婚姻(关系)中扮演丈夫,另一个人在同一婚姻中扮演妻子。这些词是名词。这并不奇怪;给东西命名需要一个名词。
陈的术语也被用于早期的思想。一些图表的线条、箭头和鱼尾纹更多的是源于早期的巴赫曼图表,而不是陈的关系图表。
陈模型的另一个常见扩展是将关系和角色“命名”为动词或短语。
角色的命名
用is的所有者和is所属的短语来命名角色也变得很流行。这里正确的名词是owner和possession。因此,人扮演所有者的角色,汽车扮演占有的角色,而不是人扮演所有者的角色,等等。
当从语义模型生成物理实现时,名词的使用有直接的好处。当一个人与car有两种关系时,就有可能产生像owner_person和driver_person这样的名字,这是有意义的
基数
对原始规范的修改是有益的。陈描述了四处查看的基数。顺便说一句,在Oracle Designer中使用的Barker-Ellis符号使用同侧表示最小基数(类似于可选性)和角色,但是查找最大基数(乌鸦脚)。(需要澄清)
在Merise,[6] Elmasri & Navathe[7]和其他[8]中,对于角色以及最小和最大基数都有对同侧的偏好。最近的研究人员(Feinerer,[9] Dullea等人,[10])已经表明,当应用于n元关系大于2时,这是更连贯的。
在Dullea等人看来,“在UML中使用的‘查看’表示法并不能有效地表示施加在关系上的参与约束的语义,这些关系的程度高于二进制。”
Feinerer说:“如果我们像使用UML关联那样在查找语义下操作,就会出现问题。”Hartmann[11]调查了这种情况,并展示了不同的转换是如何以及为什么会失败。”(虽然上面提到的“简化”是虚假的,因为两个图3.4和3.5实际上是相同的),而且“正如我们在接下来的几页中看到的,这种交叉解释引入了一些困难,这些困难阻止了简单机制从二元关联扩展到n元关联。”
陈的实体-关系建模表示法使用矩形表示实体集,用菱形表示适合于一级对象的关系:它们可以有自己的属性和关系。如果一个实体集参与了一个关系集,它们将被连接到一条线上。
属性被绘制为椭圆,并与一条线连接到一个实体或关系集。
基数约束表示如下:
- 双线表示参与约束、总体或满射:实体集合中的所有实体必须参与关系集合中的至少一个关系;
- 从实体集到关系集的箭头表示一个关键约束,即注入性:实体集的每个实体最多可以参与关系集中的一个关系;
- 粗线表示两者,即双射性:实体集合中的每个实体只涉及一个关系。
- 属性的带下划线名称表示它是键:与此属性相关的两个不同实体或关系总是具有此属性的不同值。
- 属性经常被省略,因为它们会使图表混乱;其他图表技术通常在为实体集绘制的矩形中列出实体属性。
相关图表的约定技术:
- 巴赫曼符号
- 巴克的符号
- 表达
- IDEF1X
- 鱼尾纹符号(也叫马丁符号)
- (min, max)- 1974年Jean-Raymond Abrial的记谱法
- UML类图
- Merise
- Object-role建模
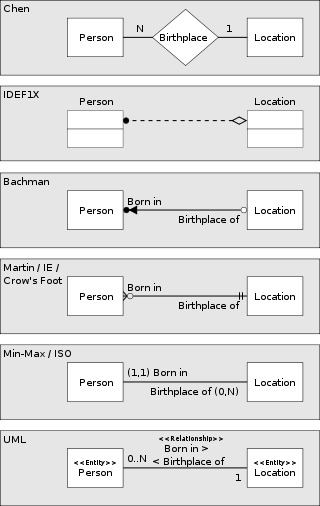
将同一关系表示为多个关系的各种方法。在每种情况下,图表都显示了一个人和一个出生地之间的关系:每个人都必须在一个地点出生,而且只能在一个地点出生,但是每个地点可能没有或有更多的人出生在那里。

两个相关的实体显示使用鱼尾纹符号。在这个例子中,歌手和歌曲之间显示了一个可选的关系;最接近歌曲实体的符号代表“0、1或多个”,而一首歌有“一个且只有一个”艺术家。因此,前者被理解为艺术家可以表演“零首,一首,或多首”歌曲。
乌鸦脚符号
鱼尾纹符号,其起源可追溯到戈登埃佛勒斯特(1976)的一篇文章,[12]用于巴克的符号,结构化系统分析与设计方法(SSADM)和信息技术工程。鱼尾纹图将实体表示为框,将关系表示为框之间的线。这些线两端的不同形状表示关系的相对基数。
在咨询公司CACI中使用了鱼尾纹符号。CACI的许多顾问(包括Richard Barker)后来都搬到了Oracle英国,在那里他们开发了Oracle CASE工具的早期版本,并将这种表示法介绍给更广泛的用户。
使用这种表示法,关系不能有属性。在必要时,关系提升为实体的:例如,如果需要捕捉艺术家表演歌曲,介绍了一个新的实体“性能”(属性反映了时间和地点),和艺术家,歌曲的关系成为一个间接的通过性能(artist-performs-performance performance-features-song)的关系。
三个符号用来表示基数:
- 这个环代表“0”
- 破折号代表“1”
- 鱼尾纹代表“许多”或“无限”
这些符号成对使用,表示一个实体在关系中可能具有的四种基数类型。符号的内部分量表示最小值,外部分量表示最大值。
- 环和破折号→最小零,最大一(可选)
- 破折号与破折号→最小一,最大一(强制)
- 环和鱼尾纹→最小零,最大多(可选)
- 破折号和鱼尾纹→最少一项,最多多项(强制)
模型可用性问题
在使用建模的数据库时,用户可能会遇到两个众所周知的问题,其中返回的结果与查询作者假定的结果不同。
第一个是“粉丝陷阱”。它与一个(主)表一起出现,该表以一对多的关系链接到多个表。这个问题的名称来自于模型在实体关系图中绘制时的样子:从主表“展开”的链接表。这种类型的模型与星型模式类似,星型模式是数据仓库中使用的一种模型。当试图使用主表上的标准SQL计算聚合的总和时,会出现意外(和不正确)的结果。解决方案是调整模型或SQL。此问题主要发生在决策支持系统的数据库中,查询此类系统的软件有时包括处理此问题的特定方法。
第二个问题是“鸿沟陷阱”。当模型表明实体类型之间存在某种关系,但某些实体之间不存在路径时,就会出现鸿沟陷阱。例如,一个建筑物有一个或多个房间,这些房间可以容纳0或更多的计算机。人们希望能够查询该模型以查看大楼中的所有计算机。然而,目前没有分配到房间的电脑(因为它们正在修理或在其他地方)不在列表中。建筑和计算机之间的另一种关系是需要捕获建筑中所有的计算机。最后一个建模问题是由于未能在模型中捕获现实世界中存在的所有关系。详见实体-关系建模2。
实体关系和语义建模
语义模型
语义模型是概念的模型,有时被称为“平台无关模型”。这是一个内涵模式。自Carnap以来,最晚的是众所周知的:[13]
“…概念的全部意义由概念的内涵和外延两个方面构成。第一部分包括概念作为一个整体嵌入到概念的世界中,即所有与其他概念的关系的总和。第二部分确立了概念的指称意义,即它在现实世界或可能世界中的对应物。
扩展模型
扩展模型是映射到特定方法或技术元素的模型,因此是“特定于平台的模型”。UML规范明确地声明类模型中的关联是扩展的,通过考虑规范提供的比任何先前候选的“语义建模语言”提供的更多的“装饰”,这实际上是不言而喻的。UML作为数据建模符号,第2部分"
实体关系的起源
ER建模之父Peter Chen在他的开创性论文中说:
实体-关系模型采用更自然的观点,认为现实世界由实体和关系组成。它整合了一些关于现实世界的重要语义信息。”[1]
在他1976年的原始文章中,陈明确对比了实体关系图和记录建模技术:
数据结构图是记录组织的表示,而不是实体和关系的精确表示。
其他几位作者也支持陈的项目:[14][15][16][17][18]
哲学对齐
从古希腊哲学家苏格拉底、柏拉图和亚里士多德(公元前428年)到现代认识论、符号学和逻辑学的皮尔斯、弗雷格和罗素,陈都符合他们的哲学和理论传统。
柏拉图本人将知识与对不变形式的理解(根据苏格拉底的说法,这些形式大致上是许多类型的事物和属性的原型或抽象表示)及其相互之间的关系联系起来。
限制
- ER假设可以在关系数据库中方便地表示信息内容。它们只描述了此信息的关系结构。
- 它们不适用于信息不能以关系形式(需要引用)表示的系统,例如半结构化数据。
- 对于许多系统来说,对所包含的信息进行可能的更改是非常重要的,足以保证明确的规范。
- 一些(谁?作者扩展了ER建模,用结构来表示变化,这种方法得到了最初作者的支持;[19]是锚建模的一个例子。另一种方法是使用流程建模技术分别对更改进行建模。其他技术可以用于系统的其他方面。例如,ER模型大致对应于UML提供的14种不同建模技术中的1种。
- 即使在原则上合适的地方,ER建模也很少作为单独的活动使用。原因之一是现在有大量的工具可以直接支持关系数据库管理系统上的图表绘制和其他设计支持。这些工具可以很容易地从现有数据库中提取与ER关系图非常接近的数据库关系图,并且它们提供了关于此类关系图中包含的信息的可选视图。
- 在一项调查中,Brodie和Liu[20]在十个财富100强公司的样本中找不到一个实体-关系建模的实例。Badia和Lemire[21]将这种缺乏使用归咎于缺乏指导,但也归咎于缺乏好处,比如缺乏对数据集成的支持。
- 增强实体-关系模型(EER建模)引入了一些与面向对象设计密切相关的概念,而不是ER建模,比如is-a关系。
- 为了对时态数据库建模,已经考虑了许多ER扩展。类似地,ER模型被发现不适合多维数据库(用于OLAP应用程序);在这一领域还没有出现主流的概念模型,尽管它们通常围绕OLAP cube(在该领域内也称为数据立方体)的概念
另请参阅
- Associative entity
- Concept map
- Database design
- Data structure diagram
- Enhanced entity–relationship model
- Enterprise architecture framework
- Value range structure diagrams
- Comparison of data modeling tools
- Ontology
- Object-role modeling
- Three schema approach
- Structured-Entity-Relationship-Model
- Schema-agnostic Databases
原文:https://en.wikipedia.org/wiki/Entity%E2%80%93relationship_model
本文:
讨论:请加入知识星球【首席架构圈】或者飞聊小组【首席架构师智库】
- 116 次浏览
【数据架构】您想了解的关于现代数据架构原理和优点的所有信息
QQ群
视频号
微信
微信公众号
知识星球
数据是任何机构的核心。它是做出知识渊博、可支持的决策的关键。这些数据的组织方式称为数据架构。
数据架构是一组模型、规则和策略,用于定义如何在数据库中捕获、处理和存储数据。
它还定义了哪些用户可以访问哪些数据以及如何使用这些数据。
如今,许多使用传统数据架构的组织正在重新思考其数据库架构。
这是因为现有的数据架构无法支持当今公司所需的速度、灵活性和容量。
现代数据架构(MDA)解决了这些业务需求,从而使组织能够跨各种存储技术快速查找和统一数据。减少时间、提高灵活性和敏捷性是MDA的主要目标。
现代数据架构通常取决于实现目标。通常,现代数据架构具有以下特征:
- 数据可以从内部系统、基于云的系统以及合作伙伴和第三方提供的任何外部数据中生成。
- 除了批量加载之外,还通过实时数据源收集数据。
- 为数据集市等传统平台以及绘图和映射等专业数据库提供分析。
- 支持从客户到数据科学家的所有类型的用户。
现代数据架构原理
- 将数据作为共享资产查看
- 为用户使用数据提供正确的接口
- 确保安全和访问控制
- 维护通用词汇
- 整理数据
- 消除数据拷贝和移动
现代数据架构的优势
- 采取集中的集成方法
- 从混合环境中删除延迟
- 在你的湖中创建人工智能和分析就绪的数据
- 自动化数据交付和数据仓库和集市的创建
现代数据架构原理
将数据作为共享资产查看
为了使数据在组织中顺畅流动,数据应被视为共享资产。
利益相关者不允许存在跨部门的竖井,而是对公司有一个完整的了解。
这意味着决策者能够透明地了解客户的见解,并能够关联包括制造和物流在内的所有业务职能部门的数据。这导致了效率的提高。
为用户使用数据提供正确的接口
仅将数据存储在一个地方并不能使数据驱动的组织顺利运作。用户应该能够访问数据以从共享数据资产中获益。
需要为用户提供使用数据的接口。
这些界面因用户而异,这取决于用户在生态系统中的位置以及他们需要访问的数据,以高效地完成工作。
确保安全和访问控制
随着大数据和Hadoop为我们提供了一个统一的平台,有必要对原始数据制定和实施数据和访问控制策略。
Apache Sentry等安全项目使这一点变得可行。为此,我们应该寻找能够让我们在不影响对系统控制的情况下构建安全解决方案的技术。
维护通用词汇
在数据中心的帮助下,组织现在能够将数据用作共享资产,并允许同一数据的多个用户访问。
然而,至关重要的是要确保所有访问数据的用户都使用通用词汇表进行分析和理解。
无论用户如何使用数据,产品目录、提供商层次结构、会计日历维度和KPI定义都需要统一。
这对于维护整个组织中数据的完整性至关重要。
整理数据
数据管理包括清理原始数据,建立各种数据集之间的适当关系,以及管理关键维度和度量。
但如果没有适当的管理,用户可能会发现很难在庞大的数据中找到他们需要的数据。这降低了底层数据的感知和实现价值。
通过对数据进行适当的管理和建模,可以充分发挥系统的潜力。
消除数据拷贝和移动
随着数据移动的每一个实例,成本、准确性和时间都会受到影响。最好尽可能减少数据的移动。
大数据和Hadoop的价值主张包括用于并行处理数据集的多结构、多工作负载环境。Hadoop随着数据量的增加而线性扩展。
现代数据架构的优势
过去主导IT基础架构的数据架构不再能够承受当今企业的巨大工作负载。现代建筑有以下各种优点:
采取集中的集成方法
来自大型组织的数据管理起来很复杂。他们经常将来自不同来源的数据输入不同的仓库和数据湖。
整合这些数据可能是一项艰巨的任务。通过集中查看数据,用户可以在整个组织中配置和管理数据。
从混合环境中去除延迟
根据研究,运行数据的价值在大约8小时后下降了大约50%。将数据从一个地方复制到另一个地方会增加过程中的延迟。
库存库存、客户服务改进或整体组织效率等功能的决策需要实时处理。
MDA支持超连接企业。这使得所有能够在尽可能短的时间内访问数据的用户都可以在整个企业中使用数据。
在你的湖中创建人工智能和分析就绪的数据
早期的数据湖计划未能达到最初预期的分析见解。
虽然在湖中收集数据是一项简单的任务,但数据处理是一项具有挑战性的任务。
处理持续更新、合并数据和创建可用于分析的结构是一项艰巨的任务。
MDA不仅将数据放置在它应该放置的位置,而且还根据需要自动创建和更新数据。
有了这一点,数据科学家和分析师可以花更多的时间分析数据,而不是准备数据。
自动化数据交付和数据仓库和集市的创建
一旦数据湖中的数据接收和分析创建实现自动化,下一步将是自动化特定功能仓库和集市的创建。
一旦数据仓库自动化到位,就可以根据需要创建和更新数据集市。这提高了灵活性,降低了项目风险。
成功实现现代数据架构的过程是漫长而复杂的。然而,有了原则和框架,这肯定是可以实现的。
数据无疑是计算的未来,也是企业运作的一种生活方式。因此,至关重要的是,我们要事先掌握数据架构原则,以便有效地管理所有数据。
- 11 次浏览
【数据架构】数据和人工智能超市架构
QQ群
视频号
微信
微信公众号
知识星球
去年,我们发表了一篇论文,介绍了数据和人工智能超市架构
使用这种方法,您可以提升您的数据和人工智能战略。

从我们的论文中摘录的文本:
我们在这个新框架中的目的是增加数据超市,这是一个将洞察生成过程生成的数据产品商业化的地方,让其他消费者用它们换取货币价值[33]。一个典型的洞察生成过程由多学科数据科学家团队开发,将原始数据转换为洞察和数据产品。我们提出的贡献是将数据超市定义为大数据货币化战略的一个关键要素,在该战略中,由大数据科学家团队创建的数据产品将以服务或产品的形式作为数据产品运送给内部或外部消费者。西班牙电信的Smart Steps是构建数据产品并将其提供给外部公司的一个成功例子。Smart Steps是一种洞察解决方案,它使用匿名和聚合的移动网络数据来提供有用的洞察[33]。因此,数据超市的主要目标是为公司创造新的收入,并使组织能够增加对新市场的渗透,这是以前从未探索过的。将数据组织到一个单独的存储库中并创建数据产品目录对最终业务用户来说也是一个好处。数据将通过适当的数据定义民主化给商业用户[34]。

在图6中,显示了构建数据产品和在数据超市中销售的生命周期。如前所述,数据超市的概念是基于普通超市。在日常生活中,人们可以在一个地方购买多种产品,这些产品都可以在超市买到。同样的概念可以转换为数据。利用同样的想法,建议数据将来自不同的数据供应商(源系统),摄入/移动到原始区域(着陆区域),在那里原始数据被组织在目录(原始区域)中。下一步是根据内部和外部业务用户的需求,将原始数据转换为不同的数据产品。就像去食品超市的体验一样,在那里所有的产品都被有组织地收集和排列。
数据超市的好处是将最佳实践应用于数据收集、数据转换、数据存储和数据消费等活动的协同作用。处理数据的所有复杂性都对最终业务用户隐藏起来,并在数据超市中呈现,以获得更好的用户体验。演示或数据超市商店将为内部或外部用户处理数据访问、数据安全和数据商业化(免费或付费)的重要任务。数据超市是负责销售数据产品的经纪人,并允许以市场为导向的公司从公司数据资产中可用的数据产品中获利。未来的数据超市/数据市场可能成为现代MO组织的重要关键资产。
这篇论文也于2020年5月21日在英国伦敦举行的ICAAI(国际自动化和人工智能会议)上发表。
Paper link:
https://doi.org/10.9781/ijimai.2019.06.003
- 15 次浏览
【数据架构】数据架构特征与原理
QQ群
视频号
微信
微信公众号
知识星球
目录
- 数据架构师的职责
- 什么是数据架构
- 数据架构组件
- 数据架构构特征
- 数据架构原则
在信息技术中,数据架构由模型、策略、规则或标准组成,用于管理收集的数据,以及数据在数据系统和组织中的存储、排列、集成和使用方式。数据通常是构成企业架构或解决方案架构支柱的几个架构域之一。
数据架构师的职责
与设计住宅或建筑的传统架构师一样,数据架构师创建的数据环境蓝图符合组织的短期和长期目标及其独特的文化和上下文要求。
数据架构师通常负责定义目标状态,在开发过程中进行调整,然后跟进,以确保按照原始蓝图的精神进行增强。
在定义目标状态的过程中,数据架构将主题分解为原子级别,然后将其重新构建为所需的形式。数据架构师通过经历3个传统架构过程来分解主题:
- 概念–代表所有业务实体。
- 逻辑–表示实体之间的关联逻辑。
- 物理——实现特定类型功能的数据机制。
什么是数据架构
数据架构定义了组织用于管理数据的一组标准产品和工具。但它远不止于此。数据架构定义了捕获、转换和向业务用户交付可用数据的过程。最重要的是,它确定了将使用这些数据的人及其独特的需求。一个好的数据架构从右到左流动:从数据消费者到数据源。
数据架构应该为其所有数据系统设置数据标准,作为这些数据系统之间最终交互的愿景或模型。例如,数据集成应该依赖于数据架构标准,因为数据集成需要两个或多个数据系统之间的数据交互。数据架构描述了企业及其计算机应用软件所使用的数据结构。数据架构处理存储中的数据、使用中的数据和运动中的数据;对数据存储、数据组和数据项的描述;以及将这些数据伪像映射到数据质量、应用程序、位置等。它为数据处理操作提供了标准,以便能够设计数据流并控制系统中的数据流。
这是一个标准化组织如何收集、存储、转换、分发和使用数据的过程。我们的目标是在需要的时候向需要的人提供相关数据,并帮助他们理解这些数据。
数据架构描述了组织的逻辑和物理数据资产以及数据管理资源的结构。数据架构的目标是将业务需求转化为数据和系统需求,并管理数据及其在企业中的流动。
数据架构组件
数据架构可以综合为三个整体组件:
- 数据架构结果。这些是通常被称为数据架构工件的模型、定义和数据流。
- 数据架构活动。这些是数据架构构意图的形式、部署和实现。
- 数据架构行为。这些是影响企业数据架构的各种角色的协作、心态和技能。
数据架构特征
数据架构是围绕某些特征构建的:
自动化
自动化消除了使遗留数据系统配置繁琐的摩擦。使用基于云的工具,耗时数月构建的流程现在可以在数小时或数天内完成。如果用户想要访问不同的数据,自动化使架构师能够快速设计一个管道来交付数据。随着新数据的来源,数据架构师可以将其快速集成到架构中。为了创建一个数据连续流动的适应性架构,数据架构师可以自动化一切。
安全
安全性内置于现代数据架构中,确保数据在业务定义的需要知道的基础上可用。良好的数据架构还可以识别现有和新出现的数据安全威胁,并确保法规遵从HIPAA和GDPR等法规。
用户驱动
在过去,数据是静态的,访问是有限的。决策者不一定得到他们想要或需要的东西,而是得到了可用的东西。在现代数据架构中,业务用户可以自信地定义需求,因为数据架构师可以汇集数据并创建解决方案,以满足业务目标的方式访问数据。
一个良好的数据架构不断发展,以满足新的和不断变化的客户信息需求。
有弹性的
任何数据架构都必须具有弹性,具有高可用性、灾难恢复和备份/恢复功能。
可扩展的数据管道
为了利用新兴技术,数据架构支持实时数据流和微批量数据突发。
协作的
有效的数据架构建立在鼓励协作的数据结构之上。良好的数据架构通过将来自组织所有部门的数据以及所需的外部来源组合到一个地方来消除竖井,从而消除相同数据的竞争版本。在这种环境下,数据不会在业务部门之间进行交换或囤积,而是被视为全公司的共享资产。
人工智能驱动
数据架构使用机器学习和人工智能来构建保持数据流动的数据对象、表、视图和模型。智能数据架构将自动化提升到一个新的水平,使用机器学习(ML)和人工智能(AI)来调整、提醒和推荐新条件下的解决方案。ML和AI可以识别数据类型,识别和修复数据质量错误,为传入数据创建结构,识别新见解的关系,并推荐相关数据集和分析。
有弹力的
弹性允许公司根据需要扩大或缩小规模。云允许快速且经济地按需扩展。弹性使管理员能够专注于故障排除和问题解决。弹性架构使管理员无需精确校准容量、必要时限制使用量以及不断过度购买硬件。弹性还产生了许多类型的应用程序和用例,如按需开发和测试环境、分析沙盒和原型游戏场地。
易于理解的
在高效的数据架构中,简单性胜过复杂性。在数据移动、数据平台、数据组装框架和分析平台方面力求简单。
最简单的架构就是最好的架构。为了降低复杂性,组织应该努力限制数据移动和数据重复,并倡导统一的数据库平台、数据组装框架和分析平台,尽管一流的支持者发出了怒吼。
有适应能力的
现代数据架构需要足够灵活,以支持多种业务需求。它需要支持多种类型的业务用户、加载操作和刷新率、查询操作、部署、数据处理引擎和管道。
受管理的
治理是自助服务的关键。现代数据架构为每种类型的用户定义了访问点,以满足他们的信息需求。数据科学家需要能够访问着陆区的原始数据,或者更好的是,有一个专门构建的沙盒,在那里他们可以将原始公司数据与自己的数据混合。
云原生
现代数据架构旨在支持弹性扩展、高可用性、运动数据和静止数据的端到端安全性,以及成本和性能可扩展性。
无缝数据集成
数据架构使用标准API接口与传统应用程序集成。它们经过优化,可跨系统、地区和组织共享数据。
实时数据启用
现代数据架构支持部署自动化和主动数据验证、分类、管理和治理的能力。
解耦且可扩展
现代数据架构被设计成松散耦合的,使服务能够独立于其他服务执行最小的任务。
数据架构原则
AtScale副总裁Joshua Klahr表示,有六条原则构成了现代数据架构的基础:
- 数据是一种共享资产。现代数据架构需要消除部门数据孤岛,让所有利益相关者都能全面了解公司。
- 用户需要足够的数据访问权限。现代数据架构需要提供接口,使用户能够使用适合其工作的工具轻松消费数据。
- 安全至关重要。现代数据架构必须为安全性而设计,并且必须支持直接对原始数据的数据策略和访问控制。
- 共同的词汇确保了共同的理解。共享数据资产,如产品目录、会计日历维度和KPI定义,需要一个通用词汇表来帮助避免分析过程中的争议。
- 应该对数据进行整理。投资于执行数据管理的核心功能
- 应针对灵活性对数据流进行优化。减少必须移动数据的次数,以降低成本、提高数据新鲜度并优化企业灵活性。
- 11 次浏览
【数据架构】数据架构的过去、现在和未来
QQ群
视频号
微信
微信公众号
知识星球
在今天的文章中,我将讨论数据架构的演变。是什么促使了体系结构的变化及其对数据计划的影响。我将介绍数据网格,这是最新一代的数据体系结构。如果您还没有订阅,请考虑订阅。
标签:数据架构|数据网格|数据湖|去中心化数据所有权
为什么我们需要数据架构?
成为一个数据驱动的组织仍然是许多公司的首要战略目标之一。数据驱动意味着将数据置于组织中所有决策和过程的中心。
领导者明白,通过超个性化和客户旅程重新设计,通过自动化和机器学习降低运营成本,并了解对高层战略和市场定位至关重要的商业趋势,成为数据驱动是改善客户体验的唯一途径。数据平台为数据的蓬勃发展创造了一个繁荣的环境。
数据平台是组织所有数据的存储库和处理库。它处理数据的收集、清理、转换和应用,以生成业务见解。它有时被称为“现代数据堆栈”,因为数据平台通常由不同供应商(Dbt、Snowflake、Kafka等)支持的多个集成工具组成。
数据平台的主要元素之一是数据架构。数据架构是设计、构建和管理组织数据资产结构的过程。它就像一个用于集成来自不同来源和应用程序的数据的框架。
设计良好的数据架构的主要目标是减少数据孤岛,最大限度地减少数据重复,并提高数据管理过程的整体效率。
随着数据环境在过去几十年中的发展,数据架构也在发展。让我们更详细地了解这种演变。
在新的消费模型的驱动下,分析数据经历了演变,从支持商业决策的传统分析到增强ML的智能产品

第一代:数据仓库架构
数据仓库架构是由从操作系统(SAP、Salesforce)和第一方数据库(MySQL、SQL Server)到商业智能系统的数据移动定义的。数据仓库是定义模式(雪花模式、星形模式)的中心点,数据将存储在维度和事实表中,使企业能够跟踪和跟踪其运营和客户互动中的变化。数据为:
- 从许多操作数据库和来源中提取
- 转换为以多维和时变表格格式表示的通用模式
- 通过CDC(变更数据捕获)过程加载到仓库表中
- 通过类似SQL的查询访问
- 主要为数据分析师提供报告和分析可视化用例服务
在这种架构风格中,数据集市也开始发挥作用。它们是数据仓库顶部的一个附加层(由一个或多个表组成),以特定的模式格式为特定的部门业务问题提供服务。如果没有数据集市,这些部门将不得不在仓库中探索和创建多个查询,以获得具有所需内容和格式的数据。

