微服务架构
微服务架构 intelligentx- 501 次浏览
「分布式架构」分布式架构中可扩展性的事务一致性
系统架构师角色的一个关键方面是权衡冲突的需求并决定解决方案,通常是通过将一个方面与另一个方面进行权衡。 随着系统变得越来越大,越来越复杂,越来越多关于如何构建应用程序的传统智慧正在受到挑战。 例如,去年3月在伦敦召开的QCon会议上,Dan Pritchard就eBay的架构发表了演讲。 从他的演讲中获得大量后续报道的主要内容之一是eBay不使用事务,事务丢失简单的数据一致性,以显着改善其系统的整体可扩展性和性能。
在他的演讲之后,InfoQ与Dan Pritchard进行了交谈,以获取更多信息:
为什么eBay不使用交易,或者如何决定应用程序级交易?
并不是我们不使用事务。我们只是不使用跨物理资源的事务,因为它跨多个组件创建了依赖关系。组件可以是应用程序服务器和数据库(例如客户端管理的事务),因为客户端故障可能会占用数据库资源的时间超过我们可以容忍的时间。我们也不使用分布式事务,因为使应用程序依赖于多个数据库会降低客户端的有效可用性。相反,我们选择设计缺少事务并构建故障模式,即使在数据库可用性问题的情况下,客户端也能成功。
应用程序级别的事务总是有些问题。无论何时您要求开发人员管理资源生命周期,您都将面临管理出错时出现的错误。事务与内存没什么不同,我们看到语言的一般趋势是由于生命周期问题而从开发人员那里消除内存管理的责任。声明性事务(例如EJB中的事务)是[a]简化事务管理的大锤方法,假设bean背后的每个数据库操作都同等重要。
决定是否使用事务实际上取决于您的可伸缩性和可用性目标。如果您的应用程序需要每秒达到数百个事务,那么您将发现分布式事务不会削减它。如果要在可用性的第3个9之后添加另一个数字,您将无法假设所有数据库提交都必须在网页的上下文中完成,或者在某些情况下完成。不幸的是,没有简单的公式可以何时退出应用程序级别的事务。相反,作为架构师,您必须决定系统上的一个约束何时需要您放松另一个约束。
你是如何为“放置出价”(Place bid)之类的东西建立自己的原子性的?
单独出价是一个有趣的问题,因为它不是关于原子性的,而是更多关于在拍卖的关键后几秒没有阻止任何竞标者。事实证明,如果您决定在展示时间而不是出价时间计算高出价者和出价,这很简单。将出价插入到单独的子表中,这是一种低争用操作。每次显示该项目时,都会检索所有出价并应用用于确定高出价者的业务规则。
你问题背后的真正问题是我们如何实现一致性?要在大规模系统中实现一致性,您必须放弃ACID而是使用BASE:
基本可用
软状态
最终一致
在每个客户端请求结束时,您需要放松数据的一致性,现在您已打开窗口以消除分布式事务并使用其他机制来达到一致状态。例如,在上述投标案例中,我们还更新由投标人组织的查看表,以便在“我的易趣”页面中快速显示。这是使用一对异步事件完成的。一个人依赖于内存队列,因为我们希望在出价和出现在“我的易趣”之间的延迟非常低。但是,在内存中队列不可靠,因此我们还使用具有出价操作的服务器端事务来捕获出价事件。如果内存队列操作失败,则作为恢复机制处理bid事件。因此,投标人视图表是分离的,并不总是与投标表的状态一致。但这是我们能够承受的宽容,并允许我们避免出价和出价视图表之间的ACID合规性。
您对大型系统的其他架构师有什么建议?
他最简单的建议是,大规模扩展不会为设计为小规模扩展的架构增加资源。 您必须摆脱传统模式,例如ACID和分布式事务。 愿意寻找机会放松传统智慧状态无法放松的约束。
对于一些简单的公理,设计所有要拆分的东西,并考虑BASE,而不是ACID。
亚马逊首席技术官Werner Vogels也在QCon上发表讲话,并以Eric Brewer的CAP定理为例,提供了一些权衡的背景。该定理在2000年PODC会议(.pdf文档)的介绍中描述,其中也涵盖了ACID与BASE,它表明,对于共享数据系统的三个属性 - 数据一致性,系统可用性和网络分区容忍度 - 只有两个可以同时发生。换句话说,不能容忍网络分区的系统可以使用诸如事务之类的常用技术来实现一致性和可用性。但是,对于亚马逊和eBay等大型分布式系统,网络分区是给定的。这样做的结果是,处理非常大的分布式系统的架构师必须决定是否放宽对一致性或可用性的要求。这两个选项都给开发人员带来了一些责任,他们需要了解他们正在使用的架构的特征。例如,如果您选择放松一致性,那么开发人员需要决定如何处理对系统的写入不会立即反映在相应读取中的情况。正如Windows Live程序经理Dare Obasanjo所说的那样.
我们在Windows Live平台的某些方面遵循类似的做法,我听说开发人员抱怨这样一个事实,即您通过事务免费获得的错误恢复由应用程序开发人员掌握。 最大的抱怨总是围绕复杂的批量操作。
有趣的是,许多大型网站似乎都独立地得出了相同的结论。 虽然只有少数节点的小型系统不必担心这些类型的权衡,但eBay和亚马逊正在解决的各种问题可能会开始出现在企业系统中,因为它们也会扩展到更大的范围。 更多的观众。
- 68 次浏览
「微服务架构」Google和eBay在构建微服务生态系统方面的深刻教训
当你看到来自谷歌,Twitter,eBay和亚马逊的大规模系统时,他们的架构已演变成类似的东西:一组多语言微服务。
当您处于多语言微服务结束状态时,它看起来像什么? Randy Shoup曾在谷歌和eBay担任过高级职位,他有一个非常有趣的话题就是探索这个想法:规模的服务架构:谷歌和eBay的经验教训。
我真正喜欢Randy的演讲是他如何自觉地试图让你沉浸在你可能没有经验的经历中:创造,使用,延续和保护大规模的架构。
在谈话的服务生态系统部分兰迪问道:拥有大规模多语言微服务生态系统是什么样的?在“规模运营服务”部分,他问:作为服务提供商,运营此类服务的感觉如何?在“建立服务”部分,他问:当您是服务所有者时,它看起来像什么?在服务反模式部分,他问:什么可能出错?
一种非常强大的方法。
对我来说,演讲的亮点是调整激励机制的想法,这是一个贯穿整个努力的一贯主题。虽然从未明确地将其作为一个单独的策略,但这是为什么您希望小团队开发小型清洁服务,为什么内部服务的退款模型如此强大,架构如何在没有架构师的情况下发展,如何清洁设计可以发展的动机自下而上的过程,以及标准如何在没有中央委员会的情况下发展。
我的想法是,有意识地调整激励机制是如何扩展大型动态组织和大型动态代码库。在没有明确控制的情况下,采用正确的激励措施可以促使事情发生,几乎同样的方式是,当您移除锁定,不共享状态,与消息通信以及并行化所有内容时,分布式系统中的更多工作都会完成。
让我们看看现代时代如何建立大规模系统......
多语言微服务是最终的游戏
大规模系统最终演变成看起来非常相似的东西:一组多语言微服务。多语言意味着微服务可以用多种语言编写。
eBay始于1995年。根据您的计算方式,他们是第5代的架构。
- 始于1995年劳动节周末创始人写的单片Perl应用程序。
- 然后它转移到一个单片C ++应用程序,最终在一个DLL中有340万行代码。
- 之前的经验促使人们转向更加分散的Java分区系统。
- 今天的eBay有相当多的Java,但是一套多语言的微服务。
Twitter的演变看起来非常相似。根据您的计算方式,他们是第三代架构。
- 作为单片Ruby on Rails应用程序启动。
- 移动到前端的Javascript和Rails组合,后端有很多Scala。
- 最终,他们已经转向我们今天称之为一组多语言微服务。
亚马逊遵循类似的道路。
- 从单片C ++应用程序开始。
- 然后用Java和Scala编写的服务。
- 结束一组多语言微服务。
服务生态系统
拥有多语种微服务的大规模生态系统是什么样的?
在eBay和Google上,数百到数千个独立服务都在一起工作。
- 现代大规模系统在关系图中组成服务,而不是层次结构或层级组。
- 服务依赖于许多其他服务,同时被许多服务依赖。
- 较旧的大型系统通常以严格的层级组织。
如何建立服务生态系统?
这些性能最佳的系统更多是进化的产物,而不是智能设计。例如,在Google,从未有过系统的自上而下的设计。它以一种非常有机的方式随着时间的推移而发展和成长。
变化和自然选择。当需要解决问题时,会创建新服务,或者更经常从现有服务或产品中提取新服务。只要服务使用,服务就会存在,只要它们提供价值,否则它们会被弃用。
这些大规模系统自下而上发展。清洁设计( Clean design)可以是一种新兴产品,而不是自顶向下设计的产品。
例如,考虑Google App Engine的一些服务分层。
- Cloud Datastore(NoSQL服务)构建在Megastore(一个地理规模的结构化数据库)上,该数据库构建在Bigtable(一种集群级结构化服务)上,该服务基于Colossus(下一代集群文件系统)构建,建立在Borg(集群管理基础架构)之上。
- 分层很干净。每个图层都添加了一些不属于下面图层的内容。它不是自上而下设计的产物。
- 它是自下而上建造的。 Colossus,谷歌文件系统是首先建立的。几年后,Bigtable建成了。几年后,Megastore建成了。几年后,Cloud Database迁移到了Megastore。
- 没有自上而下的架构,您可以将这种关注点分离出来。
这是没有架构师的架构。 Google没有人拥有建筑师的头衔。技术决策没有中央批准。大多数技术决策都是由各个团队在当地为自己的目的做出的,而不是全球性的。
与2004年的eBay相比。有一个架构审查委员会,必须批准所有大型项目。
- 通常他们只是参与项目,因为改变它们已经太晚了。
- 集中审批机构成为瓶颈。它唯一的影响往往是在最后一分钟说不。
eBay处理这种情况的一个更好的方法是在审查委员会中对智能经验丰富的人员的知识进行编码,并将其放入可由各个团队重复使用的内容中。将这种体验编码到库或服务中,甚至是一组人们可以自己使用的指南,而不是在最后一刻进入流程。
标准如何在没有建筑师的情况下发展?
没有中央控制可能最终导致标准化。
- 标准化往往发生在服务和公共基础设施之间的通信中。
- 标准成为标准,因为它们比替代品更健康。
通常标准化的通信部分:
- 网络协议。 Google使用名为Stubby的专有协议。易趣使用REST。
- 数据格式。 Google使用Protocol Buffers。易趣倾向于使用JSON。
- 接口模式标准。 Google使用Protocol Buffers。对于JSON,有JSON模式。
通常标准化的通用基础设施:
- 源代码控制。
- 配置管理。
- 集群管理器。
- 监控系统。
- 警报系统。
- 诊断工具。
- 所有这些组件都可以根据惯例发展。
在进化环境中,标准通过以下方式实施:代码,鼓励,代码审查和代码搜索。
- 鼓励最佳实践的最简单方法是通过实际代码。这不是关于自上而下的审查,也不是前期设计,而是关于生成代码的人,这使得完成工作变得容易。
- 鼓励是通过提供库的团队。
- 鼓励也是通过您希望依赖于支持X协议或Y协议的服务。
- Google以至少一位其他程序员审阅源代码控制的每行代码而闻名。这是沟通常见做法的好方法。
- 除了少数例外,Google的每位工程师都可以搜索整个代码库。当程序员试图弄清楚如何做某事时,这是一个巨大的增值。对于10K工程师来说,如果你正在尝试做一些人已经做过类似事情的话。这允许从一个区域开始的最佳实践通过代码库传播。它还允许错误传播。
为了鼓励共同的实践和标准化的惯例,使得做正确的事情变得非常容易,并且做错事情要困难得多。
个人服务彼此独立。
- 在谷歌,没有标准化的服务内部。服务是外面的黑匣子。
- 有常规和通用库,但没有编程语言要求。通常使用四种语言:C ++,Go,Java,Python。许多不同的服务都是用各种语言编写的。
- 框架或持久性机制没有标准化。
在成熟的服务生态系统中,我们标准化 图的弧,而不是节点本身。定义一个共同的形状,而不是常见的实现。
创建新服务
- 新服务在使用已经过验证后即可创建。
- 通常,为一个特定用例构建了一个功能。然后发现该功能是通用且有用的。
- 一个团队成立,服务分离到自己的独立单位。
- 只有当功能成功并适合许多不同的用例时才会发生这种情况。
- 这些架构通过实用主义而成长。没有人坐在高处并且说应该添加服务。
- Google文件系统支持搜索引擎。毫无疑问,分布式文件系统通常更常用。
- Bigtable最初支持搜索引擎,但更广泛有用。
- Megastore是作为Google应用程序的存储机制构建的,但更广泛有用。
- Google App Engine本身是由一小群工程师发起的,他们认识到需要帮助构建网站。
- Gmail来自一个内部非常有用的副项目,然后被外部化为其他人。
弃用旧服务
如果不再使用某项服务会怎样?
- 可以重新利用的技术可以重复使用。
- 人们可以被解雇或重新部署到其他团队。
- Google Wave并非市场成功,但其中一些技术最终出现在Google Apps中。 例如,多人编辑文档的能力来自Wave。
更常见的情况是核心服务经历多代并且旧代被弃用。 这种情况在Google发生了很多。 通常情况下,谷歌内部的每项服务都被弃用或尚未准备就绪。
建立服务
当您是服务所有者时,在大规模多语言微服务系统中构建服务时,它会是什么样子?
在大型架构中表现良好的服务是:
- 单用途。 它将有一个简单明确的界面。
- 模块化和独立。 我们可以称之为微服务。
- 不共享持久层。 稍后会详细介绍。
服务所有者的目标是什么?
- 满足客户的需求。 以适当的质量水平提供必要的功能,同时满足协商的性能水平,同时保持稳定性和可靠性,同时不断改进服务。
- 以最低的成本和精力满足需求。
- 这一目标以鼓励使用共同基础设施的方式调整激励措施。
- 每个团队都拥有有限的资源,因此利用常见的战斗测试工具,流程,组件和服务符合他们的利益。
- 它还可以激发良好的操作行为。 自动构建和部署您的服务。
- 它还可以优化资源的有效利用。
服务所有者的责任是什么?
- 你构建它运行它。
- 该团队通常是一个小团队,拥有从设计,开发和部署到退役的服务。
- 没有单独的维护或维护工程团队。
- 团队可以自由地制定自己的技术选择,方法和工作环境。
- 团队对他们的选择负责。
- 服务作为有限的边界。
- 团队的认知负荷是有限的。
- 没有必要了解生态系统中的所有其他服务。
- 团队需要深入了解他们的服务以及他们所依赖的服务。
- 这意味着团队可以非常小巧灵活。一个典型的团队是3-5人。 (另外一个美国海军陆战队的火队有四个人。)
- 团队规模小意味着团队内部的沟通具有非常高的带宽和质量。
- 康威定律对你有利。通过组织小团队,你最终会得到一些小的个人组件。
什么是服务之间的关系?
- 考虑服务之间的关系作为供应商 - 客户关系,即使您在同一家公司。
- 非常友好和合作,但在关系中要非常有条理。
- 对所有权非常清楚。
- 要清楚谁应该对什么负责。在很大程度上,这是关于定义一个清晰的界面并维护它。
- 奖励是一致的,因为客户可以选择是否使用服务。这鼓励客户做正确的服务。这是新服务最终建立的方式之一。
- 定义SLA。服务提供商承诺为其客户提供一定程度的服务,以便客户可以依赖该服务。
- 客户团队为服务付费。
- 为服务收费可以协调经济激励措施。它激励双方在资源利用方面极为高效。
- 当事物是自由的时,我们倾向于不重视它们,并且往往不优化它们。
- 例如,内部客户免费使用Google App Engine,他们使用了大量资源。乞求他们更有效地利用资源,结果证明这不是一个好策略。退款开始一周后,通过一两个简单的更改,他们能够将GAE资源的消耗减少90%。
- 并不是使用GAE的团队是邪恶的,他们只是有其他优先事项,因此没有动力让他们优化他们对GAE的使用。事实证明,他们实际上通过更高效的架构获得了更好的响应时间。
- 充电还可以使服务提供商保持高质量,否则内部客户可能会去其他地方。这直接激励了良好的开发和管理实践。代码审查就是一个例子。谷歌的超大规模构建和测试系统是另一个。 Google每天都会运行数百万次自动化测试。每次将代码接受到存储库时,都会运行所有相关代码的验收测试,这有助于所有小型团队保持其服务质量。
- 退回退模式鼓励小额增量变更。小变化更容易理解。此外,代码更改的影响是非线性的。千分线变化的风险不是100线变化的10倍,它更像风险的100倍。
- 保持接口的完全向后/向前兼容性。
- 切勿破坏客户端代码。
- 这意味着维护多个接口版本。在一些令人讨厌的情况下,这意味着维护多个部署,一个用于新版本,另一个用于旧版本。
- 通常由于小的增量变化模型接口没有改变。
- 有明确的弃用政策。然后,服务提供商非常激动地将所有客户从版本N移到版本N + 1。
规模运营服务
作为服务提供商,在大规模多语言微服务系统中运行服务是什么感觉?
可预测的性能是一项要求。
- 大规模服务很容易受到性能差异的影响。
- 性能的可预测性比平均性能重要得多。
- 具有不一致性能的低延迟实际上根本不是低延迟。
- 当客户端提供一致的性能时,它可以更轻松地针对服务进行编程。
- 由于服务使用许多其他服务来执行其工作,因此尾部延迟主导性能。
- 想象一下这样一种服务,在中位数上有1ms的延迟,在99.999%的ile(1 / 10,000)中,延迟是一秒。
- 拨打一个电话意味着你很慢.01%的时间。
- 如果你使用的是5000台机器,就像Google那样的大型服务,那么50%的时间你都会很慢。
- 例如,memcached中百万分之一的问题被追踪到低级数据结构重新分配事件。这个罕见的问题表现为更高级别的延迟峰值。像这样的低级细节在大规模系统中变得非常重要。
深度弹力。
- 服务中断更可能是由于某人的错误而不是硬件或软件故障而发生的。
- 适应机器,集群和数据中心故障。
- 负载平衡并在调用其他服务时提供流量控制。
- 能够快速回滚变化。
增量部署。
- 使用金丝雀系统。不要一次部署到所有计算机。选择一个系统,将该软件的新版本放在该系统上,并查看它在新世界中的表现。
- 如果它工作开始分阶段推出。开始使用10%的机器,移动到20%,依此类推,通过其余的机队。
- 如果在部署中的50%点发生问题,那么您应该能够回滚。
- eBay利用功能标志将代码部署与功能部署分离。通常在关闭功能的情况下部署代码,然后可以打开或关闭代码。这可确保在打开新功能之前正确部署代码。这也意味着如果新功能存在错误,性能问题或业务故障,则可以关闭该功能,而无需部署新代码。
你可以有太多警报,你永远不会有太多的监控。
服务反模式
大型服务
- 服务太多了。 你想要的是一个非常小的清洁服务生态系统。
- 做太多的服务只是另一个巨石。 它很难推理,它很难扩展,很难改变,而且它还创建了比你想要的更多的上游和下游依赖。
共享持久性
- 在分层模型中,服务放在应用程序层中,持久层作为应用程序的公共服务提供。
- 他们在eBay做到了这一点并没有奏效。 它打破了服务的封装。 应用程序可以通过更新数据库来支持您的服务。 它最终重新引入服务耦合。 共享数据库不允许松散耦合的服务。
- 微服务通过小型,隔离和独立来防止这个问题,这是您保持生态系统健康和发展的方式。
- 114 次浏览
「微服务架构」Saga 模式 如何使用微服务实现业务事务-第二部分
在上一篇文章中,我们看到了实现分布式事务的一些挑战,以及如何使用Event / Choreography方法实现Saga的模式。在本文中,我们将讨论如何通过使用另一种类型的Saga实现(称为Command或Orchestration)来解决一些问题,如复杂事务或事件的循环依赖性。
Saga的命令/编曲序列逻辑
在编曲方法中,我们定义了一项新服务,其唯一责任是告诉每个参与者该做什么以及何时做什么。 saga orchestrator以命令/回复方式与每个服务进行通信,告诉他们应该执行哪些操作。
让我们看一下使用我们之前的电子商务示例的样子:
- 订单服务保存挂起的定单并要求Order Saga Orchestrator(OSO)启动创建订单交易。
- OSO向付款服务发送执行付款命令,并回复付款已执行消息
- OSO向库存服务发送准备订单命令,并回复订单准备消息
- OSO向Delivery Service发送Deliver Order命令,并以Order Delivered消息回复
在上面的例子中,Order Saga Orchestrator知道执行“创建订单”事务所需的流程是什么。如果有任何失败,它还负责通过向每个参与者发送命令以撤消先前的操作来协调回滚。
为saga协调器建模的标准方法是状态机,其中每个转换对应于命令或消息。状态机是构建定义明确的行为的极好模式,因为它们易于实现,特别适合测试。
在Saga的命令/编曲中回滚
当你有一个协调器来协调所有事情时,回滚会容易得多:
使用Saga命令/编曲设计的好处和缺点
基于编排的传奇有各种好处:
避免服务之间的循环依赖,因为saga orchestrator调用saga参与者但参与者不调用orchestrator
- 集中分布式事务的编排
- 降低参与者的复杂性,因为他们只需要执行/回复命令。
- 更容易实施和测试
- 添加新步骤时,事务复杂性保持线性
- 回滚更容易管理
- 如果您有第二个愿意更改同一目标对象的事务,您可以轻松地将其保留在协调器上,直到第一个事务结束。
然而,这种方法仍然存在一些缺点,其中之一是在协调器中集中过多逻辑的风险,最终导致智能协调器告诉哑巴服务该做什么的架构。
Saga的Orchestration模式的另一个缺点是它会略微增加您的基础架构复杂性,因为您需要管理额外的服务。
Saga(传奇)模式提示
- 为每个事务创建唯一ID
为每个事务提供唯一标识符是可追溯性的常用技术,但它也有助于参与者以标准方式相互请求数据。例如,通过使用交易ID,交付服务可以询问库存服务在哪里提取产品,如果订单已付款,则可以使用支付服务仔细检查。
- 在命令中添加回复地址
不要将参与者设计为回复固定地址,而是考虑在消息中发送回复地址,这样您就可以让参与者回复多个协调者。
- 幂等运算
如果您使用队列进行服务之间的通信(如SQS,Kafka,RabbitMQ等),我个人建议您使您的操作具有幂等性。大多数队列可能会两次传递相同的消息。
它还可能会增加您的服务的容错能力。通常,客户端中的错误可能会触发/重放不需要的消息并弄乱您的数据库。
- 避免同步通信
随着事务的进行,不要忘记将每个要执行的操作所需的所有数据添加到消息中。整个目标是避免服务之间的同步调用只是为了请求更多的数据。即使其他服务处于脱机状态,它也可以使您的服务执行本地事务。
缺点是您的协调器会稍微复杂一些,因为您需要操纵每个步骤的请求/响应,因此请注意权衡。
- 103 次浏览
「微服务架构」Saga 模式|如何使用微服务实现业务事务 第一部分
最强大的事务类型之一称为两阶段提交,当第一个事务的提交取决于第二个事务的完成时,它是摘要。特别是当您必须同时更新多个实体时,例如确认订单和立即更新库存时,它非常有用。
但是,例如,当您使用微服务时,事情变得更加复杂。每个服务都是一个独立的系统,拥有自己的数据库,您不再可以利用本地两阶段提交的简单性来维护整个系统的一致性。
当你失去这种能力时,RDBMS成为一个非常糟糕的存储选择,因为你可以完成相同的“单实体原子事务”,但只需使用像Couchbase这样的NoSQL数据库就可以快几十倍。这就是为什么大多数使用微服务的公司也在使用NoSQL。
要举例说明此问题,请考虑以下电子商务系统的高级微服务架构:
在上面的示例中,人们不能只在一个ACID交易中下订单,向客户收费,更新库存,并将其发送到交货。要始终如一地执行此整个流程,您将需要创建分布式事务。
我们都知道实现分布式任务是多么困难,不幸的是,交易也不例外。处理瞬态状态,服务,隔离和回滚之间的最终一致性是在设计阶段应该考虑的场景。
幸运的是,我们已经为它提出了一些好的模式,因为我们已经实施分布式事务已有二十多年了。我今天要谈的那个叫做Saga模式。
传奇(Saga)模式
分布式事务最着名的模式之一称为Saga。关于它的第一篇论文发表于1987年,从那时起它就成了一种流行的解决方案。
Saga是一系列本地事务,其中每个事务在单个服务中更新数据。第一个事务由对应于系统操作的外部请求启动,然后每个后续步骤由前一个完成触发。
使用我们之前的电子商务示例,在一个非常高级的设计中,Saga实现如下所示:
有几种不同的方法来实现传奇交易,但最受欢迎的两种方式是:
- 事件/Choreography(编舞):当没有中央协调时,每个服务产生并监听其他服务的事件,并决定是否应该采取行动。
- 命令 / Orchestration(编曲):协调器服务负责集中saga的决策和排序业务逻辑。
让我们更深入地了解每个实现,以了解它们的工作原理。
事件/编舞
在事件/Choreography(编舞)方法中,第一个服务执行事务然后发布事件。该事件由一个或多个服务监听,这些服务执行本地事务并发布(或不发布)新事件。
当最后一个服务执行其本地事务并且不发布任何事件时,分布式事务结束,或者任何传奇(Saga)参与者都不会听到发布的事件。
让我们看看它在我们的电子商务示例中的样子:
- 订单服务保存新订单,将状态设置为挂起并发布名为ORDER_CREATED_EVENT的事件。
- 付款服务侦听ORDER_CREATED_EVENT,向客户收费并发布事件BILLED_ORDER_EVENT。
- Stock Service监听BILLED_ORDER_EVENT,更新库存,准备订单中购买的产品并发布ORDER_PREPARED_EVENT。
- Delivery Service侦听ORDER_PREPARED_EVENT,然后选择并交付产品。最后,它发布了ORDER_DELIVERED_EVENT
- 最后,Order Service侦听ORDER_DELIVERED_EVENT并将订单状态设置为已结束。
在上面的情况中,如果需要跟踪订单的状态,订单服务可以简单地监听所有事件并更新其状态。
分布式事务中的回滚
回滚分布式事务并非免费。通常,您必须实施另一个操作/事务来补偿之前已完成的操作。
假设Stock Service在交易期间失败了。让我们看看回滚会是什么样子:
- 库存服务生产PRODUCT_OUT_OF_STOCK_EVENT;
- 订单服务和付款服务都会收听上一条消息:
- 付款服务退还客户。
- 订单服务将订单状态设置为失败。
请注意,为每个事务定义一个公共共享ID至关重要,因此每当您抛出一个事件时,所有侦听器都可以立即知道它所引用的事务。
Saga 事件/Choreography(编舞)设计的好处和缺点
事件/编排是实现Saga模式的自然方式;它简单,易于理解,不需要太多的努力来构建,并且所有参与者都是松散耦合的,因为他们没有彼此的直接知识。如果您的交易涉及2到4个步骤,那么它可能非常合适。
但是,如果您不断在事务中添加额外的步骤,这种方法很快就会变得混乱,因为很难跟踪哪些服务监听哪些事件。此外,它还可能在服务之间添加循环依赖,因为它们必须订阅彼此的事件。
最后,使用这种设计实现测试会很棘手。为了模拟事务行为,您应该运行所有服务。
在下一篇文章中,我将解释如何使用另一个名为Command / Orchestration的Saga实现解决Saga事件/编舞方法的大部分问题。
- 50 次浏览
「微服务架构」七种微服务反模式
什么是微服务
流行语经常为进化的概念提供背景,并且需要一个良好的“标签”来促进对话。微服务是一个新的“标签”,它定义了我个人一直在发现和使用的领域。文章和会议描述了一些事情,我慢慢意识到,过去几年我一直在发展自己的个人经历。虽然有关微服务的行业和专业讨论已经成为Netflix,亚马逊和谷歌等公司以及成功完成这项工作的从业者的焦点,但我有一些个人经验可以为成功的微服务实施提供见解。
任何架构的三个标准和最常见的业务驱动因素是:
- 提高敏捷性 - 及时响应业务需求以便业务增长的能力
- 改善客户体验 - 改善客户体验,从而减少客户流失
- 降低成本 - 降低添加更多产品,客户或业务解决方案的成本
事实上,我们所有人都在努力在日常工作中这样做。 SOA创建了一个业务一致的软件框架,使企业能够实现这一目标。几家大型软件供应商已经出现并声称他们的产品套件可以使企业提供SOA。
如果您没有合适的人员,文化和投资,SOA将无法实现业务价值。微服务架构与SOA并没有根本的不同,目标和目标是相同的,但是方法略有改进,事实上,我只是说微服务仅仅是SOA可扩展的。微服务使应用程序/系统迫切需要从单一实现转移到服务于许多应用程序的分布式分散服务平台。微服务是独立的,它将敏捷性和应用程序演变视为企业数字化转换。微服务的成功取决于服务独立性和服务灵活性。
我将微服务定义为“通过构建细粒度服务以支持分布和组织为功能域的业务功能来提供SOA的方法”。没有模式是魔术棒或银弹。您应该正确构思和定制模式企业应该专注于解决支持架构所需的项目以构建自适应平台。
一些企业的SOA实施失败了 - 因为他们没有完全分析他们的业务能力模型,并认为开发Web服务意味着SOA或从大型供应商购买SOA套件会使他们启用SOA或无法显示SOA及其业务驱动因素/目标。
举例
经验的一个例子可能会澄清这一点。在过去的一份工作中,该企业的目标是提高敏捷性,客户体验并降低成本。我们决定构建一个标准的多租户SOA平台。该方法旨在开发细粒度的服务,以便我们可以经常进行更改,并为平台部署小的,可管理的更改。如果我们今天采用相同的方法,我们可能会称之为微服务架构。那时我们没有这个词,但它才有意义。
服务是基于业务能力模型建模的,第一个版本进展顺利。它们是基于JMS同步服务的XML,主要侧重于提供向代理,Web和语音通道应用程序公开的声明平台所需的功能。它使我们能够为我们的应用程序无缝部署频繁,小的更改和A / B功能支持。
当需求逐渐增加(并且它们总是如此)时,由于应用程序和消费者之间的集成复杂性,很难快速发布解决方案。集成,功能测试和生产发布需要紧密协调。随着业务开始扩展,更改频率比初始版本高出10倍,并且由于交付生命周期中的大多数任务都是手动的,因此上市时间不符合业务预期。很快,由于糟糕的微服务自动化和生命周期管理导致交付熵,我们的目标都没有实现。
经验教训 - 不要做这些事情,而是......做其他事情
这让我分享了我在旅途中学到的一些课程,以便您在使用微服务上路时能够密切关注这些项目
- 1)凝聚力混乱
我们开发了一项服务,以获取客户信息,旨在提取客户政策信息,个人信息和他们注册的计划。一段时间以来,它开始做的不仅仅是获取客户信息。随着新要求的出现,该服务经历了频繁的更改和部署。它无法扩展并满足所需的可用性。它成了众所周知的“泥球大球”。它是怎么到达那里的?对于初学者来说,没有关于功能性关注分离的治理。如果一个有影响力的消费者要求在这一项服务中加入不相关的逻辑来减少往返行程,那么这个功能就毫无疑问地被打了。也许网关或BPM层本可以避免这种情况,但是没有时间......只是时间来制定另一个业务功能点。
预防性治疗是为了管理与服务无关的业务功能。服务必须与业务能力明确对齐,不应试图在其边界之外做某事。关注的功能分离对于架构管理至关重要,否则会破坏敏捷性,性能和可伸缩性,最终建立紧密耦合的架构,导致传递熵和内聚混乱。
- 2)不认真对待自动化
我们没有自动部署策略和ops服务监控(运行时QoS指标)。它显然增加了部署期间的运营费用和手动错误。多次生产部署导致配置错误导致中断。这些服务始终以HA模式部署,因此容器数量是服务总数的3倍。操作团队无法手动处理每项服务的配置。经过一段时间后,操作人员开始抱怨架构效率低下,因为他们无法处理增加的容器数量。
这是什么疫苗?配方有多种成分。如果您还没有这样做,持续部署是每个企业都应该追求的必须投资和文化变革。至少,如果你没有办法自动测试和部署 - 不要做微服务。微服务的目标是以我们需要改变的速度来提高敏捷性;质量保证涉及每项服务都具有自动化单元,功能,安全性和性能测试。当我们开发与我们无法控制的服务集成的服务时,服务虚拟化是另一个强大的概念。
- 3)分层服务架构
人们用SOA做出的一个常见错误是误解了如何实现服务的可重用性。团队主要关注技术凝聚力,而不是关于可重用性的功能。例如,若干服务用作数据访问层(ORM)以将表公开为服务;他们认为这将是高度可重复使用的。这创建了由横向团队管理的人工物理层,这导致了交付依赖性。创建的任何服务都应该是高度自治的 - 意味着彼此独立。
创建多个技术,物理层的服务只会导致交付复杂性和运行时效率低下。我们最终拥有包装服务,编排服务,业务服务和数据服务。这些服务模型提供了技术问题。各个团队成立以管理这些层,最终导致业务逻辑蔓延,没有单一的业主能力,失去效率,总是有一个责备游戏。
服务中的层的逻辑分离很好,但是,不应该有任何进程外调用。尝试将服务视为一个原子业务实体,它必须实现一切以实现所需的业务功能。自包含服务比分层服务更具自主性和可扩展性。在多个服务中重写一些常用代码是完美的,这很好,并且保持自治级别是一个很好的权衡。最重要的是,没有技术问题分开的服务,而是必须根据业务能力将它们分开。由于这种特性,集装箱化的概念正在蓬勃发展。
- 4)依靠消费者签字
我们有来自三个不同渠道的多个应用程序所消耗的服务,即代理,网络和语音。代理渠道是我们的主要渠道,因此服务必须等待他们在投入生产之前签字。它延迟了语音和Web应用程序的生产版本。是什么将这三个通道紧紧地联系在一起?
当涉及通道特定功能时,该服务不是松散耦合的。为您的服务提供独立性。您提供的每项服务都必须具有测试套件,该套件应涵盖所有当前和未来消费者的所有服务功能,安全性,性能,错误处理和消费驱动测试。这必须作为自动回归测试的构建管道的一部分包含在内。
- 5)手动配置管理:
当我们开始做大量服务(并且由于缺乏服务生命周期治理而导致的不可避免的蔓延表现)时,管理每个服务的配置失控。由于密码错误,URL错误,值不正确等配置失败,我们的大部分生产部署都不顺利。手动管理这些变得越来越难。如果我们只使用应用程序配置管理工具作为PaaS或CD的一部分......但我们没有。
6)版本避免:
天真地,我们认为只需要一个版本的服务。然后我们开始添加主要的次要版本以适应多个消费者和频繁的变化。最终,每个版本都必须是主要版本,因为服务依赖于消费者签名。结果,容器的数量增加得非常快,并且管理它们变得非常痛苦。缺乏运行时治理是导致此问题的另一个方面。有些企业愚蠢地试图避免版本控制。假设变更是不可避免的,需要对服务进行架构。制定策略来管理向前兼容的服务更改,并让您的消费者优雅地升级。否则,它将导致消费者紧密绑定到服务版本并在发生更改时中断。
随着微服务世界所期望的服务数量的增长,复杂性也在增长。有一个版本控制策略,可以让消费者进行优雅的迁移,并确保提供商可以透明地部署更改,而不会影响任何人。限制生产中并排主要版本的数量并管理它们。
- 7)在每个服务中构建网关
我们没有API网关,我们没有运行时治理(我们不知道谁在什么时间消耗什么以及以什么速度消费)。我们开始在每个服务中实现最终用户身份验证,限制,协调,转换和路由等。它增加了每个服务的复杂性,并且我们失去了从服务到服务的实现的一致性,因此我们不知道谁实现了什么和哪里。最重要的是,我们的一些服务是为满足一个消费者的非功能性需求而构建的,而不是另一个。如果我们有一个网关,应用一些数据过滤和丰富模式就可以做到。要是。
投资API管理解决方案,以集中,管理和监控一些非功能性问题,并且还可以消除消费者管理多个微服务配置的负担。可以使用API网关编排可以减少Web应用程序往返的跨功能微服务。
结论
微服务的目标是解决三个最常见的问题,即改善客户体验,高度敏捷地满足新要求,并通过将业务功能作为细粒度服务来降低成本。这不是一个灵丹妙药,需要一个规范的平台,以高质量的敏捷方式提供服务。从其他错误中学习(我的)并避免在架构和交付过程中列出的上述模式。这是我们谈论集装箱化,云采用等之前的第一步。我希望本文能为您的企业提供一些思考,并在将这些反模式编织到您的架构之前解决这些反模式。大多数项目将推动组织内部的文化变革,不能仅靠自己完成,确保与您的高管和高级领导者建立伙伴关系。
- 50 次浏览
「微服务架构」亚马逊引领其自有微服务架构的原因
新堆栈”的真实故事,一次又一次,是关于具有巨大服务器需求的公司如何受到现有架构无法满足这些需求的限制,如何为自己解决问题,然后转而将其解决方案转售给 剩下的世界。 我们多么快地忘记了最早的例子,但也许仍然是最好的,是亚马逊。
“如果你回到2001年,”亚马逊AWS产品管理高级经理Rob Brigham表示,“亚马逊零售网站是一个庞大的单体架构。”
布里格姆星期三在亚马逊举行的2015年拉斯维加斯发布会上发表了一个主要参与人数很多的主要舞台。 他随行的幻灯片显示了一个公认的“2001”单体,这次高耸于辉煌的华盛顿山湖旁边,可能就在附近。 他对亚马逊的历史时机或者他自己的历史时机的聪明才智只是嗤之以鼻。
“现在,不要误会我的意思。 它的架构分为多层,这些层中有很多组件,“Brigham继续说道。 “但他们都非常紧密地联系在一起,他们表现得像一个巨大的巨石。 现在,许多创业公司,甚至是大公司内部的项目,都是以这种方式开始的。 他们采取一体化的方法,因为它很快就能快速行动。 但随着时间的推移,随着该项目的成熟,随着您在其上添加更多开发人员,随着它的增长和代码库变得越来越大,架构变得越来越复杂,这个整体将为您的流程增加开销,而软件开发生命周期也是如此。 开始减速。“
Brigham提出了软件开发生命周期(SDLC)作为开发团队结构的主题 - 特别是,当处理像Amazon.com这样的单一应用程序在2001年面临的实质内容时,开发人员将彼此区分开来,将团队从最终目标中分离出来。他们真正革命性地解决这个问题的方法成为了导致云计算创建的原型之一(美国宇航局的星云项目是其中之一)。
Brigham还透露的是,原始Amazon.com的非常类似tarball的粘性激发了另一个革命性的概念:服务架构的解耦。也许亚马逊没有发明微服务,也许它不是敏捷方法的先驱。但进化并不总是首先在一个地方发生。有大量证据表明亚马逊确实主动提出了这些概念。
Brigham讲述了亚马逊工程团队的故事,该工程团队在2000年有一项艰巨的任务,即协调数百名开发人员的进程内更改,解决他们之间的所有冲突,将它们合并为一个版本,并生成等待的主版本要移入生产的队列。 “即使你有那么庞大的新版本,”他说,“它仍然会在这个交付渠道上增加很多开销。整个新的代码库需要重建。所有测试用例都需要重新运行,以确保没有任何冲动。然后你需要整个应用程序,并将它全部部署到你的完整生产车队。“
亚马逊的方法不是摆脱管道,而是简化它。该公司的持续部署工具 - CodeDeploy,CodePipeline和CodeCommit - 围绕真正的云原生Web应用程序构建,其中该管道的各个部分可以编写脚本并自动化。 Rob Brigham表示,从世纪之交开始,亚马逊制造的建筑和物流变化直接导致了它现在为开发团队提供的工具。
上个月,Pivotal工程师Rohit Kelapure在详细描述整体架构的分解中描述了SpringOne 2GX会议的记忆,亚马逊的Brigham将他和他的同事们如何“将其分开”与Amazon.com单体相关联面向服务的架构。
“我们完成了代码,并提取了功能单元,这些功能单元只用于一个目的,我们用网络服务接口包装了这些功能单元,”他说。例如,有一项服务在零售商的产品详细信息页面上呈现“购买”按钮。另一个人有结账时计算正确税的功能。
在它们创建时,这些单一用途的功能似乎很容易实现。但想象一下数百个开发团队,其中一些由当时的数十个开发人员组成(而不是更舒适的“两个比萨”大小,不超过八个),其简单,单一用途的功能必须合并在一起一周又一周......以及之后的月份,随着SDLC的结构变得更大更庞大。
解耦管道
单一功能问题的解决方案是创建一个规则,开发人员必须遵守该规则,这些功能只能通过自己的Web服务API与世界其他地方进行通信。 “这使我们能够创建一个非常高度分离的体系结构,”Brigham说,“只要这些服务符合标准的Web服务接口,这些服务就可以彼此独立地迭代而不需要任何协调。”
服务的去耦使创建第一个自动部署系统之一,与原型的大部分时间今天亚马逊提供的客户 - 适当命名的“阿波罗”它帮助引进管道模型亚马逊的文化,它可能是Brigham在会议中明智地应用了一些自由编辑,因为这个过程不可能很简单。
但他对这方面很直率:通过能够看到管道作为图形化的东西,具有大小和形状,亚马逊的工程师可以更加确定他们需要多少改变他们的流程。当然,它们可以实现自动化,但为什么要实现冗余自动化?
“我们仍然注意到代码更改要花费很长时间才能从开发人员签到,到生产中运行,客户可以使用它,”他说。 “因此,作为一家以数据为导向的公司,我们对此进行了研究。 我们测量了代码更改在整个部署生命周期中跨越多个团队所花费的时间。 当我们将这些数据相加,并查看结果,并查看平均花费的时间时,我们坦率地感到尴尬。 这大约是几个星期。“
打破这些行动有助于工程师意识到这个管道中段的顺序和排列导致了“死时间” - 没有发生任何事情的间隔。 这尤其发生在部门之间的人工交接之间 - 其个性化应该引入流程完整性的交接,但实际上,这导致了低效率,浪费的空间和长长的队列。
“对于像亚马逊这样以效率而自豪的公司 - 对于一家在我们的履行中心内使用机器人来移动实体商品的公司,一家希望使用无人机将包裹部署到您家门口的公司 - 您可以想象它有多疯狂, “他说,”我们在软件交付过程中使用人来传递这些虚拟位。“
Brigham的演讲引发了CodePipeline的演示,其中包括在部署管道中发生的事件的内联脚本,以及与Amazon和GitHub上的私有存储库的集成。 亚马逊在这一点上表示,它正在避免将开发商店锁定为亚马逊品牌的做事方式,这与其合作伙伴生态系统之外的一些人所说的相反。
在这一点上你可能会想到Rob Brigham正在向合唱团讲道,或者说他正在捕鱼以获得亚马逊应该为这个行业创造的一些应得的赞誉。 事实上,令人尴尬的是,虽然这可能是为了观众中的很多人并观看现场直播而承认,亚马逊2001年的故事是他们2015年的故事。
- 80 次浏览
「微服务架构」从SOA进化看微服务架构治理
许多组织已经从SOA转移,但微服务的引入已经改变了治理游戏。 吐温泰勒解释了事情的变化。
微服务为IT的各个方面带来变化,尤其是IT治理的完成方式。 用英国政府数字服务部技术和运营副主任迈克尔·布伦顿 - 斯帕尔的话来说,"Microservices trade complicated monoliths for complex interacting systems of simple services."(微服务 交易(交换/替代) 用于简单服务的复杂交互系统的复杂整体 )
这组复杂的简单服务需要相互交流,并以与传统巨石/单体不同的方式进行管理。但这在实践中意味着什么?来!我们讨论一下。
分散的微服务治理
整体治理是集中的。决策是自上而下的,并且保持严格的控制以确保整个组织和应用程序堆栈的一致性。随着时间的推移,这种模式退化,创造了一个技术和架构停滞不前的系统,并减缓了创新的步伐。团队被迫仅仅遵循既定的事情顺序,而不是寻找新的,创造性的问题解决方案。
对于微服务治理,分散模型效果最好。正如应用程序本身被分解为众多相互依赖的服务一样,大型孤立的团队也被分解为小型的多功能团队。这是从开发,测试和IT团队转变为较小的DevOps团队的过程。
团队可以使用他们的首选语言和工具来构建他们拥有的服务,而不是使用相同的编程语言或技术框架来解决整个组织中的所有问题。这将导致缺乏统一性,这实际上可能是一个好处而不是一个缺点。首先,当每个决策涉及的繁文缛节较少时,解决方案的实施速度会更快。而且,由于构建服务的团队拥有其实施和维护,因此对服务的运行拥有更多的所有权,并且他们能够将其发展到更高的水平。
因此,对于刚刚创建并且没有单体历史的应用程序,这种分散的治理模型何时开始?它不是最低可行产品(MVP)阶段,因为在那时,应用程序只不过是一个想法。然而,当一个应用程序投入生产时,它很快就需要采用微服务架构,这就是分散治理开始的时候。
创新与治理
创新速度是实施DevOps的关键目标之一。但IT对治理的关注似乎与此结果相矛盾。这就是为什么IT和开发团队在尝试在创新和实际治理之间找到适当平衡时彼此之间往往会相互争吵的原因。
然而,这是一种错误的二分法。真正的创新不会忽视良好的治理,而伟大的治理应该支持最好的创新。因此,开发和运营团队处于同一方并具有相同的优先级和目标的DevOps原则是良好治理的推动因素。
对于微服务,分散治理是必要的。
DevOps团队必须明白,通过选择他们选择的平台和工具的能力,我们有责任遵守IT部门制定的企业标准。这就是为什么亚马逊在大约十年前刚刚开始作为云供应商时采用了“你建立它,你运行它”的座右铭。亚马逊网络服务公司希望其开发人员与IT共享对其提供的应用程序和功能的稳定性和可靠性的责任。这一原则有助于推动它成为当今领先的基础设施即服务平台。
在不牺牲控制的情况下加速治理的一种方法是自动执行任务。这种自动化可以在治理的不同方面发生,例如安全性和可靠性。
安全
自动化安全涉及策略的组合。与单个大型单片应用程序相比,分布式,API可访问的应用程序对攻击者具有更多潜在的入口点,但通常,使用访问控制规则,Web应用程序防火墙(WAF)的组合可以更容易地保护这些入口点。规则,身份验证和速率限制。自动执行这些任务需要一个可以处理负载平衡,内容缓存,安全策略等的现代Web服务器。
这种平台的一个例子是Nginx Plus。其ModSecurity WAF可保护应用程序层免受攻击,例如SQL注入,本地文件包含,跨站点脚本和某些类型的分布式拒绝服务攻击。此工具可用于静态分析代码,针对代码运行渗透测试和模糊输入,并识别常见的安全相关编程错误,例如无效输入。
可靠性
为了使微服务应用程序顺利运行,其服务需要能够彼此通信并且能够很好地协同工作。这需要良好的服务发现。随着为服务提供动力的底层节点或容器的更改,它们需要由系统识别。这样,服务仍然可见,并且可以成功路由请求。
此外,随着请求的激增,它们无法由单个实例处理,需要跨其他实例进行路由以共享工作负载。这种类型的服务发现和负载平衡 - 在协同工作时 - 使您能够构建可承担任何工作负载的可靠应用程序。
对于微服务治理,分散化是必要的。它提供了开发人员所渴望的创新和灵活性,同时保持了IT运营人员所需的安全性和可靠性。当您希望管理您的应用程序以使其更可靠和安全时,促进分散治理的工具是时间的需要。
- 36 次浏览
「微服务架构」企业微服务架构
首先,来自Darren的消息是,微服务架构并不是构建大规模企业应用程序的新方式。 Netflix和亚马逊等公司已经实施了微服务架构,在过去几年中提供了成功的产品。
但是微服务架构适合您的组织吗?答案不是简单的是或否,但我会尝试用Darren的讲话作为指导来引导你找到答案。
微服务架构是一个将在多个方面影响您的组织的旅程 - 在文化,技术和运营方面。让我们考虑一个跨国企业的单体应用程序,该应用程序已经成熟多年并占据了市场主导地位。从软件工程师或架构师的角度来看,简化代码库的复杂区域以使其更易于维护是一种很好的做法。
那么当你遇到一个疯狂的大型Java类时,你会怎么做,这些Java类包含许多代码行和一个不幸的方法,占40%的类?一个自然(和明智)的事情是与团队进行某种形式的讨论,并提出一种策略,将类分解为多个较小的类和/或方法。现在问问自己为什么清理整体Java类很重要?
如果您的答案是更简单的单元测试,更容易进行代码审查,更改影响,那么我建议您将相同的思维过程应用于构成产品的整体服务和模块。
将monolith应用程序拆分为更小,可管理的服务有几个原因。如果您是组织中的业务负责人,以下可能是您的一些担忧:
- 进入新市场
- 支持创新
- 在业务功能和系统之间创建更好的一致性
- 改变治理结构以更好地支持快速决策
- 快速响应新的市场条件
- 抵御市场颠覆者
作为首席技术官或首席架构师,您有责任评估最能解决上述问题的不同解决方案,并设计符合组织愿景的系统。以下是在考虑微服务架构时需要关注的一些关键领域:
- 多种服务之间的依赖关系管理
- 端到端功能测试的大小
- 快速检测故障,正常故障并快速恢复
- 容器作为构建工件
- 跨组织边界重用组件/模块
- 公共使用服务的API合同
- 监控部署生命周期的各个阶段
- 集中式架构团队与分散式架构团队
- 基建自动化
架构师的角色随着微服务的采用而发展,并委托他或她承担挑战性的责任,从而形成架构治理。架构治理是组织尝试开始微服务之旅的关键因素之一,因为如果没有正确的顺序,该过程将很快导致微管理而不是微服务。
将monolith分成多个可管理服务的最大优势之一是使一个小团队能够全面管理其服务的生命周期 - 开发,测试和推向生产。这意味着企业架构师不再需要承担单个服务的内部工作负担,而是高度关注整个系统中服务之间的交互。此外,架构师应密切关注系统的整体运行状况,以确保每项服务以一致的方式生成与监控相关的指标。
为开发团队提供完全的权限,以便在构建服务时选择他们选择的技术堆栈并不意味着架构师不再对其实现有任何发言权。事实上,架构师受到高度鼓励,可以教育和影响开发团队。例如,考虑到服务必须处理的数据的高度非结构化特性,架构师可以建议使用NoSQL数据库而不是关系数据库。例如,Netflix将JVM的使用标准化为一个平台,以便他们可以跨服务使用标准库。
虽然架构师之一忙于与开发团队合作,但另一个人正在与“业务”团队合作,以使技术愿景与业务愿景保持一致。这对于建筑师来说是一个重要特征,因为系统需要能够适应产品愿景或用户反馈的变化。因此,架构师需要始终掌握行业中的最新趋势,工具和框架,并准备好为给定的工作应用正确的工具。
Darren谈到了“部署耦合”的概念,强调了许多单片系统和传统企业架构需要在单个版本中将所有系统的更改同步到生产中这一事实。这反过来导致长时间运行的测试周期从未捕获任何东西,并且感觉没有人可以失败,因为一个系统未达到其截止日期意味着其他所有人都被推出。
通过使用远程调用作为集成服务的机制,可以避免部署耦合。微服务社区建议使用REST over HTTP而不是其他远程通信协议(如RPC或SOAP),因为基于非HTTP的协议往往会将您绑定到特定平台或对互操作性施加限制。通过基于用户级合同使用HTTP集成服务,开发团队可以避免永无止境的端到端测试阶段的陷阱并保持合适的速度。
然而,管理数百个服务会使组织的操作复杂化。作为一个组织,您必须确保拥有可靠的DevOps基础架构,以便处理应用程序监视和警报。正如我上面提到的,架构师必须至少标准化服务发出日志的方式,以便运营团队可以监控整体系统运行状况,并且如果需要进一步调查,则能够深入到服务级别监控。
最后,每个组织都必须努力招募,培训和留住高素质的技术人员,因为“微观团队”之间的沟通和协作需要有效,技术上的刺激以及最重要的乐趣是至关重要的!
我希望这可以解决你对大型企业中微服务架构的一些担忧。我鼓励你观看这个非常有见地的视频录制,其中Darren更详细地讨论了这些非常关注的问题。如果您正在寻找有关微服务架构的其他材料,请查看Martin Fowler的文章或ThoughtWorks网站上的其他微服务洞察博客。
- 56 次浏览
「微服务架构」分散您的微服务组织
适应性 - 快速,轻松地进行变革的能力 - 已成为现代企业的首要目标,并迫使技术团队构建更容易,成本更低的平台。在这样的环境中工作,这些团队越来越多地被软件架构的微服务风格所吸引。吸引他们的是承诺加快软件更改的方法,而不会给业务带来不必要的危险。
微服务的工作方式在很大程度上可以通过支持软件组件和数据的分散来实现 - 更具体地说,通过将“单体”元素分解为更小,更容易更改的部分,并在网络上部署这些部分。要使这种架构运行良好,需要改变工作方式以及如何管理工作。采用微服务的组织是“脱离开发人员的方式”,并提供自由和自主来实现魔术。
在组织设计中,他们的目标是分散决策权。而不是让少数人为组织中的每个人做出架构和软件决策,分散化将使他们能够在执行工作的人员之间分配决策权。
直接向工人推行决策权使他们能够以更大的自由和自主权生产。在适当的情况下,这将导致更好,更快的变化。但是,如果您的组织弄错了,一系列错误的决策可能会降低变更速度 - 或者更糟糕的是,最终会损害您的业务。
诀窍是只分散那些可以帮助你加速的事情,而不会牺牲系统的安全性。
找到正确的权力下放战略是一个进化过程,需要您进行调整,分析和调整。为了帮助您开始正确的方向,以下是您应该考虑的三个最重要的问题:
我们应该针对哪些决策?
我们所有这一切的目标是增强您平台的可变性。因此,您应首先找到阻止变更发生的瓶颈。仔细研究功能和变化如何从概念转变为实施,并找到需要工作的人不能做的过程部分,因为他们正在等待其他人做出决定。
权力下放不是解除瓶颈的灵丹妙药。然而,在一个倾向于集中决策的组织中,权力下放可能会有所帮助。另一方面,如果您找不到因集中决策流程而导致员工陷入困境的许多情况,那么分散化不应成为您最关心的问题。
使微服务系统工作不仅仅需要改变有关组件大小的想法。组织中涉及创建和更改服务的所有区域都可以发挥作用。以下是可能成为微服务领域分散化候选人的决策类型的非详尽列表:
- 服务生命周期 - 服务何时创建或退役?他们叫什么?我们什么时候需要将它们分开?
- 服务实施 - 我们应该在每项服务中使用哪些工具,语言和架构?
- 系统架构 - 服务如何与其他人交谈?开发人员如何了解它们?
- 数据架构 - 如何在服务之间共享数据?
- 变更流程 - 何时可以更改服务?部署和QA有哪些工具和流程?
- 团队管理 - 谁在哪个团队服务?每个团队负责什么?团队成员做什么?
- 人员管理 - 人们如何被雇佣和解雇?员工如何激励和奖励?什么是休假政策?
- 安全管理 - 我们如何降低安全事件的风险?需要做些什么才能提高整个系统的安全性?
- 采购 - 可以购买哪些软件?使用开源软件需要哪些保护措施?
分析这些空间中的决策是如何制定的,这是值得的。它们如何影响系统的更改方式?哪些决策过程阻碍了你?哪些阻止人们进行创新?最后,在哪些情况下,更多的自由和自治会有益吗?
Netflix是一家能够以创新方式下放权力的公司的典范。其政策赋予员工权力,以决定他们需要多少时间来分散传统上受到严密控制的决策。
赋予员工指定自己的假期分配的权限可能听起来很奇怪。但是,如果您希望将组织的可变性提升到更高的档位,那么您应采取的确切方法是消除冗余和不必要的协调工作,同时避免引入新风险。追求构建软件的微服务风格的团队应该考虑在整个组织中进行这些优化。
这并不意味着分发假日决策的政策应该是微服务架构的原则。 Netflix可以做到这一点,因为它的文化和劳动力使这样的政策更容易实施。它的员工可以做出最适合整个系统的决策,而且公司因其对员工的选择而闻名。
并非每个组织都看起来像Netflix,很少有人在Netflix的在线视频内容传输领域运营。每家公司都有自己独特的约束和目标。您需要为自己发现自己的目标和约束。分析,洞察力和实验将帮助您确定权力下放工作的优先顺序,并引导您的系统实现适应性目标。
参与的人是谁?
人们做出的一些决定对他们公司的影响非常大。改变银行账户交易方式的决定对传统银行来说是有风险的。对于具有熟悉旧接口的大型用户群的软件公司而言,更改应用程序的用户体验的决定将是一种风险。
组织试图加强对这些类型决策的控制,以便最大限度地降低风险,从而实现决策权的集中化。例如,在过去的几年中,Apple以拥有一个高度集中的设计小组而闻名,该小组由相对较少的人组成,他们做出了大部分关于其产品设计的决策。
集中化是因为合适的人需要做出最重要的决策。通常,“合适的人”是那些拥有人才,专业知识和经验的人,这使我们能够充分信任他们以做出最佳决策。我们可以称这些人为我们的“明星”决策者。
如果一个组织只有星星,那么它的所有决定都可以分散。如果我们信任更多员工以做出最佳决策,我们会将更多决策分发给更多人。
在实践中,公司拥有数量有限的明星决策者。实际上,大多数团队都有一些明星与更多的决策者相结合,他们有能力但缺乏一些必要的经验或才能来做出完美的决策。
好消息是,你不需要一个全明星团队来采用分权策略。您只需要考虑如何将您的团队组织在一起以及您部署最佳决策者的位置。
微服务风格使这一切变得更加容易,因为决策的影响可以在实现个别变更的速度增加的同时受到限制。如果一个团队在处理微服务时做出了错误的决定,那么错误的爆炸半径应该很小并且包含在内。当系统变更便宜且容易时,团队可以快速改进以前的决策,使他们能够更快地做出最佳决策。
在这种环境中,你不受你的明星力量的限制 - 当目标是达到最佳决策时,你只需要提供一个系统,让有能力的工人获得自由和自主权。
谁拥有哪一部分?
没有立即做出决定。它基于选择,而选择又基于领域知识。决不应立即实施。有时它可能需要某人的祝福,而在其他时候,它可能需要高度专业化的技能或知识来实施。
管理专家Henry Mintzberg为我们提供了一个很好的模型,概述了决策过程的步骤:
- 研究和信息收集
- 产生选择
- 选择(做出选择)
- 授权选择
- 执行和实施
所有这一切的关键在于,在采用决策权力下放时,您不需要绝对。 Mintzberg的每个步骤都可以独立集中或分散,在平衡基于决策的系统变更的速度和安全性时,可以提供更大的灵活性。
考虑一家大公司典型招聘流程的情况:当找到新员工时,它是集中的人力资源部门,广播开放职位并邀请人们申请工作。同一个集中团队筛选候选人并生成该组中最佳的列表。然后将该清单移交给实际的招聘经理,该经理根据进一步的审查选择最佳候选人。从那里,招聘经理将球交还给人力资源中心团队,他们完成了文书工作并完成了整个过程。
这种集中式选择生成模式与分散式选择选择相结合是大公司中常见的选择。事实上,大多数采用微服务风格的组织都以某种形式使用它。
例如,集中式企业团队可以识别所有微服务团队应该使用的三种数据库。由各个团队决定选择,但他们可以从提供的菜单中进行选择。如果他们偏离批准的列表,他们将需要证明他们的决定,从而为集中团队提供反馈机制,他们可以重新评估菜单。
分散流程的选择,授权和执行部分可以使各个团队快速,大规模地进行迁移。集中研究和选择生成步骤,总体上损害了创新,但降低了决策的风险,从而对整个系统产生负面影响。这是一种流行的模式,因为它为大多数组织提供了正确的妥协方式。
当人们谈论微服务组织时,权力下放会出现很多,因为它是提高变革速度的有效方法。但不要忘记它只是等式的一部分。您的员工是谁,您的团队如何协调,以及他们所处理的所有系统,工具和环境同样重要。
您必须了解考虑如何制定决策 - 更重要的是,如何改进流程 - 是向变革友好型组织迈进的一种很好的方式。
- 23 次浏览
「微服务架构」微服务架构中的数据一致性
在微服务中,一个逻辑上原子操作可以经常跨越多个微服务。即使是单片系统也可能使用多个数据库或消息传递解决方案。使用多个独立的数据存储解决方案,如果其中一个分布式流程参与者出现故障,我们就会面临数据不一致的风险 - 例如在未下订单的情况下向客户收费或未通知客户订单成功。在本文中,我想分享一些我为使微服务之间的数据最终保持一致而学到的技术。
为什么实现这一目标如此具有挑战性?只要我们有多个存储数据的地方(不在单个数据库中),就不能自动解决一致性问题,工程师在设计系统时需要注意一致性。目前,在我看来,业界还没有一个广为人知的解决方案,可以在多个不同的数据源中自动更新数据 - 我们可能不应该等待很快就能获得一个。
以自动且无障碍的方式解决该问题的一种尝试是实现两阶段提交(2PC)模式的XA协议。但在现代高规模应用中(特别是在云环境中),2PC似乎表现不佳。为了消除2PC的缺点,我们必须交易ACID for BASE并根据要求以不同方式覆盖一致性问题。
Saga模式
在多个微服务中处理一致性问题的最着名的方法是Saga模式。 您可以将Sagas视为多个事务的应用程序级分布式协调。 根据用例和要求,您可以优化自己的Saga实施。 相反,XA协议试图涵盖所有场景。 Saga模式也不是新的。 它在过去已知并用于ESB和SOA体系结构中。 最后,它成功地转变为微服务世界。 跨越多个服务的每个原子业务操作可能包含技术级别的多个事务。 Saga Pattern的关键思想是能够回滚其中一个单独的交易。 众所周知,开箱即用的已经提交的单个事务无法进行回滚。 但这是通过引入补偿操作来实现的 - 通过引入“取消”操作。
除了取消之外,您还应该考虑使您的服务具有幂等性,以便在出现故障时重试或重新启动某些操作。 应监控故障,并应积极主动地应对故障。
对账
如果在进程的中间负责调用补偿操作的系统崩溃或重新启动,该怎么办? 在这种情况下,用户可能会收到错误消息,并且应该触发补偿逻辑,或者 - 当处理异步用户请求时,应该恢复执行逻辑。
要查找崩溃的事务并恢复操作或应用补偿,我们需要协调来自多个服务的数据。对账
是在金融领域工作的工程师所熟悉的技术。你有没有想过银行如何确保你的资金转移不会丢失,或者两个不同的银行之间如何汇款?快速回答是对账。
在会计中,对账是确保两组记录(通常是两个账户的余额)达成一致的过程。对帐用于确保离开帐户的资金与实际支出的资金相匹配。这是通过确保在特定会计期间结束时余额匹配来完成的。 - Jean Scheid,“了解资产负债表账户调节”,Bright Hub,2011年4月8日
回到微服务,使用相同的原则,我们可以在一些动作触发器上协调来自多个服务的数据。当检测到故障时,可以按计划或由监控系统触发操作。最简单的方法是运行逐记录比较。可以通过比较聚合值来优化该过程。在这种情况下,其中一个系统将成为每条记录的真实来源。
事件簿
想象一下多步骤交易。如何在对帐期间确定哪些事务可能已失败以及哪些步骤失败?一种解决方案是检查每个事务的状态。在某些情况下,此功能不可用(想象一下发送电子邮件或生成其他类型消息的无状态邮件服务)。在其他一些情况下,您可能希望立即了解事务状态,尤其是在具有许多步骤的复杂方案中。例如,预订航班,酒店和转机的多步订单。
复杂的分布式流程
在这些情况下,事件日志可以提供帮助。记录是一种简单但功能强大的技术。许多分布式系统依赖于日志。 “预写日志记录”是数据库在内部实现事务行为或维护副本之间一致性的方式。相同的技术可以应用于微服务设计。在进行实际数据更改之前,服务会写入有关其进行更改的意图的日志条目。实际上,事件日志可以是协调服务所拥有的数据库中的表或集合。
事件日志不仅可用于恢复事务处理,还可用于为系统用户,客户或支持团队提供可见性。但是,在简单方案中,服务日志可能是冗余的,状态端点或状态字段就足够了。
编配(Orchestration)与编排(choreography)
到目前为止,您可能认为sagas只是编配(orchestration )方案的一部分。但是sagas也可以用于编排(choreography ),每个微服务只知道过程的一部分。 Sagas包括处理分布式事务的正流和负流的知识。在编排(choreography )中,每个分布式事务参与者都具有这种知识。
单次写入事件
到目前为止描述的一致性解决方案并不容易。他们确实很复杂。但有一种更简单的方法:一次修改一个数据源。我们可以将这两个步骤分开,而不是改变服务的状态并在一个过程中发出事件。
更改为先
在主要业务操作中,我们修改自己的服务状态,而单独的进程可靠地捕获更改并生成事件。这种技术称为变更数据捕获(CDC)。实现此方法的一些技术是Kafka Connect或Debezium。
使用Debezium和Kafka Connect更改数据捕获
但是,有时候不需要特定的框架。一些数据库提供了一种友好的方式来拖尾其操作日志,例如MongoDB Oplog。如果数据库中没有此类功能,则可以通过时间戳轮询更改,或使用上次处理的不可变记录ID查询更改。避免不一致的关键是使数据更改通知成为一个单独的过程。在这种情况下,数据库记录是单一的事实来源。只有在首先发生变化时才会捕获更改。
无需特定工具即可更改数据捕获
更改数据捕获的最大缺点是业务逻辑的分离。更改捕获过程很可能与更改逻辑本身分开存在于您的代码库中 - 这很不方便。最知名的变更数据捕获应用程序是与域无关的变更复制,例如与数据仓库共享数据。对于域事件,最好采用不同的机制,例如明确发送事件。
事件第一
让我们来看看颠倒的单一事实来源。如果不是先写入数据库,而是先触发一个事件,然后与自己和其他服务共享。在这种情况下,事件成为事实的唯一来源。这将是一种事件源的形式,其中我们自己的服务状态有效地成为读取模型,并且每个事件都是写入模型。
事件优先方法
一方面,它是一个命令查询责任隔离(CQRS)模式,我们将读取和写入模型分开,但CQRS本身并不关注解决方案中最重要的部分 - 使用多个服务来消耗事件。
相比之下,事件驱动的体系结构关注于多个系统所消耗的事件,但并未强调事件是数据更新的唯一原子部分。所以我想引入“事件优先”作为这种方法的名称:通过发出单个事件来更新微服务的内部状态 - 包括我们自己的服务和任何其他感兴趣的微服务。
“事件优先”方法面临的挑战也是CQRS本身的挑战。想象一下,在下订单之前,我们想要检查商品的可用性。如果两个实例同时收到同一项目的订单怎么办?两者都将同时检查读取模型中的库存并发出订单事件。如果没有某种覆盖方案,我们可能会遇到麻烦。
处理这些情况的常用方法是乐观并发:将读取模型版本放入事件中,如果读取模型已在消费者端更新,则在消费者端忽略它。另一种解决方案是使用悲观并发控制,例如在检查项目可用性时为项目创建锁定。
“事件优先”方法的另一个挑战是任何事件驱动架构的挑战 - 事件的顺序。多个并发消费者以错误的顺序处理事件可能会给我们带来另一种一致性问题,例如处理尚未创建的客户的订单。
诸如Kafka或AWS Kinesis之类的数据流解决方案可以保证将按顺序处理与单个实体相关的事件(例如,仅在创建用户之后为客户创建订单)。例如,在Kafka中,您可以按用户ID对主题进行分区,以便与单个用户相关的所有事件将由分配给该分区的单个使用者处理,从而允许按顺序处理它们。相反,在Message Brokers中,消息队列具有一个订单,但是多个并发消费者在给定顺序中进行消息处理(如果不是不可能的话)。在这种情况下,您可能会遇到并发问题。
实际上,在需要线性化的情况下或在具有许多数据约束的情况(例如唯一性检查)中,难以实现“事件优先”方法。但它在其他情况下确实很有用。但是,由于其异步性质,仍然需要解决并发和竞争条件的挑战。
设计一致性
有许多方法可以将系统拆分为多个服务。我们努力将单独的微服务与单独的域匹配。但域名有多细化?有时很难将域与子域或聚合根区分开来。没有简单的规则来定义您的微服务拆分。
我建议务实并考虑设计方案的所有含义,而不是只关注领域驱动的设计。其中一个影响是微服务隔离与事务边界的对齐情况。事务仅驻留在微服务中的系统不需要上述任何解决方案。在设计系统时我们一定要考虑事务边界。在实践中,可能很难以这种方式设计整个系统,但我认为我们应该致力于最大限度地减少数据一致性挑战。
接受不一致
虽然匹配帐户余额至关重要,但有许多用例,其中一致性不那么重要。想象一下,为分析或统计目的收集数据。即使我们从系统中随机丢失了10%的数据,也很可能不会影响分析的业务价值。
与事件共享数据
选择哪种解决方案
数据的原子更新需要两个不同系统之间达成共识,如果单个值为0或1则达成协议。当涉及到微服务时,它归结为两个参与者之间的一致性问题,并且所有实际解决方案都遵循一条经验法则:
在给定时刻,对于每个数据记录,您需要找到系统信任的数据源
事实的来源可能是事件,数据库或其中一项服务。实现微服务系统的一致性是开发人员的责任。我的方法如下:
- 尝试设计一个不需要分布式一致性的系统。不幸的是,对于复杂的系统来说,这几乎是不可能的。
- 尝试通过一次修改一个数据源来减少不一致的数量。
- 考虑事件驱动的架构。除了松散耦合之外,事件驱动架构的强大优势是通过将事件作为单一事实来源或由于更改数据捕获而产生事件来实现数据一致性的自然方式。
- 更复杂的场景可能仍然需要服务,故障处理和补偿之间的同步调用。知道有时候你可能需要在之后进行调和。
- 设计您的服务功能是可逆的,决定如何处理故障情况并在设计阶段早期实现一致性。
- 35 次浏览
「微服务架构」微服务集成中的3个常见缺陷-以及如何避免它们
微服务风靡一时。 他们有一个有趣的价值主张,即在与多个软件开发团队共同开发的同时,将软件快速推向市场。 因此,微服务是在扩展您的开发力量的同时保持高敏捷性和快速的开发速度。
简而言之,您将系统分解为微服务。 分解并不是什么新鲜事,但是通过微服务,您可以为团队提供尽可能多的自主权。
例如,专用团队完全拥有该服务,可以随时部署或重新部署。 他们通常也会使用devops来控制整个服务。 他们可以做出相当自主的技术决策并运行他们自己的基础设施数据库。 被迫操作软件通常会限制有线技术选择的数量,因为当人们知道他们将来必须操作它时,往往会更频繁地选择无聊技术。
Microservices are about decomposition, but giving each component a high degree of autonomy and isolation (微服务是关于分解,但为每个组件提供高度自治和隔离)
微服务架构的一个基本结果是每个微服务都是与其他微服务远程通信的独立应用程序。 这使得微服务环境成为高度分散的系统。 分布式系统有其自身的挑战。 在本文中,我将向您介绍我在最近的项目中看到的三个最常见的陷阱。
1.沟通很复杂
远程通信不可避免地要尊重分布式编程的8个谬误。 隐藏复杂性是不可能的,并且许多努力(例如Corba或RMI)已经失败了。 一个重要原因是您必须在服务中设计失败,以便在失败是新常态的环境中取得成功。 但是有一些共同的模式和框架可以帮助你。 让我们从一个例子开始 - 我经常遇到的真实情况。
我想飞往伦敦。 当我收到办理登机手续的邀请时,我去了航空公司的网站,选择了我的座位,然后按下按钮取回我的登机牌。 它给了我以下回应:
让我们假设航空公司使用微服务(可能不是这种情况,但我知道有其他航空公司这样做)。
我注意到的第一件事:错误返回得相当快,网站的其他部分表现正常。所以他们使用了重要的失败快速模式。条形码生成中的错误不会影响整个网站。我可以做其他一切;我无法获得登机牌。快速失败非常重要,因为它可以防止本地错误导致整个系统崩溃。该领域众所周知的模式是断路器,隔板和维修网。这些模式对分布式系统的生存至关重要。
快速失败是不够的
但快速失败是不够的。它将故障处理卸载到客户端。在这种情况下,我个人不得不重试。在上述情况下,我甚至要等到第二天,直到问题得到解决,我才能拿到登机牌!对我而言,这意味着我必须使用自己的工具来坚持重试(我的日历),以确保我没有忘记。
为什么航空公司不自行重试?他们知道我的联系数据,并且可以在准备好时异步发送登机牌。更好的反应是:
这不仅会更方便,而且还会降低总体复杂性,因为需要查看故障的组件数量会减少:
您可以将相同的原则转移到服务到服务通信。每当服务本身可以解决故障时,它就会封装重要的行为。这使得所有客户的生活更加轻松,API更加清洁。解决故障可能是有状态的(有些人称之为长时间运行)。我认为状态处理是微服务中故障处理的关键问题。
当然,上面描述的行为并不总是你想要的,将故障移交给客户端就可以了。但这应该是根据业务需求做出的有意识的决定。
我观察到大多数情况下,另一个原因导致人们避免有状态重试:它伴随着状态处理的复杂性。该服务必须重试几分钟,几小时或几天。它必须可靠地执行此操作(请记住:即使系统重新启动,我也希望登机牌),这涉及处理持久状态。
如何管理持久状态?
我看到两种处理持久状态的典型方法:
存储在数据库中的实体等持久性事物。
虽然这开始非常简单,但通常会导致很多意外的复杂性。您不仅需要数据库表,还需要一些调度程序组件来进行重试。您可能需要一些监视组件来查看或编辑等待作业。如果整体业务逻辑发生变化,您仍需要进行版本控制,而您仍想进行重试。等等等等。
这种思路导致许多开发人员如上所述跳过正确的故障处理,导致整个架构的复杂性增加 - 以及糟糕的客户体验。
相反,我建议利用轻量级工作流引擎或状态机。
构建这些引擎是为了保持持久状态并处理围绕流语言,监视和操作的后续要求,扩展以处理高容量等等。
市场上有几个轻量级工作流引擎。他们中的许多人使用ISO标准BPMN来定义流,其中许多是开源的。在这里,我将使用Camunda的开源工作流引擎来说明基本原则(快速免责声明:作为该项目背后的公司的共同创始人,我明显偏向于我的工具选择,但这是我最熟悉的工作流引擎)。对于前面描述的简单用例,可以使用Java DSL轻松创建工作流:
另一种选择是在BPMN中以图形方式建模工作流程:
这些工作流引擎在架构方面非常灵活。许多开发人员认为工作流引擎是一个集中组件,但事实并非如此。没有必要引入集中组件!如果不同的服务需要工作流引擎,则每个服务都可以运行自己的引擎来维护服务的自治和隔离。本博文中有关架构选项的更多细节将对此进行详细讨论。
另一个误解是工作流迫使开发人员切换到异步处理。这也不是真的。在上面的示例中,当一切顺利运行时,登记组件可以同步返回登机牌。只有在出现错误时才会回退到异步处理。这可以很容易地反映为HTTP返回码,200表示“一切正常,这是你的结果”,202表示“得到它,我会给你回电话。”有一些具体的示例代码来处理这个,它利用了一个简单的信号。
我将工作流引擎视为工具箱的重要组成部分,用于正确的故障处理,这通常涉及长期运行的行为,如状态重试。
2.异步性需要注意
这导致我们进行异步通信,这通常意味着消息传递。异步性通常被认为是分布式系统中的最佳默认值,因为它提供了解耦,尤其是时间解耦,因为任何消息都可以独立于接收器的可用性发送。一旦服务提供商可用,该消息将立即发送,而无需额外的魔力。
因此,重试的问题已经过时,但会出现类似的问题:您必须担心超时问题。假设航空公司在登记方案中使用异步通信。登记组件向条形码生成服务发送消息,然后等待响应。您无需关心条形码生成器的可用性,因为消息总线将在适当的时候传递消息。
但是,如果请求或响应因任何原因而丢失怎么办?您是否会在办理登机手续时遇到困难,未能在没有注意到的情况下将登机牌发送给客户?我打赌很多公司这样做,这再次导致我,客户监控响应并采取行动,如果没有登机牌在超时内到达。同样,我必须利用我的个人调度基础设施(日历)。
更好的方法是让服务监控超时本身,并在条形码未能及时到达时执行回退。可能的后备是重新发送消息,这实质上是重试。
您也可以利用工作流自动化技术来处理此用例。 BPMN中的工作流可能如下所示:
作为奖励,您可以免费报告重试次数,典型响应时间以及无法及时处理的工作流程数量。操作员可以通过提供大量上下文来轻松检查和修复失败的工作流实例,例如消息中包含的数据以及消息发送的时间。纯粹的基于消息的解决方案通常会忽略这种级别的可见性和操作控制。
我甚至看到公司更进一步,使用工作流引擎而不是消息传递中间件来在微服务之间分配工作。如果工作流引擎不主动调用服务或发送消息(称为推送原则)但依赖于工作者要求工作(称为拉取原则),则这是可能的。现在,工作流引擎中的工作队列就像一个消息队列。当我问他们为什么喜欢工作流引擎时,他们说消息传递解决方案缺乏相同的可见性和工具质量,他们希望避免构建自己的操作工具。
3.分布式交易很难
事务是以全有或全无的方式执行的一系列操作。我们都从数据库中知道这一点。您开始一个事务,做一些事情,然后提交或回滚事务。这些事务称为ACID:原子,一致,隔离和持久。
在分布式系统中,您不能指望ACID事务。是的,有像XA这样的协议实现了所谓的两阶段提交。或WS-AtomicTransaction。或像Google Spanner这样复杂的实施。但目前的共识是,这些协议太昂贵,太复杂,或者根本无法扩展。 Pat Helland的“超越分布式交易的生活:Apostate的意见”是一个很好的背景阅读。
但当然,商业交易的要求并没有消失。在没有ACID的情况下解决业务交易的常见技巧是使用补偿。这意味着您可以对过去不正确执行的所有活动执行撤消活动。 BPMN具有此内置功能,因此您可以定义这些撤消活动,并且工作流引擎负责以正确的顺序可靠地执行它们。这次我将使用预订机票的例子:
这通常也被称为Saga模式,最近变得非常流行。我在“Saga:如何在没有两阶段提交的情况下实现复杂的业务交易”中写到了这一点,其中我还链接了其他来源和一些代码。
请注意,此方法与ACID事务不同,因为您可以具有不一致的中间状态。所以,我可以保留一个座位,但尚未预订有效的机票。或者我可以在没有付款的情况下买票。实际情况是,只要确保最终清理它们并使系统恢复到一致状态,通常可以忍受这些暂时的不一致。这称为最终一致性,这是分布式系统中的一个重要概念。 “在SoA网络中拥抱最终的一致性”指出它非常好:
最终的一致性通常会产生更好的性能,更简单的操作和更好的可伸缩性,同时要求程序员理解更复杂的数据模型。
好消息是工作流程自动化简化了补偿的处理。这是因为工作流引擎可以可靠地调用所有必要的补偿活动。
服务提供商 - 做好功课!
到目前为止,我已经提出了三种简单的补救措施来应对分布式系
- 重试
- 超时
- 赔偿金
所有这些都可以使用轻量级工作流自动化技术实现。但是为了利用这些配方,每个服务提供商都必须做好功课。这意味着
- 提供补偿活动和
- 实现幂等性。
虽然第一个要求应该是显而易见的(如果有取消票证的服务,我只能取消票证),第二个 - 幂等性 - 需要更多解释。
幂等
我谈了很多关于重试的事情。一个常见的问题是,如果我通过重试两次调用服务怎么办?这个问题问得好!
首先要确保您了解每种形式的远程通信都会遇到此问题!无论何时通过网络进行通信,都无法区分三种故障情形:
- 该请求尚未到达提供商
- 请求已到达提供商,但在处理期间它已爆炸
- 提供程序处理了请求,但响应丢失了
一种可能性是询问服务提供商是否已经看到此请求。但更常见的方法是使用重试并以允许重复调用的方式实现服务提供程序。这更容易设置。
我看到两种简单的方法来掌握幂等性:
- 自然的幂等性。有些方法可以随意执行,因为它们只是翻转一些状态。示例:confirmCustomer()
- 商业幂等。有时,您拥有允许您检测重复呼叫的业务标识符。示例:createCustomer(email)
如果这些方法不起作用,您需要添加自己的幂等性处理:
- 唯一身份。您可以生成唯一标识符并将其添加到呼叫中。这样,如果您在服务提供商端存储该ID,则可以轻松发现重复呼叫。如果您利用工作流引擎,您可能会让它完成繁重的工作(例如,当Camunda允许在启动期间对密钥进行重复检查时)。示例:charge(transactionId,amount)
- 请求哈希。如果您使用消息传递,则可以通过存储消息的哈希值来执行相同的操作。您可以再次利用工作流引擎,或者您可以使用具有内置租赁功能的数据库(如Redis)。
长话短说:在您的服务中注意幂等性。这将带来巨大的回报。
给我看一下代码
您可以使用BPMN和开源Camunda引擎找到实现我在此描述的模式的源代码
Java或C#。(需要的后台发消息)
摘要
在本文中,我介绍了三个常见的陷阱,我看到客户在整合微服务时踩到了:低估了远程通信的复杂性,忽略了异步性的挑战,忘记了商业交易。
通过重试,超时和补偿活动的状态模式引入处理这些情况的功能可以降低微服务基础架构的整体复杂性并增强其弹性。它还有助于:
- 将重要的故障处理和事务行为封装在它所属的位置:在服务本身的上下文中。
- 将故障或超时处理的工作量减少到更小的范围,从而降低整体复杂性。
- 简化服务API,只发布对客户真正重要的故障。
- 改善客户体验,客户可能是其他服务,内部员工,甚至是客户。
使用轻量级工作流引擎,您可以通过应用自行开发的解决方案来处理有状态模式,而无需投入大量精力或冒着意外复杂性的风险。随附的源代码提供了具体示例。
- 23 次浏览
「微服务架构」更多关于微服务-边界,治理,重用和复杂性
我最喜欢博客(而且从来没有得到足够的)的一件事就是反馈。我之前发表的文章“雕刻它 - 微服务,巨石和康威定律”,产生了一些评论/讨论,这些评论/讨论合在一起,保证了一个后续帖子。
其中一个讨论是与Ruth Malan和Jeff Sussna就治理进行的Twitter交流。杰夫认为分权治理的概念是“有争议的”,尽管他认为集权治理是“有问题的”和“僵化”。露丝观察到“或者至少是一个权衡轴和(组织)设计......? (甚至“联邦”也有广泛的解释)“。我为一些集中治理的需要辩护,但是克制,注意“管理比必要更深的会导致问题,例如:问题是BDUF(IMO)是B,而不是UF“。
当应用程序跨越多个团队,所有团队都独立部署时,将需要一些集中式治理。关键是制定道路规则,允许团队独立工作而不会相互干扰,不会尝试微观管理。这种编排需求不仅仅局限于技术方面。正如Tom Cagley在我上一篇文章中的评论所指出的那样“在考虑跨团队和组织边界的流程改进时,也可以利用你的论点”。团队之间冲突的流程模型很容易使分布式解决方案复杂化。
另一篇关于“雕刻它 - 微服务,巨石和康威定律”的评论,这一次来自Robert Tanenbaum,讨论了重用,并质疑图书馆在某些情况下是否是更好的选择。 Robert还观察到“敏捷原则告诉我们实现满足需求的最小体系结构,只有在需求超出最小实现时才能使用更复杂的体系结构”。我认为微服务和SOA架构更像是一种分区机制而不是重用工具。因为重复使用会带来更多的成本和负担,而不是大多数人认为,我倾向于不那么热衷于这方面。但是,我绝对同意,分布式架构可能更适合于演进过程的后续步骤,而不是起点。来自Chris Richardson的“微服务:分解应用程序的可部署性和可伸缩性”的引用很好地说明了(重点是我的):
使用微服务架构的另一个挑战是决定在应用程序生命周期的哪个阶段应该使用这种架构。 在开发应用程序的第一个版本时,您通常不会遇到此体系结构解决的问题。 此外,使用精心设计的分布式架构将减缓开发速度。
Michael Brunton-Spall的“什么是微服务及其重要性”为这种架构风格所涉及的权衡性质提供了更多背景:
微服务交易复杂的单块,用于简单服务的复杂交互系统。
一个巨大的整体可能是如此复杂,以至于很难对某些行为进行推理,但在技术上可以推理它。相互交互的简单服务将表现出紧急行为,而这些行为是不可能完全推理的。
对于复杂系统而言,级联故障更是一个问题,一个简单系统中的故障会导致其他系统出现故障。幸运的是,有一些模式,例如背压,死人的开关等等,可以帮助你减轻这种情况,但你需要考虑这一点。
最后,即使问题发生变化,微服务也可以成为解决问题的解决方案。因此,一旦构建,如果您的需求发生变化以使您的有界上下文调整,正确的解决方案可能是抛出两个当前服务并创建三个来替换它们,但通常更容易简单地尝试修改其中一个或两个。这意味着微服务可以很容易地在较小的情况下进行更改,但需要更多的监督才能在大的情况下进行更改。
引号中“复杂(complicated)”和“复杂(complex)”之间的区别尤为重要。所提到的紧急行为意味着复杂系统的行为只能在回顾中完全解释。这意味着分布式应用程序不能被视为具有部件之间空间的整体件,但必须根据其性质进行设计。这是Jeppe Cramon的一个主要主题,他在TigerTeam网站上围绕微服务的持续工作非常值得一读。
Jeppe在我的帖子的LinkedIn讨论中发表了一对评论。在那次讨论中,Jeppe指出,专注于业务能力的小型服务比整体服务更可取,但这与将几个巨型网络与Web服务连接起来并不相同。然而,主要关注的是服务“拥有”的数据的性质。我在上一篇文章中非常简短地提到了这一点,并提到需要权威性的一些概念(中央治理)。 Jeppe表示赞同,并指出整体结构导致多主数据架构,其中多个系统在同一实体上包含冗余的,可能相互冲突的数据。
底线?在我看来,这种架构风格具有增强企业运营的巨大潜力,前提是它没有过度营销(“SOA治愈秃头,肠易激综合症,促进世界和平......免费!!!”)。服务并不是将遗留系统毫不费力地转变为二十二世纪技术的秘诀。有一些警告,权衡和成本。一种务实的方法,考虑到这些以及潜在的好处,应该比昨天的“如果建立它和他就会来”的哲学更有可能取得成功。
- 37 次浏览
【Rust】用Rust构建微服务

