
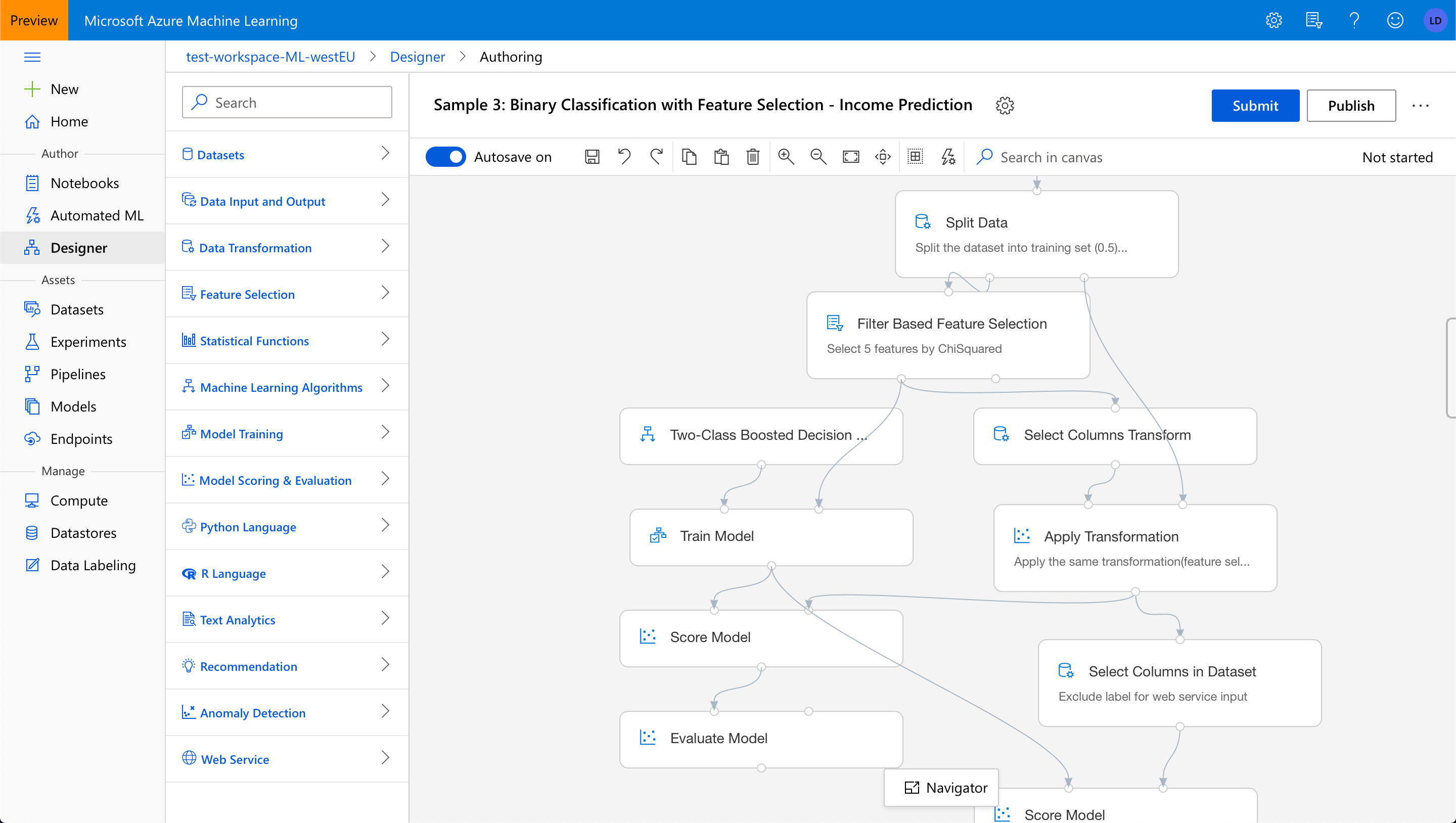
Azure ML是许多包含基于代码的模型开发特性的ML平台之一,但它也是一个“studio”(如下所示)
本文是机器学习平台系列的第一篇。它由数字弹射器和PAPIs支持。
对于所有ML成熟度级别的组织来说,模型开发平台极大地减少了创建ML模型的时间和成本。这些平台可以是现成的,也可以是定制的,基于开源或商业软件。其中一些还作为模型部署平台,在少数情况下作为模型生命周期管理平台,但是它们的核心是运行模型培训管道。
根据模型开发平台的不同,培训管道或多或少是可定制的,它们可以在您自己的机器或云基础设施上运行。我们可以将ML开发平台分为以下几种类型:
- 半专用平台(例如用于文本或图像输入)
- 高级平台即服务(主要用于表格数据)
- 自托管工作室
- 云机器学习IDE
这个平台类型列表是通过增加灵活性来排序的——但是请注意,这是以增加模型开发、配置和维护的时间为代价的。Cloud ML ide是最灵活的,可以用于任何类型的数据。然而,大多数高级平台和工作室只处理表格数据。目前有数百种ML平台,因此我们不会尝试引用所有的ML平台,而是为每种类型提供各种平台。就让我们一探究竟吧!