Figure 2 - Data Warehouse Architecture | Source: Data Mesh Book
这种方法的主要挑战:
- 随着时间的推移,成千上万的ETL作业、表和报告被构建出来,只有专门的团队才能理解和维护。
- 不应用现代工程实践,如CI/CD。
- 数据仓库的数据模型和模式设计过于僵化,无法处理来自多个来源的大量结构化和非结构化数据。
这将引导我们进入下一代数据架构。
第二代:数据湖架构
数据湖架构于2010年推出,以应对数据仓库架构在满足数据的新用途方面的挑战:数据科学家在机器学习模型训练过程中访问数据。
数据科学家需要原始形式的数据来进行机器学习(ML)模型训练过程。ML模型还需要大量数据,这些数据很难存储在数据仓库中。
构建的第一个数据湖涉及在Hadoop分布式文件系统(HDFS)中跨一组集群计算节点存储数据。数据将使用MapReduce、Spark和其他数据处理框架进行提取和处理。
数据湖架构在ELT过程中工作,而不是在ETL过程中工作。数据从操作系统中提取(E),并加载(L)到中央存储库中。然而,与数据仓库不同的是,数据湖只需要很少或根本不需要预先对数据进行转换和建模。目标是保持数据接近其原始形式。一旦数据进入湖中,该架构就会通过数据转换管道(T)进行扩展,以对原始数据进行建模,并将其存储在数据仓库或功能存储中。
数据工程团队,为了更好地组织湖泊,创建不同的“区域”。目标是根据清理和转换的程度存储数据,从最原始的数据到数据丰富的步骤,再到最干净、最可访问的数据。
这种数据架构旨在改善数据仓库所需的大量前期建模的无效性和摩擦。前置转换是一个阻碍因素,会导致数据访问和模型训练的迭代速度减慢。
Figure 3 - Data Lake Architecture | Source: Data Mesh Book
这种方法的主要挑战:
- 数据湖架构存在复杂性和恶化,导致数据质量和可靠性较差。
- 由超专业数据工程师组成的中央团队操作的批处理或流式作业的复杂管道。
- 它创建了非托管数据集,这些数据集通常不受信任且不可访问,几乎没有价值
- 数据沿袭和依赖关系很难跟踪
- 没有广泛的前期数据建模会给在不同数据源之间建立语义映射带来困难,从而产生数据沼泽。
第三代:云数据湖架构
从第二代到第三代数据架构的最大变化是向云的切换、实时数据可用性以及数据仓库和数据湖之间的融合。更详细地说:
- 使用Kappa等架构,支持流式传输以实现近乎实时的数据可用性。
- 尝试将数据转换的批处理和流处理与Apache Beam等框架统一起来。
- 完全接受基于云的托管服务,并使用具有独立计算和存储的现代云原生实现。存储数据变得更加便宜。
- 将仓库和lake融合为一种技术,要么扩展数据仓库以包括嵌入式ML训练,要么将数据仓库的完整性、事务性和查询系统构建到数据lake解决方案中。Databricks Lakehouse是一个具有类似仓库的事务和查询支持的传统湖泊存储解决方案的示例。

Figure 4 - From Data Warehouse to Data Lakehouse Architecture (On the right) | Source: Databricks blog
云数据湖正在解决前几代人的一些差距。然而,仍然存在一些挑战:
- 数据湖架构的管理仍然非常复杂,影响数据质量和可靠性。
- 架构设计仍然是集中的,需要一支超专业的数据工程师团队。
- 需要很长时间才能洞察。数据消费者需要等待几个月才能获得用于分析或机器学习用例的数据集。
- 数据仓库不再是通过数据复制真实世界,在探索数据的同时影响数据消费者的体验。
所有这些挑战使我们产生了第四代数据架构,在本文发表时,该架构仍处于早期阶段。
第四代:数据网格架构
数据网格架构是一种相对较新的数据架构方法,旨在解决以前集中式架构中发现的一些挑战。
数据网格为数据架构带来了微服务为单片应用带来的东西。
在数据网格中,数据是分散的,数据的所有权分布在各个域中。每个域都负责其范围内的数据,包括数据建模、存储和治理,架构必须提供一套实践,使每个域能够独立管理其数据。
以下是数据网格架构的关键组件:
- 域-域是一个独立的业务单元,拥有并管理自己的数据。每个域都有明确的业务目的,并负责定义数据建模、实体、模式和策略来管理数据。这一概念不同于为营销或销售等不同团队设计的数据仓库架构中的数据集市。在数据网格架构中,销售可以有多个领域,这取决于团队可能拥有的不同重点/领域。
- 数据产品-数据产品是域产生的最终结果,可供其他域或应用程序使用。每个数据产品都有明确的业务用途。一个域可以处理多个数据产品。并非所有数据资产都将被视为数据产品或应接受数据产品处理(尽管在完美的世界中是这样)。数据产品是在组织中发挥关键作用的数据资产。
- 数据基础设施-数据基础设施包括管理域内数据所需的工具和技术,类似于软件应用程序的容器化微服务。这包括数据存储、处理和分析工具。
- 数据治理-数据治理由每个域管理。这是指管理数据质量、隐私和安全的一套程序。
- 网格API——就像微服务通过HTTP REST API公开所有内容一样,数据网格域将通过定义良好的接口公开所有内容,其他域和数据产品可以使用该接口。

Figure 5 - Data Mesh Architecture. Each domain team performs cross-domain data analysis on its own. The domain ingests operational data, builds analytical data models as data products, and publish them with data contracts to serve other domains’ data needs | Source: datamesh-architecture.com
您可以将数据网格视为当今数据架构设计和数据团队组织方式的范式转变:
- 数据团队成为跨职能团队,专门从事一个或多个业务领域(而非技术),就像软件产品团队非常面向服务一样。
- 每个由一个或多个微服务组成的业务领域都有自己的OLAP数据库和分布式文件存储系统,就像微服务的任何部分都被容器化以独立工作一样。
- 数据产品A将被数据产品B消费,两者都将通过流或REST API与其他数据产品通信,就像应用程序微服务相互通信一样。
- 数据产品API之后将是传统的REST API文档,并且可以通过网格数据目录发现数据产品。
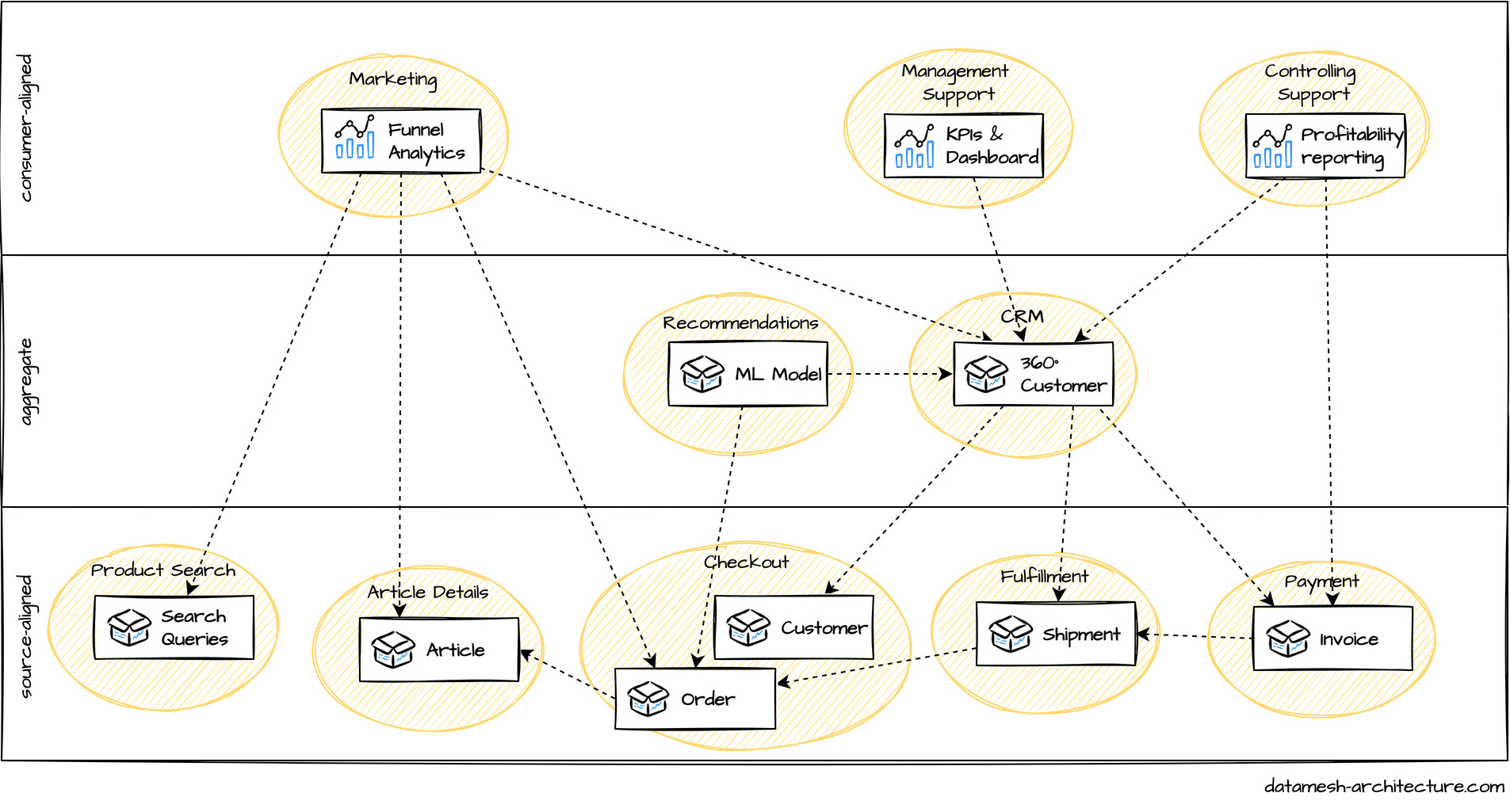
Figure 6: The mesh emerges when teams use other domains’ data products. Upstream domains publish articles, orders, and customer data products that are consumed either upstream by other data products such as shipment, or downstream by ML Models, CRM systems, or Analytics. | Source: datamesh-architecture.com
除了架构之外,数据网格还有什么变化?
数据网格最具影响力的变化是架构。但是,从集中式数据湖转移到去中心化数据网格是一种社会技术现象,这意味着还有一些额外的变化。
如果你还记得的话,从单片应用程序到微服务应用程序的转变使软件工程团队改变了他们的开发生命周期、组织结构、动机、技能和治理。这时,产品经理的角色出现了,以确保应用程序能够解决真正的用户问题。
在应用数据网格架构时也需要发生同样的情况。
在接下来的文章中,我将写更多关于数据网格实现的挑战。
- 19 次浏览
【数据架构】数据模式/纲要(data schema)和数据结构(data structure)
在讨论了数据架构和数据结构之后,接下来的问题是数据架构和数据结构之间的区别是什么?数据模式、数据结构和数据模型是如何正式命名的?
多年来,人们曾多次尝试正式命名特定的数据结构以及包含这些数据结构的数据模型。这些名字大多以某种方式与信息系统的Zachman框架相关。然而,在命名数据结构的类型、数据结构覆盖的主题区域和包含数据结构的数据模型之间产生了混淆。其结果是一系列混乱的数据结构和数据模型名称,它们构成了一个完全不同的数据资源。
一种更好的方法是正式命名每个数据模式(数据纲要),根据数据模式名称和主题区域正式命名数据结构,然后根据数据模型中包含的数据结构正式命名数据模型。
模式是一种图表表示;一个结构化的框架或计划;大纲。数据模式是数据结构的图表表示。数据模式只不过是一种数据结构。数据结构是组织数据资源中数据的排列、关系和内容的表示。它与正式的数据名称、全面的数据定义和精确的数据完整性规则直接相关,必须加以记录。数据结构是组织的数据资源中用于特定目的的特定数据模式的表现形式。
随着数据库在20世纪中期出现,数据库专业人员确定了两种数据模式。内部数据模式表示数据存储在数据库中的方式,外部数据模式表示数据被数据库外部的应用程序使用的方式。注意名称朝向物理数据库。
由于内部数据模式和外部数据模式往往有很大的不同,并且可以为相对较少的内部数据模式开发多个外部数据模式,因此第三个概念数据模式被定义为内部数据模式和外部数据模式之间的公分母。这个术语已经被使用、误用和滥用到现在还不清楚概念数据模式到底代表什么。
为了给这三种数据模式带来更多的含义和理解,内部数据模式被重命名为物理数据模式,外部数据模式被重命名为业务数据模式,概念数据模式被重命名为逻辑数据模式。这些更有意义的名称还建立了业务到逻辑到物理数据模式开发的顺序,在所有正式的数据资源设计中都应该遵循这个顺序。
随着越来越多的业务专业人员开始参与数据资源设计并开始使用数据规范化技术,出现了许多关于哪些数据实际上正在被规范化(normalization)的问题。传统的数据规范化技术和数学方法并没有为业务专业人员提供足够的理解。这些问题的答案是业务数据模式正被规范化为逻辑数据模式。
然而,业务数据模式的数据规范化并不容易或直接导致逻辑数据模式的开发,因为数据规范化本质上是将数据分开的。没有正式的技术可以将类似的数据放在一起,例如所有员工数据放在一起,所有学生数据放在一起,等等。缺乏正式的技术是当今许多公共和私营部门组织中出现的巨大数据差距的开始。
通过添加数据视图模式(这是数据规范化的结果)解决了该问题。然后根据需要组合各个数据视图模式,以确保将类似的数据(如employee、student等)分组在一起。数据优化过程的目的是防止正在开发的许多不同的数据。结果的顺序是业务数据模式规范化为数据视图模式,然后优化为逻辑数据模式,最后再非规范化为物理数据模式。
在分布式数据处理出现之前,这四个模式序列一直工作得很好,这导致了对数据如何分布和非规范化的混淆。通过在逻辑数据模式和物理数据模式之间添加部署数据模式,解决了这种混淆。逻辑数据模式通过一个称为数据去优化的过程部署到部署数据模式。
结果的顺序是业务数据模式,规范化为数据视图模式,优化为逻辑数据模式,非优化为部署数据模式,非规范化为物理数据模式,如下图所示。这是目前在正式数据资源设计中使用或应该使用的五种基本数据模式。

这五种基本数据模式对于组织数据资源的详细设计非常有效。然而,关于概念数据模式的含义和使用的词汇挑战仍然存在。概念数据模式可以是业务模式、业务模式的泛化、逻辑模式的泛化、任何以强力物理数据库开发为借口的东西等等。由于数据管理开始转向业务,概念数据模式没有什么意义,因此需要定义一个对业务专业人员有意义的术语。
通过定义战略数据模式和战术数据模式,解决了这一问题。这些术语对业务专业人员非常有意义,因为他们很容易理解战略和战术活动。简单地说,战略数据模式表示执行级透视图,战术数据模式表示管理级透视图。
战略和战术数据模式本质上是逻辑性的,并且基于组织对其运行所在的业务世界的感知。它们被放置在逻辑数据模式上,如下图所示。战略数据模式可以更详细地开发以生成战术数据模式,而战术数据模式可以更详细地开发以在称为数据模式专门化的过程中生成逻辑数据模式。类似地,逻辑数据模式可以推广到战术数据模式,在一个称为数据模式推广的过程中,战术数据模式可以推广到战略数据模式。

该图显示了数据模式的两个主要部分。一般数据模式包括战略和战术数据模式,它们本质上是一般的。详细的数据模式包括业务、数据视图、逻辑、部署和物理数据模式,这些模式在本质上是详细的。完整的排列被称为三层五模式概念。
问题总是出现在是否应该有八个更通用的数据模式来表示业务、数据视图、部署和战术和战略级别的物理数据模式。答案是,它们可能毫无意义,或者不如形式数据模式有用。业务数据模式的任何泛化都将与业务主题区域或业务功能相关。物理数据模式的任何泛化都与硬件和系统软件管理有关,例如数据文件或数据库的集群。数据视图架构和部署数据架构的泛化没有意义。因此,这些数据模式没有定义或开发。
上面已经正式命名和定义了五个详细的和两个通用的数据模式。这七个正式的数据模式名称可以加上主题区域的前缀,以提供正式的数据结构名称,如设施战略数据结构、车辆战术数据结构、人力资源业务数据结构、员工逻辑数据结构、学生物理数据结构等。使用这些正式的数据结构名称有助于业务专业人员和数据管理专业人员正确地设计、开发和管理组织的数据资源。
数据模型不仅仅是数据结构。数据模型必须包括正式的数据名称、全面的数据定义和精确的数据完整性规则。当数据结构与其他三个组件组合时,生成的数据模型将使用相同的命名约定进行正式命名。例如,相应的数据模型名称将是设施战略模型、车辆战术数据模型、人力资源业务数据模型、员工逻辑数据模型和学生物理数据模型。请注意,尽管战略和战术数据模型的细节较少,但它们仍然包含数据名称、数据定义和数据完整性规则组件。
数据管理专业人员如果希望正确设计、开发和管理组织的数据资源,就必须正式命名数据模式、数据结构和完整的数据模型。它们必须在单个组织范围的数据体系结构中开发正式的数据结构和数据模型名称。他们必须使用正式的流程来规范化、优化、去优化和去规范化数据。它们必须使用形式化过程来进行数据模式泛化和数据模式专门化。否则会导致混乱、数据差异增大以及数据资源不足以支持组织的业务信息需求。
原文:https://www.dataversity.net/data-schemas-and-data-structures-1/
本文:http://jiagoushi.pro/node/1019
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 88 次浏览
【数据架构】数据流图 DFD 百科介绍
数据流图(DFD)是表示流程或系统(通常是信息系统)的数据流的一种方式。 DFD还提供有关每个实体的输出和输入以及流程本身的信息。数据流图没有控制流,没有决策规则,也没有循环。基于数据的特定操作可以用流程图表示。[1]
有几种用于显示数据流程图的符号。上面介绍的表示法是1979年由Tom DeMarco描述的,作为“结构化分析”的一部分。
对于每个数据流,流程中必须至少存在一个端点(源和/或目标)。流程的精细表示可以在另一个数据流程图中完成,该流程图将流程细分为子流程。
数据流图是结构分析建模工具的一部分。使用UML时,活动图通常会取代数据流图的角色。数据流计划的一种特殊形式是面向站点的数据流计划。
数据流图可以看作是反向Petri网,因为此类网络中的位置与数据存储器的语义相对应。类似地,Petri网和数据流以及数据流图的转换的语义应该被认为是等效的。

具有数据存储,数据流,功能和接口的数据流程图
历史
DFD表示法采用图论,该理论最初用于运筹学以对组织中的工作流进行建模。 DFD源于1970年代末在SADT(结构化分析和设计技术)方法中使用的活动图。 DFD推广者包括爱德华·尤登,拉里·康斯坦丁,汤姆·德马可,克里斯·加内和特里什·萨尔森。[2]
数据流图(DFD)迅速成为一种流行的方式来可视化软件系统过程中涉及的主要步骤和数据。尽管DFD在理论上可以应用于业务流程建模,但通常用于显示计算机系统中的数据流。 DFD对记录主要数据流或在数据流方面探索新的高级设计很有用。[3]
DFD组件

数据流程图-Yourdon / DeMarco表示法
DFD由流程(process),流程(flow),仓库和终止符组成。查看这些DFD组件有几种方法。[4]
流程(Process)
流程(功能,转换)是将输入转换为输出的系统的一部分。进程的符号是圆形,椭圆形,矩形或带有圆角的矩形(根据符号的类型)。这个过程用一个单词,一个简短的句子或一个显然可以表达其实质的短语来命名。[2]
数据流
数据流(流,数据流)显示了信息(有时也很重要)从系统的一部分转移到另一部分。流程的符号是箭头。该流应具有一个名称,该名称确定要移动的信息(或什么材料)。例外是流程,在该流程中,通过链接到这些流程的实体清楚地传输了哪些信息。在不仅仅提供信息的系统中对物质转移进行建模。流应该只传输一种类型的信息(材料)。箭头显示了流向(如果去往/来自实体的信息在逻辑上是依赖的-例如问题和答案,它也可以是双向的)。流程链接流程,仓库和终结者。[2]
仓库
仓库(数据存储,数据存储,文件,数据库)用于存储数据以备后用。商店的符号是两条水平线,另一种查看方式显示在DFD注释中。仓库的名称是一个复数名词(例如订单)-它是从仓库的输入和输出流派生的。仓库不必只是数据文件,例如,带有文件的文件夹,文件柜和光盘。因此,在DFD中查看仓库与实现无关。来自仓库的流通常表示读取存储在仓库中的数据,而进入仓库的流通常表示数据输入或更新(有时还删除数据)。仓库由两条平行的线表示,存储器名称位于它们之间(可以将其建模为UML缓冲节点)。[2]
终结者
终结器是与系统进行通信并位于系统外部的外部实体。例如,它可以是不属于同一组织的各种组织(例如,银行),人群(例如,客户),主管部门(例如,税务局)或部门(例如,人力资源部门)到模型系统。终结器可以是建模系统与之通信的另一个系统。[2]
创建DFD的规则
实体名称应易于理解,无需进一步说明。 DFD是由分析师根据对系统用户的采访而创建的系统。它一方面是由系统开发人员确定的,另一方面是由项目承包商确定的,因此实体名称应适合于模型域或业余用户或专业人员。实体名称应该是通用的(独立的,例如进行活动的特定个人),但应明确指定实体。流程应编号,以便于映射和引用特定流程。编号是随机的,但是有必要在所有DFD级别上保持一致性(请参阅DFD层次结构)。 DFD应该明确,因为一个DFD中的最大进程数建议为6到9,一个DFD中的最小进程数为3。[1] [2]例外是所谓的上下文图,其中唯一的过程表示模型系统以及与系统通信的所有终止符。
DFD一致性
DFD必须与系统的其他模型(ERD,STD,数据字典和过程规范模型)一致。每个进程必须具有其名称,输入和输出。每个流应有其名称(例外请参见流)。每个数据存储都必须具有输入和输出流。输入和输出流不必在一个DFD中显示-但是它们必须存在于描述同一系统的另一个DFD中。一个例外是位于系统外部的仓库(与系统进行通信的外部存储)。[2]
DFD层次结构
为了使DFD更加透明(即进程不太多),可以创建多级DFD。级别较高的DFD的详细程度较低(在级别较低的DFD上汇总的详细程度较高)。上下文DFD在层次结构中最高(请参阅DFD创建规则)。所谓的零电平,其后是DFD 0,从进程编号开始(例如,进程1,进程2)。接下来,所谓的第一级-DFD 1-继续编号。例如。流程1分为DFD的前三个级别,分别为1.1、1.2和1.3。类似地,第二级(DFD 2)中的进程编号为1.1.1、1.1.2、1.1.3和1.1.4。级别数取决于模型系统的大小。 DFD 0进程可能没有相同数量的分解级别。 DFD 0包含最重要的(汇总的)系统功能。最低级别应包括能够为大约一个A4页创建一个流程规范(Process Specification)的流程。如果最小规格应更长,则应为该流程创建一个附加级别,以将其分解为多个流程。为了清楚地了解整个DFD层次结构,可以创建垂直(横截面)图。仓库显示在首次使用的最高级别,也显示在每个较低的级别。[2]
See also
- Activity diagram
- Business Process Model and Notation
- Control-flow diagram
- Data island
- Dataflow
- Directed acyclic graph
- Drakon-chart
- Functional flow block diagram
- Function model
- IDEF0
- Pipeline
- Structured Analysis and Design Technique
- Structure chart
- System context diagram
- Value-stream mapping
- Workflow
原文:https://en.wikipedia.org/wiki/Data-flow_diagram
本文:http://jiagoushi.pro/node/896
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 483 次浏览
【数据架构】数据流程图:实例-订餐系统
数据流图(DFD)提供了系统内信息流(即数据流)的可视化表示。通过绘制数据流程图,您可以了解由参与系统流程的人员提供并交付给他们的信息、完成流程所需的信息以及需要存储和访问的信息。本文以一个订餐系统为例,对数据流图(DFD)进行了描述和说明。
食品订购系统示例
上下文
上下文关系图是只显示顶层的数据流关系图,也称为0级。在这个层次上,只有一个可见的流程节点,它代表了一个完整系统的功能,包括它如何与外部实体交互。上下文关系图的一些好处是:
- 显示系统边界的概述
- 使用简单的符号不需要任何技术知识
- 简单的绘制,修改和阐述作为其有限的表示法
下图显示了为食品订购系统绘制的上下文数据流程图。它包含一个表示要建模的系统的流程(形状),在本例中是“食品订购系统”。它还显示将与系统交互的参与者(称为外部实体)。在本例中,供应商、厨房、经理和客户是将与系统交互的实体。在流程和外部实体之间有数据流(连接器),表明实体和系统之间存在信息交换。
上下文DFD是数据流模型的入口。它只包含一个进程,并且不显示任何数据存储。
1级过程
下图显示了第一级DFD,它是在DFD上下文中显示的食品订购系统流程的分解(即分解)。通读这张图,然后我们将介绍一些基于这张图的关键概念。

食品订单系统数据流图示例包含三个流程、四个外部实体和两个数据存储。
根据图表,我们知道客户可以下订单。订单食品流程接收订单,将其转发到厨房,将其存储在订单数据存储中,并将更新后的库存详细信息存储在库存数据存储中。该流程还向客户交付账单。
经理可以通过Generate Reports流程接收报告,该流程分别从库存数据存储和订单数据存储中获取库存细节和订单。
经理还可以通过提供库存订单来启动订单库存流程。流程将库存订单转发给供应商,并将更新后的库存详细信息存储在库存数据存储中。
数据流程图提示和注意事项
提示
- 过程标签应该是动词短语;数据存储由名词表示
- 数据存储必须至少与一个进程相关联
- 外部实体必须与至少一个流程相关联
- 不要让它变得太复杂;通常5 - 7个普通人可以管理流程
- DFD是不确定的——编号不一定表示顺序,它在与用户讨论时用于标识流程
- 数据存储不应该连接到外部实体,否则,这将意味着您将让外部实体直接访问您的数据文件
- 如果没有经过一个流程,数据流不应该存在于两个外部实体之间
- 有输入但无输出的过程被认为是黑洞过程
注意事项
不要混淆数据流和进程流
有些设计人员可能在看到从数据存储连接到流程的连接器时感到不舒服,因为没有看到数据请求的步骤以某种方式显示在图中。其中一些将试图通过在流程和数据存储之间添加连接器来表示请求,并将其标记为“请求”或“请求某些东西”,这是错误的。
请记住,数据流图是为表示信息交换而设计的。数据流图中的连接器用于表示数据,而不是表示流程流、步骤或其他任何东西。当我们将结束于数据存储的数据流标记为“请求”时,这意味着我们将请求作为数据传递到数据存储中。虽然这可能是在实现级别的DBMS做支持的使用功能,而摄入一些值作为参数并返回一个结果,在数据流图中,我们倾向于把数据存储作为唯一的数据夹,并不拥有任何处理能力。如果您想对系统流或流程流建模,那么可以使用UML活动图或BPMN业务流程图。如果希望对数据存储的内部结构建模,请使用实体关系图。
资源
本教程的读者也可以阅读
- 什么是数据流程图(DFD)?如何绘制DFD?
- 如何编写有效的用例?
- 如何使用ERD对关系数据库设计建模?
- 如何开发现有的和将来的业务流程?
- 数据流程图与实例-客户服务系统
原文:https://www.visual-paradigm.com/tutorials/data-flow-diagram-example-food-ordering-system.jsp
本文:http://jiagoushi.pro/data-flow-diagram-examples-food-ordering-system
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 403 次浏览
【数据架构】数据流程图与实例-客户服务系统
数据流图(DFD)提供了系统内信息流(即数据流)的可视化表示。通过创建一个数据流图,您可以告诉参与系统流程的人员所提供和交付的信息、完成流程所需的信息以及需要存储和访问的信息。数据流图在软件工程中得到了广泛的应用。您可以在信息系统建模中使用DFD。本文以客户服务系统为例,对数据流图(DFD)进行了描述和说明。
CS系统示例
数据流图是一个层次图,包括:
- 上下文关系图(概念上为零级)
- 第1层的过程
- 以及可能的第2级DFD和功能分解的进一步级别,这取决于系统的复杂性
上下文
下图显示了为铁路公司的客户服务系统绘制的上下文数据流程图。它包含一个表示要建模的系统的流程(形状),在本例中是“CS系统”。它还显示将与系统交互的参与者(称为外部实体)。在本例中,CS Assistant和Passenger是将与系统交互的两个实体。在流程和外部实体之间有数据流(连接器),表明实体和系统之间存在信息交换。

上下文DFD是数据流模型的入口。它只包含一个进程,并且不显示任何数据存储。
1级过程
下图显示了第一级DFD,它是在DFD上下文中显示的CS系统过程的分解(即分解)。通读这张图,然后我们将介绍一些基于这张图的关键概念。

CS系统数据流图示例包含四个流程、两个外部实体和四个数据存储。虽然没有控制数据流图中形状位置的设计指导原则,但我们倾向于将流程放在中间,将数据存储和外部实体放在两侧,以便于理解。
由图可知,乘客可以通过查询运输明细流程接收运输明细,具体由数据存储、运输明细和铁路实时统计提供。存储在运输明细中的数据是持久性数据(由标签“D”表示),而存储在铁路实时统计中的数据是短暂保存的瞬态数据(由标签“T”表示)。标注形状用于列出乘客可以查询的详细信息。
CS Assistant可以启动购买纪念品流程,将订单细节存储在订单数据存储中。虽然购买纪念品的是顾客本人,但是进入系统存储订单细节的是CS助理。因此,我们使数据流从CS助理到购买纪念品流程。
CS Assistant还可以通过提供订单细节来启动购买过程,这些细节将再次存储在订单数据存储中。数据流图是一个高度抽象的高级图。这里所绘制的数据存储顺序并不一定意味着数据库中的实际订单数据库或订单表。订单细节的物理存储方式将在以后实现系统时决定。
最后,CS Assistant可以通过提供事件和物品细节来启动报告丢失过程,并将信息存储在物品丢失数据库中。
数据流程图提示和注意事项
用D、M和T表示数据类型
在数据流图中绘制的每个数据存储都以字母为前缀,默认情况下为'D'。字母表示数据存储所保存的数据的类型。字母“D”用于表示持久的计算机化数据,这可能是典型信息系统中最常见的数据类型。除了计算机化的数据,数据还可以被暂时保存一小段时间。我们称这种数据为暂态数据,用字母“T”表示。有时,数据是不用计算机来存储的。我们称这种数据为人工数据,用字母M表示。最后,如果数据在不使用计算机的情况下存储,并且保存时间很短,则称为手动暂态数据,用T(M)表示。
注意细节的层次
在这个数据流图示例中,在标记数据时多次使用了单词“details”。我们有“运输详情”和“订单详情”。如果我们把它们明确地写为“路线信息、列车时间和延误”、“纪念品名称、数量和数量”、“票款类型和数量”会怎样?这是正确的吗?这个问题没有明确的答案,但在做决定时试着问自己一个问题。你为什么要画DFD?
在大多数情况下,数据流程图是在系统开发的早期阶段绘制的,其中许多细节还有待确认。一般术语如“细节”、“信息”、“证书”的使用当然会留下讨论的空间。然而,使用通用术语可能会缺乏细节,使设计失去其实用性。所以这取决于你设计的目的。
不要透支
在数据流图中,我们关注的是系统和外部方之间的交互,而不是接口之间的内部通信。因此,接口和使用的数据存储之间的数据流被认为超出了范围,不应该显示在图中。
不要混淆数据流和进程流
当遇到从数据存储连接到流程的连接器时,如果没有在关系图上显示指定的数据请求步骤,一些设计人员可能会感到不舒服。有些设计人员会尝试将请求附加到流程和数据存储之间的连接器上,并将其标记为“请求”或“对某些东西的请求”,这当然是不必要的。
请记住,数据流图是为表示信息交换而设计的。数据流图中的连接器用于表示数据,而不是表示流程流、步骤或其他任何东西。当我们将以数据存储为结尾的数据流标记为“请求”时,这实际上意味着我们将请求作为数据传递到数据存储。虽然这可能是在实现级别的DBMS做支持的使用功能,而摄入一些值作为参数并返回一个结果,然而,在数据流图中,我们倾向于把数据存储作为一个唯一的数据夹,并不拥有任何处理能力。如果希望对系统流或流程流建模,则可以使用活动图或BPMN业务流程图。如果要对数据存储的内部结构建模,可以使用实体关系图。
资源
本教程的读者也可以阅读
- 什么是数据流程图(DFD)?如何绘制DFD?
- 如何编写有效的用例?
- 数据流程图:实例-订餐系统
- 如何使用ERD对关系数据库设计建模?
- 如何开发现有的和将来的业务流程?
原文:https://www.visual-paradigm.com/tutorials/data-flow-diagram-example-cs-system.jsp
本文:http://jiagoushi.pro/data-flow-diagram-examples-customer-service-system
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
- 156 次浏览
【数据架构】数据网格架构模式
企业数据网格正在彻底改变企业管理数据的方式。 什么是基础数据网格模式?