Rust是一门很棒的语言,目前是我2019年和2020年(到目前为止)学习最多的语言。Rust几乎可以与任何语言进行互操作。Rust对容器和K8s也很好。今天我要展示如何构建一个简单的微服务。我们将使用Actix、Tokio Postgress和其他库。我们将使用postgres作为事实的来源,并在docker中运行它(为了开发)。我们还将使用Barrel +一些我创建的自定义移植结构。代码将全部是异步和非阻塞IO。希望你玩得开心,我们开始吧。
架构
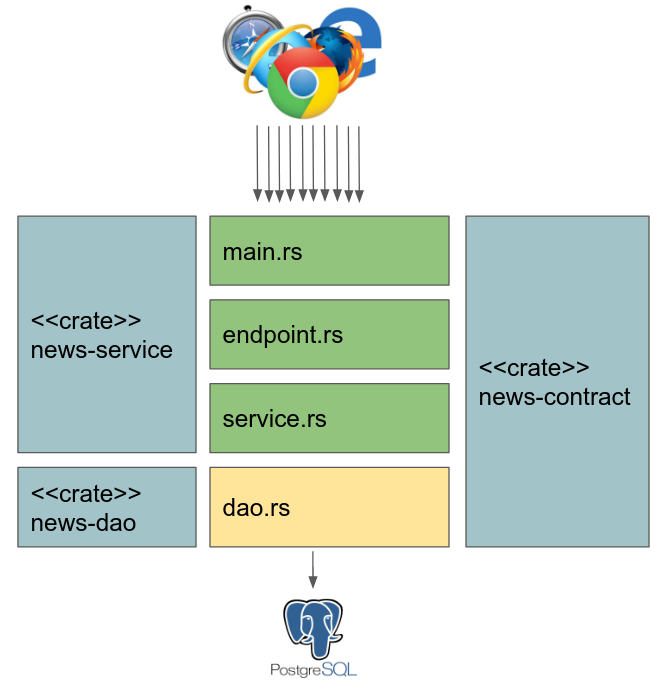
这里我们有一个多层架构,其中业务规则和rest定义在news-contract中定义。SOA契约在news-contract + news-service中定义,结构(news)在news-contract中定义。rest endpoint definitions+服务是在news-service上定义的。postgress持久性在news dao中定义。
代码结构
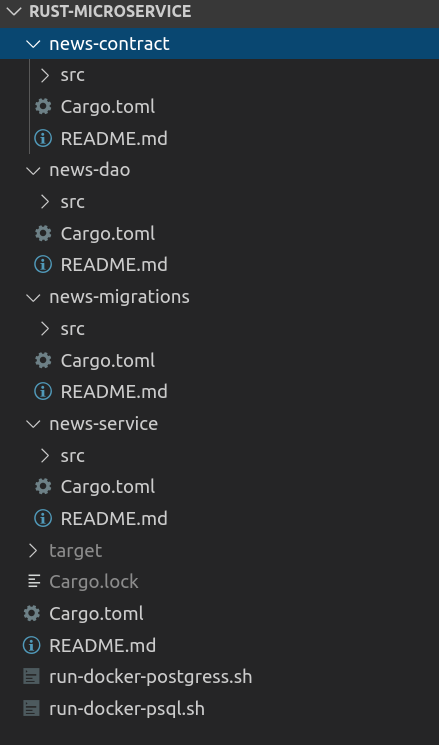
我们有5个项目,有一个全局工作区,这是一个项目,顶层的。我们有news-contract:这是SOA契约的一部分,我们在代码中使用了新闻结构。
news-dao:我们有使用tokio postgres的反应式持久性代码和新闻资源的所有CRUD操作。
News-migrations:为了测试,我们使用barrel+自定义逻辑来创建表和添加数据。
News-service:这里有端点、服务实现和配置了actixweb框架的主类。
每个项目都有自己的依赖项,由Cargo.toml文件。
我们还有两个脚本处理Docker容器。一个运行Postgres,另一个运行psql。
迁移
现在让我们看看如何进行迁移(创建表并将记录添加到Postgres SQL中)。
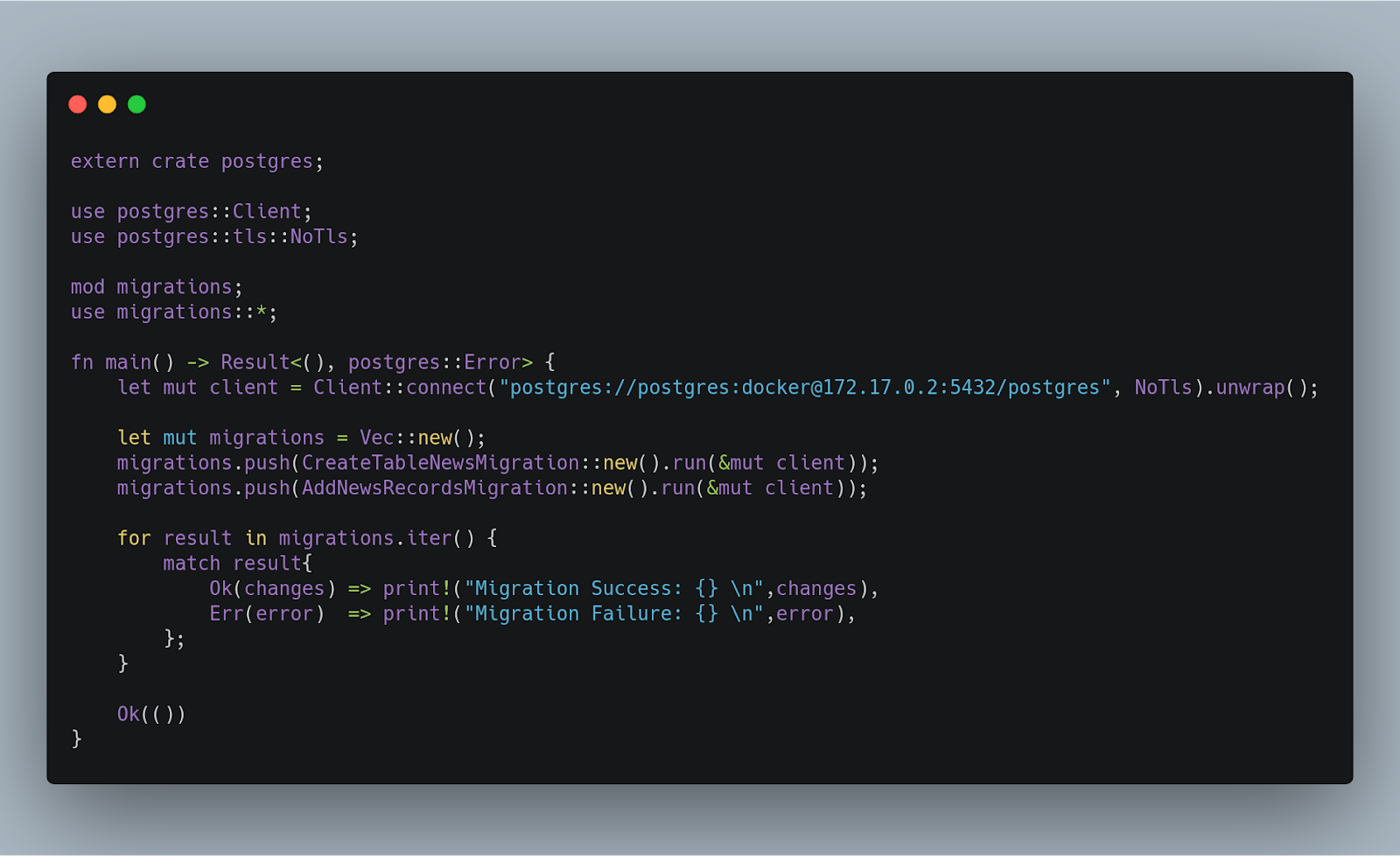
我们连接在docker上运行的Postgres数据库,创建一个包含所有迁移的向量,我们正在运行这个迁移。然后我们将进行一个for all迁移,逐个检查它们是否运行良好。
现在让我们看看下一个rust代码,什么是迁移。
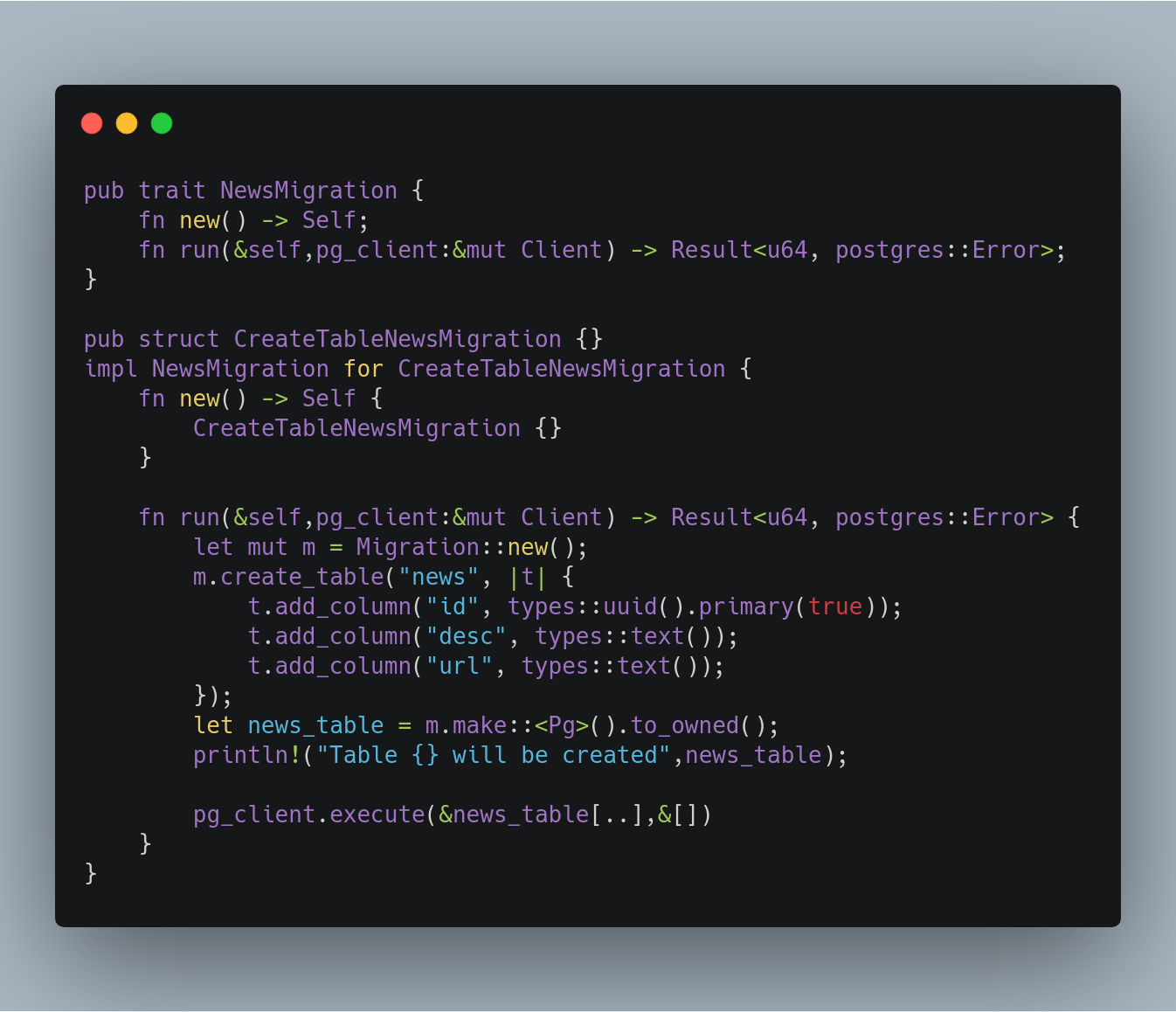
我创建了一个名为NewsMigration的结构,其中有一个新的(用于创建结构的函数)和运行迁移的方法(run)。如您所见,我创建了第二个名为CreateTableNewsMigration的结构,以及一个使用(impl)的trait实现,在我使用的barrel代码中创建了一个表结构,barrel将生成Postgres SQL INSERT语法。最后,我们在Postress中使用pg\u客户机运行生成的脚本。在这里您可能会看到有点奇怪的代码:&news_table[..],在这里我们传递String news_表的引用,并传递一个片段([..]),复制字符串并传递方法。
SOA契约
让我们来看看Soa合同的一部分,Struct新闻。
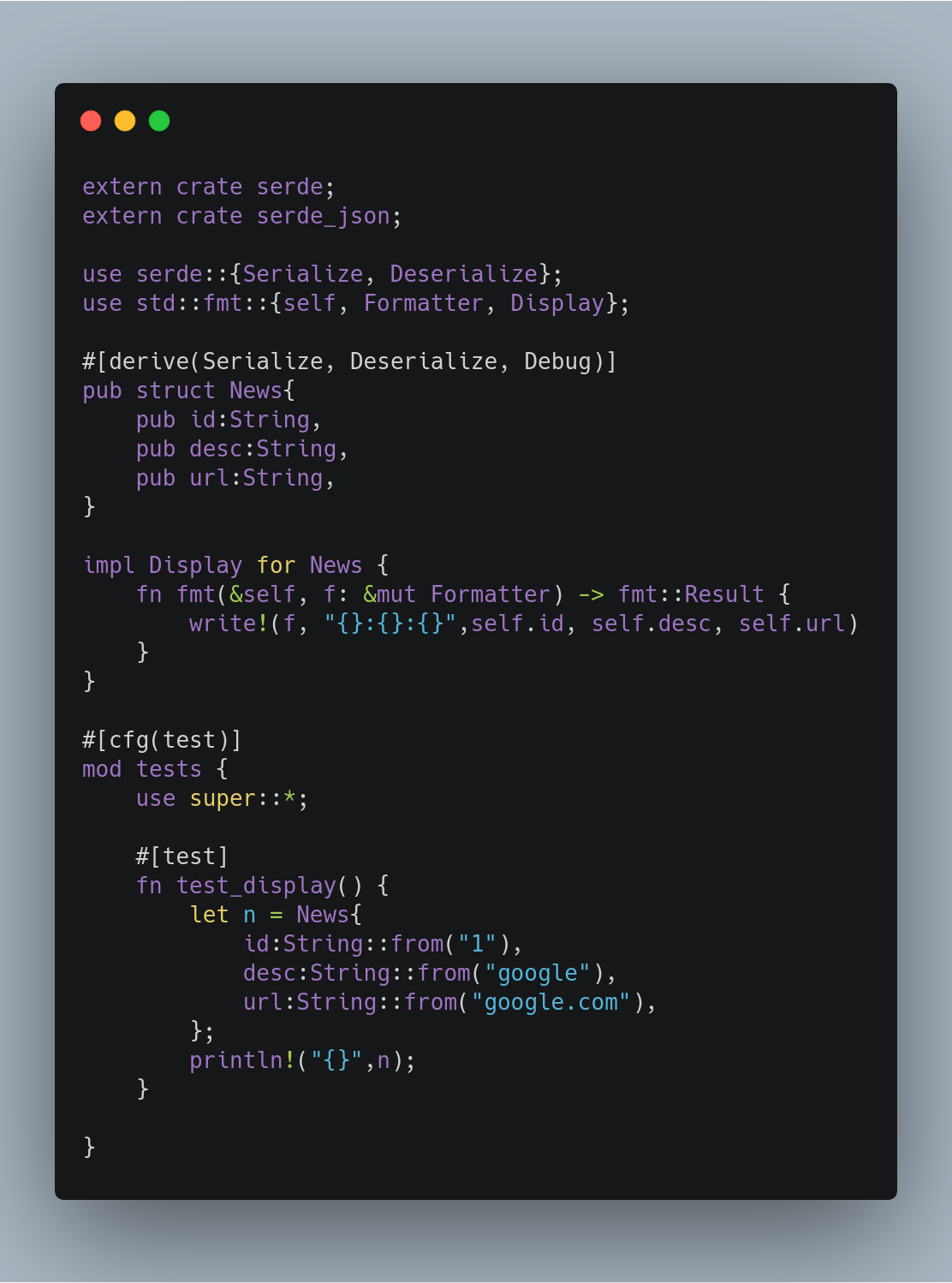
我们正在定义一个名为News的结构,我使用serde和serde_json来序列化和反序列化这个结构。我还实现了一个称为Display的特性,以便能够打印结构。最后,在文件的末尾有一个单元测试,我正在测试是否可以打印这个结构。
端点/服务
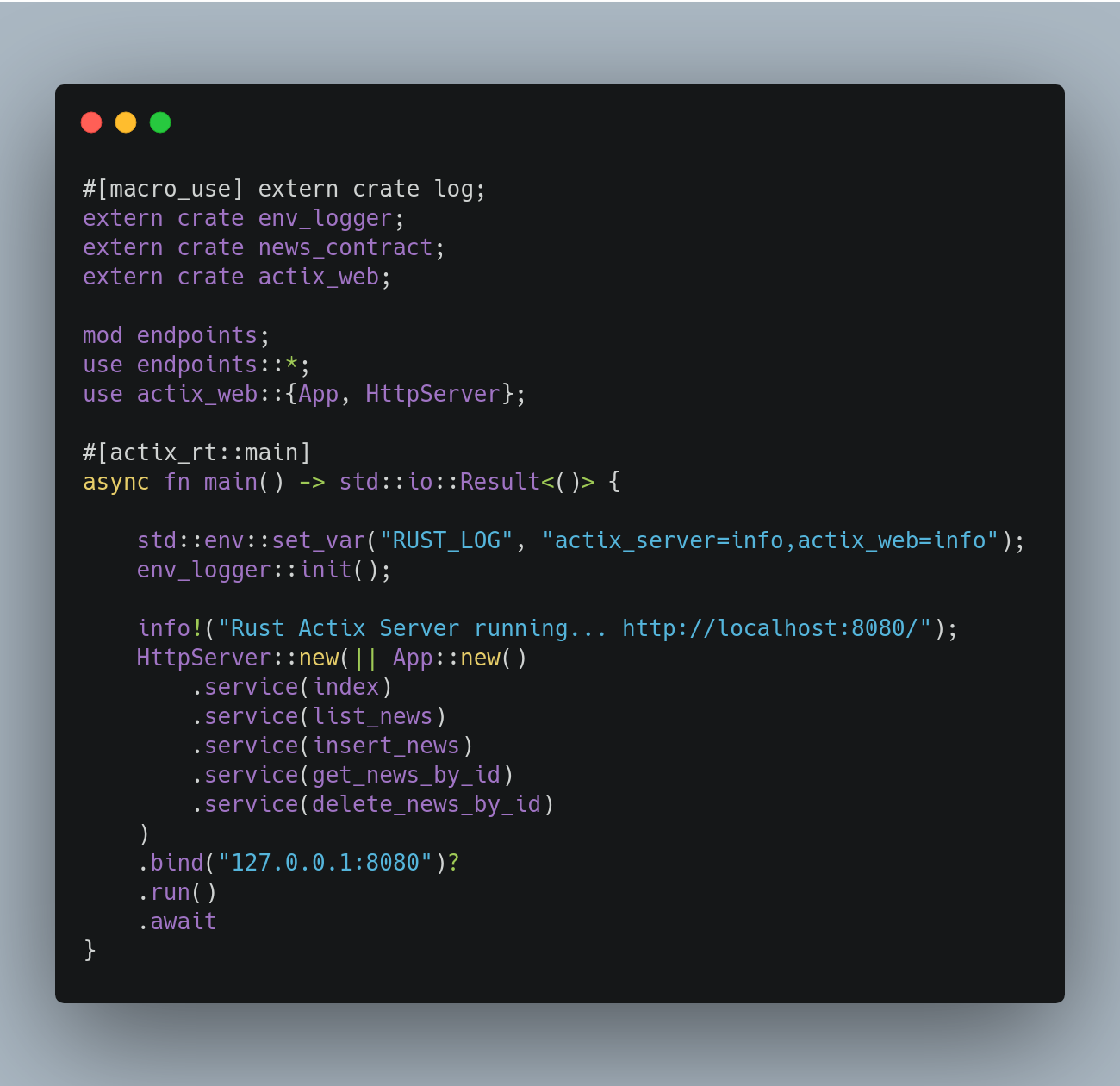
这里我定义了HttpServer actix,并定义了几个处理程序,比如:index、list、insert、get、delete等。所有信息都使用日志和env_logger创建来记录。
现在让我们看看端点.rs把剩下的定义归档。
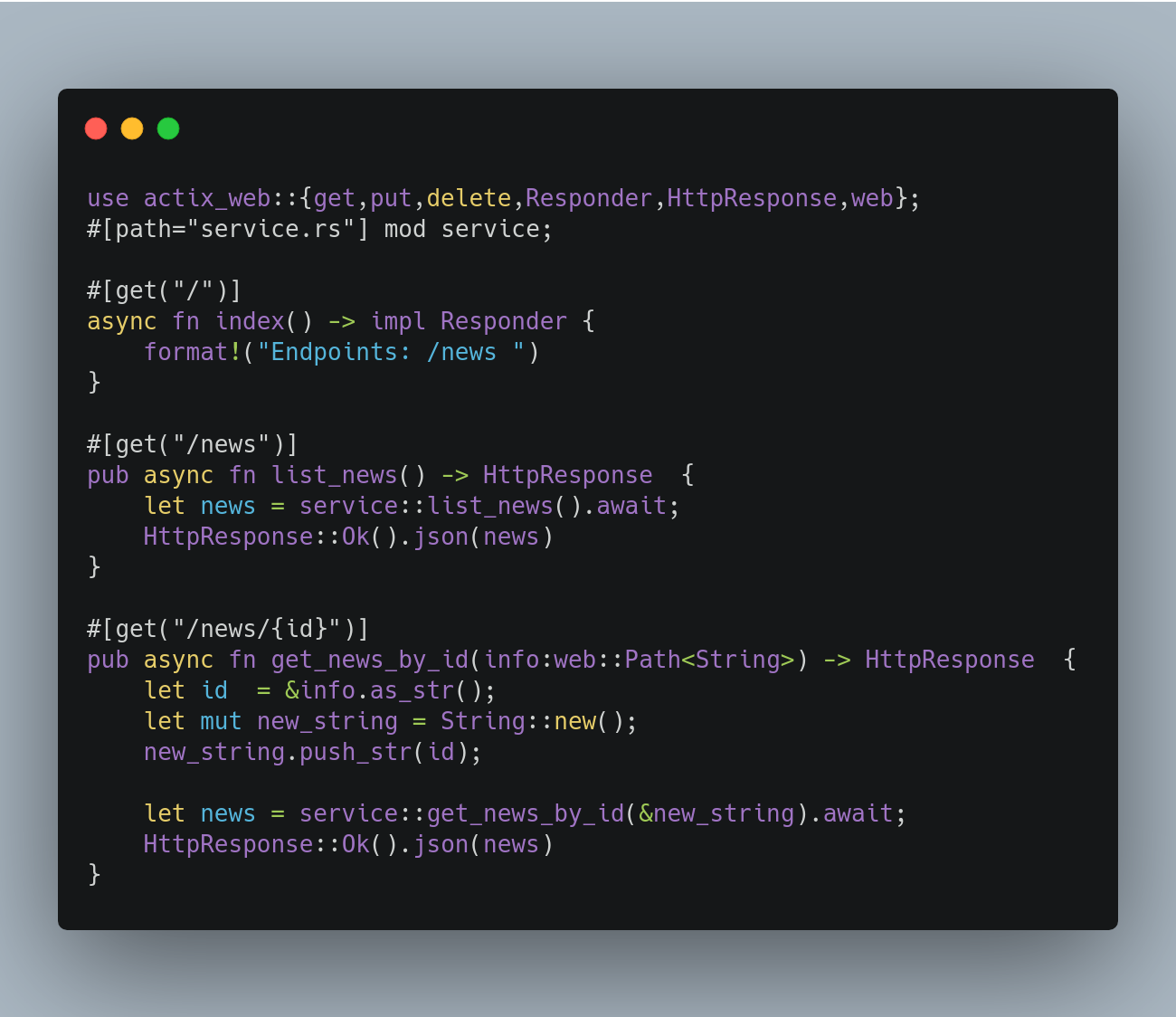
这里有一些宏使用REST操作,比如PUT、DELETE和GET。每个函数处理程序都是公共的,基本上,这里我调用服务并从服务中获取结果并序列化为json结果。
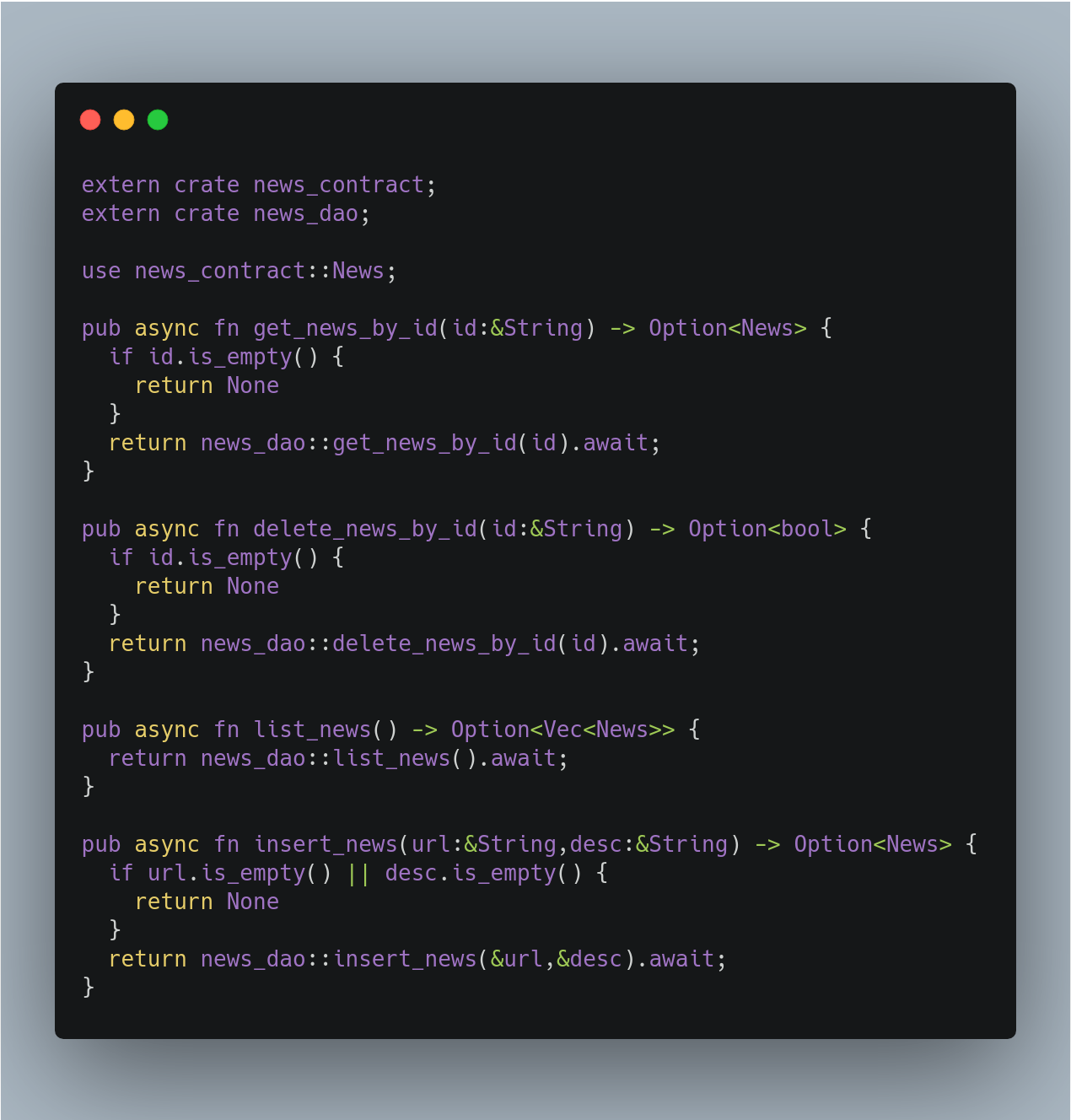
这是服务实现,我们这里没有任何REST或actix依赖关系。这里是实现验证、业务逻辑和委托给dao机箱的正确位置。CRUD上的所有函数都是异步的。
DAO
这是魔术发生的地方,我们有tokio-postgress编码。我们来看看。
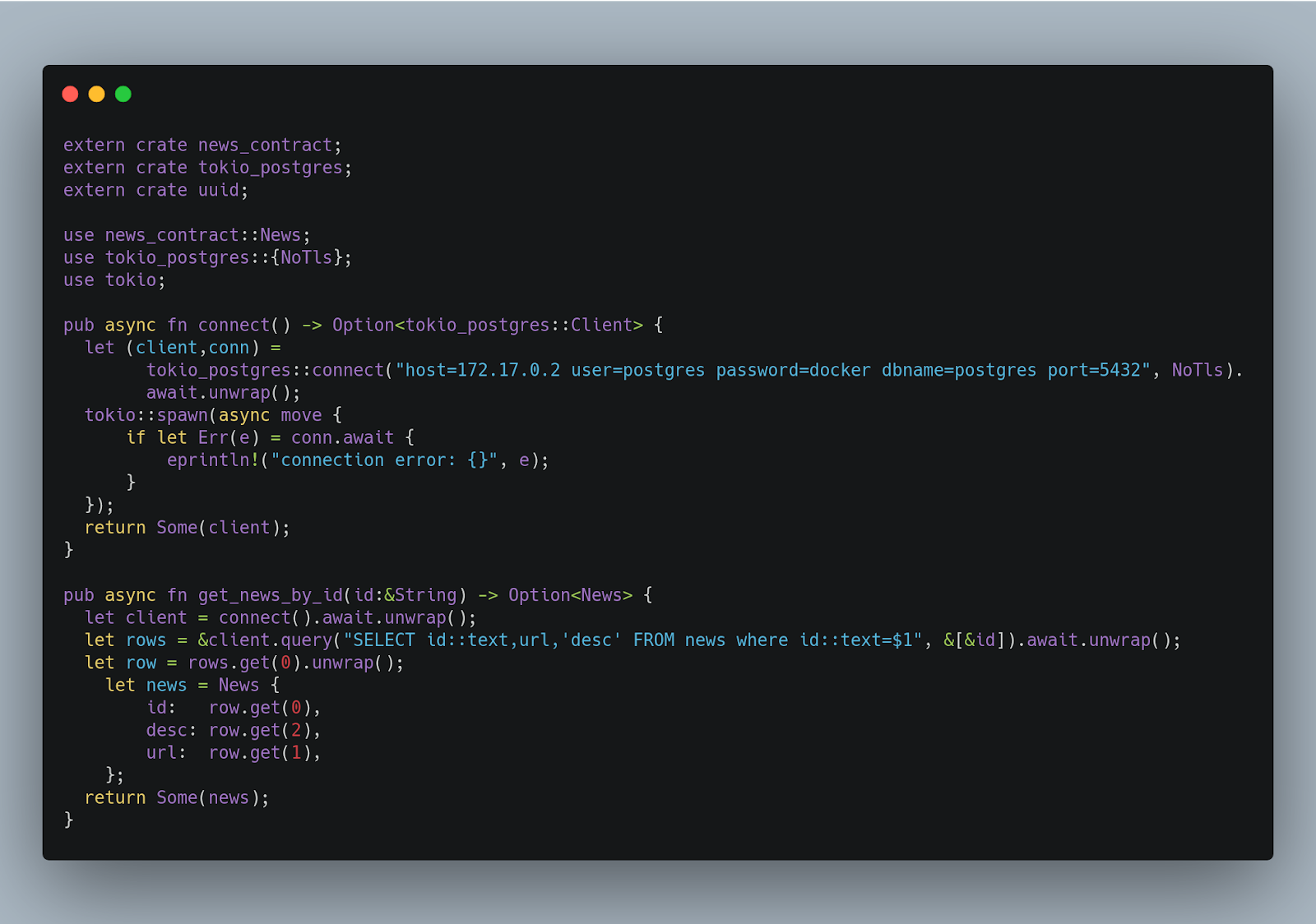
这是DAO实现。有一种方法可以在名为connect()的postgres数据库上进行连接,该方法以异步和非阻塞的方式进行。在这里,我演示了如何通过id进行查找。使用tokio postgress客户端,我执行一个查询,通过SELECT查询执行WHERE by id。在postgress id中,handle作为一个UUDI,所以我需要转换为string,这就是为什么您看到id::text=$1,在同一行中,我用&[&id]传递从参数获得的id。DAO有更多的函数,您可以在mine GitHub中查看完整的代码。
视频:代码演练+死亡演示
让我们看看我用代码演练和死亡演示制作的视频。
原文:https://medium.com/@ilegra/building-a-microservice-with-rust-ef9641cf2331
本文:http://jiagoushi.pro/node/1412
讨论:请加入知识星球【全栈和低代码开发】或者小号【it_training】或者QQ群【11107767】
- 520 次浏览
【微服务】专家组:在过去十年的微服务中,我们学到了什么?
瓦特(Watt):这是微服务专家组。Chris早些时候谈到了最小化微服务中的设计时耦合。他是microservices.io的创建者,《微服务模式》一书的作者。他也是Java冠军,在微服务领域非常有经验。我期待着与你们一起深入研究其中的一些领域。当然,我们有詹姆斯·刘易斯,他是最早创造和定义术语或架构风格的人之一,我们今天称之为微服务。James是ThoughtWorks的软件架构师和主管。ThoughtWorks技术咨询委员会成员,以及创建技术雷达的小组成员,致力于推动业界采用开源和其他工具和技术。还有凯蒂·加曼吉。凯蒂是CNCF的生态系统技术倡导者。她的重点是更广泛的生态系统和能够帮助微服务生存和繁荣的工具。她帮助发展和领导最终用户社区,同时缩小与其他一些生态系统领域和单位的差距。她过去的角色包括云平台工程师,她构建了很多平台,这些平台都被云本地技术所吸引,其中包括Kubernetes。
微服务还和十年前一样吗?
我想也许我们可以从一个问题开始,实际上,微服务作为一个定义。它真的还意味着我们今天认为它意味着什么吗?James,你不久前创造了这个术语,如果我们考虑敏捷,敏捷在今天的含义可能并不完全相同,因为它今天的含义是一样的。微服务还和十年前一样吗?
理查森(Richardson):那是什么,詹姆斯?
刘易斯(Lewis):我不知道。我应该指出,出于完全开放的考虑,不仅是我,还有弗雷德·乔治。Adrian Cockcroft同时谈到了细粒度SOA和微服务。我认为这只是一种趋同进化,不管它叫什么。时机已经成熟的想法。当时,这在很大程度上是对以技术为中心的大规模软件开发方法的反应。我们专注于技术层和所有的工具和技术,我认为我们真的希望将其从技术层带到更多的业务中,更多地关注业务,发挥更多的DDD,发挥更多的业务能力理念。本质上,我认为它有点像极限编程。有人引用Kent Beck的话说,“它只是一次做了所有的好事,结果变成了11个。”我认为这才是微服务架构真正的意义所在。它将当时存在的许多想法汇集在一起。如果你想想当时的游击队面向服务的架构。吉姆·韦伯是这个想法的始作俑者。显然,领域驱动的设计,着眼于RESTful集成,这是其中的一个重要部分,并通过超媒体实现解耦。
现在它的意思是一样的吗?不,当然不是。十年后。正如你所说,Nikki,语义扩散是一件事。词语改变了它们的意思。事实上,回想起来,我想马丁和我都会同意,我们把名字搞错了。这是零碎的。它卡住了。真的,这和尺寸无关。然后,当马丁给某物命名时,它往往保持命名状态。
理查森(Richardson):你应该使用面向服务的架构,它会消除一些反模式。
Lewis:当然,Dan North更喜欢可替换组件架构,这可能是对其真正意义的更恰当描述。这是关于可替换性而不是可维护性的设计。这是最原始的东西。
微服务中的常见反模式
瓦特:我们尝试微服务已经有相当一段时间了。我认为我们做的很多事情可能都是对的,但我想说的是,有很多是反模式。你的同事们对你一次又一次看到的最流行或最常见的反模式有什么看法,对人们如何实现和使用微服务有什么看法?
理查森:我想说一个明显的原因是人们相信这就像一个神奇的精灵尘埃。我们的工程组织交付软件的速度很慢,我们只做微服务,一切都会很好。然而,在现实中,如果您的软件交付速度慢是因为您的流程,因为缺乏自动化测试,并且您编写的代码无法维护,那么在混合中添加微服务很可能会使事情变得更糟。我觉得在采用微服务之前,或者在采用微服务的同时,您实际上必须清理您的行为并提高组织的成熟度。假设微服务实际上是解决方案的一部分,因为不知何故,你只是改进了所有其他东西。那就足够了。
伽曼吉:我可以附和。我认为这是我所看到的一种模式,当容器的采用得到更多的动力时。这不是关于容器,也不是关于技术,而是关于理解你的问题是什么,并真正触及问题的核心。大多数时候,这也伴随着文化的转变或发展。这不仅仅是关于采用微服务,而是关于你真正理解你试图解决的问题,并尝试应用一些最佳实践。谈到反模式,已经有很多使用微服务的用例,但是仍然有一些代码没有得到很好的维护。部署起来仍然很困难。自动化不是它的一部分。Chris也提到了很多功能。成功的衡量标准也不一定是真正明确定义的。其他一些组织通过他们拥有的微服务数量来衡量他们的成功,这实际上不是你应该追求的目标,不是吗?这不仅仅是关于技术,而是关于文化的转变,真正理解你试图解决的问题的根源。
理查森:我曾经和一个组织合作过。首席信息官读了我写的一本电子书,然后对微服务充满了热情,自上而下,8000人的组织,他刚刚宣布做微服务。这被转化为KPI,进而转化为奖金和其他东西,基本上就像许多微服务决定了你的奖金一样。
分布式事务
刘易斯:我们根本不是这个意思。这是我以前的客户,很有趣。这是关于分布式事务的。当您最终拥有大量服务,并且不得不协调事务并在这些微服务之间进行编排时,这可能是一场噩梦。Sam Newman和我在我们的培训课程中经常说,如果您认为您可能需要分布式事务,最好将这些事务放在一起,因为它们可能需要在同一个位置。我记得在一个组织中,他们有实体服务,然后是业务编排服务,该服务将协调这些事件和服务之间的事务。他们将其实现为ThreadLocal,因此每个调用都将存储在堆栈中的ThreadLocal中。如果他们需要解除分布式事务,他们会解除堆栈并对每个服务发出回滚。我们认为,这是一个很好的开始,因为这是一个很难解决的问题。那么,如果你需要两个呢?如果您需要其中两个,以防需要扩展,会发生什么?他们说,我们有一个计划。我们要把动ZooKeeper 带进来。现在他们遇到了所有的问题,因为现在他们也遇到了ZooKeeper 的问题。我们都知道这可能有点诡计,因为每次他们对其中一个微服务发出请求时,他们也必须与ZooKeeper 交谈。这很有趣。如果您正在构建微服务架构,我也觉得分布式事务是值得注意的。
理查森:我以前讲过,不管怎样,暗物质,暗能量,都是关于希望你分解的相互冲突的力量。那么,在服务和交易之间产生吸引力的力量就是抵制竞争的一个关键吸引力。
瓦特:我认为,在我们工作的一些客户中,我也看到了分布式的整体,在那里有很多服务,比如实体服务反模式,我认为当你从整体分解到微服务时,只是有一些非常传统的概念。然后,您必须将所有内容与事务以及跨越多个调用的所有这些内容放在一起。
Kubernetes如何影响和塑造微服务
就微服务而言,你现在无法摆脱的一件事是Kubernetes似乎与微服务齐头并进,有时甚至在这些句子中互换使用。在我们前进的过程中,库伯内特斯是如何影响和塑造微服务的?
Gamanji:Kubernetes的引入几乎就是容器的采用。对于Kubernetes,我们有一个容器编排器来帮助我们部署这些容器。这不仅仅是关于部署应用程序,而是关于Kubernetes带来的一些额外功能。例如,我们讨论的是可伸缩性。我们有一个水平吊舱自动缩放器,它可以自动识别何时需要缩放应用程序。它具有就绪性和活动性探测,这将确保应用程序重新启动,或者容器重新启动,以确保服务启动并运行。我们还有很多其他功能,如声明性配置,我们与物理基础架构层分离,因为我们需要考虑的是如何在Kubernetes世界中使用资源(如部署、副本集、服务等)定义应用程序。
然而,对于Kubernetes,它还是一种承载应用程序的机制。这并不一定意味着您可以在开发应用程序的阶段应用一些最佳实践。在很多情况下,整个单体都被部署到Kubernetes平台上。它要跑了。这将消耗大量资源。这将不是运行应用程序的最有效方式。它实际上也能让你做到这一点。有了Kubernetes,我认为它能让我们更快地,比如让我们把人们放在一个好的、积极的角度。它使应用程序能够更快地部署,但同时,它具有我刚才提到的一些功能:可达性、自动化、可伸缩性、就绪性探测、活动性探测等等。所有这一切实际上是真正的转变,从如何部署应用程序转变为只部署应用程序,将其容器化。实际上,只需使用Docker或BuildPack之类的工具对其进行打包,无论内部选择什么工具,这就足以让它真正准备好部署到集群中。
刘易斯:我刚才在看ThoughtWorks技术雷达和Kubernetes第一次出现在2015年的《评估》中,当时我认为谷歌只是开源的。微服务最早出现在这之前,Docker也出现在这之前。我认为我们所说的库伯内特斯所支持的模式,它们是更古老的模式。我不知道是否有人记得Dropwizard,它是一种有点时尚的格式。在Dropwizard之前,有一个Java库,来自同一个人Coda Hale,名为Metrics。这是一个典型的示例,放入一个简单的库,然后点击一个端点,每个应用程序都会有这个库。每个应用程序都有一个端点,它将为您提供服务正常运行时间、请求-响应延迟等等。现在,它已经从应用程序发展到基础架构。我认为这真的很吸引人,就像本质复杂性的演变一样,它仍然存在于业务代码中。然后是偶然复杂性,这是Martin Fowler的出发点,偶然复杂性正在迁移到您的网络、服务网格、侧车、容器运行时和编排工具中。我认为这是我们正在进行的一个有趣的轨迹。也许我们最终只需要一个业务分析师就可以将东西拖放到一起,然后部署到Kubernetes中。
Kubernetes是正确的抽象级别吗
瓦特:你认为Kubernetes是正确的抽象级别吗,或者你认为我们仍然需要在其上构建更多的生态系统,以使人们更容易构建微服务,因为有些东西的级别相当低?
理查森:我有几个不同的观点。我认为最重要的是,微服务架构的本质并不是真正的技术或基础设施相关。这一切都是关于正确识别服务边界、服务责任、它们的API和协作。这就是微服务架构的本质。就开发系统时必须做出的众多决策而言,这些是绝对关键的决策。我认为微服务采用的另一个反模式是,它正在反转它,然后思考,让我们找出我们的部署技术、工具和文字技术。这在很大程度上是一种反模式。这实际上都是关于服务定义的。
Kubernetes适合哪里?我将其视为许多可能的部署选项之一。一个明显的替代方案是无服务器,比如将东西打包成AWS Lambdas,然后在AWS或谷歌云功能上运行?如果这不适合,那么,可以考虑使用基于Docker的解决方案。ECS是一种更简单的选择,甚至是Kubernetes。那么Kubernetes实际上相当不错。到处都有。它从树莓皮到公共云,以及介于两者之间的一切。这很吸引人。我将其视为一种部署选项,而不是本质上与微服务定义相关的东西。
加曼吉:我可以在这里加一点,因为我认为,随着Kubernetes的流行,与此同时,我们有了另一种非常突出的文化模式。我在这里明确地定义了DevOps。同样,这不是一个部署过程。这是团队之间协作方法的文化转变。我认为这实际上非常重要,因为当我们讨论定义我们的服务可以做什么时,特别是在架构中,我们有无数的服务,并且有不同的团队控制它们。您如何确保您的API可用?您如何确保同步并了解如何使用API?如果您有一个功能需求,您如何联系该团队?我认为,DevOps文化更强调这一点,它引入了基础架构层,让平台团队与应用程序团队更紧密地协作,以确保服务或应用程序所需的所有需求也将由平台团队来满足。我认为这是关于定义应用程序的,但同时,下一个阶段是如何将其交付给消费者。有时需要更清楚地了解应用程序将部署在何处,以便充分利用现有的基础设施。这也伴随着团队之间的协作处理。
Lewis:这很有趣,不是吗,这个标准化的想法也很有趣,因为我们以前有一个叫做领域应用程序协议的东西,你可以考虑RESTful架构中的微格式。这是我真的看不到团队谈论这么多了。我想这又回到了你刚才说的,克里斯,重要的一点是这些东西是如何交流的?API是什么?我知道我可以通过什么协议和这边的另一个团队交谈?我使用的团队是服务边界的同义词。我认为这似乎正在消失。我不知道是否有其他人看到过。我们实际上要坐下来解决一个难题,即边界是什么?我们的服务之间的接口是什么?让我们商定一种相互交谈的通用方式?因为这本质上就是语义鸿沟。这就是语义问题,你不能通过技术来真正解决它,你只能通过人们相互交谈来解决它。
让人们与技术方面合作改变组织方面的挑战
瓦特:在之前的一些会谈中,围绕着如何解决其中一些挑战的实际工作所需的协作进行了大量讨论。康威定律也经常出现在围绕组织设计服务方面,反之亦然。我认为,我们经常会发现,使用微服务架构是为了帮助组织更快地发展,但这通常不会发生,因为组织实际上不会同时发生变化。我不知道你在这方面有什么经验。在让人们与技术方面合作改变组织方面,您在人力方面遇到了多少挑战?
理查森:人类,他们是麻烦。我使用成功三角的概念。这就像为了快速、频繁、可靠和可持续地交付软件,您需要三个方面的结合。从流程的角度来看,它是精益的,而且是DevOps。从组织的角度来看,这是一个松散耦合的产品团队网络。然后从架构的角度来看,它是一个松散耦合的模块化架构,有时是微服务,有时是一个整体。为了实现快速可靠的软件开发目标,您需要这三个方面。
刘易斯:这就像一句古老的格言,当持续交付是一种新事物,构建管道是一种新事物时,你会发现人们会花几个月的时间定义和构建完美的构建管道,让你的软件投入生产。我们可以按需将软件投入生产,速度非常快。太好了,什么软件?我们没有任何软件。这是一个经典[听不见00:22:47]。如果其他人看到了这一点,你肯定会想,你的构建管道有多好?因为如果你没有任何可用的软件来推动它,那就是解决真正的业务问题或产生真正的成果,那么你就不会交付任何东西。
Gamanji:从工程团队的角度来看,在内部做好战略提升工作是非常重要的。如果我们采用新的概念来部署应用程序或在内部创建应用程序,我认为创建员工可以遵守的内部标准非常重要。我认为这是非常重要的,清晰的沟通、透明和提高技能的机会。我认为人类的问题永远都会存在。但我们似乎有不同的方法来处理它。
刘易斯:组织会找到一切可能不改变的理由。Eli Goldratt几年前,我认为在《目标》(the Goal)的一篇[听不见的00:23:57]中,他谈到了范式转换,组织中的人们最难做的事情就是转换范式。有点像微服务风格的架构,采用云原生,这是一个巨大的转变。这是一个巨大的范式转变,因为它是关于人的。这是关于团队结构的。我想我们忘记了一些事情,比如,对于亚马逊,杰夫·贝佐斯(Jeff Bezos)没有说构建微服务。他说还有很多其他的东西,其他的约束,其他的强制功能,包括直接看到你的客户,建立产品团队,就像Chris说的,拥有小的授权团队,他们自己管理一切。都是这些东西。这就是一种范式转变。Eli Goldratt说,你需要三件事来改变一个范例。您需要做的第一件事是在现有的范例中尝试其他一切。你需要承受巨大的压力。你需要有人帮助你迈出第一步。当然,ThoughtWorks总是可以提供帮助的。
理查森:我也是。
瓦特:你也是,凯蒂?
伽曼吉:是的。我在这里。
如何影响管理层和领导层以适应变化
瓦特:我不知道你们中是否有人读过《团队拓扑》这本书,并且随着旅程的发展,不得不改变团队。有时您可能会有一个完整的产品团队启动,但您可能会有处于不同交互模式的平台团队。我认为这是一个可能在过程中丢失的东西,因为你发现公司倾向于建立,他们说,这是我们的结构,这是我们做事的方式。它不会随着组织和架构的实际变化而变化。对于如何真正影响管理层和领导层,使其能够认识到这一点并加以适应,您有什么建议或看到什么吗?
理查森:我认为最终,一家公司不盈利或盈利能力下降是大多数商人的最终动机。大多数组织往往不会有这样的直接危机,但如果他们有,那么这就是改变和变革的真正令人信服的原因之一。我曾经与一位客户合作过,他们是一家非常成功的公司,但他们有一块老化的单体,它是预先部署的。因为它太大太旧了,他们很难对它进行测试。它是有缺陷的,客户害怕升级,因为这意味着停机。这转化成了一个企业可以理解的问题,因为它涉及资金。然后,这实际上促使他们开始研究微服务架构,这样他们就可以切块,然后对它们进行彻底的测试。
Gamanji:我认为这是相同的问题空间,但它也可以应用于不同的领域。Chris一直在谈论采用或鼓励使用微服务。在采用Kubernetes作为平台时,我看到了一种非常类似的模式。同样,归结到相同的核心原则,每个企业都希望有一个与众不同的优势,这将使他们能够尽快向客户部署其功能。为此,有时候,当涉及到平台时,我们可以真正提供一个非常好的用例,这不仅可以降低维护基础架构的成本,而且可以使您的团队拥有更多的控制权,并且可能更容易地执行一些生命周期管理操作,例如升级和更新集群,确保有机会引入新技术,例如,服务网格。同样,拥有业务差异通常要归结于技术。在公司的不同阶段,可以采用微服务,也可以采用容器和Kubernetes,或者呼叫提供商等等。我认为这是一个正在经历的问题,即公司或组织如何盈利?
刘易斯:关于团队拓扑的话题,还有一本非常棒的书《动态重新团队》。海蒂写了这本精彩的书。这是关于实际改变团队结构的不同技术。不一定是团队拓扑,它是从平台团队到产品团队,再到它是什么。在人员轮换、保持人员新鲜、保持人员想法、保持人员参与方面。我所见过的公司中最好的例子就是制作数据库工具的Redgate,它做到了这一点,而且做得非常好。它们最初用于SQL Server,现在也可以使用其他数据库。他们做得非常成功。他们可以让员工在不同的产品之间来回走动。他们几乎有一个海报会议,每隔几个月,开发人员就会在合理的范围内选择要开发的产品。我认为这使Redgate能够做到这一点。我认为在许多组织中,尤其是大型组织中,你看不到的是,他们拥有真正的变革型领导。他们已经建立了一种学习文化,不仅仅是在他们的团队中围绕技术实践、模式和事物,而是围绕管理实践和变革型领导。我认为这是很多组织所缺少的一点,那就是我们不仅仅停留在自己的方式上。我们不会永远这样做。我们必须适应。我们必须学习。我们必须学习新技术、新风格、新的组织结构,并与管理者一样跟上该领域的最新发展,而不是坚持我们一直在做的事情。
瓦特:我认为,有时试图让这些倡议从基层开始,除非你得到管理层和领导层的认可,否则是行不通的,真的,因为你可以一直尝试,直到脸色发青,但如果高层不理解,这肯定是一个挑战。
微服务的下一次演变
关于微服务的未来,以及我们的发展方向,您是否了解CNCF或您的客户在微服务方面的最新趋势?下一个进化是什么,或者下一个我们应该关注的东西是什么?
Gamanji:我想在这里提到一些方法或工具,特别是在应用程序开发方面。当我们谈论Kubernetes和cloud native时,它围绕着集群,围绕着如何使用Kubernetes资源在配置中定义应用程序,等等。然而,现在有一个转变,重点完全放在应用程序开发人员身上。开放应用程序模型就是这样构建的,两年前在2019年被外包。这几乎允许将重点从基础架构层转移到应用程序层。最重要的是,您将能够在config中的代码中定义应用程序,并且能够跨云提供商部署它。这不仅仅是关于Kubernetes的,如果您想在数据中心或云提供商中部署它,您也可以使用这个特定的工具。
另一件我想从云原生空间提到的事情是Gitpod,它专注于应用程序开发阶段。Gitpod实际上是一个编纂本地开发环境的工具。这是一个巨大的使能器,特别是当有人在本地创建或开发应用程序时,如果遇到bug,他们将能够将其完全编码。它都基于Git存储库,您可以像一个文件一样挥舞,甚至可以像Git存储库一样挥舞,就像一切都在那里一样。其他人将能够完全重新创建它。这将是另一位工程师的镜像。这种可移植的开发环境,也一直是人们关注的焦点。
当然,就应用程序的实际部署而言,我们有不同的方法,同样可以使应用程序更快地推送到生产环境中。这就是GitOps非常突出的地方。这也是一种机制,您可以将应用程序的所需状态存储在Git存储库中。但是,它改变了开发人员将应用程序部署到集群的方式。对于所有这些工具和方法,我想说的是,Kubernetes将留下来。我们有许多调查证实了这一数据。我们有一个来自VMware的关于Kubernetes状态的最新调查,而且每年他们都看到生产中使用Kubernetes的数量在增加。现在不仅仅是基础设施,我们正在努力提高开发人员的体验。这就是我提到的所有这些工具和方法能够真正蓬勃发展的地方,它们最近实际上获得了很多动力。
瓦特:詹姆斯,你觉得怎么样?
刘易斯:对我来说,技术是一回事。这正在演变。发生了巨大的爆炸。我做了一次演讲,回顾了微服务最初出现的地方,以及它之前的内容和之后的内容。在监控、日志记录和容器编排方面,您会遇到这种巨大的爆炸。真是太棒了。我相信,这种情况会继续下去,因为这会让很多人赚很多钱。我认为我们还没有破解更多关于领域的东西,更多关于业务架构的东西。正如克里斯所说,边界是什么。在开始编写代码方面做得很出色,很多是模式,其他人也在做类似的工作。对我来说,这是一条至今仍未落地的信息。是关于生意的。这是关于团队结构的。它关注于如何解决业务问题。我认为可能仍然有太多的注意力集中在技术上。我认为我们仍然需要纠正这一点。没有多少人还在读埃里克·埃文斯的蓝皮书。虽然Data Mesh现在显然又重新流行起来,但它的受欢迎程度似乎在下降。我认为领域驱动的设计、业务能力等仍然是微服务领域的核心。
理查森:技术将继续发展。我觉得这不是微服务的核心。这是一个笑话,但也许XML将取代YAML卷土重来。我只是想说。
刘易斯:而不是在YAML或JSON中隧道XML。
Gamanji:我们将在这里用YAML替换所有东西。实际上有一个项目,它允许您使用Excel电子表格管理应用程序。如果需要,情况可能会变得更糟。
理查森:一切都是YAML。真有趣。实际上,我希望Lisp是一种配置语言,我觉得这是一种更好的方法。我觉得这个问题有两个层次。第一,我完全同意詹姆斯关于编纂设计最佳实践的观点。我认为领域驱动设计和Eric Evans的蓝皮书是关键,以及相关的东西。另一部分是关于整体与微服务的争论。首先,我们应该停止使用Twitter讨论架构。这是一个可怕的格式。所有这些辩论,如果你在推特上说,单体是好的。参与程度超出了预期。我希望我们都能就monolith架构适用于何处以及微服务架构适用于何处达成一致,因为很明显,它们都适用于何处,我们只需要确定何时适用。我希望这场辩论能得出一些结论。
刘易斯:对我来说,技术是一回事。这正在演变。发生了巨大的爆炸。我做了一次演讲,回顾了微服务最初出现的地方,以及它之前的内容和之后的内容。在监控、日志记录和容器编排方面,您会遇到这种巨大的爆炸。真是太棒了。我相信,这种情况会继续下去,因为这会让很多人赚很多钱。我认为我们还没有破解更多关于领域的东西,更多关于业务架构的东西。正如克里斯所说,边界是什么。在开始编写代码方面做得很出色,很多是模式,其他人也在做类似的工作。对我来说,这是一条至今仍未落地的信息。是关于生意的。这是关于团队结构的。它关注于如何解决业务问题。我认为可能仍然有太多的注意力集中在技术上。我认为我们仍然需要纠正这一点。没有多少人还在读埃里克·埃文斯的蓝皮书。虽然Data Mesh现在显然又重新流行起来,但它的受欢迎程度似乎在下降。我认为领域驱动的设计、业务能力等仍然是微服务领域的核心。
理查森:技术将继续发展。我觉得这不是微服务的核心。这是一个笑话,但也许XML将取代YAML卷土重来。我只是想说。
刘易斯:而不是在YAML或JSON中隧道XML。
Gamanji:我们将在这里用YAML替换所有东西。实际上有一个项目,它允许您使用Excel电子表格管理应用程序。如果需要,情况可能会变得更糟。
理查森:一切都是亚马尔。真有趣。实际上,我希望Lisp是一种配置语言,我觉得这是一种更好的方法。我觉得这个问题有两个层次。第一,我完全同意詹姆斯关于编纂设计最佳实践的观点。我认为领域驱动设计和Eric Evans的蓝皮书是关键,以及相关的东西。另一部分是关于整体与微服务的争论。首先,我们应该停止使用Twitter讨论架构。这是一个可怕的格式。所有这些辩论,如果你在推特上说,单体是好的。参与程度超出了预期。我希望我们都能就monolith架构适用于何处以及微服务架构适用于何处达成一致,因为很明显,它们都适用于何处,我们只需要确定何时适用。我希望这场辩论能得出一些结论。
刘易斯:作为对这一点的提醒,每个人。我的一个同事Neal Ford显然在建筑领域非常有名,他写了很多关于它的东西。我想他们有一本书,他和马克,这是另一本即将出版的书。我想这叫做“建筑:硬的部分”,克里斯,他们已经谈论了很多。他们有一个非常好的扰流板,因为这是他们的孩子。他们有一个非常好的模型,围绕如何考虑服务的粒度或应用程序的粒度。注意那件事。
Gamanji:这是关于确定要部署的产品的最佳架构。同时,我想提醒大家,这也是关于迭代的。目前对你有用的东西可能在几年内对你不起作用。尝试为将来的问题构建,这将帮助您拥有可维护的代码库。
原文:https://www.infoq.com/presentations/panel-microservices-architecture/
- 26 次浏览
【微服务】使用Spring Boot&Swagger的微服务 - 第1部分
微服务作为消除软件组件之间隐藏的依赖关系并允许细粒度部署而不拖拽不必要的上下文的方式已经变得流行。通过这种方式,微服务可以促进敏捷开发团队的自主性,并允许应用程序更自然地发展,并在某些情况下更快地开发。
我喜欢Java,所以我将向您展示一个为JVM开发微服务的过程和框架。这是一系列文章的第一部分,介绍了端到端的服务开发。在我们将来的文章中讨论更具体的细节之前,第一篇文章(第1部分)将介绍一些基本方面。第2部分将介绍Swagger规范中的代码生成,之后的文章将深入介绍实现良好服务的一些功能。
微服务特性
微服务的特征由James Lewis和Martin Fowler定义。我们可以总结一下技术特征:
- 单个运行时可执行文件 - 消除运行时库依赖性和对运行时容器打包的依赖性。
- 定义良好的API,支持单个有用的业务功能。
- 用于健康监控和记录的标准接口,便于管理大量独立服务
- 在Spring平台中,以下库支持这些特性:
- Spring Boot提供了单一的可执行特性,它为每个微服务提供了自己的HTTP堆栈(遗憾的是,这些内存占用了一些成本)并允许每个服务独立部署和管理。
- 使用Swagger的“合同优先”开发支持业务功能(有关此内容的更多信息,请参阅下一节)。
- Spring Actuator支持健康监测
- Sleuth支持标准化日志记录
合同优先发展
微服务应该提供单一有用的业务功能。这里有一些细微差别,可以归结为一个微服务,代表其API表示中的抽象业务级别。微服务应该从基础技术细节(例如数据模式或实现细节)中抽象出服务的使用者。抽象允许服务实现发展,同时对消费者的干扰最小。
API设计中常见的反模式是从实现开始,然后生成API规范 - “点击优先”方法。由此产生的接口往往过于技术化,“开发人员充满敌意”,并与实现细节紧密结合。
更好的模式是首先与消费者和其他利益相关者合作设计服务API。然后可以在负责服务实现,消费者实现,测试等的不同开发团队之间共享API规范。
对于此服务,我们将使用Swagger设计REST-ish API,但原理和技术与我们是否为REST-ish无关。例如,可以使用protocol buffers或其他接口规范工具轻松设计RPC样式服务。
我们发现在自己的git存储库中管理API规范是有益的,与服务实现分开。好处包括:
- 由于我们只有API规范,因此在审核后可轻松容纳更改。
- 服务实现者和消费者可以并行地开始他们的开发工作,从而增加团队自治并减少跨团队依赖性。
- 为服务使用者提供测试服务模拟的能力。
让我们将流程分为以下几个步骤:
- 设置服务接口项目。
- 在Swagger文件中定义服务规范并生成代码存根。
- 设置使用生成的代码存根的服务实现项目。
服务接口
我们将构建一个简单的Hello World服务,该服务使用GET方法公开/ greeting资源,该方法在调用时以包含“Hello World”消息字符串的JSON有效负载进行响应。
首先创建一个名为api-helloworld-v1-interface的Hello World Interface项目。项目结构符合标准的maven项目结构。
pom.xml文件包含以下库的依赖项:
- Swagger Codegen Maven插件,用于根据Swagger规范构建服务器存根
- 用于拉出实现JAX-RS规范的CXF模块的Apache CXF依赖项
- JSON编组和解组的Jackson JSON Provider依赖项使用了JAX-RS。提供程序通过JAX-RS自动注册
- Spring Boot依赖和
- PojoBuilder为JSON序列化构建支持POJO。
完整的pom.xml文件在这里可用,但主要的兴趣在于Swagger Codegen插件的配置。
的pom.xml
<plugins> <plugin> <groupId>io.swagger</groupId> <artifactId>swagger-codegen-maven-plugin</artifactId> <version>2.2.2</version> <executions> <execution> <id>generate-client-jar</id> <phase>generate-sources</phase> <goals> <goal>generate</goal> </goals> <configuration> <inputSpec>src/main/resources/swagger.yml</inputSpec> <templateDirectory>src/main/resources/swagger-codegen-templates/jaxrs-cxf</templateDirectory> <language>jaxrs-cxf</language> <configOptions> <sourceFolder>src/gen/java</sourceFolder> <apiPackage>${swagger-gen.api.package}</apiPackage> <modelPackage>${swagger-gen.model.package}</modelPackage> <serializableModel>true</serializableModel> <useJaxbAnnotations>false</useJaxbAnnotations> <dateLibrary>java8</dateLibrary> </configOptions> </configuration> </execution> <execution> <id>generate-html</id> <phase>generate-sources</phase> <goals> <goal>generate</goal> </goals> <configuration> <inputSpec>src/main/resources/swagger.yml</inputSpec> <language>html</language> </configuration> </execution> </executions> </plugin> </plugins>
我们的Swagger Codegen插件配置为两个执行任务:
- 生成代码存根,包括服务器端代码,客户端代码和模型POJO,
- 生成HTML文档。
对于代码生成,我们将输入规范提供为文件src / main / resources / swagger.yml。代码生成模板在文件夹src / main / resources / swagger-codegen-templates / jaxrs-cxf中提供。这些模板使用Mustache语法生成以下代码存根:
API:
代码gen插件使用此模板来定义Java接口。生成的Java接口在swagger规范中定义的每个operationId包含一个方法,该规范使用相应的HTTP方法,请求/响应媒体类型,查询参数,头参数,主体参数和表单参数进行注释。 swagger规范的tags:字段构成了以Api为后缀的Java接口名称的一部分
API实现:
如apiImpl.mustache文件中所指定,此模板生成API的存根实现。
模型POJO:
为Swagger规范中指定的每个对象生成POJO
正文参数:
将输入参数添加到生成的API方法中,这些API方法在API规范中定义为:body
我们使用代码生成语言作为jaxrs-cxf,因为CXF提供了一种使用HTTP绑定通过Annotations构建RESTFul服务的标准方法。
HTML生成非常简单,只需将输入规范指定为swagger.yml文件,将HTML指定为输出语言即可。
package-info.java
这为包级别文档和包级别注释提供了一个主页。
package com.example.api.hello.v1.model;
你好,client.yml
保存要与界面一起提供的可配置属性。
hello.endpoint:http:// localhost:8090 / api / v1 / hello
下一步
这篇文章讨论了我们可以用来开发Java和Spring中的微服务的工具的一些基本原理。我们已经审查了服务接口的项目设置和结构。在本系列的下一部分中,我们将讨论Swagger API定义并查看源代码生成过程。
- 30 次浏览
【微服务】复杂系统:微服务与人类
普罗布斯特:我叫凯瑟琳·普罗布斯特。我是谷歌的工程总监。我在这里向你们介绍复杂系统、微服务和人类。让我们从一个可能会有点意外的问题开始。北极熊与微服务有什么关系?乍一看,你可能会说他们之间可能没什么关系。让我们再深入一点。你可能知道,北极熊吃海豹。很容易理解北极熊的数量与海豹的数量有着密切的关系。如果你再往前走几步,事情就会变得复杂得多,速度也会快得多。让我们这样做吧。随着气候的变化,北极熊和海豹的栖息地也在发生变化。栖息地的变化对海豹以及北极熊种群的影响实际上要复杂得多。那么食物链上的其他动物呢,比如企鹅或磷虾。很快,你就会发现你的生态系统很难让我们真正了解。
微服务架构的行为方式
我认为,在某些方面,微服务体系结构的行为是相似的。我们很少有一个服务实际吃另一个服务,但我们确实有那些复杂的关系。让我们深入探讨一下。如果你已经开始了微服务的旅程,你可能已经从一个架构图开始,这个架构图看起来有点像我们左边的那个。您已经考虑了您的业务逻辑。你想要完成的事情。你的系统必须做什么。您已经绘制了一个架构图,它清楚地说明了所有内容的位置、行为方式以及您将要创建的服务之间的关系。
随着时间的推移,事情变得越来越复杂。也许你会组建新的团队。你有一个商业理由需要有新的功能,或者你意识到你的一项服务仍然包含了太多的行为,你想打破它。然后,当然,您要添加数据库,您要添加缓存,等等。很快,您就到了一个很难看到所有关系甚至写下架构中所有服务之间的所有关系的地步。事实上,这就是理论。实际上,当你与拥有非常复杂系统的公司交谈时,他们的系统看起来更像右边的一个,非常复杂的体系结构,其中许多公司拥有数百甚至数千个服务,并且它们都相互交互。也许并不是所有人都能直接互动,但他们之间有着很强的关系。当你看到如右图所示的东西时,实际上很难只写下体系结构和系统中发生的一切。
我想强调的是,从我的角度来看,这并不意味着巨石是正确的答案,微服务本身让生活变得艰难。这不是我的观点。我的观点是,如果你有和这里一样多的功能,需要数百或数千个服务,如果你把所有这些都放在一个整体中,你会有很多其他的问题。这不一定更容易推理。在我看来,有些情况下,巨石是正确的架构。在许多情况下,微服务也是正确的体系结构。微服务和复杂的微服务系统很难推理,这是我觉得我们应该接受的事实。事实上,该行业正在使用和构建许多工具来帮助我们理解这些系统。
当您构建微服务体系结构时,我们中的许多人都遵循某些最佳实践。例如,您在左侧看到的是一个关于此架构如何与团队协调的提示。有些团队可能拥有多个微服务。我们真正想要避免的反模式是,许多团队共同拥有一个服务。将这些职责清晰地分开确实有助于分解功能,使团队能够对其系统的各个部分进行单独的推理。然后,不仅是关于它的原因,而且也演变了他们在这个系统中的部分。
我们的人类系统就像我们的分布式系统一样
我认为有一个方面值得一提,那就是我们实际上已经有了一个由人组成的组织。我们在通常组织成团队的组织中工作。你可以在左边看到一个理论组织结构图。这看起来就像你在自己的公司里看到的一样。我们有这些组织结构图,还有这些团队组织。那么,组织结构图不一定能很好地映射到微服务架构上,也许它不应该。这些团队之间的相互关系实际上比你在组织结构图中看到的更微妙、更复杂。这是因为如果您有微服务,并且这些微服务之间存在依赖关系以及它们之间的交互,那么拥有它们的团队有时需要相互交互。微服务的构建方式使各个团队尽可能地独立和自主。我们还了解到,微服务仍然可以相互影响,因此,在这些团队之间建立这些强大的联系仍然是有益的。
复杂系统的两个层次
我想说的是,我们实际上有两个层次的复杂系统。我们有我们的微服务,然后我们有我们的人类组织,我们的人类系统覆盖,或者你可以称之为微服务系统的基础。没关系。关键是它们实际上是两个系统,它们都是复杂的。他们都以有趣的方式相互交流,我认为我们需要更深入地讨论和研究。
微服务系统
当我们谈论驯服这些系统的复杂性时,我的思维模式是这分为三个粗略的阶段。这不是唯一的分类方法。这有助于我在谈论如何更好地理解系统、如何创建一个系统、如何保持一个健康、良好运行的系统时,了解需要思考的问题。我的心智模型分为这三类。第一个bucket是配置和设置。这就是你想的,我的架构是什么样子的?我所做的基本设计选择是什么?例如,我是否创建服务网格,甚至是否创建微服务?我希望遵循的最佳实践是什么?
然后,创建系统。然后你就有了一个系统,这个系统需要不断地改变。我们已经讨论过添加新服务,但是在现有服务中也发生了许多变化。您需要改进业务逻辑,添加新功能,等等。在这个领域有很多工作正在进行,讨论如何快速、安全地将新代码交付到生产环境中,比如CI/CD、GitOps。我们的最佳实践是测试和缓慢推出更改。
第三个铲斗是第2天的操作。这意味着生产中正在运行的代码。您的客户正在与该代码交互。您希望确保生产中运行的任何东西都能保持运行,并为您的客户保持良好的运行。有一系列的工作正在进行,我会粗略地描述为掉进了那个桶里,比如负载测试。
了解系统可以承受的负载。监控非常基本的事情,比如日志监控、测试、混沌测试等等。同样,这是我的心理模型,边界有些模糊。显然,我们拥有的一些工具,比如Kubernetes,不仅可以帮助您进行配置和设置,还可以帮助您进行更改。负载测试不仅仅是测试已经在生产环境中运行的系统,它还帮助您进行安全的更改。粗略地说,我觉得它很有用,因为它帮助我理解,我需要注意哪些事情?在这些桶中,我使用了哪些工具来帮助我获得基本的理解?
事件/意外(incidents)
当我们谈论系统和保持系统健康时,我们经常谈论事件。这是一个重要的组成部分,但我想强调的是,拥有一个健康的系统不仅是为了防止事故,也是为了确保我们能够以合理的速度发展我们的系统,以便我们能够快速添加功能。比如说,他们不需要几年的时间来添加。我们的系统实际上是可观察的、经过良好测试的、可维护的。事故是健康系统的重要组成部分。因为我们希望我们的客户体验一个非常可靠的系统,他们可以以适合自己业务需求的方式进行交互。
让我们谈一谈事件。几乎从定义上讲,如果你做得对,事故或停机是令人惊讶的。为什么?因为我们中的许多人都会在事后进行尸检,或者在事情发生后进行反思,或者在事件发生后进行事件回顾。这些事件审查的全部目标是确保同一事件不再发生。如果您这样做是正确的,那么几乎按照定义,停机将让您感到惊讶。我想没关系。我认为接受这一点是可以的,并且说,是的,我们在不断改进。我们有时仍然会遇到麻烦,因为我们需要提供一个没有人可以解释的系统。我认为接受这一点是很好的一步。有助于使我们保持一种心态,不断改善系统的健康状况和对系统的理解。
例如,当事件发生时,它们可能发生在系统中彼此相距很远的部分,实际上很难看到这是如何发生的。你可以举一个例子,比如左边的服务,比如说,这是一个推荐系统。比如说,你推出了一种新的算法,可以帮助你更好地推荐,无论你想推荐什么。然后在右上角有一个系统,假设这是你的计费系统。显然,您的计费系统对您的业务非常重要,因为这是客户向您付款的方式。像左边的推荐系统这样的系统可能会对计费系统产生真正的负面影响。你可能会坐在那里想,为什么会这样?这不应该发生。这是正确的。它永远不应该这样。也许一个答案是你有一个隐藏的依赖。通常,在复杂的微服务系统中,您拥有这些依赖关系,您甚至可能没有意识到您拥有这些依赖关系,或者您没有意识到您拥有这些依赖关系的程度。再次回到我的三个bucket,也许服务网格可以真正帮助您了解这些依赖关系的位置以及它们的强度。
关于事件的另一个重要方面是,它们实际上可能在代码发布后的几天或几个月内发生。问题是,它可以在任何时间点命中。不管什么时候发生,感觉都很不方便。我们在右下角以Alice为例。也许她正在为其中一个系统待命,也许她正在为计费系统待命。一切都进行得很顺利,但是这个新的推荐算法在一段时间后对这个隐藏的依赖性产生了负面影响,现在影响到了她的系统。也许爱丽丝刚刚投入了一整天的工作,她真的很累,正要回家,然后警报响起。
人体系统
这真的让我们讨论了人类系统实际上如何影响我们的微服务系统的健康。当你们谈论人类系统时,我的心智模型实际上和我关于微服务系统的心智模型并没有什么不同。在这一点上,我仍然相信我们有这三个粗糙的桶,帮助我通过我需要思考和需要注意的事情进行推理。在第一个bucket中,我们有配置和设置。这是组织花费大量时间思考工作阶梯和组织文化的地方。如何激励人们。如何设定特定角色的期望。此外,这也是多样性、公平性和包容性发挥巨大作用的地方。真正创建一个高效运作的组织是本书的重点。
第二个因素是承认组织在不断变化。从积极的方面来说,我们有人得到提升,然后他们可能会有更多的发展空间。太好了。看到人们在事业上取得进步真是太好了。这是对我们所拥有的组织体系的改变。这可能意味着这个人现在承担了额外的责任,因此他们不再像以前那样关注系统的某个部分。也许这会留下一个缺口。同样,我们也有新人加入。显然,我们需要训练他们。我们有人离开球队,有时令人遗憾,有时却没有。无论哪种方式,这些都是系统的重大变化。然后,当然,当您移动整个组织时,组织会发生变化,并且需要真正确保新的组织运作良好,团队之间相互作用良好。这是本质上由组织本身推动的变化。
还有一类我称之为第二天操作的东西,只是为了与我们之前的操作相比较。这就是我所认为的外部力量和更广泛的文化变化。外部力量是我们所有组织都经历过的一件大事。一个非常明显的例子是新冠病毒,它不可能以一种全面的方式进行规划。作为一个组织,我们需要处理并充分利用它。我们需要做大量的工作来确保我们的组织仍然健康,尽管由于这些外部因素(如新冠病毒)给我们的组织和员工带来了各种压力。那么积极的文化变革就是我们所做的变革,再一次,也许是为了确保在那里工作的每一个人都感觉到自己的参与,并且能够表现出来,把他们最好的作品带到工作中去。
事件的真实性
如果你想一想这三个桶,你会花一点时间回想一下我们刚刚谈到的事件,爱丽丝在那里待命。她在呼叫计费系统,但它失败了。这三个桶与事件的结局有什么关系?我想说的是,事实上他们与此有很大关系。爱丽丝现在正经历着情绪的过山车。她可能很沮丧。她很害怕。她的晚餐计划被破坏了,她很沮丧。这里起作用的是整个文化,组织的基础文化。例如,她是否从同龄人那里得到了适当的培训?这很清楚。那么,还有,假设她发现她需要联系某人,她觉得这样做舒服吗?她是否拥有了解联系对象所需的正确工具?
通常,事故需要来自世界各地的专家。回到我们这里的事件示例。爱丽丝在这里的右边。她负责计费系统。左边是伊桑,他负责推荐系统。我敢肯定,由于推荐系统的改变,会有更多的人,比如对这种依赖性负责的人,出现问题。现在,让我们考虑一下相互关系。爱丽丝认识伊森吗?她和他接触感到舒服吗?他们一起工作吗?他们是否有共同努力解决这一问题的正确动机?或者,他们是否有动力将问题抛到一边,让其他人来处理,例如,因为他们担心这可能对他们的职业生涯意味着什么。所有这些文化因素在这一事件的发展过程中起着巨大的作用。我想强调的是,这不仅仅是事件。您可以对组织的健康状况提出同样的论点,影响您交付功能的速度、代码的可维护性等等。从我的角度来看,我们必须尽我们所能建立健康的组织,这不仅对组织中的人来说是健康的,这是非常关键的,而且他们实际上也会对底线产生影响。
这里的主要收获是,我相信两个复杂系统之间存在着复杂的相互作用。我们经常说,发生的任何事情都不是一个单一的根本原因,而是许多促成因素。同样,这可能是一个意外事件。它可能是一个延迟的功能启动或类似的事情。也许没有一个根本原因,但有几个因素,如一个人可能有冒名顶替综合征。也许有一个人不会承认他们不知道什么。也许我们没有适当的警报和指标。所有这些东西都相互作用,产生我们可能喜欢也可能不喜欢的结果。
一些现有技术
当我们谈论人类系统时,我会假设,事实上,有很多现有技术。从我的角度来看,我们需要将大量的现有技术带到我们的组织中,并利用它尽我们所能建立健康的组织。我在这里给你们举了一些例子,但这张幻灯片的真正目的是让你们思考哪些方面可以帮助我更好地了解公司?显然,在组织心理学方面有很多研究。还有其他一些领域也涉及到具体方面。例如,人为因素研究人为错误与环境之间的相互作用。你可能会想,我在做什么,让人们更容易慢慢地进行更改?我有什么系统?同样,这可能是我们前面提到的系统之一,比如Kubernetes或服务网格。有一些CI/CD工具在帮助自动化这些步骤方面非常有用,而不是强迫人们在许多步骤中手动操作,而他们可能不会这样做。
然后,这实际上与我在行为经济学中感兴趣的研究有关,比如说,与激励有关。我们是否在我们的环境和组织中建立了正确的激励机制?我们是否确保激励人们寻求帮助,激励他们与其他团队合作?或者,我们真的在为这样做制造障碍,或者不幸的是,将它们推开?这是我在这里举的另一个例子。让他们不要问别人。也许他们看到过这样的例子,他们的绩效评估受到了伤害,因为他们问了某人一个问题,而那个人反应不好。我们需要确保我们的组织是以一种能让我们在这里取得成功的方式建立起来的。
最后一点是关于动机。这真的是深思熟虑,人们真的能够带来他们最好的作品吗?他们是否有这样做的动机?他们学习新事物的动机是掌握吗?他们有权利自主吗?他们是否了解他们的工作如何与更广泛的情况相适应,以及为什么这很重要?同样重要的是要指出,不同的人受到不同事物的驱动,或者这些事物的不同组合。我认为,真正了解我们的组织,而不仅仅是推动一件事情,也是非常有帮助的。这些只是我认为我们可以学习的领域的例子。实际上,我认为这是一个重要的步骤,因为有这么多的工作和这么多的现有技术可以帮助我们真正理解如何使我们的人类系统更好,以及我们的微服务系统更好。
现在怎么办?微服务系统
我们怎么处理这些?我想我想让你们了解的一件主要事情是,从我的角度来看,微服务系统,是的,它们可以是超级复杂的。如果你有成百上千的微服务,它们可能很难解释。然而,正确的选择不是说“它们太复杂了,我不会走那条路。”从我的角度来看,在很多情况下,它们仍然是正确的选择。然后,正确的方法是接受,是的,它们很复杂。现在,我们该怎么办?这就是我要说的,这个行业实际上已经花费了大量的时间和精力来创建各种工具和方法来帮助我们理解和改进我们的系统。我在这里列出了一些。还有很多。我想说的一件事是,弄清楚你在用这些工具做什么实际上非常重要。我建议不要因为其他人都在采用这些工具而采用其中一种,你会说,“我会采用它,然后我会找出它是如何有用的,或者为什么我需要它。”相反,要非常清楚你在努力实现什么。也许我介绍的配置更改和第2天操作的心智模型有助于了解您需要了解的系统类型。为了使您的系统更加自动化、改进和稳定,您需要准备什么样的东西。我认为,明确目标是至关重要的。
现在怎么办?人类系统
当谈到人类系统时,我觉得我们经常谈论游戏日、教育论坛、设计审查和随叫随到的培训。我认为这些都是非常棒和非常重要的。我认为他们做得还不够。我认为我们需要更深入一层。这就是我在谈论文化和包容以及我们建立的合作激励机制时所要表达的意思,等等。因为我认为,如果你的组织运作不好,激励机制也不好,那么世界上所有的比赛日都不会让你处于一个好的位置。世界上所有的随叫随到培训都不会让你处于这样一种境地,即随叫随到的人都会感到舒适,如果这正是你的组织所鼓励的。我的观点是,我们真的需要更深入地思考我们建立的各种工作阶梯,我们建立的组织。我们的人民如何在其中发挥作用。我们如何持续改善组织健康。就我所处的位置而言,组织健康本身就非常关键。让人们觉得他们可以参加工作真的很重要。他们有一条职业道路。他们对此感到高兴。即使你不是出于这种动机,我认为有一个非常清楚的理由可以证明,组织健康对企业健康有着真正的影响。
问答
布莱恩特:在一个团队关系由门票和官僚制度驱动的组织中,你能建议一些快速的胜利来让这些关系更顺利地运行吗?
问题:显然,我认为这取决于组织。我曾见过一些组织,并与那些在组织中工作的人交谈过,在这些组织中,一切都是通过票证来完成的,一切都是通过票证解决的速度来衡量的。这就是激励人们的方式。从某种意义上说,我不知道有什么捷径可以解决整个问题。当我看到一些组织,他们希望做出重大转变,那么可能需要一段时间。将组织推进到一个不同的方向需要很多推动。话虽如此,我认为根据我的经验,当情况恶化到人们只是就门票和事件进行交流,然后把他们放在一个房间里或虚拟房间里,只是相互了解,这对我来说真的很有帮助。也有人发帖说,微笑可能会有所帮助。这也是一个很好的观点。
布莱恩特:接下来,你谈到让团队的开发者拥有微服务?这不会产生额外的筒仓吗?如果是这样,您如何管理或避免这种情况?
问题:我不确定它将如何创建额外的筒仓。根据我的经验,有一件事是有点反模式的,那就是如果你有一组人编写代码,另一组人可能对代码一无所知,但在凌晨3点出错时必须接听电话。这本身在理论上可能不是一个筒仓,但在实践中,这在这两支球队之间造成了差距。基本上,在一个团队中,团队不仅编写代码并推出更改,可能与另一个团队一起,而且在系统出现问题时,至少部分地处于钩子上,我认为这创造了一种感觉,我驱动它。我拥有它。我已经准备好了,这是我的。我认为这确实很有帮助。
布莱恩特:我见过Netflix的人谈论事物的全生命周期所有权,这非常有趣。
问题:当然也可以为单独的团队留出空间,比如SRE团队或类似的团队,这也是整个流程的一部分。我认为,尽可能让这些团队共同拥有它是非常有帮助的。
布莱恩特:我正在设计微服务,但我有大约10个服务,并且已经看到了很多集成问题?您如何管理这些服务中的混乱?
问题:系好安全带。我认为这是完全正确的。事情很快变得复杂起来。我认为这就是为什么在可观察性上有如此多的投资,在这个工具上,所以我们可以让我们的头脑绕过它。我认为,显然,我们需要大量的工具和仪器来尽可能多地了解系统。这也涉及到分布式跟踪和理解系统如何相互影响,等等。我想我的建议是,不要回避,但要投资。投资于尽可能地了解系统的行为。
布莱恩特:现在回到更多的人这边。你能举例说明你过去参与过的组织中的激励措施吗?
问题:我认为当你谈论激励时,人们通常首先开始谈论钱。当然,这是一个激励因素。老实说吧。我觉得有点深。我认为,从我的角度来看,当激励措施以一种创造正确行为的方式建立起来,并且实际上让人们快乐并发展他们的事业时,激励措施最有效。让我们回到这个例子,如果出现问题,开发人员可能还需要在凌晨3点拿起电话。也许在某些组织中,他们不会因此得到任何奖励。这意味着你没有以奖励他人的方式建立激励机制。即使是在绩效考核中,或是在同侪的强化下,或是在领导层的强制执行下,你实际上是在奖励,那么奖励就不同了。它是以不同的方式设置的。这就是我说的动机。例如,如果您需要一个团队协作良好的组织,您如何激励它?你可能不仅通过创建会议,而且还通过奖励那些真正推动合作的人来激励这种合作。
布莱恩特:你能推荐一些关于面对人类挑战的书吗?我知道你放了一些像丹·平克的经典书,就在那里。还有别的书吗?
问题:我有很多我喜欢的。我现在正在重读《轻推》。
布莱恩特:马尔科姆·格拉德威尔?
问题:不,是这个。这并不完全是关于商业的,但它确实讨论了如何创造小的激励和小的推动来慢慢改变行为。我真的很喜欢这样,因为我认为当你有一个大的组织,或者你正试图完成的一个大的改变,通常最好的行动方式就是慢慢地朝一个方向前进。这与商业无关,但一个具体的例子是,如果你尽量不吃太多糖果,而把糖果留在厨房而不是桌子上,你就会少吃糖果。这是关于轻推的建议。您可以将其应用于许多不同的情况。
布莱恩特:我读过这本书。这是一本很棒的书。
再次进入技术领域。如何最好地评估微服务系统。假设你是一名技术领导者。你已经进入了一个组织。您已经对愿景有所了解,并且希望了解技术方面和人员方面的情况。有什么建议吗?
问题:我想如果你对这个系统完全陌生,我首先要考虑的是,你的团队是否了解他们所有的上游和下游依赖关系?这并不总是被理解的。您的团队是否了解其系统的限制?这也不总是很好理解。如果您不能与所有这些下游服务通信,您的系统会发生什么情况?您是否设置了指标、仪表盘和其他设置?那是另一个。然后,我要看的另一件事是速度。您能够以多快的速度进行更改,并在生产中安全地实现这些更改?有时候,你的系统中生长的藤壶越多,事情就越慢。我认为这是另一个非常重要的方面。
布莱恩特:你如何衡量组织的健康状况?
问题:我们谈论微服务系统是复杂的。我认为人类是无限迷人的,人类的组织也许更是如此。当涉及到度量或评估组织的健康状况时,有很多事情。一些更明显的事情是,你的记忆力是什么?人们总是在沮丧中离开吗?这是出问题的明显迹象。我认为,当你也在观察你的组织的生产力时,有很多代理指标,人们会发现它们有很多缺点。我明白为什么。比如代理指标,比如提交了多少代码,或者我们能以多快的速度完成代码审查之类的事情?这些都是代理指标,但它们可以告诉你一些事情,也可以告诉你趋势。这是一件事。另外一件事,老实说,我发现你只需要和人们谈谈,因为每个人都有不同的观点。世界上所有的代理指标都无法让你更深入地了解人们在为什么而挣扎,人们在为什么而高兴。
原文:https://www.infoq.com/presentations/microservices-best-practices/
- 43 次浏览
【微服务】微服务安全 - 如何保护您的微服务基础架构?