半专业化平台:语言和愿景
语言平台允许用户根据自己的数据训练定制文本模型。输入将是使用给定语言的文本。对于视觉平台,输入将是图像或视频。对于语言和视觉平台来说,输出都是标识“概念”的标签。如果您愿意,这些可以是“专有的”概念(例如,我们组织内部的引用,例如项目名称或团队名称)。您将向平台提供自己的训练数据(输入和输出),它将自动创建您自己的ML模型。请注意,模型训练过程可能是不可定制的,但至少您能够快速创建工作模型。
视觉平台的例子有:Clarifai, Amazon Rekognition, and Google AutoML Vision。下面我们将展示如何使用Clarifai在2个API调用中创建模型:一个用于发送训练数据,另一个用于实际创建模型。
$ curl https://api.clarifai.com/v2/inputs -H "Authorization: Key YOUR_API_KEY" -H "Content-Type: application/json" -d '{ "inputs": [ { "data": {"image": {"base64": "'"$(base64 /home/user/object1.jpeg)"'"}, "concepts": [ {"id": "defect", "value": true} ] } ] }' $ curl https://api.clarifai.com/v2/models -H "Authorization: Key YOUR_API_KEY" -H "Content-Type: application/json" -d '{"model": { "name": "defect_detector", "output_info": { "data": {"concepts": [{"id": "defect"}]}, "output_config": { "concepts_mutually_exclusive": true, "closed_environment": false }}}}'
然后您就可以检查您的模型并评估其性能。
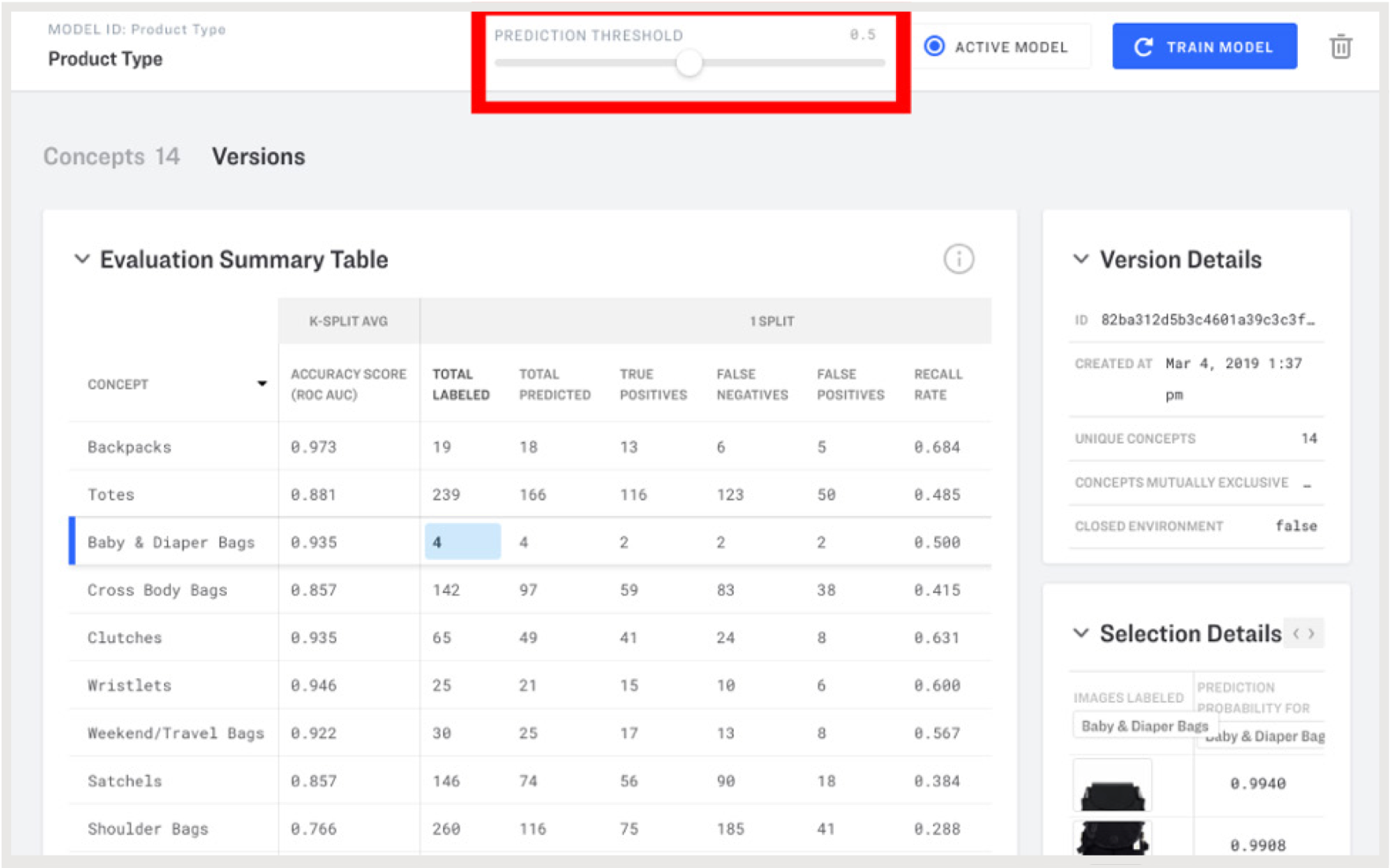
在Clarifai门户中进行模型评估和阈值调整
一些示例语言平台:Amazon understand、谷歌AutoML Natural Language和MonkeyLearn。Lateral是另一个有趣的API,它包括一个标记建议API(基于现有文本文档和标记)和一个推荐API,该API将类似的文档推荐给给定的文本文档。这使用了一种混合的方法,其中相关性是根据文本内容和用户行为决定的。
请注意,一些平台还提供数据注释服务,以帮助创建专有模型(例如,谷歌有一个众包数据标签服务)。如果您选择的平台没有这样的服务,则有专用的数据注释平台,如图8所示。
高级PaaS
作为服务的平台是最容易使用的,因为不需要安装,也不需要担心基础设施。高级功能包括:
- 问题类型的自动检测(例如,分类或回归)
- 数据的自动准备(如分类变量的编码、归一化、特征选择等)。
- 学习算法的自动化配置(具有元学习和超参数智能搜索的自动化)
这些平台对不太了解ML算法的人特别有用,领域专家或软件开发人员也可以访问它们。可以说,它们对数据科学家也很有用,因为它们允许更快的实验和更少的错误。这反过来又允许我们关注在从数据中学习之前和之后发生的所有事情——这在实践中是最重要的:收集ml准备好的数据,评估预测,并在软件中使用它们。