数据网格模式
企业数据网格正在成为一种独特且引人注目的方式来管理企业内的数据。它将“产品思维”引入企业数据管理,同时在企业中实现更高水平的敏捷性和数据治理。它创造了一种“自助服务”能力,具有近乎实时的数据同步,从而为实时数字企业奠定了基础。
但是,唉,没有单一的产品可以为您带来数据网格。相反,企业的数据网格由许多常用组件组成(请参阅下一节数据网格架构回顾)。
但成功的关键是了解这些组件如何相互作用。在本文中,我将使用架构模式来描述这些交互。
数据网格架构回顾
企业数据网格由许多组件组成(更多详细信息可在此处、此处和此处获得)。数据产品是数据网格中的主要构建块,包含使用企业的数据网格在整个组织中同步的运营、分析和/或参与数据。 API 用于访问数据产品中的数据。为了支持联合治理,每个数据产品都包含一个记录数据更改的审计日志和一个它管理的数据目录。
一个企业的数据网格有很多数据产品。数据产品订阅彼此的数据,这样当一个数据产品更改其数据时,此更改会使用更改数据捕获和事件流主干传达给其他数据产品。
最后,企业数据目录(所有数据产品目录和数据更改的同步聚合)用于使任何用户或开发人员轻松查找、使用和管理整个企业的任何数据,同时也为理解提供了基础整个企业的数据沿袭。

- Figure 1, Enterprise Data Mesh Architecture
我们将在本文中描述以下架构模式:
- 变更数据捕获 (CDC)
- 事件流主干(Event Streaming Backbone)
- 数据产品目录 (Data Product Catalog )
- 企业数据产品目录 (Enterprise Data Product Catalog )
- 不可变的变更/审计日志 (Immutable Change / Audit Log )
数据网格模式:变更数据捕获
如今,很难在服务和应用程序边界之间安全、可靠和一致地交付数据。有两种方法可以应对这一挑战。首先,可以使用“两阶段提交”(2PC) 等协议跨多个数据库同步更新数据,但这种方法通常复杂且成本高,并且通常保留用于保持多个数据源同步绝对关键的情况.
第二种方法是立即更新主数据库,同时在将来更新辅助数据库(但不在事务范围内)。当更新主数据库和辅助数据库之间的时间跨度超过预期时,就会出现问题。
变更数据捕获 (CDC) 是企业数据网格用来应对这一挑战的基础组件。 CDC 通过在数据库的事务日志中捕获和发布条目来工作,但最重要的是,它在原始事务之外不显眼地执行此操作。这意味着 CDC 透明地捕获操作(或分析)数据的变化,而不会影响原始应用程序或事务流。
(注意:这里有更多详细信息供那些寻找有关 CDC 如何在企业中工作的详细信息的人使用)

- Figure 2, Data Mesh Pattern: Change Data Capture
但是 CDC 对捕获的“事件”做了什么。 在 Enterprise Data Mesh 中,它将事件发布到 Event Streaming Backbone(下一个模式),以便在整个企业中分发。
数据网格模式:事件流主干
Event Streaming Backbone 在企业数据网格中分发事件。 事件通常来自应用程序、API,在我们的例子中,也来自 CDC。 然而,特别重要的是,任何已发布的事件都可以被任何其他订阅实体安全、可靠且近乎实时地使用。

- Figure 3, Data Mesh Pattern: Event Streaming Backbone
Event Streaming Backbone 中有几个核心托管实体:
由 JSON 模式定义的事件分布在企业数据网格中。
- 主题用于在整个企业中排队和分发事件;企业数据网格通过允许许多实体发布和使用事件来使用类似于队列的众所周知的主题。
- 生产者将事件发布到主题;企业数据网格中的生产者可能是 API、应用程序或 CDC。
- 消费者消费来自主题的事件。企业数据网格中的消费者可以是订阅主题并在事件可用于处理时收到通知的任何实体或应用程序。
- 事件流处理器可以按事件处理事件,也可以按时间窗口聚合事件,从而在企业数据网格中实现非常复杂和强大的分析技术。
- 经纪人管理上述组件,以确保整个企业数据网格中安全可靠的事件通信。
数据网格模式:数据产品目录
他们说,数据是新的黄金和采矿,它将带来巨大的洞察力和财富。但在当今的大多数企业中,数据散布在组织中的许多组中。销售拥有客户数据,分销拥有供应链,财务拥有交易和账户。
不幸的是,这使得查找数据变得非常困难,而且一旦找到,就更难以将它们整合在一起以做出全面的业务决策。结果是:决策缓慢、代价高昂且不知情。
数据产品目录 (DPC) 包含有关数据产品的数据(“元数据”)的信息。 DPC 提供的信息使任何授权人员或应用程序都可以轻松地在企业数据网格中查找、查看和使用数据产品。 DPC 提供了几个好处:
- 通过启用本地所有权和问责制,易于管理。
- 通过允许本地化和更快的决策制定,易于更改和发展。
- 易于查找、查看和使用数据,使任何(授权)实体都可以轻松查找、查看和使用数据(即“自助服务”)。
- Figure 4, Data Mesh Pattern: Data Product Catalog
数据网格模式:企业数据产品目录
企业数据产品目录 (EDPC) 是一个从所有本地数据产品目录 (DPC) 聚合元数据的存储库。 企业数据目录用于存储有关在企业数据网格中维护的所有数据的信息和统计数据(元数据),从而可以轻松查找、查看、使用和管理数据:
- 数据科学家使用 EDPC 来查找企业中可用于训练模型的数据位置。
- 业务用户使用 EDPC 来查找业务决策所需的信息。
- 开发人员使用 EDPC 来了解其应用程序所需的数据结构。
- Governance Professionals 使用 EDPC 来理解和监控整个企业的数据,从而在企业数据网格内实现联合计算治理。

Figure 5, Data Mesh Pattern: Enterprise Data Product Catalog
数据网格模式:不可变变更/审计日志
了解数据的沿袭——定义为数据经历的变化的汇总列表——对于治理和监管目的至关重要。为什么这很重要?考虑今天的一个常见情况:人工智能/机器学习的出现现在是企业必备的能力。数据科学家使用复杂的模型来支持和做出关键的业务决策。
然而,在许多企业中,尤其是医疗保健和金融企业,这些模型的实际可行性取决于满足监管机构对可重复性和可追溯性要求的能力(更多信息可在此处和此处获得)。不幸的是,大多数企业没有能力以审计人员或监管机构要求的方式跟踪数据沿袭。
企业数据网格的不可变变更/审计日志通过在企业数据网格中保留历史数据更改以供未来审计和治理之用,从而满足了这一需求。本地数据 产品更改/审核日志会在数据发生任何数据更改时自动更新。然后将这些日志传播到企业数据产品目录 (EDPC),以便整合企业中数据更改的历史记录。
换句话说,EDPC 包含企业数据网格中所有元素的数据沿袭。 EDPC 使用此数据提供元数据的可搜索索引——其中明确包括对每个数据产品的不可变更改/审计日志的引用——允许轻松找到和确认数据沿袭。
- Figure 6, Data Mesh Pattern: Immutable Change/Audit Log
结论性想法
企业数据网格正在成为实时数字企业的基础推动者。 架构模式提供了一种既定的方式来描述数据网格交互。 虽然没有现成的可用工具,但构建您自己的组织数据网格的第一步是了解启用数据网格的基础模式。
希望本文为您提供必要的洞察力来启动您自己的企业数据网格!
原文:https://towardsdatascience.com/data-mesh-architecture-patterns-98cc1014…
- 73 次浏览
【数据架构】无头湖仓架构
QQ群
视频号
微信
微信公众号
知识星球
建造无头湖屋的设计注意事项
在过去的几十年里,我们看到了向消费者提供(大规模)数据的演变,从数据仓库(Azure Synapse、Redshift、Big Query、Snowflake或ClickHouse),到数据湖(ADLS Gen2、S3或GCS),再到最新的迭代,即数据湖仓(Delta Lake、Apache Hudi或Iceberg)。
数据仓库模式现在在行业中占主导地位,通常与特定的供应商(例如Databricks)、计算引擎(例如Synapse Spark)、存储(例如ADLS Gen2)和开放表格式(例如Delta Lake)有关。虽然单个计算引擎可以与不同的查询引擎、表格式、存储和元数据存储很好地集成,但由于继承的依赖性,切换到另一个计算引擎可能非常复杂。
在今天的lakehouse架构中,主计算引擎(head)可以确定架构和能力决策,从而导致集中式数据湖和数据网格拓扑中的问题。此外,每个数据角色(数据工程师、数据科学家等)与数据和工具有着不同的关系,具有不同的需求和期望的结果,这使得单个主管往往不理想。这导致了三个主要问题:
- 有限的数据和元数据互操作性:并非总是可以从辅助计算引擎访问数据和元数据。这是对数据访问的倒退,也是对互操作性的倒退。例如,跨Spark和配置单元查询Delta还不可能——从Spark(例如Azure Databricks)创建的Delta表无法从配置单元(例如HDInsight)读取,反之亦然。此外,OSS HMS和HDInsight HMS并不完全兼容,需要更改模式才能使其工作。
- 数据访问和管理:用户希望跨系统查看表所有权元数据。例如,从Azure Databricks创建的增量表元数据在Synapse上可用吗?同样,用户如何在不同计算引擎创建的表和数据集之间实现统一的数据访问和治理?Unity Catalog适用于Databricks,Purview适用于Synapse,或Apache Ranger适用于HDInsight。
- 安全、监控和集成:除了数据访问和治理支持外,当转移到辅助引擎时,安全(例如RLS、CLS或动态数据屏蔽)、监控(例如工具和遥测/警报奇偶校验)和ETL的集成程度如何?这种新的计算是如何与现有的报告(Power BI)或数据科学工具(AzureML)集成的?
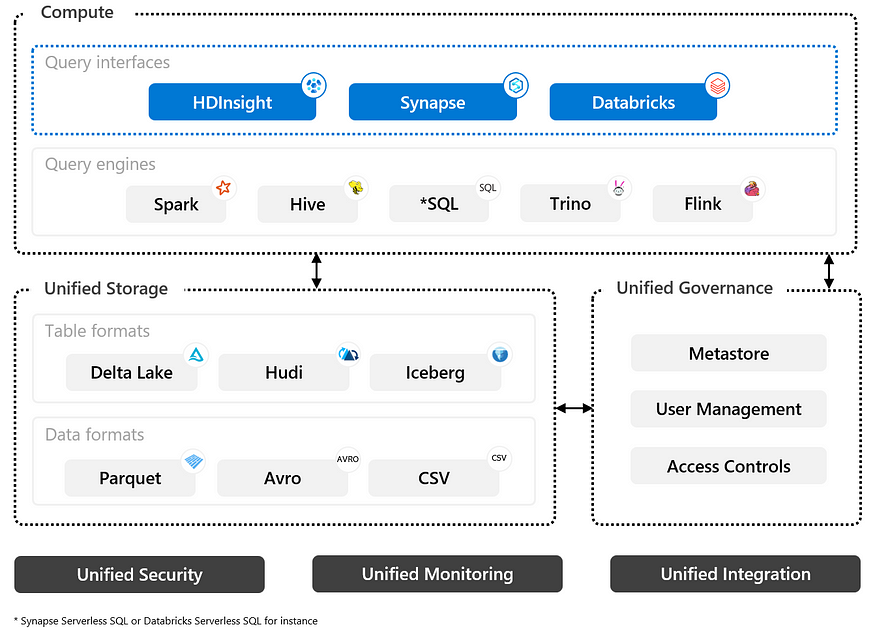
什么是无头湖屋?
无头lakehouse(又名可配置计算)可以定义为一种统一的数据架构,它提供了一种无缝的方式来访问和管理不同计算系统、存储位置和格式的数据。它使不同的系统和用户能够轻松地访问、分析和使用数据,提高了数据管理和分析的灵活性和可扩展性。这样,寻找可互操作计算引擎的用户将能够快速、顺畅地访问数据,并拥有自己的计算引擎。其他功能包括:
用户不希望数据被锁定在特定的存储和/或元存储中,无法用于其他引擎,或者在数据传输和格式转换上花费额外的时间和计算成本。
- 支持通过多个查询引擎和工作负载进行数据访问的多种计算功能。这可以是无服务器的,也可以是已配置的。
- 统一的数据和元数据存储,避免冗余存储、元数据和跨系统ETL。
- 统一的管理和治理,包括用户管理、访问控制、数据沿袭和质量、模式演变等。
- 数据存储和所有计算引擎中的统一安全性将其统一用于查询和作业。
- 统一协作和数据共享促进了基于API的不同团队之间的协作和数据分享。
- 对日志、度量和警报进行统一监控,包括平台可观察性。
- 统一集成和ETL将来自各种来源的数据集成到统一的数据存储中,并使其可供消费者使用。
多种计算功能
在无头湖屋模式中,多个计算引擎可以导致两种不同的拓扑结构。在这两种拓扑中,关注引擎、元存储和数据格式的版本对于确保互操作性至关重要:
- 相同查询引擎:第一个拓扑是“相同查询引擎”。在这个模型中(见下图),不同的计算引擎(如HDInsight和Synapse)使用相同的查询引擎(如Spark)。每个计算引擎都可以访问底层数据和元存储。
- 交叉查询引擎:“交叉查询引擎”拓扑涉及使用多个查询引擎(如Spark和Hive)访问同一存储和元存储。这允许不同的计算系统(例如HDInsight和Databricks)使用相同的数据和元存储。
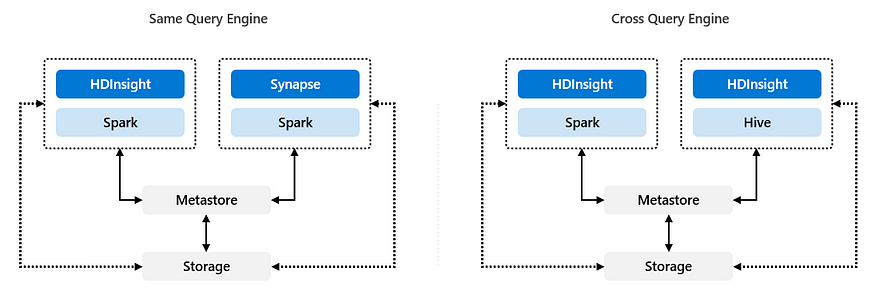
统一的数据和元数据存储
用户可以使用德尔塔表将数据保存在ADLS Gen2中,并从不同的计算引擎读取数据。这允许从一个平台切换到另一个平台,使数据在不同的计算引擎之间具有互操作性。在无头湖屋模式中,从多个系统访问这样的统一数据存储至关重要。例如,Synapse、HDInsight和Azure Databricks与ADLS Gen2配合良好。
类似地,元数据也可以存储在单独的外部元存储中。通过共享HMS或同步机制,可以跨多个计算引擎访问此类元数据,而无需迁移元数据或从外部表重建元存储。
- 共享Metastore:共享HMS方法的一个关键优势是得到所选计算引擎(+供应商)的充分支持,因此不需要构建任何定制的东西。这降低了实现和支持方面的风险,但它确实限制了供应商偏离元存储方法的一些功能兼容性,就像Databricks Unity Catalog的情况一样。有关更多详细信息,请参阅此。
- 同步Metastore:如果有人希望进行一些定制开发,那么同步元商店的方法可能更合适。在同步模型中,将有一系列元存储来掌握数据产业的不同引擎。然后,这些不同的元商店将通过定制的流程进行同步,以提供所有引擎的可见性和互操作性。例如,这可以在外部HMS上使用Azure SQL数据同步来实现。
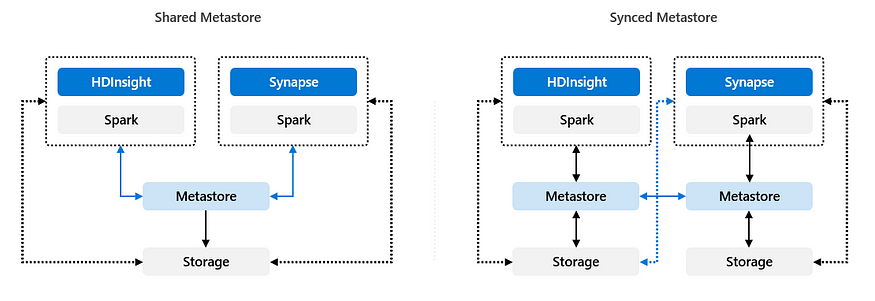
如有任何建议或问题,请随时联系:)
参考文献:
- Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics (cidrdb.org)
- Data lakes — Azure Architecture Center | Microsoft Learn
- Data Mesh topologies. Design considerations for building a… | by Piethein Strengholt | Towards Data Science
- Using a Shared Hive Metastore Across Azure Synapse, HDInsight, and Databricks | by Aitor Murguzur | Mar, 2023 | Medium
- Building a Data Lakehouse Using Azure HDInsight | by Aitor Murguzur | Apr, 2023 | Medium
- 11 次浏览
【数据架构】松散耦合——17世纪的数据架构?
QQ群
视频号
微信
微信公众号
知识星球

在17世纪末,有一项创新将永远改变世界。这项创新来自法国工程师兼中将让-巴蒂斯特·格里博瓦尔。他负责改革法国军队的火炮。他发明了一套标准化的大炮和炮弹。直到那时,大炮还没有标准化,对于每门大炮,你都会制作适合特定大炮枪管的炮弹。使用让-巴蒂斯特的规格,法国人只需在设计公差范围内就可以自由生产炮弹。互换性(interchangeability )的概念被引入世界,它成为工业革命的一个组成部分。

我分享这个故事是因为它很好地说明了一种叫做耦合的东西。但炮弹只是对耦合的粗略简化。Karl Weick提出了耦合概念,他写了一些更无形的系统,比如组织和信息系统。他发现,当系统中的所有步骤都存在并得到考虑时,紧密耦合的系统运行非常平稳,但这些类型的系统对任何变化都很脆弱。就像碰上一块多米诺骨牌,剩下的都倒下了。当你建立一个将数据转化为信息的系统时,理解耦合真的很有用。让我给你举几个我们经常在这个空间看到的紧密耦合场景的常见例子。

第一个例子-依赖数据专家

紧密耦合
假设你有一个“数据员”,可以为你提供所需的所有信息。这意味着你和那个数据人紧密相连。分析师找到新工作的那一天就是你停止获取信息的那一刻。“数据人”越是独特地提供和了解组织的数据,他或她的离职就越痛苦。
松耦合
放松对无所不知的数据大师的依赖并不容易。业务利益相关者不希望陷入必须了解数据的混乱之中。有三件事可以避免人们头脑中的所有逻辑。
数据编目工具
数据编目工具为组织提供了一个协作的地方,以便识别、描述和引用数据元素。对于试图解决数据工作方式问题的人来说,访问数据目录是必须的。最优秀的人把自己的角色看作是大众的工具,而不会陷入困境。数据目录在最大程度的人类参与下工作得最好。
数据仓库
数据仓库负责聚合和整合来自多个来源的数据,这样业务用户就可以使用组件化的、易于查询的数据,而不是原始事务。这不是什么神奇的工具,数据仓库是在业务和IT利益相关者的认真投资和关注下开发的。最好的数据仓库被视为组织内的程序(program),而不是将其视为一个一劳永逸的项目。
BI元数据层
BI元数据层提供了业务利益相关者将看到的数据的外观。因此,业务利益相关者将看到实际的业务术语,而不是看到数据库表名。有多种工具声称可以利用元数据层。然而,这里的关键是元数据层与数据仓库协同工作的效果如何。理想情况下,元数据层将处理数据的重任留给数据仓库。许多分析供应商采用吸收所有数据来提供可视化的方法,但这最终只是创建了一层又一层。
第二个示例-自定义应用程序

紧密耦合
您的组织决定将所有分析自定义构建到CRM或ERP应用程序中。这意味着您将自己与软件供应商紧密耦合,因为您的所有信息资产都是在其中自定义编码的。因此,当你与供应商协商费用时,你就不再占据上风。或者更糟的是,如果您必须更换该供应商,您现在就不得不完全重建如何将数据转化为信息。
松耦合
CRM和ERP等应用程序为您最关心的流程提供了结构和自动化。然而,组织在将每个功能都投入到这些应用程序中时往往做得太过分了,就像上面的紧密耦合示例一样。应用程序的部署需要遵循COTS策略。每个应用程序都应该尽可能地部署为商用现货(COTS)。这样,组织就避免了与一个供应商的紧密耦合。但是,如何可能松散地耦合来自应用程序的分析?
参考单独的分析层
与其自定义应用程序以可视化数据,不如在应用程序中使用框架来引用单独的商业智能层的分析。这些参考框架通常可以参数化,以提供应用程序所在的上下文。这样,分析就不依赖于应用程序前端。
数据仓库
为了获得有意义的信息,您的组织将要求将数据整合到组织可以用来组装分析的组件中。否则,每一次数据请求都是一次钓鱼探险。
数据仓库允许这种一致性与应用程序分开发生,所有分析都是从这个单独的层派生出来的。因此,如果我们想更改应用程序,我不应该重建所有的分析,而是只需要将新的应用程序数据与数据仓库相一致。所有报告、分析、仪表板以及查询数据仓库的其他内容都保持不变。
第三个示例-嵌套逻辑
紧密耦合
您的组织需要改变计算成本的方式。这将要求您更改分析中的一些逻辑。然而,由于您已经有数千份报告和分析,我们需要确保所有报告和分析都考虑到了变化。只有一个问题,即您为数据可视化选择的解决方案,将SQL查询逻辑嵌套在数据可视化本身中。现在,您必须单独打开每一个,编辑SQL,并重复…一千次。因为可视化和查询逻辑是紧密耦合在一起的。
松耦合
我已经就这个话题写了一整篇白皮书。在部署商业智能工具时,您需要长期思考。通常,组织采用数据可视化工具,却发现在未来的道路上,他们有1000个独立的分析。如果您部署的工具是为了支持大量内容而设置的,那么这就不是问题。但是,如果每一个内容本身都是SQL逻辑的孤岛,那么您就有问题了。当一些查询逻辑需要在多个报告和分析中更改时,你有很多工作要做。那么,如何在不把自己逼到角落的情况下开发大量内容呢?
BI元数据层
BI元数据层旨在将单个报告和分析与实际查询解耦。这是通过将查询主体集中在元数据模型中来实现的,该模型指向数据但不存储数据。此外,它还允许您在一个地方定义检索数据的逻辑。因此,如果我需要更改一些逻辑,我会在一个地方更改它,所有的报告都会采用它。当进行查询时,BI元数据层会自动提供SQL,数据会传递到可视化中。
数据仓库
希望您开始看到为什么数据仓库如此重要的趋势。数据仓库提供了所需的中立性,以证明您在符合数据逻辑方面的投资是合理的。(数据仓库并不便宜)确保这项投资的是,数据仓库是一个数据库,任何可以发布SQL的东西都可以查询。(因此任何商业智能工具)
针对数据仓库的查询不仅简单得多,因为所有的属性和度量都已一致,而且查询运行速度也快得多。此外,数据仓库符合来自多个数据源的数据,这将可能有400行SQL逻辑的数据减少到不到10行。
第四个示例-计算和存储
紧密耦合
每天晚上,您都会将数据加载到数据仓库中,为您的业务提供分析。然而,在某个特定的夜晚,加载时间太长,所以现在它在白天运行,用户甚至无法查询数据仓库,因为它的计算能力与加载数据有关。因此,在这种情况下,计算和存储紧密耦合在一起,因此您只需等待数据加载完成,即可再次访问数据。
松耦合
我通常不会在我的作品和视频中为供应商背书。相反,我更喜欢概述某些架构的优点和缺点。然而,偶尔会有一个创新出现,被一个供应商逼到了绝境。这通常不会持续足够长的时间来引起轰动,但在真正解耦计算和存储的情况下,Snowflake Computing在这一功能上占据了一席之地。他们的数据库从头开始设计,能够将数据留在廉价的存储云环境中,同时使用弹性计算资源进行数据处理。这意味着与分析相关的计算资源和与处理新传入数据相关的计算源可以完全相互独立。如果你想进一步调查Snowflake,我已经写了一篇题为“什么是Snowflak?”的白皮书?