在当今行业使用各种软件架构和应用程序的市场中,几乎不可能感觉到您的数据是完全安全的。 因此,在使用微服务架构构建应用程序时,安全问题变得更加重要,因为各个服务相互之间以及客户端之间进行通信。 因此,在这篇关于微服务安全的文章中,我将按以下顺序讨论您可以实施的各种方法来保护您的微服务。
- 什么是微服务?
- 微服务面临的问题
- 保护微服务的最佳实践
什么是微服务?
微服务,又名微服务架构,是一种架构风格,将应用程序构建为围绕业务领域建模的小型自治服务的集合。 因此,您可以将微服务理解为围绕单个业务逻辑相互通信的小型单个服务。

现在,通常当公司从单体架构转向微服务时,他们会看到许多好处,例如可扩展性、灵活性和较短的开发周期。但是,与此同时,这种架构也引入了一些复杂的问题。
那么,接下来在这篇关于微服务安全的文章中,让我们了解一下微服务架构面临的问题。
微服务面临的问题
微服务面临的问题如下:
问题1:
考虑一个场景,用户需要登录才能访问资源。现在,在微服务架构中,用户登录详细信息必须以这样一种方式保存,即用户每次尝试访问资源时都不会被要求进行验证。现在,这产生了一个问题,因为用户详细信息可能不安全,也可能被第 3 方访问。
问题2:
当客户端发送请求时,需要验证客户端详细信息,并且需要检查授予客户端的权限。因此,当您使用微服务时,可能会发生对于每项服务,您都必须对客户端进行身份验证和授权。现在,要做到这一点,开发人员可能会为每项服务使用相同的代码。但是,您不认为依赖特定代码会降低微服务的灵活性吗?好吧,它确实如此。因此,这是该架构中经常面临的主要问题之一。
问题3:
下一个非常突出的问题是每个单独的微服务的安全性。在这种架构中,除了第三方应用程序之外,所有微服务同时相互通信。因此,当客户端从 3 rd 方应用程序登录时,您必须确保客户端无法访问微服务的数据,这样他/她可能会利用它们。
好吧,上述问题并不是微服务架构中发现的唯一问题。我想说的是,根据您拥有的应用程序和架构,您可能会面临许多其他与安全相关的问题。关于这一点,让我们继续阅读这篇关于微服务安全的文章,并了解减少挑战的最佳方法。
微服务安全最佳实践
提高微服务安全性的最佳实践如下:
纵深防御机制
众所周知,微服务会采用任何细粒度的机制,因此您可以应用深度防御机制来使服务更加安全。通俗地说,深度防御机制基本上是一种技术,您可以通过它应用多层安全对策来保护敏感服务。因此,作为开发人员,您只需识别具有最敏感信息的服务,然后应用多个安全层来保护它们。这样,就可以确保任何潜在的攻击者都无法一次性破解安全,而必须向前尝试破解所有层级的防御机制。
此外,由于在微服务架构中,您可以在不同的服务上实施不同的安全层,因此成功利用特定服务的攻击者可能无法破解其他服务的防御机制。
令牌和 API 网关
通常,当您打开应用程序时,您会看到一个对话框,上面写着“接受许可协议和 cookie 许可”。这条消息意味着什么?好吧,一旦您接受它,您的用户凭据将被存储并创建一个会话。现在,下次您进入同一页面时,该页面将从缓存内存而不是服务器本身加载。在这个概念出现之前,会话集中存储在服务器端。但是,这是应用程序水平扩展的最大障碍之一。
令牌
所以,这个问题的解决方案是使用令牌,来记录用户凭据。这些令牌用于轻松识别用户并以 cookie 的形式存储。现在,每次客户端请求网页时,请求都会被转发到服务器,然后服务器会判断用户是否可以访问所请求的资源。
现在,主要问题是存储用户信息的令牌。因此,需要对令牌的数据进行加密,以避免对第三方资源的任何利用。 Jason Web 格式或最常见的 JWT 是一种定义令牌格式的开放标准,提供各种语言的库,并加密这些令牌。
API 网关
API 网关作为一个额外的元素通过令牌身份验证来保护服务。 API 网关充当所有客户端请求的入口点,并有效地向客户端隐藏微服务。因此,客户端无法直接访问微服务,因此,任何客户端都无法利用任何服务。
分布式跟踪和会话管理
分布式跟踪
在使用微服务时,您必须持续监控所有这些服务。但是,当您必须同时监控大量服务时,就会出现问题。为避免此类挑战,您可以使用一种称为分布式跟踪的方法。分布式跟踪是一种查明故障并确定故障原因的方法。不仅如此,您还可以确定发生故障的位置。因此,很容易追踪到哪个微服务面临安全问题。
会话管理
会话管理是保护微服务时必须考虑的重要参数。现在,只要用户进入应用程序,就会创建一个会话。因此,您可以通过以下方式处理会话数据:
- 您可以将单个用户的会话数据存储在特定服务器中。但是,这种系统完全依赖于服务之间的负载均衡,只满足水平扩展。
- 完整的会话数据可以存储在单个实例中。然后可以通过网络同步数据。唯一的问题是,在这种方法中,网络资源会耗尽。
- 您可以确保可以从共享会话存储中获取用户数据,从而确保所有服务都可以读取相同的会话数据。但是,由于数据是从共享存储中检索的,因此您需要确保您有一些安全机制,以便以安全的方式访问数据。
第一次会话和相互 SSL
第一次会议的想法很简单。用户只需登录应用程序一次,即可访问应用程序中的所有服务。但是,每个用户最初都必须与身份验证服务进行通信。好吧,这肯定会导致所有服务之间的大量流量,并且对于开发人员来说,在这种情况下找出故障可能很麻烦。
使用 Mutual SSL 后,应用程序通常会面临来自用户、第 3 方以及相互通信的微服务的流量。但是,由于这些服务是由第 3 方访问的,因此总是存在受到攻击的风险。现在,此类场景的解决方案是微服务之间的相互 SSL 或相互身份验证。这样,服务之间传输的数据将被加密。这种方法唯一的问题是,当微服务数量增加时,由于每个服务都会有自己的 TLS 证书,开发人员更新证书将非常困难。
3rdparty 应用程序访问
我们所有人都访问属于 3 rd 方应用程序的应用程序。 3 rd 方应用程序使用用户在应用程序中生成的 API 令牌来访问所需的资源。因此,第 3 方应用程序可以访问该特定用户的数据,而不是其他用户的凭据。好吧,这是针对单个用户的。但是,如果应用程序需要访问来自多个用户的数据怎么办?您认为如何满足这样的要求?
OAuth 的使用
解决方案是使用 OAuth。当您使用 OAuth 时,应用程序会提示用户授权 3 rd 方应用程序,使用所需的信息,并为其生成令牌。一般使用授权码来请求令牌,以确保用户的回调 URL 不被盗用。
因此,在提及访问令牌时,客户端与授权服务器进行通信,该服务器授权客户端以防止其他人伪造客户端的身份。因此,当您将微服务与 OAuth 结合使用时,服务充当 OAuth 架构中的客户端,以简化安全问题。
好吧,伙计们,我不会说这些是确保服务安全的唯一方法。您可以根据应用程序的架构以多种方式保护微服务。因此,如果您是一个渴望构建基于微服务的应用程序的人,那么请记住,服务的安全性是您需要谨慎的一个重要因素。关于这一点,我们结束了这篇关于微服务安全的文章。我希望你发现这篇文章内容丰富。
如果您想查看更多有关人工智能、DevOps、Ethical Hacking 等市场最流行技术的文章,您可以参考 Edureka 的官方网站。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. What is Microservices?
- 2. Microservices Architecture
- 3. Microservices vs SOA
- 4. Microservices Tutorial
- 5. Building Microservices Application Using Spring Boot
- 6. Microservices Security
原文:https://medium.com/edureka/microservices-security-b01b8f2a9215
- 43 次浏览
【微服务】微服务间通信的最佳实践
一个好的 API 架构对于有效处理微服务之间的通信很重要。不要害怕创建新的微服务,并尽可能地尝试解耦功能。例如,与其创建一个通知服务,不如尝试为电子邮件通知、SMS 通知和移动推送通知创建单独的微服务。
在这里,我假设您有一个 API 网关来管理请求、处理到负载平衡服务器的路由并限制未经授权的访问。
通讯类型
- 同步协议:HTTP 是一种同步协议。客户端发送请求并等待服务的响应。这与客户端代码执行无关,它可以是同步的(线程被阻塞)或异步的(线程未被阻塞,并且响应最终会到达回调)。这里的重点是协议(HTTP/HTTPS)是同步的,客户端代码只有在收到 HTTP 服务器响应后才能继续其任务。
- 异步协议:其他协议如 AMQP(许多操作系统和云环境支持的协议)使用异步消息。客户端代码或消息发送者通常不等待响应。它只是将消息发送到消息代理服务,例如 RabbitMQ 或 Kafka(如果我们使用的是事件驱动架构)。
为什么你应该避免同步协议
- 如果您不断添加相互通信的新微服务,那么在代码中使用端点会造成混乱,尤其是当您必须在端点中传递额外信息时。例如,身份验证令牌。
- 您必须等待耗时的调用才能获得响应。
- 如果响应失败并且您有重试策略,那么它可能会造成瓶颈。
- 如果接收器服务关闭或无法处理请求,那么我们要等到服务启动。例如,在电子商务网站中,用户下订单并请求发送到发货服务以发货,但发货服务关闭,我们丢失了订单。一旦完成,如何将相同的订单发送到运输服务?
- 接收方可能无法一次处理大量请求,因此应该有一个地方让请求必须等待,直到接收方准备好处理下一个请求。
为了应对这些挑战,我们可以使用一个中间服务来处理两个微服务之间的通信,也称为“消息代理”。
RabbitMQ 被广泛用作消息代理服务,如果您将 Azure 云作为托管服务提供商,您也可以使用 Azure 服务总线。
如何使用RabbitMQ来处理微服务之间的通信
可能存在发件人想要向多个服务发送消息的情况。 让我们看看 RabbitMQ 如何处理的下图。
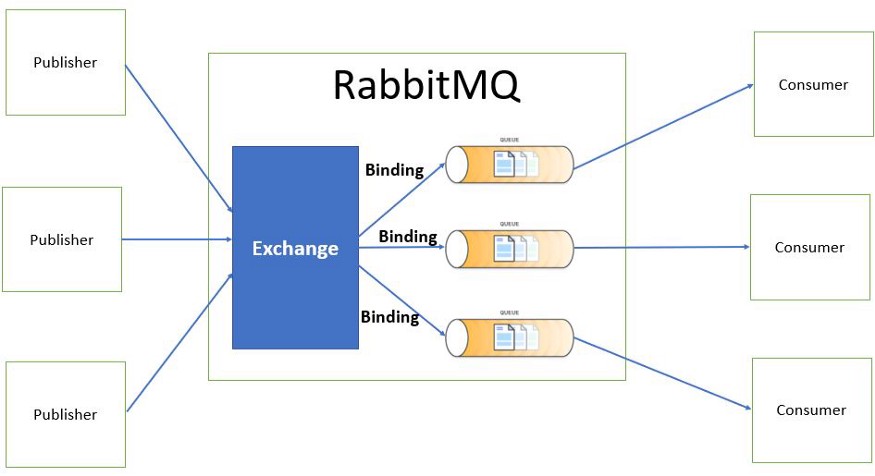
当发布者发送消息时,它被 Exchange 接收,然后 Exchange 将其发送到目标队列。消息保持在队列中,直到接收方接收并处理它。
交换类型
- 直接交换根据消息路由键将消息传递到队列。这是默认的交换类型。
- 扇出交换将消息传递到所有队列。
- Header Exchange 根据消息头标识目标队列。
- 主题交换类似于直接交换,但路由是根据路由模式完成的。它不使用固定的路由键,而是使用通配符。
例如,假设我们有以下路由模式。
- order.logs.customer
- order.logs.international
- order.logs.customer.electronics
- order.logs.international.electronics
“order.*.*.electronics” 的路由模式只匹配第一个词是“order”,第四个词是“electronics”的路由键。
“order.logs.customer.#”的路由模式匹配任何以“order.logs.customer”开头的路由键。
实现RabbitMQ
安装
按照此链接在 Windows 上安装 RabbitMQ。安装后 RabbitMQ 服务将在 http://localhost:15672/ 上启动并运行。在用户名和密码中输入“guest”登录,您将能够看到所有静态信息。
创建发件人服务
RabbitMQ 启动并运行后,创建两个控制台应用程序
Sender:向RabbitMQ发送消息
Receiver:从RabbitMQ接收消息
向两个应用程序添加包“RabbitMQ.Client”。
using System;
using RabbitMQ.Client;
using System.Text;
class Send
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
channel.QueueDeclare(queue: "hello", durable: false, exclusive: false,
autoDelete: false, arguments: null);
string message = "Hello World!";
var body = Encoding.UTF8.GetBytes(message);
channel.BasicPublish(exchange: "", routingKey: "hello",
basicProperties: null, body: body);
Console.WriteLine(" [x] Sent {0}", message);
}
Console.WriteLine(" Press [enter] to exit.");
Console.ReadLine();
}
}
上面的代码将创建一个到 RabbitMQ 的连接,创建一个队列“hello”并向队列发布一条消息。
using RabbitMQ.Client;
using RabbitMQ.Client.Events;
using System;
using System.Text;
class Receive
{
public static void Main()
{
var factory = new ConnectionFactory() { HostName = "localhost" };
using(var connection = factory.CreateConnection())
using(var channel = connection.CreateModel())
{
channel.QueueDeclare(queue: "hello", durable: false,
exclusive: false, autoDelete: false, arguments: null);
Console.WriteLine(" [*] Waiting for messages.");
var consumer = new EventingBasicConsumer(channel);
consumer.Received += (model, ea) =>
{
var body = ea.Body.ToArray();
var message = Encoding.UTF8.GetString(body);
Console.WriteLine(" [x] Received {0}", message);
};
channel.BasicConsume(queue: "hello", autoAck: true, consumer: consumer);
Console.WriteLine(" Press [enter] to exit.");
Console.ReadLine();
}
}
}
上面的代码将创建一个到 RabbitMQ 的连接,创建一个队列(如果它还没有创建),并注册一个将接收和处理消息的处理程序。
在运行发送方和接收方应用程序时,您将能够看到在 RabbitMQ 门户上创建的队列,以及表示收到新消息的图形上的尖峰。从门户中,您将能够看到哪个服务有待处理的消息,您可以添加该服务的另一个实例以进行负载平衡。
一开始你可以使用rabbitMQ,事情会很顺利。但是当复杂性增加并且您有很多端点调用其他服务时,它就会造成混乱。很快,您会发现自己围绕驱动程序创建了一个包装器,这样您就可以减少需要编写的代码量。例如,每次您调用另一个服务的端点时,您都必须提供身份验证令牌。然后你会发现自己需要处理 ack 与 nack,你将为此创建一个简单的 API。最终,您将需要处理有害消息——格式错误并导致异常的消息。
要处理所有这些工作流,您可以使用 NserviceBus。让我们讨论一个项目结构:

考虑到这种架构,ClientUI 端点将 PlaceOrder 命令发送到 Sales 端点。 因此,Sales 端点将使用发布/订阅模式发布 OrderPlaced 事件,该事件将由 Billing 端点接收。
NserviceBus 配置:
class Program
{
static async Task Main(string[] args)
{
await CreateHostBuilder(args).RunConsoleAsync();
}
public static IHostBuilder CreateHostBuilder(string[] args)
{
return Host.CreateDefaultBuilder(args)
.UseNServiceBus(context =>
{
var endpointConfiguration = new EndpointConfiguration("Sales");
//configure transport - configure where your message will
//be published/saved
//you can configure it for RabbitMq, Azure Queue, Amazon
//SQS or any other cloud provider
endpointConfiguration.UseTransport<LearningTransport>();
endpointConfiguration.SendFailedMessagesTo("error");
//When a message fails processing
//it will be forwarded here.
endpointConfiguration.AuditProcessedMessagesTo("audit");
//All messages received by an endpoint
//will be forwarded to the audit queue.
return endpointConfiguration;
});
}
}
然后使用 IMessageSession 对象发送消息:
public class HomeController : Controller
{
static int messagesSent;
private readonly ILogger<HomeController> _log;
private readonly IMessageSession _messageSession;
public HomeController(IMessageSession messageSession, ILogger<HomeController> logger)
{
_messageSession = messageSession;
_log = logger;
}
[HttpPost]
public async Task<ActionResult> PlaceOrder()
{
string orderId = Guid.NewGuid().ToString().Substring(0, 8);
var command = new PlaceOrder { OrderId = orderId };
// Send the command
await _messageSession.Send(command)
.ConfigureAwait(false);
_log.LogInformation($"Sending PlaceOrder, OrderId = {orderId}");
dynamic model = new ExpandoObject();
model.OrderId = orderId;
model.MessagesSent = Interlocked.Increment(ref messagesSent);
return View(model);
}
}
最后,添加一个处理程序来接收和处理消息:
public class PlaceOrderHandler :
IHandleMessages<PlaceOrder>
{
static readonly ILog log = LogManager.GetLogger<PlaceOrderHandler>();
static readonly Random random = new Random();
public Task Handle(PlaceOrder message, IMessageHandlerContext context)
{
log.Info($"Received PlaceOrder, OrderId = {message.OrderId}");
return Task.CompletedTask;
}
}
这是 NserviceBus 和 RabbitMQ 的基本实现。
概括
在服务之间通信时避免使用同步协议。 使用 RabbitMQ 在服务之间进行通信并在消息从源传送到目标之前临时保存它们。 使用 NserviceBus 解耦应用程序代码和消息代理,并管理长时间运行的请求。
原文:https://irfanyusanif.medium.com/how-to-communicate-between-microservice…
- 38 次浏览
【微服务】构建应用程序的顶级微服务设计模式

在当今市场上,微服务已成为构建应用程序的首选解决方案。 众所周知,它们可以解决各种挑战,但是,熟练的专业人员在使用此架构时经常面临挑战。 因此,相反,开发人员可以探索这些问题中的常见模式,并可以创建可重用的解决方案来提高应用程序的性能。 因此,在这篇关于微服务设计模式的文章中,我将讨论构建成功的微服务所必需的顶级模式。
本文将介绍以下主题:

- 什么是微服务?
- 用于设计微服务架构的原则
- 微服务的设计模式
什么是微服务?
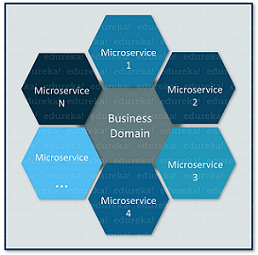
微服务,又名微服务架构,是一种架构风格,将应用程序构建为围绕业务领域建模的小型自治服务的集合。在微服务架构中,每个服务都是自包含的并实现单一的业务能力。如果想详细了解微服务,可以参考我的微服务架构一文。
用于设计微服务架构的原则
用于设计微服务的原则如下:
- 独立自主的服务
- 可扩展性
- 权力下放(去中心化)
- 弹性服务
- 实时负载均衡
- 可用性
- 通过 DevOps 集成实现持续交付
- 无缝 API 集成和持续监控
- 故障隔离
- 自动配置
微服务的设计模式
- 聚合器
- API 网关
- 连锁或责任链
- 异步消息
- 数据库或共享数据
- 事件溯源
- 分支
- 命令查询职责分离器
- 断路器
- 分解
聚合器模式
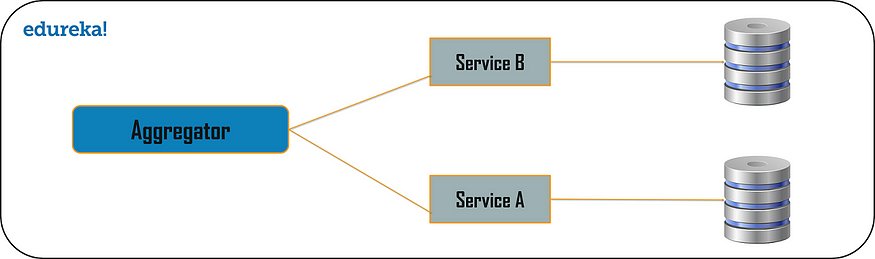
计算世界中的聚合器是指收集相关数据项并显示它们的网站或程序。因此,即使在微服务模式中,聚合器也是一个基本的网页,它调用各种服务来获取所需的信息或实现所需的功能。
此外,由于输出源在将单体架构分解为微服务时被划分,因此当您需要通过组合来自多个服务的数据来输出时,这种模式被证明是有益的。因此,如果我们有两个服务,每个服务都有自己的数据库,那么具有唯一事务 ID 的聚合器将从每个单独的微服务收集数据,应用业务逻辑并最终将其发布为 REST 端点。稍后,收集到的数据可以由需要收集到的数据的各个服务使用。
聚合设计模式基于 DRY 原则。基于此原则,您可以将逻辑抽象为复合微服务,并将特定业务逻辑聚合到一个服务中。
因此,例如,如果您考虑两个服务:服务 A 和 B,那么您可以通过将数据提供给复合微服务来同时单独扩展这些服务。
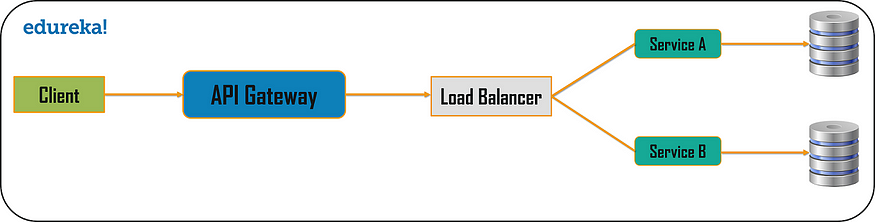
API 网关设计模式
微服务的构建方式使得每个服务都有自己的功能。但是,当应用程序被分解为小型自治服务时,开发人员可能面临的问题可能很少。问题可能如下:
- 如何从多个微服务请求信息?
- 不同的 UI 需要不同的数据来响应同一个后端数据库服务
- 如何根据消费者需求从可重用的微服务中转换数据
- 如何处理多个协议请求?
好吧,这些问题的解决方案可能是 API 网关设计模式。 API 网关设计模式不仅解决了上述问题,还解决了许多其他问题。这种微服务设计模式也可以被认为是代理服务,将请求路由到相关的微服务。作为聚合器服务的一种变体,它可以将请求发送到多个服务,并类似地将结果聚合回组合或消费者服务。 API Gateway 还充当所有微服务的入口点,并为不同类型的客户端创建细粒度的 API。
借助 API Gateway 设计模式,API 网关可以将协议请求从一种类型转换为另一种类型。同样,它也可以卸载微服务的身份验证/授权责任。
因此,一旦客户端发送请求,这些请求就会传递到 API 网关,该网关充当入口点,将客户端的请求转发到适当的微服务。然后,在负载均衡器的帮助下,处理请求的负载并将请求发送到相应的服务。微服务使用服务发现作为指导来找到它们之间的通信路径。然后微服务通过无状态服务器相互通信,即通过 HTTP 请求/消息总线。
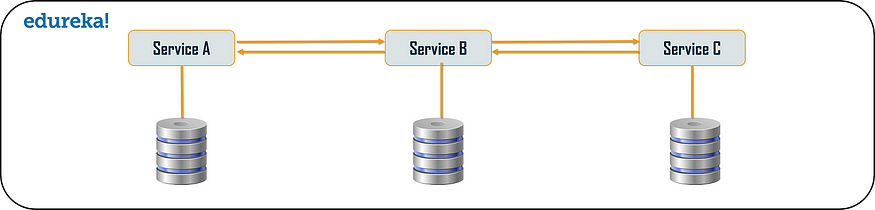
链式或责任链模式
链式或责任链设计模式产生单个输出,该输出是多个链式输出的组合。因此,如果您将三个服务排成一条链,那么,来自客户端的请求首先由服务 A 接收。然后,该服务与下一个服务 B 通信并收集数据。最后,第二个服务与第三个服务通信以生成合并的输出。所有这些服务都使用同步 HTTP 请求或响应进行消息传递。此外,在请求通过所有服务并生成相应的响应之前,客户端不会得到任何输出。所以,总是建议不要做长链,因为客户端会等到链完成
您需要了解的另一个重要方面是,从服务 A 到服务 B 的请求可能看起来与服务 B 到服务 C 不同。同样,从服务 C 到服务 B 的响应可能看起来与服务 B 到服务 A 完全不同。
异步消息设计模式
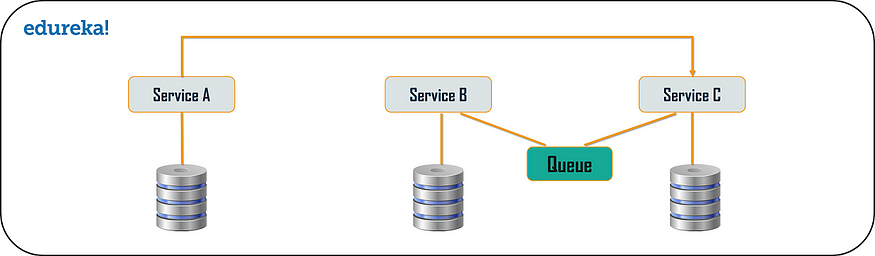
从上面的模式中,很明显客户端在同步消息中被阻塞或等待很长时间。 但是,如果您不希望消费者等待很长时间,那么您可以选择异步消息传递。 在这种类型的微服务设计模式中,所有服务都可以相互通信,但它们不必按顺序相互通信。 因此,如果考虑 3 个服务:服务 A、服务 B 和服务 C。来自客户端的请求可以直接同时发送到服务 C 和服务 B。 这些请求将排在队列中。 除此之外,请求还可以发送到服务 A,其响应不必发送到请求所经过的同一服务。
数据库或共享数据模式
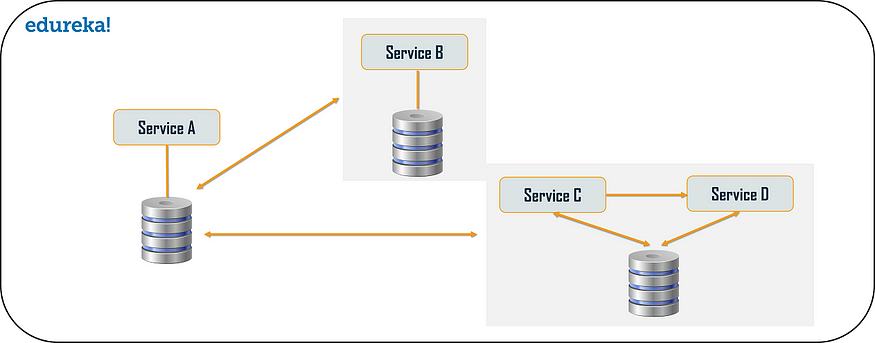
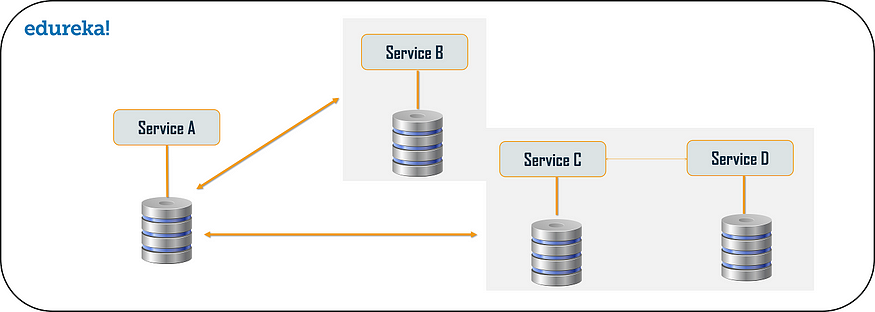
对于每个应用程序,都存在大量数据。因此,当我们将应用程序从其单体架构分解为微服务时,非常重要的是要注意每个微服务都有足够的数据量来处理请求。因此,系统可以为每个服务拥有一个数据库,也可以为每个服务拥有一个共享数据库。您可以使用每个服务的数据库和每个服务的共享数据库来解决各种问题。问题可能如下:
- 数据重复和不一致
- 不同的服务有不同的存储需求
- 很少有业务可以查询数据,有多种服务
- 数据去规范化
好吧,为了解决前三个问题,我认为您可以使用每个服务的数据库,因为它将由微服务 API 本身访问。因此,每个微服务都有自己的数据库 ID,这会阻止系统中的其他服务使用该特定数据库。除此之外,为了解决反规范化问题,您可以为每个服务选择共享数据库,为每个微服务对齐多个数据库。这将帮助您为分解为微服务的单体应用程序收集数据。但是,您必须记住,您必须将这些数据库限制为 2-3 个微服务;否则,扩展这些服务将是一个问题。
事件溯源设计模式
事件源设计模式创建有关应用程序状态更改的事件。 此外,这些事件被存储为一系列事件,以帮助开发人员跟踪何时进行了哪些更改。 因此,借助此功能,您可以随时调整应用程序状态以应对过去的变化。 您还可以查询这些事件以了解任何数据更改,并同时从事件存储中发布这些事件。 发布事件后,您可以在表示层上看到应用程序状态的变化。
分支模式
分支微服务设计模式是一种设计模式,您可以在其中同时处理来自两个或多个独立微服务的请求和响应。 因此,与链式设计模式不同,请求不是按顺序传递的,而是将请求传递给两个或多个互斥的微服务链。 这种设计模式扩展了聚合器设计模式,并提供了从多链或单链产生响应的灵活性。 例如,如果您考虑一个电子商务应用程序,那么您可能需要从多个来源检索数据,而这些数据可能是来自各种服务的数据的协作输出。 因此,您可以使用分支模式从多个来源检索数据。
命令查询职责分离器 (CQRS) 设计模式
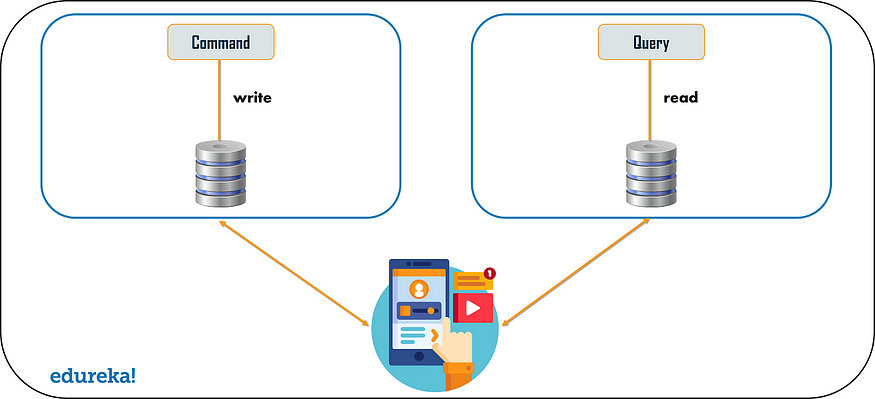
每个微服务设计都有每个服务模型的数据库或每个服务的共享数据库。 但是,在每个服务的数据库模型中,我们无法实现查询,因为数据访问仅限于一个数据库。 因此,在这种情况下,您可以使用 CQRS 模式。 根据这种模式,应用程序将分为两部分:命令和查询。 命令部分将处理与 CREATE、UPDATE、DELETE 相关的所有请求,而查询部分将处理物化视图。 通过使用上述事件源模式创建的一系列事件来更新物化视图。
断路器模式
顾名思义,断路器设计模式用于在服务不工作时停止请求和响应过程。因此,例如,假设客户端正在发送从多个服务检索数据的请求。但是,由于某些问题,其中一项服务已关闭。现在,您将面临主要两个问题:首先,由于客户端不知道某个特定服务已关闭,因此请求将不断发送到该服务。第二个问题是网络资源枯竭,性能低下,用户体验差。
因此,为避免此类问题,您可以使用断路器设计模式。在此模式的帮助下,客户端将通过代理调用远程服务。该代理基本上将充当电路屏障。因此,当故障数量超过阈值数量时,断路器会在特定时间段内跳闸。然后,所有调用远程服务的尝试都将在此超时时间内失败。一旦该时间段结束,断路器将允许通过有限数量的测试,如果这些请求成功,断路器将恢复正常操作。否则,如果出现故障,则超时周期重新开始。
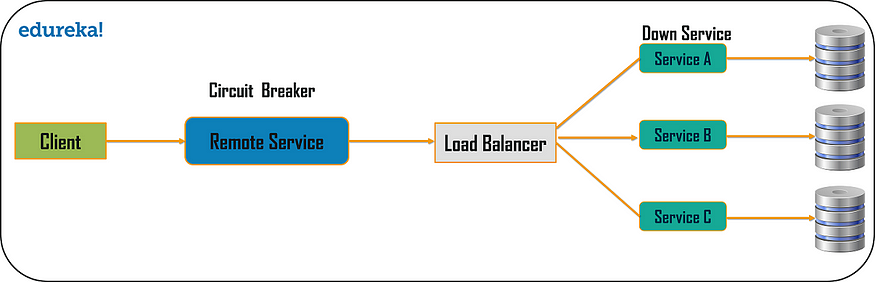
分解设计模式
微服务是根据开发人员的想法开发的,即创建小型服务,每个服务都有自己的功能。但是,将应用程序分解成小的自治单元必须在逻辑上完成。因此,要将小型或大型应用程序分解为小型服务,您可以使用分解模式。
借助此模式,您可以基于业务能力或基于子域来分解应用程序。例如,如果您考虑一个电子商务应用程序,那么如果您按业务能力进行分解,那么您可以为订单、支付、客户、产品提供单独的服务。
但是,在相同的场景中,如果您通过分解子域来设计应用程序,那么您可以为每个类提供服务。在这里,在这个例子中,如果你把客户看作一个类,那么这个类将用于客户管理,客户支持等。所以,分解,你可以使用整个领域模型的领域驱动设计细分为子域。然后,这些子域中的每一个都有自己的特定模型和范围(有界上下文)。现在,当开发人员设计微服务时,他/她将围绕范围或有界上下文设计这些服务。
尽管这些模式对您来说听起来可行,但它们对于大型单片应用程序并不可行。这是因为识别子域和业务能力对于大型应用程序来说并不是一件容易的事。因此,分解大型单体应用程序的唯一方法是遵循藤蔓模式或扼杀者模式。
扼杀者模式或藤蔓模式
扼杀者模式或藤蔓模式是基于与藤蔓的类比,藤蔓基本上扼杀了它所缠绕的树。因此,当将此模式应用于 Web 应用程序时,每个 URI 调用都会来回调用,并且服务会分解为不同的域。这些域将作为单独的服务托管。
根据扼杀者模式,两个独立的应用程序将并排存在于同一个 URI 空间中,并且在一个实例中将考虑一个域。因此,最终,新的重构应用程序会环绕或扼杀或替换原始应用程序,直到您可以关闭单体应用程序
如果您想查看更多有关人工智能、DevOps、Ethical Hacking 等市场最流行技术的文章,您可以参考 Edureka 的官方网站。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. What is Microservices?
- 2. Microservices Architecture
- 3. Microservices vs SOA
- 4. Microservices Tutorial
- 5. Building Microservices Application Using Spring Boot
- 5. Microservices Security
原文:https://medium.com/edureka/microservices-design-patterns-50640c7bf4a9
- 24 次浏览
【微服务原则】利用微服务缩短产品上市时间
无论他们是访问网站还是移动应用,人们对他们经常使用的应用程序抱有很高的期望。 因此,公司必须不断提供新功能和修复。 在过去,这个过程很痛苦,因为应用程序通常是作为单个(通常是单片的)应用程序开发,构建和提供的。
微服务是一种应用程序架构风格,其中应用程序由许多离散的,网络连接的组件组成,称为微服务:
- 大型单片应用程序被分解为小型服务。
- 单个网络可访问服务是微服务应用程序的最小可部署单元。
- 每个服务都在自己的进程中运行。 此规则有时称为“每个容器一个服务”,可能是容器或任何其他轻量级部署机制,例如Cloud Foundry运行时。
客户正在尝试使他们的应用程序现代化,以跟上变化的速度......在过去,操作决定了应用程序的编写方式......人们花了数年时间编写单一应用程序,其中许多应用程序功能都打包在应用程序中。 ..现在他们看到了开发人员在添加新功能以应对不断变化的营销需求方面遇到的困难。----- Roland Barcia,杰出工程师兼首席技术官:微服务
微服务的好处
采用微服务的企业可享受许多好处:
高效的团队
微服务是分成一组可独立部署的小型服务的应用程序。由于微服务旨在独立行动,因此它们自然地与促进端到端团队所有权的敏捷原则保持一致。
简化部署
每个微服务都围绕业务功能构建和对齐,以降低应用程序变更管理过程的复杂性。由于每项服务都是在不影响其他服务的情况下单独更改,测试和部署的,因此加快了上市时间。
适合工作的正确工具
开发微服务的团队可以做出适合工作的技术决策。他们可以尝试新技术,库,语言和框架,从而缩短创新周期。
提高应用质量
由于微服务的“分而治之”方法,微服务的功能和性能测试都比单片应用程序更容易。微服务架构适用于测试驱动的开发,因为组件可以单独测试,并与完整或虚拟化的微服务组合。这种方法可以全面提高应用质量。
可扩展性
微服务比单片应用程序更容易扩展。通过根据各个服务对整体应用程序,吞吐量,内存和CPU负载的关键性来扩展各个服务,团队可以更有效地扩展应用程序。
微服务原则
在为应用程序开发微服务时,请记住以下原则:
单一职责
每个微服务必须针对单个功能进行优化。每项服务都更小,更易于编写,维护和管理。罗伯特马丁称这一原则为“单一责任原则”。
单独的流程
微服务之间的通信必须通过REST API和消息代理进行。从服务到服务的所有通信都必须通过服务API进行,或者必须使用显式通信模式,例如Hohpe的Claim Check Pattern。
执行范围
虽然微服务可以通过API公开自己,但重点不在于接口,而在于运行组件。此图中突出显示了微服务应用程序的粒度:

微服务API通信
CI / CD
每个微服务可以连续集成(CI)并连续交付(CD)。当您构建由许多服务组成的大型应用程序时,您很快就会意识到不同的服务以不同的速率发展。如果每个服务都具有唯一的持续集成或连续交付管道,则该服务可以按照自己的进度进行。在整体方法中,系统的不同方面都以系统中最慢的移动部分的速度释放。
弹性
您可以将高可用性和群集决策应用于每个微服务。当您构建大型系统时,您拥有的另一个实现是,当涉及到群集时,一个大小并不适合所有。在同一级别上扩展整体中所有服务的单一方法可能导致服务的过度使用或使用不足。更糟糕的是,当共享资源被垄断时,服务可能会被忽略。在大型系统中,您可以将不需要扩展的服务部署到最少数量的服务器以节省资源。其他服务需要扩展到大数量。
将应用程序迁移到微服务
微服务是一个小应用程序,通常包含一个功能。该功能通过API和消息传递。每个微服务都可以拥有自己的DevOps管道,可以单独扩展,并拥有自己的数据库,拥有数据模型。
该图显示了单片应用程序架构如何演变为基于微服务的应用程序架构:
微服务示例概述

在单片应用程序中,代码位于单个服务器上。更新单个组件时,必须同时部署其他组件,因此需要一个完全等效的服务器,以通过蓝绿色部署满足高可用性要求。
在重构的微服务应用程序中,简化了更新部署,因为业务服务在独立的基于云的计算基础架构上独立运行。
要了解微服务应用程序的工作方式以及从单片应用程序迁移到微服务,请观看此视频:
下一步是什么?
既然您已了解使用微服务的概念和价值,请通过阅读微服务参考架构了解有关如何设计微服务应用程序的更多信息。在了解了体系结构之后,请参考教程在Kubernetes上部署微服务应用程序。
原文:https://www.ibm.com/cloud/garage/architectures/microservices
本文:http://pub.intelligentx.net/improve-time-market-microservices
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 26 次浏览
【微服务架构 】微服务第3部分:服务注册表
在微服务系列的这篇文章中,我们将讨论服务注册表。在第2部分中,我们讨论了API网关,其中我们提到服务已在数据库中注册。网关根据该数据库中包含的信息调度请求。下面我们将探讨如何填充数据库以及服务,客户端和网关与之交互的方式。
服务注册表
服务注册表是一个数据库,其中包含有关如何将请求分派给微服务实例的信息。注册表和其他组件之间的交互可以分为两组,每组有两个子组:
微服务和注册表之间的交互(注册)
- 自注册
- 第三方注册
客户端与注册表之间的交互(发现)
- 客户端发现
- 服务器端发现
注册
大多数基于微服务的架构都在不断发展。随着开发团队分离,改进,弃用和完成工作,服务会上下波动。每当服务端点发生更改时,注册表都需要了解更改。这就是注册的全部内容:谁发布或更新有关如何联系每项服务的信息。
自注册迫使微服务自己与注册表进行交互。当服务上升时,它会通知注册表。服务中断时会发生同样的事情。无论注册表需要哪些其他数据,都必须由服务本身提供。如果你一直关注这个系列,你就会知道微服务都是关于处理一个问题,所以自我注册可能看起来像一个反模式。但是,对于简单的体系结构,自注册可能是正确的选择。
第三方注册通常在行业中使用。 在这种情况下,有一个管理所有其他服务的进程或服务。 此过程以某种方式轮询或检查哪些微服务实例正在运行,并自动更新服务注册表。 可以以每服务配置文件(或策略)的形式提供附加数据,注册过程使用该文件来更新数据库。 在使用Apache ZooKeeper或Netflix Eureka等工具以及其他服务管理器的架构中,第三方注册很常见。
第三方注册还提供其他好处。例如,当服务出现故障时会发生什么?可以将第三方注册服务配置为为失败的服务提供安全回退。其他案例可能会实施其他政策。例如,服务注册表进程可能会收到高负载情况的通知,并通过请求实例化新的微服务进程或VM来自动添加新端点。可以想象,这些可能性对于大型架构至关重要。
发现
可以想象,从客户的角度来看,发现是注册的对应物。当客户想要访问服务时,它必须找出服务所在的位置(以及执行请求的其他相关信息)。
客户端发现强制客户端在执行实际请求之前查询发现服务。正如自我注册所发生的那样,这要求客户处理除主要目标之外的其他问题。发现服务可能位于API网关后面,也可能不位于API网关后面。如果它不在网关后面,则可能需要为发现服务重新实现平衡,身份验证和其他横切关注点。此外,每个客户端都需要知道要联系发现服务的固定端点(或端点)。这些都是缺点。一个很大的优点是不必在网关系统中编写必要的逻辑。选择发现方法时,请仔细研究。
服务器端发现使API网关处理发现请求的正确端点(或端点)。 这通常用于更大的架构。 由于所有请求都直接发送到网关,所以与之相关的所有好处都适用(参见第2部分)。 网关还可以实现发现缓存,以便许多请求可以具有较低的延迟。 高速缓存失效背后的逻辑特定于实现。
“服务器端发现使API网关能够处理发现请求的正确端点。”
服务器端发现
示例:注册表服务
在第2部分中,我们研究了一个简单的API网关实现。在该示例中,我们通过查询到服务数据库来实现动态调度请求。换句话说,我们实现了服务器端发现。对于此示例,我们将通过处理注册方面来扩展我们的微服务架构。我们将以两种方式这样做:
- 通过提供一个简单的注册库,任何开发团队都可以将其集成到他们的微服务中以执行自我注册。
- 通过提供在启动或关闭期间注册服务的示例systemd单元(使用systemd作为服务管理器的第三方注册)。
为什么要系统?它已成为大多数Linux安装中的事实上的服务管理器。管理服务还有其他选择,但都需要安装和配置。为简单起见,我们选择了大多数发行版中预装的那个,这是systemd。
注册库
我们之前发布的微服务示例是为node.js开发的,所以我们的库也适用于它。这是我们库的主要逻辑:
module.exports.register = function(service, callback) {
if(!validateService(service)) {
callback(new Error("Invalid service"));
}
findExisting(service.name, function(err, found) {
if(found) {
callback(new Error("Existing service"));
return;
}
var dbService = new Service({
name: service.name,
url: service.url,
endpoints: service.endpoints,
authorizedRoles: service.authorizedRoles
});
dbService.save(function(err) {
callback(err);
});
});
}
module.exports.unregister = function(name, callback) {
findExisting(name, function(err, found) {
if(!found) {
callback(new Error("Service not found"));
return;
}
found.remove(function(err) {
callback(err);
});
});
}
执行自注册的微服务需要在启动或关闭期间调用这些功能(包括异常关闭)。 我们已通过以下方式将此库集成到现有的微服务示例中(将SELF_REGISTRY变量设置为任何值以启用此功能)。 启动代码:
// Standalone server setup
var port = process.env.PORT || 3001;
http.createServer(app).listen(port, function (err) {
if (err) {
logger.error(err);
} else {
logger.info('Listening on http://localhost:' + port);
if(process.env.SELF_REGISTRY) {
registry.register({
name: serviceName,
url: '/tickets',
endpoints: [ {
type: 'http',
url: 'http://127.0.0.1:' + port + '/tickets'
} ],
authorizedRoles: ['tickets-query']
}, function(err) {
if(err) {
logger.error(err);
process.exit();
}
});
}
}
});
和关机代码:
function exitHandler() {
if(process.env.SELF_REGISTRY) {
registry.unregister(serviceName, function(err) {
if(err) {
logger.error(err);
}
process.exit();
});
} else {
process.exit();
}
}
process.on('exit', exitHandler);
process.on('SIGINT', exitHandler);
process.on('SIGTERM', exitHandler);
process.on('uncaughtException', exitHandler);
使用systemd进行第三方注册
我们的网关示例从Mongo数据库中读取服务信息。 Mongo提供了一个命令行界面,我们可以在启动或关闭期间使用它来注册服务。 这是一个示例systemd单元(如果您使用此帖子中的示例微服务,请记住禁用SELF_REGISTRY环境变量):
[Unit]
Description=Sample tickets query microservice
#Uncomment the following line when not running systemd in user mode
#After=network.target
[Service]
#Uncomment the following line to run the service as a specific user
#User=seba
Environment="MONGO_URL=mongodb://127.0.0.1:27018/test"
ExecStart=/usr/bin/node /home/seba/Projects/Ingadv/Auth0/blog-code/microservices/server.js
ExecStartPost=/usr/bin/mongo --eval 'db.services.insert({"name": "Tickets Query Service", "url": "/tickets", "endpoints": [{"type": "http", "url": "http://127.0.0.1:3001/tickets"}], "authorizedRoles": ["tickets-query"] });' 127.0.0.1:27017/test
ExecStopPost=/usr/bin/mongo --eval 'db.services.remove({"name": "Tickets Query Service"});' 127.0.0.1:27017/test
[Install]
WantedBy=default.target
注册由ExecStartPost和ExecStopPost指令通过调用命令行Mongo客户端(包含在所有标准MongoDB安装中)来处理。
获取代码https://github.com/auth0/blog-microservices-part3。
另外:使用Auth0作为您的微服务
由于JWT的神奇之处,Auth0和微服务齐头并进。 看看这个:
var express = require('express');
var app = express();
var jwt = require('express-jwt');
var jwtCheck = jwt({
secret: new Buffer('your-auth0-client-secret', 'base64'),
audience: 'your-auth0-client-id'
});
app.use('/api/path-you-want-to-protect', jwtCheck);
// (...)
您可以通过Auth0仪表板获取客户端ID和客户端密钥。 创建一个新帐户并开始黑客攻击!
结论
服务注册表是基于微服务的体系结构的重要组成部分。 有不同的处理注册和发现的方法,适合不同的架构复杂性。 在承诺之前考虑上述每种替代方案的优缺点。 在第4部分中,我们将详细研究服务依赖性以及如何有效地管理它们。
- 34 次浏览
【微服务架构】 微服务API网关,第2部分
在微服务系列的这篇文章中,我们将讨论API网关以及它们如何帮助我们解决基于微服务架构的一些重要问题。我们在本系列的第一篇文章中描述了这些和其他问题。
什么是API网关以及为什么要使用它?
在所有基于服务的体系结构中,有几个关注点在所有(或大多数)服务之间共享。基于微服务的架构也不例外。正如我们在第一篇文章中所说,微服务几乎是孤立开发的。交叉问题由软件堆栈中的上层处理。 API网关是其中一个层。以下是API网关处理的常见问题列表:
- 认证
- 运输安全
- 负载均衡
- 请求调度(包括容错和服务发现)
- 依赖性解决方案
- 运输转型
认证
大多数网关对每个请求(或一系列请求)执行某种身份验证。根据特定于每个服务的规则,网关将请求路由到所请求的微服务或返回错误代码(或更少的信息)。大多数网关在将请求传递给后面的微服务时将身份验证信息添加到请求中。这允许微服务在需要时实现用户特定的逻辑。
安全
许多网关作为公共API的单一入口点。在这种情况下,网关处理传输安全性,然后通过使用不同的安全通道或通过删除内部网络内不必要的安全约束来分派请求。例如,对于RESTful HTTP API,网关可以执行“SSL终止”:在客户端和网关之间建立安全SSL连接,然后通过非SSL连接将代理请求发送到内部服务。
“许多网关作为公共API的单一入口点。”
负载均衡
在高负载情况下,网关可以根据自定义逻辑在微服务实例之间分发请求。每项服务可能都有特定的扩展限制。网关旨在通过考虑这些限制来平衡负载。例如,某些服务可能通过在不同的内部端点下运行多个实例来扩展。网关可以将请求分派给这些端点(甚至请求更多端点的动态实例化)来处理负载。
请求调度
即使在正常负载情况下,网关也可以为调度请求提供自定义逻辑。在大型体系结构中,随着团队工作或生成新的微服务实例(例如,由于拓扑更改),会添加和删除内部端点。网关可以与服务注册/发现过程或描述如何分派每个请求的数据库协同工作。这为开发团队提供了出色的灵活性。此外,故障服务可以路由到备份或通用服务,这些服务允许请求完成而不是完全失败。
依赖性解决方案
由于微服务处理非常具体的问题,一些基于微服务的架构往往变得“健谈”:要执行有用的工作,需要将许多请求发送到许多不同的服务。出于方便和性能的原因,网关可以提供在内部路由到许多不同微服务的外观(“虚拟”端点)。
传输转换
正如我们在本系列的第一篇文章中所了解到的那样,微服务通常是孤立开发的,开发团队在选择开发平台时具有很大的灵活性。这可能导致微服务返回数据并使用对于网关另一侧的客户端不方便的传输。网关必须执行必要的转换,以便客户端仍然可以与其后面的微服务进行通信。
API网关示例
我们的示例是一个简单的node.js网关。它处理HTTP请求并将它们转发到适当的内部端点(在传输过程中执行必要的转换)。它处理以下问题:
认证
使用JWT进行身份验证。单个端点处理初始身份验证:/ login。用户详细信息存储在Mongo数据库中,对端点的访问受角色限制。
/*
* Simple login: returns a JWT if login data is valid.
*/
function doLogin(req, res) {
getData(req).then(function(data) {
try {
var loginData = JSON.parse(data);
User.findOne({ username: loginData.username }, function(err, user) {
if(err) {
logger.error(err);
send401(res);
return;
}
if(user.password === loginData.password) {
var token = jwt.sign({
jti: uuid.v4(),
roles: user.roles
}, secretKey, {
subject: user.username,
issuer: issuerStr
});
res.writeHeader(200, {
'Content-Length': token.length,
'Content-Type': "text/plain"
});
res.write(token);
res.end();
} else {
send401(res);
}
}, 'users');
} catch(err) {
logger.error(err);
send401(res);
}
}, function(err) {
logger.error(err);
send401(res);
});
}
/*
* Authentication validation using JWT. Strategy: find existing user.
*/
function validateAuth(data, callback) {
if(!data) {
callback(null);
return;
}
data = data.split(" ");
if(data[0] !== "Bearer" || !data[1]) {
callback(null);
return;
}
var token = data[1];
try {
var payload = jwt.verify(token, secretKey);
//Your custom validation logic goes here.
if(!payload.jti || revokedTokens[payload.jti]) {
logger.debug('Revoked token, access denied: ' + payload.jti);
callback(null);
} else {
callback({jwt: payload});
}
} catch(err) {
logger.error(err);
callback(null);
}
}
免责声明:此帖中显示的代码未准备好生产。 它仅用于显示概念。 不要盲目复制粘贴:)
传输安全
传输安全性通过TLS处理:所有公共请求首先由具有样本证书的反向nginx代理设置接收。
负载均衡
负载平衡由nginx处理。 请参阅示例配置。
动态调度,数据聚合和故障
根据存储在数据库中的配置动态调度请求。 支持两种类型的请求:HTTP和AMQP。
请求还支持在多个微服务之间拆分请求的聚合策略:单个公共端点可以聚合来自许多不同内部端点(微服务)的数据。 所有返回的数据都是JSON格式。 看看Netflix关于这个策略如何帮助他们实现更好性能的优秀帖子。 另请查看我们关于Falcor的帖子,该帖子允许从多个来源轻松获取数据。
通过记录错误并返回少于请求的信息来处理失败的内部请求。
/*
* Parses the request and dispatches multiple concurrent requests to each
* internal endpoint. Results are aggregated and returned.
*/
function serviceDispatch(req, res) {
var parsedUrl = url.parse(req.url);
Service.findOne({ url: parsedUrl.pathname }, function(err, service) {
if(err) {
logger.error(err);
send500(res);
return;
}
var authorized = roleCheck(req.context.authPayload.jwt, service);
if(!authorized) {
send401(res);
return;
}
// Fanout all requests to all related endpoints.
// Results are aggregated (more complex strategies are possible).
var promises = [];
service.endpoints.forEach(function(endpoint) {
logger.debug(sprintf('Dispatching request from public endpoint ' +
'%s to internal endpoint %s (%s)',
req.url, endpoint.url, endpoint.type));
switch(endpoint.type) {
case 'http-get':
case 'http-post':
promises.push(httpPromise(req, endpoint.url,
endpoint.type === 'http-get'));
break;
case 'amqp':
promises.push(amqpPromise(req, endpoint.url));
break;
default:
logger.error('Unknown endpoint type: ' + endpoint.type);
}
});
//Aggregation strategy for multiple endpoints.
Q.allSettled(promises).then(function(results) {
var responseData = {};
results.forEach(function(result) {
if(result.state === 'fulfilled') {
responseData = _.extend(responseData, result.value);
} else {
logger.error(result.reason.message);
}
});
res.setHeader('Content-Type', 'application/json');
res.end(JSON.stringify(responseData));
});
}, 'services');
}
角色检查
var User = userDb.model('User', new mongoose.Schema ({
username: String,
password: String,
roles: [ String ]
}));
var Service = servicesDb.model('Service', new mongoose.Schema ({
name: String,
url: String,
endpoints: [ new mongoose.Schema({
type: String,
url: String
}) ],
authorizedRoles: [ String ]
}));
function roleCheck(jwt_, service) {
var intersection = _.intersection(jwt_.roles, service.authorizedRoles);
return intersection.length === service.authorizedRoles.length;
}
传输和数据转换
执行传输转换以在HTTP和AMQP请求之间进行转换。
日志
日志记录是集中的:所有日志都发布到控制台和内部消息总线。在消息总线上侦听的其他服务可以根据这些日志采取措施。
获取完整代码。
旁白:webtask和Auth0如何实现这些模式?
我们在系列的第一篇文章中告诉过你关于webtasks的事情。由于webtasks是微服务,它们也在网关后面运行。 webtasks网关处理身份验证,动态调度和集中式日志记录,因此您也没有。
- 对于身份验证,Auth0是令牌的发布者,webtask将验证这些令牌。它们之间存在信任关系,因此可以验证令牌。
- 对于实时日志记录,webtask实现了无状态弹性ZeroMQ架构,该架构可在整个集群中运行。
- 对于动态调度,有一个定制的Node.js代理,它使用CoreOS etcd作为pub-sub机制来相应地路由webtasks。
结论
API网关是任何基于微服务的架构的重要组成部分。 可以以方便且通用的方式处理诸如认证,负载平衡,依赖性解析,数据转换和动态请求调度之类的横切关注点。 然后,微服务可以专注于他们的特定任务,而无需重复代码。 这使得每个微服务的开发更容易和更快速。
- 46 次浏览
【微服务架构】 您需要知道的所有最佳实践
切换到微服务架构似乎很容易,但技术领导者倾向于低估项目的复杂性并犯下灾难性的错误。
在将单片系统转换为微服务或从头开始之前,您需要仔细考虑将要出现的技术和组织挑战。
如果您想要,这篇文章适合您:
- 从单片系统切换到微服务。
- 从经验丰富的技术领导者那里收集见解。
- 了解微服务的缺点和优点。
- 避免灾难性的错误。
- 对微服务做出更好的技术决策。
我们对来自以色列和美国等5个不同国家的技术领导人进行了13次采访,然后将他们的知识压缩到这个可操作的帖子中。
这篇文章真的很长!您可以使用以下链接跳转到特定部分:
- 了解你的原因
- 明确定义微服务是什么
- 微服务架构的优点和缺点
- 最大的微服务挑战和解决方案
- 避免犯这些错误
- 切换到微服务架构的最佳实践
- 您应该为特定的微服务选择哪些技术?
- 选择适当技术的过程
了解你的原因
您可以犯的最大错误是在没有明确目标的情况下切换到微服务架构。您需要了解并有真正的理由说明为什么要这样做。
“人们盲目地做了很多事情:哦,码头很酷,微服务很棒!它可能不适合您构建的每件作品,您需要了解为什么要这样做。“ - Steven McCord,ICX Media的创始人兼首席技术官
如果你的工作系统运行良好,那你改变它的动力是什么?
仅仅因为微服务被大肆宣传并不意味着你需要加入这个潮流。它可能不是您软件的最佳技术选择。
确定原因至关重要;这就是David Dawson,Steven McCord和Avi Cavale所强调的。
“当我们的客户要求我帮助他们实施微服务时,我问的第一个问题是,为什么?我正在寻找的答案是, “我们希望更快地改变我们的系统”和“我们希望利用云技术。”我让他们意识到,做得对的微服务比 构建单片系统更昂贵,更难。它为您的数据做了有趣的事情,并在您的数据模型中引入了一个网络,可 以随时任意分区,数据丢失。你让自己暴露在分布式计算的全面愤怒之中。“ - David Dawson,系统架构师
推荐方法:
- 西蒙·沃德利的沃德利地图
- Gojko Adziks的影响映射
明确定义微服务是什么
“我不一定会选择微服务。我会选择中型服务,所以不是从单块服务到数百种服务,而是更大的服务,与工 程团队和业务垂直市场保持一致。“ - DanielWeb研发副总裁Daniel Ben-Zvi
如果您在服务,微服务和功能之间找不到适当的平衡,您可以:
- 对您的应用程序进行细分,这样您就不会看到微服务的好处。
- 过度分割您的应用程序,这意味着管理微服务本身的重量将破坏微服务可以提供的价值(Avi Cavale)。
对于微服务特性如何为您的公司寻找一个非常明确的理念至关重要。
你怎么做呢?微观案例研究
“我们通过查看代码片段来确定微服务是什么,如果更改,最终会创建指数测试用例。我们开始解决这些问题 是因为我们的目标是减少我们为每一项改变所做的测试。如果这是你的目标,那么你定义为微服务的方式与有人 说“我希望计费成为微服务”不同。“ - Seippable联合创始人兼首席执行官Avi Cavale
推荐阅读:微服务与单片架构
微服务架构的优点和缺点
微服务的优点
- 可扩展性:您可以分析小块,以查看每个部分的要求。它使您可以单独扩展应用程序的不同部分。
“对我来说,另一大好处是我可以在任何VM之外扩展这些容器。我可以将容器放入我想要的任何配置中,这样我的 应用程序就可以完全移植。“ - Steven McCord,ICX Media创始人兼首席技术官
- 更易于维护:让不同的团队以或多或少的独立方式处理不同的组件。
- 部署和配置没有太多干扰:您可以部署和配置系统的微小部分,而不会影响其他服务。多个团队可以为生产提供多种结果,而不会干扰和踩到彼此的脚趾。
- 问题隔离:更容易隔离和检测问题。
- 更容易招聘:当您正在寻找开发人员或第三方提供商时,您只需要为系统的一小部分进行培训。
- 责任明确定义:一个团队负责给定的微服务。
- 深刻的知识:从事内部工作的团队从内到外都知道。
- 各种各样的编程语言:您可以使用不同的编程语言,具体取决于最适合微服务的目的。
- 更容易监督和理解:您可以将庞大的代码库拆分为较小的项目。这种方法可以让您和您的团队更好地理解项目及其代码。
- 更容易打开组件:当明确定义边界和接口时,更容易向新业务单元或外部实体打开组件或现有功能。
微服务的缺点
- 部署和互操作性:缺点是部署和互操作性成为主要问题。
- 编程语言太多:这可能会限制代码的可重用性和可维护性,并且可能会使招聘变得更加复杂。
- 使组件协同工作:您始终需要确保以他们协同工作的方式组合您的服务。只需考虑更改单个端点,这会破坏旧版本中的其他依赖服务。
- 与整体系统相比,整个系统的集成测试更难,一切都在一个地方。
- 从一开始就必须仔细考虑架构:如果服务之间存在太多的凝聚力,那么即使不是所有优势,也会失去最多。
- 需要更多的沟通工作:在服务之间的沟通方面,您需要进行相关的投资。在服务通信之间可能发生很多失败。
- 难以监控整个系统:你有很多碎片可能是一个噩梦来监控。
- 需要时间学习:使用微服务需要学习,这需要时间。
- 复杂性:拥有越来越多的微服务,使整个系统更加复杂,更难以监督整个操作。
“所有这些作品都在四处闲逛。如果你没有非常好的工程流程,那么你最终将会遇到许多根本无法使用的东西。“ - Seippable联合创始人兼首席执行官Avi Cavale “在基于微服务的平台上调试生产问题是一个完全不同的歌剧。如果没有适当的监控,日志记录和跟踪设施, 系统的复杂性就会显着增加。这就像穿过迷宫一样。工程实践和标准化变得至关重要。“ - DanielWeb研发副总裁Daniel Ben-Zvi
- 登录到一个地方很有挑战性。像Loggly,Splunk或Heroku这样的第三方日志聚合服务是非常好的解决方案,但它们确实以非常高的价格出售。根据我的经验,遥测专门集中测井是一个最大的痛苦。您必须考虑每项服务的详细程度。如果不这样做,您最终可能只需支付50-60%的费用来记录下文。 (微软网站可靠性工程师Sonu Kumar)
最大的微软服务挑战和解决方案
在转向微服务时,这些是技术领导者和开发团队可能面临的最大挑战。
- 挑战1:立即切换系统
- 挑战2:拆分系统
- 挑战3:组织支持
- 挑战4:团队
挑战1:一次性切换你的系统
“从单片架构切换到微服务架构并不是你可以同时做到的。如果您有一个单片服务器,那么您可能拥有存储库, 部署任务,监视以及围绕它紧密设置的许多其他内容。改变这一切并非易事。“ - Bruaka Benavides, Inaka的前首席技术官 “如果一家公司从未有过使用微服务的经验,即使是绿色的现场项目也会比他们想象的更难。” - LogMeIn的DevOps工程师Viktor Tusa
✅可能的解决方案
我们当时所做的是保持整体服务器的位置,但任何新的添加都是作为微服务开发的,所以最终事情从原始服务器中消失,直到它最终成为我们最老和最大的微服务。 (Brujo Benavides)
挑战2:分裂系统
如果组件和服务从项目开始就粘在一起,那么隔离组件和服务可能非常具有挑战性。 (Robert Aistleitner)。 您需要定义各个部分之间的交互和流程。 如果您没有以良好的方式定义,您的系统将产生更多问题。 (StyleSage高级开发人员Jose Alvarez) “没有模式; 将系统拆分成微服务有很多不同的规则,但没有人会告诉你如何在你的应用程序中这样做。 没有两个相同的微服务。“ - Recart首席架构师David Papp
✅可能的解决方案
“将单片系统拆分为微服务的唯一方法是首先检查单片系统,看看它最痛”的地方。 系统的这些部分应该被取出并转换成微服务。“ - Andras Fincza,Emarsys的工程副总裁
如果您没有适当监控,您将无法看到系统的工作方式。监控所有部件的工作情况以及他们正在做的事情。如果您 监控系统,则可以轻松检测并解决问题。 (何塞阿尔瓦雷斯)
逐步增加,逐个模块是拆分单片系统的最佳方式。如果你想一次做所有事情,你肯定会失败。
监控工具提示:
- New Relic
- Datadog
- Influxdb
- Grafana
挑战3:组织买入
“获得组织支持可能是最难的部分。” - Steven McCord,ICX Media的创始人兼首席技术官
这不是技术决定。您需要明确说明微服务架构的好处,以说服您的公司重新分配资源。这是一个漫长而乏味的过程,直到组织接受这样的变更,组织越大,决策就越长。
✅可能的解决方案
说服您的组织切换到微服务的最佳方法是将系统中一个非关键部分转换为微服务。通过这种方式,您可以使用真实的工作微服务来展示其优势。
挑战4:团队
“最大的挑战发生在团队本身,因为它需要不同的思考。” - Shippable联合创始人兼首席执行官Avi Cavale
开发人员必须花费更多时间来了解什么是端到端场景。 他们需要熟悉技术,可能需要转换思维模式,这需要时间。
对于那些在一个可以进行端到端测试的世界工作的人来说,这是不舒服的,现在你突然将它分解成小块。 这更像是一种文化变革。 (Avi Cavale)
✅可能的解决方案
从非常小的东西开始,您可以从中获益并选择一些不是您应用程序关键部分的东西。 获得一个小团队,将应用程序的这一部分转换为微服务。 证明它实际上更好,并逐步扩展到组织(Avi Cavale)。
避免造成这些错误
“避免立即将整个系统切换到微服务。” - Emarsys工程副总裁Andras Fincza
“我想你可能犯的最大错误就是你没有对微服务架构的变化所带来的影响进行概述。在实际开始实施新方法之前,您必须包含 许多移动部件。“ - 用户工程副总裁Robert Aistleitner “使用巨石,可以轻松更改内部界面;您只需重新编译代码并运行测试。使用微服务,您的API必须是黄金。这是依赖, 你不一定了解你的所有客户。在没有API的情况下进行未来验证将在未来产生许多令人头疼的问题。此外,请确保您有 一个分布式跟踪系统。“ - SimilarWeb研发副总裁Daniel Ben-Zvi “避免在没有弄清平台和依赖关系的情况下尝试切换到微服务。此外,相信微服务是好的,因为每个微服务都可以用 不同的语言编写,这是一种不好的做法。“ - Viktor Tusa,LogMeIn的DevOps工程师 “处理数据至关重要。搞砸数据很容易,但很难恢复。数据迁移应该采取更多步骤。“ - Andras Fincza,Emarsys的 工程副总裁 “在微服务之间共享数据是一个很大的禁忌。如果两个服务正在操纵相同的数据,您将开始遇到一致性问题并消除所 有权的歧义。“ - Daniel Ben-Zvi和Varun Villait “将应用程序分解成太多太小的部分,或者强迫将系统转换为不应该是微服务的微服务 - 只是因为炒作”. - Csaba Kassai,Doctusoft的首席开发人员
切换到微服务架构的最佳实践
在微服务之间创建隔离使它们能够根据您的需要进行更改。这通常需要在几个层面进行隔离:
- 运行时进程:这是最明显的,也是通常很快采用的进程。在你有一个过程之前,现在你有很多。这里的主要成本是采用某种形式的分布式计算,这很难做到。这可能会导致您采用容器化,事件体系结构,各种http管理方法,服务网格和断路器。
- 团队/文化。分离团队,给你自主权,意味着你划分人与人之间的沟通。这往往导致知识孤岛和工作重复(选择性与资源效率选择的结合)。推荐阅读:由Peter Naur编写的理论构建
- 数据。采用分布式计算方法(如微服务)的最大影响在于它对数据的影响。您已经以某种形式对数据进行了分区,因此您需要在系统级别重新集成它以给人一种“系统”的印象。这为您提供了一些有关扩展的有趣潜在好处,但它还需要更多想到的不是简单的单片数据架构方法。 (大卫道森)
您应该选择哪种技术来获得特定的微服务?
这是不同意见开始发生碰撞的地方......
一方面,人们认为使用什么技术和编程语言无关紧要。
“几乎所有问题都可以通过任何技术解决。其他人花费太多时间寻找合适的技术,但如果你以反复的方式做到这一点, 你就有时间思考并看到它在行动中。通过这种方式,可以减轻糟糕的决策。“ - Andras Fincza,Emarsys的工程副总裁 “大多数大型现代语言(Python,Java,C#,Node / JavaScript)同样快速且可扩展。从这个角度来看,语言并不重要 。每种语言都有其优点和缺点;大多数时候,语言选择是基于个人偏好而不是技术论据。“ - Viktor Tusa,LogMeIn的DevOps工程师
花费大量时间选择最好的技术是不值得的,因为差异很小。
“选择技术的重要性太高估了。如果运行成本很重要,那么它可以接受,但对我们而言并不重要。“ - Andras Fincza,Emarsys工程副总裁 “如果它是一个绿地项目,那么我使用我的程序员最了解的语言。如果它不是一个绿地项目,那么我在 系统中的业务实体使用客户端覆盖范围最广的语言。“ - Viktor Tusa,LogMeIn的DevOps工程师 “微服务的优点是它封装在一个微服务中,只要你提供一个外部微服务接口来与那个东西交谈。 只要他们有接口,我就不在乎。“ - Steven McCord,ICX Media的创始人兼首席技术官
选择合适的技术不仅仅是一个技术问题,也是一个招聘决策。
如果您选择具有10种不同编程语言的微服务架构,则需要确保您的团队能够处理该问题。
“我不建议混合太多的编程语言,因为招聘人员变得更加困难。此外,程序员的上下文切换会降低开发速度。 “ - Usernap工程副总裁Robert Aistleitner “你必须有意识地选择你想要建立什么类型的开发团队。如果你想使用许多不同的编程语言,你需要建立 一个能够使用和学习不同编程语言的动态团队。“ - Steven McCord,ICX Media的创始人兼首席技术官
一些技术建议:
“我强烈建议在Google Cloud Platform中使用AppEngine等托管服务。从肩膀上承担很多负担。此外, 在选择语言/技术/框架时,为特定的微服务用例选择合适的一个是非常重要的,不要仅仅因为你熟悉它 而强迫某些东西。“ - Csaba Kassai,Doctusoft的首席开发人员
来自Brujo Benavides
另一方面,一些技术领导者很乐意推荐一些技术,这些技术非常适合服务于特定角色的微服务。
在为微服务选择技术时,建议考虑:
- 可维护性
- 容错
- 可扩展性
- 建筑成本
- 易于部署
Brujo团队用于微服务的框架/技术的一些示例:
- Scrapy for web crawling
- Celery + RabbitMQ来传达微服务
- 机器学习部分中的NLTK + Tensorflow(以及其他一些)
- AWS服务
推荐阅读:基于云的应用程序的技术选择案例研究
选择适当技术的过程
为您的微服务选择编程语言/技术时,您需要考虑许多事项。
其中一个最重要的事情是了解您的开发人员具备哪些能力以及语言/技术背后的支持(工具,社区......)。根据我 的经验,公司倾向于根据其开发人员的能力选择一种编程语言。“ - Csaba Kassai,Doctusoft的首席开发人员 “使用拥有大量支持(资源和活跃社区)的技术。我会推荐Ruby和JavaScript,因为你得到了很多支持,如果出现 任何问题,很多人都会帮助你。我想只要你确保有很多人使用它,承担一种语言应该不是问题。因为在这种情况下, 如果您的团队不具备这些知识,您可以依赖外部资源。“ - 工业首席执行官Varun Villait “另一个因素可能是存在一种可用于加速项目的语言库。你理想的语言选择可能没有你可能需要自己发明的某些 东西的库,这可能是另一个时间流失。显然,容错和可扩展性等问题也应该是一个重要因素。如果你不得不在几 个月后从头开始重新编写一些东西,因为最初的选择无法扩展,那么你最好先咬一口。我认为这一切都取决于 具体的团队情况以及他们愿意做出的投资。“ - Greg Neiheisel,天文学家联合创始人兼首席技术官
这是EMARSYS的流程:
在Emarsys,如果他们想要应用新的编程语言,开发人员需要提供真实的逻辑原因并咨询主要开发人员。团队聚集在一起讨论技术的优缺点。
他们总是使用不同的技术创建一个尖峰解决方案。这使他们可以尝试给定技术的边界,看看它是否可以应用于给定的微服务。这非常适合揭示技术的局限性。
“建议使用您的团队已经熟悉的语言。通过这种方式,他们可以更舒适地工作,并且进步更快。“ - Andras Fincza,Emarsys的工程副总裁
这是他们在SIMILARWEB的做法:
作为一家大型数据和分析公司,我们应对非常大规模的挑战,这会增加选择错误技术的风险和影响。单个线程框架(如NodeJS)虽然适用于网络绑定服务,但在处理实时密集型数据处理时无法扩展。
工程师通过平衡战术和战略需求以及查看技术和组织约束来确定使用哪种技术。我们处于快速原型设计阶段吗?该服务是否处理大量数据?我们是否想要在我们的堆栈中添加新技术,因为我们相信它的生态系统还是我们使用已经掌握的现有技术?我们想要实验吗?我们能找到对此充满热情的工程师吗?我们是否愿意长期致力于这项技术?技术生态系统是一个主要因素。我们希望与开源社区合作,而不是重新使用和贡献现有框架,而不是重新发明轮子。
一般来说,我们不希望传播得太薄;否则,你没有获得专业知识。
定义明确的指导方针,甚至是清单,可以帮助促进健康的决策过程,并缩小可能的技术选项,以选择最适合您的团队和产品的选项。
DAVID DAWSON对选择技术的建议:
- 从数据架构的角度来看,您需要能够提供数据的东西,您可以轻松地在服务之间通过网络同步到一致的可用状态。有各种各样的方法,这是我在微服务部署中实际寻找的方法。因此,您可以观察实现这些模式的各种框架和技术(这是Kafka,Spring Data Flow,Akka和朋友等技术人员所在的地方)。
- 一旦我们确定了这些模式和方法,您就可以使用您可用的资源进行网格化。如果您已经决定使用大量反应式编程的数据流方法,并且您已经拥有Java开发人员,那么选择Spring,Spring Cloud Data Flow和Kafka是有意义的,并且可能部署到某种形式的Cloud Foundry(如果你可以得到它!)。
如果您需要大量较重的数据转换,请引入Spark或Kafka Streams来帮助解决这个问题。如果你有JavaScript开发人员,那就没有意义了。相反,你会在JS运行时(clojurescript等)上采用一些函数式语言,再次使用一些类似的反应式集成技术(Kafka肯定会在这个空间中制造波浪)并从中获取它。
关键要点:
- 不要强调选择完美的技术。 采用迭代的实验方法代替。
- 每个微服务架构都是独一无二的; 选定的技术应与系统的需求保持一致。
- 请记住,太多不同的技术使招聘更加复杂。
结论
在切换到微服务架构时,存在许多挑战。
在开始将系统转换为微服务之前,请确保有真正的理由说明为什么要这样做。了解优势和劣势可能会有很大帮助。您不必遵循最新的炒作,而是首先考虑系统的独特功能,而只是改变最容易受到伤害的系统部分。不建议从头开始使用微服务架构,因为很难明确定义微服务的边界。
如果您决定切换到微服务,请采用增量方法并取出系统中一个非常关键的小部分,以了解其工作原理。这也是获得组织支持以创建更多微服务的好方法。
没有一种最佳方法可以为微服务选择完美的技术。每项与技术相关的决策都会受到您团队当前知识以及公司未来招聘计划的影响。在某些情况下,为微服务选择技术更多是招聘决策,而且取决于您希望在未来构建哪种类型的开发人员团队。
为了缩小可能的技术,来自Emarsys的Andras Fincza,来自SimilarWeb的Daniel Ben-Zvi和David Dawson提供了一个可以轻松应用的简短流程。
渴望更多?
4软件团队的有效知识转移方法
招聘开发人员是一个挑战吗?以下是科技公司如何应对它
优先考虑软件开发需求的科学方法
- 294 次浏览
【微服务架构】API版本控制最佳实践介绍

变化是不可避免的,增长是一件好事。当您的API已经超出了最初的意图和容量时,就该考虑下一个版本了。
无论下一次迭代是一个完整的版本升级还是一个功能扩展,重要的是要考虑你如何让你的开发人员知道它的优缺点。与传统的软件版本控制相比,API版本控制可能会对下游使用它的产品产生复杂的影响。
较大的版本调整通常意味着API代码库中一个重要的里程碑。它声明了API使用和实现需求的重大变化。不需要改变现有调用的特性添加是产品有机增长的一部分,不需要同样的考虑。
一旦你开始删除一些东西,或者戏剧性地改变现有的东西,就该考虑另一个版本了。通常,这些新版本会变成全新的产品。尽管它们共享一个共同的祖先,但是遗留api的新版本在实现时需要仔细考虑。
传统的API版本控制:n+1
可以保证新版本的服务更改包括:删除操作、重命名操作、移位数据类型或顺序的操作参数更改,以及数据类型的复杂结构更改。
版本增量还可以指示API使用需求的重大变化。它还可以对API提供的底层资源进行彻底的更改。在任何一种情况下,依赖于API实现核心功能的产品和平台都可能需要进行代码重构来适应。
这可能会耗费大量的时间和资源,因此对于多个涉众来说,使用一种合理且文档记录良好的URI版本控制方法是至关重要的。版本控制在团队中可能是一个有争议的话题,通常第一个问题就是是否使用它。
一个URI来统治所有的URI
一种思想是专注于一个不变的URI,只有一组消费标准。如果改变了API结构、改变了资源或修改了参数集,那么产品将使用相同的URI重新启动。这就把重构代码的责任推给了下游的开发人员。
蒂姆•伯纳斯-李(Tim Berners-Lee)的名字被这种方法的支持者提到。他经常说:“一个酷的URI是不会改变的。”这句话的本意是要说明新兴的互联网依靠网页内的超链接才能生存下去。互联网络在当时是一系列信息节点。
不过,世界已经改变了,我们使用的是一个相互连接的矩阵,它由功能强大、资源丰富的web服务组成。一旦服务变得广泛,早期的方法类似于软件版本号。但是,独立软件对下游的影响与相互依赖的web服务大不相同。
IBM在他们自己的“Web服务最佳实践”中解决了这个问题:
正确处理API版本控制一直是分布式系统开发者面临的最困难的问题之一。人们提出了各种各样的方案,从CORBA(公共对象请求代理体系结构)采用的自由放任的方法,到DCOM中使用的更严格的方案(分布式组件对象模型)。随着Web服务的出现,您可以利用一些新特性来帮助缓解问题,但残酷的事实是,版本控制还没有内置到Web服务体系结构中。”
什么是“最佳实践”已经随着时间的推移而演变,并由供应商对其自己产品的选择决定,而不一定来自任何外部管理机构。因此,当涉及到选择版本控制方法时,有各种各样的实践。
在向后兼容
另一个要考虑的问题是向后兼容性。对于许多web资源API的提供者来说,这是首要考虑的问题。维护一个资源密集型API的多个版本会严重消耗工程团队的时间和精力。它还会给迁移到更现代体系结构的服务带来长期的稳定性问题。
对许多人来说,引入一个实质上改变API的新版本实际上就是启动一个全新的服务。将其作为一个新产品,使用新的文档、服务水平协议、层访问更改等,可能会产生重大的业务影响。许多白板上都写满了数字,争论一个变化是工程选择还是商业转变。
一旦做出了引入新版本的决定,查看一下已建立的提供商,看看是否有经过测试的解决方案,这是很有帮助的。
更广的进行版本控制的例子
我们可以从已建立的web API提供商的版本控制实践中学到什么?谷歌从一开始就直截了当地肯定了编号版本化:“网络API应该使用语义版本化。“没有多少回旋余地。它们也有一个类似的平面系统。版本指示器使用v. major . min . patch形式。
Twilio在URL中使用了时间戳,而不是版本号。Salesforce选择vXX.X在URL的中间。Facebook会将版本预先添加到端点路径中。版本实际上是可选的,未指定的版本请求将被路由到最旧的可用版本。
请注意vX.X提供的粒度,vX.X通常用于开发,而不一定用于生产。首先检查文档,但是在生产代码中选择序号引用是一个好主意。
DevOps人员可能熟悉用于版本定义的UDDI和WDSL方法。HTTP解决方案要流行得多,但是有对这种方法的支持。它需要通过XML交换进行版本请求以获得正确的版本。
像微软、IBM和Oracle这样的巨石公司在他们的一些文档中都引用了这种方法。尽管,HTTP版本标识在许多部门和产品中被接受。
约会网络Badoo选择了持续的版本控制,即添加特性而端点保持不变。旧客户端可以使用旧字段,新客户端可以使用添加的字段。API请求是事务性的,发出一个特性请求调用并返回可用选项列表。特性检查可以作为一种状态请求。
API stylebook在版本控制方面还有其他一些方法可供探索。没有一套成文的规范,公司继续探索不同的选择。
带有Accept标头的版本
路径参数的一种常见替代方法是头交换。它们可以更详细地描述预期的响应,并且通常包含在HTTP请求中。使用特定于资源的头方法允许包含其他参数(如缓存、压缩和内容协商)。
API提供者通常在其响应中传达资源标准和限制,因此开发人员无论如何都需要检查header交换。除了响应代码之外,常见的报头响应还包括速率限制、特定的错误消息、基于时间的数据等等。
聪明的离群值使用MIME类型包含版本指示符。API提供者在其后端注册这些MIME类型,然后用户包括Accept头和Content-type头。IETF在RFC4627中合法化了这种方法。虽然这是可行的,但是选择这种方法的开发人员最终将不可避免地向管理类型解释他们的选择,这些管理类型会说:“但是它不能在HTML表单上工作,那么为什么要这样做呢?”
Accept: application/pre.company.app-v1+json Content-Type: application/pre.company.app-v1+json
关于实施的争论是深刻的,并将继续下去。因此,开发人员和供应商将不得不根据他们的具体需求做出选择。通常,最常见的方法是URI参数和头标准的组合。api接受带有参数的URI请求,然后返回带有适当响应代码的有效负载,以及(希望如此)响应头中的详细元数据。
工程师们会在公司的欢乐时光里,兴高采烈地大声讨论什么是合适的回应码。但是,这里有一些有用的负面反应,它们冗长到足以对下游有所帮助。
400: BAD_REQUEST: ApiVersionUnspecified: An API version is required, but was not specified
400: BAD_REQUEST: InvalidApiVersion: An API version was specified, but it is invalid
400: BAD_REQUEST: AmbiguousApiVersion: An API version was specified multiple times with different values
400, 405: BAD_REQUEST, METHOD_NOT_ALLOWED: UnsupportedApiVersion: The specified API version is not supported
301: MOVED_PERMANENTLY: movedPermanently: This request and future requests for the same operation have to be sent to the URL specified in the Location header of this response instead of to the URL to which this request was sent
410: GONE: deleted: The request failed because the resource associated with the request has been deleted
299: OK: Warning: "Deprecated API"
业务动机将指导版本选择
在某些方面,版本控制的技术方面是最容易解决的。真正的争论归结为产品需求、业务关注点和未来计划。就工程支持、后端资源和简单带宽而言,支持一个API的多个版本的需求可能非常高。
另外,要想做得好,新版本需要丰富的文档来成功地转换。由于对快速发展的公司来说,最新的文档往往没有什么优先级,因此它可能会以新旧文档的混搭而告终。糟糕的文档会导致时间和金钱上的巨大损失。
这里的主要要点是版本控制是一个多方面的对话。这不仅仅是一个技术问题。下游影响和遗留成本可能是巨大的,为了有效增长,应该对整个过程进行仔细考虑。
原文:https://nordicapis.com/introduction-to-api-versioning-best-practices/
本文:http://jiagoushi.pro/node/1208
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群[11107777]
- 69 次浏览
【微服务架构】BPMN和微服务编排,流程语言,引擎和永恒模式(第1部分)
我们正在构建Zeebe作为下一代工作流引擎,用于新兴用例,例如微服务编排用例,这些用例可能需要引擎每秒处理数十万(或数百万)个新工作流实例。
为此,我们使用的图形建模标准已经存在了近15年:BPMN(业务流程模型和表示法)。
尽管BPMN是经过实战考验的ISO标准,但很可能你们中的许多人从未亲自动手或者甚至没有听说过它。
或者更糟糕的是,您已经听说过BPMN,但您已将其作为一种仅在单片或SOA世界中相关的遗留技术编写。
上个月,我们从黑客新闻评论者那里得到了这句话(我们保证他们不是Zeebe团队的隐身成员):
“BPMN是我们IMO领域最被低估的技术。”
我们不能同意,并且本着这种精神,我们将发布一个关于BPMN和微服务编排的两部分博客系列 - 更具体地说,为什么BPMN非常适合工作流程中的新兴用例世界。
在第1部分中,我们将:
- 提供BPMN的快速介绍
- 说明为什么过去蓬勃发展的成熟标准也能在未来蓬勃发展
- 查看BPMN支持的常见业务流程模式
- 讨论Zeebe中BPMN的当前状态和未来计划
在第2部分中,我们将:
- 深入了解BPMN的图形模型(以及定义工作流程的其他方法)
- 看一下使用图形模型而不是基于代码的模型大大简化工作流程定义的示例
关于BPMN的简短入门
BPMN是一种广泛使用的建模标准,用于定义和执行业务流程。 2004年首次发布(随着2011年的现代BPMN 2.0规范 - 这是Zeebe使用的),BPMN自2013年以来一直是ISO标准。
BPMN用于定义图形模型和所谓的执行语义。换句话说,可视模型存储为XML文件,该文件可以直接在引擎上执行,该引擎保持运行工作流实例的持久状态。
举一个例子,下面的模型用这个XML表示。
重要的是要说BPMN不涉及代码生成而且没有转换! XML本身就是源代码。 BPMN只关注流程 - 您可以将正常代码用于解决方案的所有其他方面。
这是微服务编排的关键点,外部工作人员在您的工作流程中执行任务。 当与正确的引擎结合使用时,BPMN可以轻松地将工作流中的任务连接到微服务,并且这样做的方式不会违反松散耦合和服务独立性的原则。
扩展上面的示例订单工作流程,我们可以构建3个不同的微服务来处理付款,库存和运输。 工作流引擎负责在流程的正确位置将工作发送到正确的服务。
最后,有BPMN的成熟度。 BPMN非常受欢迎且已经成熟,并且已经证明了它在大型和小型公司的许多工作流程自动化项目中的价值。出于这个原因,市场上已经有很多经验丰富的BPMN人才以及教程和书籍,使新手很容易学习这个标准。
一切听起来都不错。但BPMN可以处理我喜欢的新架构吗?
我们暂时进入隐喻模式。
虽然有关汽车历史的具体细节尚未引起争议,但很多人都赞扬卡尔·奔驰在1886年建造了第一辆汽车并将其带到德国曼海姆附近。在过去130年左右的时间里,汽车 - 在这种情况下,字面意思是“引擎” - 已经发展了很多。
然而,“流动”仍然是相当静止的。帮助我们从A点安全地到达B点的道路,标志和法律仍然遵循许多几十年前实施的相同模式。这可能最终会改变(参见:Hyperloop,无人机),但重点是给定的“流动模式”可以支持许多重要的“引擎”进步。
因此,当我们评估像BPMN这样完善的标准时,我们必须区分“流量要求”和“引擎要求”。
BPMN已经围绕流动提出了许多模式,这些模式是永恒的。按顺序或并行执行一系列活动可以应用于更传统的BPMN用例,例如人工任务管理以及在AWS中调用无服务器功能。等待打印和签名文档的传入副本在模式方面与在事件流体系结构中关联多个消息具有可比性。
确实改变的是吞吐量(工作流实例的数量)以及性能和可伸缩性要求。这些问题可以通过执行相同流语言的新引擎来解决 - 这就是我们使用Zeebe所采用的方法,Zeebe可以扩展到每秒数百万个新的工作流实例。
另一种方法是构建一个新引擎,并在您使用时发明一种新的流语言。但是使用新的流语言,你不可避免地会花时间解决BPMN中已经解决的问题。而且您可能无法有效地或以所有利益相关者都能轻易理解的方式解决这些问题。
我们将在本系列的第2部分详细阐述这个想法,我们将比较BPMN中表达的复杂的现实工作流模式与Amazon States Language。
现在,让我们回顾一下常见工作流模式的示例,以帮助说明为什么我们非常有信心BPMN是微服务编排和其他下一代工作流用例的正确流程语言。
在BPMN中定义业务流程模式
我们不打算在这篇文章中提供完整的BPMN教程。我们的目标是让您了解您可以使用的构建块的子集,并提供一些如何使用它们的示例。
如果您愿意,这不应该阻止您深入了解BPMN。我们上面提到的Camunda的BPMN教程是一个开始的好地方,我们的BPMN参考也是如此。
您也可以开始使用我们的Zeebe特定的图形建模工具,我们将在本系列的第2部分中详细介绍图形模型。
现在进入模式。
顺序流程,决策和并行处理
BPMN的核心是序列流,它定义了工作流中的步骤的执行顺序。
正如您可能想象的那样,将工作流限制为一个简单的一个接一个的任务序列会使许多现实世界的业务逻辑无法解决。除了任务(工作单元)之外,BPMN工作流还包括网关(引导流程)和事件(代表工作流可以响应或通知其他系统的事件)。
BPMN提供用于基于关联数据(专用网关)将工作流实例路由到单个序列流的构造,以及用于需要并行执行的一个或多个序列流(并行网关)的构造。
消息与超时的关联
BPMN的接收任务是标准为消息关联提供支持的一种方式,这是一种非常强大的功能,可以将等待的工作流实例向前移动,或者只有在消息可以正确匹配(“关联”)时才能执行其他操作 正在使用公共标识符等待它的特定工作流实例。
这是一项特别难以从头开始构建然后大规模支持的功能 - 并且BPMN与正确的引擎相结合,您可以开箱即用。
BPMN对发送和接收消息的支持意味着模型可以与消息驱动的体系结构无缝集成,这种体系结构在微服务领域尤为常见。
工作流程可以通过某些类型的消息启动; 它们还可以发出要由下游系统使用的消息。 或者工作流实例可以基于接收的消息结束。 例如,可以响应于与特定订单相关联的传入订单取消消息来终止正在进行的工作流实例 - 诸如电子商务公司中的订单履行过程。
正如您将看到的那样(我们将经常重复),可以轻松组合不同元素,这是BPMN如此强大的原因。
例如,接收任务可以与Timer事件组合,以便如果所需消息未在4小时内到达,则任务“超时”并且工作流实例遵循不同的路径。
多条消息的相关性
将一条消息与工作流实例相关联是有帮助的,但如果需要关联两个,三个或十个,该怎么办?
BPMN也涵盖了这种模式。 通过将接收任务与并行网关相结合,您可以等待两个或多个消息同步并合并其有效负载,然后再向前移动工作流实例。
让我们更进一步,将此模式与超时结合起来。
同样,下图中添加的计时器和子流程只是一个例子,说明了如何组合不同的BPMN元素来表达复杂的流程; 当然,某些组合在某种程度上没有逻辑意义,对于如何连接BPMN符号以定义工作流程基本没有限制。
等待任意数量的消息
在某些情况下,我们可能不知道需要等待多少消息将与给定的工作流实例相关联。
考虑一个示例,在我们继续工作流程之前,我们需要为订单中的每个项目接收itemAvailable消息。 每个订单中的项目数量可能差别很大,我们可以使用BPMN的多实例活动在我们的模型中对其进行说明。
错误处理
您可能需要在工作流程中设计某些“业务逻辑错误”。 在这里,我们不讨论服务因技术原因而失败的错误,而是由于我们可以提前计划的业务问题导致工作流无法进行的情况。 BPMN的错误边界事件是针对这种特殊情况而设计的。
在此示例中,我们尝试向客户的信用卡收费。 如果由于客户帐户中的资金不足而导致费用下降,我们会通知客户该问题。
我们可以继续......
谈到BPMN支持的模式,我们只是略微划清界限。 我们希望您能够了解仅使用这些BPMN符号可以表达多少个不同的用例。
我们在这些示例中展示的内容并不是说明性的,也不会告诉您应该如何使用BPMN。 相反,我们的目标是激发您对可以构建的模型类型的想象。
Zeebe的BPMN状态
希望您在这篇文章中了解BPMN在定义和执行复杂工作流程时的可能性。
但真正的问题是:我们在Zeebe中支持多少BPMN?
从长远来看,Zeebe将支持所有对工作流自动化有意义的符号,就像我们使用Camunda BPMN工作流引擎一样。
目前,Zeebe 0.11(最新版本)支持:
当然,这是一个有限的范围,到目前为止,我们主要关注Zeebe的引擎 - 即确保Zeebe具有处理高吞吐量用例的可扩展性和性能。
但是本季度我们一直在大力投资Zeebe的BPMN支持,我们将在不久的将来支持消息关联:
随着我们在2018年准备生产Zeebe,我们计划增加对更多符号的支持,例如:
- 计时器,
- 范围(子流程)和
- 并行执行
在2019年,我们将根据用户反馈以及我们对Zeebe将要解决的用例的了解来扩展符号支持。
我们处于BPMN系列第1部分的末尾。 我们在这篇文章中只提到了BPMN的一个非常重要的方面:模型可以用图形方式定义,然后由引擎直接执行。
因此,我们将很快回到第2部分,我们将在BPMN中了解图形模型的诸多优势,特别是与为业务流程用例构建的其他流语言相比时。 我们还将解决那些对图形模型有负面经验的开发人员的担忧。
如果您对此帖有任何问题或意见,我们很乐意听取您的意见。
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 588 次浏览
【微服务架构】Consul概述
Consul概述
作为JHipster Registry的替代品,您可以选择使用来自Hashicorp的数据中心管理解决方案Consul。 与Eureka相比,它具有许多优点:
- 在多节点集群中操作比Eureka中更容易。
- 它有利于可用性的一致性,因此可以更快地传播集群状态的变化。
- Consul服务发现可以通过其DNS接口或HTTP API与现有应用程序进行简单的互操作。
架构图
入门
要开始开发依赖Consul注册表的应用程序,您可以在docker容器中启动Consul实例:
- 运行docker-compose -f src/main/docker/consul.yml up 以在开发模式下启动Consul服务器。然后,可以在Docker主机的端口8500上使用Consul,因此如果它在您的机器上运行,则应该在http://127.0.0.1:8500/。
您还可以使用Docker Compose子生成器为多个启用了consul的应用程序生成docker配置。
Consul的应用程序配置
如果您在生成JHipster微服务或网关应用程序时选择了Consul选项,它们将自动配置为从Consul的Key / Value存储中检索其配置。
可以使用http:// localhost:8500 / v1 / kv /或其REST API提供的UI来修改密钥/值(K / V)存储。但是,通过这种方式进行的更改是临时的,并且将在Consul服务器/集群关闭时丢失。因此,为了帮助您轻松地与Key / Value商店进行交互并将配置作为简单的YAML文件进行管理,JHipster团队开发了一个小工具:consul-config-loader。从consul.yml docker-compose文件启动Consul时会自动配置consul-config-loader,但它也可以作为独立工具运行。它可以以两种模式运行:
- 开发模式,来自central-server-config目录的YAML文件自动加载到Consul中。此外,对此目录的任何更改都将立即与Consul同步。
- 一个prod模式,它使用Git2Consul来设置Git存储库中包含的YAML文件,作为Key / Value存储的配置源。
请注意,与JHipster Registry一样,您的配置文件需要命名为appname-profile.yml,其中appname和profile对应于您要配置的服务的应用程序名称和配置文件。例如,在consulapp-prod.yml文件中添加属性将仅为名为consulapp的应用程序设置这些属性,这些应用程序以prod配置文件开头。此外,将为所有应用程序设置application.yml中定义的属性。
原文:https://www.jhipster.tech/consul/
本文:https://pub.intelligentx.net/consul-overview
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 72 次浏览
【微服务架构】IBM 教程 :微服务简介
微服务简介
更小,更快,更强:从头开始构建更好的云应用程序
在整个2014年和2015年,微服务成为热门的新流行词,迅速取代了云计算。本教程将向您介绍微服务的历史以及构建微服务架构的意义。
Netflix流媒体:普及微服务的诞生
无论你是否听说过微服务,我相信你已经听说过Netflix了。感谢Netflix在创建和发布用于管理云基础架构的软件方面的成功,我甚至愿意打赌您已经听说过Netflix开源软件(NOSS) - 这是为Netflix数字娱乐流媒体帝国提供动力的软件。
从2009年左右开始 - 完全由API驱动,并将我们作为微服务所知的最初浪潮 - Netflix完全重新定义其应用程序开发和运营模型。当时,该公司受到行业旁观者的嘲笑:“你们疯了!”或“这可能适用于Netflix,但其他任何人都无法做到这一点。”快进到2013年,当时大部分情绪都变为“我们正在使用微服务。”超过525,000个微服务的谷歌搜索结果表明,这个概念肯定既有效又强大。
但什么是微服务?什么是基于微服务的架构?图1显示了旅行预订服务的微服务的概念视图。图中七个瓦片中的每一个代表一个单独的微服务。它们被安排来显示哪些微服务可以与其他微服务交互,为内部和外部应用程序提供必要的功能。服务的不同垂直高度表示它们如何以不同的量相互使用。在本文中,我将介绍微服务的基础,以便您了解如何表示自己的基于微服务的体系结构。
图1.概念化的微服务
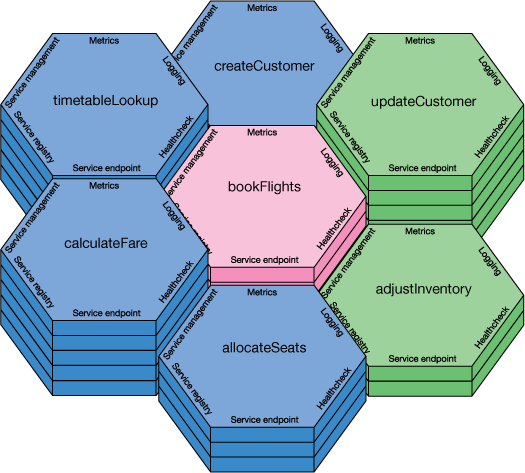
有关微服务开始的深入解释,请阅读Martin Fowler的优秀博客文章。我将在这里尝试捕获的是该帖子的精髓,它在当今环境中的应用,以及如何到达那里。
在一次会议上,前Netflix的Adrian Cockcroft将微服务定义为“细粒度的SOA(面向服务的架构)”。您不需要非常熟悉SOA(十多年前创造的架构风格),只需要在首字母缩略词中使用的术语。理想情况下,从第一天开始就构建整个服务架构。在微服务中,这些服务中的每一项都有一个单独的目的,没有副作用,使您能够以更少的整体专用工程师覆盖更大的规模。
为了定义微服务和相关的架构,我正在调整和修改用于描述现代运动员的“更大,更快,更强”的短语:更小,更快,更强(见图2)。从本质上讲,微服务是许多较小的架构组件,无论是独立还是整体,都可以快速构建和交付。
图2.微服务:更小,更快,更强
较小
微服务意味着不再是巨石。 Monolith很大,很笨重,速度慢,效率低,就像图3中的Grim Monolith一样。我们正在从一个拥有2GB WAR文件的世界(是的,只是WAR文件 - 而不是应用程序服务器或操作系统组件)转向世界 由许多500MB的服务组成,包含整个应用程序,服务器和必要的操作系统组件。
图3.一个严峻的巨石