第五个示例-供应商拥有的数据仓库
紧密耦合
作为一名营销专业人士,你必须掌握有意义的分析,帮助你做出一些重要的日常决策。您要么没有IT部门,要么无法依靠IT部门对您的分析需求做出足够的响应。您的组织决定购买一个一体式解决方案,该解决方案以交钥匙的方式提供数据仓库和可视化产品。现在,所有的数据逻辑和可视化都紧密地耦合在一起,并且耦合到一个供应商。当你找到另一个强大的分析工具时,你就会陷入困境,因为你的数据仓库与该供应商提供的单个BI层耦合。
松耦合
如果你必须使用外部帮助来生成你的分析,那么我建议你避免任何不同的供应商锁定。数据仓库是一个数据库,任何东西都可以查询,这一事实证明了对数据仓库的全部投资是合理的。当我说这个数据库是为了服务于一个单一的数据可视化工具时,我已经损害了投资的正当性。
一个松散耦合的替代方案是利用Intricity的信息工厂作为服务。这是一个开放云架构,其所有权在合同期限结束时可以转让。这些组件使用了在分析领域多年经验中的数据仓库和商业智能最佳实践。该产品确实提供了一个独特的BI工具,但它为查询BI层之外的环境提供了一扇敞开的大门。
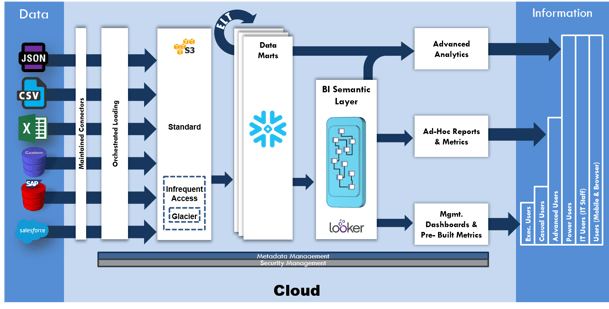
如果您想了解信息工厂即服务,请参阅此处:http://www.intricity.com/information-factory-ifaas/
提前计划

正如您所看到的,松耦合提供了一种设置进程的方法,该方法可以容忍故障,而不会影响其他进程。与其说多米诺骨牌的倒下影响了所有这些,不如说它只是局部失效。
建立一个松散耦合的数据体系结构需要原始的经验。这是因为紧密耦合的体系结构通常不会在部署过程的早期显露出来。只有通过修复失败部署的经验,您才能了解这些缺点。我建议您联系Intricity,与我们的一位专家谈谈您的具体情况。我们可以帮助您制定一个解决方案体系结构,它将超越市场的奇思妙想和流行语,并为您的数据和信息需求带来价值。
谁是Intricity?
Intricity是一个由100多名数据管理专业人员组成的专业团队,其办公室位于美国各地,总部位于纽约市。我们的专家团队已在多个行业实施,包括医疗保健、保险、制造、金融服务、媒体、制药、零售等。Intricity是一家独特的企业合作伙伴,它深入了解数据的来源。这种共同的知识和敏锐性使Intricity一次又一次地击败了四大竞争对手。Intricity的专业领域横跨整个信息生命周期。这意味着当你的问题涉及到数据;Intricity将是值得信赖的合作伙伴。Intricity的服务涵盖了信息工程需求的广泛数据:

是什么让趣味性与众不同?
虽然Intricity从事高度复杂的数据管理项目,但Intricity首先是一家以商业用户为中心的咨询公司。我们的内部口号是简化复杂性。这意味着我们要应对复杂的数据管理挑战,不仅要让业务人员理解这些挑战,还要让它们更易于操作。Intricity通过使用业务人员熟悉但适合IT内容的工具和技术来实现这一点。
思想领导力
有趣的作者,一个备受追捧的数据管理视频系列,面向商业利益相关者https://www.intricity.com/videos.这些视频被世界各地的大学使用。以下是一小部分利用Intricity视频作为教学工具的大学:

- 8 次浏览
【数据架构】现代数据架构的六大原则
QQ群
视频号
微信
微信公众号
知识星球
我在AtScale工作中最喜欢的部分之一是,我可以花时间与客户和潜在客户相处,了解在他们转向现代数据架构时什么对他们来说很重要。最近,在这些讨论中出现了一套一致的六个主题。这些主题跨越了行业、用例和地域,我开始将它们视为企业数据架构的关键原则。
无论您是负责数据、系统、分析、战略还是结果,都可以使用现代数据架构的6条原则来帮助您在快节奏的现代数据和决策世界中导航。将它们视为数据架构的基础,使您的业务能够在今天和未来以优化的水平运行。
1.将数据视为共享资产。
首席信息官解释说,那些一开始就将数据视为共享资产的企业最终会超越竞争对手。这些企业不允许部门数据孤岛持续存在,而是确保所有利益相关者都能全面了解公司。我所说的“完整”是指对客户洞察的360度视图,以及将包括制造和物流在内的所有业务功能的有价值数据信号关联起来的能力。其结果是提高了企业效率。
2.为用户在现代数据分析架构中消费数据提供正确的接口。
将数据放在一个地方不足以实现数据驱动文化的愿景。纯粹使用基于系统的数据仓库的日子已经一去不复返了。现代数据架构要求企业使用数据仓库、数据湖和数据集市来满足可扩展性需求。
你的头现在可能在旋转。仓库、湖泊和集市如何在现代数据分析架构中发挥作用?以下是一个简单的分解:
- 数据仓库:存储所有数据的中心位置
- 数据湖:以原始格式存储的特定数据的较小存储库
- 数据集市:服务层,也就是一个专注于特定团队或业务线的简化数据库
为了利用这种结构,数据需要能够在仓库、湖泊和集市之间自由移动。为了让人们(和系统)从共享数据资产中受益,您需要提供方便用户使用数据的接口。这可以是用于商业智能的OLAP接口、用于数据分析的SQL接口、用于目标系统的实时API或用于数据科学家的R语言。最后,这是关于让你的员工使用他们知道的、适合他们需要执行的工作的工具。
3.确保安全和访问控制。
Snowflake、Google BigQuery、Amazon Redshift和Hadoop等统一数据平台需要直接在原始数据上执行数据策略和访问控制,而不是在下游数据存储和应用程序网络中执行。像Apache Sentry这样的数据安全项目使这种统一数据安全的方法成为现实。寻找能够保护您的现代数据架构并提供广泛的自助服务访问而不影响控制的技术。
4.建立一个通用词汇表。
通过投资企业数据中心,企业现在可以为整个企业的多个消费者创建共享数据资产。这就是现代数据分析架构的美妙之处。然而,确保这些数据的用户使用通用词汇表进行分析和理解是至关重要的。无论用户如何使用或分析数据,产品目录、会计日历维度、提供商层次结构和KPI定义都需要通用。如果没有这些共同的词汇,你将花费更多的时间来争论或调和结果,而不是推动绩效的提高。
5.整理数据。
控制您的数据对于有效实施现代数据分析架构至关重要。我一次又一次地看到,投资Hadoop或基于云的数据湖(如亚马逊S3或谷歌云平台)的企业在允许自助数据访问存储在这些集群中的原始数据时开始遭受损失。如果没有适当的数据管理(包括建模重要关系、清理原始数据以及管理关键维度和措施),最终用户可能会有令人沮丧的体验,这将大大降低底层数据的感知和实现价值。通过投资于执行数据管理的核心功能,您有更好的机会实现共享数据资产的价值。
6.消除整个现代数据架构中的数据拷贝和移动。
每次移动数据都会产生影响;成本、准确性和时间。就这一问题与任何IT团队或业务用户交谈,他们都同意;数据移动的次数越少越好。云数据平台和Hadoop等分布式文件系统的部分承诺是一个用于并行处理大量数据集的多结构、多工作负载环境。这些数据平台随着工作负载和数据量的增长而线性扩展。通过消除对额外数据移动的需求,现代企业数据架构可以降低成本(时间、精力、准确性),提高“数据新鲜度”,并优化整个企业数据的灵活性。
无论您所在的行业、您在组织中扮演的角色或您在大数据旅程中所处的位置如何,我鼓励您采用并分享这些原则,以此为构建现代大数据架构奠定坚实的基础。虽然这条路看起来很长,也很有挑战性,但有了正确的框架和原则,你可以比想象的更快地成功实现这一转变。
告诉我们您对现代数据架构的核心原则。为了为您的组织管理大数据,您每天都坚持做什么?我们很想了解您的见解。
准备好在大数据之旅中迈出下一步了吗?了解如何通过现代数据模型实现数据分析的扩展,如轮辐式方法。
- 10 次浏览
【数据架构】确保数据恢复能力
当托管数据发生故障时,数据弹性允许数据保持可用于包含API和其他分析服务的传统应用程序和应用程序。
在整体业务连续性计划的背景下选择正确的数据弹性技术和技术集是至关重要的,但它可能既复杂又困难。 你如何重建稳定状态? 恢复可能会明显影响用户或系统吗? 您需要能够建立同步点,重新启动,了解任何飞行和不可恢复的内容以及退出。
选择正确的数据弹性技术集至关重要。
备份:旧备用
传统上,组织使用数据备份来恢复数据。备份通常锚定在单个应用程序上。但在互联的世界中,特别是在应用程序互连的地方,备份可能面临重新同步的挑战。备份之间的延迟也会造成数据丢失的缺口。根据数据存储的基础技术,可能无法使用日志记录系统来减少丢失的差距。
由于备份是逐步进行的,因此重新构建要还原的映像可能很麻烦。一些现代数据库非常庞大,甚至无法进行备份。
快照
逻辑磁盘单元的快照可以解决超出单个应用程序的备份。但是,它们可能无法始终与镜像数据和条带数据的各种技术一起使用。
镜像
存在各种镜像技术。镜像副本可以位于同一磁盘驱动器上,也可以推送到远程系统。通常,操作系统处理镜像或复制。
镜像技术可以在同步和异步复制之间变化。使用同步镜像时,数据的两个副本是相同的,并且可能存在关于主要位置和次要位置之间允许的物理距离的延迟问题。异步镜像通常没有距离限制,但如果发生意外故障,延迟可能会导致数据丢失。
在硬件级别,对等远程复制可以提供一种镜像形式,使资源服务能够提供受控的切换或故障转移。
Flash副本
闪存副本可以提供数据的快速时间点副本。您可以使用该副本将应用程序联机到单独的分区或系统中。此类复制还可以补充完成脱机备份或为非生产系统填充数据的能力。
逻辑复制
如果使用逻辑复制来构建具有高可用性的多系统,请确保使用使用同步远程日记的传输机制。日记提供了一种重播方式。
硬件复制
硬件复制在操作系统或磁盘级别而不是在对象级别完成。硬件复制优于逻辑复制的一个优点是硬件复制在较低级别完成。同步完成复制时,您更可能拥有相同的数据副本。缺点是只能从一个副本访问数据,并且在活动复制期间不能使用第二个副本。
软件复制
当您需要移动到辅助系统(例如数据湖或数据仓库)时,软件或数据库复制非常有用。如果使用更改数据捕获(CDC)技术,则数据复制软件依赖于提供日志记录机制的数据库。
业务决策推动了对数据弹性的需求
许多组织正在跨多个云部署应用程序。在多个内部部署和私有云上分散业务的理由受到若干因素的驱动,例如传统部署中的感知弱点以及符合当地法律,法规和文化需求的必要性。
了解数据在企业中的位置和方式 - 因此,跨所有各种云提供商 - 对于缓解数据泄露和数据泄漏非常重要。这些知识还可以帮助您了解如何从数据丢失中恢复并为数据基础架构提供弹性。
随着组织从专门构建的多云架构转变为设计架构,数据弹性至关重要。当出现性能需求或发生灾难性故障时,您需要一个经过深思熟虑并经过测试的数据恢复计划。
避免陷阱
数据弹性计划的两个主要敌人是数据量和网络延迟。要为高可用性,灾难恢复或工作负载重新分配建立弹性,您必须考虑现实世界的物理因素。
将数据从一个位置移动到另一个位置的时间取决于距离。距离越长,延迟越长。一次发送数PB的数据可能会阻塞可用带宽。所有这些约束都与其他考虑因素无关,例如重建索引或在目标位置创建同步点的时间。
无论您是批量移动数据,通过CDC或消息队列涓流数据,还是使用镜像技术,您都需要数据策略,数据拓扑和数据治理。如果您不相信,请考虑今天不同的部署体系结构,现代数据量以及组织无法在没有数字数据的情况下运行。
最后,与数据库存储和内存数据管理相关联的基础技术可以提供提交或同步点,例如创建物理检查点。从业务角度来看,事务可以在事务被视为完全提交之前跨越多个应用程序,数据库,服务器或位置。在任何旨在避免数据丢失的数据弹性计划中,请务必考虑并解决物理和逻辑检查点问题。
原文:https://www.ibm.com/cloud/garage/architectures/resilience/ensure-data-resilience
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 36 次浏览
【数据架构】设计良好的数据架构的5个原则
QQ群
视频号
微信
微信公众号
知识星球
以下是五个核心数据架构原则,可帮助组织构建一个成功满足其数据管理和分析需求的现代架构。
你有没有看到房地产清单上描述的房子是建筑师设计的?它增加了很多要价,但不是所有的房子都是建筑师设计的吗?大多数都是,但它们通常是由一家建筑公司大量生产的。不过,如果你的房子算是建筑,那么有人会根据特定的需求和品味来设计它。
同样,当您的数据架构基于您的特定数据管理和分析需求组合在一起时,您的组织也会受益。但通常情况下,我们从技术供应商的产品设计中继承了许多通用组件和集成。如果我们已经定制了数据架构的一些结构,那么这可能会在很长一段时间内临时发生。
很难从一开始就提供一个规范的架构来满足您的所有需求。但我可以提出一些经验法则和最佳实践,帮助定义有效的现代数据架构。以下是需要牢记的五个数据架构原则。
1.储存是一种商品,但仍然是一种考虑因素
不久前,数据存储还很昂贵。以至于定义存储格式、备份策略和归档计划成为数据架构师工作的重要组成部分。甚至可以选择和调整记录中单个字段的数据类型,以降低存储成本。
事情发生了怎样的变化。我不再需要从专业供应商那里征用1TB的存储空间,以及机架安装、电源和冷却风扇。今天,我可以在一张SD卡上,甚至是一张microSD卡上节省一兆字节。曾经,这足以运行世界上最大的数据库。存储——无论是在云中还是在本地——现在都是一种商品。
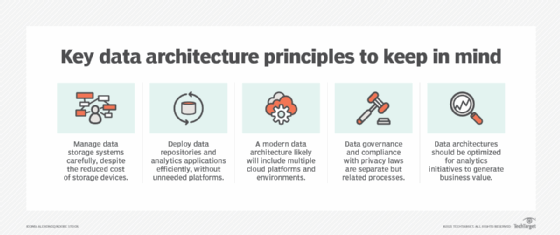
这有三个积极的结果。首先,当然,我们节省了很多钱。此外,现代数据架构不再仅仅为了降低存储成本而涉及复杂的过程。如果数据管道中的一些数据转换可以通过使用临时云存储更容易地完成,那就去做吧。增加的成本可能可以忽略不计。最后,我们可以存储比以前多得多的数据,包括曾经存档的老化或补充数据集。现在,我们的企业数据的全部范围都可以使用了。
即便如此,数据架构最佳实践仍应考虑数据存储。例如,将数据存储在处理位置附近可以提供实时分析和操作所需的性能优势。如今,即使是内部存储也足够便宜,可以实现这一点。此外,我们可能会选择保持大量历史数据的连续可用性,因为我们可以负担得起。但在发生停机时恢复这样的系统可能需要比分割当前和旧数据更长的时间。
2.分析应遵循数据
从数据仓库的早期到商业智能系统的出现,再到今天的机器学习管道,我认为这是最实用的数据架构原则之一:分析遵循数据。通常,在数据源附近部署分析工具比将数据移动到分析环境更有效。
大多数分析应用程序只将数据减少到我们需要的字段。如果你知道SQL编程语言,你就会记得你被教导不要使用SELECT*的速度有多快,这是一个著名的糟糕的初学者查询,它从表中的每一列返回数据。同样,在数据分析中,我们通常会选择特定的记录进行分析。我们的许多计算工作都涉及到从过程中删除数据。
考虑到这一点,当数据分析师的首要任务是减少数据时,将所有源数据移动到新环境中是没有意义的。在源系统中进行所需的数据建模、缩减和整形工作更有效。
您也可以将源数据留在本地系统中进行分析,而不是将其迁移到云中。这就是为什么BI应用程序迁移到云的速度相对较慢的原因:当大多数数据都在本地处理和存储时,在那里进行分析也是有意义的。
数据移动量越少,性能越好,数据架构越不复杂,需要管理的环境越少,数据管理也越容易,所需的用户访问控制也越少。
3.多云环境是常态
世上没有云这样的东西。好吧,这有点争议,但我希望我能引起你的注意。我的意思是,当我们谈论云时,我们是在懒惰。没有一朵云。对于大多数企业来说,可能有几个——事实上,很多——不同的云服务在使用。它们通常在不同的云平台上运行,它们之间或多或少(通常很少)有连接和集成。
例如,今天使用基于云的CRM、费用管理和人力资源系统是很常见的。但是,如果你想分析这些应用程序中的数据——比如说,为了衡量销售团队的成本和效率——你可能必须将多个平台作为数据架构的一部分进行集成。所涉及的问题可能不像许多内部部署系统中的部门数据仓库那样具有挑战性。云应用程序通常比传统应用程序具有更好的API和元数据。但您仍然需要考虑不同的数据结构和不同的系统延迟。
4.不要将数据治理与合规混为一谈
随着公众对数据隐私的日益关注和世界各地立法的不断增加,企业数据的使用和滥用不再只是一个技术问题。从首席营销官(他必须找到新的方法来管理邮件列表和广告)到首席财务官(他对数据泄露的巨额罚款感到担忧),监管合规性让每个人都感到担忧。
解决这些焦虑的架构通常涉及数据治理工具和其他数据管理软件。例如,企业数据目录对来自各种来源的数据的使用进行分类和管理,包括操作系统和报告系统。分析目录也对项目进行分类,但侧重于我们在数据之上构建的工件,如仪表板和数据可视化。它有助于管理数据使用,而不是数据源本身。
数据架构中包含的其他治理工具可以提供集成的安全性,例如用于各种技术的单点登录平台。一些工具跟踪数据的存储、移动和使用位置,因为国家和地区的隐私法各不相同。
尽管这些工具可能很有用,但我们必须牢记一个关键原则:治理和合规不是一回事,但它们之间存在着重要的双向关系。
合规性很容易描述:您的组织对数据的使用是否遵循相关法律、准则和规则?换句话说,您的流程是否勾选了所有正确的框?这些复选框可能是当地、国家和国际法律的要求,如欧洲的GDPR或美国的CCPA和HIPAA。ISO和NIST等标准机构也可能要求这些复选框。内部规则和程序也是一种遵守形式。错过哪怕一个盒子,你也可能不顺从,这可能会带来潜在的后果。这在理论上很简单,但在实践中很复杂。
另一方面,治理让人感觉有点自相矛盾。这与做出正确的决定无关,而是以正确的方式做出决定:你遵循最佳流程吗?数据治理需要一套预先定义、在行动中遵循并可回顾的策略和流程。其中不仅包括数据架构的最佳实践,还包括业务实践。
在没有良好管理的情况下遵守规定是可能的——你可能会因为运气好而不是判断好而勾选所有的框。但这种情况不太可能发生,更不可能持续下去。通过这种方式,数据治理和法规遵从性是相辅相成的,而治理是更基本的数据架构组件。
5.未经分析的数据是浪费的资产
数据是一种商业资产,这是现代数据管理的陈词滥调。但是,仅仅放在那里的数据只是一个成本中心,需要维护,而没有提供任何业务效益。当我们使用它时,我们开始意识到它的价值,尤其是以新的方式。
一些组织通过将数据货币化找到了新的收入来源。高价值数据,如详细的消费者信息,可能是一个重要的收入来源。但对于大多数企业来说,数据货币化只是一种副业。
然而,分析可以释放新的商业见解,从而释放新的价值。BI帮助高管规划业务战略并跟踪绩效指标。BI软件中内置的新增强分析工具将机器学习带入商业主流,以帮助数据准备和分析。数据科学家使用机器学习算法和其他先进的分析技术来预测商业问题和机会,并在数据集中发现对人眼来说太复杂、太大或太快的模式。
优化您的数据架构以支持分析过程是值得的。考虑一下如何移动数据:将数据保留在本地有好处吗?是否存在需要将数据存储在特定国家或州的安全或治理问题?这些因素和其他因素可以帮助您找到最适合您的组织的架构设计。
数据架构设计思维
当然,这五个原则并不是构建有效数据架构所需要的全部。但它们可以为你提供一些有用的思维模式。在房地产上市中,你经常会遇到一些房子,它们一开始是普通的建筑,但被业主打造成了独一无二的。您的数据架构应该朝着同样的方向发展。它可能没有梦想之家的浪漫,但它是你的组织有史以来最重要的投资之一。
- 9 次浏览
【数据架构】谁是数据架构师?角色、职责、技能等
QQ群
视频号
微信
微信公众号
知识星球
目录
- 数据架构揭秘谁是数据架构师?
- 数据架构师做什么?
- 数据架构师的职责是什么?
- 数据架构师需要具备哪些技能?
- 如何成为一名数据架构师?
数据——四个字母的单词是推动现代企业发展的巨大力量。如今,没有一个组织不试图利用数据的力量来寻找问题的解决方案,做出明智的决策,高效地部署战略,并经济高效地平稳运行业务运营。
根据《福布斯》的一篇文章,52%的全球企业正在积极分析数据,以获得运营见解,从而做出更好的决策。71%的企业认为,未来几年,组织在数据和分析方面的支出将加快。
在围绕数据的讨论和关于大数据的高级讨论中,出现了几个新的组织角色,帮助公司每天从企业内部和外部获取、处理和吸收复杂的数据。数据架构师或大数据架构师就是这样一个角色,在当今数据驱动的世界中非常重要。在我们详细说明数据架构师做什么之前,让我们了解什么是数据架构。
数据体系结构的神秘化
简单地说,数据体系结构是与业务流程相一致的组织框架,用于标准化数据收集、存储、转换、分发和使用过程。该框架旨在保护敏感数据的安全,同时使授权人员能够在正确的时间访问最相关的部分。
Dataversity的Keith D.Foote将数据架构定义为“一组规则、策略和模型,用于确定收集什么类型的数据,以及如何在数据库系统中使用、处理和存储数据。”
整个框架所基于的数据架构原则将数据视为根据预设参数定义的资产,是可访问、可共享、可管理和可安全的。
企业部署数据体系结构主要是将业务需求转换为数据和系统需求,使业务流程与IT系统保持一致,并管理组织内复杂的数据和信息流。在2017年的一份趋势报告中,考虑到新的商业模式和创新的出现,数据和创新越来越受到数据和创新的驱动,数据架构被标记为商业和技术决策。
这就引出了一个大问题:谁构建了这个重要的数据架构?数据架构是由数据架构师根据业务需求进行概念化和设计的。
谁是数据架构师?
数据架构师是IT专业人员,其任务是定义将用于为组织收集、组织、存储和检索信息的策略、过程、模型和技术。
数据架构师是制定组织数据战略的专家,包括数据质量标准、组织内数据流和数据安全性。正是这位数据管理专业人士的愿景将业务需求转化为技术需求。
作为业务和技术之间的关键纽带,对合格数据架构师的需求一直在增长。
Recruiter.com的一项调查显示,只有3.9%的数据管理专业人士选择自营职业,而其中高达96.1%的人被希望利用数据获取战术商业优势的组织抢购一空。同一项调查预测,未来几年对数据架构师的需求将以15.94%的速度增长。《Robert Half Technology 2020薪酬指南》将数据架构师的平均薪酬定为141250美元。
我们是否让您对数据架构师的角色感兴趣?让我们进一步讨论详细的数据架构师职位描述、成功担任该职位所需的基本技能,以及如何成为一名数据架构师。
数据架构师做什么?
根据DAMA International的数据管理知识体系,数据架构师“提供标准的通用业务词汇,表达战略需求,概述满足这些需求的高级集成设计,并与企业战略和相关业务架构保持一致。”
数据架构师了解业务需求,探索现有的数据结构,并创建一个蓝图,用于构建一个与业务战略相一致的易于访问、安全的数据集成框架。数据架构师还定义了测试和维护数据库所涉及的过程。
“数据架构师”和“数据工程师”这两个名称通常是错误的,更糟糕的是,它们可以互换使用。但数据架构师的角色与数据工程师的角色非常不同。在这场数据工程师与数据架构师的争论中,当后者设计数据框架的蓝图时,前者将该蓝图付诸行动,以构建数据框架。
数据架构师考虑了与业务运营有关的所有数据源,并概述了集成、集中和维护数据的设计。另一方面,数据工程师负责为组织构建和测试可持续的数据体系结构,以便于数据搜索和检索。数据架构师与数据工程师密切合作,构建完善的数据架构。
数据架构师的职责是什么?
数据架构师的角色是组织中富有远见的领导者。数据架构师的角色和职责包括:
- 制定和实施符合业务流程的整体组织数据战略。该战略包括数据模型设计、数据库开发标准、数据仓库和数据分析系统的实施和管理。
- 识别内部和外部数据源,并制定与组织数据战略相一致的数据管理计划。
- 与跨职能团队、利益相关者和供应商进行协调和合作,以确保企业数据系统的顺利运行。
- 管理端到端数据架构,从选择平台、设计技术架构、开发应用程序到最终测试和实现所提出的解决方案。
- 使用Hadoop等技术规划和执行大数据解决方案。事实上,大数据架构师的角色和职责需要Hadoop解决方案的完整生命周期管理。
- 定义和管理组织内的数据流和信息传播。
- 集成技术功能,确保数据的可访问性、准确性和安全性。
- 对数据管理系统性能进行持续审计,在需要时进行改进,并立即向利益相关者报告任何违规或漏洞。
数据架构师需要具备哪些技能?
一些必备的数据架构师技能包括:
- 系统开发知识,包括系统开发生命周期、项目管理方法和需求、设计和测试技术
- 精通数据建模和设计,包括SQL开发和数据库管理
- 了解预测建模、NLP和文本分析、机器学习
- 能够实施常见的数据管理和报告技术,以及柱状数据库和NoSQL数据库、数据可视化、非结构化数据和预测分析的基础知识。
- 数据挖掘、可视化和机器学习技能
- 编程语言Python、C/C++、Java和Perl的知识
此外,数据架构师需要在日常功能中与用户、系统设计师和开发人员进行协调和协作。因此,有效沟通、团队管理、解决问题和领导力等软技能是数据架构师非常理想的特质。
如何成为一名数据架构师?
要成为一名数据架构师,最低资格要求是计算机科学、计算机工程或相关领域的学士学位。课程应涵盖数据管理、编程、应用程序设计、大数据开发、系统分析和技术架构。
如果你是一名渴望成为数据架构师的应届毕业生,你可以从提供网络管理和应用程序设计机会的实习开始,并继续担任数据库管理员。通过学习与数据库管理、数据建模和数据仓库相关的技能,您可以逐步将自己的职业生涯提升为数据架构师的个人资料。
公司通常更喜欢具有数年数据设计、管理和存储工作经验的硕士学位来担任高级职位。
虽然数据架构师所需的每一项技术技能都不是在一门课程中教授的,但在工作中学习相关技能是有意义的。或者,你也可以获得额外的证书来装备自己。
- 147 次浏览
【数据架构】首席数据官会成为首席数据架构师吗?
QQ群
视频号
微信
微信公众号
知识星球
根据您的组织,您的首席数据官可能会更加关注数据库、基础架构和法规遵从性。另一方面,他们可能更专注于分析和业务问题。在某些情况下,他们可能试图同时关注这两者。
当然,这两条路都有优点。随着《加州消费者隐私法》(CCPA)等更多隐私法案的提出并签署成为法律,其影响值得企业层面思考数据治理和数据的整体使用。但是,考虑到我们今天收集的所有数据,实现以底线影响为重点的数据驱动决策也将始终是一种流行和必要的策略。
CDO的口味也取决于行业。从本质上讲,医疗保健和银行业更侧重于对数据的防御性风险管理态势。但是,尽管一些数据专家长期以来一直专注于如何成为首席数据官,但这个头衔可能不适合一些组织未来想要扮演的角色。
正在演变成CDO,还是已经过去了?
你可能会说,随着时间的推移,CDO将更加专注于分析和从数据中提取价值,但我可能会看到情况发生了不同的变化。随着公司对数据越来越熟悉和熟悉,他们可能会跳过CDO担任首席分析官,继续担任更接近首席数据架构师的角色。这个角色将更加关注组织所做的一切中数据的使用和扩散。
一旦数据的使用完全融入营销、增长、收购及其所有其他潜在的最终用途,你需要有一个单独的人来担心吗?也许首席财务官正牢记这一点。也许在未来,首席数据官会确保所有数据都是可访问的、合规的、安全的。
作为一个行业,我们在过去几年里一直在推动首席数据官的概念。这几乎让我想知道,如果CDO从来没有真正达到那个水平怎么办?如果CDO在成为一种东西之前就已经过时了呢?那一定会这么糟糕吗?
- 5 次浏览
【数据架构】首席数据架构师职位描述
QQ群
视频号
微信
微信公众号
知识星球
首席数据架构师,总监V,由负责IT战略的副首席信息官(DCIO)和首席技术官(CTO)挑选并对其负责。首席数据架构师执行高级数据分析和架构工作,并在战略运营和规划方面提供管理指导和指导。帮助创建下一代大数据分析解决方案。将工程专业知识与创新和独创性相结合,提供强大的企业级数据平台,服务于德克萨斯州的项目领域。管理一支由高影响力数据架构师和数据工程师组成的团队,从大量结构化和非结构化数据中提取和传播知识。推动新的战略和服务产品,为健康和人类服务计划领域带来新的功能。
该职位与多个职能小组和机构接触,以了解挑战、原型新想法和新技术,帮助创建推动下一波创新的解决方案,并管理机构和项目领域参与的交付项目组合。工作涉及为企业范围的信息治理、数据系统完整性和集成制定政策、标准、设计和行动计划,以及将数据用于商业智能、数据分析、战略规划和项目评估。计划、分配和/或监督他人的工作。在最低限度的监督下工作,具有广泛的使用主动性和独立判断的自由度。
基本工作职能:
- 根据机构休假政策,定期和可预测地参加工作,并履行分配的其他职责。
- 为监督范围内的工作人员提供有效的指导和领导,并让他们对实现绩效预期、既定计划目标和立法授权负责。审查与信息技术分析相关的立法、审计结果和法规。监督与数据架构师服务管理相关的职能,并与其他HHS、IT和业务部门合作和集成,以履行职责。进行定期评估,以确定目标是否得到实现,并始终如一地确定修改优先事项的机会和必要性。评估技术和方法,确定新趋势,以确定和实施适当的战略。向CTO报告调查结果和改进建议。(25%)
- 为数据分析、主数据管理、数据仓库和数据集市解决方案的开发和实施提供数据设计和获取策略指导。推动数据标准、数据安全、利用率和优先级的指导和监督。充当升级点,充当数据专家,协助识别、分析和解决数据驱动的问题。制定、实施和实施与数据相关的政策、控制和标准。分析数据库实施方法,以确保符合卫生和公众服务部的政策以及相关的联邦和州法规。(25%)
- 为与HHSC和HHS数据相关的所有活动及其在商业智能、数据分析和项目评估中的使用提供技术监督。审查和批准供应商的技术建议、数据架构设计、数据获取策略、拟议解决方案、数据模型和可交付成果。随着数据设计和业务需求的变化,确保数据设计与业务需求保持一致。管理交付项目组合。与HHS系统的所有领域协调,包括分析和决策支持中心、电子健康协调办公室、访问和资格服务(AES)、医疗和社会服务(MSS)以及监察长,以评估数据分析、绩效衡量和报告需求,确保技术和工具建议满足业务需求。(20%)
- 确保用于决策和战略规划的企业数据报告始终正确使用授权的商业智能和分析数据系统。监督数据质量和完整性的控制,包括数据质量监控系统和流程的部署。审查在定义的生命周期中对企业信息资产进行适当保护的策略、程序和控制。(10%)
- 参与制定采购文件(RFP、RFI、SOW等)和质量保证团队(QAT)框架文件(尤其是执行能力评估和技术架构评估)。作为评估员和谈判代表参与与数据分析活动相关的采购。(5%)
- 代表HHSC和该部门参加商务会议、立法会议、研讨会、会议、工作组、工作队和委员会。回应立法查询或其他通知请求
- 了解主数据、元数据、参考数据、数据仓库、数据库结构以及商业智能原理和流程,包括技术架构。
- 了解企业信息管理流程和方法。
- 了解网络、操作系统、互联网技术、数据库和安全应用程序的操作支持要求。
- 了解与数据管理和数据治理相关的地方、州和联邦法律法规。
- 了解行业标准技术和工具,包括数据库管理系统、主数据和元数据管理工具、数据获取策略、云存储以及所有数据分类的相关安全考虑因素。
- 了解数据和分析系统的硬件和软件技术基础设施、配置、网络和电信要求。
- 数据挖掘和分割技术知识。
- 具备数据可视化工具(如Tableau)和数据建模工具(如Erwin和ERStudio)的知识。
- 了解SQL和Oracle。
- 企业级数据库设计技能,包括数据安全和访问审核注意事项,以及大型企业系统的完整数据生命周期管理(收集、清理、发布、归档、备份和恢复以及清除)。
- 批判性思维能力。
- 使用计算机和适用软件的技能。
- 能够识别影响组织工作的内部和外部动态,并与个人和团体进行谈判。
- 能够识别问题,评估备选方案,并实施有效的解决方案。
- 能够有效沟通,准备演讲,建立并保持有效的工作关系。
- 能够制定和评估政策和程序,并计划、分配和监督他人的工作。
- 能够做出高质量、及时的决策。
注册或执照要求:
- 具有行业认证的候选人优先(认证数据专家、商业智能认证专家、认证大数据专家、Hadoop)。能够在开始工作的18个月内获得两个或两个以上的证书。安全+或CISSP认证也是首选。
初始选择标准:
- 认证学院或大学的学士学位,健康信息技术、计算机科学、工商管理或相关专业优先;加上十(10)年逐步负责的专业经验。
- 五(5)年所需经验必须在卫生信息技术和大型IT运营、数据标准、数据清理和数据治理方面。
- 在卫生信息技术和大型IT组织方面有丰富的技术经验,可以取代学历要求。
- 8 次浏览
【数据架构】:建立企业数据管理的综合策略 执行概述
构建企业数据管理策略
议程
- 定义企业数据管理(EDM)
- 业务驱动的企业数据管理方法
- 定义EDM策略
─挑战
─好处
─定义EDM策略的不同的技术
─全面EDM策略的指导原则
4.MIKE2.0方法
─战略活动概述
─示例任务输出从战略活动
5.经验教训
企业数据管理
如何定义企业数据管理
在许多类型的项目中,有一个定义良好的数据管理方法是成功的关键.
- 数据治理
- 数据调查和再造
- 数据集成
- 数据迁移(一次性批迁移和并行运行)
- 数据仓库(传统的)
- 数据仓库(实时,面向服务)
- 数据集市的整合
- 特定于应用程序的仓库或迁移
- 主数据管理
- 数据融合
- IT转型
此外,对于许多不属于“数据项目”的项目,数据管理方法是其成功的关键因素。由于这些共性和问题的复杂性,有必要使用企业方法进行数据管理。
数据管理的高层业务驱动
数据管理问题是我们优先考虑的问题
CIO:
首席信息官面对业务的双方;每个IT项目的增长和扩张需求以及成本合理性.
各机构每年都在这方面投入数百万美元,但它们感觉自己已经这样做了,达到了能够控制成本,同时又能进行大规模收购的限度.
CFO:
在《萨班斯-奥克斯利法案》(Sarbanes-Oxley act)之后的环境中,首席财务官被要求在财务报表签字。财务报表的质量,数据和数据的质量以及产生这些数据的系统数据现在比以往任何时候都受到更严格的审查.
CRO:
随着《巴塞尔协议II》(Basel II)和《美国爱国者法案》(USA Patriot act)等一系列法规的出台,金融机构的风险合规问题变得更加复杂对遵从性的竖井方法不再有效,可以在围绕风险的计划池中找到大量的节省.
CMO:
在一个CMOs被要求用比以往更少的人力来增加收入的环境中,新的法规正在阻碍他们的发展
有效性.
隐私政策,退出政策破坏现有数据库之前,很难交叉销售和出售现有客户.
定义EDM策略的挑战
迎接这些挑战是成功的关键
建立一个EDM策略,可以适应:
- 通过基于增量交付的持续开发
- 在多年计划中改变业务需求
- 在长期战略计划 的下文中 交付战术项目
- 随着供应商发布和技术进步持续地改变技术
将EDM战略与其他战略计划相结合:
- 提供交付物定义一致的“蓝图”,“路线图”,“框架”
- 确保一致的水准——重构太高级或太详细的可交付成果
- 确保策略是联系组织文化和改变的能力
- 定义一个交付方法,允许并行的活动和避免连环瓶颈
- 确保交付是集中在高风险地区的数据管理
- 通过重用提高运营效率的共同的工作产品
在整个组织内建立更完善的数据管理能力:
- 从数据管理的角度——从IT、整个业务和跨部门——遵循一个系统的过程交付
- 数据管理性能指标融入您的所有活动
- 建立一个框架来重用内容详细的技术水平
- 提供解决方案,集成概念、逻辑和物理从供应商更改绝缘水平
EDM策略:驱动和利益
实现
- 确保所有系统之间的公共数据协调
- 改进了整个企业环境中的数据质量
- 通过数据标准降低信息管理环境的复杂性
- 能够跟踪体系结构中所有系统之间的信息流
- 规模能满足未来业务量的增长
- 满足任何启动项目的需求,还可以扩展到更广泛的企业环境
避免
- 导致数据质量问题的根深蒂固的信息过程
- 与综合管理和信息管理有关的不必要的工作重复
- 导致数据协调问题的不一致的信息管理过程
- 低效的软件开发过程会增加成本并减慢交付速度
- 共享公共信息的项目之间的未知交接
- 不灵活的系统和特定技术的锁定
- 不必要重复的技术支出
MIKE2.0查看了3种可行的方法来定义EDM策略
拟定计划的方法
- 全面的蓝图规划方法跨越了人员、流程、组织和技术
- 目标是形成一个综合信息发展组织
- 遵循MIKE2.0前两阶段的所有活动
- 战略的路线图方面是针对每个增量执行的
元数据驱动的方法
- 重点是构建组织的参考模型,其不仅包括数据字典,还包括完整的企业信息管理环境
- 元数据驱动的方法不仅仅是通用的数据定义 - 包括转换,治理规则
- 融入Blueprinting方法虽然经常在战略的路线图方面开始(第3阶段)
- 数据调查可以帮助填充元数据驱动的方法
调查的方法
- 进行数据分析以定量地理解当前环境的数据质量问题
- 帮助消除有关当前信息环境的不确定性和假设通常使用基于工具的方法
- 允许对信息管理策略做出基于事实的决策
EDM战略的指导原则
人
- 从一开始就正式建立高层赞助。
- 为相关数据主题领域指定数据管理员。 将指派数据治理负责人来指导整体工作
- 使具备适当技能的员工能够构建和管理新的信息系统,并创建卓越的信息文化
- 将员工行为改为架构师解决方案而不是仅仅构建解决方案
流程
- 明确设计企业范围的举措
- 建立一种可以从战略到运营的方法论方法
- 定义企业范围的标准,政策和程序
- 通过蓝图避免“协作迷宫”,实现持续的沟通和实施
- 建立一个整体愿景,使企业与技术保持一致,战略战略
- 不要过多细节 - 建立愿景,然后专注于'下一件事.
组织
- 建立一个信息管理网络组织,以最有效的方式为业务交付解决方案。
- 在3个层次上对企业进行建模,并高度关注信息和基础设施
- 转到卓越中心提供信息和基础设施发展模式
- 在架构、交付和领导之间建立力量平衡
技术
- 从明确和全面的战略需求中推动技术选择
- 重点是大大提高灵活性和重用作为战略框架的一部分
- 基于开放通用标准选择技术,设计实现
- 从开始阶段就建立基础能力,并将其作为每个实现阶段的早期活动优先考虑
- 38 次浏览
【数据架构什么是数据架构?管理数据的框架
QQ群
视频号
微信
微信公众号
知识星球
数据架构将业务需求转化为数据和系统需求,并寻求管理数据及其在企业中的流动。

数据架构定义
根据开放组架构框架(TOGAF),数据架构描述了组织的逻辑和物理数据资产以及数据管理资源的结构。它是企业架构的一个分支,包括管理组织中数据的收集、存储、安排、集成和使用的模型、策略、规则和标准。组织的数据架构是数据架构师的职责范围。
数据架构目标
数据架构的目标是将业务需求转化为数据和系统需求,并管理数据及其在企业中的流动。如今,许多组织都希望将其数据架构现代化,以此作为充分利用人工智能并实现数字化转型的基础。麦肯锡数字咨询公司指出,由于流程复杂性而非技术复杂性,许多组织未能实现其数字化和人工智能转型目标。
数据架构原则
Splunk公司产品管理、核心产品副总裁兼AtScale公司前产品管理副总裁Joshua Klahr表示,六项原则构成了现代数据架构的基础:
- 数据是共享资产。现代数据架构需要消除部门数据孤岛,并为所有利益相关者提供公司的完整视图。
- 用户需要充分访问数据。除了打破筒仓之外,现代数据架构还需要提供界面,使用户能够使用适合其工作的工具轻松地使用数据。
- 安全至关重要。现代数据架构必须为安全性而设计,并且必须支持直接对原始数据的数据策略和访问控制。
- 共同的词汇确保共同理解。共享数据资产(如产品目录、会计日历维度和KPI定义)需要一个通用词汇表,以帮助避免分析过程中的争议。
- 应整理数据。投资于执行数据管理的核心功能(建模重要关系、清理原始数据以及管理关键维度和度量)。
- 应优化数据流以提高灵活性。减少数据必须移动的次数,以降低成本、增加数据新鲜度并优化企业敏捷性。
数据架构组件
根据IT咨询公司BMC的说法,现代数据架构由以下组件组成:
- 数据管道。数据管道是收集、移动和细化数据的过程。它包括数据收集、优化、存储、分析和交付。
- 云存储。并非所有数据架构都利用云存储,但许多现代数据架构使用公共云、私有云或混合云来提供灵活性。
- 云计算。除了使用云进行存储之外,许多现代数据架构还利用云计算来分析和管理数据。
- 现代数据架构使用API来方便地公开和共享数据。
- AI和ML模型。AI和ML用于自动化数据收集、标记等任务的系统。同时,现代数据架构可以帮助组织释放大规模利用AI和ML的能力。
- 数据流。数据流是指将数据连续地从源流到目的地,以便实时或近乎实时地进行处理和分析。
- 容器编排。开源Kubernetes等容器编排系统通常用于自动化软件部署、扩展和管理。
- 实时分析。许多现代数据架构的目标是提供实时分析,即在新数据到达环境时对其进行分析的能力。
数据架构与数据建模
根据《数据管理知识手册》(DMBOK 2),数据架构定义了管理数据资产的蓝图,与组织战略相一致,以建立战略数据需求,并设计满足这些需求。另一方面,DMBOK 2将数据建模定义为“发现、分析、表示和传达数据需求的过程,其精确形式称为数据模型”
虽然数据架构和数据建模都试图弥合业务目标和技术之间的差距,但数据架构是一种宏观视图,旨在理解和支持组织的功能、技术和数据类型之间的关系。数据建模更关注特定系统或业务案例。
数据架构框架
有几种企业架构框架通常作为构建组织数据架构框架的基础。
- DAMA-DMBOK 2。DAMA International的数据管理知识体系是专门用于数据管理的框架。它提供了数据管理功能、可交付成果、角色和其他术语的标准定义,并提出了数据管理的指导原则。
- Zachman企业架构框架。Zachman框架是由John Zachman于20世纪80年代在IBM创建的企业本体。Zachman框架的“数据”列包含多个层,包括对业务重要的架构标准、语义模型或概念/企业数据模型、企业/逻辑数据模型、物理数据模型和实际数据库。
- 开放组架构框架(TOGAF)。TOGAF是一种为企业软件开发提供高级框架的企业架构方法。TOGAF的C阶段包括开发数据架构和构建数据架构路线图。
现代数据架构最佳实践
- 现代数据架构必须设计为利用人工智能(AI)、自动化、物联网(IoT)和区块链等新兴技术。Protiviti技术咨询高级主管Dan Sutherland表示,现代数据架构应遵循以下最佳实践:
- 云原生。现代数据架构应设计为支持弹性扩展、高可用性、移动数据和静止数据的端到端安全性,以及成本和性能可扩展性。
- 可扩展的数据管道。为了利用新兴技术,数据架构应支持实时数据流和微批量数据突发。
- 无缝数据集成。数据架构应使用标准API接口与遗留应用程序集成。还应优化它们,以便跨系统、地理位置和组织共享数据。
- 实时数据支持。现代数据架构应支持部署自动化和主动数据验证、分类、管理和治理的能力。
- 解耦且可扩展。现代数据架构应设计为松散耦合,使服务能够独立于其他服务执行最小的任务。
数据架构角色
根据PayScale的数据,以下是与数据架构和每个职位的平均工资相关的一些最受欢迎的职位:
- 数据架构师:7.9K至16.0万美元
- 项目经理:5.8万美元-12.9万美元
- 解决方案架构师:7.6万美元-16.3万美元
- 数据工程师:6.6万美元-13.2万美元
- 数据分析师:4.5K-8.7K美元
- 数据科学家:6.8万-13.6万美元
- 14 次浏览
【数据架构原则】 现代数据架构的10条原则及其实现方法
QQ群
视频号
微信
微信公众号
知识星球
数据架构的主要原则以及如何将其付诸实践的重要指南。
数据架构和常规架构一样。在这两个领域,都应该遵守良好架构的基本原则。当然,有些设计可以很好地适用于广泛的应用程序,还有一些更小众的设计,但无论结构的确切性质如何,你可以打赌,如果它是一个成功的设计,架构师都会牢记要点。
什么是数据架构?

数据架构可能会变得复杂。
与数据科学家相关的数据架构流程图
但没有必要马上把这件事搞复杂。大多数架构方法都是从基础开始的,这就是我们要在这里奠定的。
数据架构可以描述为一个实体如何组织其数据。
这有三个方面:
- 数据是如何存储的?
- 数据是如何处理的?
- 数据是如何使用的?
我们将看到这些问题在数据架构问题上突然出现,有时会同时出现两个或全部三个问题。
但是,为了依次处理每一个问题,
- 存储包括准确性、访问、控制和可扩展性等因素。这是原始数据的“数据湖”。
- 处理包括安全性、与外围源之间的数据传输以及灵活性。处理后的数据形成“数据仓库”
- 用途包括接口、数据共享和应用程序。
有些公司对数据架构的这三个方面有非常正式的方法,有些则不然。但所有公司都应该以某种方式涵盖它们。通过这种方式,他们可以确保数据管理得到应有的优先权。
这些是对粗心处理数据的惩罚(2021,美国公司因数据泄露而被判的平均罚款为424万美元),组织应为自己、客户和任何联系人对其数据尽责。数据是宝贵的,因此企业需要将其视为资本。
我们将首先转向这种对数据的必要尊重。
1.数据文化
随着任何范式的转变,如果你想要重大变革,那么孤立地关注公司的一个方面是没有好处的。例如,工作场所的性别歧视正在受到挑战(尽管速度很慢),但并没有完全集中在招聘或任何其他单一领域。为了确保所需的彻底变革,有必要解决工作场所的整个环境和心理问题。换句话说,就是它的文化。
与数据完全相同。必须对数据问题进行优先排序,这是通过让每个人都遵守数据信条来实现的。数据不再仅仅是数据科学家的专利。
这里有一种描述方式:
数据区域性的组成部分
公司犯的最大错误之一是招聘一组数据员工,给他们一个配备了所有最新设备的高级办公室,然后坐下来,以为数据工作已经完成了。问题是,你的新部门为你照顾的数据将被许多其他人访问,包括内部团队和公司以外的团队。如果其他人不那么注意数据问题,你可能会遇到麻烦。
这些其他人最终可能会将数据传播给那些无权访问的人。我们已经提到了数据安全和访问治理价值的重要性。几乎同样糟糕的是,他们可能不会向需要它的人提供它,工作流程可能会受到影响。
所有员工都有责任确保数据绝对送达所有需要的人,而不是其他人。你的工作是向他们灌输这一点,让他们开始看到有价值的商品的数据,而不仅仅是那些可能会被谁知道的人抓住或不被抓住的东西。
分享的需要引导我们走向下一个原则。
2.收集数据
因此,员工应该在任务需要的地方相互提供数据。但这还不止于此。应该注意让数据以同样的方式为每个人服务。其中一个非常突出的方面是度量。一个特定的指标在市场营销中的意义应该与对销售团队的意义相同。必须有一个通用的词汇表,没有晦涩难懂的办公室方言。
比方说,业务的两个部分正在处理类似的数据,但一个部分只处理月度数据,而另一个部分仅处理周数据。如果可能的话,应该努力统一他们的数据,以便更容易、更快地进行有意义的比较和关系评估。
跨部门就具体数据所代表的内容及其对组织的指导达成的共识越多,您的业务就越能从联合部门的联合思考中受益。
首先,当涉及到共享时,您优秀的数据专业人员可能需要一些鼓励。通常情况下,数据工作人员可以将自己视为监护人,而实际上他们应该将自己视作为促进者。这种便利化的一部分可以归结为减少行话。在这方面,从非常实际的意义上说,应该努力让每个人都说一种共同的语言。
最后一点:确保公司数据的组织方式确保其可访问性得到保护。例如,尝试使其免受停电的影响,以便优化正常运行时间,并为客户使用您的服务提供受保护的能力。
3.避免供应商锁定
供应商锁定是指当你获得一项技术时会发生的情况,而这项技术最终会因为不容易从你的架构中交换出来而陷入困境。例如,当一家公司从一系列托管PBX提供商中进行选择时,它应该寻找一条方便的出口路线和一个诱人的入口。否则,随着未来的发展,它的通信可能会由一种可能被证明不合适的服务来运行。
因此,任何技术采购都需要着眼于未来。你需要考虑的不仅仅是这项技术在成为你业务的一部分时能做出什么贡献。你需要思考它是如何通过被轻易抛弃而做出贡献的。
4.安全
如何将确保合法访问的需要与阻止未经授权访问的要求结合起来?数据架构通过根据数据项进行分类来确保这一点

数据结构
敏感度以及谁可以访问它们。以托管的联络中心软件为例,将制定一项规定,以确保只有那些对该信息有明确和许可目的的人才能访问客户详细信息。
例如,医疗保健数据架构将确保仅用于宏观分析的任何数据都将被匿名化。
数据架构将规定隐私控制保证保密性的方法。可以在数据架构中构建多层安全性,以确保数据在任何阶段都不会受到攻击,无论是在存储、处理还是应用程序中。
这是一个来自传统架构界的有趣数据,在那里发现,一半的受访架构师因担心数据安全而不鼓励使用他们的BIM(架构信息建模)团队软件。
发现数据安全阻碍BIM协作使用的架构师图表
因此,许多有价值的合作都没有发生,因为参与的员工感觉自己在一个足够安全的环境中。你需要提供这种安全保障。

5.成为一名更优秀的数据策展人
现在到处都有更多的数据。有时我们几乎被淹没在其中。当它处于原始和/或无序状态时,数据的有用性可能会受到威胁。它需要一定的整理才能达到其功效潜力。
例如,我们的电视比我们所知道的要多。有时,刚开始决定那天晚上要看什么可能会让人感到困惑。这就是为什么电视服务通常有策展人模式,根据之前的观看和其他数据,某些电影或连续剧被突出显示为观众可能更感兴趣。
观众可以根据服务的建议接受服务,也可以不接受服务。如果他们决定不这样做,他们几乎肯定会通过查看各种节目分组来寻找其他材料——戏剧、惊悚片、科幻片等。这是另一层策展,被称为分类法。
当涉及到工作场所的数据时,同样的原则也适用。为了确保您的员工获得最适合其任务的材料,数据架构必须以易于理解和访问的模式显示信息。
策划的数据必须对业务用户有帮助,因此应定期进行质量检查。出于这个原因,数据架构应该包括测试自动化中的最佳实践。
6.灵活
商业中有一个不变的东西:变化。你越期待它,甚至接受它,你的业务就会表现得越好。考虑到这一点,您实现的任何数据架构都应该具有轻松发展的潜力。例如,模块化将受到高度重视,使组织有机会更新系统,而无需大规模更换。
灵活性的另一个领域在于工作人员访问数据的方式。将数据架构设计为允许多种格式的访问请求是有意义的。这样,您的系统将能够处理,例如,非结构化电子邮件以及结构化CSV文件。这种应对非技术人员投入的能力将消除可能耗时且昂贵的培训需求。
7.减少数据拷贝
您的数据架构应该以这样的方式进行安排,以减少不断复制数据的需要。生产无休止的数据拷贝在处理空间和最终的财务方面都是浪费。这本身也是一个安全风险。
数据虚拟化可以消除传输和复制数据的需要。使用Azure Synapse Analytics等工具,可以在不需要传输的情况下对所有数据运行查询。
8.反向ETL
你可能已经知道ETL是什么了。如果你不知道,ETL(或提取、转换、加载)是企业数据仓库的常用方法。这是一种将来自多个来源的数据组合成一个连贯整体的方法。

ETL到反向ETL流程
因此,反向ETL是一种从数据仓库中获取数据并更改其格式的方法。为了使数据与Salesforce、Hubspot或Marketo等第三方来源的应用程序兼容,需要将数据从存储位置取出,并转换为更合适的形状。
因此,您的数据架构必须考虑到这一点。有一些反向ETL工具预先安装了API集成,从而简化了使用和维护。但是,即使您没有使用实际的反向ETL,重要的是您要意识到需要一个过程,通过该过程可以访问数据以供各种应用程序使用。
根据业务的性质和存储的数据,应该实现标准化接口,如SQL、RESTful API或OLAP。
这种标准化将确保检索到的数据以可预测的格式到达,因此可以立即使用。
9.摄入问题
您的摄取工具是将数据从摄取堆栈加载到数据仓库的方法。这些数据将以多种形式来自丰富的来源,因此您的数据架构需要一个能够处理尽可能多的数据的接收工具。
与其拥有许多单一来源的摄取工具,不如拥有一些通用的摄取工具。必须在工具之间切换会消耗时间,并会影响您的数据性能。
因此,您需要做的是确定需要支持哪些摄取表单,例如FTP、Batch、CDC、API),并确保您的数据架构是围绕一个可以处理这些表单的摄取工具构建的。
10.数据发现
您的数据架构中应该包含用于自动数据发现会话的规定。这可以揭示有趣和有价值的数据模式,并突出显示应用程序可以在哪些方面进行更新。
例如,云电话系统应该定期进行数据发现扫描,以检查过时或有冲突的个人信息。
结论
因此,数据架构主要是为了确保您已经仔细考虑了信息持有的结构。它有符合标准的输入手段吗?输出格式是否符合您的业务需求?任何系统规划方法都必须包括这些问题的答案。
要返回到我们最初的存储、处理和使用模式,很明显,数据架构的大多数部分会影响其中的多个领域。在这方面,良好的数据架构与一般良好的操作系统设计有很多共同点。
尽管通过分解来分析通常是很好的,但有时人们必须有一个整体的观点才能看到一个结构是如何工作的。这样的观点将为数据架构带来红利。
- 26 次浏览
【数据架构原则】4项数据架构原则将加速您的数据战略
QQ群
视频号
微信
微信公众号
知识星球
您的数据体系结构只有与其基本原理一样好。如果没有正确的意图、标准和通用语言,就很难启动您的战略。
因此,在您使用客户数据来推动分析操作之前,先退一步考虑一下您是否奠定了正确的基础。最终,遵循正确的数据体系结构原则将有助于加强您的数据战略,并使您能够开发加速价值实现和提高数据质量的管道。
强大的数据体系结构的重要性
正确的数据体系结构是数据战略成功的核心。它由管理和定义您正在收集的数据类型的所有策略、规则和标准组成,包括:
- 您如何使用数据
- 数据存储位置
- 您如何管理数据并将其集成到整个业务中
完善这一过程是任何成功的数据策略的关键。因此,如果未能实现数据架构最佳实践,往往会导致错位问题,例如业务和技术团队之间缺乏凝聚力。
但是,您的业务如何确保您的数据体系结构战略跟上现代业务需求?
您需要了解的四个最佳数据体系结构原则
为了获得对数据的完全控制,您需要以清晰和可访问的方式构建数据架构。要做到这一点,您需要遵循最佳数据体系结构原则。
根据定义,数据体系结构原则与围绕数据收集、使用、管理和集成的一组规则有关。最终,这些原则使您的数据体系结构保持一致、干净和负责任,并有助于改进组织的整体数据战略。
以下是四种数据体系结构最佳实践,供您遵循。