从大型机到客户端/服务器架构的迁移是一个很大的步骤,也是许多公司和开发人员都在努力解决的问题。 从基于Web的核心应用程序服务器到SOA采用的最新迁移也是类似的问题。 过去几年应用服务器中包含的许多组件都适用于微服务; 但是,它们仍然包含在多GB的安装二进制文件中。 例如,图4显示了使用WebSphere®ApplicationServer和Java™Enterprise Edition组件部署的传统Web应用程序体系结构的体系结构。
图4.标准WebSphere Application Server应用程序体系结构
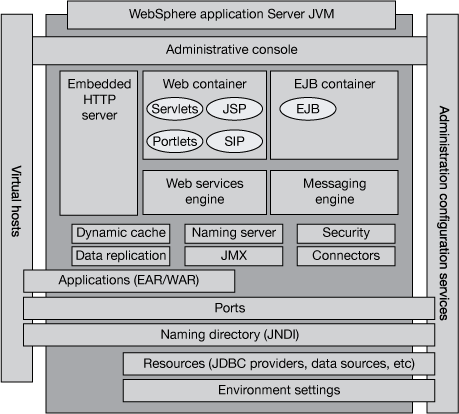
微服务是与所有交互组件集成的一种练习,它更松散地耦合。 微服务的整个想法变得即插即用。 我将在Stronger部分更多地讨论这个问题,但基本上一个基于微服务的系统大规模采用了霰弹枪方法,以维护和保护更多的小组件而不是更少的大组件。 您可以删除单点故障并在任何地方分发这些故障点。
失败的建筑只能用较小的碎片来完成。 如果你为失败建立一个巨石,你会花太多时间专注于每个边缘情况的低效率。 如果构建单个服务实例以进行故障,则其他服务实例将在消费者发出请求时接管。
图5中的图表是使用微服务的实现的一个示例。
图5.视频流应用程序的概念路由示例
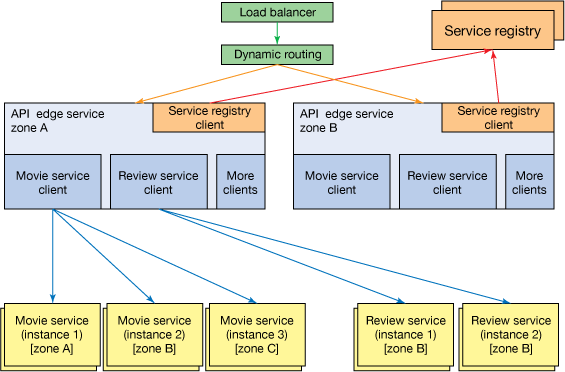
在图5中,每个单独的盒子都是独立维护的,可以自行调整,知道它所在的位置,并知道从何处获取所需的信息。并非每个微服务架构都需要此图中的每个组件,但它们确实有帮助!
比较图4和图5,您可以看到类似应用程序的部署方式的差异。在图4中,所有内容都部署到垂直扩展系统上的单个进程。当需要更多吞吐量时,整个服务器堆栈会一次又一次地被标记出来。每个服务器都在自己的进程内运行。在图4的Web服务引擎或EJB容器中获得更多吞吐量的唯一方法是将整个服务器JVM扩展到集群环境中的新实例。但是,这也会创建另一个Web容器,另一个嵌入式HTTP服务器,另一个消息传递引擎等,无论这些组件是否需要扩展。
与图4的刻度类型相比,图5具有可独立缩放的组件。我将介绍各个组件以及它们如何在Faster部分中扩展,但现在关注每个组件和服务的分布式特性。与图4中的示例应用程序(需要完全高度可用的Web应用程序服务器堆栈以提供可用性)不同,这些组件本质上是分布式的,只提供单一的,集中的功能,通常使用与其他组件不同的技术。此结构使应用程序体系结构能够更快地发展,并包含更新的技术以及更新的版本,而与其他组件无关。
总而言之,较小的开发,操作,维护和交互更好。
快点
与云一起出现的另一个流行语是DevOps。 DevOps运动使开发人员能够在交付管道中控制更多代码,不断集成并实现更高的可见性。 DevOps的主要原理,如图6中顺时针顺序所示,是观察,定位,决定和行动。
图6. DevOps的原理
有什么比更快地交付小件更好,对吧?您无法每两周向单个应用程序服务器实例提供更新,但在同一时间范围内,您绝对可以为许多其他服务所使用的单个服务提供更新。当您构建新的临时环境,通过管道移动项目以及交付到生产环境时,较小的组件会产生较少的开销。
别误会我的意思。仍然可以使用整体进行持续交付和集成。我已经看到它发生了。然而,那时你是杂耍的巨石,而不是大理石。从掉落大理石中恢复比从掉落大石更容易恢复。
与DevOps相关的开发周期非常适合微服务。您的目标是缩短开发周期,不断增加功能,而不是更长的开发周期,从而立即构建完整的整体愿景。这种称为敏捷的开发方法是DevOps成功的基本实践。无论您选择迭代还是增量开发,微服务,DevOps文化和敏捷规划的组合使您能够在过去几年中计划第一个瀑布周期时快速构建整个基础架构。
更快的另一方面涉及执行。微服务建立在这样一种观念之上:如果你需要更快,只需要投入更多的资源。经理的梦想!通过构建可独立扩展的每个服务,您可以允许组件之间的交互,以利用资源池而不是单个组件接口。
回到上一个示例,在图5中,您可以看到Service Registry服务器和客户端。此功能在基于微服务的应用程序中至关重要。在此示例中,边缘服务包含Movie Service和Review Service引用。基于负载,这些服务以不同的速率扩展;因此,你不能再以相同的规模管理它们。
随着Movie Services规模的扩大,Service Registry会自动了解创建的新服务实例。当边缘服务尝试处理请求时,它会调用Service Registry并获取它所依赖的所有服务的客户端引用。 Movie Service客户端引用更可能是最近创建的新引用,而以前使用的旧服务实例可以返回。此Service Registry功能允许您的微服务真正充当“众多之一”,在组件之间具有松散耦合的依赖性,但是在需要时获得更多组件副本的高度可靠性。
图7显示了图5中视频流应用程序的相同概念架构,并为Movie Service添加了扩展的微服务。
图7.视频流应用程序的概念性缩放示例
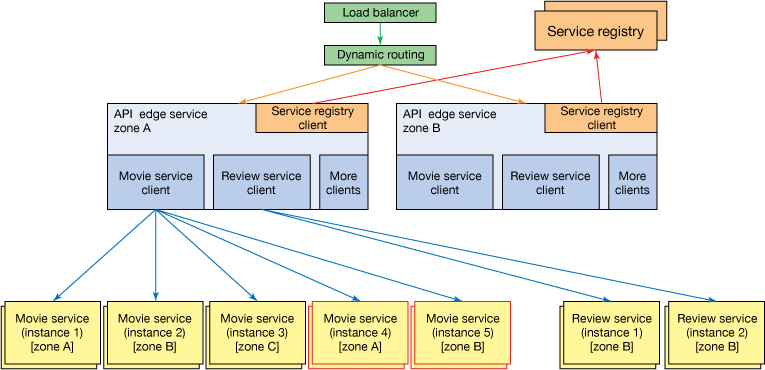
使用能够自我感知新实例的系统,根据需要进行有效扩展。不,这不是天网。这就是使基于微服务架构的应用程序更强大的原因。
更强
并非所有系统都是长寿的。它们在需要时创建,并在不再用于某个目的时被删除。正如我之前提到的,这通过在整个系统中分发这些点来消除单点故障,因为您知道需要机制来考虑不可用或性能不佳的服务和实例。
牛,不是宠物
使用微服务,部署系统的概念变成了牛,而不是宠物:
- Pets are given names; cattle are given numbers.
- Pets are unique; cattle are often identical.
- Pets are nursed back to health; cattle are simply replaced when ill.
- 从Gavin McCance的CERN数据中心Evolution演示文稿中获取。
这个概念导致创建许多服务,以及许多服务中的一个。我们不再一方面计算服务实例或管理长期实例,而是担心维护状态,存储,系统修改等。不要误解我的意思 - 我们仍然对性能调优和配置非常感兴趣,但现在这些事情在开发周期中更早发生,而不是在分段或生产中。这种方法为我们提供了许多服务,以及每项服务的许多实例。
为了验证这一力量支柱,在其旅程中,Netflix开始利用混乱 - 确切地说是混沌之猴(见图8)。混沌猴是一个云应用程序组件,Netflix用它来引入应用程序操作的系统混乱。
图8.混沌之猴

此功能将通过基础结构并有目的地关闭对生产至关重要的服务和服务实例。为什么Netflix会这样做?它怎么能这样做并存活下来?
首先,为什么。这是一种让您轻松识别快速失败所需的方法。新服务太慢了吗?他们需要更有效地扩展吗?当外部服务提供商关闭时,而不仅仅是内部服务会发生什么?所有这些都需要在微服务架构中加以考虑。
第二,如何。由于我之前提到的霰弹枪方法,Netflix可以生存。这个想法很简单:提供足够的服务实例,99.9999%的请求将成功完成。任何失败的请求都将在重试时起作用。拔下服务实例上的插件,另一个本地插件将取代它。拔下整个服务上的插头,您的系统应该将用户补偿或重新路由到具有该特定服务的其他可用区或区域。如果没有别的可用,用户或请求应该快速失败,而不是等待超时。
Netflix扩展了Chaos Monkey的概念并发布了作为Simian Army的功能(见图9),包括Chaos Monkeys,Janitor Monkeys,Conformity Monkeys和Latency Monkeys--云应用程序组件,它们将特定的混乱引入操作,包括延迟和合规性问题。
图9.猿人军队

正如您所看到的,Netflix(以及其他采用微服务的公司)认为杀死您的应用程序的想法使其变得更强大。
结论
我提到的微服务的主要好处是:
- 它们的小尺寸使开发人员的工作效率最高。
- 很容易理解和测试每项服务。
- 您可以正确处理任何相关服务的故障。
- 它们减少了相关故障的影响。
致谢和图片学分
我要感谢Jonathan Bond的演讲,这让我能够捕捉和定位我的想法并借用一些图像(图1,5,6和7)。
- 59 次浏览
【微服务架构】IBM微服务参考架构
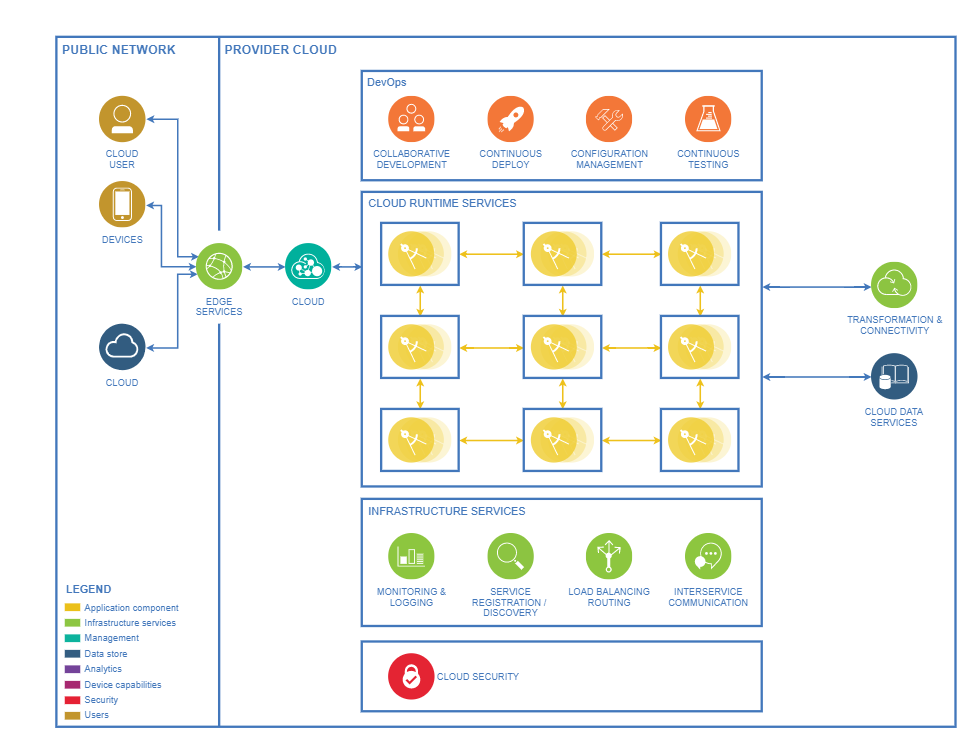
- 56 次浏览
【微服务架构】IBM微服务参考架构
在微服务应用程序架构风格中,应用程序由许多离散的,网络连接的组件组成,称为微服务。微服务架构风格是SOA(面向服务架构)架构风格的演变。使用SOA服务构建的应用程序倾向于专注于技术集成问题,而实现的服务级别通常是细粒度的技术API。相比之下,微服务方法通过更大粒度的业务API实现了明确的业务功能。
这两种方法的最大区别在于它们的部署方式。多年来,应用程序已经以单片方式打包 - 这是一个开发人员团队构建了一个大型应用程序,可以满足业务需求。构建之后,该应用程序随后在应用程序服务器场中多次部署。相比之下,使用微服务架构风格,开发人员可以独立构建和打包几个较小的应用程序,每个应用程序只实现整个应用程序的一部分。
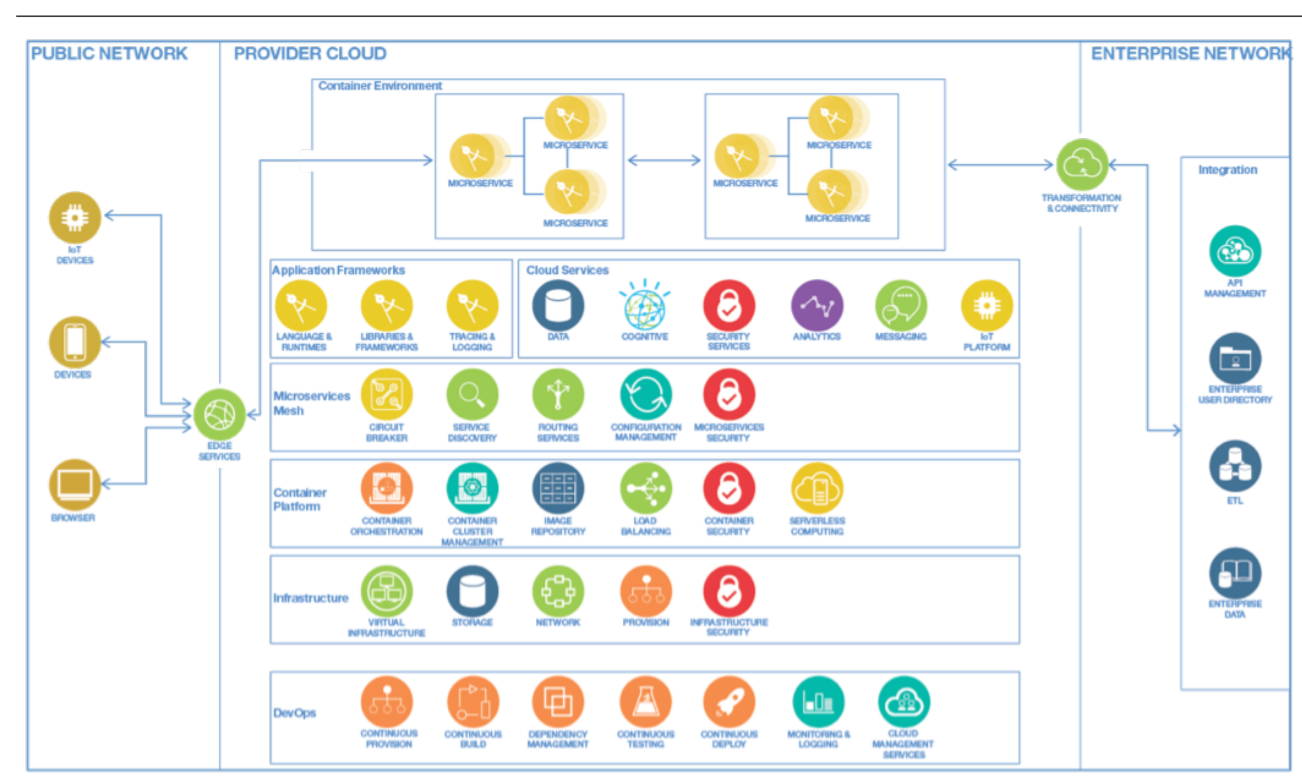
功能要求
-
通过移动和Web应用程序背后的API构建微服务。
-
为微服务提供实现选择,例如Java,Node JS,Swift等。
-
使用API Connect/Gateway将微服务暴露给前端。
-
从iOS或Android中构建的本机移动客户端以及使用AngularJS或ReactJS等技术的Web客户端调用API。
-
使用不同的云工作负载模式部署微服务,例如Docker,Cloud Foundry和基于Apache OpenWhisk的IBM Cloud Functions。
-
使用微服务框架,如Amalgam8或Netflix OSS,实现众所周知的微服务模式,如路由,断路器和自动缩放。
-
通过使用群集,自动扩展,故障转移,断路器,批量头和灾难恢复来创建弹性微服务。
-
为前端应用程序使用关键服务,例如移动分析,推送通知,内容管理等。
-
为基于微服务的应用程序的操作,监视和管理提供指导。
-
通过提供有关如何为微服务和前端构建持续集成/连续交付管道的详细指导,构建端到端DevOps。
-
在微服务环境中使用Garage Method for Cloud,例如测试驱动开发。
- 133 次浏览
【微服务架构】IBM教程:容器和微服务 - 完美的一对
为什么比以往更容易交付更小,更快的应用程序组件
在本系列的第1部分中,我谈到了什么是微服务以及它们与传统构建的系统(monoliths)的区别。第二部分是关于Linux容器的强大功能 - 它们如何彻底改变软件开发并为微服务提供动力以改变整个行业。在基于微服务的应用程序采用基于容器的基础架构时,我将介绍三个对您至关重要的概念:
- 记录和监控
- 零停机持续交付
- 动态服务注册表
我将首先概述容器,容器管理器以及容器与微服务的关系。
容器和微服务:完美的一对
除非您对云技术和云原生应用程序开发完全陌生,否则您可能听说过Linux容器以及过去几年引爆的基于容器的项目。但是如果你还没有,可以将Linux容器视为轻量级虚拟机,可以更灵活地使用,更快地集成,并且更容易分发。领导此项收费的项目之一是Docker。自2012年推出以来,Docker团队(现在的公司)提供了一种通过Linux容器构建,打包和分发云原生应用程序的简单方法。
容器与虚拟机有何不同?每个虚拟机(如下图左侧所示)运行自己的客户机操作系统实例,并包含自己的库和二进制文件。容器(如右图所示)是隔离的,共享底层主机操作系统和库,同时只打包必要的应用程序二进制文件。
“许多行业领导者正在转向基于容器的基础架构,无论是在云端还是在本地,都能获得极大的收益。”
容器作为Linux系统上的最小资源集运行,并且打包的应用程序通常不超过几百兆字节。基于虚拟机的应用程序通常至少要大三到四个数量级(几十千兆字节)。您可以轻松地了解容器如何适应微服务范例,更小更快 - 第1部分中的两个微服务原则。
许多行业领导者正在转向基于容器的基础架构,无论是在云端还是在本地,都可以获得极大的收益。其中一个主要收获是Docker和其他类似的Linux容器技术很容易集成到持续集成和连续交付管道中:根据最近自筹资金的Docker研究,平均而言,Docker用户的软件发送频率是其七倍。像Gilt Groupe这样的公司已经拥抱微服务和集装箱化基础设施,有时每天运送软件100次。能够快速推动代码更改,自动重建最小尺寸的Docker镜像,并从公共代码库管理大量这些部署的图像,从而通过公司的交付管道获得令人印象深刻的速度。
Docker容器的另一个好处是这些打包应用程序的可移植性,称为Docker镜像。 Docker镜像可以跨环境和构建管道无缝移动。例如,BBC新闻(英国广播公司的一个部门)表示,其基于Docker的基础设施的持续集成工作速度提高了60%以上。能够在整个交付流程中移动相同的代码 - 最大限度地减少每个阶段的软件配置需求并在此过程中具有可预测的硬件资源需求 - 通过开发,测试和生产来加快应用程序的速度。公司能够看到效率的提高,因为他们的系统组件在每个Docker镜像中都是模块化的。您无需在每次需要时配置软件。你只需启动一个容器实例,就可以了。
Docker是一个代码的运输容器系统,可以轻松地通过Linux容器进行软件开发和交付。 Docker充当引擎,可以将任何有效负载封装为轻量级,便携式自给自足的容器。这些容器可以使用标准操作进行操作,并且几乎可以在任何硬件平台上运行。
如果您是容器和Docker的新手,请参阅相关链接,了解有关Docker和Linux容器的一般介绍材料。如果您对Docker有经验并希望在云中亲自动手使用Docker,那么IBM Cloud Kubernetes Service是一种企业级容器服务,您可以立即免费使用它。您可以使用自己的私有注册表来存储所有映像,访问支持的中间件的IBM公共注册表,托管交付管道集成以及访问150多种IBM Cloud™服务。您可以比以往更快地在Docker容器中运行应用程序。
更快更小:容器作为软件开发的纳米机器人
您可以开始了解容器对于微服务如此重要的原因 - 作为架构风格的关键支持技术之一 - 您也可以开始看到容器的管理同样重要。正如您在第1部分中所了解的那样,我们不是按比例放大,而是在微服务中扩展。我们只是获得了同一类型的另一个微服务运行时,而不是向微服务运行时添加更多RAM。需要更多内存?得到第三个实例。这种方法适用于每个只有一个容器实例的几个服务,但是对于拥有计算机技能和大家庭知识的人来说,当您远程管理数十台服务器时,它可能会很快失控。
想想您需要多快管理100多个单独的实例。如果你从构成你的应用程序的一些微服务开始 - 比如说五个或六个 - 每个应该至少有三个容器实例支持每个微服务。所以马上,你就是18个集装箱实例。假设您添加了另一个微服务,或者您的应用程序非常成功,您需要为某些服务扩展到5到10个容器实例。在一个美好的一天,你很容易接近超过100个容器实例来管理。
值得庆幸的是,许多开源项目可以满足这一需求。例如,Kubernetes,Apache Mesos和fleet使用基于基础结构的特定于域的语言,可以轻松地从单个控制台或命令行管理数千个容器实例。
这种管理概念紧紧地强化了第1部分中与牛相比较的概念。我们的想法是,我们通过持续集成/持续交付流程部署的所有容器都是不可变的。部署后,您无法更改它们。相反,如果您需要更改或更新,请启动一个新的容器集群,并应用正确的更新并拆除旧的容器。管理1,000头牛比1000只宠物要容易得多。不要误会我的意思:我们都喜欢我们的宠物,但如果您想要快速创新并为您的客户创造价值,并为您的企业带来收益,您就无法花费所有必要的时间来为每只宠物提供所有宠物它需要温柔的爱护。诸如Kubernetes,Apache Mesos以及诸如IBM Cloud Kubernetes服务之类的托管和托管容器服务等项目使您可以集成交付管道和图像注册表,从而快速,轻松地管理基础架构的所有阶段,即高效率的牛群。
另外,应该注意的是,虽然某些容器服务仍然使用虚拟机作为Docker主机,但这些仍应被视为牛。这些虚拟机在资源和集成管理功能方面更加强大,但它们通常被认为是牛,因为它们是由基于容器的工作负载的需求动态管理的。
微服务结构:你最好的打击Whack-A-Mole的借口
到目前为止,我已经讨论了为什么更多的容器更好以及如何大规模处理通用基础设施。现在您对容器开发和与宠物说再见的概念感到满意,您需要开始考虑开发应用程序并将其投入生产。
这让我了解了对基于微服务的应用程序开发至关重要的三个关键要素:
- 记录和监控
- 零停机持续交付
- 动态服务注册表
您想从第一天开始考虑这些功能,但不一定要立即解决。
在讨论这些功能时,您还将了解为什么集成的微服务结构(例如IBM Cloud及其相关服务)使您的微服务架构的管理变得更加容易。
记录和监控
如果您为应用程序和服务提供生产级支持,那么您的第一个问题应该始终是“出现问题时我该怎么办?”请注意,在该问题中甚至没有提示“if”。组件将失败,版本将更改,第三方服务将中断。如何保持一定的理智水平,以及为用户提供所需的正常运行时间?这是一个问题。
正如我之前所说,你希望你的容器是不可变的。出于这个原因,大多数IT组织不提供对容器实例的系统级访问 - 没有SSH,没有控制台,没有任何东西。那么你怎么知道你无法改变的黑匣子里面发生了什么?这是第二个问题。
值得庆幸的是,这个问题已经通过ELK stack-Elasticsearch,LogStash和Kibana的概念得到了解决。
这三个独立的组件提供了聚合日志,通过聚合日志搜索自由格式,以及基于日志和跨平台监控活动创建和共享仪表板的功能。这是一个很棒的功能 - 比登录到个人计算机和运行sed,grep和awk的sysadmin工具箱要好得多。您可以全面访问所有日志的中央存储库。您可以跨系统和微服务关联事件,因为您通常会看到事件和ID在您的系统中传播并遇到类似问题。
您可以通过多种方式与ELK堆栈集成,无论您是在云中运行还是在本地运行:通过托管服务,开源变体以及通常构建在平台即服务产品中的选项(如IBM Cloud Kubernetes)例如,服务。在IBM Cloud上的容器运行时内部,您可以访问功能齐全的多租户ELK堆栈,该堆栈自动从Docker基于容器的运行时接收日志,使您可以查看和搜索这些运行时事件,同时还为您提供预配置的Kibana-基于仪表板的开箱即用。如果您希望开始使用容器,这是一个关键功能,它使IBM Containers成为基于容器的微服务的卓越选择。
零停机持续交付
现在你很自在地知道当天空开始下降时该做什么(当然你希望它永远不会发生),你可以继续快速部署你所有惊人的应用程序更新。考虑到一些大型公司每周部署数十,数百或数千次应用程序,您不得不怀疑停机时间。当然,这些公司每次推出新版本时都没有应用程序中断 - 如果他们这样做了,他们就永远不会失败。
这些公司已经掌握了零停机部署。这可以被称为许多东西,通常有多种颜色,从红黑到蓝绿等等,但它们都回归到同样的原则:即使通过丰富的更新,您的应用程序始终可用,无论如何,因为计划停机造成的网站中断对您或您的用户不利。
现在使用第1部分中描述的整体结构,避免计划停机对于每个参与者而言都是危险,耗时,昂贵且耗费精力。需要大量资源的多个镜像图像是非常难以管理的,导致深夜,在一个假设的“非工作时间”窗口,当大量的出汗完成同时使新版本和旧版本下降 - 更不用说计算如果需要回滚或者在直接负责的团队控制范围之外出现问题,该如何处理旧版本。
借助微服务和基于容器的应用程序,即使没有完全删除,这些担忧也会被最小化,尤其是当今IBM Cloud上提供的一些关键服务。通过将组件分解为更小的组件,您可以在对整个系统产生最小影响的情况下部署它们,同时在特定时间保持更多组件以防止中断。较小的团队可以更有效地管理更多应用程序,因为部署的每个版本都可以自动监控维护其正常运行时间,从而降低人工注意力和计算资源的成本。
动态服务注册表
本部分的最后一个主题是动态服务注册表的概念。本主题包括您可能已经知道的服务发现或服务代理的概念。这两个概念无论如何都不尽相同,但它们足够接近这一方法。
既然您将创建数千个容器实例来支持所有应用程序中的微服务,那么应用程序中的其他组件将如何理解正在发生的事情?他们如何知道他们可以使用哪些其他微服务来进行服务呼叫?他们将如何回应对他们的服务电话?
服务发现和服务代理之间的区别取决于您是想自己进行搜索还是让其他人为您处理。作为类比,假设您需要送货服务。您是否希望从单个提供商(例如美国邮政服务(USPS))或多服务清算中心(如Staples)查询服务。
例如,如果我想运送一个包裹,我可以去USPS网站,为我要找的邮局输入几个参数,找回选项列表,选择一个,然后去那里运送我的包。这是服务发现的概念:我使用一个众所周知的可用服务端点注册表,这些服务端点在服务联机并脱机时更新。通过REST API,调用应用程序可以查询服务发现服务,以确定特定服务调用可用的服务类型和数量,直至该请求服务的特定版本。
如果我不想成为我选择运送包装的地方的人 - 我只想说,“把这个包裹拿到地址标签上的内容” - 我可以把它带到Staples。然后Staples根据我提供的所有信息为我的包装选择最具成本效益的运输选项。我正在把这个包带到一个知名的服务提供商那里,让它为我处理我的包的路由。这是服务代理的概念:您调用一个众所周知的端点,并根据预先建立的规则或元数据将该调用自动转发到提供对服务请求的实际响应的支持服务。
优先考虑服务发现优于服务代理,反之亦然,但实际上归结为偏好或实施经验/要求。一些开源服务发现产品,如etcd和Consul,提供分布式服务注册表,您可以使用它们注册,标记和检测所有可用的服务实例。甚至还有像Registrator这样的很酷的项目,只要创建Docker容器,它就会自动将您的服务注册到其中一个端点。
一些比较流行的服务代理项目支持以下关键参数:从长远来看,服务代理方法需要更少的网络跃点才能获得最终的支持服务。 Netflix Hystrix项目是最大和最受欢迎的服务代理项目之一。 Hystrix是一个基于Java™技术的库,它超越了简单的服务代理,但在服务代理库中提供了许多服务质量改进。
显然,这两种模式对于自动管理服务实例并使其成为可用微服务基础架构的一部分非常重要。 IBM Cloud将很快拥有自己的多租户服务发现服务(如果您在阅读本文时尚未拥有它) - 无需管理服务发现服务,这可能是少数几项。想象一下,自动注册所有容器实例,无论是手动启动它们,推送它们通过IBM Cloud的Delivery Pipeline,还是与Jenkins等内部部署管道集成。
结论
您已经在这里看到容器如何加速推动云原生应用程序开发。与以往相比,更小,更快的应用程序组件可以更快,更轻松地交付,具有比以往更多的内置管理功能。在托管服务(例如IBM Cloud Kubernetes Service)上部署容器以及所有支持的微服务功能(包括日志记录和监视,主动部署和服务发现),可以轻松地将下一步从现有的整体块中移除到云。
我们正朝着更智能的模块化系统发展,这些系统从头到尾更加自动化,集成度更高。这些将按照自己的进度发展,自我意识到基础设施中可用的内容,让它知道什么不是,并在需要改变时告知它。所有这些功能和更多功能将在本系列的一些即将发布的系列文章中介绍。
原文 :https://developer.ibm.com/tutorials/cl-ibm-cloud-microservices-in-action-part-2-trs/
- 29 次浏览
【微服务架构】Kafka vs Moskitto-哪种工具更适合微服务之间的通信?
近年来,微服务架构越来越流行。Docker和Kubernetes等编排工具使创建和维护此类应用程序变得非常简单。可以说,这些工具甚至正在推动微服务架构。

微服务之间的通信
不幸的是,这样的架构,除了许多优点之外,也有一些挑战!其中之一就是在微服务之间找到一种良好的通信方式。
如果您遇到这样的问题,您肯定听说过三种解决方案:REST API、MQTT或Kafka。信不信由你,但REST API在这个用例中是不可能的。所以我们只剩下两个解决方案:MQTT和Kafka。
两者都是消息传递代理,它们有不同的协议和服务于不同的目的,所以让我们来比较一下这两者。
完美的消息传递代理
让我们从对微服务来说最重要的事情开始。
微服务应该有持久的数据存储。他们应该能够接受大量的流量和大量的数据集。此外,它们还应该能够将流量分成独立的逻辑部分,例如,主题。最后,微服务应该具有非常高的可靠性和事件交付能力。
考虑到这些要求,让我们来比较一下Kafka和莫斯基托
Kafka:
Kafka最初是由LinkedIn员工在2011年创建的,当时考虑到了他们的信息系统。它后来在Apache许可证上发布。Kafka持久化事件,这意味着消息在收到时立即写入文件系统。
它能够扩展服务而不必担心事件的重复处理。Kafka通过添加更多的分区来扩展,这样来自每个分区的消息可以并行处理,从而使该工具更容易和高度可伸缩。这是因为,从一开始,它就是为大系统开发的。它的规模比其他类似的“有状态”消息代理更好。
Kafka可以轻松处理高速数据摄取。除此之外,这些库是用最流行的语言编写的。它有一些非常有趣的框架,看看这个基于Ruby的框架-Karafka。
不幸的是,Kafka要想正常工作就得靠Zookeeper 了。
Mosquitto:
让我们看看mosquito,另一个用于微服务间通信的工具。
Mosquitto 是最流行的解决方案之一。它是为物联网项目创建的轻量级协议。它基于发布/订阅模型。消息代理独立于其他应用程序或库。
Mosquitto是在EPL/END下授权的,这意味着它是开源的,也是Eclipse基金会的一部分,这对许多项目来说是一个重要因素。Mosquitto有多种语言的多个库,所以可以肯定地说,它是非常通用的,这意味着开发人员可以很容易地根据项目进行调整。
回答:
Kafka更适合微服务。它具有持久性存储,因此可以从一开始就重放来自特定主题的事件,从而引入事件源模式。
原文:https://naturaily.com/blog/kafka-mosquitto-microservices
本文:http://jiagoushi.pro/node/1101
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 38 次浏览
【微服务架构】Kubernetes微型服务(Spring)
部署显示古董计算设备目录的店面购物应用程序。 客户可以浏览目录并从中进行购买。 该应用程序是一个云原生微服务应用程序,基于Kubernetes的IBM Cloud™容器服务构建。 使用DevOps工具实现自动持续集成和持续部署。

流程
步骤1
Kubernetes集群中的Ingress控制器(IBM Cloud Kubernetes服务或IBM Cloud Private)接收来自用户的请求,并将其转发到Web Backend for Frontend(BFF)pod。 Web BFF pod中的容器处理请求并发送响应,呈现Web应用程序主页。
第2步
用户通过单击主页上的链接来浏览目录。
第3步
浏览目录的请求被发送到Web BFF,后者使用Kubernetes专用网络上的kube-dns向后端目录微服务发出HTTP请求。
第4步
目录微服务从按需填充的内存中Elasticsearch数据库中获取当前目录数据,并通过Web BFF将该数据发送给用户。
第5步
用户通过单击Web浏览器中的“登录”链接并输入登录凭据来登录。
第6步
Ingress控制器将登录请求作为OAuth请求发送到Web BFF和身份验证微服务。
第7步
身份验证微服务调用客户微服务,使用用户凭据验证用户名和密码,这些凭据存储在CouchDB数据库中。成功登录后,将生成OAuth令牌并将其返回到请求的浏览器会话。
第8步
经过身份验证的用户通过单击项目详细信息页面上的“购买”按钮来下订单。 Ingress控制器将交易请求转发给Web BFF,后者调用订单微服务来完成购买交易。
第9步
订单存储在MariaDB数据库和订单微服务中。经过身份验证的用户通过单击“配置文件”选项卡来访问订单。
https://github.com/ibm-cloud-architecture/refarch-cloudnative-kubernete…
https://www.ibm.com/cloud/garage/tutorials/microservices-app-on-kuberne…
https://www.ibm.com/cloud/garage/files/microservices-with-kubernetes.pdf
https://www.ibm.com/cloud/garage/files/microservices-with-kubernetes-ed…
原文:https://www.ibm.com/cloud/garage/architectures/microservices/microservices-kubernetes
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 60 次浏览
【微服务架构】Medium的微服务架构实践
微服务¹架构的目标是帮助工程团队更快,更安全,更高质量地交付产品。解耦服务允许团队快速迭代,对系统的其余部分影响最小。
在Medium,我们的技术堆栈始于2012年的单片Node.js应用程序。我们已经构建了几个卫星服务,但我们还没有制定一个系统地采用微服务架构的策略。随着系统变得越来越复杂并且团队不断发展,我们在2018年初转向了微服务架构。在这篇文章中,我们希望分享我们有效地做到这一点并避免微服务综合症的经验。
什么是微服务架构?
首先,让我们花一点时间来思考微服务架构是什么,不是什么。 “微服务”是那些过载和混乱的软件工程趋势之一。这就是我们在Medium认为它是什么:
在微服务架构中,多个松散耦合的服务协同工作。每项服务都专注于一个目的,并具有相关行为和数据的高度凝聚力。
该定义包括三个微服务设计原则:
- 单一目的 - 每项服务应专注于一个目的并做得好。
- 松耦合 - 服务彼此知之甚少。对一项服务的更改不应要求更改其他服务。服务之间的通信应仅通过公共服务接口进行。
- 高内聚性 - 每项服务将所有相关行为和数据封装在一起。如果我们需要构建新功能,则所有更改应仅本地化为一个服务。
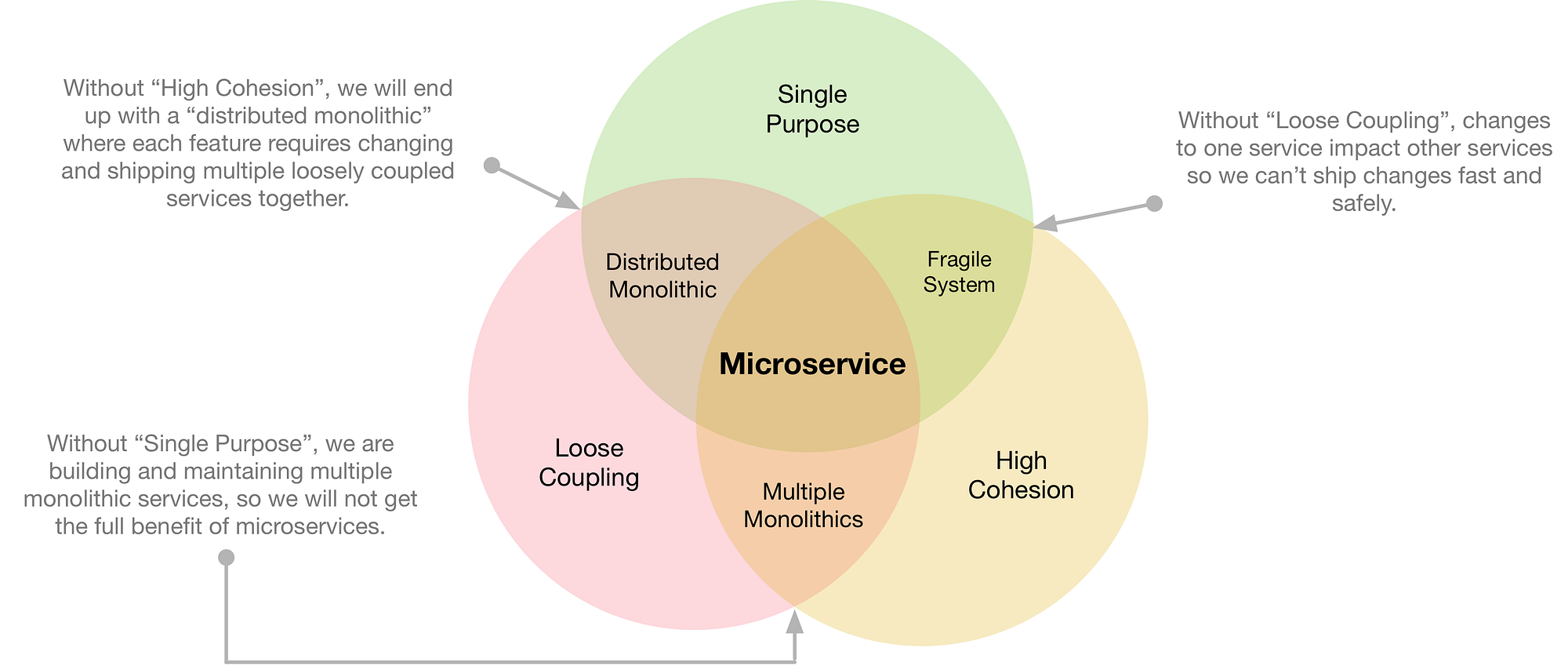
Three Principles of Modeling Microservices
当我们对微服务进行建模时,我们应该遵守所有三个设计原则。这是实现微服务架构全部潜力的唯一途径。错过任何一个都会成为反模式。
没有一个目的,每个微服务最终会做太多事情,成长为多个“单片”服务。我们不会从微服务架构中获得全部好处,我们也会支付运营成本。
如果没有松散耦合,对一个服务的更改会影响其他服务,因此我们无法快速安全地发布更改,这是微服务架构的核心优势。更重要的是,紧密耦合引起的问题可能是灾难性的,例如数据不一致甚至数据丢失。
如果没有高凝聚力,我们将最终得到一个分布式单片系统 - 一组混乱的服务,必须同时进行更改和部署才能构建单一功能。由于多个服务协调的复杂性和成本(有时跨多个团队),分布式单片系统通常比集中式单片系统差得多。
与此同时,了解微服务不是什么很重要:
- 微服务不是具有少量代码行或“微”任务的服务。这种误解来自“微服务”这个名字。微服务架构的目标不是拥有尽可能多的小型服务。只要符合上述三项原则,服务就可能是复杂而实质的。
- 微服务不是一直使用新技术构建的服务。尽管微服务架构允许团队更轻松地测试新技术,但它并不是微服务架构的主要目标。只要团队从分离的服务中受益,就可以使用完全相同的技术堆栈构建新服务。
- 微服务不是必须从头开始构建的服务。如果您已经拥有一个架构良好的单一应用程序,请避免养成从头开始构建每个新服务的习惯。可能有机会直接从单一服务中提取逻辑。同样,上述三个原则应该仍然有效。
为什么现在?
在Medium,我们总是在做出重大产品或工程决策时会问“为什么现在?”这个问题。 “为什么?”是一个显而易见的问题,但它假设我们拥有无限的人,时间和资源,这是一个危险的假设。当你想到“为什么现在?”时,你突然有了更多的限制 - 对当前工作的影响,机会成本,分心的开销等等。这个问题有助于我们更好地优先考虑。
我们现在需要采用微服务的原因是我们的Node.js单片应用程序已经成为多个方面的瓶颈。
首先,最紧迫和最重要的瓶颈是其性能。
某些计算量很大且I / O很重的任务不适合Node.js.我们一直在逐步改进整体应用程序,但事实证明它是无效的。它的低劣性能使我们无法提供更好的产品而不会使已经非常慢的应用程序变慢。
其次,整体应用程序的一个重要且有点紧迫的瓶颈是它会减慢产品开发速度。
由于所有工程师都在单个应用程序中构建功能,因此它们通常紧密耦合。我们无法灵活地改变系统的一部分,因为它也可能影响其他部分。我们也害怕做出重大改变,因为影响太大,有时难以预测。整个应用程序作为一个整体进行部署,因此如果由于一次错误提交导致部署停滞,那么所有其他更改(即使它们完全正常工作)也无法完成。相比之下,微服务架构允许团队更快地发货,学习和迭代。他们可以专注于他们正在构建的功能,这些功能与复杂系统的其余部分分离。更改可以更快地进入生产。他们可以灵活地安全地尝试重大变革。
在我们新的微服务架构中,更改会在一小时内完成生产,工程师不必担心它会如何影响系统的其他部分。该团队还探索了在开发中安全使用生产数据的方法²多年来一直是白日梦。随着我们的工程团队的发展,所有这些都非常重要。
第三,单一应用程序使得难以为特定任务扩展系统或隔离不同类型任务的资源问题。
使用单一的单一应用程序,我们必须扩展和缩小整个系统,以满足更多资源需求的任务,即使这意味着系统过度配置用于其他更简单的任务。为了缓解这些问题,我们对不同类型的请求进行分片,以分离Node.js进程。它们在一定程度上起作用,但不会扩展,因为这些微单一版本的单片服务是紧密耦合的。
最后但同样重要的是,一个重要且即将成为紧迫的瓶颈是它阻止我们尝试新技术。微服务架构的一个主要优点是每个服务都可以使用不同的技术堆栈构建,并与不同的技术集成。这使我们能够选择最适合工作的工具,更重要的是,我们可以快速安全地完成工作。
微服务策略
采用微服务架构并非易事。它可能会出错,实际上会损害工程生产力。在本节中,我们将分享七个在采用早期阶段帮助我们的策略:
- 建立具有明确价值的新服务
- 单片持久存储被认为是有害的
- 解耦“建立服务”和“运行服务”
- 彻底和一致的可观察性
- 并非每项新服务都需要从头开始构建
- 尊重失败因为它们会发生
- 从第一天开始就避免使用“微服务综合症”
- 建立具有明确价值的新服务
有人可能会认为采用新的服务器架构意味着产品开发的长时间停顿以及对所有内容的大量重写。这是错误的做法。我们永远不应该为了建立新的服务而建立新的服务。每次我们建立新服务或采用新技术时,都必须具有明确的产品价值和/或工程价值。
产品价值应以我们可以为用户提供的利益为代表。与在单片Node.js应用程序中构建值相比,需要一项新服务来提供值或使其更快地交付值。工程价值应该使工程团队更好,更快。
如果构建新服务没有产品价值或工程价值,我们将其留在单一的应用程序中。如果十年内Medium仍然有一个支持某些表面的单片Node.js应用程序,那就完全没了问题。从单一应用程序开始实际上有助于我们战略性地对微服务进行建模。
建立具有明确价值的新服务
有人可能会认为采用新的服务器架构意味着产品开发的长时间停顿以及对所有内容的大量重写。这是错误的做法。我们永远不应该为了建立新的服务而建立新的服务。每次我们建立新服务或采用新技术时,都必须具有明确的产品价值和/或工程价值。
产品价值应以我们可以为用户提供的利益为代表。与在单片Node.js应用程序中构建值相比,需要一项新服务来提供值或使其更快地交付值。工程价值应该使工程团队更好,更快。
如果构建新服务没有产品价值或工程价值,我们将其留在单一的应用程序中。如果十年内Medium仍然有一个支持某些表面的单片Node.js应用程序,那就完全没了问题。从单一应用程序开始实际上有助于我们战略性地对微服务进行建模。
单片持久存储被认为是有害的
建模微服务的很大一部分是对其持久数据存储(例如,数据库)进行建模。跨服务共享持久数据存储通常似乎是将微服务集成在一起的最简单方法,然而,它实际上是有害的,我们应该不惜一切代价避免它。这就是原因。
首先,持久数据存储是关于实现细节的。跨服务共享数据存储会将一个服务的实现细节暴露给整个系统。如果该服务更改了数据的格式,或者添加了缓存层,或者切换到不同类型的数据库,则还必须相应地更改许多其他服务。这违反了松散耦合的原则。
其次,持久数据存储不是服务行为,即如何修改,解释和使用数据。如果我们跨服务共享数据存储,则意味着其他服务也必须复制服务行为。这违反了高内聚的原则 - 给定域中的行为泄露给多个服务。如果我们修改一个行为,我们将不得不一起修改所有这些服务。
在微服务架构中,只有一个服务应该负责特定类型的数据。所有其他服务应该通过负责服务的API请求数据,或者保留数据的只读非规范(可能具体化)副本。
这可能听起来很抽象,所以这是一个具体的例子。假设我们正在构建一个新的推荐服务,它需要来自规范帖子表的一些数据,目前在AWS DynamoDB中。我们可以通过两种方式之一为新推荐服务提供发布数据。
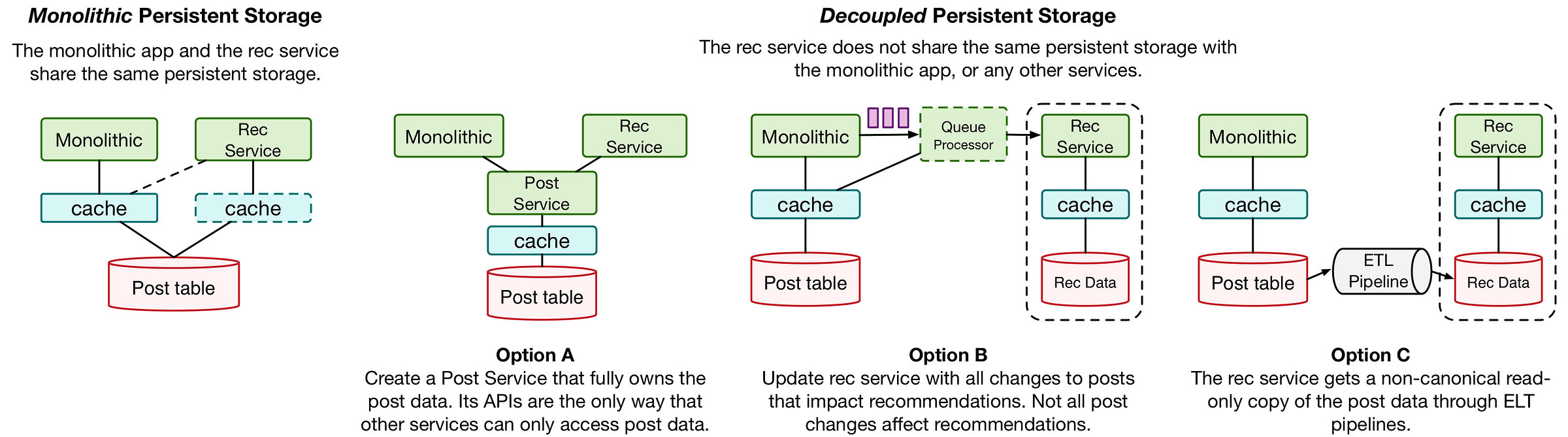
在单片存储模型中,推荐服务可以直接访问单片应用程序所执行的相同持久存储。这是一个坏主意,因为:
缓存可能很棘手。如果推荐服务与单一应用程序共享相同的缓存,我们也必须在推荐服务中复制缓存实现细节;如果推荐服务使用自己的缓存,当单片应用更新帖子数据时,我们将不知道何时使其缓存无效。
如果单片应用程序决定更改为使用RDS而不是DynamoDB来存储帖子数据,我们将不得不重新实现推荐服务中的逻辑以及访问帖子数据的所有其他服务。
单片应用程序具有解释帖子数据的复杂逻辑,例如,如何确定帖子是否应该对给定用户不可见。我们必须在推荐服务中重新实现这些逻辑。一旦整体应用程序更改或添加新逻辑,我们也需要在任何地方进行相同的更改。
即使推荐服务是自己的数据访问模式的错误选项,推荐服务仍然停留在DynamoDB上。
在解耦存储模型中,推荐服务不能直接访问发布数据,也不能直接访问任何其他新服务。发布数据的实现细节仅保留在一个服务中。有不同的方法来实现这一目标。
Option A 理想情况下,应该有一个拥有帖子数据的Post服务,其他服务只能通过Post服务的API访问邮政数据。但是,为所有核心数据模型构建新服务可能是一项昂贵的前期投资。
当人员配置有限时,还有一些更实用的方法。根据数据访问模式,它们实际上可能是更好的方式。
在选项B中,单一应用程序可让推荐服务知道何时更新相关的帖子数据。通常,这不必立即发生,因此我们可以将其卸载到排队系统。
在选项C中,ETL管道生成推荐服务的发布数据的只读副本,以及可能对推荐有用的其他数据。在这两个选项中,推荐服务完全拥有其数据,因此它可以灵活地缓存数据或使用最适合的数据库技术。
解耦“建立服务”和“运行服务”
如果构建微服务很难,那么运行服务往往更难。当运行服务与构建每个服务相结合时,它会减慢工程团队的速度,团队必须不断重新发明这样做。我们希望让每项服务都专注于自己的工作而不用担心如何运行服务的复杂问题,包括网络,通信协议,部署,可观察性等。服务管理应该与每个服务的实现完全分离。
将“构建服务”和“运行服务”分离的策略是使运行服务任务与服务技术无关,并且使自己的意见,以便应用工程师可以完全专注于每个服务自己的业务逻辑。
由于最近在容器化,容器编排,服务网格,应用程序性能监控等方面的技术进步,“运行服务”的解耦变得比以往更容易实现。
网络。网络(例如,服务发现,路由,负载平衡,流量路由等)是运行服务的关键部分。传统方法是为每种平台/语言提供库。它工作但不理想,因为应用程序仍然需要非常繁琐的工作来集成和维护库。通常,应用程序仍然需要单独实现某些逻辑。现代解决方案是在Service Mesh中运行服务。在Medium,我们使用Istio和Envoy作为边车代理。构建服务的应用工程师根本不需要担心网络问题。
通信协议。无论您选择哪种技术堆栈或语言来构建微服务,从一个高效,类型化,跨平台且需要最少开发开销的成熟RPC解决方案开始是非常重要的。支持向后兼容性的RPC解决方案也使部署服务更加安全,即使它们之间存在依赖关系。在Medium,我们选择了gRPC。
一种常见的替代方案是基于HTTP的REST + JSON,它长期以来一直是服务器通信的福音解决方案。但是,尽管该堆栈非常适合浏览器与服务器通信,但它对于服务器到服务器的通信效率很低,尤其是当我们需要发送大量请求时。如果没有自动生成的存根和样板代码,我们将不得不手动实现服务器/客户端代码。可靠的RPC实现不仅仅包装网络客户端。另外,REST是“自以为是”,但总是让每个人都对每个细节都达成一致很困难,例如,这个调用真的是REST,还是只是一个RPC?这是一种资源还是一种操作?等等
部署。拥有一致的方法来构建,测试,打包,部署和管理服务非常重要。所有Medium的微服务都在容器中运行。目前,我们的编排系统是AWS ECS和Kubernetes的混合体,但仅限于Kubernetes。
我们构建了自己的系统来构建,测试,打包和部署服务,称为BBFD。它在一致地跨服务工作和为个人服务提供采用不同技术堆栈的灵活性之间取得平衡。它的工作方式是让每个服务提供基本信息,例如,要监听的端口,构建/测试/启动服务的命令等,BBFD将负责其余的工作。
彻底和一致的可观察性
可观察性包括允许我们了解系统如何工作的过程,约定和工具,以及在不工作时对问题进行分类。可观察性包括日志记录,性能跟踪,指标,仪表板,警报,并且对于微服务架构的成功至关重要。
当我们从单个服务迁移到具有许多服务的分布式系统时,可能会发生两件事:
我们失去了可观察性,因为它变得更难或更容易被忽视。
不同的团队重新发明了轮子,我们最终得到了零碎的可观察性,这实际上是低可观察性,因为很难使用碎片数据连接点或分类任何问题。
从一开始就具有良好且一致的可观察性非常重要,因此我们的DevOps团队提出了一致的可观察性策略,并构建了支持实现这一目标的工具。每项服务都会自动获取详细的DataDog仪表板,警报和日志搜索,这些服务在所有服务中也是一致的。我们还大量使用LightStep来了解系统的性能。
并非每一项新服务都需要从零开始构建
在微服务架构中,每个服务都做一件事并且做得非常好。请注意,它与如何构建服务无关。如果您从单一服务迁移,请记住,如果您可以从单片应用程序中剥离微服务并不总是必须从头开始构建。
在这里,我们采取务实的态度。我们是否应该从头开始构建服务取决于两个因素:(1)Node.js适合该任务的程度如何;(2)在不同的技术堆栈中重新实现的成本是多少。
如果Node.js是一个很好的技术选项并且现有的实现很好,我们将代码从单片应用程序中删除,并用它创建一个微服务。即使采用相同的实现,我们仍将获得微服务架构的所有好处。
我们的单片Node.js单片应用程序的架构使我们可以相对轻松地使用现有实现构建单独的服务。我们将在本文稍后讨论如何正确构建单片。
尊重失败,因为他们会发生
在分布式环境中,更多的东西可能会失败,而且它们会失败。如果处理不当,任务关键型服务的失败可能是灾难性的。我们应该始终考虑如何测试故障并优雅地处理故障。
- 首先,我们应该期待一切都会在某些时候失败。
- 对于RPC调用,需要付出额外的努力来处理故障情况。
- 确保我们在发生故障时具有良好的可观察性(如上所述)。
- 在线提供新服务时始终测试失败。它应该是新服务检查列表的一部分。
- 尽可能构建自动恢复。
从第一天起避免使用微服务综合症
微服务不是灵丹妙药 - 它解决了一些问题,但创造了一些其他问题,我们将其称为“微服务综合症”。如果我们从第一天开始就不去考虑它们,那么事情会变得很快,如果我们以后再照顾它们会花费更多。以下是一些常见症状。
- 建模不良的微服务造成的伤害大于好处,特别是当你有超过几个时。
- 允许太多不同的语言/技术选择,这会增加运营成本并使工程组织分散。
- 将运营服务与构建服务相结合,这大大增加了每项服务的复杂性并减慢了团队的速度。
- 忽略数据建模,最终得到具有单片数据存储的微服务。
- 缺乏可观察性,这使得难以对性能问题或故障进行分类。
- 当遇到问题时,团队倾向于创建新服务而不是修复现有服务,即使后者可能是更好的选择。
- 即使服务松散耦合,缺乏整个系统的整体视图也可能存在问题。
我们应该停止构建单片服务吗?
随着最近的技术创新,采用微服务架构要容易得多。这是否意味着我们都应该停止构建单一服务?
虽然新技术支持得更好,但微服务架构仍然存在高度复杂性和复杂性。对于小型团队来说,单一的应用程序通常仍然是更好的选择。但是,请花些时间来构建单片应用程序,以便以后在系统和团队成长时更容易迁移到微服务架构。
从单一体系结构开始是很好的,但要确保模块化并使用上述三种微服务原则(单一用途,松散耦合和高内聚)来构建它,除了“服务”在同一技术堆栈中实现,一起部署并在同一进程中运行。
在Medium,我们在早期的单片应用程序中做出了一些很好的架构决策。
我们的单片应用程序由组件高度模块化,即使它已经发展成为一个非常复杂的应用程序,包括Web服务器,后端服务和离线事件处理器。脱机事件处理器单独运行,但使用完全相同的代码。这使得将一大块业务逻辑剥离到单独的服务相对容易,只要新服务提供与原始实现相同(高级)的接口即可。
我们的整体应用程序在较低级别封装了数据存储详细信息。每种数据类型(例如,数据库表)具有两层实现:数据层和服务层。
- 数据层处理对一种特定类型数据的CRUD操作。
- 服务层处理一种特定类型数据的高级逻辑,并为系统的其余部分提供公共API。服务不共享它们之间的数据存储。
这有助于我们采用微服务架构,因为一种类型数据的实现细节完全隐藏在代码库的其余部分。创建新服务来处理某些类型的数据相对容易且安全。
单片应用程序还可以帮助我们对微服务进行建模,并使我们能够灵活地专注于系统中最重要的部分,而不是从头开始为所有微服务建模。
结论
单片Node.js应用程序为我们服务了好几年,但它开始减慢我们从运送伟大的项目和快速迭代。我们开始系统地和战略性地采用微服务架构。我们仍处于这一旅程的早期阶段,但我们已经看到了它的优势和潜力 - 它大大提高了开发效率,使我们能够大胆地思考并实现大量的产品改进,并解锁了工程团队以安全地测试新技术。
加入Medium的工程团队是一个激动人心的时刻。如果这听起来很有趣,请查看我们的工作页面 - 在Medium工作。如果您对微服务架构特别感兴趣,您可能需要先了解这两个开头:高级全栈工程师和高级平台工程师。
谢谢阅读。如果您有任何疑问或希望更多地讨论我们如何开始采用微服务架构,请给我们留言。
这篇文章的原始版本发布在Hatch,我们的内部版本的Medium。感谢Kyle Mahan,Eduardo Ramirez,Victor Alor,sachee,Lyra Naeseth,Dan Benson,Bob Corsaro,Julie Russell和Alaina Kafkes对选秀的反馈。
¹在这篇文章中,我们将以两种方式使用“微服务”一词,(1)指微服务架构,(2)指微服务架构中的一项服务。
²在开发中获取生产数据是一把双刃剑。这绝对是值得商榷的,但如果我们能安全地做到这一点,它就会非常强大。需要说明的是,我们不会测试其他用户的数据。工程师只使用自己的帐户。我们非常重视用户的隐私。
原文 :https://medium.engineering/microservice-architecture-at-medium-9c33805eb74f
讨论: 请加入知识星球【首席架构师圈】
- 87 次浏览
【微服务架构】jhipster技术堆栈
在客户端的技术堆栈
单个网页应用程序:
- Angular或 React或Vue
- 使用Twitter Bootstrap进行响应式Web设计
- HTML5 Boilerplate
- 兼容现代浏览器(Chrome,FireFox,Microsoft Edge ......)
- 全面的国际化支持
- 可选的 Sass支持CSS设计
- Spring Websocket支持可选的WebSocket
凭借出色的开发工作流程:
使用NPM轻松安装新的JavaScript库
使用Webpack构建,优化和实时重新加载
使用 Jest 和Protractor进行测试
如果单个网页应用程序不足以满足您的需求,该怎么办?
支持 Thymeleaf模板引擎,在服务器端生成Web页面
服务器端的技术堆栈
A complete Spring application:
- Spring Boot for easy application configuration
- Maven or Gradle configuration for building, testing and running the application
- “development” and “production” profiles (both for Maven and Gradle)
- Spring Security
- Spring MVC REST + Jackson
- Optional WebSocket support with Spring Websocket
- Spring Data JPA + Bean Validation
- Database updates with Liquibase
- Elasticsearch support if you want to have search capabilities on top of your database
- MongoDB and Couchbase support if you’d rather use a document-oriented NoSQL database instead of JPA
- Cassandra support if you’d rather use a column-oriented NoSQL database instead of JPA
- Kafka support if you want to use a publish-subscribe messaging system
微服务的技术堆栈
Microservices are optional, and fully supported:
- HTTP routing using Netflix Zuul or Traefik
- Service discovery using Netflix Eureka or HashiCorp Consul
准备投入生产:
- Monitoring with Metrics and the ELK Stack
- Caching with ehcache (local cache), hazelcast or Infinispan
- Optimized static resources (gzip filter, HTTP cache headers)
- Log management with Logback, configurable at runtime
- Connection pooling with HikariCP for optimum performance
- Builds a standard WAR file or an executable JAR file
- Full Docker and Docker Compose support
- Support for all major cloud providers: AWS, Cloud Foundry, Heroku, Kubernetes, OpenShift, Azure, Docker…
原文:https://www.jhipster.tech/tech-stack/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 23 次浏览
【微服务架构】为故障设计微服务架构
微服务架构可以通过定义明确的服务边界隔离故障。但就像在每个分布式系统中一样,网络、硬件或应用程序级别问题的可能性更高。由于服务依赖关系,任何组件都可能对其消费者暂时不可用。为了最大限度地减少部分中断的影响,我们需要构建可以优雅地响应某些类型的中断的容错服务。
本文基于 RisingStack 的 Node.js 咨询与开发经验,介绍了构建和运行高可用微服务系统的最常用技术和架构模式。
如果您不熟悉本文中的模式,并不一定意味着您做错了什么。建立一个可靠的系统总是需要额外的成本。
更新:本文多次提到 Trace,RisingStack 的 Node.js 监控平台。 2017 年 10 月,Trace 与 Keymetrics 的 APM 解决方案合并。点击这里试一试!
微服务架构的风险
微服务架构将应用程序逻辑转移到服务中,并使用网络层在它们之间进行通信。通过网络而不是内存调用进行通信会给系统带来额外的延迟和复杂性,这需要多个物理和逻辑组件之间的协作。分布式系统的复杂性增加导致特定网络故障的可能性更高。#microservices 允许您实现优雅的服务降级,因为可以将组件设置为单独失败。
与单体架构相比,微服务架构的最大优势之一是团队可以独立设计、开发和部署他们的服务。他们对其服务的生命周期拥有完全的所有权。这也意味着团队无法控制他们的服务依赖关系,因为它更有可能由不同的团队管理。对于微服务架构,我们需要记住,提供者服务可能会因发布、配置和其他更改的中断而暂时不可用,因为它们由其他人控制,并且组件彼此独立移动。
优雅的服务降级
微服务架构的最大优势之一是您可以隔离故障并在组件单独失败时实现优雅的服务降级。例如,在照片共享应用程序中断期间,客户可能无法上传新照片,但他们仍然可以浏览、编辑和共享现有照片。

微服务单独失败(理论上)
在大多数情况下,很难实现这种优雅的服务降级,因为分布式系统中的应用程序相互依赖,您需要应用几种故障转移逻辑(其中一些将在本文后面介绍)来准备 临时故障和中断。
Services depend on each other and fail together without failover logics.
变更管理
谷歌的网站可靠性团队发现,大约 70% 的中断是由实时系统的变化引起的。 当您更改服务中的某些内容时——部署新版本的代码或更改某些配置——总是有可能失败或引入新错误。
在微服务架构中,服务相互依赖。 这就是为什么你应该尽量减少失败并限制它们的负面影响。 要处理变更带来的问题,您可以实施变更管理策略和自动推出。
例如,当您部署新代码或更改某些配置时,您应该逐渐将这些更改应用到您的实例子集,监控它们,甚至在您发现部署对您的关键指标产生负面影响时自动恢复。

Change Management – Rolling Deployment
另一种解决方案可能是您运行两个生产环境。您总是只部署到其中一个,并且只有在验证新版本按预期工作后才将负载均衡器指向新的。这称为蓝绿或红黑部署。
还原代码并不是一件坏事。您不应该将损坏的代码留在生产环境中,然后再考虑问题出在哪里。如有必要,请始终还原您的更改。越早越好。
健康检查和负载均衡
由于故障、部署或自动缩放,实例不断启动、重启和停止。它使它们暂时或永久不可用。为避免出现问题,您的负载均衡器应从路由中跳过不健康的实例,因为它们无法满足客户或子系统的需求。
应用程序实例的健康状况可以通过外部观察来确定。您可以通过重复调用 GET /health 端点或通过自我报告来做到这一点。现代服务发现解决方案不断从实例收集健康信息,并将负载均衡器配置为仅将流量路由到健康组件。
自我修复
自我修复可以帮助恢复应用程序。当应用程序可以执行必要的步骤从损坏状态中恢复时,我们可以谈论自我修复。在大多数情况下,它是由一个外部系统实现的,该系统监视实例的运行状况并在它们长时间处于损坏状态时重新启动它们。在大多数情况下,自我修复非常有用,但是在某些情况下,它可能会通过不断地重新启动应用程序而导致麻烦。当您的应用程序由于过载或数据库连接超时而无法提供积极的健康状态时,可能会发生这种情况。
实施先进的自我修复解决方案,为微妙的情况(如丢失的数据库连接)做好准备可能会很棘手。在这种情况下,您需要向应用程序添加额外的逻辑来处理边缘情况,并让外部系统知道不需要立即重新启动实例。
缓存故障转移
由于网络问题和我们系统的变化,服务通常会失败。然而,由于自我修复和高级负载平衡,这些中断中的大多数都是暂时的,我们应该找到一种解决方案,让我们的服务在这些故障期间正常工作。这就是故障转移缓存可以提供帮助并向我们的应用程序提供必要数据的地方。
故障转移缓存通常使用两个不同的到期日期;较短的表示您在正常情况下可以使用缓存多长时间,较长的表示您可以在故障期间使用缓存的数据多长时间。
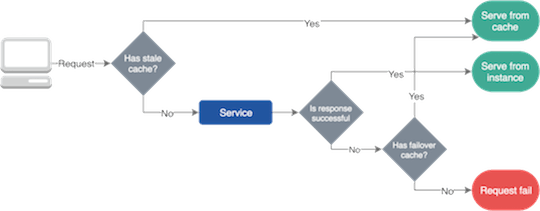
故障转移缓存
值得一提的是,您只能在故障转移缓存为过时数据提供服务时使用总比没有好。
要设置缓存和故障转移缓存,您可以使用 HTTP 中的标准响应标头。
例如,使用 max-age 标头,您可以指定资源被视为新鲜的最长时间。使用 stale-if-error 标头,您可以确定在发生故障时应该从缓存中提供资源多长时间。
现代 CDN 和负载均衡器提供各种缓存和故障转移行为,但您也可以为您的公司创建一个包含标准可靠性解决方案的共享库。
重试逻辑
在某些情况下,我们无法缓存数据或想要对其进行更改,但我们的操作最终会失败。在这些情况下,我们可以重试我们的操作,因为我们可以预期资源会在一段时间后恢复,或者我们的负载均衡器将我们的请求发送到一个健康的实例。
向应用程序和客户端添加重试逻辑时应小心谨慎,因为大量重试会使情况变得更糟,甚至会阻止应用程序恢复。
在分布式系统中,一个微服务系统重试可以触发多个其他请求或重试,并启动级联效果。为了最大限度地减少重试的影响,您应该限制重试的数量并使用指数退避算法不断增加重试之间的延迟,直到达到最大限制。
由于重试是由客户端(浏览器、其他微服务等)发起的,并且客户端在处理请求之前或之后不知道操作失败,因此您应该准备应用程序来处理幂等性。例如,当您重试购买操作时,您不应向客户重复收费。为每个事务使用唯一的幂等键有助于处理重试。
速率限制器和减载器
速率限制是一种定义特定客户或应用程序在一段时间内可以接收或处理多少请求的技术。例如,通过速率限制,您可以过滤掉导致流量峰值的客户和微服务,或者您可以确保您的应用程序不会过载,直到自动缩放无法挽救。
您还可以阻止较低优先级的流量,为关键事务提供足够的资源。

A rate limiter can hold back traffic peaks
一种不同类型的速率限制器称为并发请求限制器。当您拥有不应超过指定时间调用的昂贵端点,而您仍想提供流量时,它会很有用。
车队使用负载卸载器可以确保始终有足够的资源可用于服务关键事务。它为高优先级请求保留一些资源,并且不允许低优先级事务使用所有这些资源。卸载程序根据系统的整个状态做出决策,而不是基于单个用户的请求桶大小。卸载程序可帮助您的系统恢复,因为它们可以在您遇到持续事件时保持核心功能正常工作。
要了解有关速率限制器和负载粉碎器的更多信息,我建议查看 Stripe 的文章。
快速失败和独立
在微服务架构中,我们希望让我们的服务能够快速且独立地失败。为了隔离服务级别的问题,我们可以使用隔板模式。您可以稍后在此博客文章中阅读有关隔板的更多信息。
我们还希望我们的组件快速失败,因为我们不想等待损坏的实例直到它们超时。没有什么比挂起的请求和无响应的 UI 更令人失望的了。这不仅浪费资源,还破坏了用户体验。我们的服务是链式调用的,所以我们应该特别注意在这些延迟总结之前防止挂起操作。
您想到的第一个想法是为每个服务调用应用精细等级超时。这种方法的问题在于,您无法真正知道什么是好的超时值,因为在某些情况下发生网络故障和其他问题时只会影响一两次操作。在这种情况下,如果只有少数几个超时,您可能不想拒绝这些请求。
我们可以说,通过使用超时来实现微服务中的快速失败范例是一种反模式,您应该避免它。您可以应用取决于操作的成功/失败统计信息的断路器模式,而不是超时。
隔板
舱壁在工业中用于将船舶分隔成多个部分,以便在船体破裂时可以将部分密封起来。
隔板的概念可以应用于软件开发以隔离资源。
通过应用舱壁模式,我们可以保护有限的资源不被耗尽。例如,如果我们有两种操作与连接数量有限的同一个数据库实例进行通信,我们可以使用两个连接池而不是 shared on。由于这个客户端 - 资源分离,超时或过度使用池的操作不会导致所有其他操作停止。
泰坦尼克号沉没的主要原因之一是它的舱壁设计失败,水可以通过上面的甲板从舱壁顶部倾泻而下,淹没整个船体。

Bulkheads in Titanic (they didn’t work)
断路器
为了限制操作的持续时间,我们可以使用超时。超时可以防止挂起操作并保持系统响应。然而,在微服务通信中使用静态的、微调的超时是一种反模式,因为我们处于一个高度动态的环境中,几乎不可能提出在每种情况下都能正常工作的正确时间限制。
我们可以使用断路器来处理错误,而不是使用小的和特定于事务的静态超时。断路器以真实世界的电子元件命名,因为它们的行为是相同的。您可以通过断路器保护资源并帮助它们恢复。它们在分布式系统中非常有用,其中重复性故障会导致滚雪球效应并导致整个系统瘫痪。
当特定类型的错误在短时间内多次发生时,断路器会打开。一个打开的断路器会阻止进一步的请求——就像真正的断路器阻止电子流动一样。断路器通常在一定时间后关闭,为底层服务恢复提供足够的空间。
请记住,并非所有错误都应该触发断路器。例如,您可能希望跳过客户端问题,例如具有 4xx 响应代码的请求,但包括 5xx 服务器端故障。一些断路器也可以处于半开状态。在这种状态下,服务发送第一个请求以检查系统可用性,同时让其他请求失败。如果第一个请求成功,它将断路器恢复到关闭状态并让流量流动。否则,它会保持打开状态。

Circuit Breaker
测试失败
您应该针对常见问题不断测试您的系统,以确保您的服务能够承受各种故障。您应该经常测试故障,以使您的团队为事件做好准备。
对于测试,您可以使用识别实例组并随机终止该组中的一个实例的外部服务。有了这个,您可以为单个实例故障做好准备,但您甚至可以关闭整个区域以模拟云提供商中断。
最受欢迎的测试解决方案之一是 Netflix 的 ChaosMonkey 弹性工具。
奥特罗
实施和运行可靠的服务并不容易。这需要您付出很多努力,也需要您的公司花钱。
可靠性有很多层面和方面,因此为您的团队找到最佳解决方案非常重要。您应该将可靠性作为业务决策过程中的一个因素,并为此分配足够的预算和时间。
关键要点
- 动态环境和分布式系统(如微服务)会导致更高的故障几率。
- 服务应该单独失败,实现优雅降级以改善用户体验。
- 70% 的中断是由更改引起的,还原代码并不是一件坏事。
- 快速而独立地失败。团队无法控制他们的服务依赖关系。
- 缓存、隔板、断路器和速率限制器等架构模式和技术有助于构建可靠的微服务。
原文:https://www.progress.com/blogs/rest-api-industry-debate-odata-vs-graphq…
本文:
- 24 次浏览
【微服务架构】什么是微服务? — 全面了解微服务架构

What is Microservices — Edureka
您有没有想过,什么是微服务以及扩展行业如何与它们集成,同时构建应用程序以满足客户的期望?
要了解什么是微服务,您必须了解如何将单体应用程序分解为独立打包和部署的小型微型应用程序。本文将让您清楚了解开发人员如何使用微服务根据需要扩展其应用程序。
在本文中,您将了解以下内容:
- 为什么是微服务?
- 什么是微服务?
- 微服务架构的特点
- 微服务架构的优势
- 设计微服务的最佳实践
- 使用微服务的公司
为什么是微服务?
现在,在我告诉你微服务之前,让我们看看在微服务之前流行的架构,即单体架构。
用外行的话来说,你可以说它类似于一个大容器,其中应用程序的所有软件组件都组装在一起并紧密打包。
列出了单体架构的挑战:
Challenges of Monolithic Architecture — What is Microservices
不灵活——无法使用不同的技术构建单体应用程序
不可靠——即使系统的一个功能不起作用,那么整个系统也不起作用
不可扩展——应用程序无法轻松扩展,因为每次需要更新应用程序时,都必须重新构建整个系统
阻碍持续开发——应用程序的许多功能不能同时构建和部署
开发缓慢——单体应用程序的开发需要大量时间来构建,因为每个特性都必须一个接一个地构建
不适合复杂应用程序——复杂应用程序的特性具有紧密耦合的依赖关系
上述挑战是导致微服务发展的主要原因。
什么是微服务?
微服务,又名微服务架构,是一种架构风格,它将应用程序构建为围绕业务领域建模的小型自治服务的集合。
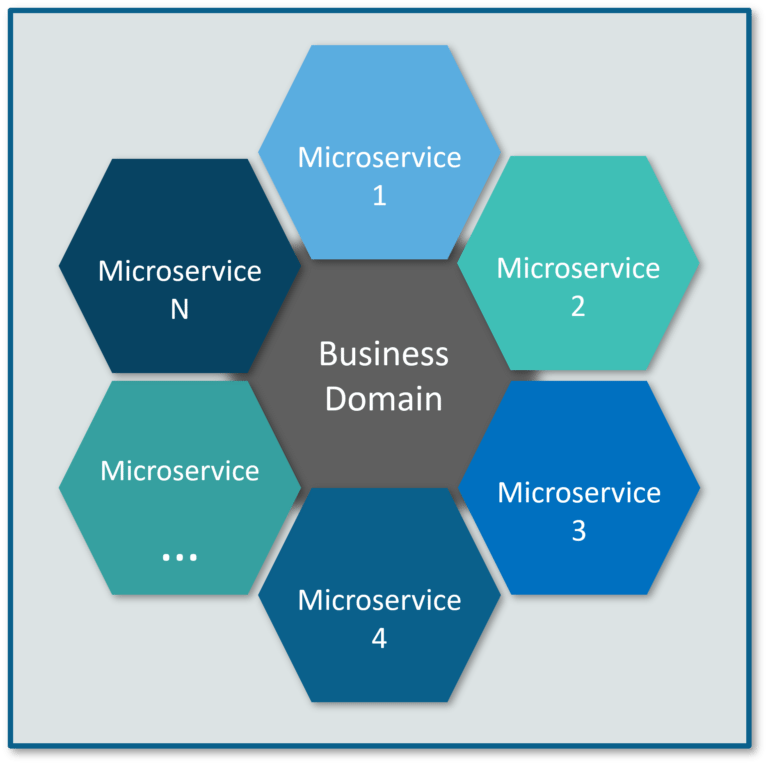
Microservices Representation —What Is Microservices
在微服务架构中,每个服务都是自包含的,并且实现了单一的业务能力。
传统架构与微服务的区别
将电子商务应用程序视为一个用例,以了解它们之间的区别。
我们在上图中观察到的主要区别在于,所有功能最初都在共享单个数据库的单个实例下。 但是,对于微服务,每个特性都被分配了一个不同的微服务,处理它们自己的数据,并执行不同的功能。
现在,让我们通过查看其架构来更多地了解微服务。 参考下图:
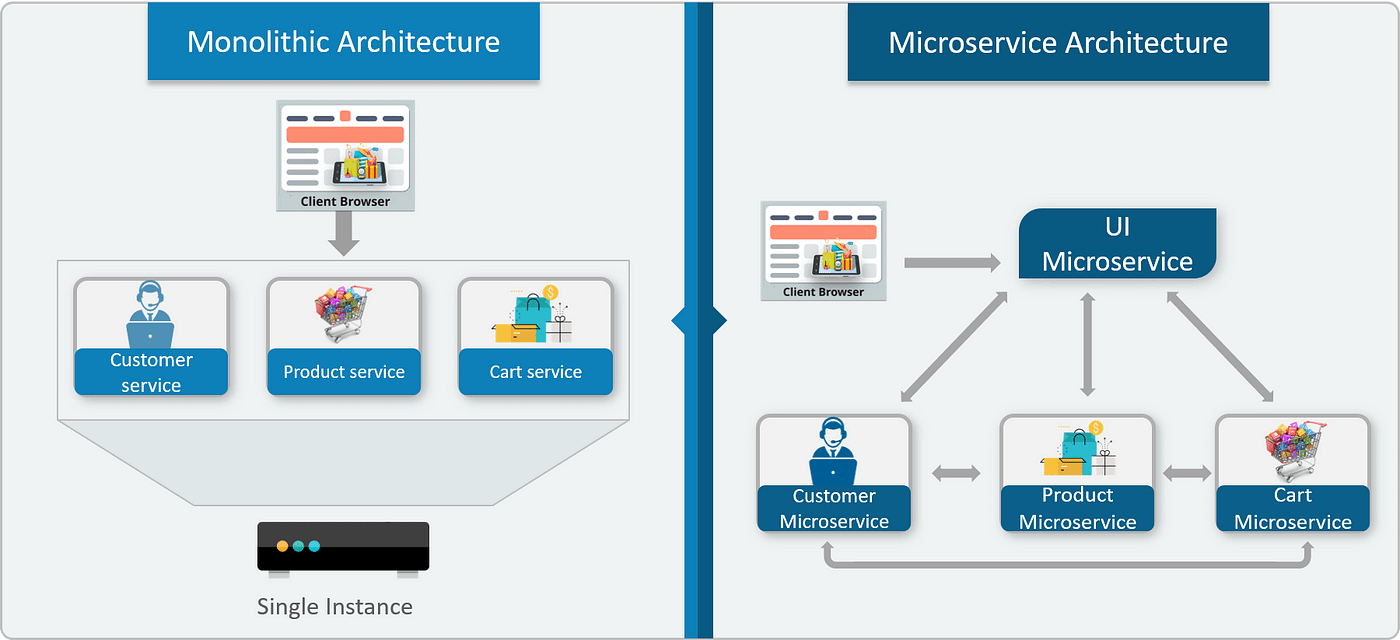
Differences Between Monolithic Architecture and Microservices - What is Microservices
微服务架构
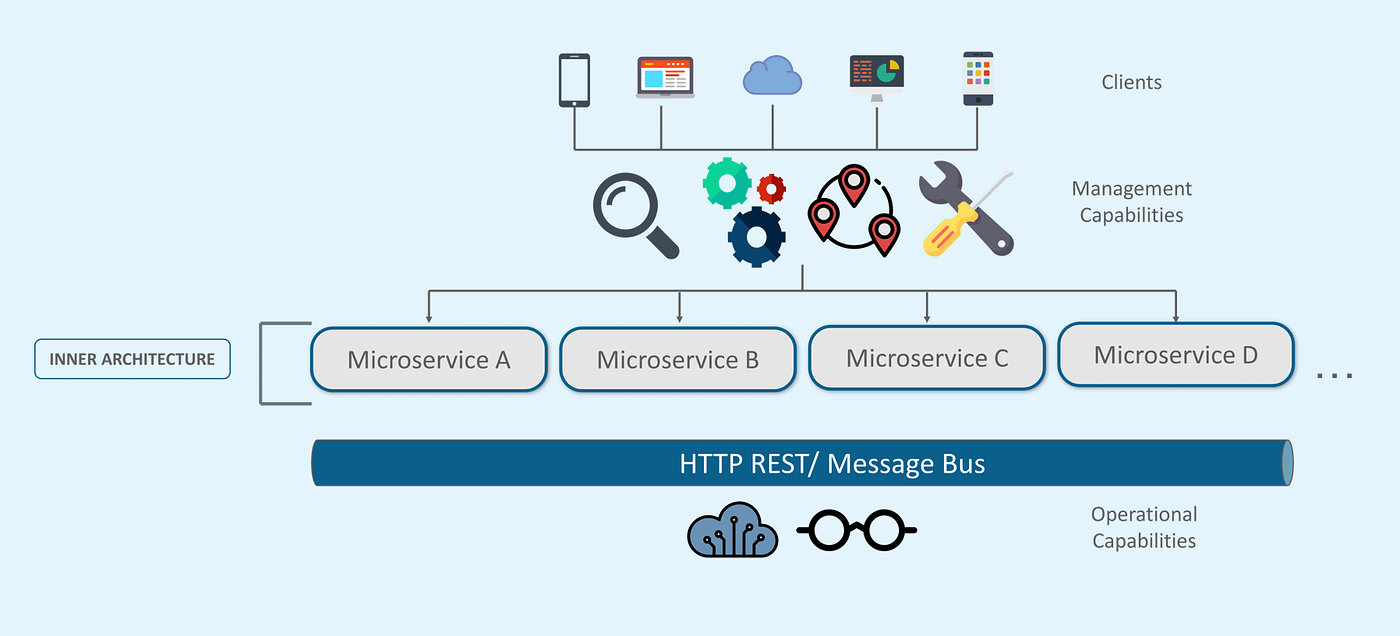
Microservice Architecture - What is Microservices
- 来自不同设备的不同客户端尝试使用不同的服务,例如搜索、构建、配置和其他管理功能。
- 所有服务都根据其域和功能进行分离,并进一步分配给各个微服务。
- 这些微服务有自己的负载均衡器和执行环境来执行它们的功能,同时在自己的数据库中捕获数据。
- 所有微服务都通过无状态服务器(REST 或消息总线)相互通信。
- 微服务借助服务发现了解其通信路径,并执行自动化、监控等操作功能。
- 然后,微服务执行的所有功能都通过 API 网关与客户端通信。
- 所有内部点都从 API 网关连接。因此,任何连接到 API 网关的人都会自动连接到整个系统。
现在,让我们通过查看其特性来了解更多关于微服务的信息。
微服务功能
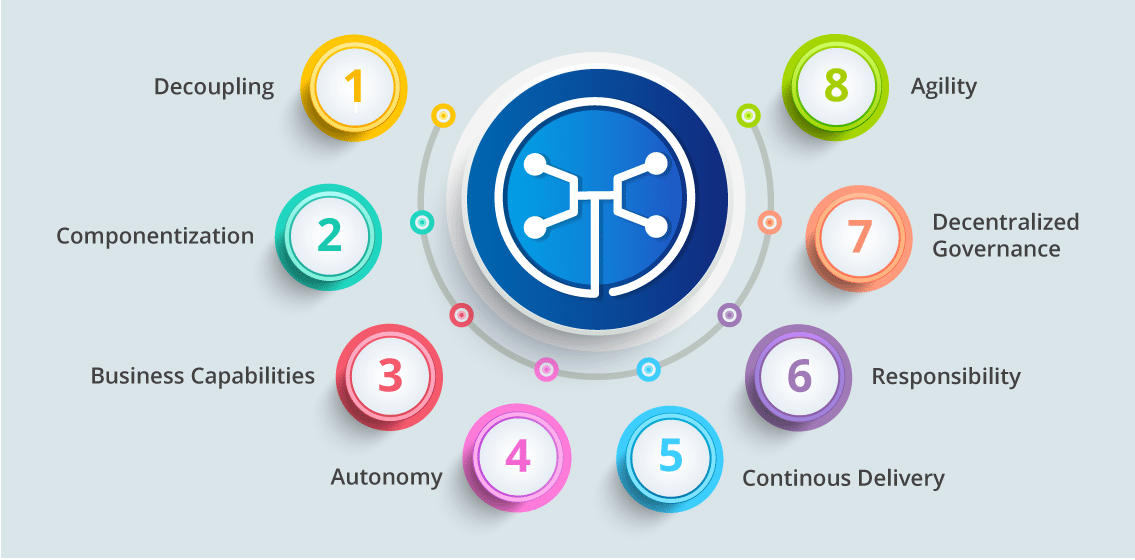
Features Of Microservices — What is Microservices
- 解耦——系统内的服务在很大程度上是解耦的。因此,整个应用程序可以轻松构建、更改和扩展。
- 组件化——微服务被视为可以轻松更换和升级的独立组件。
- 业务能力——微服务非常简单,专注于单一能力。
- 自治——开发人员和团队可以彼此独立工作,从而提高速度。
- 持续交付——通过软件创建、测试和批准的系统自动化,允许频繁发布软件。
- 责任——微服务不关注应用程序作为项目。相反,他们将应用程序视为他们负责的产品
- 去中心化治理——重点是为正确的工作使用正确的工具。这意味着没有标准化的模式或任何技术模式。开发人员可以自由选择最有用的工具来解决他们的问题
- 敏捷性——微服务支持敏捷开发。任何新功能都可以快速开发并再次丢弃
微服务的优势

Advantages of Microservices - What is Microservices
- 独立开发——所有微服务都可以根据各自的功能轻松开发
- 独立部署——根据他们的服务,他们可以单独部署在任何应用程序中
- 故障隔离——即使应用程序的一项服务不工作,系统仍然继续运行
- 混合技术栈——不同的语言和技术可用于构建同一应用程序的不同服务
- 粒度缩放——单个组件可以根据需要进行缩放,无需将所有组件一起缩放
设计微服务的最佳实践
在当今世界,复杂性已成功渗透到产品中。 微服务架构承诺让团队保持扩展并更好地运作。
以下是设计微服务的最佳实践:
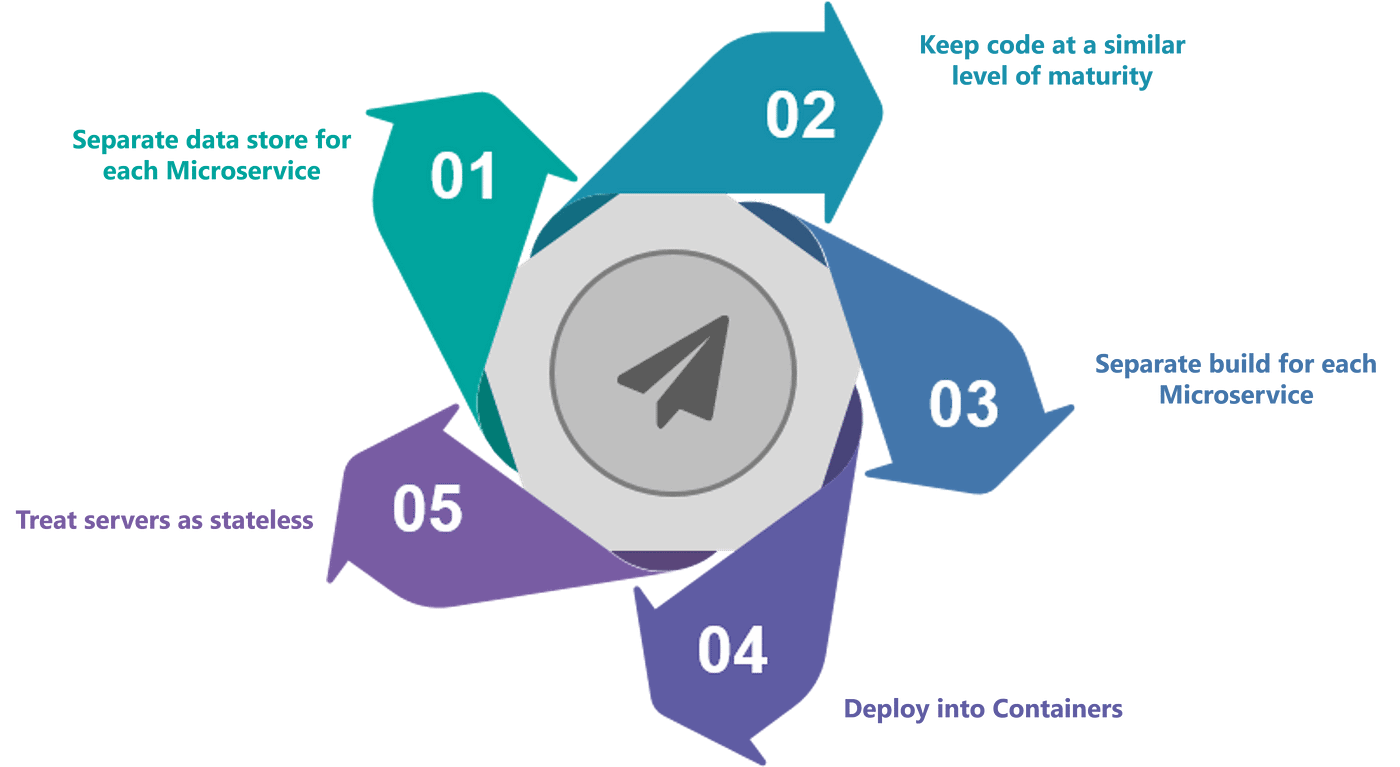
Best Practices To Design Microservices - What is Microservices
现在,让我们看一个用例来更好地理解微服务。
用例:购物车应用程序
让我们看一个购物车应用程序的经典用例。
当您打开购物车应用程序时,您看到的只是一个网站。 但是,在幕后,购物车应用程序具有接受付款的服务、客户服务等。
假设这个应用程序的开发人员已经在一个整体框架中创建了它。 请参考下图:
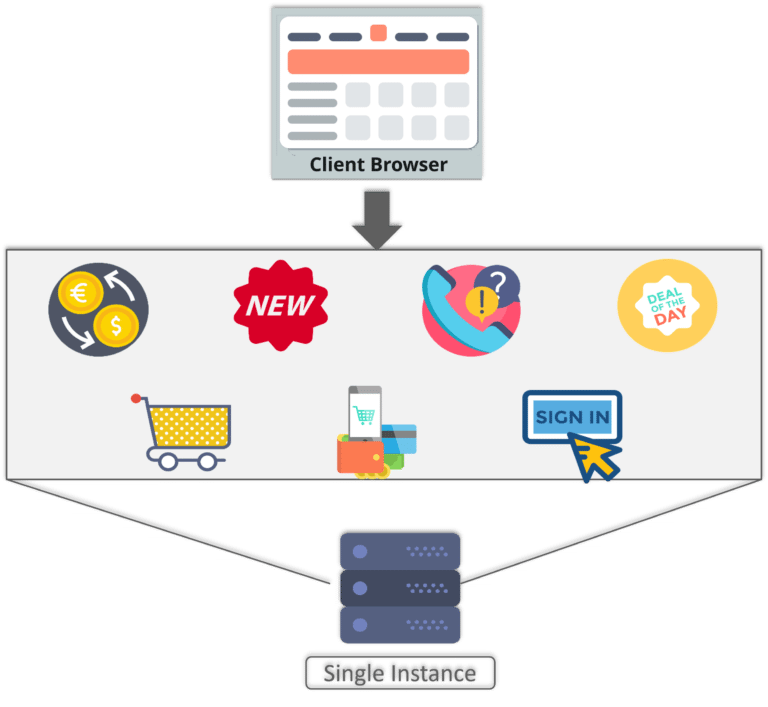
Monolithic Framework Of Shopping Cart Application — What is Microservices
因此,所有功能都放在一个代码库中,并位于一个底层数据库下。
现在,让我们假设市场上出现了一个新品牌,开发人员希望将即将推出的品牌的所有细节都放在这个应用程序中。
然后,他们不仅需要为新标签重新设计服务,还必须重新构建整个系统并相应地进行部署。
为了避免此类挑战,该应用程序的开发人员决定将他们的应用程序从单体架构转变为微服务。 参考下图了解购物车应用的微服务架构。
Microservice Architecture of Shopping Cart Application — What is Microservices
这意味着开发人员不会创建 Web 微服务、逻辑微服务或数据库微服务。 相反,他们为搜索、推荐、客户服务等创建单独的微服务。
这种类型的应用程序架构不仅可以帮助开发人员克服以前架构面临的所有挑战,还可以帮助购物车应用程序轻松构建、部署和扩展。
使用微服务的公司
有很多公司使用微服务来构建应用程序,这些只是仅举几例:

Companies using Microservices - What is Microservices
这将我们带到关于什么是微服务的文章的结尾。 我希望您发现这篇文章内容丰富,并为您的知识增加了价值。
。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. Microservice Architecture
- 2. Microservices vs SOA
- 3. Microservices Tutorial
- 4. Building Microservices Application Using Spring Boot
- 5. Microservices Security
原文:https://medium.com/edureka/what-is-microservices-86144b17b836
- 46 次浏览
【微服务架构】介绍KivaKit框架
关键点
- KivaKit是一个模块化Java框架,用于开发需要Java 11+虚拟机但与Java 8源代码兼容的微服务
- KivaKit提供了实现应用程序的基本功能,包括命令行解析和应用程序配置
- KivaKit组件是轻量级组件,使用广播/侦听器消息传递系统传递状态信息
- KivaKit迷你框架,包括转换、验证、资源和日志迷你框架,通过消息传递使用和报告状态信息
- KivaKit配置并运行Jetty、Jersey、Swagger和Apache Wicket,以一致的方式提供微服务接口
- 关键的KivaKit基类也可以作为有状态特征或“mixin”提供
概述
KivaKit是一个Apache许可证开源Java框架,设计用于实现微服务。KivaKit需要一个Java11+虚拟机,但源代码与Java8和Java9项目兼容。KivaKit由一组精心集成的迷你框架组成。每个迷你框架都有一个一致的设计和自己的重点,可以与其他迷你框架配合使用,也可以单独使用。这些框架的简化依赖关系网络提供了KivaKit的良好高级视图:
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1mini-frameworks-1637785248958.png)
每个迷你框架都解决了开发微服务时经常遇到的不同问题。本文简要概述了上图中的微型框架,并简要介绍了如何使用它们。
消息传递
如上图所示,消息传递是KivaKit的核心。消息传递在构建状态可观察的组件时非常有用,这在基于云的世界中是一个有用的功能。KivaKit中的许多对象广播或侦听状态消息,如警报、问题、警告或跟踪。大多数是中继器,侦听来自其他对象的状态消息,并将其重新广播给下游感兴趣的侦听器。这将与终端侦听器形成侦听器链:
C->B->A
通常,链中的最后一个侦听器是某种记录器,但在链的末尾也可以有多个侦听器,任何实现侦听器的对象都可以工作。例如,在Validation mini框架中,ValidationSues类捕获状态消息,然后使用该类确定验证是否成功,以及向用户显示验证失败的特定问题。
给定上面的侦听器链,C和B实现Repeater,最后一个对象A实现listener。在链中的每个类中,侦听器链都扩展为:
listener.listenTo(广播员)
要将消息发送给感兴趣的侦听器,将从广播机继承方便方法,以获得常见类型的消息:
|
Message |
Purpose |
|
problem() |
Something has gone wrong and needs to be addressed, but it’s not fatal to the current operation. |
|
glitch() |
A minor problem has occurred. Unlike a Warning, a Glitch indicates validation failure or data loss has occurred. Unlike a Problem, a Glitch indicates that the operation will definitely recover and continue. |
|
warning() |
A minor issue has occurred which should be corrected, but does not necessarily require attention. |
|
quibble() |
A trivial issue has occurred that does not require correction. |
|
announcement() |
Announces an important phase of an operation. |
|
narration() |
A step in some operation has started or completed. |
|
information() |
Commonly useful information that doesn’t represent any problem |
|
trace() |
Diagnostic information for use when debugging. |
广播器还提供了一种机制,通过对类和包进行模式匹配,从命令行打开和关闭跟踪消息。
混合
在KivaKit中,有两种实现中继器的方法。第一种方法是简单地扩展BaseRepeater。第二种是使用有状态特征或Mixin。实现RepeaterMixin接口与扩展BaseRepeater相同,但是repeater mixin可以在已经有基类的类中使用。注意,下面讨论的组件接口使用相同的模式。如果不能扩展BaseComponent,那么可以实现ComponentMixin。
Mixin接口为缺少的Java语言特性提供了一个解决方案。它的工作原理是将状态查找委托给包私有类MixinState,该类使用实现Mixin的类的this引用在标识哈希映射中查找关联的状态对象。Mixin接口如下所示:
public interface Mixin
{
default T state(Class type, Factory factory)
{
return MixinState.get(this, type, factory);
}
}
如果state()找不到此的state对象,则将使用给定的工厂方法创建新的state对象,然后该对象将与状态映射中的mixin关联。例如,我们的Repeatermxin接口大致如下(为了简洁起见,没有大多数方法):
public interface RepeaterMixin extends Repeater, Mixin
{
@Override
default void addListener(Listener listener, Filter filter)
{
repeater().addListener(listener, filter);
}
@Override
default void removeListener(Listener listener)
{
repeater().removeListener(listener);
}
[...]
default Repeater repeater()
{
return state(RepeaterMixin.class, BaseRepeater::new);
}
}
这里,addListener()和RemovelListener()方法各自通过repeater()检索其BaseRepeater状态对象,并将方法调用委托给该对象。正如我们所见,在KivaKit中实现mixin并不复杂。
应该注意的是,对mixin中方法的每次调用都需要在状态映射中进行查找。标识哈希映射通常应该相当有效,但对于一些组件来说,这可能是一个性能问题。与大多数性能问题一样,我们最好做最简单的事情,直到我们的分析器不这么说。
组件
KivaKit组件通常可能是微服务的关键部分。组件通过扩展BaseComponent(最常见的情况)或通过实现ComponentMixin提供对消息传递的轻松访问。从组件继承不会向对象添加任何状态,但从Repeater继承的侦听器列表除外。这使得组件非常轻量级。大量实例化它们并不是一个问题。由于组件是中继器,因此可以创建侦听器链,如上所述。
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1component-1637785248958.jpg)
除了提供对消息的方便访问外,组件还提供以下功能:
- 注册和查找对象
- 加载和访问设置对象
- 访问包资源
让我们看看这些设施。
对象注册和查找
KivaKit使用服务定位器设计模式,而不是依赖项注入。在组件中使用此模式很简单。一个组件可以使用registerObject()注册对象,另一个组件可以使用require()查找对象:
Database database = [...] registerObject(database); [...] var database = require(Database.class);
如果需要注册单个类的多个实例,可以使用枚举值来区分它们:
enum Database { PRODUCTS, SERVICES } registerObject(database, Database.PRODUCTS); [...] var database = require(Database.class, Database.SERVICES);
在KivaKit中,任何可能使用依赖项注入的地方都使用register和require。
设置
KivaKit中的组件也可以使用require()方法轻松访问设置信息:
require(DatabaseSettings.class);
与注册对象一样,如果存在多个相同类型的对象,则可以使用枚举来区分设置对象:
require(DatabaseSettings.class, Database.PRODUCTS);
可以通过多种方式注册设置信息:
registerAllSettingsIn(Folder) registerAllSettingsIn(Package) registerSettingsObject(Object) registerSettingsObject(Object, Enum)
在KivaKit 1.0中,使用RegisterAllSettings sin()方法加载的设置对象由.properties文件定义。将来,将提供一个API,以允许从其他源(如.json文件)加载属性。要实例化的设置类的名称由class属性提供。然后从其余属性中检索实例化对象的各个属性。使用KivaKit转换器(如下所述)将每个属性转换为对象。
例如:
DatabaseSettings.properties
class = com.mycompany.database.DatabaseSettings
port = database.production.mypna.com:3306
DatabaseSettings.java
public class DatabaseSettings
{
@KivaKitPropertyConverter(Port.Converter.class)
private Port port;
public Connection connect()
{
// Return connection to database on desired port
[...]
}
}
包资源
KivaKit提供了一个资源迷你框架,它统一了多种资源类型:
- 文件夹
- Sockets
- Zip或JAR文件条目
- 包资源
- HTTP响应
- 输入流
- 输出流
- […]
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1resources-1637785248958.png)
资源是应用程序可以从中读取流数据的组件。WritableResources是应用程序可以向其写入流数据的资源。文件可用的大多数方法在任何给定资源中都可用,但某些资源类型可能会使某些方法不受支持。例如,资源可能是流式的,因此它无法实现sizeInBytes()。
KivaKit文件是一种特殊的资源。它使用服务提供者接口(SPI)来允许添加新的文件系统。kivakit extensions项目提供了以下文件系统的实现:
- HDFS文件
- S3对象
- GitHub存储库(只读)
KivaKit组件便于访问PackageResources。KivaKit中封装资源的风格类似于ApacheWicket中的风格,组件的包将有一个子包,其中包含其运行所需的资源。这允许从单个源代码树轻松打包和使用组件。相对于组件对包资源的访问如下所示:
public class MyComponent extends BaseComponent
{
[...]
var resource = listenTo(packageResource("data/data.txt"));
for (var line : resource.reader().lines())
{
}
}
Where the package structure looks like this:
├── MyComponent
└── data
└── data.txt
应用
KivaKit应用程序是一个美化的组件,包含与启动、初始化和执行相关的方法。服务器是应用程序的一个子类:
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1application-1637785248958.jpg)
微服务是KivaKit应用程序最常见的用途,但也可以实现其他类型的应用程序(桌面、web、实用程序等)。microservice应用程序的基本代码如下所示:
public class MyMicroservice extends Server
{
public static void main(final String[] arguments)
{
new MyApplication().run(arguments);
}
private MyApplication()
{
super(MyProject());
}
@Override
protected void onRun()
{
[...]
}
}
这里的main()方法创建应用程序,并使用从命令行传递的参数调用应用程序基类中的run()方法。然后,微服务的构造函数将项目对象传递给超类构造函数。此对象用于初始化包含应用程序的项目以及它所依赖的任何其他项目。继续我们的示例,我们的项目类如下所示:
public class MyProject extends Project
{
private static Lazy project = Lazy.of(MyProject::new);
public static ApplicationExampleProject get()
{
return project.get();
}
protected ApplicationExampleProject()
{
}
@Override
public Set dependencies()
{
return Set.of(ResourceProject.get());
}
}
{
可以使用get()检索MyProject的单例实例。MyProject的依赖项由dependencies()返回。在本例中,MyProject仅依赖于ResourceProject,ResourceProject是kivakit资源迷你框架的项目定义。ResourceProject也有自己的依赖项。KivaKit将确保在调用onRun()之前初始化所有可传递的项目依赖项。
部署
KivaKit应用程序可以从名为deployments的应用程序相关包中自动加载设置对象集合。将微服务部署到特定环境时,此功能非常有用。我们的应用程序的结构如下所示:
├── MyMicroservice
└── deployments
├── development
│ ├── WebSettings.properties
│ └── DatabaseSettings.properties
└── production
├── WebSettings.properties
└── DatabaseSettings.properties
当开关-deployment=在命令行上传递给应用程序时,它将从命名的部署(本例中为开发或生产)加载设置。为微服务使用打包部署设置特别好,因为应用程序的使用非常简单:
java-jar my-microservice.jar-deployment=development[…]
这使得在Docker容器中运行应用程序变得很容易,即使您对它了解不多。
如果不需要打包部署设置,可以通过设置环境变量KIVAKIT_settings_FOLDERS来使用外部文件夹:
-DKIVAKIT_SETTINGS_FOLDERS=/Users/jonathan/my microservice SETTINGS
命令行解析
应用程序还可以通过返回一组SwitchParser和/或ArgumentParser列表来解析命令行:
public class MyMicroservice extends Application
{
private SwitchParser<File> DICTIONARY =
File.fileSwitchParser("input", "Dictionary file")
.required()
.build();
@Override
public String description()
{
return "This microservice checks spelling.";
}
@Override
protected void onRun()
{
var input = get(DICTIONARY);
if (input.exists())
{
[...]
}
else
{
problem("Dictionary does not exist: $", input.path());
}
}
@Override
protected Set<SwitchParser<?>> switchParsers()
{
return Set.of(DICTIONARY);
}
}
这里,KivaKit使用switchParsers()返回的字典开关解析器来解析命令行。在onRun()方法中,通过get(DICTIONARY)检索在命令行上传递的文件参数。如果命令行存在语法问题或未通过验证,KivaKit将自动报告该问题,并提供从description()以及开关和参数解析器派生的用法帮助:
┏-------- COMMAND LINE ERROR(S) -----------
┋ ○ Required File switch -input is missing
┗------------------------------------------
KivaKit 1.0.0 (puffy telephone)
Usage: MyApplication 1.0.0 <switches> <arguments>
This microservice checks spelling.
Arguments:
None
Switches:
Required:
-input=File (required) : Dictionary file
Switch Parsers
In our application example, we used this code to build a SwitchParser:
private SwitchParser<File> INPUT =
File.fileSwitchParser("input", "Input text file")
.required()
.build();
The File.fileSwitchParser() method returns a switch parser builder which can be specialized with several methods before build() is called:
public Builder<T> name(String name)
public Builder<T> type(Class<T> type)
public Builder<T> description(String description)
public Builder<T> converter(Converter<String, T> converter)
public Builder<T> defaultValue(T defaultValue)
public Builder<T> optional()
public Builder<T> required()
public Builder<T> validValues(Set<T> validValues)
The implementation of File.fileSwitchParser() then looks like this:
public static SwitchParser.Builder<File> fileSwitchParser(String name, String description)
{
return SwitchParser.builder(File.class)
.name(name)
.converter(new File.Converter(LOGGER))
.description(description);
}
所有开关和参数都是类型化对象,因此builder(Class)方法使用File类型(使用type()方法)创建一个builder。它的名称和描述传递给fileSwitchParser(),File.Converter方法用于在字符串和文件对象之间进行转换。
转换器
KivaKit提供了许多转换器,转换器可以在KivaKit的许多地方使用。转换器是将一种类型转换为另一种类型的可重用对象。它们特别容易创建,并且可以处理异常、空值或空值等常见问题:
public static class Converter extends BaseStringConverter<File>
{
public Converter(Listener listener)
{
super(listener);
}
@Override
protected File onToValue(String value)
{
return File.parse(value);
}
}
调用StringConverter.convert(字符串)将字符串转换为文件。调用StringConverter.uncert(文件)将把文件转换回字符串。转换过程中遇到的任何问题都会广播给感兴趣的侦听器,如果转换失败,则返回null。
正如我们所看到的,转换器对侦听器链采取了不同的方法。所有转换器都需要一个侦听器作为构造函数参数,而不是依赖转换器用户来调用listenTo()。这确保所有转换器都能够向至少一个侦听器报告转换问题。
验证
在上面的命令行解析代码中,使用kivakit validation mini框架验证开关和参数。另一个常见的用例是向微服务验证web应用程序用户界面的域对象。
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1validation-1637785949145.jpg)
可验证类实现:
public interface Validatable
{
/**
* @param type The type of validation to perform
* @return A {@link Validator} instance
*/
Validator validator(ValidationType type);
}
要实现此方法,可以匿名地对BaseValidator进行子类化。BaseValidator提供了检查状态一致性以及广播问题和警告的方便方法。KivaKit使用ValidationSues对象捕获这些消息。然后可以使用Validatable接口中的默认方法查询此状态。用法如下所示:
public class User implements Validatable
{
String name;
[...]
@Override
public Validator validator(ValidationType type)
{
return new BaseValidator()
{
@Override
protected void onValidate()
{
problemIf(name == null, "User must have a name");
}
};
}
}
public class MyComponent extends BaseComponent
{
public void myMethod()
{
var user = new User("Jonathan");
if (user.isValid(this))
{
[...]
}
}
}
这里捕获来自验证的消息以确定用户对象是否有效。同样的消息也会广播到MyComponent的监听器,这些消息可能会记录或显示在某些用户界面中。
日志
KivaKit记录器是一个消息侦听器,记录它听到的所有消息。基本应用程序类有一个日志记录器,用于记录从组件到应用程序级别的任何消息。这意味着不需要在应用程序或其任何组件中创建记录器,只要侦听器链从每个组件一直引导到应用程序。
最简单的记录器是ConsoleLogger。将此设计缩小到基本结构,ConsoleLogger和相关类大致如下所示(请参见下面的UML图):
:
public class ConsoleLogger extends BaseLogger
{
private Log log = new ConsoleLog();
@Override
protected Set<Log> logs()
{
return Sets.of(log);
}
}
public class BaseLogger implements Logger
{
void onMessage(final Message message)
{
log(message);
}
public void log(Message message)
{
[...]
for (var log : logs())
{
log.log(entry);
}
}
}
public class ConsoleLog extends BaseTextLog
{
private Console console = new Console();
@Override
public synchronized void onLog(LogEntry entry)
{
console.printLine(entry.message().formatted());
}
}
BaseLogger.log(Message)方法通过添加上下文信息将提供给它的消息转换为日志条目。然后,它将日志条目传递给logs()返回的日志列表中的每个日志。对于ConsoleLogger,将返回一个ConsoleLog实例。ConsoleLog将日志条目写入控制台。
/filters:no_upscale()/articles/introducing-kivakit/en/resources/1logging-1637785248958.jpg)
KivaKit有一个SPI,允许从命令行动态添加和配置新的记录器。KivaKit提供的一些伐木工人包括:
- ConsoleLog
- EmailLog
- FileLog
Web和REST
kivakit扩展项目包含对Jetty、Jersey、Swagger和ApacheWicket的基本支持,因为它们在实现微服务时通常很有用。这些微型框架都集成在一起,因此启动Jetty服务器非常容易,为微服务提供REST和Web访问:
@Override
protected void onRun()
{
final var port = (int) get(PORT);
final var application = new MyRestApplication();
// and start up Jetty with Swagger, Jersey and Wicket.
listenTo(new JettyServer())
.port(port)
.add("/*", new JettyWicket(MyWebApplication.class))
.add("/open-api/*", new JettySwaggerOpenApi(application))
.add("/docs/*", new JettySwaggerIndex(port))
.add("/webapp/*", new JettySwaggerStaticResources())
.add("/webjar/*", new JettySwaggerWebJar(application))
.add("/*", new JettyJersey(application))
.start();
}
JettyServer允许Jersey、Wicket和Swagger与一致的API相结合,使代码清晰简洁。通常这就是所需要的。
结论
尽管KivaKit在1.0版上是全新的,但它在Telenav上已经使用了十多年。非常欢迎来自开源社区的输入,包括反馈、bug报告、特性想法、文档、测试和代码贡献。
以下资源可帮助您深入了解详细信息:
|
Resource |
Description |
|
License |
|
|
Related Projects |
|
|
Developer Setup |
|
| Blog | State-of-the-Art |
|
GitHub |
|
|
Code |
git clone https://github.com/Telenav/kivakit.git |
|
|
|
|
|
- 33 次浏览
【微服务架构】介绍NGINX的微服务参考架构
作者注:本博文是系列文章的第一篇:
- Introducing the NGINX Microservices Reference Architecture (this post)
- MRA, Part 2: The Proxy Model
- MRA, Part 3: The Router Mesh Model
- MRA, Part 4: The Fabric Model
- MRA, Part 5: Adapting the Twelve‑Factor App for Microservices
- MRA, Part 6: Implementing the Circuit Breaker Pattern with NGINX Plus
所有六个博客,以及一个关于微服务应用程序的Web前端的博客,都被收集到一个免费的电子书中。
另请查看有关微服务的其他NGINX资源:
- A very useful and popular series by Chris Richardson about microservices application design
- The Chris Richardson articles collected into a free ebook, with additional tips on implementing microservices with NGINX and NGINX Plus
- Other microservices blog posts
- Microservices webinars
- Microservices Solutions page
- Topic: Microservices
介绍
NGINX从一开始就参与了微服务运动。 NGINX的轻巧,高性能和灵活性非常适合微服务。
NGINX Docker映像是Docker Hub上排名第一的应用程序映像,您今天在Web上找到的大多数微服务平台都包含一个演示,它以某种形式部署NGINX并连接到欢迎页面。
因为我们认为转向微服务对于客户的成功至关重要,我们NGINX已经启动了一个专门的程序来开发支持Web应用程序开发和交付这种地震转变的功能和实践。我们还认识到,实现微服务有许多不同的方法,其中许多方法都是新颖的,并且特定于各个开发团队的需求。我们认为需要使用模型来使公司更容易开发和交付自己的基于微服务的应用程序。
考虑到这一切,NGINX专业服务部门正在开发NGINX微服务参考架构(MRA) - 一组可用于创建自己的微服务应用程序的模型。
MRA由两部分组成:三个模型中的每一个的详细描述,以及实现我们的示例照片共享程序的可下载代码,Ingenious。三种型号的唯一区别是用于为每种型号配置NGINX Plus的配置代码。这一系列博客文章将提供每个模型的概述说明; Ingenious示例程序的详细描述,配置代码和代码将在今年晚些时候推出。
我们构建此参考架构的目标有三个:
- 为客户和行业提供随时可用的蓝图,用于构建基于微服务的系统,加速和改进开发
- 创建用于测试NGINX和NGINX Plus中新功能的平台,无论是内部开发还是外部开发,分布在产品核心中或作为动态模块
- 为了帮助我们了解合作伙伴系统和组件,我们可以从整体上了解微服务生态系统
微服务参考架构也是NGINX客户专业服务产品的重要组成部分。在MRA中,我们尽可能使用NGINX开源和NGINX Plus共有的功能,并在需要时使用NGINX Plus特有的功能。 NGINX Plus依赖关系在更复杂的模型中更强,如下所述。我们预计,MRA的许多用户将受益于NGINX专业服务的访问以及NGINX Plus订阅的技术支持。
微服务参考架构概述
我们正在构建参考架构以符合Twelve-Factor App的原则。这些服务设计为轻量级,短暂的和无状态的。
MRA使用行业标准组件,如Docker容器,各种语言 - Java,PHP,Python,NodeJS / JavaScript和Ruby - 以及基于NGINX的网络。
迁移到微服务时,应用程序设计和体系结构的最大变化之一是使用网络在应用程序的功能组件之间进行通信。在单片应用程序中,应用程序组件在内存中进行通信。在微服务应用程序中,该通信通过网络进行,因此网络设计和实施变得至关重要。
为了反映这一点,MRA已经使用三种不同的网络模型实现,所有这些模型都使用NGINX或NGINX Plus。它们的范围从相对简单到功能丰富且更复杂:
- 代理模型 (Proxy Model)- 一种简单的网络模型,适用于实现NGINX Plus作为微服务应用程序的控制器或API网关。该模型建立在Docker Cloud之上。
- 路由器网格模型(Router Mesh Model ) - 一种更强大的网络方法,每台主机上都有一个负载均衡器,可以管理系统之间的连接。该模型类似于Deis 1.0的体系结构。
- 织品模型 (Fabric Model) - MRA的皇冠上的明珠,面料模型在每个容器中都有NGINX Plus,处理所有入口和出口交通。它适用于高负载系统,并支持所有级别的SSL / TLS,NGINX Plus提供减少的延迟,持久的SSL / TLS连接,服务发现以及所有微服务中的断路器模式。
我们的目的是您使用这些模型作为您自己的微服务实现的起点,我们欢迎您提供有关如何改进MRA的反馈。 (您可以从添加到下面的评论开始。)
以下是每种模型的简要说明;我们建议您阅读所有描述,以便开始了解如何最好地使用一个或多个模型。未来的博客文章将详细描述每个模型,每个博客文章一个。
代理模型简介
代理模型是一种相对简单的网络模型。它是初始微服务应用程序的出色起点,或者是转换中等复杂的单片遗留应用程序的目标模型。
在代理模型中,NGINX或NGINX Plus充当入口控制器,将请求路由到微服务。当创建新服务时,NGINX Plus可以使用动态DNS进行服务发现。当使用NGINX作为API网关时,代理模型也适合用作模板。

如果需要进行服务间通信 - 并且大多数应用程序都处于任何复杂程度 - 服务注册表提供集群内的机制。 (有关服务间通信机制的详细列表,请参阅此博客文章。)Docker Cloud默认使用此方法;为了连接到另一个服务,服务查询DNS并获取IP地址以发送请求。
通常,代理模型适用于简单到中等复杂的应用程序。它不是负载平衡最有效的方法/模型,特别是在规模上;如果您有严重的负载平衡要求,请使用下面描述的模型之一。 (“Scale”可以指大量的微服务以及高流量。)
编辑器 - 有关此模型的深入探索,请参阅MRA,第2部分 - 代理模型。
路由器网格模型
路由器网格模型中等复杂,非常适合强大的新应用程序设计,也适用于转换不需要Fabric模型功能的更复杂的单片遗留应用程序。
通过在每个主机上运行负载均衡器并主动管理微服务之间的连接,路由器网状网模型采用比代理模型更强大的网络方法。路由器网格模型的主要优点是服务之间的更高效和稳健的负载平衡。如果使用NGINX Plus,则可以实施活动运行状况检查以监视各个服务实例,并在关闭时优雅地限制流量。
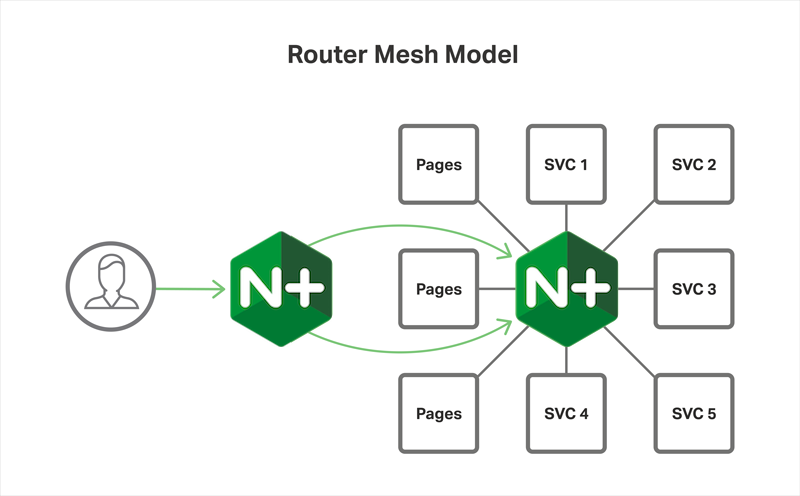
Deis Workflow使用类似于路由器网格模型的方法在服务之间路由流量,NGINX实例在每个主机上的容器中运行。当新的应用程序实例被启动时,进程从etcd服务注册表中提取服务信息并将其加载到NGINX中。 NGINX Plus也可以在这种模式下工作,使用各种位置及其相关的上游。
编辑器 - 有关此模型的深入探索,请参阅MRA,第3部分 - 路由器网格模型(https://www.nginx.com/blog/microservices-reference-architecture-nginx-r…)。
最后 - Fabric模型,带有可选的SSL / TLS
我们NGINX对Fabric模型最为兴奋。它带来了一些最令人兴奋的微服务承诺,包括高性能,负载平衡的灵活性,以及无处不在的SSL / TLS,直到单个微服务的水平。 Fabric模型适用于安全应用程序,可扩展到非常大的应用程序。
在Fabric模型中,NGINX Plus部署在每个容器中,并成为进出容器的所有HTTP流量的代理。应用程序与本地(localhost)主机位置通信以获取所有服务连接,并依赖NGINX Plus进行服务发现,负载平衡和运行状况检查。
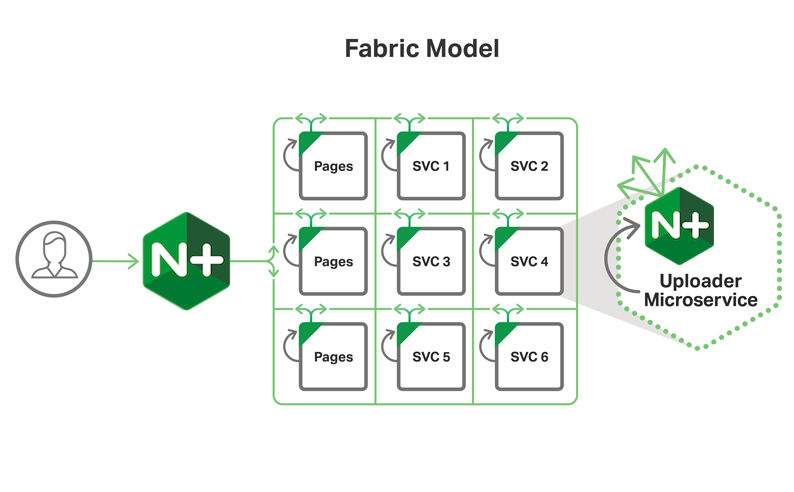
在我们的配置中,NGINX Plus向ZooKeeper查询应用程序需要连接的所有服务实例。例如,使用DNS频率设置(有效)设置为1秒,NGINX Plus会每隔一秒扫描ZooKeeper,并适当地路由流量。
由于NGINX Plus中强大的HTTP处理功能,我们可以使用keepalive来维护与微服务的状态连接,减少延迟并提高性能。当使用SSL / TLS来保护微服务之间的流量时,这是一个特别有价值的功能。
最后,我们使用NGINX Plus的主动健康检查来管理健康实例的流量,并且基本上免费构建断路器模式。
编辑 - 有关此模型的深入探索,请参阅MRA,第4部分 - 结构模型(https://www.nginx.com/blog/microservices-reference-architecture-nginx-f…)。
MRA的巧妙演示应用程序
MRA包括一个示例应用程序作为演示:Ingenious照片共享应用程序。 Ingenious在三种模型中实现 - 代理,路由器网格和结构。 Ingenious演示应用程序将于今年晚些时候向公众发布。
Ingenious是照片存储和共享应用程序的简化版本,la Flickr或Shutterfly。我们选择照片共享应用程序的原因有以下几点:
- 用户和开发人员都很容易掌握它的功能。
- 需要管理多个数据维度。
- 在应用程序中很容易融入漂亮的设计。
- 它提供了非对称计算要求 - 高强度和低强度处理的混合 - 可以实现跨不同功能的故障转移,扩展和监视功能的真实测试。

结论
NGINX微服务参考架构对我们来说是一个令人兴奋的发展,对于我们迄今为止共享的客户和合作伙伴而言。 在接下来的几个月里,我们将发布一系列博客文章,详细描述它,我们将在今年晚些时候推出。 我们还将在9月7日至9日在德克萨斯州奥斯汀举行的nginx.conf 2016上详细讨论。 请给我们您的反馈意见,我们期待着与您相见。
原文:https://www.nginx.com/blog/introducing-the-nginx-microservices-reference-architecture/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 65 次浏览
【微服务架构】使用Canary版本来简化API版本控制
API提供者可能面临的最大困难之一是如何管理版本和从实例到实例的构建。迭代的持续需求与组织的持续需求相匹配,使得版本控制成为现代API开发中一个有争议且经常被讨论的方面。但是,对于传统的版本控制,有一些替代方法可以带来一些主要的好处。
今天,我们将讨论其中一个解决方案——canary release。Canary已经迅速成为透明API开发的一个巨大组件,对于开放银行来说,它可能是现代金融机构在不破坏基础互操作性的情况下实现透明、有效的版本控制的最佳工具之一。
为什么API版本控制和金丝雀的发布如此重要?
有时,API提供者和API使用者之间可能存在某种紧张关系。API提供者可能希望在他们有新的、更好的想法时改变API。这些想法很有前途,展示了API的新特性、新方法和可能的新方向。
然而,API使用者通常只想要一些稳定的东西。除非使用者对这个新的、很棒的想法感兴趣,否则他们希望API能够以可预见的方式运行。
这就产生了一个明显的问题,这也是版本控制对许多用户来说如此困难的主要原因。不过,对于版本控制最好的争论来自于REST设计之父Roy Fielding。他对实现版本控制的看法是什么?“不要。”
版本是什么?
具体来说,为什么?为什么我们不应该理所当然地进行版本控制呢?让我们看看版本化api的影响。
版本控制是指在向服务添加特性时,从根本上创建现有对象的新版本。这些版本是截然不同的,并且通常具有完全独立的功能,具有不同的目的,因此,被视为完全独立的开发。
在传统的版本化开发中,这些新版本将被标记为用于测试的beta版本,以及用于全面改进的里程碑版本。一旦进行了测试,通常以一种可选择的方式,这些beta版本将慢慢地转向候选版本,然后是实际版本。
这种类型的版本控制有一些主要的好处,主要的好处是在形式和功能上的主要改进得到了明确的划分。这种划分的能力非常重要,特别是在使用不同的硬件版本时,但最终,这本身就是版本化方法的失败之处。许多用户都知道,当他们尝试使用一个设备时,却发现其固件、软件或其他元素不兼容,需要更新。因此,他们不使用该系统,并在以后返回时发现情况更糟。
这最终导致用户群中大量的更新和未更新的划分,并且把太多的重要性放在单个实例上而不是整体系统本身。
什么是金丝雀发布?
金丝雀释放是一种试图减轻许多负面影响的技术。Canary版本通常被定位为版本控制的替代品,就像lite版本控制一样。
在canary版本中,引入新软件的风险是通过先慢慢地将这些变化推广给一小部分用户来减轻的,而不是像经典版本控制中那样通过选择加入和后来的强制发布来推广它们。这些小的用户子集通过动态负载平衡测试新版本,一旦版本控制被验证为符合预期的功能,新版本就成为默认版本。
我们称之为金丝雀释放,因为它的功能类似于井筒中的金丝雀。金丝雀曾经被矿工用来测试矿井里的空气。如果空气有毒,金丝雀就会死掉,这就向矿工发出他们必须立即离开的信号。同样地,如果正在缓慢测试的API实例是坏的,那么检测它的原因将是小子集中的故障,而不是对一般用户的大规模故障。
应用程序正在调用一个绑定到API的服务实例——随着这些请求逐渐暴露给新版本,特定的应用程序、硬件、方法等可以根据新版本动态地进行粒度测试。最终,如果一切顺利,所有内容都将转到新版本,旧版本将被弃用,用户也不会知道。
这里的一个巨大好处是,回滚很容易——最终,您只需停止向新的canary实例发送请求,而只需将其发送到旧的canary实例。
荷兰国际集团(ING)版本
一旦您看到了它的实际应用,这种方法就更容易理解。Patrice Krakow在2017北欧api平台峰会上做了关于canary发布的演讲,他提供了下面的工作流程作为ING银行如何处理canary发布的例子。
构建系统
在ING系统中,大部分API交互是由API网关驱动的。他们认为他们的网络分为两层——外部网络和内部网络,第三层内部网络代表办公室网络。Patrice注意到,API网关功能在外部边界和内部边界上,但他指出,并没有真正的“内部网关”,正如设计所暗示的那样。
就其API而言,包括负载平衡和逻辑寻址在内的一切都主要通过API服务发现来处理。当创建一个服务的实例时,该服务将作为一个实例、一组端点和一个地址通过路由器交付给API服务器发现。现在,我们必须绕一小段路来讨论一下路由器。在ING,它们不把路由器作为外部组件来处理,而是作为客户端的一部分来处理——通过这种方式,客户端代码处理自己的负载平衡。
在ING系统中,服务和端点是两个独立的东西,但是它们被称为manifest的东西链接和控制。这个清单本质上是服务和API端点列表之间定义良好的显式链接,并作为实例本身如何工作的一种指导。
当一个软件包想要调用一个API端点时,它首先声明它的意图。在ING中,这被称为订阅,它的作用是作为软件包(也称为应用程序)和特定API端点之间的关系。当在内部生成对等令牌时,API规范的版本将从创建此订阅时开始存储,并将实例版本作为更大的canary系统的一部分。
利用该系统
有了所有这些组成部分,ING最终通过它的路由器实现金丝雀释放。流程从API和端点开始,这些API和端点在一个Swagger文件中声明,该文件存在于API注册表中。服务被附加到API端点,然后清单被添加到具有特定规范版本的服务中。当启动一个服务的实例时,它会向API服务发现模块提供其物理地址,以及其所有端点的清单。

摘自帕特里斯·克拉科夫的演讲。幻灯片。
当应用程序想要调用一个端点时,它订阅一个可以调用的端点列表以及它想要与之对话的特定版本。路由器,不管是在代码内部还是在代码外部,然后传递注册对等令牌和信息,并使用端点的物理地址调用API服务发现。如果特定的API规范版本匹配,则可以将代码定向到基础实例或与该版本兼容的向后兼容版本。
通过这种方式,系统可以开始卸载到向后兼容旧实例的新实例,并且一旦测试了整个子集,就可以动态地增加用户基数。最后,当100%的用户基被透明地迁移后,旧的实例id就会被弃用,而新实例将成为清单中的默认实例。
结论:许多行业都能从金丝雀发布中受益
最终,API提供者选择合并canary版本还是坚持传统的版本控制完全取决于API开发人员自身的具体用例。虽然canary的发布确实使版本控制变得更加容易,但如果API每隔几年就只有一个或两个主要版本,那么它有时可能会付出更多的努力。但是,如果一个API不断地移动、不断地迭代,canary release可能是管理这种移动的最强大、最有效的方法之一。
这一概念在各种行业中都有许多应用。我们可以只看一个来看看这个潜在的概念是多么强大。例如,开放银行业运动正在鼓励金融机构远离旧的标准方法。因此,释放金丝雀的想法不仅是一种技术手段——它是一种新的风气,为银行在金融交易和架构构造方面的功能提供了范式转变。
虽然这是一个非常具体的应用程序,但canary版本控制的使用适用于各种函数和目的。由于这个原因,它仍然吸引着许多开发人员。你觉得放金丝雀怎么样?你认为它比它的价值更复杂,还是你认为它像一些人声称的那样是一个有前途的解决方案?请在下面的评论中告诉我们。
原文:https://nordicapis.com/using-canary-release-to-ease-api-versioning/
本文:http://jiagoushi.pro/node/1209
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 64 次浏览
【微服务架构】使用Spring Cloud Config和Vault进行外部配置
让您的应用程序提取其配置和凭据
你开始一个新项目。一开始,它主要是原型;你尝试了一些想法并且还没有修复,所以在你的应用程序配置方面你非常务实。一些属性文件存储在源代码旁边 - 至少您没有使用硬编码的URL和凭据!首次将应用程序部署到开发或演示环境时,只需复制和修改属性文件即可。原型变成了生产代码,但配置仍然是以临时方式管理的。这对你来说听起来很熟悉吗?无论如何,这是我在一年多前的一个当前项目中发现自己的情况。
在不同的环境中维护配置文件的单独副本可能永远不是最好的方法,即使我们曾经部署到少数长时间运行的雪花服务器上也是如此。鉴于我们越来越多地学习利用云产品,因此经常为测试创建短暂的应用程序环境,甚至将我们的生产系统部署为凤凰服务器,我们需要做得更好。
这篇文章描述了我们如何使用Spring Cloud Config和Spring Cloud Vault在我们的一个基于Spring Boot的项目中解决这个问题,以及我们如何定制这些库以满足我们的需求。特别是,该帖子着眼于外部化配置的动机,并在描述(a)我们为实现Spring Cloud Config而实施的扩展之前,对Spring Cloud Vault,Hashicorp Vault和Spring Cloud Vault进行了(非常)高级概述。客户端从Vault获取必要的HTTP基本身份验证凭据,以及(b)我们如何使应用程序从Vault读取所有TLS(客户端或服务器)密钥材料。您可以分别在公共演示项目demo-authorized-spring-config-server和demo-spring-boot-tls-material-from-vault中的GitHub上找到相关代码。
- 外化配置
- Spring服务
- Spring Cloud Config
- 配置服务器
- 配置客户端
- Spring Cloud Config
- Hashicorp Vault
- Spring Cloud Vault
- Vault Authentication
- Haufe的Spring Cloud Vault扩展
- 授权的配置服务器
- PKI密钥和信任库集成
- 来自Vault的Trustore配置
- 来自Vault的TLS客户端配置
外化配置
当然,配置挑战并不新鲜,因此我们可以看到经过测试的概念。例如,十二因素应用程序的宗旨是应用程序将通过环境独家配置:几乎每个操作系统和部署模型都支持环境变量,无论您使用哪种语言或框架,它们都可以轻松访问,并且您可以定义它们而不对您的部署工件进行任何修改。
虽然我接受了12因素应用程序方法的情绪,并同意声称部署到新环境(可能在不同的平台上)不应该要求对部署工件进行任何修改,但我不相信结论由十二因素应用程序绘制:不应将这些配置组合在一起。
原因很简单:严格遵循十二因素应用指南可能确实可以保证您始终可以更改应用程序的任何配置方面。但它只是将配置管理的负担放在部署者身上,它无助于解决这一挑战。根据我的经验,它还将使开发人员只公开他们希望从一个环境变为另一个环境的少数参数;所有其他配置将最终融入部署工件中。
最后但并非最不重要的是,通过环境传递敏感的秘密并不适合我:如果你可以保证应用程序运行的VM根本不共享可能没问题 - 在这种情况下,攻击者很可能能够无论如何,读取环境将能够从您的应用程序中提取秘密。但是,如果您将不同的应用程序部署到同一个VM(或针对不同租户的多个应用程序实例),那么我不相信容器化解决方案提供的进程隔离,以使一个容器的环境变量与确定的攻击者保持对另一个容器的访问权限。同一台机器。
如果传递一组配置属性的名称(或者,更具技术性地说,标识符),则可以避免上述问题。唯一的前提条件是您必须随时可以自由地重新组织这些属性集。
确实,这引入了对服务的依赖,以某种方式可以解析这样的配置集标识符;但是,与依赖于您的应用程序必须可以访问的数据库服务相比,这并没有太大的不同。只要此配置服务具有定义良好的API,您就可以在必要时轻松进行模拟。
Spring 服务
回到我刚才提到的项目:它在文档数据库前面使用一组Spring Boot服务。这些服务被打包到部署到小型集群中的Docker映像中。 (到目前为止,Docker Swarm模式对我们来说效果很好。但是如果像Azure管理的Kubernetes服务(AKS)这样的产品让我们的生活变得更简单,我将不排除在未来的某个地方切换到Kubernetes。)
Spring框架引入了带有配置文件和属性源的环境抽象概念。 Spring Boot构建于此环境抽象之上,开箱即用,提供了许多选项,可以将配置属性传递给应用程序:“传统”属性文件,YAML配置文件,JVM系统属性,命令行参数,OS环境变量和等等。最后,所有适用的属性源(根据活动配置文件)都组织在由环境抽象管理的列表中。当应用程序需要特定属性的值时,Spring会遍历此列表并使用定义相关属性的第一个源中的值。由于列表中属性源的顺序,更具体的源可以覆盖“默认”配置。如果属性值引用了某个其他属性,则再次从列表的头部开始查找。当然,可以向环境添加自定义属性源。
Spring Boot配置概念对我们来说效果很好 - 我们可以定义合理的默认配置,配置属性(例如,如果我们激活安全连接,所有TLS设置)可以轻松地分组到特定于配置文件的配置中,我们可以轻松为新的部署目标定义其他配置文件。我们只错过了两个关键功能:配置文件不应嵌入到docker镜像中,并且不得在配置文件中保留数据库用户凭据或私钥等秘密。
Spring Cloud Config
在Dave Syer和Josh Long的SpringDeveloper演示文稿的录制中,我回忆起Spring Cloud Config至少解决了前者的问题。
配置服务器
Spring Cloud Config的服务器部分是一个“普通”Spring Boot Web应用程序,它以简单的JSON结构提供属性源列表。 最好以示例的方式显示:
以下JSON对象是本地配置服务器对URL http:// localhost:9400 / demo / plain-actuator-access,integration-db的GET请求的响应。 第一个URL路径段指定应用程序名称 - 配置服务器实例可以为多个应用程序提供配置。 第二个路径段指定以逗号分隔的应用程序配置文件列表。 Config Server还支持第三个路径段(此处未使用),其标签可用于例如请求特定版本的配置。
{ "name": "demo", "profiles": [ "plain-actuator-access,integration-db" ], "label": null, "version": null, "state": null, "propertySources": [ { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/demo-integration-db.yml", "source": { "demo.db.host": "integrationtest.demo.contenthub.haufe.io" } }, { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/demo-plain-actuator-access.yml", "source": { "management.security.enabled": false } }, { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/demo.yml", "source": { "demo.db.host": "localhost", "demo.db.database": "demo", "demo.db.url": "jdbc:postgresql://${demo.db.host}/${demo.db.database}", "demo.db.user": "${vault.demo.db.user}", "demo.db.password": "${vault.demo.db.passord}", "management.security.enabled": true } }, { "name": "file:///Users/ludwigc/Java/JUG/authenticated-config-server/vault-config-client-demo/configurations/application.yml", "source": { "endpoints.shutdown.enabled": true } } ] }
响应的重要部分是数组propertySources:如果演示应用程序是使用指定的配置文件和类路径中的相应配置文件启动的,则此数组中的每个对象都表示将按此顺序加载到Spring环境中的属性源。
请注意,可以在多个源中定义相同的属性,其中属性源的顺序决定“赢家”。此外,Spring递归地解析占位符(使用$ {...}语法)。仅给出此属性源列表,属性demo.db.url因此解析为jdbc:postgresql://integrationtest.demo.contenthub.haufe.io/demo。
由于这个特定的配置服务实例是从我的IDE中运行的,并且我希望它提供反映我的本地工作空间内容的配置,因此我使用本机配置文件启动了配置服务器 - 使用此配置文件,服务器将配置的文件系统文件夹视为只读配置源。
除非服务器用于本地开发,否则更常见的是让服务器从Git存储库中提取配置。更准确地说,配置服务器指向本地Git存储库或配置为在启动时克隆远程存储库。当客户端请求配置时,服务器从远程存储库中提取所有相关更新,并检出客户端请求中指定为标签的分支或版本。 (如果URL中省略了label,则配置服务器默认为主分支的HEAD。)然后,配置服务器才会读取配置文件。
旁注:Config Server依赖Eclipse的JGit库来实现所有Git功能。不幸的是,JGit仅支持ssh-rsa密钥,并且不了解known_hosts文件中的散列条目。如果已经存在远程Git主机的哈希条目,则很容易导致错误。由于JGit抛出的异常中的错误消息根本不清楚,因此很难诊断出这个问题 - 当我第一次尝试配置服务器时,它花了我几个小时。
如果有疑问,您可以使用ssh-keygen -F bitbucket.org查看您的known_hosts文件是否包含bitbucket.org的密钥。如果对于任何返回的键,第一个字段不以纯文本显示相关的主机名,则需要从known_hosts文件中删除键并添加非散列的ssh-rsa键:
$ ssh-keygen -R bitbucket.org
$ ssh-keyscan -t rsa bitbucket.org >>〜/ .ssh / known_hosts
配置客户端
Spring Cloud Config客户端库从配置服务器获取相关配置属性,并将它们作为属性源插入到您的应用程序环境中。仍然支持所有其他配置选项,环境将只有其他来源。对于您的应用程序代码,属性来自哪里没有任何区别。
当然,配置客户端也需要配置 - 至少,它需要配置服务器的地址。 Spring Boot的引导阶段进入图片:在Spring Boot应用程序开始构建其应用程序上下文(应用程序的Spring bean的所有注入和自动装配)之前,它会创建一个引导上下文,其中包含以后用于的所有组件构建应用程序上下文。其中,引导上下文确定如何设置应用程序上下文的环境。
引导上下文的环境使用每个Spring引导应用程序可用的相同源;唯一的区别是配置文件名为bootstrap.yml和bootstrap-profilename.yml(如果您更喜欢使用传统属性文件,则为bootstrap.properties和bootstrap-profilename.properties)。
如上所述,配置服务器可以在底层存储库中的分支之间切换。属性spring.cloud.config.label控制客户端应用程序请求的版本或分支。我们将gradle-git-properties插件添加到我们项目的Gradle构建中,从而构建应用程序的分支在运行时被称为属性git.branch。通过在bootstrap.yml中设置spring.cloud.config.label = $ {git.branch},我们使应用程序从与源分支匹配的分支中获取配置。如果要测试添加或更改配置属性的功能分支,这非常方便。
回顾十二因素应用程序的配置方法,我们可以在应用程序的bootstrap.yml中使用一些默认的配置客户端属性(适用于本地开发),并在部署时使用环境覆盖,例如,配置服务器端点变量。配置服务器地址不敏感,只有很少的属性在部署之间变化,因为环境变量方法可以很好地管理。
作为应用程序运行状况检查的一部分,配置客户端还会定期从服务器重新加载配置。大多数情况下,环境只在应用程序上下文初始化期间读取,因此重新加载不会产生太大影响 - 除非您使用@RefreshScope注释bean。这似乎是即时更改的一个很好的功能,但我还没有第一手的经验。
Hashicorp Vault
使用Spring Cloud Config,我们提供存储在Git存储库中的配置 - 在我们的示例中,在实际的代码存储库中。到目前为止,您应该知道不应该在Git存储库中存储明确的秘密 - 至少,必须使用与存储库分开存储的密钥正确加密机密。 (几年前,一些开发人员在亚马逊收取未经授权的用户可能使用的资源时收取的费用很难,因为在公共存储库中找到了AWS凭据。)
很少有开发人员是密码学专家,因此加密正确很难。并且您不希望保留大量其他代码来拦截您的配置属性,并在应用程序使用它们之前对其进行解密。最后,您最好使用像Hashicorp Vault这样的专用秘密商店解决方案。
Hashicorp Vault是一种安全访问秘密的工具,可以在休息时处理秘密的加密,可以在审计日志中记录任何秘密访问,并附带精心设计的访问控制概念。它还支持动态机密,例如即时创建的数据库密码,一旦相应的Vault令牌过期,它将自动被删除。与Vault实例的所有交互都通过其(通常是TLS安全的)REST接口进行。
我们在通用秘密商店之上使用的功能之一是Vault的PKI后端,可以颁发X.509证书;它本质上提供私人CA. (CA的注册机构事实上是由Vault的角色和访问控制实现实现的。)对于客户和合作伙伴(包括Haufe内的其他项目)访问的端点,我们当然配置由“众所周知的”CA之一颁发的TLS证书;感谢Let's Encrypt,现在获取您的客户可能信任的证书已经不再麻烦了。但在我们的应用程序中,我们需要通过TLS和客户端身份验证来保护一些内部通信路径。我们的加密不会发出客户端证书,因此通过Vault的REST接口可访问的私有CA使操作更加简单。
Spring Cloud Vault
与Spring Cloud Config类似,Spring Cloud Vault客户端将其他属性源插入Spring Boot应用程序的环境中。但是,这些属性是存储在Vault中的机密。
您甚至可以拥有特定于配置文件的机密:Vault将机密存储为JSON对象;您可以通过类似于文件系统路径的分层路径名来解决这些JSON对象,从相应的秘密插件的安装名称开始。
haufe-lexware-blog-chludwig ludwigc$ vault read -format=json local-secrets/ch-integrationtests/CHinteg { "request_id": "0ca07792-c7da-625b-0dd7-57b794fb9856", "lease_id": "", "lease_duration": 604800, "renewable": false, "data": { "vault.content.apiKey": "*********", "vault.content.clientId": "*********", "vault.content.clientSecret": "*********", "vault.ingest.apiKey": "*********", "vault.ingest.clientId": "*********", "vault.ingest.clientSecret": "*********" }, "warnings": null }
当我在路径local-secrets / ch-integrationtests / CHinteg查询对象时,您会看到我从本地Vault实例获得的响应(我用星号标记的实际机密值)。 实际的秘密存储在数据对象中。 鉴于Spring Boot应用程序ch-integration在配置文件CHinteg中运行,Spring Cloud Vault客户端将从Vault位置获取秘密local-secrets / ch-integrationtests / CHinteg,local-secrets / ch-integrationtests,local-secrets / defaultContext / CHinteg 和local-secrets / defaultContext。 defaultContext是应用程序的bootstrap.yml中指定的名称; 它意味着保存多个应用程序共享的秘密。
如果在应用程序中同时激活Spring Cloud Config和Vault,下图显示了数据流:
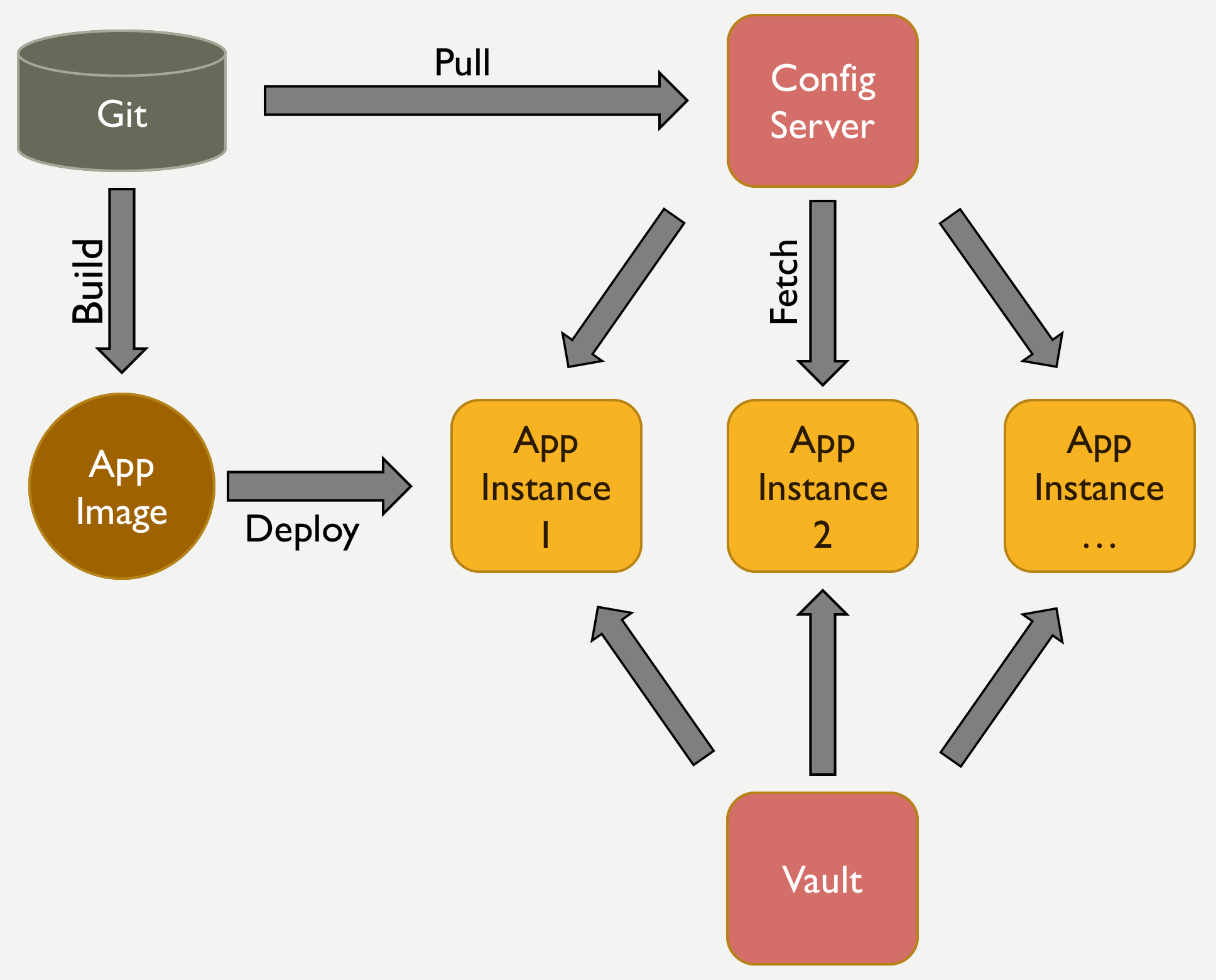
Vault 验证
Spring Cloud Vault支持与服务身份验证相关的Vault身份验证方法;其中,支持AppRole和Token身份验证。 Spring Cloud Vault客户端还负责令牌续订。但是,我们如何将必要的凭据传递给我们的应用程序实例?毕竟,Vault凭据至少与Vault中可访问的最敏感秘密一样有价值。
在项目中,我们有两种类型的应用程序:
1.批量作业,例如,每天运行一次,并且分别仅作为单个实例启动。
在这里,Vault与AppRole身份验证一起使用的一次性秘密ID非常匹配:部署管道从Vault首次使用后请求新的secret-id。这个secret-id通过一个环境变量传递给应用程序。应用程序将立即将此秘密ID替换为Vault令牌 - 之后,secret-id无用。因此,潜在的攻击者只有非常小的时间窗口才能窃取和使用secret-id。
即使攻击者成功,也不会被忽视:如果攻击者使用了secret-id,应用程序的登录尝试将失败。必须将其记录为安全事件,以便立即做出响应。
2. 部署到Docker Swarm集群中的长时间运行的服务。
某些服务被复制,因此在部署后多个应用程序实例需要登录到Vault - 一次性secret-id是不够的。 n-time secret-id(其中n是服务实例的数量)不会削减它,因为集群可以随时自由重启服务实例,以便将实例移动到另一个工作节点。因此,我们必须将一个秘密ID传递给不能进入攻击者手中的服务实例。
幸运的是,Docker Swarm Mode可以与服务实例共享秘密。 (Kubernetes具有类似的功能。)首先,部署管道要求Vault提供新的机密ID,并将其作为集群中的密钥存储。 Docker通过相互认证的TLS连接将密钥发送到集群管理器,并在集群的Raft存储中加密静态的秘密:
$ vault write -f –format=json auth/approle/role/myapprole/secret-id |\ jq -r '.secret_id' |\ docker secret create myapprole_secretid -
其次,部署管道请求swarm启动我们的服务,并使上面创建的秘密可用于服务实例。该秘密将映射到服务实例的容器文件系统,但此挂载仅保留在内存中:
$ docker service create --name="myapp" \ --secret="myapprole_secretid" myapp:alpine
请注意,secret-id的值永远不会出现在命令行或环境变量中。
Haufe的Spring Cloud Vault扩展
在我们使用Spring Cloud Config和Vault时,我们遇到了开箱即用的其他要求。幸运的是,它们提供了足够的定制钩子。
授权的配置服务器
我们拆分了配置属性:敏感属性存储在Vault中,其余属性在我们的Git存储库中管理,并通过Spring Config Server提供给应用程序实例。因此配置服务器不会泄露秘密。
然而,配置服务器提供了对应用程序内部结构的更多洞察,而不是我们想要自由地分发给潜在的攻击者。这不是“默默无闻”的尝试,但不必要的信息暴露(CWE-200)仍然可以帮助攻击者进行攻击。如果可以通过Internet访问配置服务器,或者通过Intranet访问公司的大多数公司,那么我们需要一些客户端身份验证。
基于TLS的HTTP基本身份验证应该足以达到此目的(假设密码足够强)。这也很容易实现 - 我们所要做的就是将Spring Security添加到Spring Config Server。配置服务器中的Spring Cloud Vault客户端从Vault获取凭据,因此Spring Security配置可以设置内存中的用户存储 - 这是一般的Spring Boot服务开发。
在客户端,情况更棘手:使用这种安全配置服务器的服务实例需要访问凭据作为其配置客户端引导程序设置的一部分。凭据是秘密,保存在Vault中。但是,Spring Cloud Vault提取的属性仅在“常规”应用程序上下文环境中可见,它们在引导环境中不可用!
我仔细阅读了文档并使用调试器逐步完成了Spring Boot应用程序初始化代码。我曾希望我能告诉Spring Boot(例如,通过添加@Order注释)来首先从Vault加载秘密,然后才开始初始化Spring Cloud Config客户端 - 无济于事。无论我尝试了什么,Config Client都从未看到Vault客户端读取的属性。
当我再次浏览Spring Cloud Config文档时,我终于有了一个想法:Spring Cloud Config客户端支持服务发现。 Spring Cloud附带了例如Eureka或Consul的实现,并且在其典型用例中,客户端将通过发现来学习配置服务器的地址。但与大多数Spring功能一样,很容易提供发现客户端的自定义实现;并且发现客户端界面支持基本身份验证凭据。以下显示了剥离文档,日志记录和大多数错误处理的发现客户端实现的核心:
public class VaultBasedDiscoveryClient implements DiscoveryClient { public static final String CONFIG_SERVICE_ID = "configserver"; public static final String URI_PROPERTY_NAME = "spring.cloud.config.uri"; public static final String USERNAME_PROPERTY_NAME = "spring.cloud.config.username"; public static final String PASSWORD_PROPERTY_NAME = "spring.cloud.config.password"; public static final String CONFIG_PATH_PROPERTY_NAME = "spring.cloud.config.configPath"; private final ConfigClientProperties configClientProperties; private final PropertySourceLocator vaultPropertySourceLocator; private final Environment environment; private final Supplier<List<ServiceInstance>> memoizedConfigServiceListSupplier; public VaultBasedDiscoveryClient(ConfigClientProperties configClientProperties, PropertySourceLocator vaultPropertySourceLocator, Environment environment) { this.configClientProperties = configClientProperties; this.vaultPropertySourceLocator = vaultPropertySourceLocator; this.environment = environment; } @Override public String description() { return "Vault-based Discovery Client"; } @Override @Deprecated public ServiceInstance getLocalServiceInstance() { return null; } @Override public List<ServiceInstance> getInstances(String serviceId) { VaultBasedConfigServiceInstance serviceInstance = null; if (CONFIG_SERVICE_ID.equals(serviceId)) { serviceInstance = createServiceInstance(); } return serviceInstance != null ? Collections.singletonList(serviceInstance) : Collections.emptyList(); } @Override public List<String> getServices() { return Collections.singletonList(CONFIG_SERVICE_ID); } private VaultBasedConfigServiceInstance createServiceInstance() { PropertySource<?> vaultPropertySource = vaultPropertySourceLocator.locate(environment); URI uri = getUri(vaultPropertySource); if (uri == null) { return null; } String userInfo = uri.getUserInfo(); String username = getUsername(vaultPropertySource, userInfo); String password = getPassword(vaultPropertySource, userInfo); String configPath = getVaultProperty(CONFIG_PATH_PROPERTY_NAME, vaultPropertySource, null); return new VaultBasedConfigServiceInstance(CONFIG_SERVICE_ID, uri, username, password, configPath); } private URI getUri(PropertySource<?> vaultPropertySource) { String uriString = getVaultProperty(URI_PROPERTY_NAME, vaultPropertySource, configClientProperties.getUri()); try { return StringUtils.isNotBlank(uriString) ? new URI(uriString) : null; } catch (URISyntaxException e) { return null; } } private String getUsername(PropertySource<?> vaultPropertySource, String userInfo) { String defaultUsername = configClientProperties.getUsername(); if (userInfo != null) { String[] userInfoParts = userInfo.split(":", 2); defaultUsername = userInfoParts[0]; } return getVaultProperty(USERNAME_PROPERTY_NAME, vaultPropertySource, defaultUsername); } private String getPassword(PropertySource<?> vaultPropertySource, String userInfo) { String defaultPassphrase = configClientProperties.getPassword(); if (userInfo != null) { String[] userInfoParts = userInfo.split(":", 2); if (userInfoParts.length > 1) { defaultPassphrase = userInfoParts[1]; } } return getVaultProperty(PASSWORD_PROPERTY_NAME, vaultPropertySource, defaultPassphrase); } private String getVaultProperty(String propertyName, PropertySource<?> vaultPropertySource, String defaultValue) { Object property = vaultPropertySource.getProperty(propertyName); if (property != null) { return property.toString(); } return defaultValue; } }
如果使用服务标识“configserver”调用VaultBasedDiscoveryClient#getInstances(String serviceId),则它会将请求委派给VaultBasedDiscoveryClient#createServiceInstance(),然后从VaultPropertySourceLocator提供的PropertySource读取所需的属性。 后一类是Spring Cloud Vault的一部分,可以访问从Vault检索的属性。
用户名和密码也在ConfigClientProperties的实例中查找,ConfigClientProperties是Spring Cloud Config客户端的类型安全配置类。 这样,如果Vault中未指定属性,我们仍然可以使用配置客户端的“标准”配置作为后备。
您可能已经注意到VaultBasedDiscoveryClient上没有任何Spring注释 - 它不是@Component或类似的。 将SpringBasedDiscoveryClient实例创建为Spring bean则是配置类VaultBasedDiscoveryClientAutoConfiguration的任务:
@Configuration @ConditionalOnExpression("${haufe.cloud.config.vaultDiscovery.enabled:true} and ${spring.cloud.vault.enabled:true}") @ConditionalOnMissingBean(VaultBasedDiscoveryClient.class) @AutoConfigureAfter(RefreshAutoConfiguration.class) @Import(VaultBootstrapConfiguration.class) public class VaultBasedDiscoveryClientAutoConfiguration { @Resource(name = "vaultPropertySourceLocator") private PropertySourceLocator vaultPropertySourceLocator; @Bean DiscoveryClient discoveryClient(@Autowired ConfigClientProperties configClientProperties, @Autowired Environment environment) { return new VaultBasedDiscoveryClient(configClientProperties, vaultPropertySourceLocator, environment); } }
这个类是Spring Boot部分的一个例子我不是那么热衷于:对我来说,至少,对注释的这种蔑视总是让人很难理解它们的净效应。
无论如何,让我们试一试:
- @Configuration将此类声明为应用程序上下文中Spring bean的贡献者,具体取决于以下注释中的条件。
- 注释@ConditionalOnExpression要求两个属性haufe.cloud.config.vaultDiscovery.enabl…,否则将忽略此配置类。
- 由于@ConditionalOnMissingBean批注,仅当没有通过其他方式实例化VaultBasedDiscoveryClient bean时,才会使用此配置类。
- @AutoConfigureAfter(RefreshAutoConfiguration.class)告诉Spring,只有在Spring的日志记录设置等完成后才应用此配置。
- @Import(VaultBootstrapConfiguration.class)从Spring Cloud Vault的自动配置中加载bean定义 - 特别是名为vaultPropertySourceLocator的bean。
通过类路径上的VaultBasedDiscoveryClientAutoConfiguration(并启用),配置客户端将引用VaultBasedDiscoveryClient以获取其自己的配置,并从Vault加载所需的属性(包括配置服务器凭据)。
PKI密钥和信任库集成
TLS密钥材料的管理通常是令人厌烦的任务。像openssl或Java的keytool这样的工具使用起来不是很直观,很少有开发人员熟悉所有选项。不幸的是,您的应用程序仍然按预期工作的事实并不意味着您的安全性足够强大。因此,更重要的是我们自动处理TLS密钥和信任存储,以避免由于手动操作而导致的未检测错误。
在许多情况下,您可以利用像Let's Encrypt这样的服务 - 以完全自动化的方式 - 发布大多数客户信任的证书。但您仍需要以安全的方式为您的应用程序提供密钥材料。如果您的服务不公开,那么您有时最好使用私有证书颁发机构颁发的证书。特别是,如果您依赖相互身份验证的TLS来保护服务之间的连接,则通常会出现这种情况。
传统上,我们曾经将带有必要密钥材料的密钥(和/或信任)存储文件放入文件系统中,应用程序可以从中加载它们。当然可以将这些密钥库作为通用机密存储在库中,并在应用程序启动之前将它们下载 - 例如,作为Docker入口点脚本的一部分 - 下载到Docker tmpfs mount中的文件夹中。这会将密钥和证书分发给应用程序实例,但您仍需要准备密钥库才能将其上载到Vault中。
Mark Paluch在他的示例代码中演示了如何使Spring Boot应用程序的嵌入式Web服务器直接从Vault加载TLS密钥(即,不触及文件系统)。如果您将Vault的PKI后端用作私有CA,则服务甚至可以即时请求新证书。
实际上,示例代码侧重于后一部分。但它会在通用秘密存储中缓存已颁发的证书,并在可能的情况下从那里加载它们。这可以很容易地适应我们将从外部CA获取的密钥和证书上载到Vault的情况。
我们将服务代码扩展为从库中加载信任库。诚然,信托商店不需要保密;但是,您必须保证信任存储的完整性,否则攻击者可能会使您的应用程序接受由攻击者颁发的证书或为攻击者颁发的证书。此外,我们还添加了配置TLS客户端的功能。
来自Vault的Trustore配置
作为Spring Vault的一部分实现的CertificateBundles包括私钥的Base64字符串表示,证书,颁发者证书以及证书的序列号。 Mark Paluch的示例代码包括EmbeddedServletContainerCustomizer,它使嵌入式Web容器使用Vault中的CertificateBundleread内容进行TLS服务器身份验证。不幸的是,它始终注入一个仅包含服务器证书的颁发者证书的信任库。由于CA颁发服务器证书或客户端证书(但不是两者)非常常见,因此此信任库设置不符合我们的要求。
因此,我们决定从Vault加载受信任的证书。我们扩展的TrustedCertificates类非常简单 - 它包含信任库条目的列表,信任库条目又包含证书的Base64字符串表示以及Java用来引用证书的证书别名。我们添加到CertificateUtils的readTrustedCertificates(VaultOperations,String)方法从Vault读取这样的TrustedCertificates对象。由Spring Vault实现的VaultOperations #read(String,Class <T>)处理所有“繁重的工作”。
TrustedCertificates#createTrustStore()从这些条目构建内存中的Java KeyStore。为方便用户,实现剥离PEM证书开始和结束标记,并从证书表示中删除所有空格。这使得可以以PEM或Base64编码的DER格式将证书存储在Vault中。
通过这些扩展,我们可以在VaultPkiConfiguration中修改EmbeddedServletContainerCustomizer的实现,以便它注入从Vault获取的信任库,或者 - 如果没有配置此信任库,则为JVM的默认信任库的副本。
来自Vault的TLS客户端配置
到目前为止,我们讨论了Spring Boot应用程序的嵌入式servlet容器的配置。通常,您的应用程序还充当后端服务的HTTP客户端,并且客户端还需要自定义TLS配置 - 也许该服务使用来自私有CA的证书,JVM默认不信任该私有CA,或者您的客户端必须使用X.509客户端证书。
Spring @Configuration类ServiceClientTLSConfig创建一个TLSClientKeyMaterial Spring bean,它捆绑私钥材料(即密钥库,密钥库密码和密钥密码)以及信任材料(即信任库和信任库密码)。如果spring.cloud.vault.enabled和haufe.client.ssl.vault.enabled都为真且如果Spring上下文中有可用的VaultOperations bean(即Spring Vault可用且已激活),则TLSClientKeyMaterial将初始化为从Vault通用秘密后端读取的值。用于在Vault中存储密钥材料的数据格式与服务器密钥材料的数据格式相同。
在某些情况下(如针对后端服务的集成实例的本地开发),在文件系统上使用密钥和信任存储可能仍然更方便。 ServiceClientTLSConfig适应这种情况;只需将haufe.client.ssl.vault.enabled设置为false,然后将从文件系统初始化TLSClientKeyMaterial。这是由Spring Boot的bean创建方法的@ConditionalOnXYZ注释控制的:ServiceClientTLSConfig #tlsClientKeyMaterialFromVault(ServiceClientTLSProperties,VaultOperations)仅在满足上述所有条件时才会被调用。在所有其他情况下,ServiceClientTLSConfig#tlsClientKeyMaterialFromFilesystem(ServiceClientTLSProperties)从文件系统加载密钥材料。 (乍一看,使用@ConditionalOnXYZ可能看起来有点过分;但是,如果我们想在关闭Vault支持的情况下运行应用程序,它会避免不满意的Spring bean依赖关系,因为那时不会有VaultOperations bean。)
当然,如何使HTTP客户端使用密钥材料取决于您的HTTP客户端实现。演示存储库包含模块demo-service-frontend中的示例:组件ClientHttpRequestFactoryConfigurer使用Spring注入构造函数的TLCLientKeyMaterial bean来设置SSLContext,而SSLContext又用于构造HttpComponentsClientHttpRequestFactory。我希望其他客户端实现的设置看起来类似。
原文:http://work.haufegroup.io/spring-cloud-config-and-vault/
本文:https://pub.intelligentx.net/externalized-configuration-spring-cloud-config-and-vault
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 138 次浏览
【微服务架构】单片到微服务架构的模式和最佳实践
在本文中,我们将学习如何使用设计模式、原则和最佳实践来设计微服务架构。 我们将使用正确的架构设计模式和技术。
在本文结束时,您将了解如何在微服务分布式架构上设计系统以实现高可用性、高可扩展性、低延迟和对网络故障的弹性,从而处理数百万个请求。
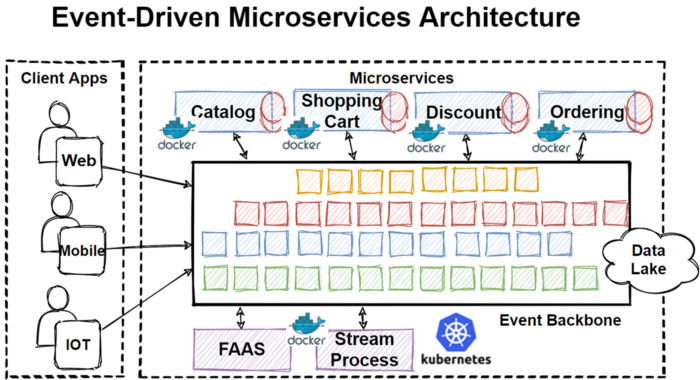
Event-Driven Architecture
本课程将是软件架构设计的旅程,逐步将架构单片演变为事件驱动的微服务。
我们将从设计处理少量请求的电子商务整体架构开始软件架构的基础知识。
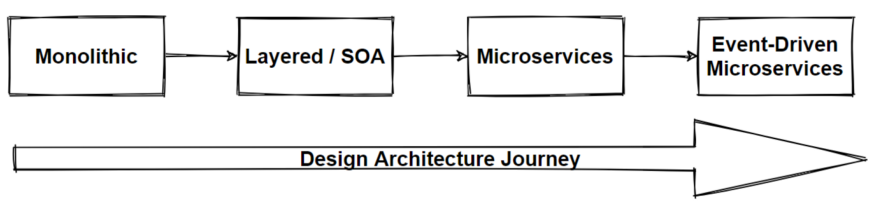
Journey of Design Architectures
之后逐步演变架构
- 分层架构
- SOA
- 微服务
- 最后是事件驱动的微服务架构
一起设计处理数百万个请求。
带课程的逐步设计架构
在本课程中,我们将学习如何使用设计模式、原则和最佳实践来设计微服务架构。我们将从设计单体到事件驱动的微服务开始,并一起使用正确的架构设计模式和技术。
文章流
在文章流中将既有理论信息又有实践信息;
- 我们将学习一个特定的模式,我们应该使用的原因和位置
- 之后,我们将看到应用这些模式的参考架构
- 之后,我们将应用这个新学习的模式来设计我们的架构
- 最后,我们将决定哪些技术可以作为该架构的选择。
所以我们将迭代和演化架构单体到事件驱动的微服务架构。
架构演进
我们将根据问题发展这些架构
- 我们如何扩展应用程序?
- 我们的应用程序需要处理多少个请求?
- 我们的拱门可以接受多少秒的延迟?
因此,我们根据以下问题演变这些问题;