1.在进入点验证所有数据
你知道吗,糟糕的数据质量会直接影响88%的公司的利润?为了避免常见的数据错误并提高整体运行状况,您需要设计您的体系结构以尽快标记和更正问题。
然而,当您有大型数据集、复杂的手动过程和很少的支持时,发现错误是很困难的。幸运的是,投资一个数据集成平台,在进入时自动验证您的数据,可以防止未来的损坏,并阻止坏数据在整个系统中扩散。
此外,使用自动化工具过滤异常将有助于最大限度地减少清理和准备所需的时间。由于每天收集的数据如此之多,因此只保留有价值的信息至关重要,从而创建可持续的数据验证和纠错循环。
2.努力保持一致性
为数据架构使用通用词汇表将有助于减少混乱和数据集分歧,使开发人员和非开发人员更容易在同一项目上进行协作。这为您的团队提供了“真相的单一版本”,并允许您创建正确定义实体关系的数据模型,并将其转换为可执行代码。
一致性是关键,因为它可以确保每个人都使用相同的核心定义。例如,无论应用程序或业务功能如何,都应该始终使用相同的列名来输入客户数据。偏离这个通用词汇表的那一刻,就是失去对数据体系结构和数据治理的控制。
3.记录所有内容
定期的“数据发现”将使您的组织能够检查其正在收集的数据量、哪些数据集已对齐以及哪些应用程序需要更新。为了实现这一点,您需要每个业务功能都具有透明度,以便对数据使用情况进行全面概述。
但是,要获得完全的可见性,您首先需要养成记录数据过程每一部分的习惯。这意味着在整个组织中标准化您的数据。正如我们已经确定的那样,你需要努力在你所做的每件事上保持一致,如果你的公司没有人花时间把事情写下来,这是不可能的。
此文档应与您的数据集成过程无缝配合。一家关联管理系统提供商仅使用Excel电子表格和数据集成平台开发了他们的数据架构,将工作流程从文档加载到生产,并自动定期更新到他们的分析仓库。他们所需要做的就是维护Excel文档。
4.避免重复功能
当您在多个应用程序、函数或系统上工作时,很容易在它们之间复制数据。但从长远来看,这会显著增加开发人员更新重复数据集的时间,并阻止他们在其他更关键的领域增加价值。
相反,您需要投资于一种有效的数据集成体系结构,该体系结构可以自动将数据保存在一个通用的存储库和格式中。这不仅使普遍更新数据变得更加简单,还防止了组织筒仓的形成,这些筒仓通常包含冲突甚至过时的数据。现在,每个人都可以从单一版本的真相中进行操作,而无需更新和验证每一条信息。
成功来自于坚持自己的原则
根据Gartner的数据,85%的大数据项目未能启动。但是,为了避免成为这种不必要的统计数据的一部分,您需要遵循正确的数据架构原则,并将其构建到您的战略和文化的核心。
从在进入点验证数据到共享关键实体的通用词汇表,确保您遵守这些原则将加速您的数据战略,并为您提供更快、更高效地满足现代客户需求所需的平台。
- 7 次浏览
【数据架构原则】现代数据架构的九条原则
QQ群
视频号
微信
微信公众号
知识星球

什么是现代数据架构
有人说,今天所有的企业都是It企业。他们只是碰巧通过销售不同的东西来赚钱。虽然这种说法可能并不普遍正确,但软件和计算机技术已成为大多数公司日常运营的核心部分。在他们软件生态系统的所有组成部分中,最重要的是他们的数据。无论是客户列表、产品目录还是生产计划,每家公司的数据都是其独特之处。它是其历史的记录,也是其未来的关键。
简单地说,数据架构就是组织数据。一般来说,公司的数据架构以三种方式描述其数据处理方法——如何存储数据、如何处理数据以及如何使用数据。该架构通过描述数据的组织方式来影响数据存储,从而使数据准确、能够高效地访问并随业务扩展。数据处理包括将数据从其源获取到数据存储系统,并在需要时进行检索。公司的数据架构管理数据的处理,以确保数据是安全的,易于被需要它的系统使用,并且足够灵活,可以处理可能输入系统的许多数据源。最后,数据架构定义了如何使用数据。它描述了系统可以用来访问数据的接口,并鼓励组织将数据视为共享资产。
每个公司都有一个数据架构。有些公司有非常明确的系统和流程来管理数据的存储、处理和使用,而另一些公司则根本没有正式的系统。在这篇文章中,我们将讨论构成每个数据架构基础的九个特征。它们共同构成了一个坚实的基础,将支持公司的数据需求,并有助于确保公司能够高效地发展以满足客户的需求。
数据存储

消除数据拷贝和移动
公司数据架构需要解决的最关键和最具挑战性的任务之一是数据重复的趋势。这种重复在没有适当管理和监督的系统中自然演变。当一个新的系统或应用程序被添加到企业的软件生态系统中时,它通常需要现有数据基础设施中已经存在的基本信息,例如用户信息或产品目录。软件开发团队倾向于以优化的方式为他们的特定需求建模和存储这些通用信息。最终,这种趋势可能会导致整个企业的数据一致性问题和性能下降。
当同一数据的多个副本保存在企业中时,需要其他流程和过程来同步该数据并保持其一致性。随着软件生态系统的不断发展和共享数据的新用途的需要,这些过程的维护往往具有挑战性。尽管团队尽了最大努力,但数据最终会变得不同步,代价高昂的错误变得更加可能。除了管理公共数据的多个副本的复杂性之外,所需的同步任务往往会导致性能下降。这种降级的两个常见来源是实际同步过程本身的开销,以及需要验证所使用的数据实际上是最新和正确的。
现代数据架构定义了要存储的通用企业数据的位置。这些公共数据库是这些信息的唯一真实来源,从而消除了数据复制带来的低效率。然而,这确实给集中式系统带来了负担,因为它们必须为整个组织的软件套件服务。要做到这一点,必须选择一个灵活且可扩展的存储解决方案。
扩展以满足存储需求
一个组织的数据受到广泛的性能需求的影响。一些数据,如过去的销售记录,很少被访问,而客户的购物车等信息可能会被不断访问。现代数据架构提供了标准和指导方针,以帮助量化企业所有数据所需的访问需求。它还定义了数据系统必须满足的最低性能要求。该架构还为处理随着时间的推移而增加的数据需求做出了准备。这可能是由于长期增长或一些短暂的事件,如假期。现代数据架构提供了增加带宽和存储容量以满足这些更高需求的能力,并允许数据存储系统在高需求期结束时缩减规模。从而有助于使组织的运营成本与其收入保持一致。
建立通用词汇
给事物命名是最难做到的事情之一。如果没有适当的指导,IT组织内的团队将倾向于采用类似但不完全相同的通用数据术语——系统用户的中心数据应该称为用户、帐户、客户或其他什么吗?所有这些选项可能都是有效的,但在公司的数据系统中使用它们会导致混乱和效率低下。现代数据架构为标准数据项建立了通用词汇表。这个词汇表应该存储在一个活文档中,该文档可以随着组织需求的变化而增长和发展。此外,数据架构应该为如何在需要时命名新事物建立一个模式。一些精心设计的指导方针可以大大加快开发工作,使数据更容易在公司内共享。
数据处理

确保安全和访问控制
公司的数据是公司最有价值的资产之一。不幸的是,这也意味着它成为滥用和盗窃的目标。现代数据架构建立了指导方针,允许根据每个数据项的敏感程度对其进行分类。它还定义了用于确保每个数据项得到充分保护的机制和过程。最敏感的数据通常会受到“深度防御”方法的保护,该方法保护多个安全层背后的信息,从而降低成功攻击的可能性。现代数据存储系统允许在原始数据本身上设置高级别的安全性,从而允许执行非常精细的安全规则。可以在数据访问系统以及应用程序级别中应用额外的安全层。在整个组织的数据架构中定义数据安全控制,可以降低漏洞暴露的可能性,从而使数据被滥用或损坏。
整理数据
如果一个组织的数据没有组织、准确和可靠,那么它就是无用的。数据架构定义了如何为消费准备摄入数据库中的信息。数据管理通常涉及对原始文本的处理,以将这些数据分类为已知值。当原始数据将用于填充将用于约束查询或命令的维度时,这一点尤为重要。数据管理的另一个关键方面是执行任何必要的数据转换。原始数据通常使用不同的单位(例如公里、英里等)进行收集。数据架构为如何存储数据以及如何从传入的单位系统转换为数据系统的标准制定了规则。
保持数据可访问性
组织的数据只有在可用的情况下才会增加价值。现代数据架构的一个关键原则是,需要确保业务的利益相关者能够在需要时访问他们需要的数据。现代数据体系架构利用基于云的数据库等技术,确保信息高度可用,并针对网络中断、维护任务等造成的停机时间进行加固。然而,无障碍的概念超出了这一点。组织的数据架构还必须确保可以在合理的时间内访问数据。对于地理分布的组织来说,这通常需要通用数据的区域克隆。但是,必须注意在快速访问数据的需要与创建和维护这些克隆可能导致的效率低下之间取得平衡。
数据使用情况

将数据作为共享资产查看
增加自定义软件价值的最常见技术之一是设计尽可能有效地重用的代码。如果编写和记录得当,代码重用可以消除重复解决同一问题的需要,从而节省开发人员的时间。共享数据为组织提供了类似的好处。当数据被视为组织范围内的资产,而不是被孤立在不同的部门内时,整个数据系统的运行会更加高效。一个成功的数据架构鼓励数据共享,并为如何存储和记录数据建立模式和期望,以便整个企业能够从其存在中受益。这方面的努力还倾向于通过培养通用词汇和减少数据重复来改善公司的整体数据系统。
灵活变通
许多公司都有大量的信息,需要使用这些信息来填充数据库。信息可以是结构化CSV文件或非结构化电子邮件的形式,甚至可以是诸如JSON文档之类的半结构化输入。数据架构提供了摄取每种类型的传入信息的机制。此外,架构必须指定如何存储这些信息。许多数据库系统可以以可查询的方式本地存储XML和JSON文档。利用这些功能可以显著降低数据导入操作的复杂性,方法是将这些文档的处理推迟到它们被消耗掉。然而,这样的决定不能轻易做出,因为从数据完整性的角度来看,未处理的文档更难验证。
为消费提供正确的接口
许多开发项目使用直接查询和命令与数据库进行交互。这会导致整个应用程序套件中的逻辑重复。现代数据架构定义了接口服务,这些接口服务提供标准化机制,以允许轻松地消费数据。这些接口可能包括支持web服务和应用程序的RESTful API、用于数据分析的SQL接口或用于商业智能的OLAP接口。通过提供底层数据源的抽象,每个专家都可以专注于解决他们所负责的业务问题,而不是浪费时间试图将数据强制转换为他们需要的形式。
每个公司都有一个数据架构,无论是正式的还是非正式的。现代数据架构考虑所有企业数据的存储、处理和使用,为其整个软件生态系统奠定基础。当考虑到上述九项原则时,数据系统将成为一个安全、高效和有组织的平台,为公司的成功奠定基础,并为未来做好准备。
- 23 次浏览
【数据架构师】什么是数据架构师?IT的对数据框架有远见卓识的人
QQ群
视频号
微信
微信公众号
知识星球
数据架构师可视化并设计组织的企业数据管理框架,与企业战略和业务架构保持一致。
数据架构师角色
数据架构师是将业务需求转化为技术需求并定义数据标准和原则的资深梦想家。数据架构师负责可视化和设计组织的企业数据管理框架。该框架描述了用于规划、指定、启用、创建、获取、维护、使用、归档、检索、控制和清除数据的流程。DAMA International的数据管理知识机构表示,数据架构师还“提供了标准的通用业务词汇,表达了战略需求,概述了满足这些需求的高级集成设计,并与企业战略和相关业务架构保持一致”。
数据架构师职责
根据Panoply的说法,典型的数据架构师职责包括:
- 将业务需求转化为技术规范,包括数据流、集成、转换、数据库和数据仓库
- 定义数据体系结构框架、标准和原则,包括建模、元数据、安全性、参考数据(如产品代码和客户类别)以及主数据(如客户、供应商、材料和员工)
- 定义参考体系结构,这是其他人创建和改进数据系统时可以遵循的模式
- 定义数据流,即组织的哪些部分生成数据,哪些部分需要数据才能发挥作用,如何管理数据流,以及数据在过渡中如何变化
- 与多个部门、利益相关者、合作伙伴和外部供应商进行协作和协调
数据架构师与数据工程师
数据架构师和数据工程师的角色密切相关。在某些方面,数据架构师是高级数据工程师。数据架构师和数据工程师协同工作,以可视化和构建企业数据管理框架。数据架构师负责可视化数据工程师随后构建的完整框架的“蓝图”。根据Dataversity的说法,数据架构师在一个可供数据科学家、数据工程师或数据分析师使用的框架中可视化、设计和准备数据。数据工程师协助数据架构师构建数据搜索和检索的工作框架。
数据架构师与数据科学家
Dataversity表示,数据架构师和数据科学家的角色是相关的,但数据架构师专注于将业务需求转化为技术需求,定义数据标准和原则,并构建供数据科学家使用的模型开发框架。数据科学家是将计算机科学、数学和统计学应用于构建模型的专家。
如何成为数据架构师
数据架构师是一个不断发展的角色,目前还没有针对数据架构师的行业标准认证或培训计划。通常,数据架构师在工作中学习数据工程师、数据科学家或解决方案架构师,并凭借多年的数据设计、数据管理和数据存储工作经验逐步成为数据架构师。
在数据架构师中寻找什么
大多数数据架构师拥有信息技术、计算机科学、计算机工程或相关领域的学位。根据Dataversity的说法,优秀的数据架构师对云、数据库以及这些数据库使用的应用程序和程序有着扎实的理解。他们了解数据建模,包括概念化和数据库优化,并表现出对继续教育的承诺。
数据架构师有能力:
- 设计实现预期业务模型的数据处理模型
- 开发表示关键数据实体及其关系的图表
- 生成构建设计系统所需的组件列表
- 清晰、简单、有效地沟通
数据架构师技能
- 数据架构师需要精通数学和计算机科学、数据管理技能以及分析和呈现统计信息的能力。
- Anthem分析交付主管、CapTech咨询公司前总监Bob Lambert表示,重要的数据架构师技能包括:
- 系统开发的基础:数据架构师必须了解系统开发生命周期、项目管理方法以及需求、设计和测试技术。
- 数据建模和设计:Lambert表示,这是数据架构师的核心技能,也是数据架构师工作描述中最需要的技能,他指出,这通常包括SQL开发和数据库管理。
- 成熟和新兴的数据技术:数据架构师需要了解成熟的数据管理和报告技术,并对柱状和NoSQL数据库、预测分析、数据可视化和非结构化数据有一定的了解。
- 沟通和政治悟性:数据架构师需要人际交往技能。Lambert说,他们必须是能言善辩、有说服力的优秀销售人员,他们必须构思并向他人描绘大数据图景。
数据架构师认证
虽然没有针对数据架构师的行业标准认证,但有一些认证可能有助于数据架构师的职业生涯。除了其组织使用的主要数据平台中的认证外,以下认证也很受欢迎:
- Certified Data Management Professional (CDMP)
- Arcitura Certified Big Data Architect
- IBM Certified Data Architect – Big Data
- IBM Certified Solution Architect – Cloud Pak for Data v4.x
- IBM Certified Solution Architect – Data Warehouse V1
- Salesforce Certified Data Architecture and Management Designer
- TOGAF 9 Certification Program
数据架构师工资
根据PayScale的薪酬分析,数据架构师的薪酬中值为每年121606美元,包括奖金和利润分成在内的总薪酬从每年78000美元到158000美元不等。
根据PayScale的数据,以下是与数据架构和每个职位的平均工资相关的其他一些流行职位:
- BI架构师:8.3K美元-14.4K美元
- 数据工程师:6.5万美元-13.2万美元
- 数据仓库架构师:$8.7K-$15K
- 数据库架构师:7.3K美元-15.5K美元
- 信息架构师:6万至14.8万美元
- 解决方案架构师:7.6万至16.1万美元
数据架构师工作
最近在Indeed.com上搜索数据架构师职位时,显示了一系列行业的职位,包括咨询、金融服务、医疗保健、高等教育、酒店、物流、制药、零售和技术。
数据架构师的工作描述示例显示了关键的职责领域,例如:创建数据操作和BI转型路线图,开发和维护数据战略,实施和优化物理数据库设计,以及设计和实施数据迁移和集成过程。
公司正在寻找计算机科学、信息科学、工程或同等领域的学士学位,但硕士学位优先。大多数人都希望有8到15年的相关工作经验。他们需要积极性高、经验丰富的创新者,具有出色的人际交往技能、强大的协作能力以及有效的口头和书面沟通能力。
更多关于数据架构和科学的信息:
- 22 次浏览
【数据架构师】数据架构师指南
QQ群
视频号
微信
微信公众号
知识星球
了解数据架构师的工作内容以及完成此项工作所需的技能。
这描述了数据架构师的角色和所需的技能,包括:
- 角色介绍,告诉你在这个角色中会做什么,以及完整的技能列表
- 描述该角色的级别,从数据架构师到首席数据架构师,指定您需要的技能和相应的技能级别(意识、工作、从业者、专家)
该职位是公务员数字、数据和技术专业的一部分。
数据架构师角色介绍
数据架构师通过数据设计为组织使用数据设定愿景,以确保数据得到正确管理并满足组织的需求。
成为数据架构师所需的技能
您需要具备以下技能才能胜任此职位,尽管每个职位的专业知识水平会有所不同,具体取决于职位级别。
- 技术和非技术人员之间的沟通。您可以跨越组织、技术和政治边界进行有效沟通,了解上下文。您可以使复杂的技术信息和语言变得简单,并可供非技术受众访问。你可以代表团队进行宣传,并交流团队的工作,以建立信任和真实性。你可以成功应对挑战。
- 正在通信数据。您可以使用最合适的媒介和工具来可视化数据,讲述与业务目标相关的引人注目的故事,并采取行动。您可以有效、适当地呈现、交流和传播数据,并具有很高的影响力。
- 数据分析和综合。您可以将数据转化为有价值的见解,为决策提供信息。您可以有效地让团队参与分析和综合,以增加共识并挑战假设。您可以识别和使用最合适的分析技术,并且您对分析工具有一定的了解。你可以展示算术能力。您可以了解数字分析工具和数据处理产品的进步,并随时了解它们。您可以收集、整理、净化、综合和解释数据,以获得有意义和可操作的见解。
- 数据治理(数据架构师)。您可以了解数据治理,它如何应用于数据架构,以及它如何与其他组织治理结构相关。您可以参与或提供服务、项目或计划的保证。
- 数据创新。您可以探索从数据中获取价值的新的、更高效的方法。您可以优化和设计数据以支持商业机会。
- 数据建模。您可以生成数据模型,并了解在哪里使用不同的类型。您可以理解不同的工具并比较不同的数据模型。您可以对实时系统中的数据模型进行逆向工程。您可以了解行业公认的数据建模模式和标准。
- 数据标准(数据架构师)。您可以确定并建立组织的数据标准。你可以认可已公布的最佳实践,并在政府内部有效应用。您可以传达数据标准的商业利益,并在整个组织中支持和管理这些标准。
- 元数据管理。您可以了解元数据管理和支持其交付的工具选项。您可以设计和维护适当的元数据存储库,使组织能够了解其数据资产。
- 问题管理(数据架构师)。您可以确定数据解决方案有助于解决组织问题的地方,还可以记录、分析、确定和实施适当的解决方案。您可以协同工作以确保风险和问题得到管理,并采取适当的行动以确保问题得到解决。
- 战略思维。您可以从整体角度看待业务问题、事件和活动,并讨论其更广泛的影响和长期影响。您可以确定模式、标准、政策、路线图和愿景声明。你可以有效地关注结果,而不是解决方案和活动。
- 将业务问题转化为数据设计。您可以与业务和技术利益相关者合作,将业务问题转化为数据设计。您可以通过迭代过程创建最佳设计,使系统需求和组织目标与用户需求保持一致。
数据架构师
数据架构师设计和构建数据模型,以满足首席数据架构师定义的组织的战略数据需求。
在此角色级别,您将:
- 根据数据策略,为数据的升级、管理、退役和归档提供设计、支持和指导
- 为数据字典提供输入
- 定义和维护数据技术架构,包括元数据、集成和业务智能或数据仓库架构
此角色级别所需的技能
- 技术和非技术人员之间的沟通。您可以与技术和非技术利益相关者进行有效沟通。您可以在多学科团队中支持和主持讨论,这可能会带来困难。你可以在外部为团队辩护,也可以管理不同的观点。(技能等级:工作)
- 正在通信数据。您可以意识到数据需要与最终用户的需求保持一致。您可以创建基本的视觉效果和演示文稿。(技能等级:意识)
- 数据分析和综合。您可以进行数据分析和源系统分析。您可以向同事提供清晰的见解,以支持数据的最终使用。(技能等级:工作)
- 数据治理(数据架构师)。您可以了解需要什么样的数据治理。您可以负责保证数据解决方案,并提出建议以确保法规遵从性。(技能等级:工作)
- 数据创新。您可以通过新的工具和数据的使用来展示对创新机会的认识。(技能等级:意识)
- 数据建模。您可以解释数据建模的概念和原理。您可以根据组织的具体需求生成、维护和更新相关数据模型。您可以对实时系统中的数据模型进行逆向工程。(技能等级:工作)
- 数据标准(数据架构师)。您可以为特定组件开发数据标准。您可以分析数据标准被应用或违反的地方,并对违反情况进行影响分析。(技能等级:工作)
- 元数据管理。您可以使用元数据存储库来完成复杂的任务,如数据和系统集成影响分析。您可以维护存储库,以确保信息保持准确和最新。(技能等级:工作)
- 问题管理(数据架构师)。您可以启动和监控行动,以调查解决问题的模式和趋势。您可以在需要时有效地咨询专家。您可以确定适当的补救措施并协助实施。您可以确定预防措施。(技能等级:工作)
- 战略思维。你可以解释你工作的战略背景以及为什么它很重要。您可以以管理身份支持战略规划。(技能等级:意识)
- 将业务问题转化为数据设计。您可以通过处理特定的业务问题并将其与企业范围的标准和原则相一致来设计数据架构。您可以在理解良好的架构的上下文中工作,并确定适当的模式。(技能等级:工作)
高级数据架构师
高级数据架构师为组织提供由首席数据架构师设定的愿景。
在此角色级别,您将:
- 设计数据模型和元数据系统
- 帮助首席数据架构师解释组织的需求
- 为设计和生产数据人工制品的其他数据架构师提供监督和建议
- 数据字典管理的设计与支持
- 确保您的团队按照首席数据架构师为组织制定的标准工作
- 与技术架构师合作,确保组织的系统设计符合适当的数据架构
此角色级别所需的技能
- 技术和非技术人员之间的沟通。您可以倾听技术和业务利益相关者的需求,并对其进行解释。您可以有效地管理利益相关者的期望。您可以管理主动和被动通信。您可以在团队内部或与不同的高级利益相关者一起支持或主持艰难的讨论。(技能等级:从业者)
- 正在通信数据。您可以了解交流调查结果的适当媒体。你可以为观众塑造沟通。(技能等级:工作)
- 数据分析和综合。您可以进行数据分析和源系统分析。您可以向同事提供清晰的见解,以支持数据的最终使用。(技能等级:工作)
- 数据治理(数据架构师)。您可以发展和定义数据治理。您可以负责围绕更广泛的治理提供支持和协作。您可以保证并集成数据服务,以满足多种业务服务的需求。您可以积极主动地确保组织设计考虑数据的架构。(技能等级:从业者)
- 数据创新。您可以了解数据工具、分析技术和数据使用方面的新兴趋势对组织的影响。(技能等级:工作)
- 数据建模。您可以跨多个主题领域生成相关的数据模型。您可以解释将哪些模型用于何种目的。您可以了解行业认可的数据建模模式和标准,以及何时应用它们。您可以比较和调整不同的数据模型。(技能等级:从业者)
- 数据标准(数据架构师)。您可以跨多个主题领域开发和设置数据标准。您可以充当违反数据标准的升级点,并就组织应如何解决这些问题提出建议。(技能等级:从业者)
- 元数据管理。您可以设计适当的元数据存储库,并对现有元数据存储库进行更改。您可以了解一系列用于存储和处理元数据的工具。您可以为团队中缺乏经验的成员提供监督和建议。(技能等级:从业者)
- 问题管理(数据架构师)。您可以确保采取正确的行动来调查、解决和预测问题。您可以协调团队调查问题、实施解决方案并采取预防措施。(技能等级:从业者)
- 战略思维。您可以在战略背景下工作,并交流活动如何实现战略目标。你可以为战略和政策的制定做出贡献。(技能等级:工作)
- 将业务问题转化为数据设计。您可以设计处理跨不同业务领域问题的数据架构。您可以识别问题之间的联系,以制定通用的解决方案。您可以跨多个主题区域工作,也可以跨单个大型或复杂的主题区域工作。您可以生成适当的图案。(技能等级:从业者)
首席数据架构师
首席数据架构师根据适当的治理机构的指示,为组织使用数据设定愿景。
在此角色级别,您将:
- 监督多个数据模型的设计,并广泛了解每个模型如何满足组织的需求
- 负责支持和调整组织的数据战略
- 在内部以及通过政府最高层的合作和沟通来支持数据架构
- 为数据架构社区制定标准和工作方式
- 负责确保项目或企业级别的数据模型
- 为项目团队提供建议,并监督全数据产品生命周期的管理
- 负责确保组织的系统按照企业数据架构进行设计
此角色级别所需的技能
- 技术和非技术人员之间的沟通。您可以倾听技术和业务利益相关者的需求,并对其进行解释。您可以有效地管理利益相关者的期望。您可以管理主动和被动通信。您可以在团队内部或与不同的高级利益相关者一起支持或主持艰难的讨论。(技能等级:从业者)
- 正在通信数据。您可以将复杂的数据转化为清晰易懂的解决方案,并根据这些解决方案采取行动。您可以与团队和组织共享数据沟通技能。考虑到风险和不确定性,您可以理解并交流不同的选择。(技能等级:从业者)
- 数据分析和综合。您可以进行数据分析和源系统分析。您可以向同事提供清晰的见解,以支持数据的最终使用。(技能等级:工作)
- 数据治理(数据架构师)。您可以确保数据治理支持对组织战略的更改。您可以将数据治理与更广泛的治理(例如,预算)结合起来。您可以通过了解重要风险并通过保证机制提供缓解措施来确保公司服务。(技能等级:专家)
- 数据创新。您可以确定数据工具和技术的创新领域,并确定采用的适当时机。(技能等级:从业者)
- 数据建模。您可以理解数据建模的概念和原理,并可以生成相关的数据模型。您可以跨政府和行业工作,认识到在不同组织中重复使用和调整数据模型的机会。您可以设计对组织内的数据模型进行分类的方法。(技能等级:专家)
- 数据标准(数据架构师)。您可以为组织制定和设置数据标准。您可以传达数据标准的商业利益,在整个组织中支持和管理这些标准。你可以了解整个组织需要在哪里制定标准,以及如何在更广泛的政府背景下在组织内制定标准。(技能等级:专家)
- 元数据管理。您可以了解元数据存储库如何支持不同的业务领域。您可以宣传和交流元数据存储库的价值。您可以设置强健的治理流程,以保持存储库的最新状态。(技能等级:专家)
- 问题管理(数据架构师)。你可以预见问题并在正确的时间进行防御。你可以理解这个问题是如何融入全局的。你可以阐明问题并帮助他人这样做。你可以培养他人解决问题的能力。(技能等级:专家)
- 战略思维。您可以定义战略和政策,为其他人在战略背景下的工作提供指导。您可以评估当前的战略,以确保在可能的情况下满足并超过业务需求。(技能等级:从业者)
- 将业务问题转化为数据设计。您可以设计处理整个企业问题的数据架构。你可以在所有组织主题领域以及内部和外部项目中工作。(技能等级:专家)
- 14 次浏览
【数据架构师】首席数据架构师是什么?
QQ群
视频号
微信
微信公众号
知识星球
多年来,许多头衔被提议并用于主要的数据管理职位,如数据管理员(data administrator)、数据监护人(data guardian)、数据沙皇(data czar,)、数据保管人(data custodian)等。最近的一个头衔是数据统治者(data custodian),可能是为了管理数据治理功能。然而,数据是不可管理的,只有人才能被管理。[i] 最近的另一个头衔是数据科学家,大概是为了管理大数据。[ii]然而,这意味着小数据不需要数据科学家。
首要数据管理头衔的整个场景似乎是搜索一个有效的头衔,然后保留该头衔——这种场景被称为银弹头衔。这种情况只是数据管理中正在进行的炒作周期的另一种形式。它避免了对组织中的职位职责和职位位置进行精确定义。
该方案继续提出设立首席数据官的建议。好消息是,该提案最终承认,首席信息官(CIO)没有,也没有正确管理数据资源。提案还认识到数据和信息之间的区别,这意味着CDO管理数据资源,而CIO管理从该数据资源中产生的信息。然而,坏消息是,这些提议可能不会比以前的头衔更好。
首席信息官由首席财务官(CFO)演变而来,主要是因为数据处理起源于大多数组织的财务部门。随着数据处理演变为信息技术(IT),首席信息官的职位成为了IT的一部分。问题是首席信息官和IT从未将数据作为组织的关键资源进行充分管理,大量不同的数据阻碍了数据资源的有效利用,以支持运营和分析业务信息需求。
信息技术,包括首席信息官,通常是以硬件和软件为中心的。它主要涉及硬件和软件的获取、物理数据结构以及对数据的操作以产生信息。它很少对在单个组织范围的数据架构中正式设计和开发高质量的数据资源感兴趣。
这种取向不太可能随着CDO而改变。CDO保留了军官(Officer )的概念,并可能继续致力于硬件和软件的获取、数据库管理以及数据的物理操作。CDO不太可能根据业务需求将数据作为组织的关键资源进行正式设计和开发。收获甚微。
问题变成了如何解决不同的数据情况,从而满足业务信息需求?具体而言,公共和私营部门组织的头衔应该是什么,数据管理应该放在哪里,以确保组织的数据资源得到适当设计和实施,以充分支持运营和分析业务信息需求?
答案是建立一个首席数据架构师。首席数据架构师成立于20世纪90年代中期,旨在应对将组织的数据作为关键资源进行管理的挑战,并根据正式的概念、原则和技术建立一个单一的组织范围的数据架构,在该架构中正式设计和管理组织的数据。[ii]
建筑师是指设计和建议建筑的人;计划并实现困难目标的人;建筑大师。首席数据架构师是一名架构师,负责在单个组织范围内的数据架构中加快和促进高质量数据资源的设计和开发,以满足组织当前和未来的业务信息需求。首席数据架构师必须了解业务,并为业务、由业务和为业务服务。
首席数据架构师负责分析业务需求并综合解决方案。他们必须遵循业务理解、逻辑数据资源设计和物理数据资源实现的顺序。[iv]他们必须避免任何暴力的物理开发努力,阻止日益增长的数据差异,并解决现有的数据差异。
数据架构师为首席数据架构师工作,负责数据资源的详细设计和开发。数据建模师与数据架构师合作,生成数据体系结构的完整模型,包括正式名称、全面定义、适当的结构、精确的完整性规则和健壮的文档。数据架构师通常具有人员技能,数据建模师通常具有工具技能。两者都必须熟练地以商业专业人士基于他们对商业世界的感知而易于理解的方式来描述商业需求。[v]
首席业务架构师全面了解业务活动,并与首席数据架构师密切合作,设计和开发数据资源。它们加快并促进了单个组织范围内业务活动架构的开发,并解决了业务活动差异,而业务活动差异通常大于数据资源差异。他们确保业务专业人员能够清楚地解释他们的数据需求。
信息技术管理硬件、系统软件、数据库、系统升级、备份/恢复、数据存储和检索、性能、迁移等。IT中的数据库专业人员与数据架构师和数据建模师合作,在不影响逻辑设计的情况下实现逻辑设计。
一个小型组织可能只有一名首席数据架构师。一个中等规模的组织可以有一名首席数据架构师和一名或多名数据架构师和数据建模师。较大的组织可以有首席数据架构师、高级数据架构师和数据建模师,以及初级数据架构师和数字建模师。
首席数据架构师必须位于业务的执行层,而不是IT层,以确保数据资源的设计和开发从业务需求到逻辑设计再到物理实现。该职位必须相当于财务、人力资源和设施管理总监,并且必须负责所有业务职能。数据架构师和数据建模师可分配给首席数据架构师,或分配给特定的业务职能或主题领域。根据组织的规模、结构和工作量,可以根据需要永久定位或分配它们。基本原则是,他们必须遵循正式的数据资源设计和开发规则,就像遵循财务规则、人力资源规则或物业管理规则一样。
对于主要的数据管理职责,有一些指导方针。在以下情况下,公共和私营部门组织有更好的机会成功管理其作为组织关键资源的数据:
- 将数据作为一种关键资源进行管理的主要职责位于业务部门而非IT部门,并且与首席信息官分开。
- 首席数据架构师的主要职责延伸到所有业务职能。
- 高质量数据资源的设计和开发受当前和未来运营和分析业务信息需求的驱动,并基于正式的概念、原则和技术。
- 数据资源是在单个组织范围内的数据架构中设计和开发的,避免了多个独立和竞争的数据架构,并防止了数据差异。
- 数据资源的设计和开发从业务需求到逻辑设计再到物理实现,避免了任何暴力的物理方法。
- 商业专业人员积极参与数据资源的设计和开发。
- 数据库专业人员积极参与数据资源的物理实现和操作,而不影响逻辑设计。
- 在数据资源的设计、开发和实施以及从该数据资源中准备信息之间建立了团队合作方法。
数据资源管理的主要责任——将数据作为组织的关键资源进行管理——必须由业务部门承担,因为包括首席信息官在内的IT部门没有将数据作为关键资源进行充分的管理。首席数据架构师必须领导数据资源管理,必须位于行政级别,并且必须负责所有业务职能。首席数据架构师加快并促进业务信息需求的分析、支持这些需求的数据资源的逻辑设计以及该设计的物理实现。
首席信息官负责开发数据资源中的信息。数据库专业人员将留在IT部门,只要他们正确地实现了逻辑设计。否则,该职能必须由首席数据架构师负责。
如果数据管理专业人员和业务专业人员希望开发出能够充分支持其运营和分析业务信息需求的高质量数据资源,则他们必须积极推动和支持首席数据架构师的创建。没有设立首席数据架构师的组织失败的几率更大。
- 7 次浏览
【数据架构趋势】2023年5大云数据架构趋势
QQ群
视频号
微信
微信公众号
知识星球
最初是作为我的substack时事通讯的一部分发布的
你也可以阅读我去年关于2022年数据趋势的文章

亲爱的朋友们,您好!我希望你们在2022年取得圆满成功!
介绍
在这篇文章中,我将写下5个数据趋势,我认为这些趋势将是2023年数据企业的首要任务。这是基于我在过去2-3个月里参加的多次网络研讨会、会谈和峰会。
让我们开始吧!
2023年趋势-目录
- ·湖屋(Lakehouse)架构
- ·数据网格
- ·数据治理
- ·实时处理/流媒体
- ·数据体系结构和数据建模
湖屋架构
这是大多数峰会/网络研讨会上谈论最多的举措之一。
现在每个人都想建造一个湖屋,而不是数据仓库和数据湖。所有领先的数据平台现在都有用于实现lakehouse的产品/功能。
- Databricks是市场领导者,最好的解决方案似乎是Spark&Delta lake的创始人。
- Apache Iceberg正在被Athena、EMR和Glue等AWS服务所采用。
- Snowflake现在支持使用Iceberg表实现lakehouse。
似乎有一个明显的转变,即建造湖边小屋,而不是企业仓库。如果你还没有探索过湖屋,现在是阅读和了解它的工作原理及其优势的合适时机。
数据网格
整个2022年,我一直在听说数据网格架构。每个现代数据企业似乎都在讨论并计划实施它。但这并不是那么容易。
数据网格不仅仅是一个架构上的改变,它是一个组织级的举措,需要改变人们对数据的拥有和管理方式以及谁应该拥有和管理数据的观念。
数据网格基于4个主要支柱。
- 领域所有权-领域团队对其数据负责。
- 数据即产品-领域团队应将其数据视为产品,并将其提供给其他领域或下游消费者。
- 自助数据基础设施-专门的团队管理数据平台,并使领域团队能够利用该平台进行用例。
- 联合治理-跨领域数据产品的标准化,使其更易于管理、共享并遵守行业和监管标准。
阅读更多关于数据网格的信息,了解它的含义。如果你是数据世界的新手,你可能需要了解它如何在当今的现代数据世界中发挥作用。
数据治理
数据治理是一个需要讨论和理解的广泛话题。它包括几个以更好的方式管理数据的计划。
作为数据治理的一部分,一些举措包括
- 数据质量-验证和改进
- 元数据管理和数据发现
- 数据审计和数据排列/数据沿袭
- 访问控制和安全的数据共享
- 管理主数据
- 定期审查流程
这些都不是新的,并且已经实施了多年,用于管理仓库中的数据。然而,在管理数据湖或数据库中的数据时,它们中的大多数都具有挑战性。
没有多少组织成功地针对存储在云对象存储中的非结构化数据实现了这些功能。您可能会在组织中看到使用现代数据堆栈来实现这些功能的新举措。
市场上有多种产品可用于实现其中的每一种,这使得为您的特定用例找到合适的产品变得更加困难。Lakehouse、Data Mesh、Data Products和Data Market Place等新的架构模式和用例将使数据治理变得更加关键和具有挑战性。
实时处理/流
传统的数据仓库是在EoD(一天结束)或SoD(一日开始)作为一个批处理过程填充的。BI用户很乐意每天看到一次他们的数据(正确和完整)。但随着时间的推移,现在的决策更加实时。
您现在想要信用卡欺诈或未经授权访问的即时警报。即使是实时电影推荐或快闪销售警报也需要快速决策。
随着世界向更实时的用例发展,对实现能够支持此类流分析的架构的需求将很大。2023年,许多企业可能会开始支持流媒体、近实时或微批量用例的旅程。
数据架构和数据建模
最后,这是我最喜欢的一个——更多地关注数据架构和数据建模。
这些是实现数据平台的构建块。从长远来看,获得正确的架构蓝图和合适的建模策略来存储数据会有所帮助。
随着Hadoop的兴起,数据建模已经退居二线。在没有任何建模指导的情况下,任何形状和形式的数据都被倾倒在湖中。这很快导致了数据沼泽( data swamps ),使得发现和使用数据变得极其困难。
自去年以来,我听到许多行业专家谈论对正确架构和建模的需求。数据建模器的需求似乎又回来了,企业现在希望使用最合适的建模方法——维度模型或数据保险库(Data Vault)——将数据存储在湖泊、湖边小屋或仓库中。
这无疑是构建数据平台的一个重要方面。密切关注围绕数据架构和数据建模的各种讨论。
总结
2023年你应该注意的5个数据趋势
- 湖屋架构
- 数据网格
- 数据治理
- 流媒体/实时处理
- 数据架构和数据建模
感谢您的阅读,并祝2023年一切顺利!
- 15 次浏览
【数据架构需求】数据架构要求
QQ群
视频号
微信
微信公众号
知识星球
好吧,所以这篇文章不会真正提供任何关于预定义数据体系结构的细节,但它确实强调了构建数据体系结构时的一些首要任务。如果您对需求和高级思想感兴趣,请继续阅读,否则请等待下一篇文章:)
因此,为了构建一个功能良好的数据环境,我们必须定义一些基本需求。我们应该努力建立一个适应性强、可持续的数据环境,能够满足您的所有数据需求,包括ML/AI、分析、数据应用程序或其他任何东西。一些数据平台供应商会说,你只需注册,你想要的一切都已经得到了考虑,但事实远非如此。数据架构由许多模块组成,这些模块必须相互交互和“馈送”,就像任何生态系统一样…
根据我的说法,这些是数据架构最重要的要求。是的,无论您喜欢的方法是集中式数据仓库、数据仓库、数据库、数据结构、数据网格还是孤立的ML/AI项目,这些要求都是一样的。
让我们将需求分组到几个桶中。交付、数据信任、适应性、成本、技术和可移植性等等!
General data architecture requirements
1.交付(Delivery)
能够以尽可能低的延迟交付数据。这适用于新的需求,但也适用于持续的增强。别忘了,我们需要我们的数据提供给可能关心的人,而且只提供给他们,但要简单地查找、访问和理解

It’s all about the ability to deliver value… fast!
实现价值的时间短
- 原因:简单地说,就是快速满足新需求的能力。
- 如何:在所有事情上引入“自动化优先”的方法。努力实现那些可以自动化的部件的自动化。它不仅加快了开发速度,还将提高您的整体质量,并实现非常纤薄的维护。不符合可用自动化模式的东西应该分开。
以下是我们可以实现自动化以提高生产力和质量的领域列表。
- 代码生成
- 流式处理和批处理自动化
- 测试自动化
- 自动数据验证和筛选
- 自动化部署
- 自动访问控制
- 自动化数据词汇表
如果我们学会了如何激活可用的元数据,这并不难。
访问数据
- 为什么:我们必须允许数据发现和简化访问,同时确保隐私和数据完整性!
- 如何:以景观为目标,我们可以搜索数据,了解数据并请求访问。当被授予(希望是自动化的)时,我们应该能够使用我们选择的工具集访问数据,只需单一登录,没有(低)代码。访问权限应该易于授予和撤销。我们的数据环境的所有部分都应该包括在内,并且访问政策适用于所有地方。重要的是,您的数据架构支持通用访问安全层,这样就可以实现单一的管理点。启用支持轻松访问所需数据的框架,消除数据格式和连接库等障碍。
2.数据信任
第二个最重要的需求是数据信任。基本上,这是围绕着可追溯性展开的。我们在使用什么,数据是如何被更改的,为什么被更改,由谁更改,何时更改?还有谁在使用数据集?数据集的新鲜度和准确性如何?这些都是任何数据消费者都应该问的问题,因此答案应该掌握在掌握范围内。

How do we achieve data trust?
可追溯性
- 为什么:数据的一个非常重要的方面是数据来源、谁或什么处理了数据以及如何处理。数据出现在什么上下文(模型)中?谁消费它,谁拥有它?(如果可能…)
- 如何:所有流程都应该生成和使用元数据。从一个特定数据产品的初始发布开始,经过任何中间过程,直到最终消费。如果我们调整流程以使用元数据作为规范,并自动发现已发布的结果。根据定义,我们将激活元数据,使其准确并更新。因此,我们的元数据将具有更高的质量,并且绝对正确。
审计能力
- 原因:数据信任的另一个重要方面是能够看到谁、什么、什么时候发生了什么以及为什么发生。
- 如何:跟踪所有内容的更改。在跟踪更改时不要引入选择。应跟踪所有数据、所有代码和所有描述性信息的更改。这是确保100%审计跟踪的唯一方法。不允许手动编辑代码、模型或数据,并引入临时数据。
数据(质量)可观测性
- 为什么:我们必须能够信任我们消费的数据。努力不是为了拥有完美的数据质量,而是为了在数据不是最优的时候突出显示。努力获取数据,当数据不符合时发出警告。请记住,数据质量也是非常主观的,对一个消费者来说,糟糕的数据质量可能对另一个消费者是好的数据质量。。。
- 如何:当数据偏离预期结果时,我们应该能够创建警报、警告和/或通知。例如;
- 当流程没有按照应有的方式进行预成型时。
- 当数据丢失和/或暂停时。
- 当一个数据集与另一个数据集中没有“相加”时
- 出现缺失值时
- 出现新值时
- 当数据出现异常时
正如在组织内定义KPI一样自然,也应该定义“质量绩效指标”。
持久性和非易失性
- 原因:通过日复一日地提供稳定和可预测的结果,实现数据信任。
- 如何:确保我们根据已知的数据管理最佳实践对数据进行建模和结构化。
- 保持历史记录并使数据在一段时间内具有可比性。
- 添加新数据时,不应删除以前的数据。
- 应保留历史数据,以便进行比较、趋势和分析。
- 使用物理数据建模实践,使我们能够保留以前的数据并附加新的数据。
- 如果可能的话,争取只插入模式,并将数据与现在的数据结合起来呈现。
- 至少引入一种双时态方法。
合并和集成
- 为什么:围绕键和概念集成数据可以实现简单和可扩展的使用,而不会引入手动错误。将数据整合到单个来源点可以最大限度地减少数据的滥用。
- 如何:将数据建模为清晰简洁的数据模型。使用数据建模实践,使您能够适应和扩展新的属性、对象和上下文。事实上,我们的数据环境应该允许多个上下文/模型,而不会丢失对来源的跟踪。找到需要整合和集成的概念,并在建模任务上花费时间。暂停或丢弃当前纯粹隔离(或面向单个域)的用例的数据,直到出现跨域使用的用例。这使我们能够专注于重要的任务,并为那些具有高业务影响的事情整合对象、属性、上下文和度量。
3.适应性
一切都在变化…我们的业务、竞争对手、技术、源系统、数据消费模式、需求和人员。事实是,当我们的数据环境增长时,会引入更多的变化。对于我们与之互动的每一个系统,其发展速度都会发生变化。随着我们消费和分析越来越多的数据,我们将需要更多的数据。因此,它甚至不是变化的线性增长,而是变化的指数增长。因此,我们的数据环境必须以适应性为首要任务。
有适应能力的(Adaptable)
- 原因:变化会发生,也降会发生。
- 怎样:
- 启用源代码一致的数据合同/产品,确保我们的交付流程具有稳定性。
- 通过从元数据构建通用流程或生成的流程,我们可以简单地更改映射的目标或源方面。
- 允许数据驱动的分类和业务规则,并将其推送给下游运营者。
- 将分类和业务规则视为源数据。
- 使用喜欢变化的整体建模方法。
- 引入时间数据结构。
- 努力在所有选定的工具中使用数据结构的动态分配。
数据建模
- 原因:任何信息都是无用的,除非以用户可以使用的格式传递。数据建模有助于将用户的需求转化为可用于支持业务流程和规模分析的数据模型。
- 如何:没有上下文和集成的数据很快就会失去价值。一个好的数据模型将在不破坏质量的情况下引入数据的扩展使用和探索。
- 使用集合数据模型,花时间集成和规范术语和对象。
- 为具有特定格式的特定用例在集成数据模型之上创建语义模型。
(去)集中
- 原因:同样的集中式流程,无论是否与数据有关,总是比同样的去集中式方法慢,因为从定义上讲,它无法扩展。然而,去中心化的方法更难协调一致。
- 如何:使用通用方法和基础架构实现去中心化。精简通用模式和定义可以帮助并行化数据处理,而不会失去控制。基于元数据发现的自动化通用过程将允许模式重新分解,而无需重新构建现有功能。集中数据环境中在去集中化时能够实现最佳效果的部分。一次又一次地重复该策略。
4.成本
毫无疑问,在我的经验中,成本是进行任何形式转换最常见的用例。关注成本变得越来越重要,因为成本可能不像以前那么清楚……今天,许多成本都是基于消费的。因此,硬件和人员配置不像以前那样可预测。一个糟糕实现的功能可能无法扩展,因此随着时间的推移,成本会越来越高。一个糟糕的工具选择可能需要我们的开发人员花更多的时间来掌握。性能较低的平台可能需要较长的等待时间,这些时间可能会花在其他任务上。所有这些例子都是浪费成本,可以通过政策和信任来避免。
Balance COST vs. PERFORMANCE on both tech and staff
简单
- 为什么:不那么复杂的系统成本更低
- 如何:尽量将复杂性隐藏在简单的工具、任务和结构中。制定可重复的模式,并从任何维护任务中收集知识。努力用简化的流程取代复杂的流程。
易于学习,易于掌握
- 为什么:将新的个人引入数据环境应该是一个短暂而顺利的过程。花在引进上而不是生产上的每一天都是沉没成本。
- 怎样:
- 在数据环境的所有部分使用简单而高效的接口。
- 避免编写脚本和键入命令,而是在UI中嵌入功能。
- 对每个数据点具有完整的可追溯性。理想的情况是,只需单击一下,就可以看到原始数据的来源以及所有/任何转换。
- 如果开发模式相同,那么理解和产生新功能将更加顺利。
- 每一次技术故障都应该能够一次又一次地运行,而不会产生新的结果。这可以防止由于打嗝和糟糕的操作而导致的错误,还有一个额外的好处,即关于故障处理的决策将更容易做出。
- 最后,一个干净的架构使它能够透明地了解发生什么、为什么发生以及在哪里发生,从而更快地进行故障排除。
低拥有成本
- 为什么:支付所需的计算费用,而不是更多,按需扩展,并简化维护任务。
- 怎样:
- 标准化流程(开发和运营)。
- 优化我们的接入点并利用可扩展的平台。
- 明智地使用缩放,将不良模式转换为更具成本效益的模式。
- 确保所有运行代码的标准和原则一致。
- 尝试使用可以上下扩展的平台,希望不要将计算与存储捆绑在一起。
可预测的
- 原因:使用基于消费的价格模型有时会感到不确定和可怕。SaaS和云产品的价格可能会突然发生变化,这与我们想要的正好相反。技术的正确选择实际上是成本/性能的平衡。
- 如何:考虑分析、直接访问或基于内存的过程。什么最适合我们的用例。也许两者兼而有之?
- 构建尽可能精简的管道,只使用更改的数据,或者至少使用可预测的数据块。
- 根据自身和备选方案分析和比较成本。
- 使数据环境中的组件可移植,并且不在特定技术上投入太多,防止技术锁定。谁知道呢,我们首选的SaaS可能会突然改变他们的价格模式,并危及整个设置。
5.技术
数据环境应被视为其自身的应用程序,并与源系统分离。这种明显而简单的方法使我们能够为用例优化工作负载,并使我们能够根据业务需求和未来场景对数据进行建模,而不与源系统绑定。
分离的(Separated)
- 为什么:将数据环境与源系统分离。针对用例进行优化,并针对未来进行构建。
- 如何:分离的平台、基于用例的数据模型、数据接收管道或发布模式。
并行且可缩放
- 为什么:我们的工作负载必须能够并行执行,并能够纵向和横向扩展,从而实现更多的流程和更多的消费者。
- 如何:首先保护一个或多个允许同时使用和并行读/写的数据平台。其次,流式数据与批处理数据相结合的安全模式。最后,将数据建模到物理模型中,以实现独立加载。
可变数据格式
- 为什么:一个好的数据环境可以支持所有格式的数据,无论它是结构化的、半结构化的还是非结构化的。
- 如何:通过允许数据以本机格式上传、自动分析并在数据发现目录中发布,简化数据发布过程。将数据复制为“单一”符合要求的数据格式,以便于访问和使用。
可访问性
- 原因:开放的数据环境使我们的数据消费者能够使用他们熟悉和熟悉的工具,从而提高生产产品的质量。
- 如何:让我们的数据环境变得灵活,因为新的工具和用户可以很容易地从调色板中添加或删除。然而,数据访问限制了可能性。这使我们能够更加数据驱动和灵活地处理数据,同时能够完全控制数据的完整性。相反,将消费锁定在用户甚至可能没有能力使用的选定工具集上,从而危及生产产品的质量。
6.可移植性
我们今天选择的技术在几年内可能不会那么突出。价格模型可能会改变,技术可能无法满足当前的工作量。也许我们的合作已经与另一家供应商达成了战略协议。无论如何,在可预见的时间内,有很多可能性,很难做出最佳的技术选择。