可扩展性和可靠性是衡量您的应用程序对最终用户的服务程度的衡量标准。 如果我们的电子商务应用程序可以在没有明显停机的情况下为数百万用户提供服务,那么我们可以说该系统具有高度可扩展性和可靠性。 可扩展性和可用性可能是设计良好架构的主要因素。
- 可扩展性=电子商务应用程序应该能够为数百万用户提供服务
- 可用性 = 电子商务应用程序应该 24/7 可用
- 可维护性=电子商务应用程序应该发展几年
- 效率 = 电子商务应用程序应响应可接受的延迟,
- 例如 < 2 秒 - 短响应延迟
每秒请求和可接受的延迟
好的,让我们谈谈可接受的延迟,
如果我们的应用程序被越来越多的用户使用,我们如何使我们的应用程序具有可接受的延迟?
请看表格;

正如您在表中看到的,我们将启动一个小型电子商务应用程序,该应用程序仅获得 2K 并发用户,每秒获得 500 个请求。
我们将根据这些预期数量设计我们的电子商务架构。
在那之后,当我们的业务不断发展壮大时,它将需要更多的资源来容纳更大的请求数量,我们将看到如何根据这些数字来发展我们的架构。
单体架构
经过几十年的软件开发,有许多方法和模式演变而来,它们都有自己的好处和挑战。
因此,我们将从了解构建我们的电子商务应用程序的现有方法开始,然后发展和迁移到云。
为了理解云原生微服务,我们需要了解什么是单体应用程序,以及我们是如何从单体转向微服务的。
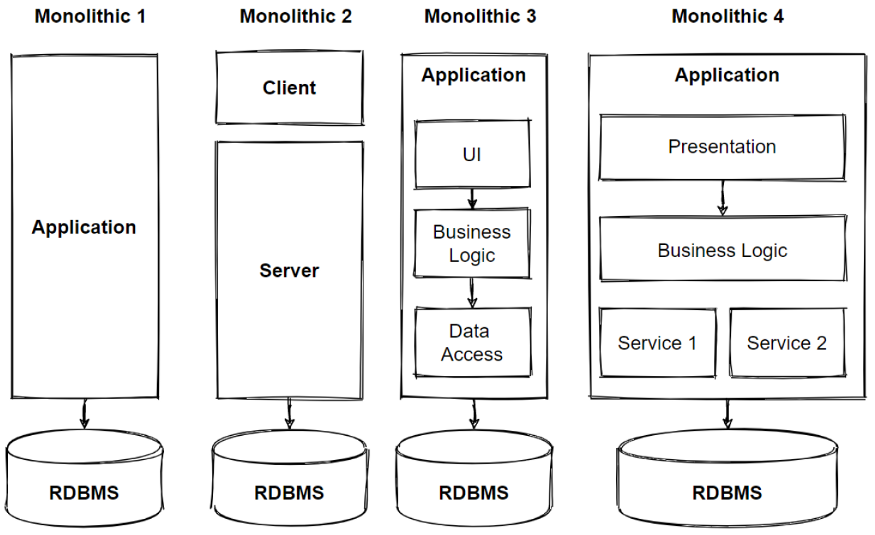
对于遗留应用程序,我们可以说大多数遗留应用程序主要是作为一个单体架构来实现的。
如果一个项目的所有功能都存在于一个代码库中,
那么该应用程序被称为单片应用程序。在单体模式中,用户界面、业务代码和数据库调用等所有内容都包含在同一个代码库中。
所有应用程序关注点都包含在一个大型部署中。
即使是单体应用程序也可以在不同的层(如表示层、业务层和数据层)中进行设计,然后将该代码库部署为单个 jar/war 文件。
整体方法有几个优点,我们将在接下来的视频中讨论它们。但让我在这里说一些主要的优点和缺点。
由于它是单个代码库,因此很容易拉取并开始项目。
由于项目结构在 1 个项目中,并且易于调试跨不同模块的业务交互。
不幸的是,单体架构有很多缺点,我们可以这样说;
- 随着时间的推移,它的代码量变得太大,这就是为什么它真的很难管理。
- 难以在同一代码库中并行工作。
- 难以在遗留的大型单体应用程序上实现新功能
- 任何更改都需要部署整个应用程序的新版本。
等等..
如您所见,我们了解单体架构。
何时使用单体架构
即使是单体架构也有很多缺点,如果您正在构建小型应用程序,那么单体架构仍然是您可以应用于项目的最佳架构之一。因为,在许多方面,单体应用程序都很简单。
它们很简单:
- 建造
- 测试
- 部署
- 疑难解答
- 垂直缩放(放大)
- 非常简单快捷。
相对于需要熟练的开发人员来识别和开发服务的微服务,开发起来很简单。由于只部署了一个 jar/war 文件,因此更易于部署。
设计单体架构
在本节中,我们将逐步设计具有单体架构的电子商务应用程序。
我们将根据需求一一迭代架构设计。
我们应该始终从写下 FR(功能要求)和 NFR(非功能要求)开始。
功能要求
- 列出产品
- 按品牌和类别过滤产品
- 将产品放入购物车
- 申请折扣券并查看购物车中所有商品的总费用
- 结帐购物车并创建订单
- 列出我的旧订单和订单商品历史
非功能性要求
- 可扩展性
- 增加并发用户
此外,最好在我们的图片中添加原则以便始终记住它们。
原则
- KISS
- YAGNI
我们将在设计架构时考虑这些原则。
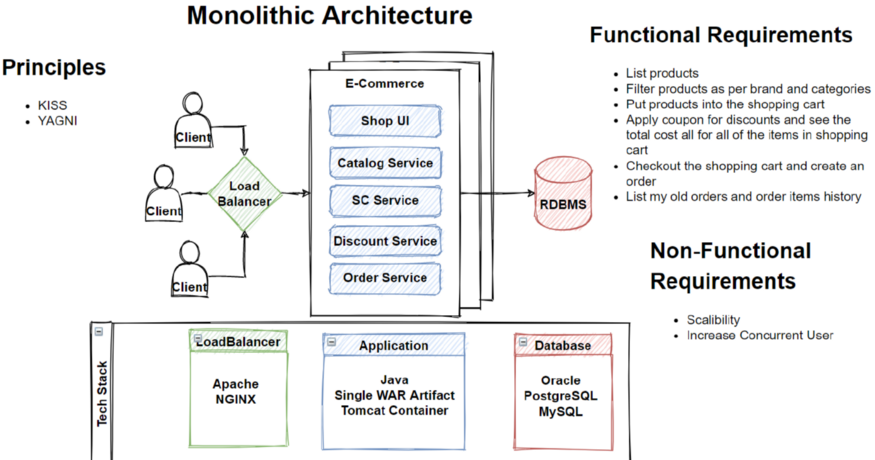
如您所见,我们使用单体架构设计了我们的电子商务应用程序。
我们添加了大电子商务框,我们的电子商务应用程序的组件是什么;商店 UI、目录服务、SC 服务、折扣服务、订单服务。如您所见,这个传统 Web 应用程序的所有模块都是容器中的单个工件。
这个单体应用程序有一个包含所有模块的庞大代码库。如果向该应用程序引入新模块,则必须对现有代码进行更改,然后将具有不同代码的工件部署到 Tomcat 服务器。我们遵循我们的 KISS 原则,即保持简单。
我们将根据需求重构我们的设计,并逐步迭代在一起。
单体架构的可扩展性
如您所见,我们通过添加 2 个应用服务器并在客户端和电子商务应用程序之间的单体应用程序前面放置负载均衡器,通过水平扩展来扩展单体架构。
为了在单体架构上提供可扩展性。我们需要创建电子商务应用服务器。并将负载均衡器放在我们的应用程序前面。
基本上,负载均衡器将使用一致的哈希算法来容纳请求并将请求发送到我们的电子商务应用程序服务器。这将为服务器提供同等负载。
适配技术栈
我们将讨论技术选择——适应技术堆栈。
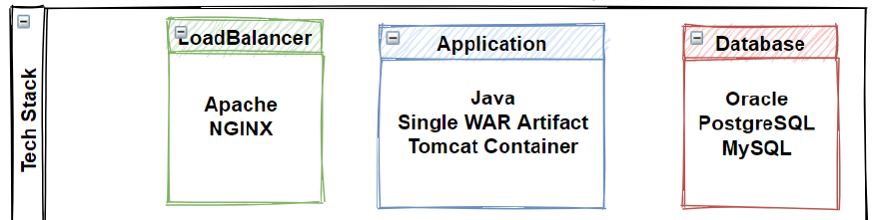
正如您所看到的图像,我们已经为我们的电子商务整体应用程序选择了潜在的选项。 NGINX 是负载平衡和 Java 的非常好的选择——Oracle 是此类应用程序的标准实现。
微服务架构
微服务是可以协同工作并且可以自主/独立部署的小型企业服务。
来自 Martin Fowlers 微服务文章;
微服务架构风格是一种将单个应用程序开发为一组小服务的方法,每个服务都在自己的进程中运行并与轻量级机制(通常是 HTTP 或 gRPC API)进行通信。
所以我们可以说,微服务架构是一种云原生架构方法,其中应用程序由许多松散耦合且可独立部署的较小组件组成。
微服务
- — 拥有自己的技术栈,包括数据库和数据管理模型;
- — 通过 REST API、事件流和消息代理的组合相互通信;
- — 按业务能力组织,分隔服务的线通常称为有界上下文。
在接下来的部分中,我们还将看到如何将微服务与有界上下文解耦。
微服务特征
微服务体积小、独立且松耦合。一个小型开发团队可以编写和维护服务。每个服务都是一个单独的代码库,可以由一个小型开发团队管理。
服务可以独立部署。团队无需重建和重新部署整个应用程序即可更新现有服务。
服务负责保存自己的数据或外部状态。这与传统模型不同,在传统模型中,单独的数据层处理数据持久性。
微服务架构的好处
敏捷。
- 微服务最重要的特征之一是因为服务更小且可独立部署。
- 小而专注的团队。
- 微服务应该足够小,以至于单个功能团队可以构建、测试和部署它。
可扩展性。
- 微服务可以独立扩展,因此您可以扩展需要较少资源的子服务,而无需扩展整个应用程序。
微服务架构的挑战
复杂。
微服务应用程序有很多服务需要协同工作并且应该创造价值。由于有很多服务,这意味着比单体应用程序有更多的移动部件。
网络问题和延迟。
因此,由于微服务很小并且与服务间通信进行通信,我们应该管理网络问题。
数据的完整性。
微服务有自己的数据持久化。因此,数据一致性可能是一个挑战。
设计微服务架构
在本节中,我们将逐步设计微服务架构。 根据需求一一迭代拱设计。
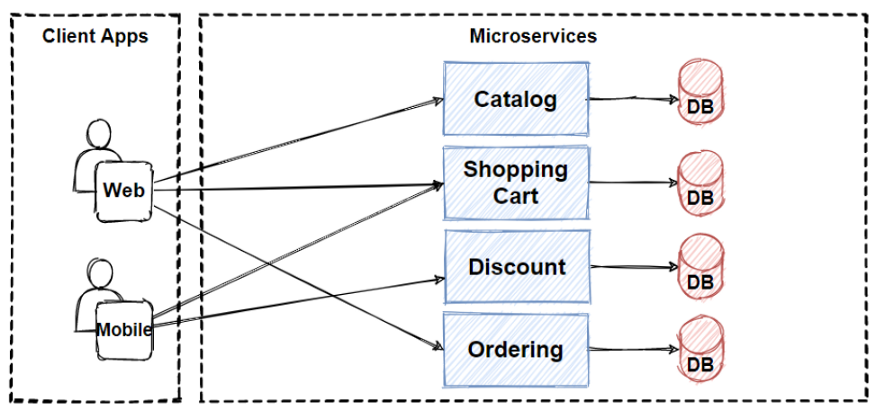
我们在设计微服务架构和放置所有微服务的数据库时遵循了每服务数据库模式。 微服务由具有独立服务的单体应用程序模块分解而成。
所以现在这些数据库可以是多语言持久化的。 也就是说 Product ms 可以使用 NoSQL 文档数据库 SC ms 可以使用 NoSQL 键值对数据库, Order ms 可以根据 ms 数据存储要求使用 Relational 数据库。
发展架构
让我们看看微服务架构图,想想这个架构缺少什么? 这种架构的痛点是什么? 我们如何将这种架构发展为更好的架构,以提高可扩展性、可用性,能够容纳更多并发请求?
看到 UI 和 Microservices 通信是直接的,而且似乎很难管理通信。
我们现在应该专注于微服务通信!
微服务通信
迁移到基于微服务的应用程序时,最大的挑战之一是改变通信机制。因为微服务是分布式的,微服务之间通过网络级别的服务间通信进行通信。每个微服务都有自己的实例和进程。
因此,服务必须使用服务间通信协议(如 HTTP、gRPC 或消息代理 AMQP 协议)进行交互。
由于微服务是独立开发和部署的服务的复杂结构,因此我们在考虑通信类型并将它们管理到设计阶段时应该小心。
微服务通信设计模式——API网关模式
如果您想设计和构建具有多个客户端应用程序的基于微服务的复杂应用程序,建议使用 API 网关模式。
该模式提供了一个反向代理来将请求重定向或路由到您的内部微服务端点。 API 网关为客户端应用程序提供单个端点,并在内部将请求映射到内部微服务。我们应该在客户端和内部微服务之间使用 API 网关。
API 网关可以处理授权等横切问题
因此,无需编写每个微服务,授权可以在集中式 API 网关中处理并发送到内部微服务。 api 网关还管理到内部微服务的路由,并能够在 1 个响应中聚合多个微服务请求。
总之,API 网关位于客户端应用程序和内部微服务之间。它充当反向代理并将请求从客户端路由到后端服务。它还提供横切关注点,如身份验证、SSL 终止和缓存。
设计 API 网关 — 微服务通信设计模式
我们将通过添加 API 网关模式来迭代我们的电子商务架构。
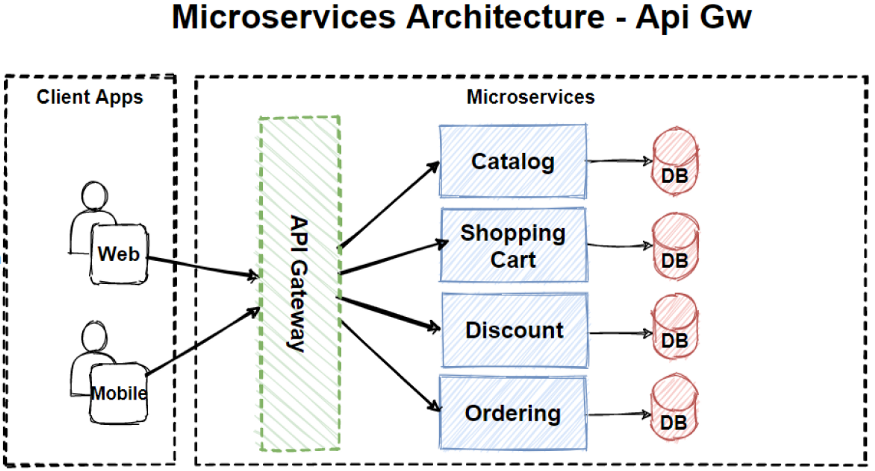
您可以看到在单个入口点收集客户端请求并将请求路由到内部微服务的图像。
这将处理客户端请求并路由内部微服务,
还将多个内部微服务聚合到单个客户端请求中
并执行横切关注点,如身份验证和授权、速率限制和节流等。
发展架构
我们将继续发展我们的架构,但请查看当前的设计并思考如何改进设计?
这里有几个客户端应用程序连接到单个 API 网关。
我们应该小心这种情况,因为如果我们在这里放置一个单独的 api 网关,这意味着这里可能存在单点故障风险。
如果这些客户端应用程序增加,或者为 API 网关中的业务复杂性添加更多逻辑,这将是反模式。
所以我们应该用 BFF-backends-for-frontends 模式来解决这个问题。
Backends for Frontends 模式 BFF — 微服务通信设计模式
前端模式的后端基本上根据特定的前端应用程序分离 api 网关。所以我们有几个后端服务被前端应用程序使用,在它们之间我们放置 API 网关来处理路由和聚合操作。
但这会导致单点故障,所以为了解决这个问题,BFF 提供了创建多个 API 网关并根据它们的边界对客户端应用程序进行分组并将它们拆分为不同的 API 网关。
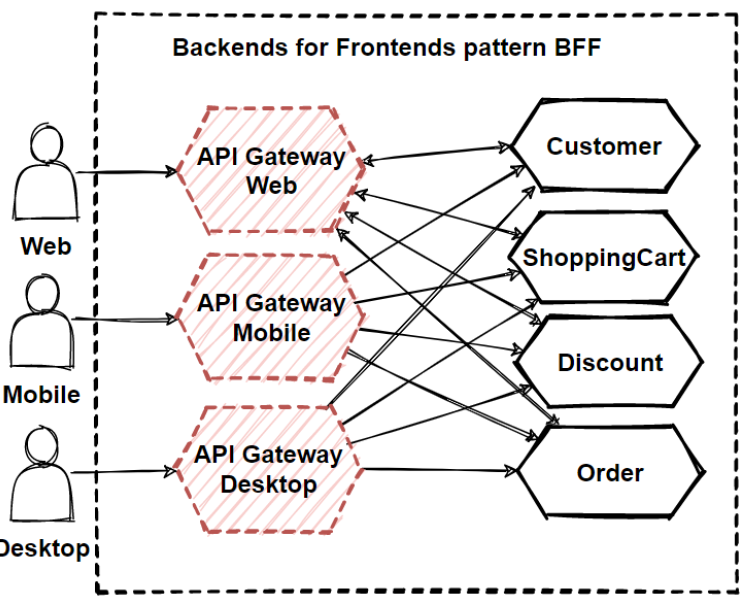
单个复杂的 api 网关可能存在风险,并成为您架构的瓶颈。 较大的系统通常通过对客户端类型(如移动、Web 和桌面功能)进行分组来公开多个 API 网关。 当您想避免为多个接口定制单个后端时,BFF 模式很有用。
所以我们应该根据用户界面创建几个 api 网关。
这些 api 网关提供最匹配前端环境的需求,而无需担心影响其他前端应用程序。
Backend for Frontends 模式为实现多个网关提供了方向。
为前端模式 BFF 设计后端 — 微服务通信设计模式
我们将根据后端模式 BFF 添加更多 API 网关模式来迭代我们的电子商务架构。
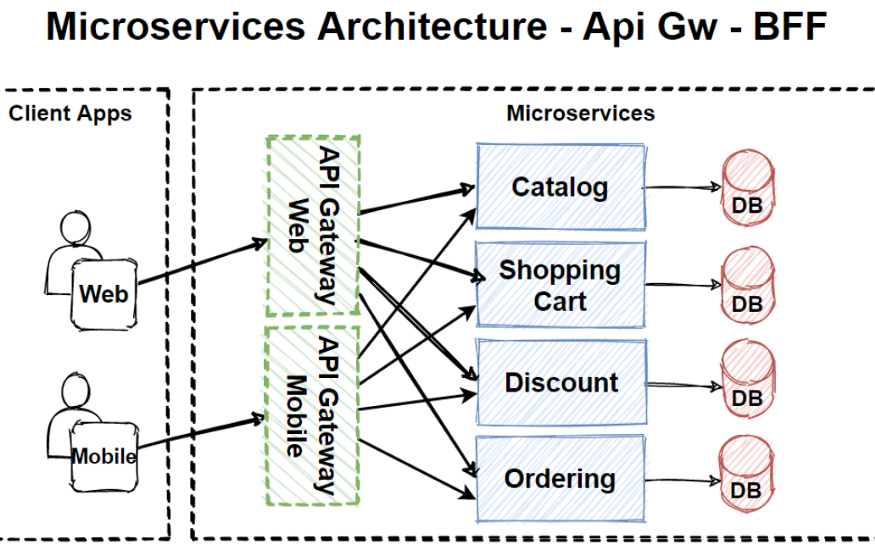
如您所见,我们在应用程序中添加了多个 API 网关。 这些 api 网关提供最匹配前端环境的需求,而无需担心影响其他前端应用程序。 Backend for Frontends 模式为实现多个网关提供了方向。
后端内部微服务之间的服务到服务通信——微服务通信设计模式
好的,我们已经在我们的微服务架构中创建了 API Gws。 并表示所有这些同步请求都来自客户端,并通过 api gws 进入内部微服务。
但是,如果客户端请求需要访问多个内部微服务怎么办? 我们如何管理内部微服务通信?
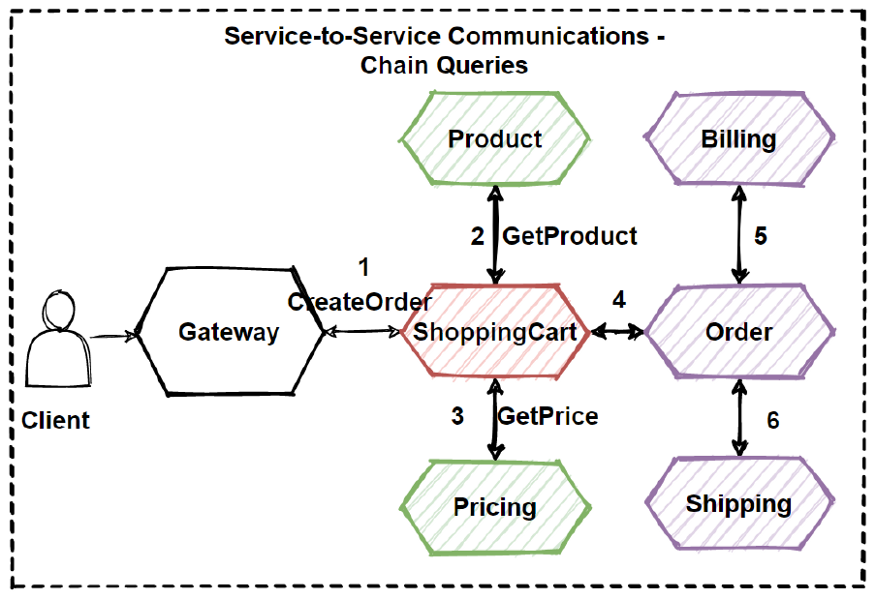
在设计微服务应用程序时,我们应该注意后端内部微服务如何相互通信。最佳实践是尽可能减少服务间通信。
但是,在某些情况下,由于客户要求或请求的操作需要访问多个内部服务,我们无法减少这些内部通信。
例如,查看图像并考虑用例:
- 用户想要结帐购物车并创建订单
那么我们如何实现这个请求呢?
所以这些内部调用使每个微服务耦合,在我们的例子中 sc - Product 和 Pricing 微服务是相互依赖和耦合的。
如果其中一个微服务出现故障,它就无法向客户端返回数据,因此它没有任何容错能力。如果微服务的依赖和耦合增加,那么就会产生很多问题,并且会削弱微服务架构的力量。
如果客户端结帐购物车,这将启动一组操作。
因此,如果我们尝试使用请求/响应同步消息模式来执行这个订单用例,那么它看起来就像这个图像。
如您所见,一个客户端 http 请求有 6 个同步 http 请求。
因此很明显,增加延迟并对我们系统的性能、可扩展性和可用性产生负面影响。
如果我们有这个用例,如果第 5 步或第 6 步失败了怎么办,或者如果某个中间服务宕机了怎么办?
即使没有宕机,也可能是一些服务繁忙,无法及时响应,导致不可接受的高延迟。
那么这种需求的解决方案是什么?
我们可以应用 2 种方法来解决这个问题,
1- 将微服务通信更改为与消息代理系统的异步方式,我们将在下一节中看到这一点。
2- 使用服务聚合器模式在 1 个 api gw 中聚合一些查询操作。
服务聚合器模式——微服务通信设计模式
为了最小化服务到服务的通信,我们可以应用服务聚合器模式。基本上,服务聚合器设计模式是接收来自客户端或 api gw 的请求,然后分派多个内部后端微服务的请求,然后将结果组合并在 1 个响应结构中响应发起请求。
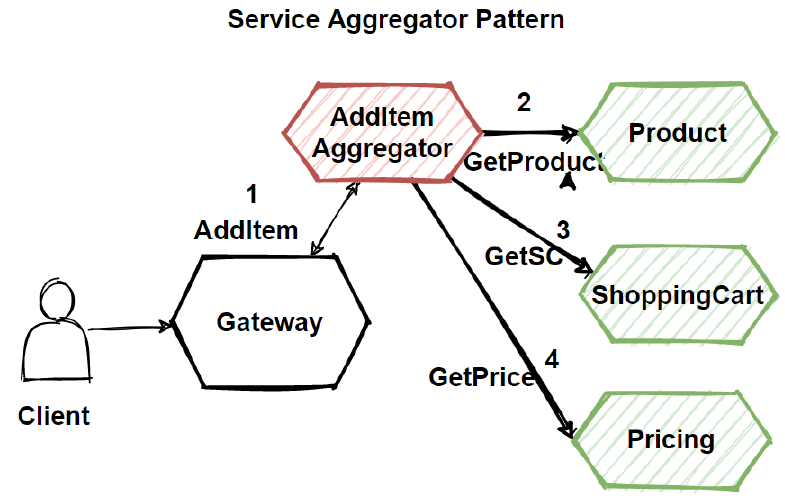
通过服务聚合器模式实现,我们可以减少客户端和微服务之间的聊天和通信开销
设计——服务聚合器模式——服务注册模式——微服务通信设计模式
在本节中,我们将通过添加服务聚合器模式 - 服务注册表模式 - 微服务通信设计模式来迭代我们的电子商务架构。
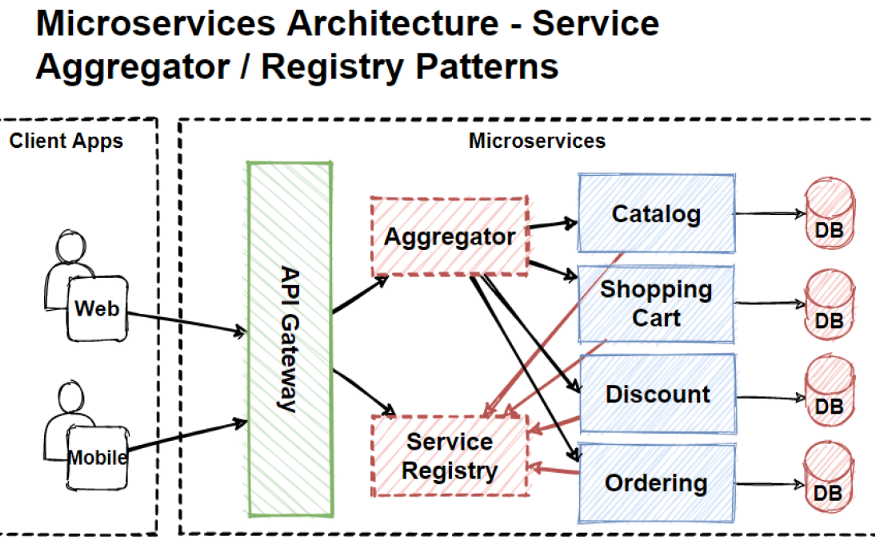
正如你所看到的,我们已经为我们的电子商务架构应用了服务聚合器模式——服务注册模式。
微服务基于消息的异步通信
如果您的通信仅在几个微服务之间进行,则同步通信是好的。 但是当涉及到几个微服务需要相互调用并等待一些长时间的操作直到完成时,我们应该使用异步通信。
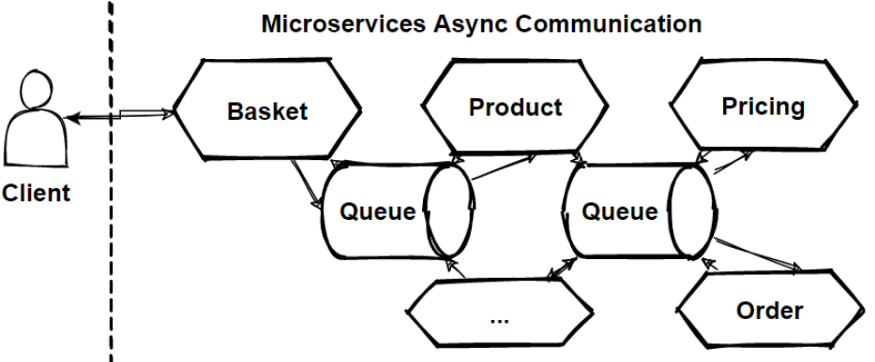
否则,微服务的依赖和耦合将造成瓶颈并造成架构的严重问题。
如果你有多个微服务需要相互交互
如果你想在没有任何依赖或松耦合的情况下与它们交互,那么我们应该在微服务架构中使用基于异步消息的通信。
因为基于异步消息的通信提供了事件处理。 所以事件可以放置微服务之间的通信。
我们称这种通信为事件驱动的通信。
发布-订阅设计模式
发布-订阅是一种消息传递模式,有消息的发送者称为发布者,有特定的接收者称为订阅者。
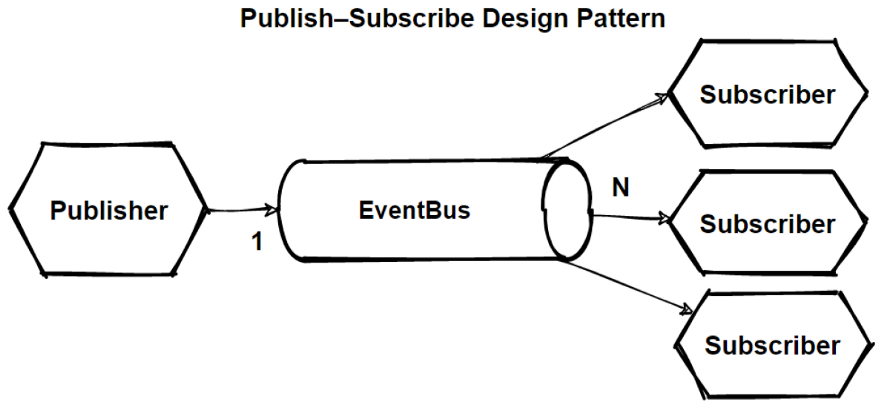
所以发布者不会将消息直接发送给订阅者。
相反,对已发布的消息进行分类并将它们发送到消息代理系统,而不知道那里有哪些订阅者。
类似地,订阅者表示感兴趣并且只接收感兴趣的消息,而不知道哪些发布者发送给他们。
设计——发布/订阅消息代理——微服务异步通信设计模式
在本节中,我们将通过添加 Pub/Sub 消息代理来迭代我们的电子商务架构,以提供微服务异步通信设计。
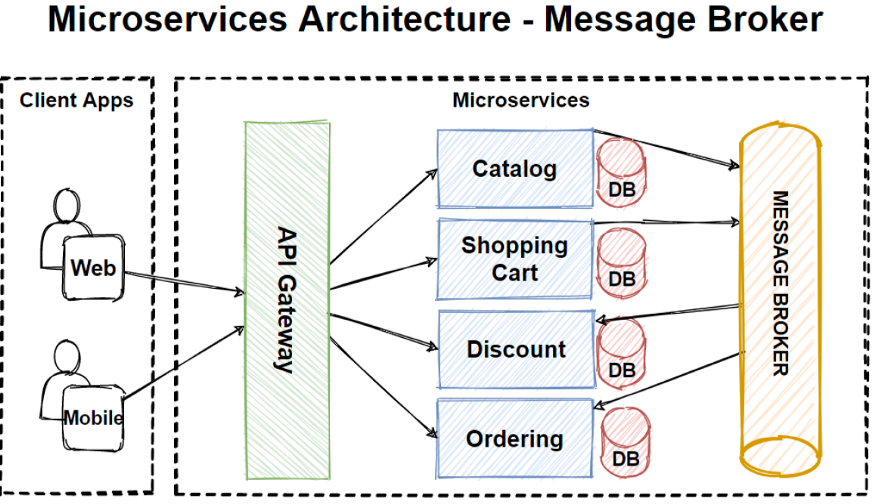
如您所见,我们已经应用了 Pub/Sub Message Broker — 微服务异步通信设计模式。
如果我们调整技术堆栈,我们基本上从 Pub/Sub 消息代理的选项开始。您可以选择 2 个不错的选择;
1- Kafka
2- RabbitMQ
微服务数据管理
在单体架构中,查询不同的实体非常好,因为单个数据库保持数据管理也很简单。跨多个表查询数据很简单。对数据的任何更改都会一起更新或全部回滚。严格一致性的关系型数据库具有ACID事务保证,便于管理和查询数据。
但是在微服务架构中,当我们使用“多语言持久性”时
这意味着每个微服务都有不同的数据库,包括关系数据库和无 sql 数据库,我们应该在执行用户交互时设置策略来管理这些数据。
这意味着我们在处理微服务之间的数据交互时有几种模式和实践,我们将在本节中学习这些模式和原则。
微服务是独立的,只执行特定的功能需求,对于我们在电子商务应用程序中的案例,我们有产品、购物篮、折扣、订购微服务需要相互交互以执行客户用例。这意味着他们需要经常相互整合。大多数这些集成是查询每个服务数据以进行聚合或执行逻辑。
CQRS 设计模式
CQRS 是微服务间查询的重要模式之一。我们可以使用 CQRS 设计模式来避免复杂的查询来摆脱低效的连接。 CQRS 代表命令和查询责任分离。基本上,这种模式将数据库的读取和更新操作分开。
为了隔离命令和查询,其最佳实践是将读写数据库与 2 个数据库物理分离。通过这种方式,如果我们的应用程序是读密集型的,这意味着读多于写,我们可以定义自定义数据模式以优化查询。
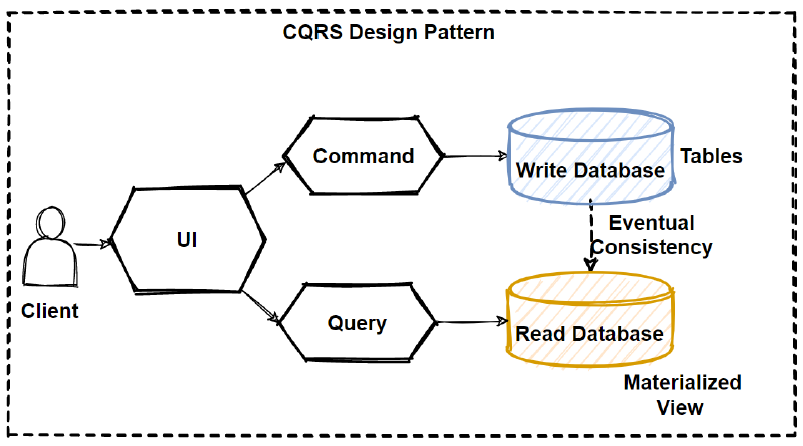
物化视图模式是实现读取数据库的好例子。
因为通过这种方式,我们可以避免使用预定义的细粒度数据进行复杂的连接和映射以进行查询操作。
通过这种隔离,我们甚至可以使用不同的数据库来读取和写入数据库类型,例如使用 no-sql 文档数据库进行读取和使用关系数据库进行 crud 操作。
事件溯源模式
我们已经学习了 CQRS 模式,并且 CQRS 模式主要与 Event Sourcing 模式一起使用。 当使用带有事件溯源模式的 CQRS 时,主要思想是将事件存储到写入数据库中,这将是真实事件数据库的来源。
之后,CQRS 设计模式的读取数据库提供具有非规范化表的数据的物化视图。 当然,这个物化视图读取数据库消耗来自写入数据库的事件并将它们转换为非规范化视图。
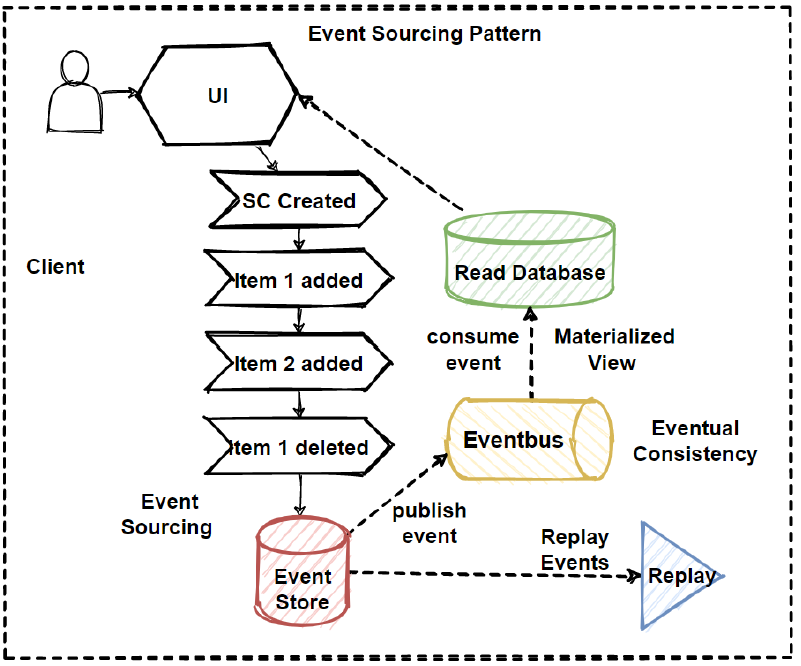
随着事件溯源模式的应用,它正在改变为将数据保存到数据库中的操作。 事件溯源模式不是将数据的最新状态保存到数据库中,而是提供将所有事件按顺序排列的数据事件保存到数据库中。 这个事件数据库称为事件存储。
它不会更新数据记录的状态,而是将每个更改附加到事件的顺序列表中。 因此,事件存储成为数据的真实来源。 之后,这些事件存储转换为遵循物化视图模式的读取数据库。 此转换操作可以通过带有消息代理系统的发布事件的发布/订阅模式来处理。
设计架构——CQRS、事件溯源、最终一致性、物化视图
我们将通过应用 CQRS、事件溯源、最终一致性、物化视图来设计我们的电子商务架构。

因此,当用户创建或更新订单时,我将使用关系写入数据库,当用户查询订单或订单历史时,我将使用 no-sql 读取数据库,并在使用消息代理系统同步 2 个数据库时使它们保持一致应用发布/订阅模式。
现在我们可以考虑这些数据库的技术栈,我将使用 SQL Server 进行关系写入数据库,使用 Cassandra 进行无 SQL 读取数据库。当然,我们将使用 Kafka 将这 2 个数据库与 pub/sub Kafka 主题交换同步。
如您所见,我们已经完成了微服务数据库模式的设计。让我们深入了解微服务中的这些事件驱动架构。
事件驱动的微服务架构
基本上事件驱动的微服务架构是指通过事件消息与微服务进行通信。我们在微服务异步通信部分的发布/订阅模式和 Kafka 消息代理系统中看到了这一点。
我们说过,使用事件驱动架构,我们可以进行异步行为和松散耦合的结构。例如,服务不是在需要数据时发送请求,而是通过事件使用它们。这将提供性能提升。
但在事件驱动的微服务架构上也有巨大的创新,例如使用实时消息传递平台、流处理、事件中心、实时处理、批处理、数据智能等。
因此,我们可以使这种事件驱动的方法更通用,并随着这种架构的发展而具有实时事件处理功能。
根据这种新的事件驱动微服务架构,每件事都是通过 Event-Hubs 进行通信。 我们可以认为 Event-Hubs 是一个可以进行实时处理的大型事件存储数据库。
设计架构——事件驱动的微服务架构
我们将使用事件驱动的微服务架构来设计我们的电子商务应用程序。

现在让我们决定在这个架构中使用技术栈。 当然,我们应该选择 Apache Kafka——作为事件中心和 Apache Spark,用于转换或响应数据流的实时和近实时流应用程序。
正如你所看到的,现在我们有了事件驱动微服务架构的反应式设计。
现在我们可以问同样的问题;
多少并发请求可以容纳我们的设计?

借助这种最新的事件驱动微服务架构,它使用容器和编排器进行部署,可以以低延迟满足目标并发请求。
因为该架构是完全松散耦合的,并且设计用于高可扩展性和高可用性。
如您所见,我们设计的电子商务微服务架构具有设计原则和模式的各个方面。 现在,您可以通过这些学习准备设计自己的架构,并知道如何在您的设计中使用这些模式工具箱。
带课程的逐步设计架构
我刚刚发布了一门新课程——使用模式和原则设计微服务架构。
在本课程中,我们将学习如何使用设计模式、原则和最佳实践来设计微服务架构。 我们将从设计单体到事件驱动的微服务开始,并一起使用正确的架构设计模式和技术。
原文:https://medium.com/design-microservices-architecture-with-patterns/mono…
- 59 次浏览
【微服务架构】如何使用SSO保护企业微服务架构
QQ群
视频号

微信

微信公众号

知识星球
什么是安全?
这是一个重要方面,注意系统完整性的安全性。如果不考虑安全方面,它会传播风险,并可能容易受到其他网站、网络和其他It基础设施上的恶意软件攻击。
什么是SSO及其工作原理?
单点登录(SSO)是一种技术,它将多个不同的应用程序登录屏幕合并为一个。一旦您登录到特定系统,该声明登录令牌就可以在所有应用程序中共享,它们可以在其中定义信任。
身份验证和授权
身份验证:
是检查您是谁的过程。这是我们根据密码验证用户以识别此人的方式。
这方面有两种机制。
身份代理:
您可以通过社交登录实现登录。比如使用google/facebook/apple-like登录。
在这里,您单击任何社交链接,然后它将重定向到您的身份提供商,并提供用户名和密码,然后它会将令牌返回给Keyclock。现在,Keyclock可以使用特定的用户角色生成自己的令牌并将其返回。
身份联合:
在这里,Keyclok可以针对多个数据源验证用户。我们可以教Keyclok如何验证用户,以及在这个过程中应该涉及哪些数据源。它是可定制的。
授权:
它有两个方面。
- 说说你能做什么
- 告诉我你可以做什么
- 当我们实施票证管理解决方案时,支持工程师可以读取用户的配置文件。他可能有配置文件读取权限,但不应该访问任何配置文件。必须有一些限制。只有当特定用户的支持票证分配给他时,他才能读取配置文件。这些是用户策略。
- 因此,使用授权服务器实现和维护这些类型的策略有点困难。
让我们看看如何做到这些。
- 所以通常我们创建用户,创建角色。让我们假设我们创建了一个用户管理服务。因此,我们必须确定用户管理可以做什么。
- 它可以读取/写入/编辑/删除/列出用户。
- read表示您给出特定的用户id并获取该用户信息。
- 列表意味着您可以将所有用户作为列表获取。
- 现在,假设我们创建了以上5个权限。现在,您将这些权限分配给特定角色,然后将该角色分配给特定用户。
- 因此,如果用户属于特定角色,那么我们可以查看属于该角色的权限并应用该权限。
- 所以用户登录到UI。当他们登录到UI时,它将重定向到身份验证服务器。
- 假设我们在这里使用Keyclok(一种开源软件产品,允许使用身份和访问管理进行单点登录(SSO))。在实现Keyclok之后,用户将重定向到Keyclok。在这里,我将对用户进行身份验证。之后,该令牌将返回到UI,然后UI将提交其服务请求。
- 当服务请求到来时,API网关将标识为用户正在尝试创建新用户。然后它将检查此令牌是否携带创建用户权限?如果是:它会让交通流进来
但问题是,该用户可以在哪个部门下创建新用户?
- 因此,我们必须验证这一点。为此,我们可以使用策略管理解决方案。(我们可以使用OPA Open策略代理,这是一个流行的工具)
因此,当流量流动时,在创建新用户之前,我们联系OPA,要求该用户在部门d001上创建新用户。允许吗?这里OPA验证并返回true或false。
让我们看看另一个用例:
- 假设支持工程师现在要读取用户的配置文件。因此,支持工程师属于具有读取用户配置文件权限的角色。当请求到达API网关时,它将允许请求流入服务,因为他具有用户读取权限。
那么现在,如果我们与OPA交谈,询问这位支持工程师是否有从这个特定用户分配的用于尝试读取配置文件的票证?如果是,OPA将返回true。否则为false。
Active directory:当用户已经登录到Active directory时,如果他们来到我们的应用程序,则UI转到Keyclock。然后,keyclock与active directory对话。active directory然后确保该用户已经登录。因此,keycloke将生成令牌。由于此过程,用户无需再次登录即可访问应用程序,我们称之为SSO(单点登录)。
当我们将这里讨论的所有这些东西放在一起并应用到系统中时,我们将能够为我们的应用程序构建更安全的身份验证和授权解决方案。
- 50 次浏览
【微服务架构】实用建议:使用Kubernetes在Java中构建微服务应用程序时的关键决策
作为Java开发人员或解决方案架构师,您的领导团队可能会问您以下问题:
- 我们是否利用云的优势(例如,集中管理,计算效率,可扩展性,安全性,易维护性)?
- 为了鼓励重用和开发效率,我们是否推广微服务方法?
- 我们是否使用基于Docker的容器技术来简化我们的部署和可扩展性策略?
如果我是你,答案将是:“当然!我们正在做这件事。”
最近,我的解决方案工程师团队将这些问题作为开发样本店面应用程序的一部分,作为微服务Garage方法参考架构的一部分。这个应用程序,内部称为BlueCompute,是按照微服务原则设计的(如果感兴趣,您可以阅读其设计的更多细节,并在项目ibm-cloud-architecture / refarch-cloudnative中仔细阅读GitHub上的实现)。
除了遵循微服务原则,我们还决定使用Kubernetes作为我们的容器编排平台。在此过程中,我们制定了关键设计和架构决策,我想以问题/答案的形式分享:
-
Should I use Kubernetes virtual IP or DNS based service lookup?
-
How do I expose the services for external consumption? LoadBalancer or Ingress or NodePort?
-
Which tool should I use for continuous integration and deployment (CI/CD) in Kubernetes cluster?
我们相信,在IBM Bluemix平台上使用Kuberenetes服务构建系统时,在项目早期考虑这些设计决策将会非常有用。
Q1:作为Java开发人员,我应该使用哪个框架作为构建微服务风格应用程序的基础?
Sprint Boot是Java开发人员的热门选择之一。其独立的应用程序方法非常适合微服务模块化原理。作为单个进程运行允许Sprint Boot应用程序轻松打包并作为Docker容器分发。 MicroProfile是另一个新兴的框架,尤其受到企业Java开发人员的青睐。
Q2:我应该在哪里运行Kubernetes平台?
Kubernetes可以在您自己的数据中心或云提供商的开发笔记本电脑,VM或裸机服务器上运行。显然,这个决定必须与您组织的整体云和托管策略保持一致。如果您正在寻找托管的Kubernetes环境(或Kubernetes即服务),那么IBM Bluemix容器服务是一个不错的选择。如果您出于安全性和合规性原因希望在自己的数据中心托管托管Kubernetes服务,则可以选择IBM Spectrum Conductor for Containers或OpenShift。当然,您可以通过在数据中心或基于云的基础架构中作为服务安装和配置Kubernetes环境来自行推出。
根据您的具体情况,您最终可能会采用不同的方法。例如,使用托管Kubernetes服务在公共云上运行开发/测试环境,并将生产工作负载部署到内部部署的Kubernetes平台。这种混合方法利用了Docker容器和Kubernetes的可移植性功能。就个人而言,我尽可能地利用托管的Kubernetes服务,从我的盘子中删除另外一项任务。
问题3:如何处理应用程序服务注册表和发现?
为了从您在分布式弹性云环境中创建的许多微服务中受益,正确的服务注册和发现策略对于允许它们彼此通信或被消费至关重要。作为云原生微服务实现的先驱,Netflix已经构建并发布了一组名为Netflix OSS的自定义库,如Eureka,Zuul,Ribbon等。它们与Spring框架很好地集成在一起。通常,服务注册到Eureka,Ribbon / Zuul处理服务发现和基本负载平衡。然而,我所描述的是近5年前。
今天,Kubernetes本身支持服务注册,发现和负载平衡。您不再需要Netflix OSS来完成这些任务。相反,您将系统设计为Kubernetes方式。您可以利用Kubernetes的服务类型来公开您的微服务,然后通过虚拟IP或DNS方法自动注册到Kubernetes系统(我将在下一个问题/答案中详细说明这个决定)。该发现将通过熟悉的DNS查找样式进行。对于基于服务的集群,Kubernetes提供了一个内置的负载均衡器,用于在Pod(容器)之间分配工作负载。
问题4:我应该使用Kubernetes虚拟IP还是基于DNS的服务查找?
如前面的问题/答案中所述,我们决定服务注册表和查找应该以Kubernetes方式完成。您有两种选择:环境变量或DNS。环境变量由Kubernetes引物开箱即用。在封面下,Kubernetes公开集群中的服务虚拟IP,以便其他Pod / Services可以通过此环境变量条目调用目标服务。这种方法的缺点是服务在依赖Kubernetes服务事务中的创建顺序。一般而言,依赖IP地址并不是一个好主意。
更好的解决方案是基于DNS的方法。假设我有一个“Order”微服务,我将它命名为order-service,作为服务yaml定义中名称的一部分。前端Web服务可以通过REST端点http:// order-service / id简单地调用Order服务。这将从底层基础架构中抽象出应用程序。要使用DNS方法,如果要构建自己的Kubernetes基础结构,则需要安装Kubernetes DNS加载项。但是,如果您使用Kubernetes作为服务,例如使用IBM Bluemix Container服务,则会在群集中自动启用DNS服务。
问题5:Kubernetes处理应用程序弹性,但是如何优雅地处理依赖服务的故障?
Kubernetes通过其内置的自我恢复机制确保应用程序弹性或容错。作为ReplicaSet实现,Kubernetes确保您的应用程序Pod(容器)始终尝试满足所需的状态。例如,在任何给定时间,我的群集中总是有3个订单服务Pod在运行。
这很酷,并由Kubernetes提供服务。但是你仍然需要设计你的微服务以应对依赖性失败。例如,如果下游服务已关闭,或者存在数据库或存储中断。如果发生这种情况,您不希望此服务问题通过阻止资源或降低整个用户体验来影响整个应用程序。您希望优雅地降级或失败保护此服务。对于基于Java的实现,我建议使用Netflix Hystix库来提供命令来实现故障处理模式,如Circuit Breaker或Bulkhead,以及用于查看系统整体运行状况的仪表板。它与基于Spring Boot的容器应用程序集成良好; Hystrix仪表板本身可以轻松打包和部署为容器,并由Kubernetes管理。
问题6:如何公开服务以供外部消费? LoadBalancer或Ingress或NodePort?
您需要确定客户端应用程序(Web 2.0或移动应用程序)如何访问Kubernetes集群上托管的微服务。很可能,您不希望将您的核心业务逻辑或数据微服务直接暴露给Internet,而应该构建一个BFF(前端后端)或一个API网关,后者又决定将哪个后端服务消耗。在此设计下,通常只能通过Kubernetes内部网络访问后端数据微服务。前端层(BFF或API网关)成为面向Internet的组件。
然后问题就变成了如何公开这个前端服务层以供外部消费。您在Kubernetes中有两个选择:LoadBalancer或Ingress(还有第三个选项 - NodePort - 但我不推荐它用于生产用途)。
具有LoadBalancer的服务提供外部可访问的IP地址,可将流量发送到群集节点上的正确端口。 LoadBalancer易于启用,并允许您的客户端应用程序通过服务定义的HTTP路径访问REST API。 LoadBalancer的缺点是为您的应用程序消耗更多的IP(可计费资源),依赖于云供应商实现,以及缺乏处理TLS终止等常见任务的中心入口点。
另一种方法是Ingress。 Ingress不是为您希望向公众公开的每个服务创建LoadBalancer服务,而是提供一种独特的公共路由,允许您根据各自的路径将公共请求转发到群集内的服务。此方法允许您应用程序的中央入口点。因此,您可以轻松地在多个Kubernetes区域中添加DNS路由和全局负载平衡。这是一个很有前景的解决方但在早期阶段 - Ingress控制器仍然不够灵活,无法处理复杂的应用程序/服务路由路径,终止TLS,过滤传入请求等。
在我们的实现中,我们最终部署了另一个具有Ingress服务类型的NGINX服务。在NGINX内部,我应用上述处理。当Ingress成熟时,这可能是一个临时解决方案。
问题7:我应该在Kubernetes集群中使用哪种工具进行持续集成和部署(CI / CD)?
现在您已准备好编码,但请等待!还有一个决定。您不想进行自动持续集成和部署(CI / CD)吗?如果是这样,最好在开始之前制定策略。
CI / CD是一个通用术语;当它引用Kubernetes集群中的微服务应用程序时,它包括自动Spring Boot应用程序构建,构建Docker映像,将映像推送到Docker注册表,以及部署Kubernetes服务或Pod。当开发人员向源控制系统(例如git)提交代码更改或修复问题时,流程通常会启动。
这是最容易做出的决定之一 - 我们只是使用Jenkins作为工具。我们最终确定了一个名为Jenkins-kubernetes-plugin的开源工具(GitHub上的jenkinsci / kubernetes-plugin)。这种方法的主要好处是我们可以轻松地将Jenkins构建主节点和从节点作为Kubernetes组件运行。这使我们免于安装和维护单独的Jenkins环境。同样,对我们来说,少一项任务是好的。
使用此工具,CI / CD流程如下:
- 开发人员在GitHub中提交代码更改
- Git webhook通过插件触发部署在Kubernetes集群中的Jenkins master的构建
- 主服务器在您的Kubernetes集群中部署Jenkins slave Pod
- Jenkins slave Pod开始构建阶段 - 构建Sprint Boot应用程序,构建Docker镜像,推送到Docker注册表。
- 完成构建阶段后,Jenkins master部署了另一个Jenkins slave Pod,它将启动部署阶段。
- 部署阶段(在Jenkins文件中定义)将您的Microservices部署为Kubernetes服务。
所有这些步骤都是自动化的。
结论
要了解我们如何将这些决策付诸实践,请尝试构建在IBM Bluemix Container服务之上的参考实现应用程序。我们的样本店面应用程序是使用Microservices方法构建的,它实现了本文中描述的所有设计原则。 GitHub上的ibm-cloud-architecture / refarch-cloudnative项目的自述文件包括下载代码并在您自己的Bluemix环境中安装代码的体系结构和说明的概述。
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 27 次浏览
【微服务架构】微服务-生存还是毁灭!
上周,我谈到了作为一系列微服务开发的产品技术架构。谈话几分钟后,很明显团队已经支付了微服务高级版,但没有明显的投资回报。这组微服务是由一个由10名工程师组成的团队构建的,所有服务都是用java实现的,并使用消息总线将必要的数据复制到共享postgres实例中的自己的模式中。虽然工程师可能最有意愿建立一个可以扩展的系统,但它立刻让我想起了Donald Knuth的名言,
过早优化是万恶之源
我认为团队会更有效率,如果系统被构建为具有良好模块性和服务之间松散耦合的整体系统,那么系统就不那么复杂了。
让我们看一下微服务架构的优缺点,从我自己的经验来看,我在SAP时为我们构建的产品采用了微服务架构。
释放灵活性
采用微服务使我们能够灵活地根据微服务中代码的成熟度和质量来决定哪些功能可以通过v1发布。另一方面,单片应用程序意味着延迟发布,直到我们把所有事情都弄好。
主题移交
虽然我不是世界各地分布式团队的忠实粉丝,但我们需要接受并继续前进,这是今天的商业现实。通过遍布三大洲(美国,德国和印度)的全球开发团队实施产品非常具有挑战性,但在微服务方面明确分离功能使我们能够灵活地在不同地点之间移动功能。由于团队不需要了解整个代码库以详细了解功能集的一小部分,因此主题切换非常易于管理。
规模
扩展单片应用程序(尤其是水平扩展)绝对是可能的,但并非应用程序的所有部分都可能从扩展中受益,因为吞吐量要求因产品的不同功能而异。微服务架构允许我们根据吞吐量要求扩展应用程序的不同部分,并有效利用可用资源。
自治
我非常相信团队的完全自主权,这与微服务架构相得益彰,因为团队之间的依赖关系减少到最小,并且通过定义良好的接口或API进行通信。团队完全自治的缺点是编程语言,框架,开发工具的动物园,一旦团队扩展到100人,就变得无法管理。虽然微服务架构鼓励多语言运行时,但我建议坚持几个运行时,几个框架以及一个基于一个工具集的构建和发布过程。
监测和支持
由于微服务按照定义分布在许多服务器(物理或虚拟)上以实现水平扩展,因此它们运行的平台应提供强大的监控和支持基础架构。监视和支持在调试和查找日志文件中的错误的根本原因方面由于缺少聚合每个产品的日志和跟踪文件的工具而变得非常麻烦。例如,支持工程师可能需要查看每个微服务的大量日志文件,以找出错误的根本原因。
构建和发布
在微服务部署的情况下,构建和发布过程的复杂性有时会使团队士气高涨,因为他们不断与构建作业和部署作业作斗争。对我们来说,缺乏构建,部署和发布自动化是一项挑战。照顾一个构建工作,一个代码扫描,每个服务就像放牧猫一样。如果有什么东西打破没有人通知。事实上,我们每个微服务都有多个构建作业 - 一个用于拉取请求,一个用于运行代码扫描和集成测试的主构建,另外一个可以发布到工件库中。完全自动化的构建和发布过程是微服务架构有效提高开发人员工作效率的关键。
安全
在微服务架构中获得安全性是一个真正的复杂性助推器。我们花了很多时间来确定基本的安全要求,例如身份验证和授权(特别是在服务到服务通信上下文中),因为每个微服务都运行在它自己的进程中,而不是整体结构。使用单一应用程序,处理安全性就像将spring安全库放入Web应用程序,创建spring-security.xml并向REST端点添加一些安全注释一样简单。使用微服务,使用JWT处理复杂的OAuth流并在服务之间传递令牌并非易事.
数据复制
最后,我认为在微服务方面最重要的权衡是关于是否复制数据的争论(特别是在大数据环境中)。关于如何复制数据的技术 - 消息总线,点对点REST API等是这个决定的简单后续。
通常,为微服务(有界上下文)获取服务边界非常困难。如果服务边界不正确,则会导致数据重复并增加服务之间的耦合。数据重复是一个很大的问题,特别是当微生物主要是分析性的并且需要依赖于或多或少相同的大数据集进行分析时。
在大数据分析环境中,我不是复合服务或复合API的忠实粉丝(我将其定义为需要处理大约数百万个数据点以满足请求 - 如排序,过滤)。复合REST API实现往往性能较慢,无法与DB的响应时间相匹配,DB是处理连接,聚合,过滤等事情的理想场所。
我们最终创建了一个数据服务,它创建了一个像依赖的平台,因为几乎所有其他微服务都依赖于这个服务来查询大数据集。必须在此层中实现任何新查询,这会降低新功能的开发速度。但查询响应时间对于应用程序来说至关重要,因此我们可以进行权衡。
生存还是毁灭 !
与所有软件架构一样,为您的产品采用或不使用微服务是一种权衡讨论和决策。
- 17 次浏览
【微服务架构】微服务不是魔术:处理超时
微服务很重要。它们可以为我们的架构和团队带来一些相当大的胜利,但微服务也有很多成本。随着微服务、无服务器和其他分布式系统架构在行业中变得更加普遍,我们将它们的问题和解决它们的策略内化是至关重要的。在本文中,我们将研究网络边界可能引入的许多棘手问题的一个示例:超时。
在你害怕“分布式系统”这个词之前,请记住,即使是一个带有 Node 后端的小型 React 应用程序,或者一个与 AWS Lambda 对话的简单 iOS 客户端,也代表一个分布式系统。当您阅读这篇博文时,您已经参与了一个分布式系统,其中包括您的 Web 浏览器、内容交付网络和文件存储系统。
在背景方面,我将假设您了解如何使用您选择的语言进行 API 调用并处理它们的成功和失败,但这些 API 调用是同步还是异步、HTTP 或不是。如果您遇到不熟悉的术语或想法,请不要担心!我很高兴在 Twitter 或其他地方进行更多讨论,并且我还尝试在适当的地方添加链接。
我们将要探讨的问题是:如果我们遇到一个非常非常慢的 API 调用最终超时,并且我们假设 (a) 它成功或 (b) 它失败,我们就会遇到错误。超时(或更糟糕的是,无限长的等待)是分布式系统的一个基本事实,我们需要知道如何处理它们。
问题
让我们从一个思想实验开始:你有没有给同事发邮件向他们要东西?
- [星期二,上午 9:58] 你:“嘿,你能把我加到我们公司的潜在导师名单中吗?”
- 同事:“……”
- [星期五,下午 2:30] 你:[?]
你该怎么办?
如果您希望您的请求得到满足,您最终需要确定没有回复。你会等更长的时间吗?你想等多久?
那么,一旦你决定等待多长时间,你会采取什么行动?您是否再次尝试发送电子邮件?你尝试不同的传播媒介吗?你认为他们不会这样做吗?
好的,现在这里到底发生了什么?我们希望看到这种请求-响应行为:

但是出了点问题。 有几种可能性:
- 他们从来没有得到消息。

- 他们收到了邮件,成功处理了邮件,然后给您发回了一个从未收到您的回复(或转到您的垃圾邮件文件夹)。

- 他们得到了信息,但他们仍在思考,或者他们失去了它,或者[喘气!]他们忘记了。

- 最终,我们只是不知道!

正是这个问题出现在分布式系统上的任何通信中。
我们可能会延迟我们的请求、处理或响应,而这些延迟可能是任意长的。因此,与电子邮件示例一样,我们需要确保“我们要等多久?”问题有答案,我们称该持续时间为超时。
如果您只从本文中学到一个教训,那就这样吧:使用超时。否则,您将面临永远等待永远不会完成的操作的风险。
但是一旦我们达到了超时,等待的上限,我们该怎么办?
方法
当人们在远程系统调用中遇到超时时,有几种常见的方法。我并不声称这份清单是详尽无遗的,但它确实涵盖了我见过的许多最常见的场景。
方法#1
当您遇到超时时,假设它成功并继续前进。
请不要这样做。[1]不幸的是,我不得不说这是一个常见的无意识选择,即使在生产应用程序中,也会有一些非常糟糕的用户体验结果。如果我们假设手术成功了,我们可怜的消费者就会合理地假设事情进展顺利——只是后来当他们发现结果时会感到失望和困惑。
任何时候你有一个网络呼叫,寻找成功和失败的案例。例如,如果你在 JavaScript 中通过 Promise.then(...) 使用异步 API,请问问自己对应的 .catch(...) 在哪里。如果它丢失了,你几乎肯定有一个错误。
在一些非常特殊的情况下,您可能理所当然地不在乎请求是成功还是失败。 UDP 是具有此属性的非常成功的协议。另外,很多软件坏了,继续赚钱就好了!但请不要让这成为您的默认设置——先用尽您的其他选项。
方法#2
对于读取请求,请使用缓存或默认值。
如果您的请求是读取请求并且不打算对远程端产生任何影响,那么这可能是一个不错的选择。在这种情况下,您可以使用先前成功请求中的缓存值。或者,如果还没有成功的请求或者缓存在您的情况下没有意义,您可以使用默认值。这种方法相对简单:它不会增加太多的性能开销或实现复杂性。但请记住,如果您使用的是通过网络访问的进程外缓存(例如,memcached、Redis 等),那么您将回到类似的情况,即您的请求对缓存本身可能会超时。
方法#3
当您遇到超时时,假设远程操作失败,然后自动重试。
这提出了更多的问题:
- 如果重试不安全怎么办?网络连接另一端的服务获取重复项只是烦人吗?或者你是双重收取信用卡? (!)
- 您应该同步重试还是异步重试?
- 如果您同步重试,从消费者的角度来看,这些重试会减慢您的速度——您是否有可能无法满足他们的期望?这在服务中尤其重要,而不是最终用户应用程序。
- 如果你异步重试,你告诉你的消费者关于操作成功的什么?您是一次尝试一个,还是在一段时间内分批重试?
- 您应该重试多少次? (一次?两次?10次?直到成功?)
- 您应该如何在重试之间延迟? (指数退避[例如,1s、2s、4s、8s、16s,...] 以最大等待时间为界?使用抖动?)
- 如果远程服务器由于过载而出现性能问题,重试是否会使他们的情况变得更糟?
如果远程 API 可以安全地重试,我们称之为幂等。如果没有幂等属性,您可能会创建重复数据(如信用卡费用的情况)或导致竞争条件(即,如果您尝试更改您的电子邮件地址两次,并且第一个在第二个完成后重试)。
在许多情况下,使自动重试安全可能需要大量的架构工作。但是,如果您可以安全地重试(例如,通过发送请求 UUID,并让远程端跟踪这些),事情就会变得非常非常简单。查看 Stripe API 以了解实际情况的一个很好的示例。
方法#4
检查请求是否成功,如果安全再试一次。
这里的想法是,在某些情况下,我们可以在超时请求之后跟上另一个请求,询问我们原始请求的状态。这种方法显然需要存在一个端点,可以为我们提供我们想要的信息。给定这样一个端点,如果端点说我们的请求成功,我们可以明确地说我们不需要重试。
但是这里有一个严重的问题,我们无法真正知道重试是否安全。因为通常我们的远程服务可以接收到请求,但仍在处理中,因此我们正在检查的查询端点将无法确认成功。当然,检查本身可能会超时!远程服务器可能由于与初始故障相同的原因而完全无法访问,但即使这是真的,我们仍然无法知道问题是在处理初始请求之前还是之后发生的。
方法#5
放弃并让用户弄清楚。
这需要最少的努力,并且可以说可以防止我们做出错误的决定,因此在许多情况下这可能是最佳选择。我们还需要问自己:我们的用户能找出正确的做法吗?他们是否有足够的信息和对其他系统的洞察力来确定如何前进?
在某些情况下,让我们的消费者知道这个问题可能是最好的选择。对于任何涉及重试的方法,如果我们不想允许无限次数的重试,我们最终可能仍会退回到这条路径!
结论
所以在这一点上,事情可能看起来很黯淡。分布式系统很难,看来我们不能只选择其中一种解决方案作为灵丹妙药。如果您感到失败,请振作起来,不要让完美成为美好的敌人。
使用超时。
即使超时时间很长,比如 5 秒、10 秒或 [gulp!] 甚至更多,每个网络请求都应该有一些超时时间。选择超时可能很棘手——当请求最终成功时,您不希望有太多失败(误报),也不希望浪费太多时间并冒着不健康的应用程序的风险。您可以通过查看历史请求的分布和趋势以及您的应用程序自身的性能保证或风险概况来确定好的值。
在任何情况下,我们都不希望我们的应用服务器的队列、连接池、环形缓冲区或任何瓶颈被将永远等待的东西堵塞。您绝对可以根据您的生产需求研究并添加更高级的东西,例如断路器和隔板,但是超时很便宜并且库很好地支持。使用它们!
默认使重试安全。
除了让你的代码更简单、更安全之外,你还会说“幂等性”,这很有趣。
考虑以不同的方式委派工作。
异步消息传递在这里有一些吸引人的特性,因为您的远程服务不再需要保持快速和可用;只有您的消息代理可以。但是,消息传递/异步性并不是灵丹妙药——您仍然需要确保代理收到消息。不幸的是,这可能很难!消息代理也有权衡。您的用户对于何时需要重试会有自己的想法。例如,如果消息处理延迟,他们可能会决定重新提交,因为他们的订单尚未显示在订单历史记录中。分布式日志/流媒体平台也可能出现类似问题。如果您正在考虑消息传递路线(实际上,即使没有!),请仔细查看 Enterprise Integration Patterns — 尽管它年代久远,但其中的模式与当今的架构极为相关。
并且冒着成为派对大便的风险,不要忘记您可能能够完全移动或删除该网络边界!把一个难题变成一个简单的问题并没有什么可耻的。因此,也许您可以使用一个网络请求而不是五个,或者您可以将两个服务内联在一起。或者,也许您采用上述方法之一以可靠和安全的方式处理超时。无论您选择哪种方式,请记住,您的用户并不关心您是否使用微服务——他们只是想让事情正常工作。
原文:https://8thlight.com/blog/colin-jones/2018/09/18/microservices-arent-ma…
- 34 次浏览
【微服务架构】微服务作为进化架构
微服务架构风格正在风靡全球。去年三月,O'Reilly举办了他们的第一次软件架构会议,并且计划委员会在微服务的某些方面获得了大量的摘要。为什么这种建筑风格突然风靡一时?
微服务是DevOps革命后的第一个建筑风格,第一个完全接受持续交付的工程实践。它也是一个演化架构的例子,它支持增量不间断变化,作为应用程序结构层面多维度的第一原则。但是,它只是支持某些进化行为的一组架构之一。本文探讨了这一系列建筑风格的一些特征和原则。
进化架构
软件中的常识曾经认为,建筑元素“以后难以改变”。作为第一原理,进化架构设计用于架构中的增量变化。进化架构很有吸引力,因为改造在历史上很难预测,而且改造成本也很高。如果体系结构中内置了渐进式变更,那么变更就会变得更容易,更便宜,从而允许更改开发实践,发布实践和整体敏捷性。
微服务因其强大的有界环境原理而符合这一定义,使得Evan的域驱动设计中描述的逻辑划分成为物理分离。微服务通过高级DevOps实践(如机器配置,测试和自动部署)实现这种分离。因为每个服务都与所有其他服务(在结构级别)分离,所以将一个微服务替换为另一个微服务类似于将一个乐高积木换成另一个。
进化架构的特征
进化架构具有几个共同的特征。我们已经为即将到来的进化建筑书确定了大量的内容;这里有几个。
模块化和耦合
如果开发人员想要进行不间断的更改,那么将组件沿明确定义的边界分离的能力就会明显受益。没有任何建筑元素,传说中的泥球大球,不支持进化,因为它缺乏区域化。

来自一个未命名的客户项目的泥球大球中的类别(周边点)之间的耦合。]
不恰当的耦合通过以难以预测的方式传播变化来抑制进化。进化架构都支持某种程度的模块化,通常在技术架构上(例如,经典的分层架构)。
围绕业务能力进行组织
现代成功的体系结构越来越多地在域架构级别上具有模块化,受域驱动设计的启发。基于服务的体系结构与传统SOA的区别主要在于分区策略:SOA严格按技术层划分,而基于服务的体系结构倾向于微服务的灵感域分区。
实验
实验是超级大国的进化架构之一,为企业提供服务。对应用程序进行操作上廉价的微不足道的改变可以实现常见的持续交付实践,如A / B测试,Canary Releases等。通常,微服务架构是围绕服务之间的路由来定义应用程序,允许在生态系统中存在特定服务的多个版本。这反过来允许实验和逐步替换现有功能。最终,这种力量使您的企业能够花更少的时间来推测故事积压,而是参与假设驱动的开发。
进化架构原理
思考进化架构的一种方法是通过原则。这些原则描述了架构本身或架构设计方法的各种特征。一些原则将注意力集中在何时在流程中做出特定的架构决策。
合适的功能
我们区分紧急和进化架构,这种区别是重要的。与遗传算法等进化计算技术非常相似,建筑适应度函数指定了我们的目标体系结构。有些系统需要很长的正常运行时间,而有些则更关注吞吐量或安全性。

[雷达图用于突出适用于该软件系统的重要适应度函数。]
关于特定系统的适应度函数的前期思考为决策制定和决策时间提供了指导。建筑决策相对于适应度函数进行评分,以便我们可以看到架构正朝着正确的方向发展。
带来痛苦
由于极限编程社区的启发,持续交付和进化架构中的许多实践都体现了带来痛苦向前的原则。当项目中的某些东西有可能引起疼痛时,强迫自己更频繁,更早地进行,这反过来又会鼓励您自动消除疼痛并尽早发现问题。通过部署管道,自动化机器配置和数据库迁移等常见的持续交付实践,通过消除常见的变更难点,可以简化进化架构。
最后的责任时刻
当决策发生时,传统架构和进化架构之间存在重大区别。这些决策可能围绕应用程序的结构,技术堆栈,特定工具或通信模式。在传统架构中,这些决策在编写代码之前就会早期出现。在进化架构中,我们等待最后一个负责任的时刻来做出决策。延迟决定的好处是可用于做出决定的额外信息。成本是一旦做出决定就必须进行的任何潜在的重新工作,这可以通过适当的抽象来减轻 - 但成本仍然是实际的。但是,过早做出决定的成本也是真实的。考虑选择消息传递工具。各种工具具有不同的支持功能。如果我们选择比我们最终需要的更重的工具,我们已经在我们的项目中引入了技术债务来源。这种债务是以使用错误工具导致的发展拖累的形式出现的。这不是先发制人地“抽象所有事情”的借口 - 我们仍然支持敏捷的YAGNI(你不需要它)原则 - 而是在适当的时候做出决定的明智尝试。
当然,在考虑最后一个负责任的时刻时,当前的问题是决定何时。适应度函数为该决定提供指导。应该更早地做出对其他架构或设计选择产生重大影响的决策,或影响项目关键成功因素的决策。延迟做出决定对项目的影响往往大于等待的好处。
结论
软件架构师有责任通过创建图表来阐明系统如何组合在一起的决策。太多的建筑师没有意识到静态的二维建筑图片的保质期很短。软件世界处于不断变化的状态;它是动态的而不是静态的。架构不是一个等式,而是一个正在进行的过程的快照。
持续交付和DevOps运动说明了忽略实施架构并保持最新状态所需工作的缺陷。建模体系结构和捕获这些工作没有任何问题,但实现只是第一步。架构在实施之前是抽象的。换句话说,除非你不仅实现了它,而且还要升级它,否则你无法真正判断任何架构的长期可行性。甚至可能使它能够承受不寻常的事件。
架构师的操作意识对于进化架构至关重要。 Evolution会影响实现的细节,因此实现细节不容忽视。持续交付对架构的要求使得实施更加明显,并使其演变变得容易。因此,持续交付是任何进化架构的重要推动因素。
其他资源:
在ThoughtWorks Tech Leaders Podcast的这一集中,Rebecca和Neal讨论了进化架构的含义以及组织如何将其用作业务优势。
原文:https://www.thoughtworks.com/insights/blog/microservices-evolutionary-architecture
本文:http://pub.intelligentx.net/microservices-evolutionary-architecture
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 93 次浏览
【微服务架构】微服务可加快产品上市速度并提高应用质量
微服务可加快产品上市速度并提高应用质量
采用云原生方法,使用微服务架构构建移动和Web应用程序。
利用微服务缩短产品上市时间
无论他们是访问网站还是移动应用,人们对他们经常使用的应用程序抱有很高的期望。 因此,公司必须不断提供新功能和修复。 在过去,这个过程很痛苦,因为应用程序通常是作为单个(通常是单片的)应用程序开发,构建和提供的。
微服务是一种应用程序架构风格,其中应用程序由许多离散的,网络连接的组件组成,称为微服务:
大型单片应用程序被分解为小型服务。
单个网络可访问服务是微服务应用程序的最小可部署单元。
每个服务都在自己的进程中运行。 此规则有时称为“每个容器一个服务”,可能是容器或任何其他轻量级部署机制,例如Cloud Foundry运行时。
客户正在尝试使他们的应用程序现代化,以跟上变化的速度......在过去,操作决定了应用程序的编写方式......人们花了数年时间编写单一应用程序,其中许多应用程序功能都打包在应用程序中。 ..现在他们看到了开发人员在添加新功能以应对不断变化的营销需求方面遇到的困难。
-------- Roland Barcia, Distinguished Engineer and CTO: Microservices
微服务的好处
采用微服务的企业可享受许多好处:
高效的团队
微服务是分成一组可独立部署的小型服务的应用程序。由于微服务旨在独立行动,因此它们自然地与促进端到端团队所有权的敏捷原则保持一致。
简化部署
每个微服务都围绕业务功能构建和对齐,以降低应用程序变更管理过程的复杂性。由于每项服务都是在不影响其他服务的情况下单独更改,测试和部署的,因此加快了上市时间。
适合工作的正确工具
开发微服务的团队可以做出适合工作的技术决策。他们可以尝试新技术,库,语言和框架,从而缩短创新周期。
提高应用质量
由于微服务的“分而治之”方法,微服务的功能和性能测试都比单片应用程序更容易。微服务架构适用于测试驱动的开发,因为组件可以单独测试,并与完整或虚拟化的微服务组合。这种方法可以全面提高应用质量。
可扩展性
微服务比单片应用程序更容易扩展。通过根据各个服务对整体应用程序,吞吐量,内存和CPU负载的关键性来扩展各个服务,团队可以更有效地扩展应用程序。
微服务原则
在为应用程序开发微服务时,请记住以下原则:
一份工作/单一职责
每个微服务必须针对单个功能进行优化。每项服务都更小,更易于编写,维护和管理。罗伯特马丁称这一原则为“单一责任原则”。
单独的进程
微服务之间的通信必须通过REST API和消息代理进行。从服务到服务的所有通信都必须通过服务API进行,或者必须使用显式通信模式,例如Hohpe的Claim Check Pattern。
执行范围
虽然微服务可以通过API公开自己,但重点不在于接口,而在于运行组件。此图中突出显示了微服务应用程序的粒度:
CI / CD
每个微服务可以连续集成(CI)并连续交付(CD)。当您构建由许多服务组成的大型应用程序时,您很快就会意识到不同的服务以不同的速率发展。如果每个服务都具有唯一的持续集成或连续交付管道,则该服务可以按照自己的进度进行。在整体方法中,系统的不同方面都以系统中最慢的移动部分的速度释放。
弹性
您可以将高可用性和群集决策应用于每个微服务。当您构建大型系统时,您拥有的另一个实现是,当涉及到群集时,一个大小并不适合所有。在同一级别上扩展整体中所有服务的单一方法可能导致服务的过度使用或使用不足。更糟糕的是,当共享资源被垄断时,服务可能会被忽略。在大型系统中,您可以将不需要扩展的服务部署到最少数量的服务器以节省资源。其他服务需要扩展到大数量。
将应用程序迁移到微服务
微服务是一个小应用程序,通常包含一个功能。该功能通过API和消息传递。每个微服务都可以拥有自己的DevOps管道,可以单独扩展,并拥有自己的数据库,拥有数据模型。
该图显示了单片应用程序架构如何演变为基于微服务的应用程序架构:
在单片应用程序中,代码位于单个服务器上。 更新单个组件时,必须同时部署其他组件,因此需要一个完全等效的服务器,以通过蓝绿色部署满足高可用性要求。
在重构的微服务应用程序中,简化了更新部署,因为业务服务在独立的基于云的计算基础架构上独立运行。
要了解微服务应用程序的工作方式以及从单片应用程序迁移到微服务,请观看此视频:
下一步是什么?
既然您已了解使用微服务的概念和价值,请通过阅读微服务参考架构了解有关如何设计微服务应用程序的更多信息。 在了解了体系结构之后,请参考教程在Kubernetes上部署微服务应用程序。
原文:https://www.ibm.com/cloud/garage/architectures/microservices/overview
交流:知识星球【首席架构师圈】
- 46 次浏览
【微服务架构】微服务安全性如何保护您的微服务基础设施?
在当今的市场中,各个行业都在使用各种软件架构和应用程序,因此几乎不可能认为您的数据是完全安全的。因此,在使用微服务体系结构构建应用程序时,安全问题变得更加重要,因为各个服务之间和客户端之间进行通信。因此,在这篇关于微服务安全性的文章中,我将按照以下顺序讨论保护微服务的各种方法。
- microservices是什么?
- 微服务面临的问题
- 确保微服务的最佳实践
Microservices是什么?
微服务,又称微服务体系结构,是一种体系结构样式,它将应用程序构造为围绕业务域建模的小型自主服务集合。因此,您可以将微服务理解为围绕单个业务逻辑彼此通信的小型独立服务。如果您希望更深入地了解微服务,那么可以参考我的文章。
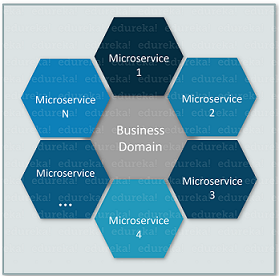
现在,当公司从单一架构转向微服务时,他们通常会看到许多好处,比如可伸缩性、灵活性和较短的开发周期。但是,与此同时,这种架构也引入了一些复杂的问题。
因此,在本文关于微服务安全性的下一篇文章中,让我们了解微服务体系结构中面临的问题。
微服务面临的问题
微服务面临的问题如下:
问题1:
考虑一个场景,其中用户需要登录才能访问资源。现在,在微服务体系结构中,必须以这样一种方式保存用户登录细节,即在用户每次试图访问资源时都不需要进行验证。现在,这产生了一个问题,因为用户细节可能不安全,也可能被第三方访问。
问题2:
当客户端发送请求时,需要验证客户端详细信息,还需要检查授予客户端的权限。因此,在使用微服务时,可能需要对每个服务进行身份验证和授权。现在,为了做到这一点,开发人员可能对每个服务使用相同的代码。但是,您不认为依赖特定的代码会降低微服务的灵活性吗?当然有。所以,这是这个架构中经常面临的主要问题之一。
问题3:
下一个非常突出的问题是每个微服务的安全性。在这种体系结构中,除了第三方应用程序之外,所有的微服务都可以同时彼此通信。因此,当客户端从第三方应用程序登录时,您必须确保客户端不能访问微服务的数据,以防止他/她利用这些数据。
好了,上述问题并不是微服务体系结构中发现的唯一问题。我想说,基于应用程序和您所拥有的体系结构,您可能会面临许多与安全性相关的其他问题。在这一点上,让我们继续这篇关于微服务安全性的文章,并了解减少挑战的最佳方法。
微服务安全的最佳实践
提高微服务安全性的最佳实践如下:
深度防御机制
众所周知,微服务采用任何细粒度级别的机制,因此可以应用深度防御机制来增强服务的安全性。通俗地说,深度防御机制基本上是一种技术,通过这种技术可以应用多层安全对策来保护敏感服务。因此,作为开发人员,您只需用最敏感的信息标识服务,然后应用多个安全层来保护它们。通过这种方式,您可以确保任何潜在的攻击者都不能在一次攻击中破解安全性,并且必须继续尝试破解所有层的防御机制。
此外,由于在微服务体系结构中,您可以在不同的服务上实现不同的安全层,因此成功利用特定服务的攻击者可能无法破解其他服务的防御机制。
令牌和API网关
通常,当您打开一个应用程序时,您会看到一个对话框,上面写着“接受cookie的许可协议和权限”。这个信息意味着什么?一旦您接受了它,您的用户凭证将被存储并创建一个会话。现在,下一次访问同一页面时,页面将从缓存中加载,而不是从服务器本身加载。在这个概念出现之前,会话集中存储在服务器端。但是,这是横向扩展应用程序的最大障碍之一。
令牌
所以,这个问题的解决方案是使用令牌来记录用户凭证。这些令牌用于轻松地识别用户,并以cookie的形式存储。现在,每当客户机请求web页面时,请求都会被转发到服务器,然后服务器确定用户是否可以访问所请求的资源。
现在,主要的问题是存储用户信息的令牌。因此,需要对令牌数据进行加密,以避免第三方资源的利用。Jason Web Format(通常称为JWT)是一种开放标准,它定义了令牌格式,为各种语言提供库,并且对这些令牌进行加密。
API网关
API网关作为额外的元素添加,以通过令牌身份验证保护服务。API网关充当所有客户端请求的入口点,并有效地向客户端隐藏微服务。因此,客户端不能直接访问微服务,因此,没有客户端可以利用任何服务。
分布式跟踪和会话管理
分布式跟踪
在使用微服务时,您必须不断地监视所有这些服务。但是,当您必须同时监视大量的服务时,就会出现问题。为了避免这些挑战,您可以使用一种称为分布式跟踪的方法。分布式跟踪是一种查明故障并找出故障原因的方法。不仅如此,您还可以确定失败发生的位置。因此,很容易追踪到哪个微服务面临安全问题。
会话管理
在保护微服务时,会话管理是必须考虑的一个重要参数。现在,只要用户进入应用程序,就会创建一个会话。因此,可以通过以下方式处理会话数据:
您可以将单个用户的会话数据存储在特定的服务器中。但是,这种系统完全依赖于服务之间的负载平衡,只满足水平扩展。
完整的会话数据可以存储在单个实例中。然后数据可以通过网络同步。唯一的问题是,在这种方法中,网络资源会被耗尽。
您可以确保可以从共享会话存储中获取用户数据,从而确保所有服务都可以读取相同的会话数据。但是,由于数据是从共享存储中检索的,因此需要确保有某种安全机制,以便以安全的方式访问数据。
第一会话和相互SSL
第一次会议的想法很简单。用户需要登录一次应用程序,然后才能访问应用程序中的所有服务。但是,每个用户最初必须与身份验证服务通信。当然,这肯定会导致所有服务之间的大量通信,而且对于开发人员来说,在这种情况下找出故障可能很麻烦。
对于相互SSL,应用程序经常面临来自用户、第三方以及彼此通信的微服务的流量。但是,由于这些服务是由第三方访问的,因此总是存在被攻击的风险。现在,这种场景的解决方案是微服务之间的相互SSL或相互身份验证。这样,在服务之间传输的数据将被加密。这种方法的惟一问题是,当微服务的数量增加时,由于每个服务都有自己的TLS证书,因此开发人员很难更新证书。
第三方应用程序访问
我们所有人都访问第三方应用程序。第三方应用程序使用用户在应用程序中生成的API令牌来访问所需的资源。因此,第三方应用程序可以访问特定用户的数据,而不能访问其他用户的凭据。这是关于单个用户的。但是,如果应用程序需要访问多个用户的数据呢?你认为如何处理这样的要求?
使用OAuth
解决方案是使用OAuth。当您使用OAuth时,应用程序会提示用户对第三方应用程序进行授权,以使用所需的信息并为其生成一个令牌。通常,授权代码用于请求令牌,以确保用户的回调URL不会被窃取。
因此,在提到访问令牌时,客户机与授权服务器通信,而该服务器授权客户机,以防止其他人伪造客户机的身份。因此,当您与OAuth一起使用微服务时,这些服务充当OAuth体系结构中的客户端,以简化安全问题。
好了,各位,我不会说这是唯一的方式,通过这些您可以确保您的服务。您可以基于应用程序的体系结构以多种方式保护微服务。因此,如果您希望构建基于微服务的应用程序,那么请记住,服务的安全性是您需要谨慎考虑的一个重要因素。关于这一点,我们将结束这篇关于微服务安全性的文章。我希望这篇文章能让你有所收获。
原文:https://www.edureka.co/blog/microservices-security
本文:https://pub.intelligentx.net/microservices-security-how-secure-your-microservice-infrastructure
讨论:请加入知识星球或者小红圈【首席架构师圈】或者飞聊小组【首席架构师智库】
- 29 次浏览
【微服务架构】微服务已死——迷你服务万岁
免责声明警告:这将是那些纯粹主义者的文章之一,这些文章解释了你如何没有做你认为你正在做的事情,仅仅是因为你并不真正了解你认为你正在做的事情的完整定义。
如果您对此表示满意,那么我们可以继续。
您是否曾经定义或实现过基于微服务的架构?你可能错了。对不起,今天我扮演的是“定义警察”的角色。
你最有可能处理的不是微服务,而是:迷你服务。让我们试着解释一下为什么会这样,以及为什么错了是可以的。
微服务,迷你服务,它们都是小服务,不是吗?
我的意思是,是的,你没有错,事实上,这不是混乱发生的地方。
我们倾向于将“微服务”视为小型的、非常注重逻辑的服务,通常处理一项职责。然而,如果我们看一下 Martin Fowler 对微服务的定义——你知道,他是一个非常聪明的人,所以我们通常想知道他的想法——你会注意到我们缺少一个非常小的但关键的微服务特征: 解耦。
让我们仔细看看我们所说的“微服务”。近来这个词被广泛流传,以至于到了与青少年性行为完全一样的地步:每个人都在谈论它,没有人真正知道该怎么做,每个人都认为其他人都在做,所以每个人都声称他们在做.
说实话,在我作为经理接受的 99% 的采访中,当我询问微服务时,我会得到关于 REST API 的回答。不,它们不一定是同一回事。
根据定义,单独的 REST API 不能是微服务,即使您将它们分成多个较小的,每个负责单一的职责。他们不能,因为根据定义,您要能够直接使用 REST API,您需要了解它。
作为相关的旁注:有两种类型的 REST 开发人员(意味着开发人员创建 REST API):
- 那些实现了他们认为需要的尽可能多的关于 REST 的特性。这意味着如果他们愿意,他们可能会关心面向资源的 URL,也许他们会担心他们的 API 是无状态的,因为实现起来并不难。但是这种类型的开发人员将在 99.9% 的时间里放弃 HATEOAS(超媒体作为应用程序状态的引擎)。换句话说,API 结构的自发现性不再是一个特性,客户端和服务器在两者之间有一个硬编码的契约。
- 严格遵守 REST 标准的那些。我想在我的经验中我只见过一个这样的开发者——所以如果你是这样的,请发表评论,让我们联系! — .以这种方式实现 REST API 可能需要更长的时间,但结果要好得多,尤其是因为客户端与服务器的耦合非常少,他们只需要知道它在哪里以及根端点是什么。其余的都是通过自我发现完成的,非常酷。
但是,在这两种情况下,客户端和服务器之间的耦合仍然存在。你不能仅仅通过 REST 获得解耦的通信,这就是为什么如果我们对微服务的定义很严格——而且我们正在努力做到——就不能这样称呼它们。
所以相反,让我们松开定义的腰带,给自己留一些回旋的空间,把这些服务称为:迷你服务。
所以我们可以定义一个小服务为:
足够小的服务(通常是 API)被认为是“迷你”,它们仍然只需要处理一个单一的责任,但是,我们不太担心“与客户端解耦”部分。
诚然,它们的耦合越少,对未来的变化就越有利,拥有一个动态客户端肯定有助于更快地调整,并且对服务器上的变化没有太大影响。这绝对是一个优点,但这不是我们定义的一部分。
提示:使用独立组件构建,以提高速度和规模
与其构建单一的应用程序,不如先构建独立的组件并将它们组合成服务和应用程序。它使开发速度更快,并帮助团队构建更一致和可扩展的应用程序。
像 Bit 这样的 OSS 工具为构建独立组件和编写应用程序提供了出色的开发人员体验。许多团队从通过独立组件构建他们的设计系统或微前端开始。
试试看→
An independently source-controlled and shared “card” component. On the right => its dependency graph, auto-generated by Bit.
那么什么是微服务呢?
如果我们想获得技术,根据定义,我们仍然在处理一个处理单一职责的服务,但同时它能够与任何使用它的客户端分离。
那么我们如何才能实现这种解耦呢?诀窍是在服务之外思考:沟通渠道。
我们倾向于假设微服务 = REST API,同时,REST API 倾向于自动与客户端-服务器通信范式相关联。就这样,我们在一瞬间从微服务变成了客户端-服务器。但让我们倒带一下。
不久前,我写了一篇关于我最喜欢的服务间通信模式的文章,其中我列出了一个特定的选项:异步消息传递。
该选项不会直接连接客户端和我们的服务,而是需要一个中央消息总线来负责在客户端和服务之间来回传递消息,而无需它们彼此了解。你能看到我们刚刚到达那里吗?没错,我们通过一个简单的范式改变将客户端和服务器完全解耦。
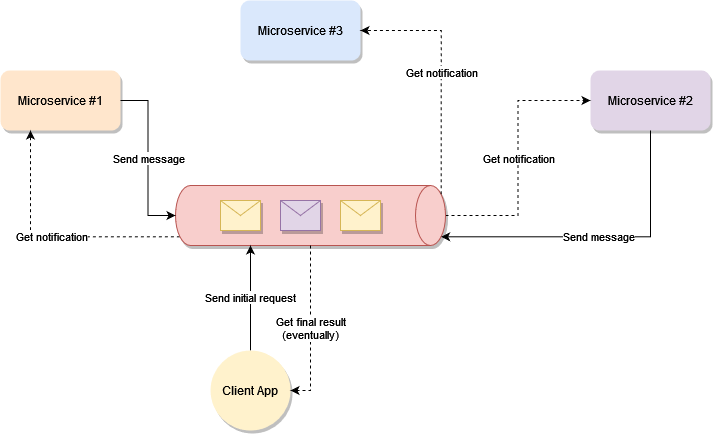
看上图,客户端应用程序用一条消息启动一个潜在的多服务请求。它甚至不必知道涉及多少服务,这太棒了。这意味着编排复杂的请求序列不再是客户责任的一部分。这是一个伟大的交易!
最终,客户端应用程序最终会收到它正在寻找的结果。我在这里说“最终”是因为这不是一个同步通信模型,考虑到它的工作原理,它需要是异步的。这不一定是个问题,它只需要改变我们为客户编写代码的方式(以及我们的其他微服务,考虑到这也是他们相互交谈的方式)。
让我们真实一点:基于消息总线的通信模型不仅可以让您正确地将服务称为“微服务”,它还提供了一些不错的优势:
- 您的整个架构,包括您的客户端应用程序的架构,都变得反应式。在我的书中,这是一个了不起的优势,尤其是当您处理本质上需要很长时间才能解决的请求时。也许您正在处理非常复杂的计算、运行一些 ML 模型,或者只是从其他第三方 API 收集数据。无论是什么原因,您的客户都可以在等待响应时继续做其他事情,而不是被活动连接锁定,希望它不会超时。事实上,在我最近的这次演讲中,我介绍了反应式架构的一些好处以及如何使用 Redis 创建一个:
- 水平扩展您的服务非常容易。对于耦合实现,例如让 REST API 直接与客户端对话,您需要有某种负载均衡器或 API 网关,以允许您在同一微型服务的所有副本之间分配负载。但如果我们处理的是解耦架构,我们不必担心,第一个接收消息的微服务会处理它,让副本自由处理下一个传入的消息。
- 添加新服务对客户端没有直接影响。如果你问我,这很残酷。因为通过客户端-服务器通信,添加新服务(因为您正在添加新功能或因为您决定拆分现有服务)意味着客户端现在需要知道在不同情况下与谁联系。要么,要么您将编排移动到所有请求都到达的中央 API,但是,在这种情况下,您还必须更新服务上的编排逻辑。当然,客户端不受影响,但您仍然有副作用。有了基于微服务的架构,情况就不再如此了。编排由消息总线完成,使添加几乎没有影响。
- 更容易重试和更有弹性的架构。这是两个非常相关的点。一方面,您必须担心如果您的服务因任何原因而死(或至少无法访问)会发生什么。对于客户端-服务器通信,这意味着请求将失败。然而,对于消息总线来说,这仅仅意味着在服务恢复之前请求不会完成。消息总线可以将消息存储一段时间,从而允许创建更具弹性的架构。同时,如果你想在失败时有某种重试逻辑,正如我已经提到的,这对于基于微服务的架构是隐含的,而你必须自己为客户端-服务器架构编写代码。
还不相信?真的吗?那可能是因为你的用例不是微服务的完美匹配。也许迷你服务是适合您的解决方案。
本文的主要内容是了解虽然“正式已知的微服务”可能很棒,但它们并不是每个架构都必须使用的。
这都是关于权衡的。微服务可能需要在基础设施层面做更多的工作,甚至可能需要让你的开发团队正确地思考异步通信。然而,从长远来看,最终产品可能会产生更好的结果和更少的麻烦。
没有灵丹妙药的架构可以解决每个人的问题,所以不要把这个狂热者对微服务的定义当我告诉你放弃你的客户端-服务器方式。这与我的意图相去甚远。
本文旨在再次表明,客户端-服务器通信模型虽然可能是最常见且更易于实现的模型,但不一定是最好的模型。
所以你怎么看?您准备好最终尝试一些微服务来进行更改了吗?或者你会暂时坚持使用迷你服务吗?
原文:https://blog.bitsrc.io/microservices-are-dead-long-live-miniservices-40…
- 391 次浏览
【微服务架构】微服务最佳实践