可移植的
- 原因:新技术以惊人的速度发展,云计算成本也在不断变化。新的用例出现,个人技能不断发展。为了避免我们的数据环境出现“遗留”品牌,我们必须将技术和成本与我们的用例和技能集相一致。
- 如何:接受我们的架构并不完美的事实。充分利用它。让每个组件尽可能少地负责,并尽可能多地自动化流程。使元数据处于活动状态,这意味着使用元数据作为我们自动化流程的中心组件。从元数据中生成代码、结构和配置,并尝试使用广泛接受的语言来处理数据,如SQL、python等。
总结
设置为适应而构建的数据环境。任何代码、模块和/或组件都应可移植到另一个平台、技术堆栈和/或服务。
接受我们的数据架构永远不会完美的事实,接受缺陷,但要构建自动化流程。代码和结构应该是生成的,或者是通用的,并且基于元数据。当我们面临必须更换某些东西的事实时,这样可以更容易地进行迁移。
确保我们在可重复任务上花费尽可能少的时间,在数据建模和定义上花费越来越多的时间。使用具有时间-时间概念的集成建模。这将使我们的系统更加稳定,并承受核心业务系统/流程的重大变化/重构。
始终专注于简化访问、数据发现、访问模式、结构简化和改进。
- 12 次浏览
【数据演进架构】消息模式演化与兼容性
模式演化
数据管理的一个重要方面是模式演化。在定义了初始模式之后,应用程序可能需要随着时间的推移对其进行改进。当这种情况发生时,下游消费者能够无缝地处理新旧模式编码的数据是至关重要的。这是一个容易在实践中被忽视的领域,直到您遇到第一个生产问题。如果不仔细考虑数据管理和模式演化,人们通常会在以后付出更高的成本。
在使用Avro时,最重要的事情之一是管理它的模式,并考虑这些模式应该如何发展。Confluent模式注册表正是为此目的而构建的。模式兼容性检查是在模式注册表中通过对每个模式进行版本控制来实现的。兼容性类型决定模式注册中心如何将给定主题的新模式与模式的先前版本进行比较。当第一次为主题创建模式时,它将获得一个惟一id和一个版本号,即版本1。当模式被更新时(如果它通过兼容性检查),它将获得一个新的惟一id和一个递增的版本号,即版本2。
兼容性类型
总结
下表总结了针对给定主题的不同兼容性类型允许的模式更改类型。Confluent模式注册表默认兼容性类型是向后的。所有兼容性类型将在下面的小节中详细描述。
| Compatibility Type | Changes allowed | Check against which schemas | Upgrade first |
|---|---|---|---|
BACKWARD |
|
Last version | Consumers |
BACKWARD_TRANSITIVE |
|
All previous versions | Consumers |
FORWARD |
|
Last version | Producers |
FORWARD_TRANSITIVE |
|
All previous versions | Producers |
FULL |
|
Last version | Any order |
FULL_TRANSITIVE |
|
All previous versions | Any order |
NONE |
|
Compatibility checking disabled | Depends |
向后兼容性
向后兼容性意味着使用新模式的用户可以读取使用最后一个模式生成的数据。例如,如果一个主题有三个模式按照X-2、X-1和X顺序变化,那么向后兼容性可以确保使用新模式X的消费者可以处理使用模式X或X-1(但不一定是X-2)的生产者编写的数据。如果使用新模式的使用者需要能够处理由所有已注册模式(而不仅仅是最后两个模式)编写的数据,那么使用BACKWARD_TRANSITIVE而不是BACKWARD_TRANSITIVE。例如,如果一个主题有三个模式按照X-2、X-1和X顺序变化,那么BACKWARD_TRANSITIVE兼容性可以确保使用新模式X的消费者可以处理使用模式X、X-1或X-2的生产者编写的数据。
- 向后:使用模式X的使用者可以处理使用模式X或X-1生成的数据
- BACKWARD_TRANSITIVE:使用模式X的使用者可以处理模式X、X-1或X-2生成的数据
请注意
Confluent模式注册表默认兼容性类型是向后的,而不是向后传递的。
向后兼容更改的一个例子是删除字段。开发用于处理事件而没有该字段的使用者将能够处理用旧模式编写的事件并包含该字段——使用者将忽略该字段。
考虑这样一种情况,Kafka中的所有数据也都加载到HDFS中,我们希望在所有数据上运行SQL查询(例如,使用Apache Hive)。在这里,重要的是,即使随着时间的推移数据正在发生变化,相同的SQL查询也要继续工作。为了支持这种用例,我们可以以向后兼容的方式演进模式。Avro有一组规则,规定允许在新模式中进行哪些更改,以使其向后兼容。如果所有模式都以向后兼容的方式发展,我们总是可以使用最新的模式统一地查询所有数据。
例如,一个应用程序可以通过添加一个新的字段favorite_color将用户模式从上一节发展到下一节:
{"namespace": "example.avro",
"type": "record",
"name": "user",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": "int"},
{"name": "favorite_color", "type": "string", "default": "green"}
]
}
注意,新字段favorite_color的默认值是“green”。这允许用旧模式编码的数据可以用新模式读取。当反序列化用旧模式编码的数据时,新模式中指定的默认值将用于缺失的字段。如果在新字段中省略了默认值,新模式就不会与旧模式向后兼容,因为不清楚应该为新字段分配什么值,而旧数据中没有这个值。
请注意
Avro实现细节:查看Apache Avro项目中的ResolvingDecoder,以了解对于使用旧模式编码的数据,Avro如何使用更新的、向后兼容的模式对数据进行解码。
向前兼容性
正向兼容性意味着使用新模式生成的数据可以被使用最后一个模式的消费者读取,即使他们不能使用新模式的全部功能。例如,如果一个主题有三个模式按照X-2、X-1和X顺序变化,那么正向兼容性可以确保使用新模式X的生产者编写的数据可以由使用模式X或X-1的消费者处理,但不一定是X-2。如果使用新模式生成的数据需要由消费者使用所有已注册的模式(而不仅仅是最后两个模式)读取,则使用FORWARD_TRANSITIVE而不是FORWARD。例如,如果一个主题有三个模式按照X-2、X-1和X顺序变化,那么FORWARD_TRANSITIVE兼容性可以确保使用新模式X的生产者编写的数据可以被使用模式X、X-1或X-2的消费者处理。
- 向前:使用模式X生成的数据可以由使用模式X或X-1的消费者准备好
- FORWARD_TRANSITIVE:使用模式X生成的数据可以由模式X、X-1或X-2的消费者准备好
向前兼容模式修改的一个例子是添加一个新字段。在大多数数据格式中,即使在接收包含新字段的新事件时,为处理事件而编写的使用者也可以继续这样做。
考虑这样一个用例,其中消费者将应用程序逻辑绑定到模式的特定版本。当模式发展时,应用程序逻辑可能不会立即更新。因此,我们需要能够将具有新模式的数据投影到应用程序能够理解的(旧的)模式上。为了支持这个用例,我们可以以向前兼容的方式演进模式:用新模式编码的数据可以用旧模式读取。例如,我们在前一节中讨论的向后兼容性的新用户模式也与旧用户模式向前兼容。当将使用新模式编写的数据投影到旧模式时,只需删除新字段。有新模式把原始字段favorite_number(数字,不是颜色),它不会向前兼容原始用户模式,因为我们不知道如何填写的值favorite_number为新数据,因为最初的模式没有为该字段指定一个默认值。
完整的兼容性
完全兼容意味着模式既向后兼容又向前兼容。模式以完全兼容的方式发展:可以用新模式读取旧数据,也可以用最后一个模式读取新数据。例如,如果有三个模式为主体,改变X - 2, X - 1,然后X完全兼容性确保消费者使用新模式可以处理数据由生产者使用模式X或者X - 1,但不一定是X - 2,使用新的模式和数据由生产商可以由消费者使用模式处理X或者X - 1,但不一定是X - 2。如果新模式需要向前和向后兼容所有已注册的模式,而不仅仅是后两个模式,那么使用FULL_TRANSITIVE而不是FULL。例如,如果有三个模式为主体,改变X - 2, X - 1,然后X FULL_TRANSITIVE兼容性确保消费者使用新模式X可以处理数据由生产者使用X, X - 1,或X - 2,和数据由生产商使用新模式可以被消费者使用模式处理X, X - 1,或X - 2。
- FULL:模式X和X-1之间的向后和向前兼容
- FULL_TRANSITIVE:模式X、X-1和X-2之间的向后和向前兼容
在一些数据格式中,如JSON,没有完全兼容的更改。每个修改要么只向前兼容,要么只向后兼容。但是在其他数据格式中,比如Avro,可以使用默认值定义字段。在这种情况下,添加或删除具有默认值的字段是完全兼容的更改。
没有兼容性检查
无兼容性类型意味着禁用模式兼容性检查。
有时候我们会做出不兼容的改变。例如,将字段类型从Number修改为String。在这种情况下,您将需要升级所有的生产者和消费者同时新模式版本,或者更有可能的是,创建一个全新的话题,开始将应用程序迁移到使用新的话题和新的模式,避免了需要处理两个不兼容的版本相同的话题。
传递属性
一旦给定主题的模式有两个以上版本时,传递兼容性检查就非常重要。如果兼容性被配置为传递的,那么它将检查新模式与所有以前注册的模式的兼容性;否则,它只检查新模式与最新模式的兼容性。
例如,如果一个主题有三个模式以X-2、X-1和X的顺序变化,则:
- 传递性:确保X-2 <==> X-1和X-1 <==> X和X-2 <==> X之间的兼容性
- 非传递性:确保X-2 <==> X-1和X-1 <==> X之间的兼容性,但不一定是X-2 <==> X
请参考模式更改的示例,这些更改在增量上兼容,但在传递上不兼容。
Confluent模式注册表默认向后兼容类型是非传递的,这意味着它不是BACKWARD_TRANSITIVE。因此,仅针对最新模式检查新模式的兼容性。
升级客户端顺序
所配置的兼容性类型对升级客户机应用程序的顺序有影响,即,生产者使用模式将事件写入Kafka,消费者使用模式从Kafka读取事件。取决于兼容性类型:
BACKWARD_TRANSITIVE或BACKWARD_TRANSITIVE:不能保证使用旧模式的用户可以读取使用新模式生成的数据。因此,在开始生成新事件之前升级所有消费者。
FORWARD或FORWARD_TRANSITIVE:不能保证使用新模式的用户能够读取使用旧模式生成的数据。因此,首先将所有生产者升级到使用新模式,并确保使用旧模式生成的数据对消费者不可用,然后升级消费者。
FULL或FULL_TRANSITIVE:可以保证使用旧模式的消费者可以读取使用新模式生成的数据,使用新模式的消费者可以读取使用旧模式生成的数据。因此,您可以独立地升级生产者和消费者。
NONE:禁用兼容性检查。因此,您需要对何时升级客户机保持谨慎。
例子
上面的每一部分都有一个兼容性类型的示例。另一个参考是Avro兼容性测试套件,它提供了具有两个模式的多个测试用例,以及它们之间兼容性测试的各自结果。
原文:https://docs.confluent.io/current/schema-registry/avro.html
本文:https://pub.intelligentx.net/message-schema-evolution-and-compatibility
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 58 次浏览
【数据趋势】2024新兴数据趋势-保持领先地位!
QQ群
视频号
微信
微信公众号
知识星球
数据日益增长的主导地位清楚地表明了它在各个行业和流程中的影响力。当我们发现2023年已经过半时,思考未来18个月数据管理平台可能会发生什么至关重要。我坚信,随着2024年的临近,许多公司将到达一个关键的十字路口,认识到利用数据和智能的关键必要性——要么是现在,要么永远不是人!
为了蓬勃发展并保持领先地位,组织必须接受关键的数据管理趋势,这些趋势将为成功指明方向。新技术唾手可得,如果你还没有出于战略考虑接受它们,那么你就已经落后了。
在即将到来的趋势中,我精心挑选了一些有望重塑数字格局的热门趋势——一如既往,我很想听听你对它们的看法。
1.开创了织物和网格的数据民主化
数据民主化,即让组织内所有人都能访问数据的做法,无论他们的技术熟练程度如何,最近得到了很大的推动——我上周在LinkedIn上简要谈到了这一点。以ThoughtSpot、Domino data Lab、K2view等平台为例,数据结构和网格等创新在数据民主化方面发挥了关键作用。
数据结构代表了一种数据管理体系结构,它将来自不同来源的数据和谐地集成到一个统一的、易于访问的视图中。同时,mesh增强了领域专家的能力,使他们能够更好地控制自己的数据,同时增强数据质量和治理。这些架构有助于确保数据民主化,提供快速访问,促进更快的决策,并通过集中访问控制和存储库确保提高数据质量和安全性。
2.采用工业4.0技术进行数据洞察
工业4.0是第四次工业革命的代名词,它利用自动化、数据分析和人工智能打造智能工厂。数据分析是工业4.0的基石,通过识别优化机会和防止缺陷,提供了提高效率、生产力和质量的巨大潜力。
例如,考虑一下数据分析如何预测机器故障,从而实现主动维护并最大限度地减少停机时间。这项技术并不局限于制造业;从2023年到2030年,它以惊人的16.3%的复合年增长率增长,可能使该行业的估值达到惊人的3770亿美元。
3.通过数据屏蔽提升GDPR合规性
数据屏蔽是保护客户和员工隐私、同时降低数据泄露风险的关键策略。它涉及编辑分析和机器学习中使用的数据集中的敏感数据,防止违反GDPR,如分析或定向营销。
数据屏蔽可以产生假名数据集,用人工标识符取代个人数据,从而加强隐私保护。K2View以其全面的数据屏蔽解决方案而闻名,包括编辑、标记化、去标识、假名化和数据混淆,确保遵守GDPR、CCPA和HIPAA等数据隐私法规。
4.DataOps的出现
DataOps是一种简化数据收集、准备、分析和交付的方法,在各个行业都越来越受欢迎。通过优先考虑跨职能协作、自动化、版本控制以及持续集成和交付,DataOps解决了常见的数据团队挑战,如数据孤岛、开发周期延长和缺乏灵活性。
自动化的数据管道和标准化的流程确保了一致的数据验证、清理和转换,提高了衍生见解的准确性和可靠性。传统的数据管理方法往往会解决瓶颈和延迟问题,而DataOps强调自动化和持续集成,使组织能够快速迭代,及时提供见解,并促进快速决策。
有一点是明确的:组织必须为即将到来的数据革命做好准备。随着数据的重要性持续飙升,主动适应和利用新兴趋势的企业将获得显著的竞争优势。在人工智能集成的进一步推动下,曾经为特定企业保留的技术将变得可供中小企业使用。未来在召唤着你——你准备好了吗?
请在评论中分享你的想法,如果你还想补充什么,请告诉我?
如果你想了解更多关于如何通过保护和留住前5%的数据人才来获得行业竞争优势的信息,请随时给我留言,我很乐意与你聊天。
- 13 次浏览
【数据领导力】现代数据领导力的策略
QQ群
视频号
微信
微信公众号
知识星球
在过去的20年里,通过我对数据和分析世界的参与,一些关键挑战不断重复。
尽管这些年来我们的业务需求和支持技术发生了巨大的变化,但数据领导者、顾问和分析师处理这些反复出现的问题的方式基本上没有变化。因此,我们未能朝着我们的目标取得进展——更重要的是,我们往往未能使数据在当今公司中可以发挥但往往不能发挥的变革作用合法化。
我怎么知道这是真的?本着数据驱动的精神,我将让数字不言自明:只有24%的公司将自己描述为“数据驱动”;只有30%的CDO表示,他们正在通过数据和分析实现ROI目标;只有44%的数据和分析领导者表示,他们的团队能够有效地为组织提供价值。
现代数据领导者的演变
CDO长期无法提供商业价值,这使我们走到了我认为是角色演变的转折点。数据领导者最终会想出如何克服他们的挑战吗?还是CDO的作用会慢慢被企业遗忘?
当你分析这些数字以了解CDO成功的核心驱动因素(或抑制剂)时,你会发现,在一次又一次的调查中,一些相同的核心可交付成果一再缺乏吸引力。
其中包括未能:
- 通过在数据管理和治理方面的投资提供有形的业务价值
- 建立和促进数据文化
- 以及定义和实现数据治理框架——仅举几个例子。
对大多数人来说,这些失败正是CDO的核心责任。因此,CDO的任期仍然是首席信息官的一半也就不足为奇了——尽管现在80%以上的公司都有CDO的职位。
作为一名Gartner分析师,我的工作是帮助CDO取得成功并克服挑战。在这个职位上,我每天都与多位数据领导者交谈,并就我们已经接受的学科中已证明的最佳实践向他们中的1000多人提供建议。尽管我真诚地希望我的客户取得成功,但许多客户没有成功,这让我在过去两年的大部分时间里都在努力理解原因。
数千次咨询中的领导力收获
当我回顾过去四年中我与数千名数据领导者、顾问和分析师的对话时——其中许多都是与同一个人和公司长期进行的——有几件值得注意的事情:
- 很大一部分数据领导者在很大程度上忽略了我们所知道的有助于改进数据管理的许多步骤。原因有很多,但这种情况经常发生。构建业务案例和量化业务成果尤其如此。
- 许多数据领导者承认有必要提高自己的能力,但即使在与分析师和昂贵的顾问(其中大多数人都主张既定的“最佳实践”)反复接触后,他们也基本上无法实施建议。
- 数据领导者(尤其是那些试图做“正确”事情的人)有一种明显的挫败感。反过来,越来越多的人指责数据组织之外的力量或人员是他们困难的根本原因。数据领导者、分析师和顾问的愤怒倾向于业务利益相关者,他们既创建(通过在业务应用程序中的互动)企业数据,又以分析见解的形式使用CDO组织的数据产品。
- 数据领导者的沮丧情绪得到了行业分析师、顾问和其他“思想领袖”的回应——他们中的大多数人同样困惑于,为什么在使用他们推荐的最佳实践时,CDO目标只取得了微小的进展。这导致许多人——其中一些人拥有极具影响力的平台,如Gartner分析师——验证了数据组织之外的力量在阻碍CDO成功方面发挥着重要作用的观点。
- 指责、沮丧和对目标持续缺乏吸引力的结合,有助于加剧数据生产者和消费者之间本已存在的问题分歧,从而形成一个负面反馈循环,只会使问题变得更糟。作为一名分析师,我经常听到数据领导者、顾问,甚至我的同行分析师对数据组织之外的业务利益相关者的敌意(如果不是彻底的蔑视)。
- 敌意和挫败感通常用“用户就是不明白”或“你可以引马下水”(当试图理解为什么没有使用数据产品时)等短语来表达,但这种挫败感的最好例子可能是数据质量。在许多组织中,业务利益相关者被反复提醒,在数据组织眼中,他们在培养数据资产方面做得有多糟糕——即使他们可能达到了所有可能的业务绩效指标。一次又一次,诸如“80%的数据科学家时间因数据质量差而浪费,或者只有3%的企业数据符合最低质量标准”等已发表的声音片段强化了这样一种说法,即CDO难以提供价值,即使不是完全,也是外部数据组织问题的结果。
对许多人来说,显而易见的是,当以工作成功的三个最大标准(履行工作职责、价值交付和遵守最佳实践)来衡量时,令人遗憾的是,在最需要数据领导力的时候,数据领导力却缺乏卓越性。
这自然引出了一个问题:为什么?
现代数据领导者需要转变思维方式
我相信,答案在于心态。在数据和分析领域,我们的许多领导者都采用了一种有毒的心态,在数据团队中创造了一种与大多数首席数据官的既定使命完全相反的文化。
这种心态将未能成为“数据驱动”的原因归咎于数据组织之外的其他人,同时支持这样一种观点,即衡量更好的数据如何提高业务绩效是不可能的(或不切实际的)。
这种心态将产品采用率低的主要原因归咎于缺乏用户技能,同时忽视了良好产品设计的基本要素。这种心态固守着陈旧过时的数据管理和治理方法,在业务转型最重要的时候,这些方法显然无法促进有意义的变革。
继续,继续。
所有数据领导者都认同这种心态吗?当然不是,但如果这种心态是数据领导者绩效低下的原因,这表明这种剧毒心态的各个方面都很普遍,而且已经持续了很长很长一段时间。
那么我们该何去何从?有一点是肯定的:数据领导者和为他们提供建议的人一直在做的事情并不奏效,是时候做出一些重大改变了。
现代数据领导力的策略
这让我想到了我所说的现代数据领导力,这是一套旨在打破过时、无效和有害的CDO角色方法的指导原则。这些原则旨在促进数据组织内部发展一种更具生产力、创新性和适应性的文化,最终实现预期的最终目标——CDO为其组织提供长期、可量化的价值。
现代数据领导者致力于在数据和分析功能中建立一种文化,他们:
✔先向内看,再向外看
建立数据文化必须从数据团队内部开始,并从那里向外传播。
我们的运营成熟度也是如此。数据领导者不能质疑他人的成熟度,除非他们已经为他们希望他人采用的成熟度建模。
✔将数据的细化视为机遇,而非负担
是的,数据捕获错误和懒惰肯定会影响数据质量。然而,大多数被报告为“质量”问题的问题更多地与存储在不同系统中的数据中的自然可变性有关,这些数据用于同样不同的业务流程。
CRM中的数据会有意地与ERP中的数据“看起来”不同,解决这些差异是数据组织中人员的工作。这些差异是由于公司在功能筒仓(销售、营销、财务、采购等)中运作,这是故意的。
这意味着,这些竖井中的数据是针对运营用途而非分析用途进行优化的,但我们继续将数据标记为“低质量”——在分析过程中使用之前需要转换的任何数据。这是一个很大的问题。
现代数据领导者会承认,不同的数据存在是有原因的,解决这些差异是一个机会,而不是负担。
✔相信他们的客户有积极的意图
现代数据领导者会不断提醒他们的团队,数据产品的客户正在尽最大努力,对公司来说意义重大。
他们并不是有意让数据团队的生活更加艰难。
现代数据领导者将积极推动工作交换计划,以确保数据团队中的每个人都有机会站在依赖数据工作的人的立场上“走一英里”。
✔将客户置于他们所做一切的中心
现代领导者需要采用以产品和设计为中心的方法来构建解决方案。
现代数据领导者承认,客户及其成功是第一位的,技术的存在只是为了让客户成功。
现代数据领导者努力构建客户想要使用的解决方案,否则他们会乐意付费。他们执行的产品战略与业务战略完全一致。
✔将客户无法从数据解决方案中实现价值视为产品故障
如果客户不信任数据产品,难以使用它们,或者未能从中实现价值,那么现代数据领导者就会意识到问题的可能原因是产品质量差。错过了要求,设计不理想,或者数据团队未能充分了解客户的需求。
如果你的产品是次优的,那么没有人愿意使用它,再多的培训也不会改变这一点。现代数据领导者意识到,对客户进行他们不喜欢或不信任的产品培训弊大于利。
✔衡量他们提供的价值,并作为利润中心运营
现代数据领导者的心态包括对数据对业务绩效的影响进行建模和测量的必要性。现代数据领导者投资组合中的所有项目和计划都是从评估计划的财务可行性开始的,通过数据和业务KPI来衡量。
现代数据领导者渴望将数据和分析功能作为利润中心来运营——即使首席财务官的观点不同。
✔将数据治理作为客户支持功能进行管理
现代数据领导者的心态是将数据治理作为业务实现和卓越运营的基础要素。如果数据团队的客户看不到数据治理的价值,那么数据团队就无法有意义地阐明其价值。
在一个高功能的数据组织中,业务利益相关者*希望*成为数据治理的受益者,因为他们有确凿的证据表明,数据治理提供了通过任何其他方式都无法实现的价值。
✔质疑专注于“数据至上”的现状和传统心态
现代数据领导者认为,“数据驱动”的概念是一种干扰,有助于在数据团队中推广数据比卓越业务流程更重要的误导观念。
现代数据领导者知道,“数据驱动”从来不是关于数据本身,而是关于如何将数据用于基于事实的决策。现代数据领导者提倡一种文化,这种文化摒弃了数据是最重要的东西的信念,而是将客户成功作为首要关注点。
改变你的心态,开始走上现代数据领导力的道路
这些关于现代数据领导力的观点当然并不完全新颖,其中许多观点甚至也没有那么具有挑衅性。许多,就像关注客户一样,都是商业基础。
但这些基本原则必须包含在这些指导原则中的想法说明了当今许多人面临的问题的严重程度。承认这一点可能很痛苦,但由于一再未能推动实质性变革,很明显,许多数据组织已经完全迷失了方向,需要进行全面重置。
如果数据领导者接受这些替代心态,他们就可以开始慢慢接受推动有意义的变革所需的新视角。
否则,我们可以继续做我们一直在做的事情——并承受后果。
- 9 次浏览
【数据驱动应用】设计数据驱动应用程序的5种最佳实践
QQ群
视频号
微信
微信公众号
知识星球
提供能够通知、连接和激励最终用户的应用程序
数据驱动的应用程序已成为全球软件市场的主要增长引擎。分析师预测,智能计算软件将成为一个价值480亿美元的市场,并宣布我们正处于一个数据驱动的营销和销售时代。从个性化门户到可穿戴设备,数据驱动的应用程序无处不在。
然而,设计引人注目的数据驱动体验仍然是一门艺术,也是一门科学,尤其是对于拥有大量用户和大量数据集的面向客户的应用程序来说。幸运的是,受消费类设备启发,一套新兴的设计原则为交付能够通知、连接和激励最终用户的应用程序提供了指导。
- 设计可扩展和个性化应用程序的五种最佳实践(附示例)
- 为什么数据在面向客户的应用程序中是一个与众不同的因素
- 为什么大数据和移动应用给开发人员带来了新的挑战
- “小数据”设计理念如何推动专注力和灵活性
- 创建引人注目的大规模数据驱动应用程序和解决方案的建议
认识到数据如何影响客户旅程
了解客户旅程以及如何使用它来提供相关数据是关键的业务差异。让客户创建一个数字角色(例如管理他们的账户、检查他们的使用情况和个性化他们的服务)是一个游戏规则的改变者。
当今的消费者是聪明的、有联系的、有要求的,因此提供卓越的客户体验需要响应能力、个性化和便携性。一个好的应用程序将:
- 知会。当客户收到有用的数据时,他们会注意。例如,一个旅行预订工具,它分析历史数据,为客户提供何时购买旅行的建议。
- 连接。数据可以建立连接,尤其是当它在正确的时间与客户见面时。数据驱动的应用程序和个性化体验可以将用户与品牌联系起来。例如,一家使用二维码和移动应用程序将广告和网上购物相结合的网店。
- 激励。数据的最终目标是影响客户的行为。数据和背景共同推动参与和参与。
对于客户来说,这一切都是为了获得他们想要的数据,何时获得,以及如何获得。随着用户可以使用丰富的移动访问,这越来越成为一个多渠道、多设备的挑战,需要即时响应。此外,随着设备收集的大量数据集,从可穿戴腕带到我们驾驶的汽车,人们更需要一个安全且可扩展的平台来访问、管理和提供个性化内容。
该研究定义了一个数据漏斗模型,用于确定协作、活动和开发的来源和工具。它还建议关注高消耗性应用程序和仪表板,以及在构建报告、可视化和数据驱动应用程序时从多个来源获取数据的重要性。
2.聚焦大数据的“最后一公里”
大数据的最后一英里是形成意见和采取行动的地方。对于应用程序设计者来说,应对最后一英里的挑战需要了解自助服务用例,并利用工具将大数据转化为小数据,帮助人们执行特定任务。图1:用例显示了四种类型的智能应用程序用例:
- 市场洞察力
- 监控
- 目标
- 最佳操作
Digital Clarity Group的一项研究,Thinking Small:将大数据的力量带给大众,引用了基于最后一英里概念和即时数据访问和消费理念的用例。他们的建议包括:
- 通过营销塑造大数据和小数据的未来
- 在定义数据访问和消费需求时考虑即时性
- 应用最佳实践,使应用程序变得简单、智能、响应迅速和社交
- 利用数据推动更明智的决策和更具响应性的活动
3.按规模构建(来源、格式和设备)
尽管我们周围都是数据驱动的设备,但设计引人注目的数据驱动体验是一项挑战。访问大量数据、多样化的数据来源、快速实现价值的敏捷开发,以及与其他企业应用程序集成的高度品牌化、引人入胜的个性化用户界面,都增加了挑战。开发平台必须满足以下设计挑战:
- 访问数据。数据量和速度不断增加,数据源也越来越多样化,包括RDBMS、NoSQL/NewSQL、Hadoop、云、社交媒体和文档归档。
- 管理数据和应用程序。企业需要敏捷的开发、快速实现价值、可控、可预测的开发和成本管理。
- 提供大规模应用程序。应用程序必须易于使用、引人入胜,并安全地提供给网络浏览器和移动设备。它们还必须与现有的品牌和外观无缝集成。
图2中右上象限中的应用程序:面向客户的应用程序需要一个安全、可扩展的平台来满足这三个设计挑战。

企业需要以用户为中心,超越大数据,专注于增加价值。他们必须为用户提供视觉元素和引人入胜的体验,并使应用程序足够简单,让不懂技术的用户能够获得他们需要的信息。图3中的仪表板:呼叫中心操作分析,具有几种类型的交互式数据可视化,就是这样一个设计的例子。
4.倾听人群(开放更好)
对于OpenText来说,这段旅程始于2004年Actuate为大众提供其核心报告引擎。从那时起,Actuate和OpenText听取了开源社区的意见,纳入了他们的反馈,并建立了一个强大的全球开发者社区。我们的集成开发环境(IDE)目前有开源和商业版本,可以提高开发人员的生产力。社区为我们的客户提供了许多资源,以确保项目按时交付并将风险降至最低。
5.从小处着手,大处着眼
专注和敏捷是快速设计数据驱动应用程序的关键。四个原则可实现专注和灵活性:
- 让它变得简单。应用程序应该简单易用。
- 让它变得聪明。应用程序应该足够智能,能够处理特定于角色的任务。
- 反应灵敏。应用程序应该在各种平台上提供价值。
- 社交。将用户和数据安全地连接到更大的世界。
- 22 次浏览
【架构师】数据架构与信息架构:它们的区别
QQ群
视频号
微信
微信公众号
知识星球
数据架构师收集统计数据,信息架构师将数字放在上下文中,因为它们协同工作,以支持企业的数据和业务战略。
许多人认为数据架构和信息架构是一体的。但这种误解导致了许多设计糟糕的架构无法很好地处理数据或信息。
问题开始于数据和信息之间的混淆。它们是相关但不同的。数据是在应用程序、业务流程和设备中收集、更新和删除的数字、字符或其他数字格式。信息是上下文中的数据。没有上下文,一个原始数字是没有意义的,但有了它,这个数字可以代表外卖订单的销售额、体温读数或学生的考试分数。进一步的背景将揭示该数字的谁、什么、何时、地点和方式,为分析提供进一步的信息。
数据架构与信息架构
信息架构定义了企业用于其业务运营和管理的上下文。信息体系结构的组成部分是组织的应用程序、业务流程、分析和报告系统,以及内部和与客户、供应商和业务合作伙伴的信息工作流。业务需求用于开发信息架构的蓝图:概念数据模型、逻辑数据模型和业务流程模型。企业应用程序,无论是内部构建还是购买,都需要使用这些模型。
数据架构通过收集、存储、移动、集成和管理所需数据为信息体系结构提供了基础。在现代数据架构中,数据被摄取并存储在跨云、本地和混合环境的文件系统和数据库中。数据架构的基本构建块是数据仓库、分段数据存储和商业智能模式。更复杂的数据架构可能会增加数据湖、分析沙盒、数据科学中心和运营数据存储。
一流的数据架构通过支持数据质量和主数据管理计划来实现数据治理过程。它还需要一个数据集成框架,实现集成能力的组合——传统的提取、转换和加载(ETL)过程和大数据系统中常用的ELT变体,以及数据管道、数据流、API、数据准备和应用程序集成。
数据架构和信息架构是如何相关的?
现代数据架构需要信息架构,反之亦然。
信息架构的蓝图包括一个企业数据模型,例如,该模型定义了企业的客户和合作伙伴,以及在营销、销售和支持活动中如何与他们互动。数据架构将数据模型转换为用于捕获、存储和更新相关数据的物理数据库设计和数据元素。有效的数据体系结构包括转换、管理、清理和管理数据的过程,从而使其成为有用的信息。
许多架构的一个关键缺点是过于简化了数据如何转换为信息。IT和数据管理团队常常认为数据只需要从源系统移动或传输到目标系统,无法理解不同数据上下文的需要。如果没有基于数据模型和数据定义的数据转换来实现正确的上下文,分析和报告工具将无法提供正确的见解。更糟糕的是,使用这些工具的人可能会将数据导出到电子表格中,试图创建有用的信息。这样做可能会提供正确的环境,但这是无效的,也是徒劳的。
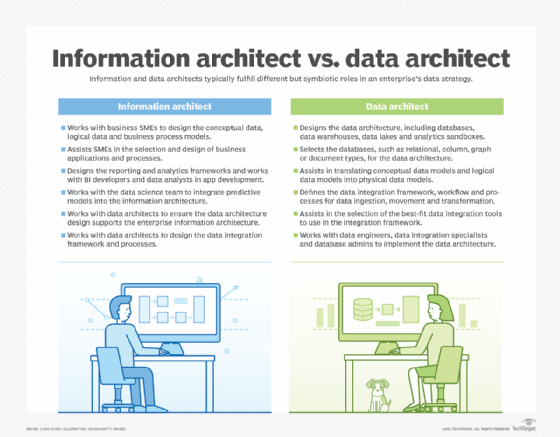
信息架构师做什么
信息架构师必须了解业务及其所需的信息。然后,他们确保应用程序、业务流程、分析和报告系统能够获得这些信息。
信息架构师的职责包括:
- 与业务主题专家(SME)合作,设计概念数据模型、逻辑数据模型和业务流程模型,这些模型构成了不断发展的企业数据模型。
- 协助中小企业选择和设计用于运营和管理企业的业务应用程序和流程。
- 设计报告和分析框架。
- 与商业智能开发人员和数据分析师合作开发报告和分析应用程序。
- 与数据科学团队合作,收集他们的需求,支持预测建模和机器学习开发,并将他们创建的模型和信息集成到信息架构中。
- 与数据架构师合作,确保数据架构设计支持企业信息架构。
- 与数据架构师一起设计数据集成框架和流程。
数据架构师做什么
数据架构师设计企业的整体数据架构,包括数据集成流程、业务智能系统以及支持的数据库和文件系统。他们根据企业的长期路线图和当前计划收集业务需求,并检查数据问题制约运营、降低生产力或抑制业务增长的领域。
许多数据架构师现在专注于将云和本地系统相结合的云实现或混合云部署。多云架构也越来越普遍。
数据架构师的职责包括:
- 设计数据架构,包括数据库、文件系统、数据仓库、数据湖、分析沙盒和数据科学中心。
- 选择最适合数据架构的数据库类型,如关系型、列型、图型或文档型。
- 帮助将概念和逻辑数据模型转换为物理数据模型。
- 定义数据集成框架、工作流和流程,以实现数据接收、移动和转换。
- 帮助选择最适合集成框架的数据集成工具。
- 与数据工程师、数据集成专家、数据库管理员和数据管理团队的其他成员一起实施数据架构。
数据策略对数据和信息架构设计的影响
数据战略是指数据如何实现企业的业务战略并支持其持续运营的愿景。与其将数据视为业务活动的副产品,不如将其视为企业资产,如果组织要成功,则需要对其进行规划、定义和管理。数据战略包括实现其目标的时间表、资源计划和财务理由。信息和数据架构是企业如何设计、构建、实施其数据战略和管理数据战略的蓝图。
企业的数据战略以及信息和数据架构将随着业务、竞争和市场的发展而发展。此外,技术变化将影响这些架构的构建和管理方式。成功的关键是认识到需要将变革纳入数据战略、数据架构和信息架构。
共生关系
企业需要信息架构和数据架构。信息架构由组织的业务战略和运营提供信息。数据架构通过提供捕获、转换、管理和管理创建有用信息所需数据的手段来支持信息架构。这两种架构的发展为增加数据和信息的使用及其业务价值提供了持续的机会。
- 51 次浏览