关键需求
-
最大限度地提高团队的自主性:创建一个团队可以完成更多工作而不必与其他团队协调的环境。
-
优化开发速度:硬件便宜,人不是。 使团队能够轻松快捷地构建强大的服务。
-
关注自动化:人们犯错误。 更多的系统操作也意味着更多的事情可能出错。 自动化一切。
-
在不影响一致性的情况下提供灵活性:让团队能够自由地为自己的服务做正确的事情,但是有一套标准化的构建模块可以长期保持健康。
-
为弹性而构建:由于多种原因,系统可能会失败。 分布式系统引入了一整套新的故障场景。 确保采取措施尽量减少影响。
-
简化的维护:而不是一个代码库,你会有很多。 有准则和工具来确保一致性。
挑战:一次切换系统
-
从一个单一的体系结构切换到一个微服务体系结构是不是你可以一次完成的。 如果你有一个单一的服务器,那么你可能会在其周围紧紧地建立一个存储库,部署任务,监视和其他许多事情。 改变这一切并不容易。
-
如果一个公司从来没有使用微服务的经验,那么即使是一个绿地项目也会比他们想象的更难。
-
保留单片服务器,但是任何新的服务都是作为一个微服务来开发的,所以最终的东西都是从原来的服务器中流出来的,直到最终成为我们最老,最大的微服务。
挑战:拆分系统
-
自项目开始以来,如果将组件和服务粘合在一起,将其隔离起来可能相当具有挑战性。
-
您需要定义各个部分之间的交互和流程。 如果你没有很好的定义,你的系统会产生更多的问题。
-
没有模式; 将系统划分为微服务有许多不同的规则,但是没有人会告诉你如何在应用程序中使用它。 没有两个相同的微服务。
-
将整体系统分解成微服务的唯一方法是首先检查整体系统,以查看它最“伤害”的位置。 系统的这些部分应该被取出并转换成微服务。
-
如果你没有适当的监控,你将不会看到你的系统是如何工作的。 监视所有部分是如何工作的,以及他们在做什么。 如果您监控您的系统,您可以轻松检测并解决问题。
-
渐进地,逐渐式是模块分离单片系统的最好方法。 如果你想一次做所有事情,你一定会失败的。
挑战:组织认同
-
获得组织认同可能是最难的部分。
-
这不是一个技术决定。您需要清楚说明微服务架构的好处,以说服您的公司重新分配资源。在这样的变革被组织接受之前,这是一个漫长而乏味的过程,组织规模越大,决策的时间就越长。
-
说服你的组织改用微服务的最佳方式是将系统中的一个非关键部分转换为微服务。 通过这种方式,您可以使用真正的,可用的微服务来展示其优势。
挑战:团队
-
团队本身面临着最大的挑战,因为它需要不同的思考。
-
开发人员必须花更多的时间来了解什么是端到端场景。 他们需要熟悉这些技术,可能需要转换思维方式,这需要时间。
-
对于在一个可以进行端到端测试的世界中工作的人来说,这是不舒服的,现在你突然把它分解成小块。 这更多的是文化上的变化。
-
从非常小的东西开始,在那里你可以真正受益,并选择一些不是你的应用程序的关键部分。 获得一个小团队,并将应用程序的这一部分转换为微服务。 证明它实际上是更好的,并逐步向组织扩展。
-
避免将整个系统一次切换到微服务。
Best Practices:平台:
-
您的平台是一套与支持工具相结合的标准
-
微服务架构转换复杂性。 而不是一个复杂的系统,你有一堆简单的服务与复杂的交互。 我们的目标是保持复杂性可控。
Best Practices:服务要点
-
独立开发和部署服务
-
服务应该有他们自己的私人数据
-
保持服务小到足以保持专注和足够大以增加价值
-
将数据存储在数据库中,而不是短暂的服务实例
-
最终的一致性是你的朋友
-
尽可能将工作卸载到异步工作人员
-
保持在一个共同的地方完成所有服务的帮助文档
-
分配负载平衡器的工作
-
网络边界上的聚合服务可以转化为外部世界
-
分层安全,不要编写自己的加密代码!
Best Practices:服务交互
-
通过HTTP传输数据,使用JSON或protobuf的进行序列化
-
对于HTTP服务,500系列错误或超时意味着服务不健康
-
API应该简单而有效
-
服务发现机制使服务很容易找到对方
-
倾向于集权协调员的分散交互
-
版本所有的API,在相同的服务实例中共存多个版本
-
在服务超载之前,使用资源限制来快速失败
-
连接池可以减少突发请求高峰对下游影响
-
Timouts最大限度地减少下游延误和失败的影响
-
容忍不相关的下游API更改
-
断路器在艰难时期给下游服务中断
-
关联ID可帮助您跟踪跨服务日志的请求
-
确保你能保证最终的一致性
-
对所有API调用进行身份验证可以更清楚地了解使用模式
-
使用随机重试间隔自动重试失败的请求
-
只能通过暴露和记录的API与服务进行交谈
-
经济力量鼓励有效使用可用资源
-
客户端库可以处理所有的基础知识,因此您可以专注于重要的事情
Best Practices:开发
-
为所有服务使用通用的源代码管理平台
-
要么模仿开发或使用孤立的云开发环境
-
推动工作代码经常主线
-
Release更少,Release更快
-
警告:共享库很难更新
-
您的服务模板应该覆盖基本原理
-
简单的服务也很容易替换
Best Practices:部署
-
使用系统映像作为部署包
-
有办法自动将任何版本的任何服务部署到任何环境
-
功能标志将代码部署与功能部署分开
-
配置应该在部署包之外进行管理
Best Practices:运维
-
在一个地方管理所有日志
-
为所有服务使用通用监控平台
-
无状态服务很容易自动扩展
-
无法在您的平台上运行的相关服务也需要自动化
Best Practices:人
-
服务团队开发,部署和运营自己的服务
-
团队在日常运营中应该是自主的
- 56 次浏览
【微服务架构】微服务架构 - 适合您的软件开发吗?
“微服务架构提供了一系列技术优势,有助于提高软件项目的开发速度和产品质量,同时也有助于提高整体业务灵活性” - MARK EMEIS,软件技术高级总监,CA技术
自从该术语成立以来,微服务一直在软件开发中获得成功。微服务(又称微服务架构)是面向服务的体系结构(SOA)的变体,用于开发大型应用程序,其中服务按照业务域分为多个块。它提供了复杂应用程序的持续交付/部署,使应用程序更易于理解,开发,测试,并且对架构侵蚀更具弹性。微服务架构提供了一种以新颖方式编织现有系统的新方法,以便快速提供软件解决方案。由于其提供模块化,可扩展性,可用性的能力,成为软件行业最热门的话题之一;许多企业软件开发公司都热衷于采用它。
但是,微服务究竟是什么?它能改善组织的文化,技能和需求吗?
为了深入理解微服务,让我们首先理解相反方法单片架构的要点。
关于单体软件的一切
维基百科说:“单片应用程序描述了一个单层软件应用程序,其中用户界面和数据访问代码从单一平台组合成一个程序。”

单片软件使用三层架构,即
- 表示层 - 它是应用程序的最顶层,描述了用户界面。主要功能是将任务和结果转换为用户可以理解的内容。用户界面代码使用HTML,JavaScript和CSS等客户端技术编写。
- 业务层 - 该层做出逻辑决策并执行计算。它处理两层之间的数据,并使用像Spring这样的技术。
- 数据访问层 - 这里存储信息并从数据库中检索信息。信息将传递到业务层,最终传递给用户。它使用像Hibernate这样的ORM工具来处理信息。
这里,Web应用程序客户端发送请求;层执行业务逻辑,数据库存储应用程序特定数据,UI将特定数据显示给用户。但是,由于它们共享相同的代码库,因此可能会出现一些问题。
这种类型的架构在一段时间内运行良好,但由于对持续交付的需求不断增加,此模型存在多个问题。
单片架构的缺点
- 运维开销:不同的利益相关者使用不同的单一应用层;因此团队将被限制在特定领域的专业知识。在表示层工作的团队专注于UI技术,但对数据访问层的了解最少。因此,如果要添加新功能,则需要不同的团队来协调和传递特定功能。这导致从构思到上市时间的更长时间跨度,并最终影响业务ROI。
- 软件堆栈自治:它限制了技术选择并迫使整个层使用单一框架。例如,如果表示层是在HTML框架中编写的,则整个层将在同一框架内实现。这避免了实施最新技术,导致应用程序代码在短时间内过时。
- 隐式接口:由于此代码在单个文件中发布,因此应用程序中的微小更改会要求重建整个应用程序。因此,正在进行的应用程序被放下并导致需要重新部署新版本。这种性质导致更新更少,并且无法尽可能快地发展。
- 可扩展性:单片应用程序具有一维可扩展性;因此无法扩展单个组件。因此,即使大多数应用程序可能不需要扩展,也需要扩展整个应用程序。
开发没有良好架构的软件会给组织带来很大的成本。例如:如果软件开发公司通过遵循非模块化方法开发软件,其中UI功能和业务功能混合在相同的源文件中,公司可能需要投入大量资金来支持他们在最新智能手机本机中的应用程序应用。这严重影响了软件的可维护性并延长了产品上市时间,最终影响了公司的销售。
单片体系结构一直是传统方法,但是扩展的限制,维护大型代码库的困难,高风险升级以及大量的前期设置成本迫使企业或软件开发公司探索不同的方法。单片应用程序是一个难以破解的难题,难以理解并随着时间的推移而扩展。
因此,为了避免这些问题,微服务架构可以成为一个救星!它提供360度扭曲以解决上述复杂问题;帮助软件开发公司在竞争对手中脱颖而出。
微服务架构简介
微服务是一种软件开发技术,它将应用程序构建为松散耦合服务的集合。每项服务都是独立的,应该实现单一的业务能力。微服务架构旨在克服较大应用程序的挑战,故障和故障。微服务提供了为系统增加弹性的机会,以便组件可以优雅地处理峰值和错误。有了这个,每个利益相关者都可以专注于整个应用程序的一个特定元素,具有自己的编程风格,而不用担心其他组件。微服务中的通信可以毫不费力地执行,因为它们是无状态的并且在明确定义的接口中(请求和响应是独立的)。
如果使用微服务方法开发应用程序/软件,将有助于采用DevOps方法,并将消除部署效率低下,从而缩短产品上市时间。由于微服务与设备和平台无关,因此可以开发应用程序,在大多数平台上提供增强的用户体验,包括Web,移动,物联网,平板电脑,可穿戴设备等等。
例如:沃尔玛加拿大在2012年之前使用了单片架构!该公司在处理600万页面浏览量/分钟时遇到了麻烦,这耗费了更多时间并导致销售额减少。由于这些问题,他们将自己的软件架构重构为微服务,并在一夜之间找到了即时结果和高转换率。停机时间最小化,公司能够使用更便宜的x86服务器而不是昂贵的硬件商品,从而节省了20%-50%的成本。
微服务和SOA
这是SOA的自然演变,其中各种技术堆栈将技术多样性带入开发团队。 SOA和微服务都允许将复杂的工作负载分解为更小,更易于管理和独立的部分。
但是,它们之间存在一些基本差异。
微服务与SOA
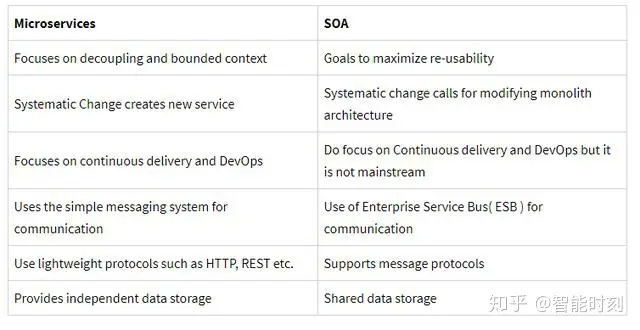
微服务哲学
微服务的哲学类似于Unix哲学,即“做一件事,做得好”。特征描述如下......
- 用于执行单一功能的组件化
- 按业务能力组织
- 专注于不加工的产品
- 分散治理和数据管理
- 服务具有弹性,弹性,可组合性,最小化和完整性
软件开发公司为什么要投资微服务架构?
- 改善了故障隔离
在微服务架构中,开发人员确切地知道在哪里寻找要解决的问题。如果单个模块受到影响,则可以轻松拆卸或解决,而不会影响应用程序的其他部分;提高应用程序的可用性。这在整体应用中完全矛盾;单个组件的故障可以拉低整个应用程序。例如,移动游戏应用程序(基于单片架构),具有不同的组件,如支付,登录,播放器,历史记录等。如果特定组件开始占用更多内存空间,整个应用程序将受到影响,这将导致糟糕的用户体验。
- 易于修改技术堆栈
通过微服务,软件开发公司可以在特定组件上尝试新的堆栈或最新技术,以提高可用性并在应用程序级别获得更大的好处。由于没有依赖性问题,软件开发人员可以避免使用特定的技术堆栈,如果他们不提供一致的用户体验。通过这种持续的现代化,您的系统不会变得容易过时。
- 提供可扩展性
微服务可扩展存在性能问题的部件,并使用最符合服务要求的硬件。由于每个服务都是独立的组件,因此可以使用更多容器部署扩展,从而实现更有效的容量规划,更少的许可成本和适当的硬件。关键服务的组件可以部署在多个服务器上,以提高可用性和性能,而不会影响其他服务的性能。这种可扩展性可带来更好的客户体验并增加成本节约。
- 与该组织保持一致
如果组织使用微服务,则可以定义团队规模以匹配所需任务。此外,团队可以分解为更小的组,并可以专注于应用程序的单个组件。由于最终目标是客户满意度和良好的用户体验,团队不分为UI团队,数据库团队等。例如,如果在阿联酋工作的团队正在处理三项服务,而在加利福尼亚工作的团队正在处理五项服务,那么在加利福尼亚和阿联酋工作的每个团队都可以独立发布和部署不同的功能。这些跨职能团队致力于实现单一功能,打破团队之间的孤岛,促进更好的协作。
- 提高生产力和速度
通过微服务,可以轻松解决生产率和速度问题。不同的团队同时处理不同的组件,而无需等待一个团队完成任务。这样可以加快质量保证,因为每个微服务都可以单独测试。其他利益相关者可以致力于增强已经开发的组件,而其他程序员则在开发其他程序员。这样可以提高速度并加快产品的发布速度。
需要考虑的障碍......
仅仅因为,一切看起来都很华丽,并不意味着它对软件行业来说是完美的;它确实有潜在的痛苦,也需要解决: -
- 由于微服务侧重于分布式系统和独立服务,因此需要在模块之间仔细处理每个请求。可能会发生其中一个服务没有响应,迫使开发人员编写额外的代码以避免中断。
- 基于微服务的应用程序的测试可能是一项痛苦的任务,因为在开始测试之前需要确认每个依赖服务。随着服务数量的增加,复杂性不会留在后台!密切关注所有服务变得不切实际,因为可能会出现数据库错误,网络延迟,缓存问题等。因此,弹性测试和故障注入成为必须。
- 每项服务都依赖于自己的API和平台,追踪所有内容都可能是一项痛苦的堆叠工作。领导者需要监控多个实体并管理整个基础架构,因为如果在任何情况下任何服务都失败,追踪问题就变得很繁琐。因此,强有力的监测变得必要。
随着持续交付和快速发展,员工必须提高灵活性和速度,这需要利用微服务带来的好处。如果他们花费很长时间来配置服务器,公司可能会遇到严重问题。
单体架构和微服务架构的区别
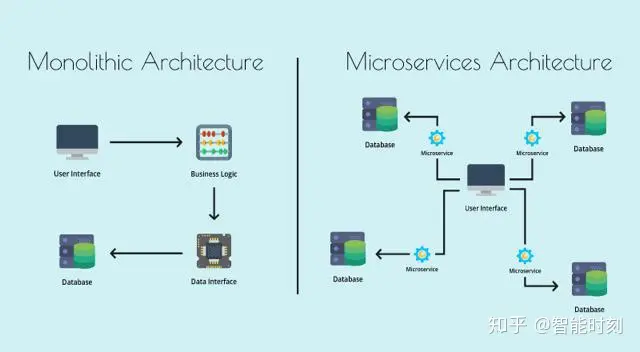
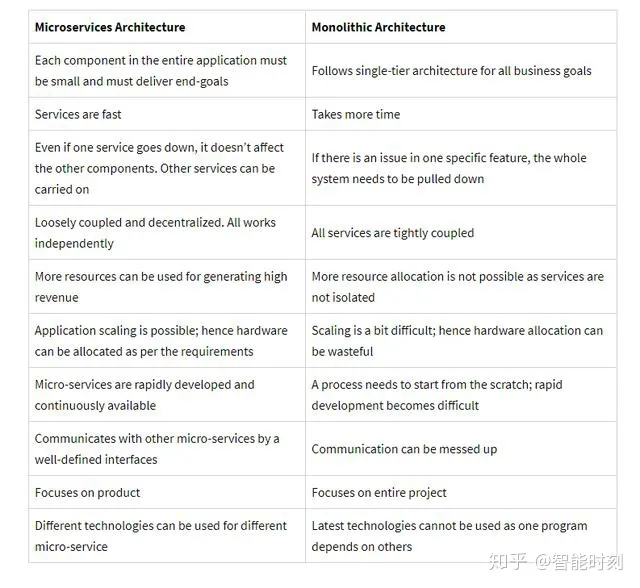
微服务架构的未来
您可能已经清楚了解微服务架构及其改变软件行业所具有的潜力!随着数字技术的使用越来越多,设备支持越来越多;软件开发正在深入到复杂的过程中。但软件行业拥有微服务架构,可以作为解决软件开发公司复杂性的完美解决方案。如果公司考虑采用它,它肯定会在技术和操作上影响文化。
Big Giants已经在使用它......
今天,随着微服务的兴起,大多数组织正在拉低整体架构并采用现代架构来利用激烈的竞争。其中一些包括Netflix,eBay,亚马逊,Twitter,PayPal,沃尔玛等等......
让我们看看NetFlix如何解决......
- NetFlix:NetFlix是最早在SOA架构中使用微服务的采用者之一。公司快速发展的时候,无法建立数据中心来提供可扩展性。开发中的一些小问题需要软件开发人员一次又一次地查找问题。但是,当他们使用微服务重构现有架构时,他们每天能够通过800个不同设备的API处理十亿次呼叫。如今,Netflix正在使用500多个微服务和30多个工程团队。
- 优步:优步以单一建筑为单一城市的单一建筑开始了它的旅程。由于它只在一个城市运营,因此一个代码库选项似乎是一个干净的选择并解决了所有业务问题。但是,当它迅速扩展到其他城市时,组件变得紧密耦合,封装是另一个问题,持续集成变成了一种负担。因此,为了解决所有这些复杂问题,工程团队重构了现有的应用程序并使用了微服务。他们介绍了
- 所有乘客和司机都通过的API网关
- 部署单独的单元以执行单独的功能
- 所有功能都可以单独缩放
因此,优步通过从单片架构转向微服务架构而获益匪浅。
- 亚马逊:亚马逊是大型电子商务商店之一,紧随其后的是整体应用程序,它使开发人员彼此分开,并将团队与最终目标区分开来。该公司必须解决协调过程之间的冲突,将它们合并为一个版本并生成所有版本的主版本。需要重新运行全新的基于代码的测试用例,以确保没有任何冲动。这些故障使公司使用微服务架构!该软件解决方案通过自己的Web服务API与全世界进行通信。因此,它非常成功。
做出选择
无论选择哪种软件解决方案,无论是单片还是微服务,都有它们各有优缺点。最后,选择软件架构取决于您的项目要求,项目规模等等。如果您希望构建小型软件,单片机可以作为一种选择,如果您更喜欢开发复杂的软件,那么微服务架构肯定是一个肯定的镜头。
仍然不清楚您的要求或希望为您的下一个大项目重构现有的软件架构?请联系我们,我们的技术顾问会回复您解决您的疑问!
- 369 次浏览
【微服务架构】微服务架构——探索 UBER 的微服务架构
从我之前的文章中,你一定对微服务架构有了一个基本的了解。 在本博客中,您将深入了解架构概念并使用 UBER 案例研究来实现它们。
在本文中,您将了解以下内容:
- 微服务架构的定义
- 微服务架构的关键概念
- 微服务架构的优缺点
- 优步——案例研究
在我谈论 UBER 的微服务架构之前,如果我给你定义微服务,这将是公平的。
微服务的定义
因此,没有对微服务(也称为微服务架构)的正确定义,但您可以说它是一个框架,由执行不同操作的小型、可单独部署的服务组成。
微服务专注于单个业务领域,可以将其实现为完全独立的可部署服务,并在不同的技术堆栈上实现它们。
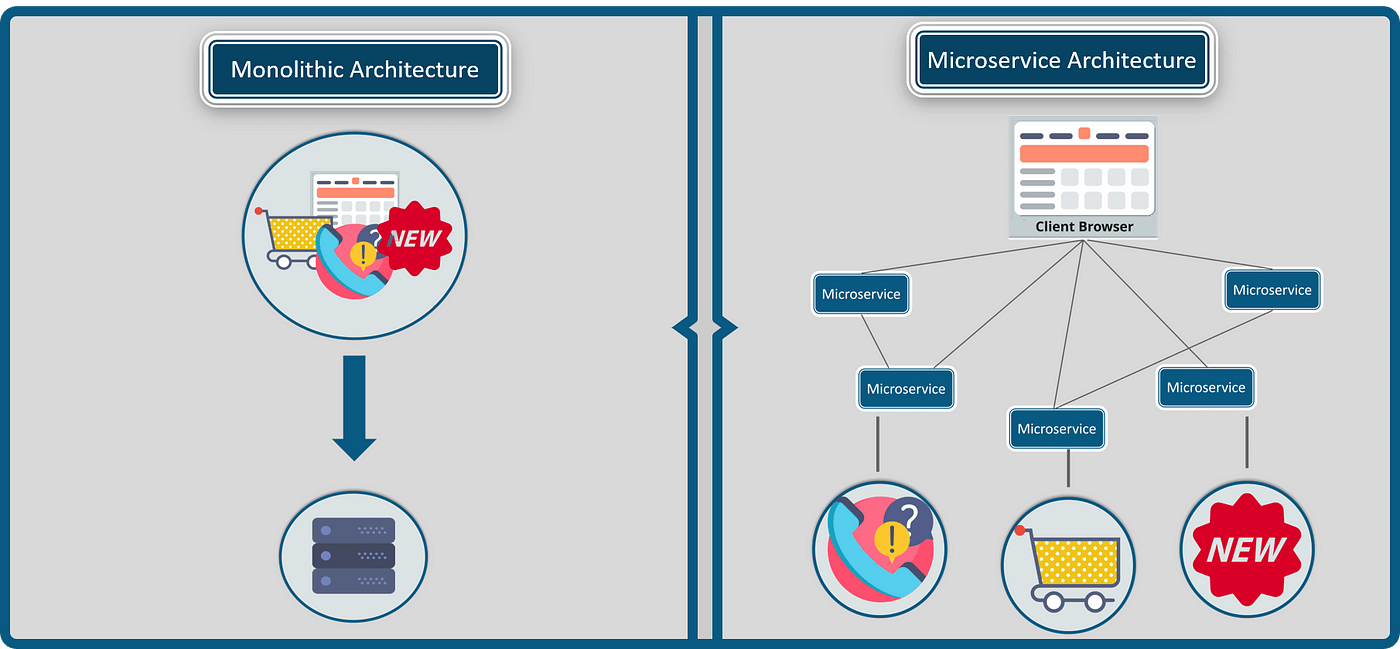
Difference Between Monolithic and Microservice Architecture — Microservice Architecture
参考上图了解单体架构和微服务架构的区别。为了更好地理解这两种架构之间的差异,您可以参考我之前的博客 What Is Microservices。
为了让你更好地理解,让我告诉你一些微服务架构的关键概念。
微服务架构的关键概念
在开始使用微服务构建自己的应用程序之前,您需要清楚应用程序的范围和功能。
以下是讨论微服务时要遵循的一些准则。
设计微服务时的指南
作为开发人员,当您决定构建应用程序时,将域分开并明确功能。
您设计的每个微服务应仅专注于应用程序的一项服务。
确保您以这样一种方式设计了应用程序,即每个服务都可以单独部署。
确保微服务之间的通信是通过无状态服务器完成的。
每个服务都可以进一步重构为更小的服务,拥有自己的微服务。
现在,您已经阅读了设计微服务时的基本指南,让我们了解微服务的架构。
微服务架构如何工作?
典型的微服务架构 (MSA) 应包含以下组件:
- 客户
- 身份提供者
- API 网关
- 消息格式
- 数据库
- 静态内容
- 管理
- 服务发现
请参考下图。
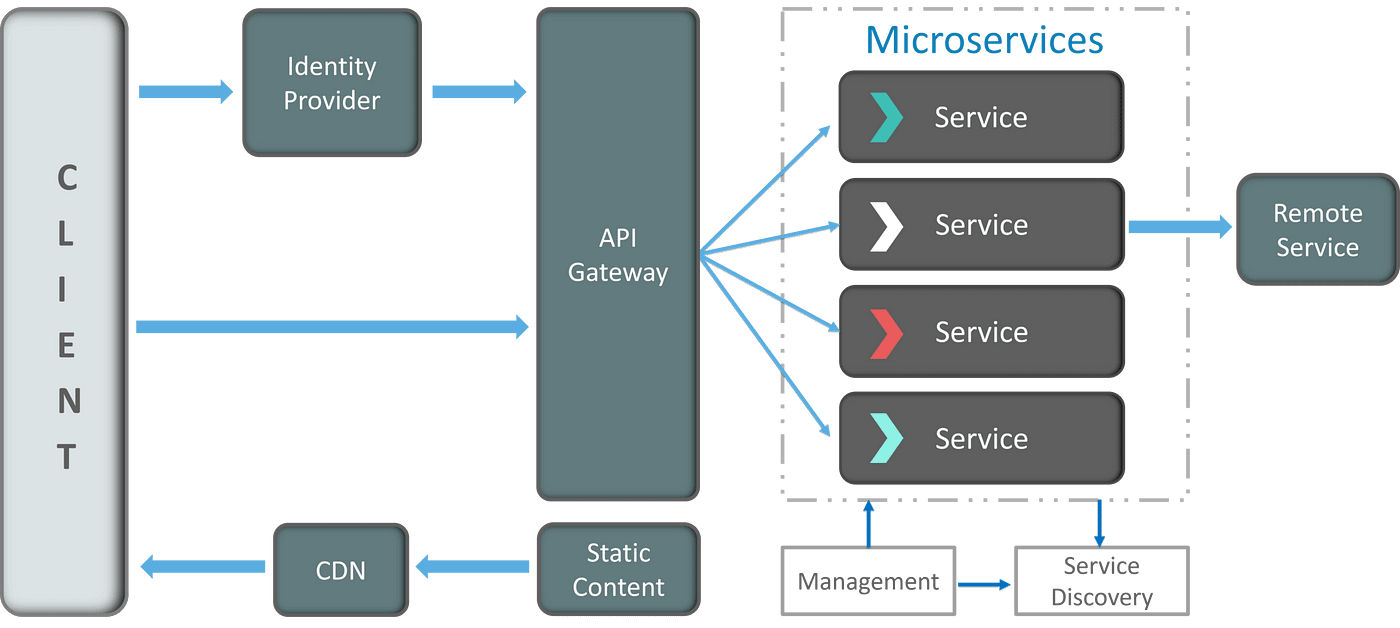
Architecture Of Microservices - Microservice Architecture
我知道架构看起来有点复杂,但让我为您简化一下。
1. 客户
该架构从不同类型的客户端开始,从不同的设备尝试执行各种管理功能,例如搜索、构建、配置等。
2. 身份提供者
然后将来自客户端的这些请求传递给身份提供者,身份提供者对客户端的请求进行身份验证并将请求传递给 API 网关。然后通过定义明确的 API 网关将请求传送到内部服务。
3.API网关
由于客户端不直接调用服务,API Gateway 充当客户端将请求转发到适当微服务的入口点。
使用 API 网关的优势包括:
- 所有服务都可以在客户不知情的情况下更新。
- 服务还可以使用对 Web 不友好的消息传递协议。
- API 网关可以执行横切功能,例如提供安全性、负载均衡等。
在接收到客户端的请求后,内部架构由微服务组成,这些微服务通过消息相互通信来处理客户端请求。
4. 消息格式
他们通过两种类型的消息进行通信:
- 同步消息:在客户端等待服务响应的情况下,微服务通常倾向于使用 REST(Representational State Transfer),因为它依赖于无状态的客户端-服务器和 HTTP 协议。使用该协议是因为它是一个分布式环境,每个功能都用资源表示以执行操作
- 异步消息:在客户端不等待服务响应的情况下,微服务通常倾向于使用 AMQP、STOMP、MQTT 等协议。这些协议用于这种类型的通信,因为定义了消息的性质并且这些消息必须在实现之间是可互操作的。
您可能会想到的下一个问题是使用微服务的应用程序如何处理它们的数据?
5. 数据处理
好吧,每个微服务都拥有一个私有数据库来捕获它们的数据并实现各自的业务功能。此外,微服务的数据库仅通过其服务 API 进行更新。请参考下图:

Representation Of Microservices Handling Data — Microservice Architecture
微服务提供的服务被转发到任何支持不同技术栈的进程间通信的远程服务。
6.静态内容
在微服务内部进行通信后,它们将静态内容部署到基于云的存储服务中,该服务可以通过内容交付网络 (CDN) 将它们直接交付给客户端。
除了上述组件之外,典型的微服务架构中还出现了一些其他组件:
7、管理
该组件负责平衡节点上的服务并识别故障。
8. 服务发现
充当微服务的指南,以查找它们之间的通信路径,因为它维护了节点所在的服务列表。
现在,让我们看看这种架构的优缺点,以便更好地了解何时使用这种架构。
微服务架构的优缺点
请参阅下表。

Pros and Cons of Microservice Architecture — Microservice Architecture
让我们通过比较 UBER 以前的架构和现在的架构来更多地了解微服务。
优步案例研究
UBER 以前的架构
与许多初创公司一样,UBER 的旅程始于为单一城市的单一产品而构建的单体架构。 拥有一个代码库在当时似乎很干净,并且解决了 UBER 的核心业务问题。 然而,随着 UBER 开始在全球扩张,他们在可扩展性和持续集成方面面临着各种问题。
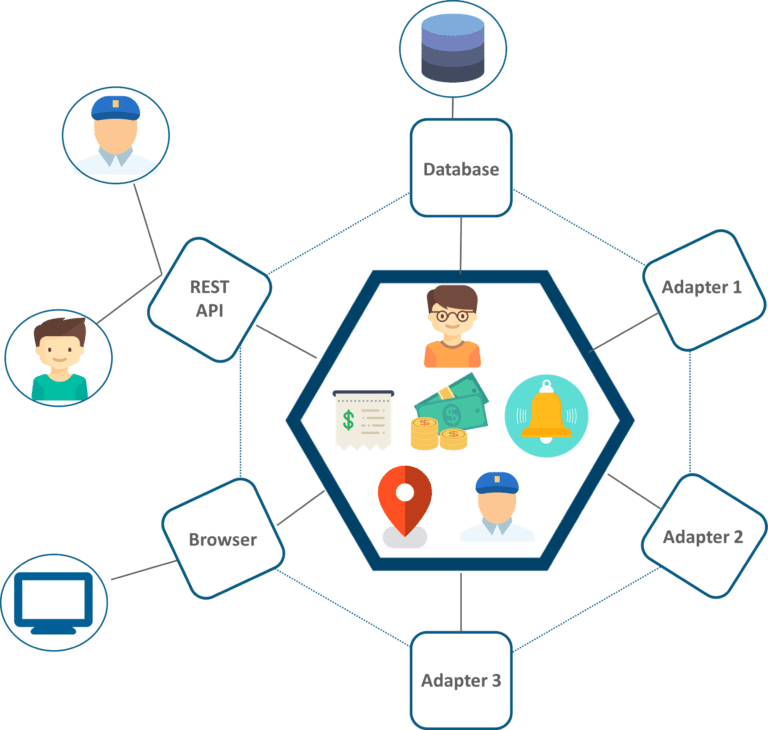
上图描绘了 UBER 之前的架构。
- 存在用于连接乘客和驾驶员的 REST API。
- 三个不同的适配器与其中的 API 一起使用,以执行我们在预订出租车时看到的计费、付款、发送电子邮件/消息等操作。
- 一个 MySQL 数据库来存储他们的所有数据。
因此,如果您注意到这里的所有功能,例如乘客管理、计费、通知功能、支付、行程管理和驾驶员管理,都在一个框架内组成。
问题陈述
虽然 UBER 开始在全球范围内扩张,但这种框架带来了各种挑战。以下是一些突出的挑战
- 所有功能都必须一次又一次地重新构建、部署和测试以更新单个功能。
- 由于开发人员不得不一次又一次地更改代码,因此在单个存储库中修复错误变得极其困难。
- 在全球范围内引入新功能的同时扩展功能很难同时处理。
解决方案
为了避免此类问题,UBER 决定改变其架构,并效仿亚马逊、Netflix、Twitter 等其他高速增长的公司。因此,UBER 决定将其单体架构分解为多个代码库,形成微服务架构。
请参考下图了解 UBER 的微服务架构。
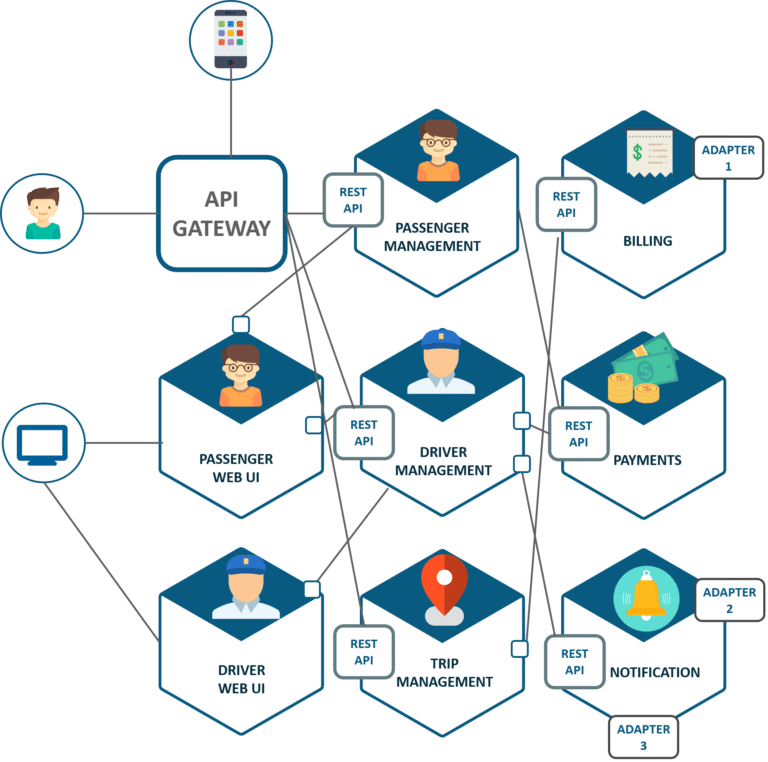
Microservice Architecture Of UBER — Microservice Architecture
- 我们在这里观察到的主要变化是引入了 API 网关,所有司机和乘客都通过它连接起来。从 API 网关连接所有内部点,例如乘客管理、司机管理、行程管理等。
- 这些单元是执行不同功能的单独独立的可部署单元。
例如:如果您想更改计费微服务中的任何内容,那么您只需要部署计费微服务,而不必部署其他微服务。
- 现在所有功能都单独缩放,即删除了每个功能之间的相互依赖关系。
例如,我们都知道搜索出租车的人数比实际预订出租车和付款的人数要多。这让我们推断,在乘客管理微服务上工作的进程数量比在支付上工作的进程数量要多。
通过这种方式,UBER 受益于将其架构从单体架构转变为微服务架构。
我希望你喜欢阅读这篇关于微服务架构的文章。如果您想查看更多有关人工智能、DevOps、Ethical Hacking 等市场最流行技术的文章,您可以参考 Edureka 的官方网站。
请注意本系列中的其他文章,这些文章将解释微服务的其他各个方面。
- 1. 什么是微服务?
- 2. 微服务设计模式
- 3. 微服务与 SOA
- 4.微服务教程
- 5. 微服务设计模式
- 6. 微服务安全
原文:https://medium.com/edureka/microservice-architecture-5e7f056b90f1
- 62 次浏览
【微服务架构】微服务架构资料
- Microservice Databases: Migrating from Relational Monolith to Distributed Data (By O'Reilly)
- https://www.infoq.com/vendorcontent/show.action?vcr=4348&primaryTopicId=2498&vcrPlace=EMBEDDED
- Why Do We Need Architectural Diagrams?
- https://www.infoq.com/articles/why-architectural-diagrams/
- Enterprise Systems Built with Microservices are Designed to Expect Failures, But Then What? How Do We Handle Failures?
- https://www.infoq.com/presentations/failure-cache-redis-pcc-hazelcast
- Achieving High Throughput with Reliability in Transactional Systems
- https://www.infoq.com/presentations/architecting-transactional-system
- 事件流和工作流引擎——Kafka 与 Zeebe
- https://www.infoq.cn/article/VORC3JP7ky*6tG4OTHI5
- 微服务框架 Lagom 1.5 发布,支持 Kubernetes 和 OpenShift 部署
- https://www.infoq.cn/article/meYfthDexSU7OrL-TMg5
- 分布式事务 Seata TCC 模式深度解析
- https://www.infoq.cn/article/G33hCC-QoSJPlkt4e64E
- 40 次浏览
【微服务架构】微服务架构(示例和图表)
介绍
在设计应用程序时,应用程序体系结构是一个需要考虑的重点,多年来,许多不同的软件开发范例已经过去,不变的主题是,需要以模块化的方式对软件系统进行组件化。由于许多原因,模块化软件是有益的。它使源代码更易于理解和遵循,开发人员可以可视化代码库并大致了解查找缺陷的位置 - 从而提高维护效率。
如果使用您的应用程序的用户数量增加,那么架构良好的软件系统也更容易扩展,更不用说,如果新开发人员加入您的团队,一个架构良好的系统可以使入职流程更快,并减少开发人员配给时间,因为每个人都是编码到一组特定的标准。
构建软件项目有很多方法,例如N-Tiered,面向服务的体系结构(SOA)或微服务体系结构等等。然而,在这篇文章中,针对软件开发人员,开发经理和CTO,我们专门研究微服务架构并涵盖以下主题:
- What is Microservice Architecture? (什么是微服务架构?)
- The need for Microservice Architecture (对微服务架构的需求)
- Benefits of Microservice Architecture (微服务架构的好处)
- Challenges of Microservice Architecture (微服务架构的挑战)
- Should You Adopt Microservice Architecture? (你应该采用微服务架构吗?)
- Sample Microservice Architecture (示例微服务架构)
- Summary (摘要)
当你阅读这篇博文时,你将对微服务架构是什么,它的好处,如果你应该考虑它以及如何构建一个应用程序以采用这种架构范例有一个充分的理解,那么让我们得到开始!
什么是MICROSERVICE架构?
在过去的几十年中,应用程序已经以整体方式开发,从上到下编码为一个单独的单元,有时没有真正的结构或思想用于将来的维护,这可能导致一系列问题。构建不良的软件解决方案也可能会出现问题,无法通过新功能进行调试或扩展,而且通常情况下,处理起来并不是很好。
微服务架构是面向服务的架构(SOA)的一种形式,其中软件应用程序被构建为松散耦合的服务的集合,而不是单个软件应用程序。每个微服务可以独立于另一个创建,或者甚至以完全不同的编程语言创建并独立运行。
在这一切的核心,每个微服务都试图满足您正在处理的特定用户故事或业务需求。它是当今日益增长的互联世界中理想的架构设计模式,有助于支持跨云,移动,物联网(IoT)甚至可穿戴设备的多种平台和设备。
实现微服务的一种流行方式是使用HTTP / REST和JSON等协议作为架构设计模式,我们看到许多主要的SaaS提供商在其解决方案和服务中采用微服务。
从Microsoft到IBM等等,软件供应商和服务提供商正在实施微服务架构。 Twitter,Netflix,eBay和亚马逊等主要厂商也青睐微服务架构,因为它有助于其服务的开发,可扩展性和持续交付。 这带来了微服务架构的一些好处。
作为一种架构实践,微服务架构近年来越来越受欢迎,这降低了它可以带来软件开发团队和企业的好处。随着软件复杂性的增加,能够将应用程序中的功能区域组件化为多组独立(微)服务可以产生许多好处,包括但不限于以下内容:
- 更有效的调试 - 不再跳过应用程序的多个层,实质上是更好的故障隔离
- 加速软件交付 - 可以使用多种编程语言,从而使您可以访问更广泛的开发人才库
- 更容易理解代码库 - 提高生产力,因为每个服务代表一个功能区域或业务用例
- 可扩展性 - 组件化的微服务自然有助于通过REST等行业标准接口与其他应用程序或服务集成。
- 容错 - 由于更具弹性的服务,减少了停机时间
- 可重用性 - 由于微服务是围绕业务案例而非特定项目组织的,由于它们的实现,它们可以重复使用并轻松地插入到其他项目或服务中,从而降低成本。
- 部署 - 因为所有内容都封装在单独的微服务中,您只需要部署已更改的服务而不是整个应用程序。微服务开发的一个关键原则是确保每项服务与现有服务松散耦合。
但是,不要只听我们的话,这里有一些真实的微服务实例,这个架构设计模式如何使沃尔玛和亚马逊受益。
MICROSERVICE架构在真实行动中的行动
在这里,我们探讨如何采用微服务作为软件架构可以增加真正的商业价值,并为亚马逊和沃尔玛带来一系列的好处。
MICROSERVICES拯救了沃尔玛的老化软件架构
零售业巨头沃尔玛的加拿大分支机构在其现有的软件架构方面存在严重问题,特别是在黑色星期五 - 连续两年。在高峰期,沃尔玛网站每分钟无法处理600万次页面浏览量,最终使访问者几乎无法获得任何积极的用户体验。
部分问题在于沃尔玛的软件架构是针对2005年的互联网设计的,该架构以台式机和笔记本电脑为中心。移动,智能和物联网设备的使用尚未完全达到顶峰。该公司决定在2012年使用微服务重新平台其遗留系统,并设定了到2020年能够为40亿个连接提供服务的目标!
通过迁移到微服务架构,沃尔玛确定:
- 移动订单增加了98% -
- 黑色星期五和节礼日的零停机时间(加拿大黑色星期五)
- 转化次数增加20%
AMAZON
亚马逊零售和现在的物流巨头对大规模交付软件并不陌生。高级AWS产品经理Rob Birgham分享了一个关于微服务架构如何与DevOps结合使用的故事。
早在2000年初,Amazons网站就被开发为一个巨大的单块解决方案,公平地说,很多业务都是以这种方式开始的。然而,随着时间的推移,随着功能区域的建立,来自多个开发团队或错误的修复,更不用说随着平台的发展,整合所有这些工作的工作开始影响整体生产力。
几天或有时整整一周致力于将开发人员更改合并到产品的主版本中,必须再次解决合并冲突,这些都会对生产力产生影响。
很快意识到这样的操作是不可持续的,亚马逊决定通过采用微服务架构来解决他们的整体代码库。每个服务都由一个目的负责,因为可以通过Web服务API访问。
一旦完成此练习,这为亚马逊创建高度解耦的架构铺平了道路,每个服务都可以独立运行 - 为每个开发人员提供相应的Web服务接口定义。
微软架构的挑战
与每个新的软件编程架构一样,每个都有优缺点列表,并不总是桃子和奶油和微服务不是这个规则的例外,值得指出其中的一些。
- 太多的编码语言 - 是的,我们将此列为一项好处,但它也可能是一把双刃剑。最终,太多的替代语言可能会使您的解决方案变得笨拙并且可能难以维护。
- 集成 - 您需要有意识地努力确保您的服务尽可能松散地耦合,否则,如果您不这样做,您将对一项服务进行更改,这会对其他服务产生连锁反应,从而使服务集成困难且耗时。
- 集成测试 - 测试一个单片系统可以更简单,因为一切都在“一个解决方案”中,而基于微服务架构的解决方案可能具有生活在其他系统和/或环境上的组件,从而使配置更加困难并且“端到端”测试环境。
- 通信 - 微服务自然需要与其他服务交互,每个服务将依赖于一组特定的输入并返回特定的输出,这些通信通道需要被定义到特定的接口并与您的团队共享。当没有遵守接口定义时,可能会发生微服务之间的故障,从而导致时间浪费。
现在我们已经讨论了微服务架构是什么,它的一些优点是什么,看看现实世界中微服务架构的一些例子以及这种范例的好处,你可能想知道微服务架构是否是对于您或您的软件项目而言,这是一个有效的问题。
您应该采用MICROSERVICE架构吗?

您不希望在项目中实现微服务架构只是为了它,所以我们总结了一些要考虑的点,这将有助于您确定该架构模式是否适合您或您的项目。
如果对这些问题中的任何一个回答“是”,那么您可能需要考虑实施微服务基础架构:
- 您当前的应用程序是否很难维护?
- 您是否预计您的应用程序将需要处理大量流量?
- 模块化和代码可重用性是主要优先事项吗?
- 您的应用程序是否需要在多种设备类型上访问,例如移动设备,物联网和网络?
- 您的应用程序需要能够扩展需求的特定区域吗?
- 您是否希望改进软件产品构建和发布流程?
但是,如果对大多数问题的回答是肯定的,那么您可以使用传统的单片应用程序架构:
- 只需要发货和MVP,来测试市场吗?
- 在您退休之前,是否已有一个稳定的产品/团队继续使用该产品?
- 您的产品“在野外”,产生收入和用户社区是否满意?如果是这样,重新发明轮子没有任何意义
参考微软架构
现在我们已经介绍了微服务架构,讨论了一些好处,各自的挑战,并看了一些微服务如何在现实世界中部署的例子,现在是时候从架构和如何看待基本的微服务了它可以设计。在下图中,您可以使用以下3个微服务:
- 帐户服务
- 库存服务
- 送货服务
在这个虚构的应用程序中,每种微服务都以两种方式之一访问:
- 从API网关(通过移动应用程序)
- 从Web应用程序(通过用户的Web浏览器)
注意:理论上可能更多,因为架构适合于此。
您可以看到每个微服务还公开了一个专用的REST API,这是定义可以针对相应微服务执行的操作的接口,并将详细说明可以传递到微服务的数据结构,数据类型或POCOS。作为其返回类型。例如,Inventory服务REST API定义可能包含一个名为GetAllProducts的端点,它允许微服务的消费者获取电子商务商店中的所有产品,这可以返回Product对象的列表,即JSON,XML甚至C#POCO。
由于每个微服务都有自己的职责,并且只能与其各自的数据库进行交互,因此这样构建的解决方案使不止一个开发人员更容易对系统进行更改。通过实施像我们刚刚详细介绍的微服务,您将获得我们之前概述的一些好处。当您使用这种方法推出架构时,确保每个微服务可以完全独立运行非常重要,否则,它会违背追求这种架构方法的目的。
摘要
那么,你有它,一个概述微服务架构。在这篇博文中,我们研究了微服务架构,我们介绍了关键概念,这种架构设计模式可以为企业带来的好处,以及它如何帮助软件开发专业人员更好地构建他们的产品。
我们还概述了采用微服务架构模式的应用程序的主要组件,并为您提供了一些关于为什么要将微服务引入项目的想法。随意评论或与您的朋友或同事分享这篇文章,或者如果您有评论,请在下面留下一个!
原文:https://www.devteam.space/blog/microservice-architecture-examples-and-diagram/
- 59 次浏览
【微服务架构】微服务的数据管理注意事项
使用微服务有助于提高应用程序质量并简化部署。但在实施微服务解决方案之前,您需要考虑应用程序将处理的数据。必须谨慎管理这些数据,以确保您的应用程序的性能和安全性符合预期和策略。您应该回答几个问题,以了解如何处理微服务用例的数据管理。
- 您的用例是否需要存储它创建或修改的数据以用于将来,趋势或漂移分析;可审计性或合规性;还是可追溯性?
- 您的用例是否适用于持续流动的数据,例如社交媒体源或物联网传感器?
- 您的用例是否适用于来自多个来源的数据,或者需要清理或修改数据以使用它?您的用例是否需要零停机时间?
- 您的用例是否适用于被视为敏感或私密的数据,例如个人身份信息(PII),或受法规控制的数据(如HIPAA或GDPR)?
- 您的用例是否依赖于高度可信的数据,其可以追溯其谱系被认为是成功的,还是专注于提高数据质量和可追溯性?
7数据管理考虑因素
虽然在许多微服务式解决方案中,各个服务大多数都是无状态的,但我们已经确定了七个数据管理接触点,或微服务解决方案中数据管理的注意事项。如果您正在构建微服务解决方案,则可以通过解决这些注意事项来帮助确保有效地管理数据。
- 任何服务都必须根据对该类数据的要求(包括法规,安全性或业务流程)访问或保存数据库或数据高速缓存中的数据。微服务解决方案通常利用可通过定义的API提供这些要求的数据库服务。
- 转换数据的服务需要通过标准消息传递这些更改,以维护沿袭和治理,通常使用定义的API或消息队列。
- 遵守适用于数据的数据访问控制策略。通常,数据访问策略由数据存储库设置,具体取决于它们包含的数据的敏感性。这些服务使用适用于应用程序选区的角色。
- 数据移动和转换服务必须在获取和可用性之间的时间内考虑SLA的性能。这些服务还必须考虑要访问的数据的数量和位置,并相应地设置SLA期望。
- 如果服务需要高度可信的公共数据,请确定它们是否应使用企业指定的主数据源。
- 存储必须考虑要存储的数据量,接收的速度,使用方式以及选择适当数据存储库时的安全性和弹性要求。
- 监视和记录有关数据如何流动以及访问哪些数据的信息,以确保采取适当的安全措施。沟通数据沿袭和治理的转型。
原文:https://www.ibm.com/cloud/garage/architectures/microservices/data-management-for-microservices
讨论:加入知识星球【首席架构师圈】
- 84 次浏览
【微服务架构】微服务简介,第1部分
每个人都在谈论微服务。行业资深人士可能会记住单片或基于SOA的解决方案是做事的方式。时代变了。新工具使开发人员能够专注于特定问题,而不会给部署或通常与隔离服务相关的其他管理任务增加过多的复杂性。选择使用合适的工具来解决正确的问题变得越来越容易。
在本系列文章中,我们将探讨微服务的世界,它如何帮助解决现实问题,以及为什么行业越来越多地将其作为标准的做事方式。在本系列中,我们将尝试解决与此方法相关的常见问题,并提供方便简单的示例。在本系列的最后,我们应该有一个完整的基于微服务的架构的框架实现。今天,我们将关注微服务以及它们与替代方案的比较。我们还将列出我们计划在以下帖子中讨论的问题。
更新:在第2部分中,我们讨论了API网关。
什么是微服务?
微服务是一个孤立的,松散耦合的开发单元,可以解决一个问题。这类似于旧的“Unix”做事方式:做一件事,做得好。诸如如何“组合”服务提供的任何事项的事项留给更高层或政策。这通常意味着微服务往往避免相互依赖:如果一个微服务对其他微服务有一个硬性要求,那么你应该问自己是否有意义将它们全部放在同一个单元中。
"A microservice is an isolated, loosely-coupled unit of development that works on a single concern."
“微服务是一个孤立的,松散耦合的开发单元,可以解决一个问题。”
微服务对开发团队特别有吸引力的是他们的独立性。团队可以自己处理问题或一组问题。这创造了许多开发人员青睐的有吸引力的品质:
- 自由选择合适的工具:您一直想要使用的是新的库或开发平台吗?你可以(如果它是适合这项工作的工具)。
- 快速迭代:第一个版本不是最理想的吗?没问题,版本2可以立即出门。由于微服务往往很小,因此可以相对快速地实现更改。
- 重写是一种可能性:与单片解决方案相比,由于微服务很小,重写是可能的。技术堆栈是错误的选择吗?没问题,切换到正确的选择。
- 代码质量和可读性:隔离开发单元的质量往往更高,新开发人员可以非常轻松地使用现有代码。
生产质量的微服务
现在我们知道微服务是什么,这里列出了在设计基于微服务的架构时需要记住的事项。如果这看起来太抽象,不要担心;我们将在整个系列文章中系统地处理所有这些问题。
必须以这样的方式实施跨领域关注,即微服务不需要处理有关其特定范围之外的问题的细节。例如,身份验证可以作为任何API网关或代理的一部分来实现。
数据共享很难。微服务倾向于支持可以直接更新的每服务或每组数据库。在为您的应用程序进行数据建模时,请注意这种处理方式是否适合您的应用程序。为了在数据库之间共享数据,可能需要实现处理数据库之间的内部更新和事务的内部过程。可以在许多微服务之间共享单个数据库;请记住,如果您需要在将来进行扩展,这可能会限制您的选择。
可用性:由于隔离和独立,需要对微服务进行监控,以尽早检测故障。在一个大型软件堆栈中,一个服务器可能会被忽视一段时间。在选择用于管理服务的软件堆栈时考虑到这一点。
进化:微服务往往快速发展。当专门团队处理特定问题时,可以快速找到新的更好的解决方案。因此,有必要考虑服务的版本控制。只要有客户需要使用旧版本,旧版本通常可用。较新版本以特定于应用程序的方式公开。例如,使用HTTP / REST API,微服务的版本可以是自定义标头的一部分,或嵌入在返回的数据中。说明这一点。
自动部署:现在微服务如此方便的全部原因是,从完全干净的环境部署新服务非常容易。请参阅Heroku,Amazon Web Services,Webtask.io或其他PaaS提供商。如果您要采用自己的内部方法,请记住,部署新服务或预先存在的服务版本的复杂性对于解决方案的成功至关重要。如果不以方便,自动的方式处理部署,您最终可能会达到一定程度的复杂性,这超出了该方法最初带来的好处。
相互依赖性:将它们保持在最低限度。处理服务之间的依赖关系有不同的方法。我们将在稍后的博客文章系列中进一步探讨它们。现在,请记住,依赖性是这种方法的最大问题之一,因此寻求将它们保持在最低限度的方法。
传输和数据格式:微服务适用于任何传输和数据格式;但是,它们通常通过HTTP上的RESTful API公开公开。任何适合您的信息的数据格式。 HTTP + JSON现在非常流行,但是没有什么可以阻止你使用协议缓冲区而不是AMQP。
把事情做正确
所有这些问题都可以系统地处理。我们将探索本系列文章中的技巧和模式来处理它们。以下是我们将来在帖子中讨论的内容:
- API代理
- 记录
- 服务发现和注册
- 服务依赖性
- 数据共享和同步
- 优雅的失败
- 自动部署和实例化
保持真实:样品微服务
现在,这应该很容易。如果微服务从开发团队的脑海中掏出这么多的包袱,写一个应该是小菜一碟,对吧?是的,在某种程度上。虽然我们可以编写一个简单的RESTful HTTP服务并将其称为微服务,但在本文中我们将通过考虑上面列出的一些事情来做到这一点(不要担心:在以下帖子中,我们将扩展此示例包括上面列出的所有问题的解决方案。
对于我们的示例,我们将从Sandrino Di Mattia的关于使用Flux进行调试的优秀帖子中选择后端代码。在Sandrino的帖子中,一个简单的express.js应用程序为React.js应用程序制作了后端。我们将采用后端并对其进行调整。您可以在此处查看原始后端代码。
Sandrino示例中的后端处理许多不同的问题:登录,身份验证,CORS,票证更新操作和查询。对于我们的微服务,我们将专注于一项任务:查询门票。看看这个:
var express = require('express');
var morgan = require('morgan');
var http = require('http');
var mongo = require('mongodb').MongoClient;
var winston = require('winston');
// Logging
winston.emitErrs = true;
var logger = new winston.Logger({
transports: [
new winston.transports.Console({
timestamp: true,
level: 'debug',
handleExceptions: true,
json: false,
colorize: true
})
],
exitOnError: false
});
logger.stream = {
write: function(message, encoding){
logger.debug(message.replace(/
$/, ''));
}
};
// Express and middlewares
var app = express();
app.use(
//Log requests
morgan(':method :url :status :response-time ms - :res[content-length]', {
stream: logger.stream
})
);
var db;
if(process.env.MONGO_URL) {
mongo.connect(process.env.MONGO_URL, null, function(err, db_) {
if(err) {
logger.error(err);
} else {
db = db_;
}
});
}
app.use(function(req, res, next) {
if(!db) {
//Database not connected
mongo.connect(process.env.MONGO_URL, null, function(err, db_) {
if(err) {
logger.error(err);
res.sendStatus(500);
} else {
db = db_;
next();
}
});
} else {
next();
}
});
// Actual query
app.get('/tickets', function(req, res, next) {
var collection = db.collection('tickets');
collection.find().toArray(function(err, result) {
if(err) {
logger.error(err);
res.sendStatus(500);
return;
}
res.json(result);
});
});
// Standalone server setup
var port = process.env.PORT || 3001;
http.createServer(app).listen(port, function (err) {
if (err) {
logger.error(err);
} else {
logger.info('Listening on http://localhost:' + port);
}
});
- 只有一件事:我们的微服务的唯一问题是查询完整的门票清单。而已。身份验证,CORS和其他问题将由我们架构中的上层处理。
- 记录:我们使用'winston'库保持记录。现在我们只需登录到控制台,但在以后的版本中,我们会将预定义格式的日志推送到集中位置进行分析。
- 没有依赖:我们的微服务与其他微服务没有依赖关系。
- 轻松扩展:没有依赖关系,单独的流程,只需一个操作,我们的微服务就可以轻松扩展。
- 小巧可读:我们的微服务小巧可读。新开发人员可以立即修改或重写它。
- 数据共享:现在我们的微服务从自己的数据库中读取数据。我们将在以后的帖子中探讨当其他微服务需要更新或创建票证时会发生什么。
- 注册和失败:我们的微服务独立存在。在以后的文章中,我们将探讨如何管理服务发现以及在微服务失败的情况下您可以做些什么。
获取https://github.com/sebadoom/auth0/blob/master/microservices/microservice-1-webtask/server.js。
旁白:对微服务感兴趣?你会喜欢webtasks!
微服务是Auth0堆栈的重要组成部分,我们提出了一种使它更容易使用的好方法。查看webtask.io。
- 轻量且简单的开发工作流程。
- 简化部署。
- 强大的安全模型,方便HTML5和移动应用程序。
- 适用于HTML和数据API的Web友好编程模型。
我们已将上面的示例转换为webtask,看看它有多简单:
npm install wt-cli -g
# This will send an activation link to your email. One time only.
wt init your.name@email.com
# This will return a new endpoint for your webtask
wt create https://raw.githubusercontent.com/sebadoom/auth0/master/microservices/m…
# Use the endpoint here (we have setup a sample DB for this example)
curl https://webtask.it.auth0.com/api/run/wt-sebastian_peyrott-auth0_com-0/0… -v
看代码。 将它与我们之前的版本进行比较,看看我们有多少变化。
结论
微服务是进行分布式计算的新方法。 部署和监控工具的进步缓解了管理许多独立服务所带来的痛苦。 好处很明显:使用正确的工具来解决正确的问题,并让团队使用他们的专有技术来解决每个问题。 困难的部分是处理共享数据。 在处理共享数据和服务间依赖关系时,必须考虑特殊注意事项。 数据建模是任何设计中必不可少的步骤,在基于微服务的架构中更是如此。 我们将在以下文章中详细探讨其他常见模式和实践。
- 16 次浏览
【微服务架构】微服务设计模式
这是微服务架构系列文章的第 3 篇
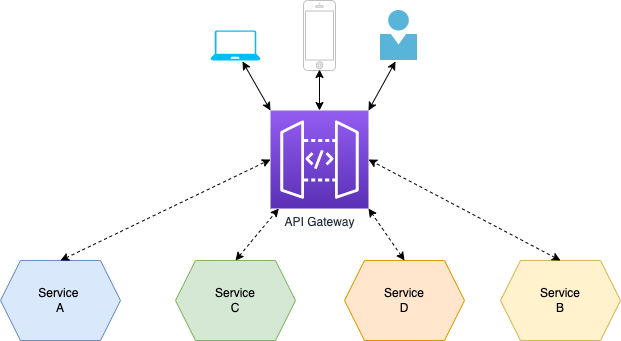
高可用性、可扩展性、故障恢复能力和性能是微服务的特征。 您可以使用微服务架构模式来构建微服务应用程序,从而降低微服务失败的风险。
模式分为三层:
应用模式
应用程序模式解决了开发人员面临的问题,例如数据分解、数据维护、测试、用户界面和一些可观察性模式。

让我们回顾一下这些应用程序模式的基础知识。
分解模式
选择如何将单体系统分解为服务
- 按业务能力分解——服务是围绕业务能力组织的。
- 按子域分解——服务是围绕域驱动设计的子域组织的。
数据模式
- 数据一致性——每个服务使用一个单独的数据库以确保松散耦合。为了跨服务的数据一致性,必须使用 Saga 模式。
- 查询——每个服务使用数据库的另一个问题是某些查询需要连接来自多个服务的数据。不可能对服务的数据库执行分布式查询,因为它的数据只能通过其 API 访问。必须使用其中一种查询模式来检索分散在多个服务中的数据。
- API 组合——对一项或多项服务进行 API 调用并汇总结果。
- 命令查询职责分离 (CQRS) — 数据保存在一个或多个可以轻松查询的副本中。
测试模式
单个微服务更容易测试,因为它们比单体应用程序小得多。在测试不同服务是否协同工作时,重要的是要避免使用同时检查多个服务的复杂、缓慢和不稳定的端到端测试。
- 消费者驱动的合同测试——确保服务满足客户的期望。
- 消费者端合约测试——确保服务的客户端可以与之通信。
- 服务组件测试——隔离服务并对其进行测试。
用户界面模式
显示与不同服务相对应的数据及其显示方式是不同团队的责任。
- 服务器端页面片段组合——每个团队开发一个 Web 应用程序,为他们的服务实现的页面区域生成 HTML 片段。 UI 团队通过在服务器端聚合特定于服务的 HTML 片段来开发页面模板。
- 客户端 UI 组合——每个团队创建一个客户端 UI 组件,为他们的服务实现屏幕区域,例如 AngularJS 指令。通过组合多个特定于服务的 UI 组件,UI 团队实现页面骨架来构建屏幕。
可观察性模式
为了有效地运行应用程序,了解其运行时行为并解决请求失败等问题非常重要。
- 审计日志——审计日志记录每个用户的操作。审计活动日志通常用于协助客户支持、确保合规性和检测可疑活动。
- 应用程序指标——监控和警报是生产环境的关键组成部分。有一系列指标,例如 CPU、内存和磁盘的利用率,到服务请求的延迟和执行的请求数。指标由提供警报和可视化的指标服务收集。
应用基础架构模式
它们适用于也会影响开发的基础设施问题,例如通信、可观察性、可靠性和安全模式。

横切关注点模式
我们必须先了解关注点,才能理解横切关注点。关注点是基于其功能的系统的一部分。有两种担忧:
- 核心关注点——它代表主要需求的单一和特定功能,例如业务逻辑。
- 横切关注点——与次要需求相关的关注点。横切关注点是适用于整个应用程序的关注点,例如安全性和日志记录。
- 外部化配置——在运行时,它向服务提供配置属性值,例如数据库凭据和网络位置。
- 微服务底盘——微服务底盘是处理一系列问题的一个或一组框架,例如外部化配置、健康检查、应用程序指标、服务发现、断路器和分布式跟踪。您可以使用微服务机箱更有效地开发服务的业务逻辑。
- 服务模板——开发人员可以通过复制源代码模板快速开始开发新服务。顾名思义,模板是一个简单的可运行服务,它实现了构建逻辑和横切关注点以及示例应用程序逻辑。
通讯模式
基于微服务的应用程序是分布式系统。微服务架构严重依赖进程间通信(IPC)。
- 远程过程调用 (RPI) — 使用请求/回复协议发出服务请求。
- 特定于域的协议 - 对于服务间通信,例如使用 SMTP/IMAP 的电子邮件,或使用 RTMP/HLS/HDS 的媒体流,请使用特定于域的协议。
- 消息传递——使用异步消息传递进行服务间通信,例如 AMQP
可观察性模式
可观察性模式提供了对应用程序行为方式的洞察。诊断微服务架构的问题要困难得多。在最终将响应返回给客户端之前,请求可以在多个服务之间反弹。
- 日志聚合——将服务活动日志写入可以执行搜索和警报的集中式日志服务器。
- 异常跟踪——应将异常报告给异常跟踪服务,该服务对异常进行重复数据删除、警告开发人员并跟踪其解决方案。
- 健康检查 API — 提供一个返回服务健康状况的端点。
- 分布式跟踪——为每个外部请求提供一个 ID,并在请求在服务之间流动时对其进行跟踪。
可靠性模式
当服务不可用时,如何保证它们之间的可靠通信?
- 断路器——断路器可用于保护跨服务调用。当一定数量的下游资源请求未能达到一定阈值时,断路器会打开。如果断路器打开,系统将很快出现故障。一段时间后,客户端会发送一些请求来检查下游服务是否已经恢复。如果有正常响应,将在健康恢复后再次发送请求。
安全模式
用户通常由微服务架构中的 API 网关进行身份验证。然后必须将用户的身份和角色传递给它调用的服务。一个常见的解决方案是使用访问令牌模式。 API 网关将访问令牌(例如 JWT(JSON Web 令牌))传递给服务,服务可以验证令牌并获取有关用户的信息。
基础架构模式
它们解决了与开发之外的基础设施有关的问题,例如部署、发现和与外部 API 的通信模式。
部署模式
部署微服务有几种模式。传统上,服务以特定语言的方式打包。有两种现代部署方法。
- 虚拟机或容器——虚拟机或容器可用于部署服务。
- 无服务器部署——无服务器平台在您上传服务代码后执行它。自动化的自助服务平台是部署和管理服务的最佳方式。
发现模式
通常,服务需要相互通信。单体应用程序使用语言级方法或过程调用来调用其服务。传统上,分布式系统在固定的、众所周知的位置(主机和端口)运行,因此可以通过 HTTP/REST 或其他一些机制访问服务。然而,大多数基于微服务的现代应用程序都在虚拟化或容器化环境中运行,其中服务实例的数量及其位置会动态变化。
- 自注册——服务向服务注册中心注册自己
- 客户端发现——服务客户端从服务注册表中检索服务实例,然后在它们之间进行负载平衡。
- 3rd Party Registration — 第三方自动向服务注册中心注册服务实例。
- 服务器端发现——服务发现由路由器完成,路由器接收来自客户端的请求。
外部 API 模式
微服务提供的 API 粒度通常与客户端所需的不同。微服务提供的 API 通常是细粒度的,因此客户端必须与多个服务交互。每个客户端需要不同数量的数据,网络性能对每个客户端的影响也不同。
- API Gateway — API Gateway 实现了一项服务,该服务是从外部 API 客户端进入基于微服务的应用程序的入口点。它执行请求路由、API 组合和其他功能,例如身份验证、速率限制、缓存等。
- 前端的后端(BFF)——为每种类型的客户端创建一个单独的 API 网关。每个移动、浏览器和公共 API 团队都将拥有自己的网关,而 API 网关团队拥有公共层。
在以后的文章中,我们将详细介绍每种模式。
原文:https://medium.com/@learncsdesign/microservices-design-patterns-91fe56a…
- 46 次浏览
【微服务架构】用JHipster做微服务
微服务与单片架构
JHipster会问你的第一个问题是你想要生成的那种应用程序。您可以选择两种架构样式:
- “单片”架构使用单个,一刀切的s应用程序,其中包含前端Angular代码和后端Spring Boot代码。
- “微服务”架构将前端和后端分开,这样您的应用程序就可以更轻松地扩展并承受基础架构问题。
“单片”应用程序更容易处理,因此如果您没有任何特定要求,我们建议使用此选项,以及我们的默认选项。
微服务架构概述
JHipster微服务架构以下列方式工作:
- 网关是JHipster生成的应用程序(在生成应用程序时使用应用程序类型微服务网关)处理Web流量,并为Angular应用程序提供服务。如果您想遵循后端前端模式(Backends for Frontends pattern),可以有几个不同的网关,但这不是强制性的。
- Traefik是一个现代HTTP反向代理和负载均衡器,可以与网关一起使用。
- JHipster Registry是一个运行时应用程序,所有应用程序都可以在其上注册并获取其配置。它还提供运行时监控仪表板。
- Consul是一种服务发现服务,以及一个键/值存储。它可以用作JHipster注册表的替代品。
- JHipster UAA是一个基于JHipster的用户身份验证和授权系统,它使用OAuth2协议。
- 微服务是JHipster生成的应用程序(在生成它们时使用应用程序类型微服务应用程序),它们处理REST请求。它们是无状态的,并且它们的几个实例可以并行启动以处理重载。
- JHipster控制台是一个基于ELK堆栈的监视和警报控制台。
在下图中,绿色组件特定于您的应用程序,蓝色组件提供其底层基础结构。
原文:https://www.jhipster.tech/microservices-architecture/
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 21 次浏览
【微服务架构】编曲与编舞——让系统协同工作的不同模式
介绍
Krzysztof(采访者):商业组织是由专家组成的,他们在他们最了解的领域提供产品或服务,以获得共同的商业成果。例如,营销团队努力争取新客户,销售团队向这些客户销售产品,客户关系团队负责积极的客户体验和保留。只有当这些团队一起工作时,才能实现共同的业务目标和利润。如何组合和安排他们的服务以实施业务流程管理的问题是定义整个组织如何运作的关键部分。今天我们将讨论这样做的最佳方法。我们有编排模式和编排模式——我们在辩论中的演讲者。你能介绍一下自己吗?
编曲模式:感谢您组织本次辩论。我是Orchestration Pattern,我相信只有一个集中且组织良好的组件才能为业务流程管理提供稳定性和跟踪。这就像一场管弦乐队音乐会——我们有一位指挥向每组音乐家展示何时发挥他们的作用。没有他,音乐家将演奏混乱而不是交响乐。同样的事情也适用于 IT 系统——如果我们在系统通信中使用 Orchestrator,我们将能够管理我们的流程并轻松验证其状态。

编舞模式:我很高兴被邀请参加这个演讲。 谢谢你有我。 我是编排模式,我对系统通信规则的观点与编排模式相反。 我认为,在我们的 IT 生态系统中间添加一个额外的决策组件是多余的。 更重要的是,我认为组件应该是自主的并且耦合松散,以提供业务价值本身,而不会影响其他组件。 这就像一支爵士乐队,当音乐家正在等待其他人停止演奏,并继续他们与另一支球队介绍的旋律相关的自由泳时。 使用这种方法,我们可以少维护一个组件,并且我们没有一个难以管理的大单点。

第 1 轮:IT 系统设计
Krzysztof(采访者):感谢您的快速介绍。 现在,我们将开始第一轮,我们将首先从技术角度讨论您的想法。 这里的问题是——你不只是同步和异步通信的不同名称吗?
编曲模式:不! 我可以实现这两种通信模式。 这就是我的 Orchestrator 组件如此重要的原因。 让我详细说明一下您在开始时介绍的示例。 当营销团队获得新客户时,客户关系和销售团队应该意识到这一点并更新客户信息——以便当销售人员想要致电客户时,他们可以立即获得有关他们的信息,发生的所有通信以及所有 客户进行的购买。 以下是我将如何实现这两个功能。
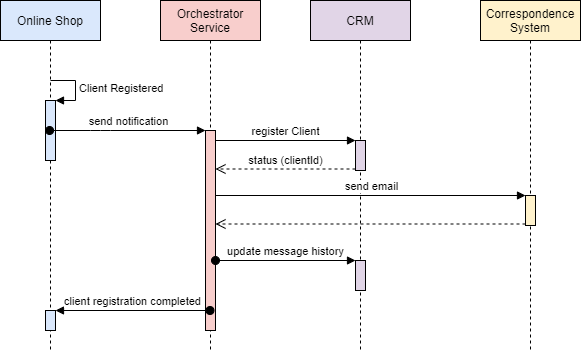
- Async Client Synchronization with Orchestration Pattern
- 使用编曲模式同步客户端详细信息响应
编舞模式:在名称方面我同意编排模式——我也可以实现同步和异步通信。 我只是不同意 Orchestrator 组件至关重要。 让我重新设计一个编排模式的想法,因为我仍然可以提供相同的业务功能,而中间没有一个全能的元素。
- Async Client Synchronization with Choreography Pattern
- 将客户端详细信息响应与编排模式同步
正如你所看到的,我可以做同样的业务逻辑,但使用更少的业务逻辑组件,更灵活的设计。
编曲模式:您的设计看起来非常复杂! 而且,我可以在中间看到一个元素——这个事件系统。 所以,我不能同意业务逻辑组件更少。 不只是 Orchestrator 而是另一个名字? 而且,老实说,我在这里看不到这种灵活性……
编舞模式:首先,您错过了这样一个事实,即如果您在 Orchestrator 中进行错误处理,您的设计看起来会非常复杂。 如果 CRM 系统在客户端同步中没有响应,您将如何反应? 您需要围绕通知在线商店有关情况来实现重复和业务逻辑。 让我用这个缺失的部分重新表述你的设计。
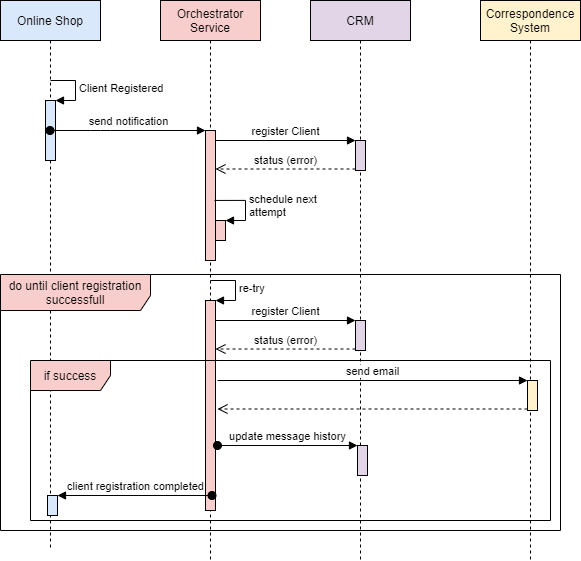
- Orchestrator 需要处理错误和系统不可用。使用 Choreography,组件只需等待适当的事件
同时,我的组件只是等待一个适当的事件——不需要在那里进行任何更改,也不会因为一个系统的不可访问性而由第三方处理错误。这样一来,您的设计看起来并不那么简单,因为您需要处理所有“假设”。
其次——我的事件系统不是业务逻辑组件。这是系统发布有关其处理的事件的空间。不包含任何业务逻辑——它就像一个论坛,每个人都分享他们所做的事情。这给了我刚才所说的灵活性——如果我不希望在客户注册过程中由通信系统发送电子邮件,我只需禁用此通信系统中的侦听器。对于其他组件,这种变化是不可见的。在您的设计中,您需要在 Orchestrator 中进行业务逻辑更改。
编曲模式:只要过程没有因错误或意外行为而中断,这一切听起来都很好。那会发生什么?如果您的元素之一失败,或者根本没有发布适当的事件,整个业务流程就会挂起。而且我们没有地方可以触发这样一个过程的结束。
编舞模式:这就是我们需要监控和跟踪工具的目的。那些轻量级的技术应用程序应该对未使用的事件或没有结束事件的卡住进程发出警报。我们可以通过这些工具自动生成最终事件,或者让人类决定做什么,就像编排模式一样,但不是在一个大而全能的元素中。然而,你说得有道理——与我一起计划和管理比与 Orchestration 更难。
第 2 轮:变更管理
Krzysztof(采访者):感谢您在第一轮中进行的激动人心的讨论。您已经提到了我们现在要讨论的一个主题——变革管理。在这一轮中,我们将着眼于改变和影响您提出的解决方案的变化的灵活性。那么,您可以用您的方法以多快的速度交付新功能和流程?改变现有的会有多困难?最后,如果您在一个组件中引入更改,那么其他组件会发生什么?
编舞模式:编排模式指责我架构的每次更改都需要对多个组件进行大量调整。这并不完全正确。是的,我同意更改流程本身需要更改负责该流程的协调器组件。但这样的变化并不总是会产生巨大的影响。将 ESB 作为集成平台,我们减少了 Orchestrator 中数据映射部分的更改次数。最重要的是,将 BPM 引擎用作协调器,简化了业务流程本身的变更交付。如果我们在一个组件中更改数据的结构,我们将需要在组件中使用类似的结构来使用数据。我怀疑我们可以通过编排模式避免这种情况,所以在变更管理的情况下,我相信我们已经接近了。
- 使用 Orchestration,很多变化都需要在 Orchestrator Element 中进行一些调整
编舞模式:我强烈不同意我们很接近。为了证明这一点,我想参考我们概念的基础知识。管弦乐就像一场管弦音乐会。如果我们想改变小提琴部分,我们需要每次都为小提琴手写一个新的旋律,有时要求指挥家进行一点不同的指挥。正如我所提到的,我更像是一支爵士乐队——如果我的一位音乐家想要扮演不同的角色,我就允许他这样做。当然,他可以完全改变旋律,其他音乐家也会想对它做出反应——但我只是让他们自己决定。在最坏的情况下,即不同步的变化,他们将完全停止播放,等待老旋律出现。对于管弦乐队来说,最坏的情况是他们演奏的一团糟,会伤到你的耳朵。老实说,我更喜欢沉默……但是好吧,现在让我回到一些例子,参考第一轮的处理。我已经提供了第一个——如果我们想删除发送电子邮件,我们只需禁用通信系统。当然,稍后,我们可能还会删除事件 #3 的 CRM 侦听器,该侦听器负责同步通信历史记录——但不这样做不会导致任何错误。第二个例子是数据映射。在 Orchestration Pattern 中,Orchestrator 负责跟踪数据结构的变化。即使是数据结构的微小变化也需要在 Orchestrator 中进行调整。我的设计也不是没有这样的问题——但我希望我的事件是用仅描述业务对象基本属性的简单数据模型创建的。当然,Orchestrator Pattern 总是可以使用这样的模型,但是在我的设计中,我们还有一个组件需要改变——Orchestrator Element。
- 使用 Choreography,多于两个组件的更改数量更小
第三轮:业务流程跟踪和数据管理
Krzysztof(采访者):现在,让我们进入第三轮,我们将讨论数据管理和跟踪流程执行。正如 Sam Newman 在构建微服务中所说:“随着我们开始对越来越复杂的逻辑进行建模,我们必须处理管理跨越单个服务边界的业务流程的问题”。这里有几个问题——您如何看待多个组件之间的共享和维护数据?您有什么计划来验证流程实例的状态?
编曲模式:就我的设计而言,这个主题非常简单。让我从数据管理开始。所有信息都被分类并存储在我的组件中,没有任何不必要的重复。如果一个组件需要更多数据,它只需询问 Orchestrator——它会收集并提供所需的数据,并带有适当的数据映射(例如,由 ESB 平台处理)。现在我的最大优势出现了——跟踪流程直接整合到我的 Orchestrator 中。一个端到端的过程发生并由这个元素管理。只需访问一个组件,您就可以准确地知道自己目前处于流程中的哪个位置。我怀疑 Choreography Pattern 的想法和我的一样简单。
- Orchestration Pattern 中的 Process Tracing 集中在 Orchestrator 组件中
编舞模式:这个话题也可以用我的设计来解决。我也会从数据管理开始。对我来说,数据正在组织中与事件和相关标识符(由业务流程发起者生成)共享。可以在组件中复制数据以供进一步使用,并根据组件业务功能调整模型。再看一下 Synch Client Details Response with Choreography Pattern 序列图。在我的设计中,不需要调用第三方来获取数据,因为它正在组件之间同步,以防业务处理需要。下一个主题是跟踪——在这里我同意它对我来说可能比使用 Orchestrator 更复杂。但是,有了流程发起者生成的相关标识符,我们仍然可以轻松地连接组成更大业务流程的子流程。
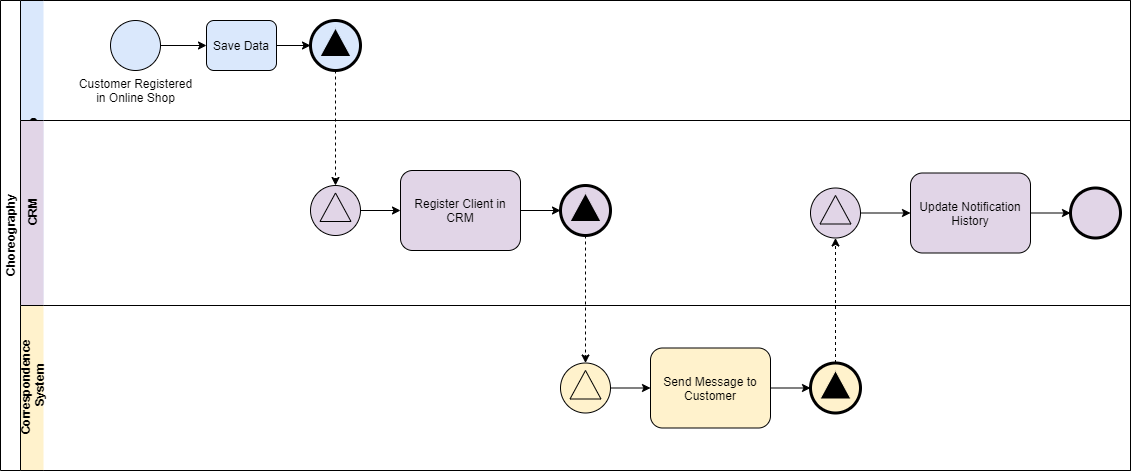
- Choreography Pattern 中的流程更加分散,因此跟踪可能是一个挑战
编曲模式:所以,看起来我是对的,而且跟踪过程对我来说更容易。编排需要有额外的专用工具来实现这一目的——我也可以使用我的 Orchestrator 来扮演那个角色。更重要的是,使用存储在我的 Orchestrator 中的数据,我可以轻松地做出报告和关键决策。 Choreography 提出的这种分布式逻辑可能是一个真正的挑战。
编舞模式:我同意——这很有挑战性。但是如果没有集中式决策引擎,我们可以使用更轻量级的工具进行跟踪,而不是使用 Orchestrator 来完成所有工作。报告也是如此——我可以拥有一个专门为此而设计的系统或微服务。这种方法广泛用于微服务生态系统。我只是喜欢我的架构组件是自主的和独立工作的,提供特定的、定义明确的业务功能——而不是一个复杂的 Orchestrator,很容易成为组织的中央 IT 系统。
第 4 轮:组织影响
Krzysztof(采访者):哇,我们在第三轮进行了非常激动人心的讨论。在他们的最后一句话中,Choreography 提到了组织的影响。现在,让我们讨论一个高层次的观点。当组织选择你作为一种广泛使用的模式时,你认为组织会如何改变?您是否认为 IT 系统设计会影响公司的运作方式?或者可能是其他情况——公司结构反映在 IT 生态系统中?
编舞模式:这实际上是一个非常有趣的问题。这位首席执行官兼编舞师会对他的董事们说:“我的愿景是成为欧洲最大的卫生口罩生产商。我现在全神贯注于你的想法”。然后,营销总监会想出一个新市场的活动,营销总监会立即开始计算他当前的销售水平,工厂总监会等待营销总监对销售的预测,这样他们就可以调整他们要购买的产品数量。需要创建。这种方法有两大优势。首先,这些董事对他们的想法和意见负全部责任。他们知道,公司的成长也是他们的功劳。第二个好处是CEO的工作量少了很多,他的责任负担也更小了。
编曲模式:确实,这是一个相关的问题。编排在组织中引入了严格的顺序,这是编排的一个关键弱点,该顺序可能没有明确定义。 CEO-Orchestrator 会对他的董事们说:“我的愿景是成为欧洲最大的卫生口罩生产商。为此,我希望营销总监为新市场创建活动,销售总监专注于当前的销售水平,以免不必要的财务问题困扰我们,工厂总监将产量翻倍”。这位 CEO 考虑周全,整个公司都知道他会带领他们走向成功。也许他的负担更大——但至少他知道组织是如何运作的。当然,在某种抽象层面上——因为他的主管考虑他们的任务,并在他们的单位中编排流程以实现低级流程。如果您问这是否对 IT 系统设计有任何影响,我会说“是的”。 Melving E. Conway 也有同样的观点,这就是他引入康威定律的证据:“任何设计系统(定义广泛)的组织都会产生一个其结构是组织通信结构副本的设计。”就我而言,Orchestrator 将反映组织中强大的管理地位和秩序。
编舞模式:编排不涉及组织中的任何顺序——它只是在多个自主团队之间划分。如果 CEO-Orchestrator 生病了怎么办?如果他错了怎么办?有了编排,我们不仅有更多的讨论空间,还有更多自主、负责任的团队分享他们的投入和改进。我同意编排模式,即 IT 系统设计反映了组织的通信结构。但我会更进一步——我相信在 IT 系统中实施编排模式将使小团队开始以同样的方式工作。然后,编排正在更大的组织单位中传播,最后——它会传到 CEO 身上。明智的人会注意到,他不再孤单地做决定,他可以委派更多的工作,并且他可以依靠团队对他们的业务职能完全负责。归根结底,他的工作会更少,操心的事情也会更少,他的员工也会对组织更有责任感。总结一下——我同意康威定律有效,但对我来说,它也可以反过来起作用。在这种情况下,微服务和编排将导致小型、敏捷、面向业务的团队。
编曲模式:有了我,这位 CEO 会立即知道他错了。通过简单的流程跟踪和监控结果,很容易在流程中发现错误。使用 Choreography Pattern,您可能知道某些事情运行不正常,但您将花费更多时间进行调试并寻找负责的单元。我可以同意的是,康威定律也适用于相反的情况——拥有一个或几个业务规则实施系统,我们很快就会提出一个类似的管理结构来制定关键的业务决策。
结论
Krzysztof(采访者):感谢您的参与、见解和分享的想法。我希望这场辩论会在接下来的几周、几个月和几年内非常有帮助,届时数十个组织将投票选出在他们的项目中使用的最佳模式。就个人而言,我会投票给编舞模式。我不认为编曲模式是一个糟糕的模式——但是使用编舞设计的解决方案更加灵活,与技术无关,并且可以量身定制以满足客户的要求。 Choreography Pattern 还帮助我们构建了 Starboost——微服务画布,它被证明是可靠的、可扩展的和可调整的,适用于真实案例的业务场景。我相信 Choreography 将使 IT 系统再次变得伟大,它在当前和即将到来的项目中拥有我的投票权。亲爱的读者,你呢?
原文:https://bluesoft.com/orchestration-vs-choreography-different-patterns-o…
- 136 次浏览
【微服务架构】让我们谈谈“拥有”他们的数据的微服务
前几天我和一位同事讨论了我的微服务将用来公开特定数据集的接口的设计。 数据由我的微服务保存在 Elastic Search 中,并根据最终用户将选择的过滤器以不同的形式由 UI 使用和呈现。 当我仅仅提出让 UI 后端直接从 Elastic Search 查询数据的亵渎想法时,经典的“微服务不应该暴露其底层数据存储”的论点被点燃了。

- Who owns the data??
暴露数据的服务
我会从头开始。 微服务可以以任何方式或使用他们希望的任何技术公开数据,具体取决于用例。
让我们想象一个简单的数据项并通过一些示例。
有问题的数据项将是这个表示消息的简单 JSON 对象:
{
id: 2321387
sender: “Joe”
message_content: “Hello World Message”
}
公开这些数据的最无争议的方式可能是:
- · REST API
- · GraphQL
这些是“纯”API,因为它们提供了接口和底层数据存储的完全解耦。 今天我可能会在 Couchbase 中保存数据,明天在 Redis 中,下周我会将其移动到 S3。 如果我改变实现,消费者不需要知道任何事情。
- Exposing Data via REST API — Not Controversial
那么消息队列中的消息呢? 像 Kafka 或 RabbitMQ 之类的东西? 软件工程社区仍将这些技术定义为公开数据的非争议方式。 在许多产品的架构中,微服务通过消息队列相互通信,对吗? 如果我想将我的实现从 Kafka 更改为 RabbitMQ 会发生什么,消费者是否也需要更改他们的实现? 他们当然会,但您可能会争辩说,完全改变产品中的整个消息传递技术确实不太可能。
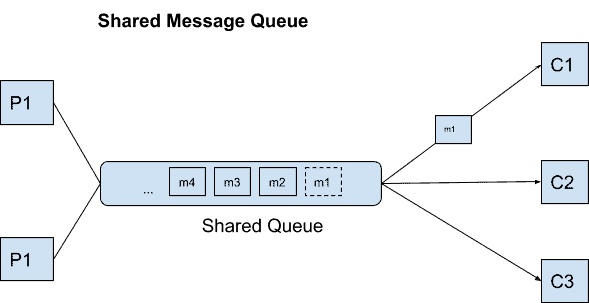
- Exposing Data via Message Queues — Not Controversial
现在让我们朝这个方向再走一步。 数据仓库和数据湖呢? 将您的数据保存在 S3 中并让消费者使用 Athena/Presto/BigQuery 在其上运行查询怎么样? 在这个用例中封装数据发生了什么? 令人惊讶的是,“接口-数据存储解耦”范式的纯粹主义者根本不认为这是一种不好的做法。
我试图争辩说,数据湖/仓库用例与通过 Elastic Search、Couchbase、Redis 或任何其他技术公开数据之间没有真正的区别。 数据的位置不是问题,因此解耦不是解决方案。 我们以错误的方式看待这个问题。
内部数据 VS 公开数据
真正的区别应该是您定义为服务的“内部”数据或状态,以及您定义为服务的“公开”数据。问题不在于您选择使用哪种技术存储数据。
内部数据是其位置和架构可以更改而不事先通知的数据。它完全在服务和拥有团队内部,任何消费者都不应该依赖它。一天它可以是内存中的 HashMap,另一天它可以是 DynamoDB 中的一个表,第三天开发人员可以决定将它存储在 S3 中,因为它太大而且太贵了。只要将这些数据定义为内部数据,我们就可以在任何时间点引入“破坏性更改”,因为它不会“破坏”任何消费者。
公开数据是您向消费者公开并提交给它及其模式的数据。无论您是通过定义良好的 REST API、定义良好的 Kafka 消息、S3 中定义良好的 ORC 文件还是 Couchbase 中定义良好的记录来公开它都没有关系。只要您和您的消费者同意这是公开的公共数据,您就不能在不通知消费者的情况下引入重大更改。您甚至可以想象一个使用 2 个 Couchbase 存储桶的服务——一个用于内部数据,一个用于公开数据。同样,技术并不重要,重要的是数据用途的定义。
重要的是要澄清,即使这些数据被公开和共享,消费者也只能从中读取。在这种模式下,拥有服务仍然是唯一对公开数据具有写访问权限的实体(显然对内部数据也是如此)。您可以将其视为微服务的一种 CQRS 实现。
为什么你甚至想通过 Couchbase 或 Athena 而不是严格地通过 REST 或 GraphQL 等 WEB API 来公开你的数据,你可能会问。
Amazon Athena 就是一个很好的例子,因为它通过多台服务器并行运行您的查询,因此您的数据消费者可以利用 Athena 的强大功能进行快速的大数据查询。有什么选择?您会在自己的服务中构建类似的功能并通过 Web API 公开它们吗?您将如何通过 Web API 公开丰富的 SQL 语言? GraphQL 能否涵盖 SQL 提供的所有选项? API 是否会是您将在内部传递给 Athena 并将结果分页给消费者的通用字符串?
相同的概念可以应用于 Couchbase、DynamoDB、Aurora 或任何其他数据存储。创建这些工具是为了扩大规模,旨在每秒接受和响应数十万个请求。如果一切都严格通过您的服务进行,则意味着您的开发人员将需要在他们自己的服务中重写这些技术的功能,或者只是在逻辑上降级数据存储的真正底层功能。
总结
您需要在内部和共享之间逻辑划分数据。后者是您与世界共享的数据,而内部数据是您的消费者不需要知道的完全封装的实现。一个数据集可以被认为是内部的并且驻留在 State Store 中,而相同数据的投影可以驻留在同一个 State Store 中并暴露在外部。这完全取决于您的用例,以及向消费者公开数据以优化使用数据的最佳方式是什么。
评论1
SQL server 是隔离的,可独立部署的,通过网络消息与其他服务通信,拥有自己的数据,是唯一可以写入磁盘来持久化它的,那么它怎么不是微服务呢?因为它的边界是由技术要求而不是业务要求决定的?因为太复杂了?因为是第三方?荒谬的。没有人真正根据约束的类型来定义技术概念。
从本质上讲,您的文章侵蚀了微服务的概念,而这正是困扰人们的地方。就是“如果我们允许这样做,它会在哪里停止?”思维。但答案很简单:它不会停止。定义微服务的方式取决于组织内部解决方案的架构师。他们可以准确地确定什么是微服务,什么不是。作为一般概念,对微服务的限制是没有用的。
我会更进一步:微服务纯度(与任何其他类型或对纯度的追求一样,但这已经太笼统了)是有毒的。接受现实中任何值得该死的系统都是技术的混合体,其中微服务只是其中的一部分,这要健康得多。
评论2:
我基本同意,我们应该专注于逻辑划分数据,而纯粹的微服务架构是弊大于利的。 虽然有些观点我认为你没有做对。
当您质疑数据库和仓库是用来回答数千个请求而 API 只能处理一个请求时,问题在于 API 的扩展方式。 瘫痪 API 工作负载可以解决数据库必须提供的资源使用不足的问题。
另一件事是,如果您期望进行临时查询,他们可能应该使用另一种连接数据的方式。 这是BI系统存在的主要原因。
也许我在挑剔,但这些是我对这个主题的想法。 我不愿意让其他人看到我的数据:p
原文:https://blog.devgenius.io/lets-talk-about-microservices-owning-their-da…
本文:
- 24 次浏览
【微服务架构】部署NGINX Plus作为API网关,第1部分 - NGINX
了解着名的Nginx服务器(微服务必不可少的东西)如何用作API网关。
现代应用程序体系结构的核心是HTTP API。 HTTP使应用程序能够快速构建并轻松维护。无论应用程序的规模如何,HTTP API都提供了一个通用接口,从单用途微服务到无所不包的整体。通过使用HTTP,支持超大规模Internet属性的Web应用程序交付的进步也可用于提供可靠和高性能的API交付。
有关API网关对微服务应用程序重要性的精彩介绍,请参阅我们博客上的构建微服务:使用API网关。
作为领先的高性能,轻量级反向代理和负载均衡器,NGINX Plus具有处理API流量所需的高级HTTP处理功能。这使得NGINX Plus成为构建API网关的理想平台。在这篇博文中,我们描述了许多常见的API网关用例,并展示了如何配置NGINX Plus以便以高效,可扩展且易于维护的方式处理它们。我们描述了一个完整的配置,它可以构成生产部署的基础。
注意:除非另有说明,否则本文中的所有信息均适用于NGINX Plus和NGINX开源。
介绍Warehouse API
API网关的主要功能是为多个API提供单一,一致的入口点,无论它们在后端如何实现或部署。并非所有API都是微服务应用程序。我们的API网关需要管理现有的API,单块和正在部分过渡到微服务的应用程序。
在这篇博文中,我们引用了一个假设的库存管理API,即“仓库API”。我们使用示例配置代码来说明不同的用例。 Warehouse API是一个RESTful API,它使用JSON请求并生成JSON响应。但是,当部署为API网关时,使用JSON不是NGINX Plus的限制或要求; NGINX Plus与API本身使用的架构风格和数据格式无关。
Warehouse API实现为离散微服务的集合,并作为单个API发布。库存和定价资源作为单独的服务实施,并部署到不同的后端。所以API的路径结构是:
api └── warehouse├── inventory└── pricing
例如,要查询当前仓库库存,客户端应用程序会向/ api / warehouse / inventory发出HTTP GET请求。
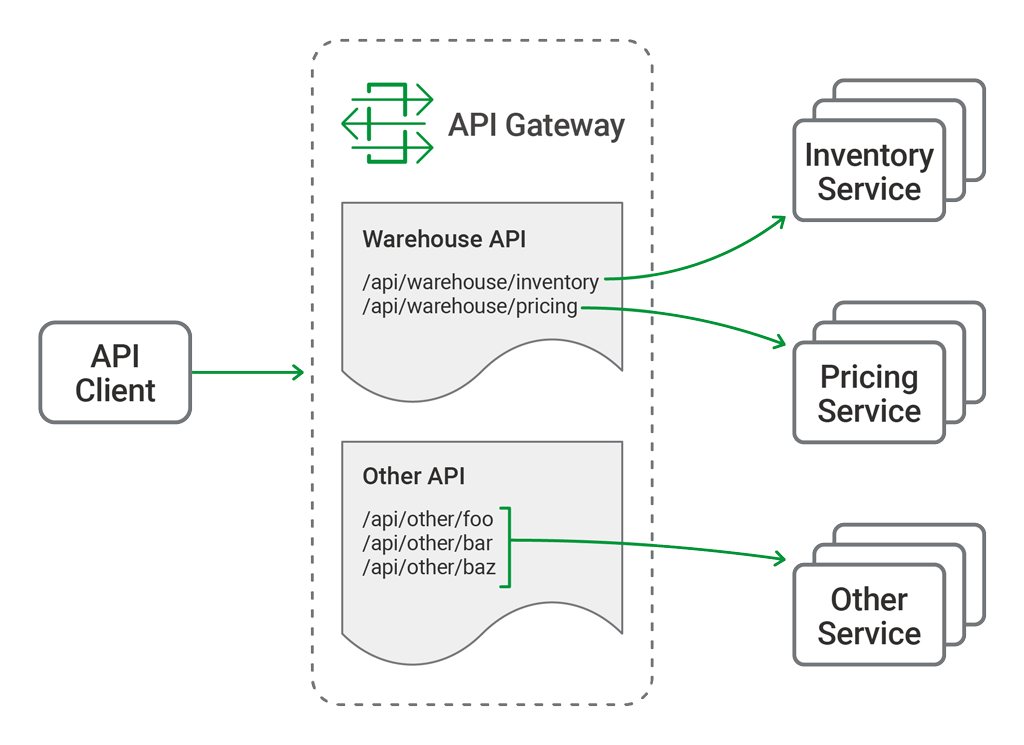
组织NGINX配置
使用NGINX Plus作为API网关的一个优点是,它可以执行该角色,同时充当现有HTTP流量的反向代理,负载平衡器和Web服务器。如果NGINX Plus已经是应用程序交付堆栈的一部分,那么通常不需要部署单独的API网关。但是,API网关所期望的某些默认行为与基于浏览器的流量的预期不同。出于这个原因,我们将API网关配置与基于浏览器的流量的任何现有(或未来)配置分开。
为实现这种分离,我们创建了一个支持多用途NGINX Plus实例的配置布局,并为通过CI / CD管道自动配置部署提供了便利的结构。 / etc / nginx下的结果目录结构如下所示。
etc/ └── nginx/├── api_conf.d/ ....................................... Subdirectory for per-API configuration│ └── warehouse_api.conf ...... Definition and policy of the Warehouse API├── api_backends.conf ..................... The backend services (upstreams)├── api_gateway.conf ........................ Top-level configuration for the API gateway server├── api_json_errors.conf ............ HTTP error responses in JSON format├── conf.d/│ ├── ...│ └── existing_apps.conf└── nginx.conf
所有API网关配置的目录和文件名都以api_为前缀。这些文件和目录中的每一个都启用API网关的不同特性和功能,并在下面详细说明。
定义顶级API网关
所有NGINX配置都以主配置文件nginx.conf开头。要读入API网关配置,我们在nginx.conf的http块中添加一个指令,该指令引用包含网关配置的文件api_gateway.conf(下面的第28行)。请注意,默认的nginx.conf文件使用include伪指令从conf.d子目录中引入基于浏览器的HTTP配置(第29行)。本博文广泛使用include指令来提高可读性并实现配置某些部分的自动化。
include /etc/nginx/api_gateway.conf; # All API gateway configurationinclude /etc/nginx/conf.d/*.conf; # Regular web traffic
api_gateway.conf文件定义了将NGINX Plus公开为客户端的API网关的虚拟服务器。此配置公开API网关在单个入口点https://api.example.com/(第13行)发布的所有API,受第16到21行配置的TLS保护。请注意,此配置纯粹是HTTPS - 没有明文HTTP侦听器。我们希望API客户端知道正确的入口点并默认进行HTTPS连接。
log_format api_main '$remote_addr - $remote_user [$time_local] "$request"''$status $body_bytes_sent "$http_referer" "$http_user_agent"''"$http_x_forwarded_for" "$api_name"';include api_backends.conf;include api_keys.conf;server {set $api_name -; # Start with an undefined API name, each API will update this valueaccess_log /var/log/nginx/api_access.log api_main; # Each API may also log to a separate filelisten 443 ssl;server_name api.example.com;# TLS configssl_certificate /etc/ssl/certs/api.example.com.crt;ssl_certificate_key /etc/ssl/private/api.example.com.key;ssl_session_cache shared:SSL:10m;ssl_session_timeout 5m;ssl_ciphers HIGH:!aNULL:!MD5;ssl_protocols TLSv1.1 TLSv1.2;# API definitions, one per fileinclude api_conf.d/*.conf;# Error responseserror_page 404 = @400; # Invalid paths are treated as bad requestsproxy_intercept_errors on; # Do not send backend errors to the clientinclude api_json_errors.conf; # API client friendly JSON error responsesdefault_type application/json; # If no content-type then assume JSON}
此配置是静态的 - 各个API及其后端服务的详细信息在第24行的include伪指令引用的文件中指定。第27到30行处理日志记录默认值和错误处理,并在响应中讨论错误部分如下。
单服务与微服务API后端
一些API可以在单个后端实现,但是出于弹性或负载平衡的原因,我们通常期望存在多个API。使用微服务API,我们为每个服务定义单独的后端;它们一起作为完整的API。在这里,我们的Warehouse API被部署为两个独立的服务,每个服务都有多个后端。
upstream warehouse_inventory {zone inventory_service 64k;server 10.0.0.1:80;server 10.0.0.2:80;server 10.0.0.3:80;}upstream warehouse_pricing {zone pricing_service 64k;server 10.0.0.7:80;server 10.0.0.8:80;server 10.0.0.9:80;}
API网关发布的所有API的所有后端API服务都在api_backends.conf中定义。这里我们在每个块中使用多个IP地址 - 端口对来指示API代码的部署位置,但也可以使用主机名。 NGINX Plus订户还可以利用动态DNS负载平衡,自动将新后端添加到运行时配置中。
定义Warehouse API
配置的这一部分首先定义Warehouse API的有效URI,然后定义用于处理对Warehouse API的请求的公共策略。
# API definition#location /api/warehouse/inventory {set $upstream warehouse_inventory;rewrite ^ /_warehouse last;}location /api/warehouse/pricing {set $upstream warehouse_pricing;rewrite ^ /_warehouse last;}# Policy section#location = /_warehouse {internal;set $api_name "Warehouse";# Policy configuration here (authentication, rate limiting, logging, more...)proxy_pass http://$upstream$request_uri;}
Warehouse API定义了许多块。 NGINX Plus具有高效灵活的系统,可将请求URI与配置的一部分进行匹配。通常,请求由最具体的路径前缀匹配,并且位置指令的顺序并不重要。这里,在第3行和第8行,我们定义了两个路径前缀。在每种情况下,$ upstream变量都设置为上游块的名称,该上游块分别代表库存和定价服务的后端API服务。
此配置的目标是将API定义与管理API交付方式的策略分开。为此,我们最小化了API定义部分中显示的配置。在为每个位置确定适当的上游组之后,我们停止处理并使用指令来查找API的策略(第10行)。

使用重写指令将处理移至API策略部分
重写指令的结果是NGINX Plus搜索匹配以/ _warehouse开头的URI的位置块。第15行的位置块使用=修饰符执行完全匹配,从而加快处理速度。
在这个阶段,我们的政策部分非常简单。位置块本身标记为第16行,这意味着客户端无法直接向它发出请求。重新定义$ api_name变量以匹配API的名称,以便它在日志文件中正确显示。最后,请求被代理到API定义部分中指定的上游组,使用$ request_uri变量 - 其中包含原始请求URI,未经修改。
选择广泛或者精确的API定义
API定义有两种方法 - 广泛而精确。每种API最合适的方法取决于API的安全要求以及后端服务是否需要处理无效的URI。
在warehouse_api_simple.conf中,我们通过在第3行和第8行定义URI前缀来使用Warehouse API的广泛方法。这意味着以任一前缀开头的任何URI都代理到相应的后端服务。使用基于前缀的位置匹配,对以下URI的API请求都是有效的:
-
/api/warehouse/inventory
-
/api/warehouse/inventory/
-
/api/warehouse/inventory/foo
-
/api/warehouse/inventoryfoo
-
/api/warehouse/inventoryfoo/bar/
如果唯一的考虑是将每个请求代理到正确的后端服务,则广泛的方法提供最快的处理和最紧凑的配置。另一方面,精确的方法使API网关能够通过显式定义每个可用API资源的URI路径来理解API的完整URI空间。采用精确的方法,Warehouse API的以下配置使用精确匹配(=)和正则表达式(〜)的组合来定义每个URI。
location = /api/warehouse/inventory { # Complete inventoryset $upstream inventory_service;rewrite ^ /_warehouse last;}location ~ ^/api/warehouse/inventory/shelf/[^/]*$ { # Shelf inventoryset $upstream inventory_service;rewrite ^ /_warehouse last;}location ~ ^/api/warehouse/inventory/shelf/[^/]*/box/[^/]*$ { # Box on shelfset $upstream inventory_service;rewrite ^ /_warehouse last;}location ~ ^/api/warehouse/pricing/[^/]*$ { # Price for specific itemset $upstream pricing_service;rewrite ^ /_warehouse last;}
此配置更详细,但更准确地描述了后端服务实现的资源。这具有保护后端服务免于格式错误的客户端请求的优点,代价是正常表达式匹配的一些小额外开销。有了这个配置,NGINX Plus接受一些URI并拒绝其他URI无效:

使用精确的API定义,现有的API文档格式可以驱动API网关的配置。可以从OpenAPI规范(以前称为Swagger)自动化NGINX Plus API定义。此博客文章的Gists中提供了用于此目的的示例脚本。
重写客户请求
随着API的发展,有时会发生需要更新客户端的重大更改。一个这样的示例是重命名或移动API资源。与Web浏览器不同,API网关无法向其客户端发送命名新位置的重定向(代码301)。幸运的是,当修改API客户端不切实际时,我们可以动态地重写客户端请求。
在下面的示例中,我们可以在第3行看到定价服务以前是作为库存服务的一部分实现的:rewrite指令将对旧定价资源的请求转换为新的定价服务。
# Rewrite rules#rewrite ^/api/warehouse/inventory/item/price/(.*) /api/warehouse/pricing/$1;# API definition#location /api/warehouse/inventory {set $upstream inventory_service;rewrite ^(.*)$ /_warehouse$1 last;}location /api/warehouse/pricing {set $upstream pricing_service;rewrite ^(.*) /_warehouse$1 last;}# Policy section#location /_warehouse {internal;set $api_name "Warehouse";# Policy configuration here (authentication, rate limiting, logging, more...)rewrite ^/_warehouse/(.*)$ /$1 break; # Remove /_warehouse prefixproxy_pass http://$upstream; # Proxy the rewritten URI}
动态重写URI意味着当我们最终在第26行代理请求时,我们不能再使用$ request_uri变量(正如我们在warehouse_api_simple.conf的第21行所做的那样)。这意味着我们需要在API定义部分的第9行和第14行使用稍微不同的重写指令,以便在处理切换到策略部分时保留URI。
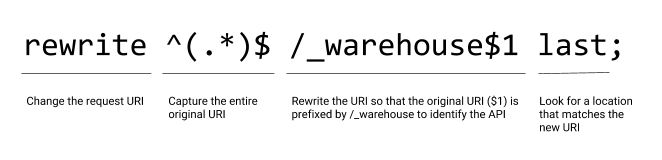
回应错误
HTTP API和基于浏览器的流量之间的主要区别之一是如何将错误传达给客户端。当NGINX Plus作为API网关部署时,我们将其配置为以最适合API客户端的方式返回错误。
# Error responseserror_page 404 = @400; # Invalid paths are treated as bad requestsproxy_intercept_errors on; # Do not send backend errors to the clientinclude api_json_errors.conf; # API client friendly JSON error responsesdefault_type application/json; # If no content-type then assume JSON
顶级API网关配置包括一个定义如何处理错误响应的部分。
第27行的指令指定当请求与任何API定义都不匹配时,NGINX Plus会返回错误而不是默认错误。此(可选)行为要求API客户端仅向API文档中包含的有效URI发出请求,并防止未经授权的客户端发现通过API网关发布的API的URI结构。
第28行指的是后端服务本身产生的错误。未处理的异常可能包含我们不希望发送到客户端的堆栈跟踪或其他敏感数据。此配置通过向客户端发送标准化错误来进一步提供保护。
完整的错误响应列表在第29行的include伪指令引用的单独配置文件中定义,其前几行如下所示。如果首选不同的错误格式,并且通过更改第30行上的default_type值以匹配,则可以修改此文件。您还可以在每个API的策略部分中使用单独的include指令来定义一组覆盖默认值的错误响应。
error_page 400 = @400;location @400 { return 400 '{"status":400,"message":"Bad request"}\n'; }error_page 401 = @401;location @401 { return 401 '{"status":401,"message":"Unauthorized"}\n'; }error_page 403 = @403;location @403 { return 403 '{"status":403,"message":"Forbidden"}\n'; }error_page 404 = @404;location @404 { return 404 '{"status":404,"message":"Resource not found"}\n'; }
有了这种配置,客户端对无效URI的请求就会收到以下响应。
$ curl -i https://api.example.com/fooHTTP/1.1 400 Bad RequestServer: nginx/1.13.10Content-Type: application/jsonContent-Length: 39Connection: keep-alive{"status":400,"message":"Bad request"}
实施身份验证
在没有某种形式的身份验证的情况下发布API以保护它们是不常见的。 NGINX Plus提供了几种保护API和验证API客户端的方法。有关基于IP地址的访问控制列表(ACL),数字证书身份验证和HTTP基本身份验证的信息,请参阅文档。在这里,我们专注于API特定的身份验证方法。
API密钥身份验证
API密钥是客户端和API网关已知的共享密钥。它们本质上是作为长期凭证发布给API客户端的长而复杂的密码。创建API密钥很简单 - 只需编码一个随机数,如本例所示。
openssl rand -base64 18 7B5zIqmRGXmrJTFmKa99vcit
在顶级API网关配置文件api_gateway.conf的第6行,我们包含一个名为api_keys.conf的文件,其中包含每个API客户端的API密钥,由客户端名称或其他描述标识。
map $http_apikey $api_client_name {default "";"7B5zIqmRGXmrJTFmKa99vcit" "client_one";"QzVV6y1EmQFbbxOfRCwyJs35" "client_two";"mGcjH8Fv6U9y3BVF9H3Ypb9T" "client_six";}
API密钥在块中定义。 map指令有两个参数。第一个定义了API密钥的位置,在本例中是在$ http_apikey变量中捕获的客户端请求的apikey HTTP头。第二个参数创建一个新变量($ api_client_name)并将其设置为第一个参数与键匹配的行上的第二个参数的值。
例如,当客户端提供API密钥7B5zIqmRGXmrJTFmKa99vcit时,$ api_client_name变量设置为client_one。此变量可用于检查经过身份验证的客户端,并包含在日志条目中以进行更详细的审核。
地图块的格式很简单,易于集成到自动化工作流程中,从现有的凭证存储生成api_keys.conf文件。 API密钥身份验证由每个API的策略部分强制执行。
# Policy section#location = /_warehouse {internal;set $api_name "Warehouse";if ($http_apikey = "") {return 401; # Unauthorized (please authenticate)}if ($api_client_name = "") {return 403; # Forbidden (invalid API key)}proxy_pass http://$upstream$request_uri;}
客户端应在apikey HTTP头中显示其API密钥。如果此标头丢失或为空(第20行),我们发送401响应以告知客户端需要进行身份验证。第23行处理API键与地图块中的任何键都不匹配的情况 - 在这种情况下,api_keys.conf第2行的默认参数将$ api_client_name设置为空字符串 - 我们发送403响应告诉身份验证失败的客户端。
有了这个配置,Warehouse API现在可以实现API密钥身份验证。
$ curl https://api.example.com/api/warehouse/pricing/item001{"status":401,"message":"Unauthorized"}$ curl -H "apikey: thisIsInvalid" https://api.example.com/api/warehouse/pricing/item001{"status":403,"message":"Forbidden"}$ curl -H "apikey: 7B5zIqmRGXmrJTFmKa99vcit" https://api.example.com/api/warehouse/pricing/item001{"sku":"item001","price":179.99}
JWT身份验证
JSON Web令牌(JWT)越来越多地用于API身份验证。原生JWT支持是NGINX Plus独有的,可以在我们的博客上验证JWT,如使用JWT和NGINX Plus验证API客户端中所述。
摘要
本系列的第一篇博客详细介绍了将NGINX Plus部署为API网关的完整解决方案。可以从我们的GitHub Gist仓库查看和下载此博客中讨论的完整文件集。本系列的下一篇博客将探讨更高级的用例,以保护后端服务免受恶意或行为不端的客户端的攻击。
原文:https://dzone.com/articles/deploying-nginx-plus-as-an-api-gateway-part-1-ngin
本文:http://pub.intelligentx.net/deploying-nginx-plus-api-gateway-part-1-nginx
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 131 次浏览
【微服务架构】面向CTO的微服务简介:微服务对企业的利弊
微服务——在这种程度上,很少有软件趋势能吸引IT决策者的注意。他们应该能够让你的应用程序更高效和可扩展。但这到底意味着什么?什么时候投资于它们而不是其他类型的软件架构是个好主意?软件公司将技术细节转化为可操作的信息,供您在业务中使用。
对于许多软件开发人员来说,基于微服务的架构已经成为他们日常工作的一个重要组成部分,因为越来越多的应用程序是这样制作的。但是,由于宣传太多,很容易把微服务当成一个时髦词。本文试图让每个可能从微服务中受益的人更容易就微服务在组织中的使用做出明智的决定。让我们来谈谈微服务;它们使用的利弊等等。
微服务——它们到底是什么?
根据Gartner的一个流行定义,microservice是应用程序的一个“紧密限定范围、强封装、松散耦合、可独立部署和独立扩展”的组件。让我们把它分解。
- 严格的范围-它有一个明确的定义,通常是非常狭窄的用途。
- 强封装——作为代码的一部分,它包含其功能的整个实现。
- 松散耦合——在大多数情况下,它是独立的,不需要其他微服务来工作。
- 独立部署-它可以单独部署,而不必损害其他微服务。
- 独立的可扩展性——即使一个微服务处理了大部分流量,我们也不需要扩展整个系统,而是只关注于扩展受影响的微服务。
还在困惑吗?基于微服务的应用程序的一个很好的例子可以是一个电子商务商店,其中每个业务领域(例如处理订单、产品目录、内部搜索、帐单、付款、交货单、PCI DSS认证)都是一个单独的微服务。微服务通常按照特定的业务用例进行组织,但是诸如身份验证或通知之类的功能也可以作为单独的微服务工作。
这种将所有这些功能划分为完全独立的块的独特能力使微服务成为分散/分布式团队的理想选择。因此,拥有诸如Netflix或Twitter这样的分布式团队的大公司可以通过将不同的微服务分配给不同的团队来高效地工作。但这并不是许多创新科技公司选择微服务的唯一原因。当你继续读下去的时候,这些优势应该会越来越明显。
微服务是如何工作的?
让我们更深入地研究微服务是如何工作的。如您所知,在一个标准的单片应用程序中,代码库可以大致分为两部分:前端和后端。每一个都有一个独立的代码库。通常,不同的团队会处理这些问题,并且每一层都可以拥有自己的主导技术(例如,针对前端和节点.js用于后端)。如下所示。
在基于微服务的体系结构中,前端层保持不变,但后端被分成多个部分,专门用于特定功能。它们中的每一个都可以有自己的存储库。由于它们是强封装的,每个微服务都可能用不同的语言编写,如下图所示。
对于许多项目——在这些项目中,没有必要(或能力)涉及这么多不同的技术,而且存在如此多的存储库会造成混乱(复杂的项目结构、存储库之间代码组织的差异等等),这些都超过了这种分离的好处——可以使用简化的版本。通过使用monorepos,可以创建包含所有使用相同技术堆栈的微服务的代码的存储库。
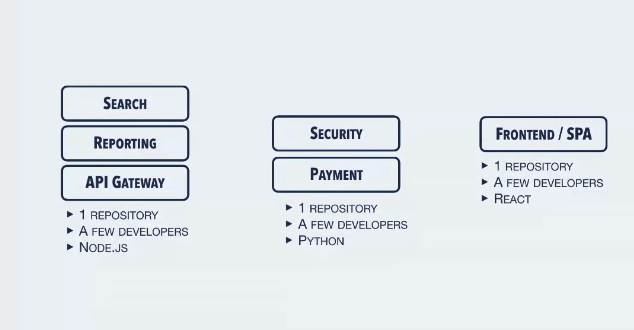
回到单片与微服务的问题。基于微服务的体系结构与整体式架构还有什么不同?
| 微服务 | 单体 | |
| 开发 |
每个服务都是一个独立的应用程序。它可能(但不一定需要)有一个单独的代码存储库,因此冲突不太常见。 为了共享一些代码,您需要有一个单独的库。 您可以更容易地扩展团队,因为每个团队可能被分配到特定的服务。 添加新功能可以扩展现有服务之一,也可以添加新服务。 |
所有的东西都放在一个地方,所以共享代码要容易得多。同时,它可能会导致一个不可维护的状态,所有的东西都是耦合的。 在同一领域工作可能会导致代码冲突,这将导致更长的开发时间。 添加新功能是指向现有应用程序添加新代码。 更难扩大团队规模。 |
| 测试 |
每个服务都是一个单独的应用程序,不仅需要单元测试,还需要组件/契约测试。 更重要的是,我们应该添加一个额外的层,允许我们同时测试多个服务之间的集成。 |
易于测试。一切都在一个地方。 大多数时候,它可以被单元和E2E测试覆盖。 |
| 部署 |
每个服务都需要单独的CI和部署过程。您需要为整个系统协调整个基础设施和配置。 但是,如果出现问题,只有一个服务将无法启动。 |
你设置了一次。不需要太多的编排。但是,如果出现问题,您根本无法部署应用程序。 |
| 维护 | 需要DevOps关于Docker、Kubernetes等的知识 | 易于维护 |
| 可靠性 | 中断一个服务并不会破坏其他服务,因此只有一组功能可能会受到影响。 | 破坏了应用程序中的一个地方,破坏了一切。 |
| 可扩展性 | 每个服务都是独立扩展的。我们只使用我们需要的资源。 | 为了扩展系统的单个部分,您必须扩展整个系统,这可能导致资源没有得到充分利用。 |
| 发布 | 您发布了一个服务,因此只需要与此特定服务相关的测试。 | 一次发布整个系统,所以每次都需要整个回归。 |
使用微服务的好处
为您的软件选择基于微服务的体系结构对您的组织有很多潜在的好处。
- 代码库与业务领域保持一致—您的微服务通常是围绕组织的实际业务功能/目标来组织的,这意味着开发人员和业务人员更容易理解技术和业务是如何联系在一起的。
- 非常适合分布式团队——不同的开发人员/团队可以在不同的微服务上工作,而不会相互妨碍。对于分布式团队来说,这比一个整体式的团队要方便得多。
- 更易于构建和维护——根据功能将代码库拆分为更小的独立片段意味着它们更易于理解和维护。Docker等许多工具简化了新微服务的创建。
- 易于部署–因为您不会中断整个应用程序,所以您可以经常修改和部署新的和现有的微服务。还有一些工具可以让它变得更简单,比如Kubernetes。
- 提高生产力——从事特定微服务的开发人员不需要等待其他开发人员完成他们的工作。接管自己的工作也更容易,因为较小的代码库更容易理解。质量保证也在这个过程中得到了突破。
- 选择技术的自由度——每个微服务都可以用不同的技术开发,这样就可以为每个问题选择最有效的解决方案。这也在很大程度上消除了技术和供应商的锁定——你的应用程序并不完全依赖于任何第三方软件。
- 高性能、高效率和可扩展性–您可以单独扩展每个微服务。这意味着单个服务可以部署在多个服务器中,以服务于增加的流量,而其他服务同时只消耗标准数量的资源。您可以以经济高效的方式保持高性能。
- 可靠性—故障隔离意味着单个服务的故障不太可能影响其他服务的性能。在一个巨石应用程序中,类似的错误可能会导致整个系统崩溃。
微服务:不同场景下的利弊
到目前为止,您可能已经对微服务能够很好地配合的项目有了一个很好的想法。总而言之:
- 由于微服务提供了出色的可伸缩性并鼓励基于敏捷的工作流,因此它们非常适合于在这些领域有高要求的应用程序。
- 由于代码库可以根据功能划分为完全独立开发的单元,因此对于分布式团队来说,这是一个明显的选择,特别是对于代表各种技术堆栈的开发人员。
- 项目越复杂、流量密集、面向长期,就越适合基于微服务的架构。
现在,让我们来看看微服务什么时候不是最好的选择——微服务的缺点。让我们考虑几个场景。
对Netflix有利的事情可能对我们不利
大型公司,如Netflix,在各地都有不同的开发团队,可以从微服务的模块化特性中获益匪浅。实现基于微服务的体系结构的成本往往比构建一个单一的应用程序要高(您需要考虑日志监视系统、请求跟踪和部署整个系统以及任何单个微服务的能力)。对于那些不希望出现大流量、可伸缩性问题和混合各种技术的系统来说,这可能不值得。
太过敏捷会让你变得僵硬
多亏了微服务,您可以通过单独部署每个微服务来更轻松地进行迭代。测试和部署成为日常工作流程的重要组成部分,而不是很少发生。但随之而来的是巨大的责任。随着动态变化的微服务数量的增加,需要大量的DevOps功能和丰富的经验才能掌握它们。
我只是在试水!
你在创建一个新的(绿地)项目吗?你是否有一个想法,并想创造一个最有价值球员?你最好的选择可能是一块巨石。你不仅不知道你需要什么样的微服务,而且从一开始就不需要微服务的复杂性。毕竟,如果有必要的话,将来您总是可以从一个整体式架构转向基于微服务的架构。
如何开始使用微服务?
有几件事你应该记住。首先,让我们考虑一下在任何情况下都成立的观点
从头开始
- 不要急于求成-确保项目证明了微服务的合理性。根据我们上面所做的所有考虑,确保您的项目适合微服务。
- 不要仅仅从理论上讲敏捷。如果没有强大的敏捷文化,您将无法从微服务中获益。
- 投资于您的DevOps文化/能力。DevOps也是如此——你的架构越大,你需要管理的微服务越多,它就越明显。
现在,谈谈更具体的问题(很有可能!)从单一体系结构到微服务的场景。
从单体到微服务
- 不要从头开始!既然你已经有了一个应用程序,你应该从它开始作为你的基础。即使你不打算马上去“微服务一路走来”,你也可以简单地在微服务中开发新功能,同时暂时保持你的基础作为一个整体。
- 避免分散的整体。不要从传统的巨石直接进入微服务。否则,你可能会得到一个分布式的整体——一个表面上模块化的应用程序,其中所有模块实际上都高度依赖于彼此。
- 去做一个模块化的整体。最好的方法是将你的整体分割成更小的、独立的部分,然后逐步地将它们转化为服务。
微服务TSH方式
你想知道软件公司是如何使用微服务的吗?我们将把最佳实践的细节留待下次讨论,但以下是TSH主管的一些最重要的观点节点.js亚当·波拉克。
TSH的一个重要实践就是不要浪费时间创建所谓的样板(创建新服务结构所需的一切)。通过在项目早期阶段创建的一组工具,我们可以快速创建新的服务,并专注于最重要的业务逻辑。”
DevOps对微服务的仔细监控对于效率、稳定性和快速恢复至关重要。
另一个重要的问题是DevOps功能,以及对服务性能的仔细监控——日志记录、跟踪、指标配置。感谢所有这些,我们的服务是稳定的。一旦出现问题,我们就能迅速找到原因。
结论
此时,您应该知道微服务是否适合您。总而言之:
- 微服务潜力巨大
- 但是,只有当项目复杂到足以超过维护和迁移到基于微服务的体系结构的成本时,才应该在项目中使用它们
- 从整体到微服务的转变应该考虑到很多因素
原文:https://tsh.io/blog/basics-of-microservices-pros-and-cons/
本文:http://jiagoushi.pro/node/1095
讨论:请加入知识星球【首席架构师智库】或者加微信小号【jiagoushi_pro】
- 25 次浏览
【微服务架构】面向CTO的微服务设计模式:API网关、前端的后端等
微服务体系结构是软件开发中最热门的趋势之一。作为CTO,你需要知道何时使用它们。但你也需要对这个主题有更深入的了解才能真正掌握你的项目。通过进一步了解微服务中的设计模式,您将确切了解微服务是如何工作的,以及开发人员如何使它们更高效、可伸缩和更安全。满足最流行的微服务设计模式。
在上一篇关于微服务的文章中,我们介绍了这种流行的软件体系结构的基础知识。有了这些知识,您就知道微服务最适合哪种项目了。但是一旦你决定去做它,会有更多的决定要做。这就是为什么你应该学习设计模式。
微服务中的设计模式是什么?
如您所知,微服务是一个很大程度上独立的应用程序组件,其任务是系统中的特定功能。多个微服务,每个微服务负责应用程序的另一个功能,再加上客户端(例如web和移动应用程序的前端)和其他(可选)中间层,构成了基于微服务的体系结构。
这种类型的设置有许多优点,例如能够用不同的技术编写任何服务并独立地部署它们,以及性能提升等等。但它也带来了一些挑战,包括复杂的管理和配置。
设计模式的存在旨在解决微服务中的此类常见挑战,并提供经验证的解决方案,使您的体系结构更高效,整个管理过程更省钱、更麻烦。因此,了解它们是更好地理解微服务的一个很好的方法——比实际的编码更高层次,但又足够具体,可以理解微服务的内部工作原理。
为什么要学习设计模式?
选择正确的设计模式可以决定你的基于微服务的项目的成败。它们是微服务本身并不是万能药的最好证明,要真正从中受益,你需要正确地使用它们。
如果您不关心微服务设计模式:
- 你的应用程序可能表现不佳(由于不必要的调用和资源使用效率低下),
- 整个系统将不稳定(例如连接和集成问题),
- 它可能面临可伸缩性问题(添加更多的服务可能导致难以维护依赖性,甚至可能使其成为事实上的一个整体),
- 它可能会通过向公众公开微服务的端点或通过其他方式危害安全性。
- 您可能有更多的维护和调试工作要做,而不是做更好的准备。
微服务设计模式的类型
微服务中的设计模式几乎存在于架构的每个方面。一些最重要的问题可分为以下几个方面:
通信
它涉及微服务和客户端应用程序(前端层)之间的通信方法。
内部沟通
这些设计模式构成了微服务之间进行通信的各种方式。
安全
各种与安全相关的问题,如安全层的组织、不同类型用户对特定微服务的授权和访问级别等。
可用性
确保所有的微服务都准备好满足系统的需求(不管流量有多大),确保尽可能少的停机时间。这包括确保微服务可以在另一台计算机上重新启动,或者是否有足够的计算机可用,微服务能够自行报告其当前状态,运行状况检查等等。
服务发现
它指的是微服务用来找到彼此并知道它们的位置的方法。
配置
设置参数并监控整个系统的性能,以便在您进行过程中不断优化
在本文的后续部分中,我们将主要关注第一种类型,讨论三种最流行的通信模式——直接模式、API网关和前端后端(BFF)。它们提供了一个很好的机会来了解基于微服务的体系结构是如何工作的,以及开发人员的选择对其性能的影响。
直接模式
这是基于微服务架构的最基本的设置。在这种模式下,客户端应用程序直接向微服务发出请求,如下图所示。每个微服务都有一个公共端点(URL),客户端可以与之通信。
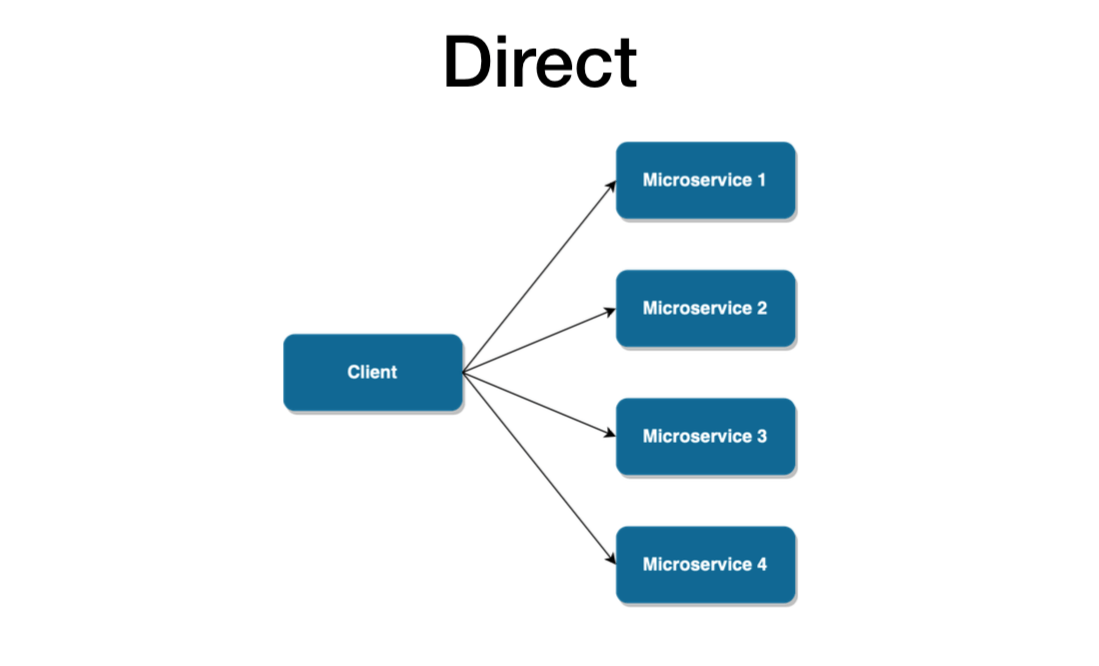
这非常容易设置,对于相对较小的应用程序来说已经足够了,但是随着应用程序的规模和复杂性的增长,这些挑战会变得越来越明显和麻烦:
性能问题
即使是应用程序的一个页面也可能需要对不同的微服务进行多次调用,这可能会导致较大的延迟和性能问题。
可伸缩性问题
因为客户端应用程序直接引用微服务,所以对微服务的任何更改都可能导致应用程序崩溃。这使得维护困难。
安全问题
没有中间层,微服务的端点就会暴露出来。这不一定会使应用程序本身就不安全,但它肯定会使安全问题变得更难处理。
复杂性问题
此外,每个公共微服务都需要包含安全和其他跨服务任务。如果有一个额外的层,它们可以被包含在那里,使所有的微服务更简单。
由于微服务通常被推荐用于复杂的应用程序,因此必须有更具可伸缩性的模式。
API网关
当然有!API网关将这一切提升到一个级别。如下图所述,它提供了一个额外的层,一组微服务和前端层之间的单一入口点。它解决了我们刚刚提到的所有问题,通过向公众隐藏微服务的端点,从客户端抽象对微服务的引用,并通过聚合多个调用来减少延迟。
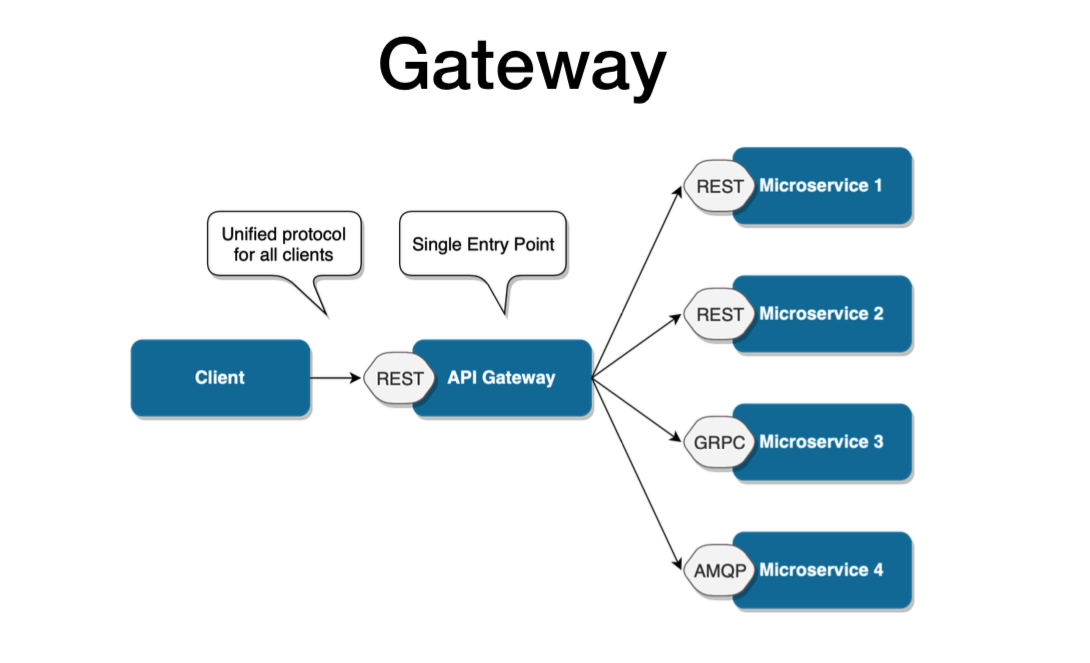
然而,API网关模式仍然不能避免可伸缩性问题。当体系结构围绕一个客户机时,这已经足够了。但是如果有多个客户端应用程序,API网关最终可能会膨胀,因为它吸收了来自不同客户端应用程序的所有不同需求。最终,它可能会成为一个单一的应用程序,并面临许多与直接模式相同的问题。
因此,如果您计划让基于microservices的系统具有多个客户机或不同的业务域,那么您应该从一开始就考虑使用前端后端模式。
前端的后端(BFF)
网关API本质上是BFF模式的变体。它还提供了微服务和客户端之间的附加层。但它不是单一的入口点,而是为每个客户机引入了多个网关。
使用BFF,您可以添加一个为每个客户机的需求量身打造的API,从而消除了由于将它们都放在一个地方而导致的大量膨胀。结果模式如下图所示。
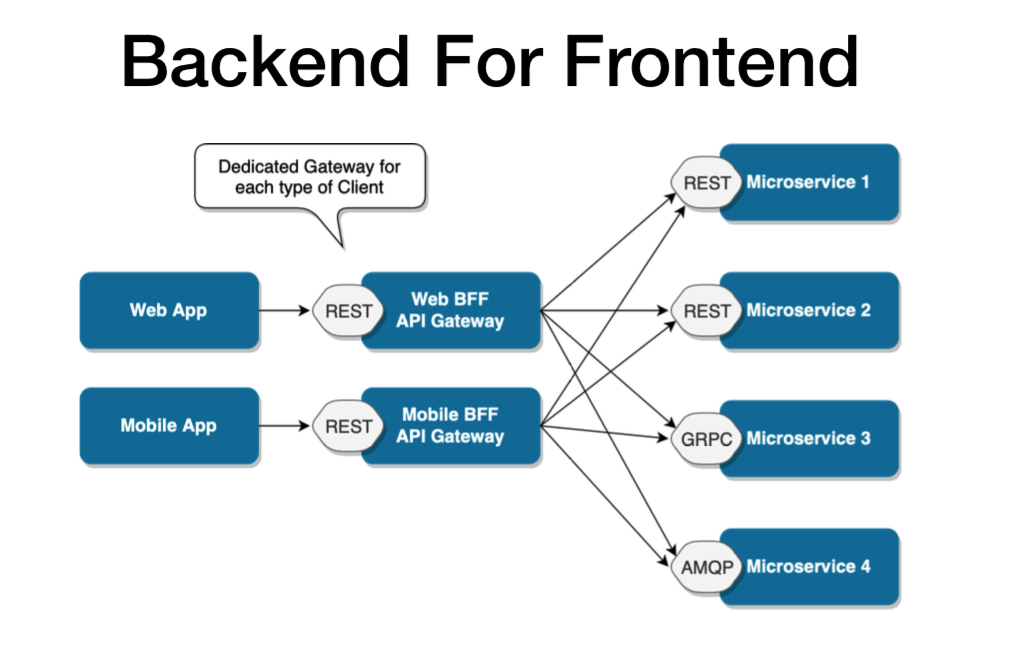
值得一提的是,这种特定的模式可能仍会扩展到特别复杂的应用程序。还可以为特定的业务域创建不同的网关。这个模型足够灵活,可以响应任何类型的基于微服务的情况。
这是否意味着每个基于微服务的架构都应该使用BFF模式?不一定。设计越复杂,需要的设置和配置就越多。并不是每个应用程序都需要这样做。但是如果你想创建一个应用程序的生态系统,或者计划在将来扩展它,为了将来的可扩展性,你可以选择更复杂的通信模式。
如果你想了解更多关于BFF的信息,一定要阅读我们的前端案例研究的后端——这是一个应用程序生态系统的故事,它是使用模式重塑的。
其他值得注意的设计模式
正如我前面提到的,设计模式存在于微服务的各个方面。开发人员常常被迫在这两者之间做出选择,考虑到不同的因素。在其他一些情况下,它们可以组合在一起或一起使用。
对于内部通信,一些最流行的模式包括REST、gRPC、messagebroker或远程过程调用。在安全性方面,访问控制列表(ACL)可以用于每个微服务或每个网关,也可以作为独立的微服务(或者根本不使用)。说到可用性,我们可以使用基于DNS或硬件的负载平衡。服务发现可以在客户端或服务器端执行。至于配置,可以是外部化的(每个微服务都有自己的一个)或集中化(所有配置都在一个地方)。名单还在继续。
另请参阅:gRPC实用介绍
结论
随着微服务越来越流行,新的设计模式出现了,以帮助解决各种开发挑战,并使体系结构更加高效。尽可能多地了解它们是值得的,但归根结底还是要为特定的软件生态系统选择正确的软件。说到这一点-相信你的开发人员,但要确保你知道他们的选择和他们对你的软件的影响。
原文:https://tsh.io/blog/design-patterns-in-microservices-api-gateway-bff-and-more/
本文:http://jiagoushi.pro/node/1088
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 64 次浏览
【架构设计】酒店预订应用程序的系统设计架构(如 Airbnb、OYO)
Airbnb、Booking.com 和 OYO 等酒店预订应用程序如何提供从酒店列表到预订再到付款的流畅流程? 而且都没有一个小故障! 在此博客中,您将获得对此的详细解释。
由于它们非常庞大,以至于它们需要处理大量的用户流量。 所以要管理这些,我们必须遵循微服务架构。 这意味着我们必须为每种类型的任务将系统分成小块。
让我们一一了解流程。 我把它分成了4个部分:
- 酒店管理服务
- 客户服务(搜索+预订)
- 查看预订服务
酒店管理服务
这是将提供给酒店经理/业主的服务。 在此管理人员可以管理他们酒店的相关信息。 在这里,管理者有一个单独的门户来访问和更新数据。
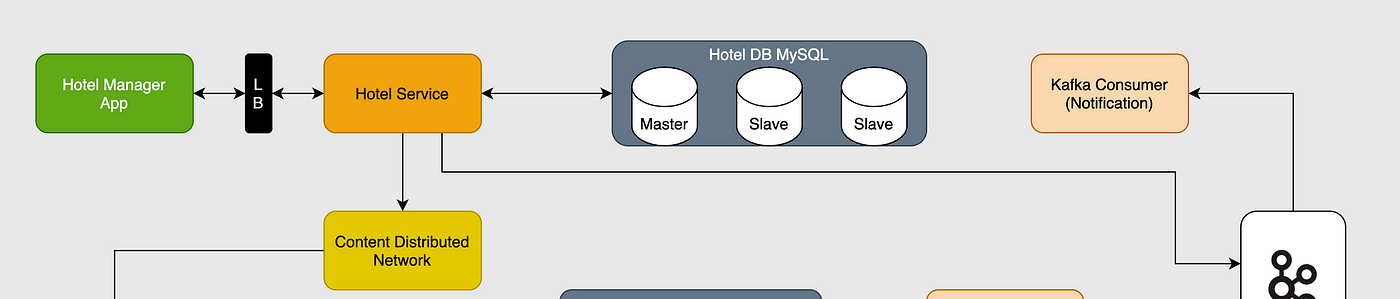
- Hotel Management Service Architecture
每当从酒店管理器应用程序触发 API 时,初始请求都会发送到负载均衡器,然后负载均衡器会将请求分发到所需的服务器进行处理。酒店服务集群有多个服务器,这些服务器具有酒店服务相关 API 的容器。
现在,该酒店服务与遵循主从架构的酒店数据库集群进行交互,以减少数据库中的负载。基本上,在这种方法中,我们创建主数据库的副本,称为从数据库。 Master DB 用于写操作,slave DB 仅用于读操作。每当在主数据库上执行写操作时,它都会将数据同步到从数据库。
每当数据库中的任何数据更新时,API 都会将数据发送到 CDN(内容分布式网络)和消息队列系统(如 Kafka、RabbitMQ)以进行进一步处理。 CDN 是一组地理分布的服务器,它们协同工作以提供 Internet 内容的快速交付。
客户服务(搜索+预订)
这是将提供给客户的服务。在这个客户可以搜索和预订酒店。在这里,客户有一个单独的门户来访问和处理数据。
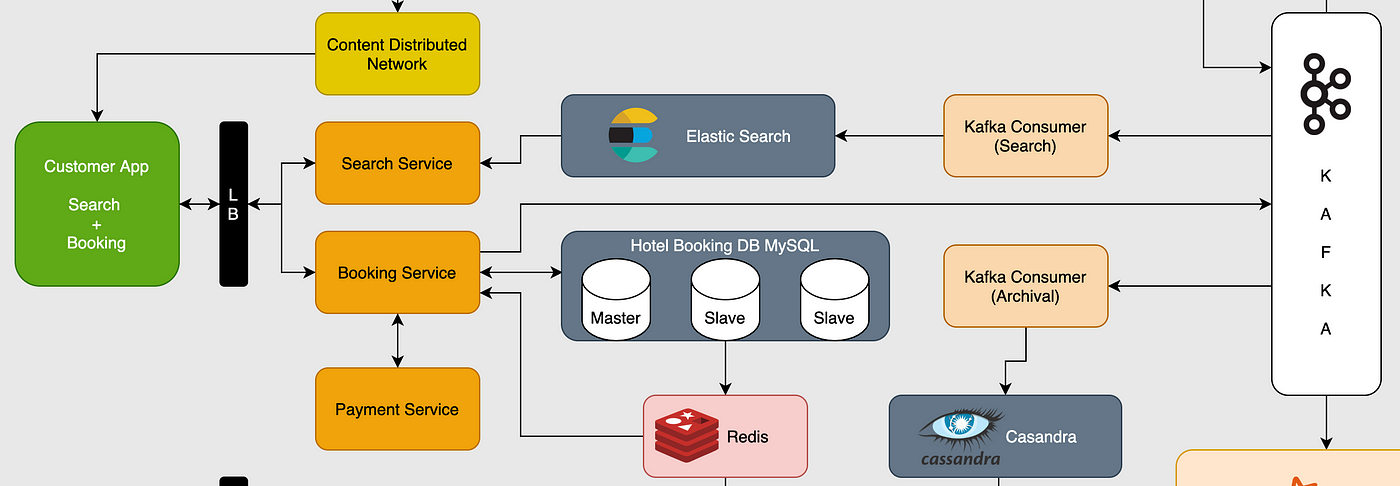
- Customer Service Architecture
CDN 应用程序向客户显示内容,例如附近的酒店、推荐、优惠等。
正如我们在上一节中讨论的,酒店数据在消息队列系统中发送以进行处理。这里我们有一个消息队列消费者,它从队列中获取数据并将数据存储在弹性搜索中。
客户应用点击 API,然后负载均衡器将请求重定向并将请求分发到相应的服务以处理请求。在这里,我们有两种服务,一种是搜索酒店,另一种是预订服务,用于预订酒店,预订服务还与第三方服务的支付服务进行交互。
搜索服务必须从 Elastic Search 中获取数据。 Elasticsearch 是一个 NoSQL 数据库,最适合其搜索引擎功能。
预订服务与 Redis 和预订数据库集群进行通信。 Redis 是缓存系统,它存储临时数据,因此数据不需要从数据库中获取,最终可以减少数据库的负载,也可以减少 API 的响应时间。
对数据库所做的任何更改都将发送到消息传递队列。然后消费者将从队列中取出数据并将其放入 Casandra。对于存档,我们使用 Casandra,因为随着时间的推移,数据库中的数据大小会增加,这会增加查询时间。这就是为什么我们可能需要从数据库中删除旧数据的原因。而 Casandra 是一个 NoSQL 数据库,擅长处理大量数据。
查看预订服务
此处向用户显示所有当前和旧的预订详细信息。经理和客户都使用此服务。

- View Booking Architecture
Customer/Manager 应用程序将请求发送到负载均衡器,并将请求分发到预订管理服务器。 然后通过 Redis 和 Cassandra 对数据的服务请求。 通过 Redis,它请求最近的数据,因为它是一个缓存服务器。 这可以减少应用程序端的加载时间。
最终设计

- Hotel Booking System Design
正如您在上面的设计中看到的,有一个用于通知的 Kafka 消费者,通知消费者发送通知。 这可能是针对客户/经理的,例如,每当客户预订酒店时,就会向经理发送通知,或者如果有新的优惠来了,就会通知客户。
Apache Streaming 服务从消息队列中获取数据并将其存储在 Hadoop 中,可用于大数据分析以用于多种用途。 比如业务分析、寻找潜在客户、受众分类等。
原文:https://medium.com/nerd-for-tech/system-design-architecture-for-hotel-b…
- 417 次浏览
【系统设计】系统设计基础:速率限制器
什么是速率限制器?
速率限制是指防止操作的频率超过定义的限制。 在大型系统中,速率限制通常用于保护底层服务和资源。 速率限制一般在分布式系统中作为一种防御机制,使共享资源能够保持可用性。
速率限制通过限制在给定时间段内可以到达您的 API 的请求数量来保护您的 API 免受意外或恶意过度使用。 在没有速率限制的情况下,任何用户都可以用请求轰炸您的服务器,从而导致其他用户饿死的峰值。
Rate limiting at work
为什么要限速?
- 防止资源匮乏:速率限制的最常见原因是通过避免资源匮乏来提高基于 API 的服务的可用性。如果应用速率限制,则可以防止基于负载的拒绝服务 (doS) 攻击。即使一个用户用大量请求轰炸 API,其他用户也不会挨饿。
- 安全性:速率限制可防止暴力破解登录、促销代码等安全密集型功能。对这些功能的请求数量在用户级别受到限制,因此暴力破解算法在这些场景中不起作用。
- 防止运营成本:在按使用付费模式自动扩展资源的情况下,速率限制通过对资源扩展设置虚拟上限来帮助控制运营成本。如果不采用速率限制,资源可能会不成比例地扩展,从而导致指数级的账单。
速率限制策略
速率限制可应用于以下参数:
- 用户:限制在给定时间段内允许用户的请求数。基于用户的速率限制是最常见和最直观的速率限制形式之一。

- 2. 并发性:这里限制了在给定时间范围内用户可以允许的并行会话数。并行连接数量的限制也有助于缓解 DDOS 攻击。
- 3. 位置/ID:这有助于运行基于位置或以人口统计为中心的活动。可以限制不是来自目标人口统计的请求,以提高目标区域的可用性
- 4. 服务器:基于服务器的速率限制是一种利基策略。这通常在特定服务器需要大部分请求时使用,即服务器与特定功能强耦合
速率限制算法
漏桶:
漏桶是一种简单直观的算法。它创建一个容量有限的队列。在给定时间范围内超出队列容量的所有请求都会溢出。
这种算法的优点是它可以平滑请求的突发并以恒定的速率处理它们。它也很容易在负载均衡器上实现,并且对每个用户来说都是高效的内存。无论请求的数量如何,都保持到服务器的恒定接近均匀的流量。
Leaky Bucket
该算法的缺点是请求的爆发可能会填满存储桶,导致新请求的匮乏。它也不能保证请求在给定的时间内完成。
2、令牌桶:
令牌桶类似于漏桶。在这里,我们在用户级别分配令牌。对于给定的持续时间 d,定义了用户可以接收的请求 r 个数据包的数量。每次新请求到达服务器时,都会发生两个操作:
- 获取令牌:获取该用户的当前令牌数。如果它大于定义的限制,则丢弃请求。
- 更新令牌:如果获取的令牌小于持续时间 d 的限制,则接受请求并附加令牌。
该算法具有内存效率,因为我们为我们的应用程序为每个用户节省了更少的数据量。这里的问题是它可能导致分布式环境中的竞争条件。当来自两个不同应用程序服务器的两个请求同时尝试获取令牌时,就会发生这种情况。
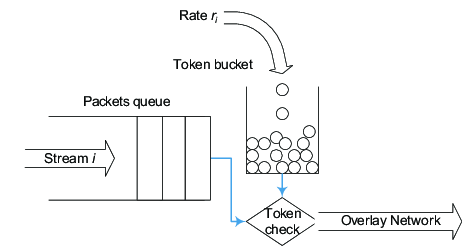
Token Bucket Algorithm
3、固定窗口计数器:
固定窗口是最基本的限速机制之一。 我们在给定的时间内保留一个计数器,并为我们收到的每个请求不断增加它。 一旦达到限制,我们将丢弃所有进一步的请求,直到重置持续时间。
这里的优点是它确保最近的请求得到服务,而不会被旧的请求饿死。 但是,在限制边缘的单个流量突发可能会囤积当前和下一个时隙的所有可用时隙。 消费者可能会轰炸边缘的服务器,以尝试最大化所服务的请求数量。

Fixed Window Counter
4. 滑动日志:
滑动日志算法涉及在用户级别维护带有时间戳的请求日志。系统将这些请求时间排序在一个集合或一个表中。它丢弃所有时间戳超过阈值的请求。我们每一分钟都在寻找旧的请求并将它们过滤掉。然后我们计算日志的总和来确定请求率。如果请求将超过阈值速率,则保留它,否则提供服务。
该算法的优点是不受固定窗口边界条件的影响。速率限制的执行将保持精确。由于系统会跟踪每个消费者的滑动日志,因此不会出现挑战固定窗口的踩踏效应。
但是,为每个请求存储无限数量的日志可能会很昂贵。计算也很昂贵,因为每个请求都需要计算消费者先前请求的总和,可能跨服务器集群。因此,它不能很好地扩展以处理大量流量或拒绝服务攻击。
5、Sliding Window:
这类似于Sliding Log算法,但内存效率高。它结合了固定窗口算法的低处理成本和滑动对数改进的边界条件。
我们保留一个按时间排序的条目列表/表格,每个条目都是混合的,包含时间戳和当时的请求数。我们保留一个持续时间的滑动窗口,并且仅在我们的窗口中以给定的速率提供服务请求。如果计数器的总和大于限制器的给定速率,那么我们只取等于速率限制的第一个条目总和。
滑动窗口方法是最好的方法,因为它提供了扩展速率限制的灵活性和良好的性能。速率窗口是一种向 API 使用者呈现速率限制数据的直观方式。它还避免了漏桶的饥饿问题和固定窗口实现的爆裂问题
分布式系统中的速率限制
上述算法非常适用于单服务器应用程序。但是当分布式系统涉及到多个节点或应用服务器时,问题就变得非常复杂。如果有多个限速服务分布在不同的服务器区域,问题就会变得更加复杂。在这些情况下遇到的两个广泛问题是不一致和竞争条件。
不一致
对于具有分布在不同区域的多个应用服务器并具有自己的速率限制器的复杂系统,我们需要定义一个全局速率限制器。
如果消费者在短时间内收到大量请求,它可能会单独超过全局速率限制器。节点数越多,用户越有可能超过全局限制。
有两种方法可以解决这些问题:
- 粘性会话:在您的负载均衡器中设置一个粘性会话,以便每个消费者都准确地发送到一个节点。缺点包括节点过载时缺乏容错和扩展问题。您可以在此处阅读有关粘性会话的更多信息
- 集中式数据存储:使用 Redis 或 Cassandra 等集中式数据存储来处理每个窗口和消费者的计数。增加的延迟是一个问题,但提供的灵活性使其成为一个优雅的解决方案。
比赛条件
竞争条件以高并发的获取然后设置的方法发生。每个请求都获取 counter 的值,然后尝试增加它。但是当写操作完成时,其他几个请求已经读取了计数器的值(这是不正确的)。因此,发送的请求数量超出了预期。这可以通过在读写操作上使用锁来缓解,从而使其成为原子操作。但这是以性能为代价的,因为它成为导致更多延迟的瓶颈。
节流
限制是在给定时间段内控制客户对 API 的使用的过程。可以在应用程序级别和/或 API 级别定义限制。当超过油门限制时,服务器返回 HTTP 状态“429 — 请求太多”。
节流类型:
- Hard Throttling:API 请求数不能超过限制。
- Soft Throttling:在这种类型中,我们可以将 API 请求限制设置为超过一定百分比。例如,如果我们的速率限制为每分钟 100 条消息并且 10% 超出限制,那么我们的速率限制器将允许每分钟最多 110 条消息。
- 弹性或动态限制:在弹性限制下,如果系统有一些可用资源,请求的数量可能会超过阈值。例如,如果一个用户每分钟只允许发送 100 条消息,我们可以让该用户每分钟发送超过 100 条消息,当系统中有可用资源时。
谢谢阅读!
References
- Sticky sessions:
- Kong API Gateway:
- Token Bucket:
原文:https://medium.com/geekculture/system-design-basics-rate-limiter-351c09…
- 86 次浏览
【韧性架构】让你的微服务容错的 5 种模式

在本文中,我将介绍微服务中的容错以及如何实现它。如果你在维基百科上查找它,你会发现以下定义:
容错是使系统在其某些组件发生故障时能够继续正常运行的属性。
对我们来说,组件意味着任何东西:微服务、数据库(DB)、负载均衡器(LB),应有尽有。我不会介绍 DB/LB 容错机制,因为它们是特定于供应商的,启用它们最终会设置一些属性或更改部署策略。
作为软件工程师,应用程序是我们拥有所有权力和责任的地方,所以让我们照顾好它。这是模式列表,我将介绍:
- 超时
- 重试
- 断路器
- 截止日期(Deadlines)
- 速率限制器
有些模式是众所周知的,你甚至可能怀疑它们是否值得一提,但请继续阅读这篇文章——我将简要介绍基本形式,然后讨论它们的缺陷以及如何克服它们。
超时
超时是允许等待某个事件发生的指定时间段。如果您使用 SO_TIMEOUT(也称为套接字超时或读取超时),则会出现问题——它表示任何两个连续数据包之间的超时,而不是整个响应,因此执行 SLA 更加困难,尤其是当响应负载很大时。您通常想要的是超时,它涵盖了从建立连接到响应的最后一个字节的整个交互。 SLA 通常用这种超时来描述,因为它们对我们来说是人道和自然的。可悲的是,它们不符合 SO_TIMEOUT 理念。要在 JVM 世界中克服它,您可以使用 JDK11 或 OkHttp 客户端。 Go 在 std 库中也有一个机制。
如果您想深入了解,请查看我之前的文章。
重试
如果您的请求失败 - 请稍等,然后重试。基本上就是这样,重试是有意义的,因为网络可能会暂时降级或 GC 命中您的请求所针对的特定实例。现在,想象一下有这样的微服务链:

如果我们将每个服务的总尝试次数设置为 3 并且服务 D 突然开始服务 100% 的错误会发生什么?这将导致重试风暴——链中的每个服务都开始重试它们的请求,因此大大增加了总负载,因此 B 将面临 3 倍负载,C - 9 倍和 D - 27 倍!冗余是实现高可用性的关键原则之一,但我怀疑在这种情况下集群 C 和 D 上是否有足够的可用容量。将总尝试次数设置为 2 也无济于事,而且它会使用户体验在小问题上变得更糟。
解决方案:
- 区分可重试的错误和不可重试的错误。当用户没有权限或负载结构不正确时,重试请求是没有意义的。相反,重试请求超时或 5xx 是好的。
- 采用错误预算——技术,当可重试错误率超过阈值时停止重试,例如如果与服务 D 的 20% 的交互导致错误,请停止重试并尝试优雅降级。在最后几秒内滚动窗口可能会跟踪错误数量。
断路器
断路器可以解释为更严格的错误预算版本——当错误率太高时,函数根本不会被执行,并且会返回回退结果(如果提供的话)。无论如何都应该执行一小部分请求,以了解第 3 方是否恢复。我们想要的是让第 3 方有机会在不进行任何手动工作的情况下恢复。
您可能会争辩说,如果功能处于关键路径上,则启用断路器是没有意义的,但请记住,这种短暂且受控的“中断”可能会阻止一个大的且无法控制的中断。
尽管断路器和错误预算具有相似的想法,但配置它们是有意义的。由于错误预算的破坏性较小,因此其阈值必须更小。
长期以来,Hystrix 是 JVM 中的首选断路器实现。截至目前,它进入了维护模式,建议改用 resilience4j 。
截止日期/分布式超时
我们已经在本文的第一部分讨论了超时,现在让我们看看如何使它们“分布式”。首先,重新访问相互调用的相同服务链:
服务 A 愿意最多等待 400 毫秒并请求需要所有 3 个下游服务完成一些工作。假设服务 B 花了 400 毫秒,现在准备调用服务 C。这是否合理?不!服务超时,不再等待结果。进一步进行只会浪费资源并增加重试风暴的敏感性。
为了实现它,我们必须在请求中添加额外的元数据,这将有助于理解什么时候中断处理是合理的。理想情况下,这应该得到所有参与者的支持并在整个系统中传递。
在实践中,此元数据是以下之一:
- 时间戳:通过您的服务将停止等待响应的时间点。首先,网关/前端服务将截止日期设置为“当前时间戳+超时”。接下来,任何下游服务都应该检查当前时间戳是否≥截止日期。如果答案是肯定的,那么关闭它是安全的,否则 - 开始处理。不幸的是,当机器可以有不同的时钟时间时,时钟偏差就会出现问题。如果发生这种情况,请求将被卡住或/并立即被拒绝,从而导致中断发生。
- 超时:通过服务允许等待的时间量。这实现起来有点棘手。与尽快设定截止日期之前一样。接下来,任何下游服务都应该计算它花费了多少时间,从入站超时中减去它并传递给下一个参与者。重要的是不要忘记排队等候的时间!所以,如果允许服务 A 等待 400ms,服务 B 花费 150ms,则在调用服务 C 时,它必须附加 250ms 的期限超时。虽然它不计算在线上花费的时间,但期限只能稍后触发,而不是更早,因此,可能会消耗更多的资源,但不会破坏结果。截止日期在 GRPC 中以这种方式实现。
最后要讨论的是——当超过最后期限时,不中断调用链是否有意义?答案是肯定的,如果你的服务有足够的可用容量并且完成请求会使它变得更热(缓存/JIT),那么继续处理是可以的。
速率限制器
前面讨论的模式主要解决了级联故障的问题——依赖服务崩溃后依赖崩溃,最终导致完全关闭的情况。现在,让我们介绍一下服务超载时的情况。它可能发生的原因有很多技术和特定领域的原因,假设它发生了。

每个应用程序都有其未知的容量。这个值是动态的,取决于多个变量——例如最近的代码更改、当前运行的 CPU 应用程序的模型、主机的繁忙程度等。
当负载超过容量时会发生什么?通常,会发生这种恶性循环:
- 响应时间增加,GC 占用空间增加
- 客户端获得更多超时,甚至更多负载到达
- 转到 1,但更严重
这是可能发生的事情的一个例子。当然,如果客户有错误预算/断路器,第二项可能不会产生额外的负载,从而有机会离开这个循环。相反,可能会发生其他事情——从 LB 的上游列表中删除实例可能会在负载和关闭邻居实例等方面造成更多不平等。
限制器来救援!他们的想法是优雅地卸载传入的负载。这就是理想情况下应该如何处理过多的负载:
- 限制器降低超出容量的额外负载,从而让应用程序根据 SLA 处理请求
- 过度负载重新分配到其他实例/集群自动缩放/集群由人工缩放
有两种类型的限制器——速率(rate )和并发,前者限制入站 RPS,后者限制任何时刻正在处理的请求数量。
为了简单起见,我假设所有对我们服务的请求在计算成本上几乎相等并且具有相同的重要性。计算不平等源于这样一个事实,即不同的用户可以有不同数量的与之关联的数据,例如喜欢的电视剧或以前的订单。通常,采用分页有助于实现请求的计算平等。
速率限制器使用更广泛,但没有提供像并发限制那样强大的保证,所以如果你想选择一个,坚持并发限制,这就是原因。
在配置速率限制器时,我们认为我们强制执行以下操作:
该服务可以在任何时间点每秒处理 N 个请求。
但我们实际上声明的是这样的:
假设响应时间不会改变,该服务可以在任何时间点每秒处理 N 个请求。
为什么这句话很重要?我会用直觉“证明”它。对于那些愿意基于数学证明的人——检查利特尔定律。假设速率限制为 1000 RPS,响应时间为 1000 毫秒,SLA 为 1200 毫秒,在给定的 SLA 下,我们很容易在一秒钟内准确地处理 1000 个请求。
现在,响应时间增加了 50 毫秒(依赖服务开始做额外的工作)。从现在开始服务的每一秒都会面临越来越多的请求同时被处理,因为到达率大于服务率。拥有无限数量的工作人员意味着您将耗尽资源并崩溃,尤其是在工作人员以 1:1 映射到操作系统线程的环境中。 1000 名工作人员的并发限制如何处理?它将可靠地提供 1000/1.05 = ~950 RPS 而不会违反 SLA,并放弃其余的。此外,无需重新配置即可赶上!
我们可以在每次依赖关系发生变化时更新速率限制,但这是一个巨大的负担,可能需要在每次变化时重新配置整个生态系统。
根据设置限制值的方式,它可以是静态限制器,也可以是动态限制器。
静止的
在这种情况下,限制是手动配置的。价值可以通过定期的性能测试来评估。虽然它不会 100% 准确,但为了安全起见,它可以被悲观。这种类型的限制需要围绕 CI/CD 管道完成工作,并且资源利用率较低。静态限制器可以通过限制工作线程池的大小(仅限并发)、添加计数请求的入站过滤器、NGINX 限制功能或 envoy sidecar 代理来实现。
动态的
在这里,限制取决于度量,它会定期重新计算。 很有可能,您的服务在过载和响应时间增长之间存在相关性。 如果是这样,度量可以是响应时间的统计函数,例如 百分位、中等或平均水平。 还记得计算相等属性吗? 此属性是更准确计算的关键。
然后,定义一个谓词来回答指标是否健康。 例如,p99 ≥ 500ms 被认为是不健康的,因此应该降低限制。 如何增加和减少限制应该由应用反馈控制算法决定,如 AIMD(用于 TCP 协议)。 这是它的伪代码:
if healthy {
limit = limit + increase;
} else {
limit = limit * decreaseRatio; // 0 < decreaseRatio < 1.0
}

AIMD in action
如您所见,限制增长缓慢,探测应用程序是否运行良好,如果发现错误行为,则急剧减少。
Netflix 率先提出了动态限制的想法并开源了他们的解决方案,这里是 repo。 它实现了几种反馈算法、静态限制器实现、GRPC 集成和 Java servlet 集成。
呵呵,就是这样! 我希望你今天学到了一些新的和有用的东西。 我想指出,这个列表并不详尽,您还希望获得良好的可观察性,因为可能会发生意想不到的事情,最好了解您的应用程序目前正在发生什么。 然而,实施这些将解决您当前或潜在的大量问题。
参考
- Google SRE book, especially chapters Addressing Cascading Failures and Handling Overload
- Netflix article about dynamic limits
原文:https://itnext.io/5-patterns-to-make-your-microservice-fault-tolerant-f…
本文:
- 26 次浏览