BigML
BigML是一个平台,它为分类和回归(决策树、随机森林、增强树、神经网络、线性和逻辑回归)提供了各种内置算法,这些算法支持数字特性、分类特性以及文本特性。它还提供了非监督学习算法(使用K-means和G-means聚类,使用隔离森林的异常检测,PCA,主题建模)和时间序列预测(指数平滑)。它的“优化”功能实现了自动化技术,可以在给定的时间预算内为给定的训练集、验证/测试集和性能度量找到最佳模型。它的“融合”功能创建了模型集合。
检查BigML自动创建的神经网络,带有交互式部分依赖图
BigML API允许用户在BigML云基础设施上大规模查询预测和触发模型训练。让我们假设BIGML_AUTH是一个包含BigML用户名和API密钥的环境变量。以下是调用API对给定的训练和测试数据集(通过其id识别)使用OptiML的方法,以最大化接受者操作特征(ROC)曲线(AUC)下的面积:
$ curl https://bigml.io/optiml?$BIGML_AUTH -d '{"dataset": "<training_dataset_id>", "test_dataset": "<test_dataset_id>", "metric": "area_under_roc_curve", "max_training_time": 3600 }'
该请求是异步的,将返回一个OptiML id。在一个小时(3600秒)后,可以点击API来获取创建的OptiML对象的信息,特别是包含为数据集找到的最佳模型的id的摘要。然后可以要求从这个模型进行预测:
$ MODEL_ID = curl https://bigml.io/optiml/<optiml_id>?$BIGML_AUTH | jq -r ".optiml.summary.model.best"$ curl https://bigml.io/predict?$BIGML_AUTH -d '{"model": "'"$MODEL_ID"'", "input_data": {"text": "I will never stay in this hotel again"}}'
BigML可能是本节介绍的平台中最容易使用的,但也是最不灵活的。ML实践者会发现缺失的功能,比如绘制学习曲线和使用自定义性能指标的能力。然而,BigML允许用户在他们的平台上用他们自己创建的称为WhizzML的语言执行脚本,这是一种专门用于机器学习的高级编程语言。这扩展了平台的功能。也是最封闭平台之一,因为它不与开源的,所以是有限的模型可以导出的格式,不可能导出脚本建模——然而,可以看到哪些算法和参数被用来创建一个模型。
谷歌的产品
谷歌AutoML表是一个beta版产品,与BigML有相似之处,但还不打算在关键应用程序中使用。它的UI更简单,而且该产品似乎更针对开发人员而不是领域专家。谷歌云推断API专注于时间序列预测。它是一个不包含UI的alpha产品,但更适合在生产中部署。
微软Azure ML
Microsoft Azure ML是一个MLaaS平台,提供了一个带有两个模型创作环境的工作室:自动化ML和设计器(以前称为“交互画布”)。该平台还可以将模型转换为可自动伸缩的预测api。设计者允许用户查看和可视化地编辑模型训练管道,即获取数据、准备数据和应用ML算法生成(和评估)预测模型的操作序列。通过避免接口捕获的潜在错误(例如,缺少数据操作的输入,或禁止的连接),设计器使理解管道变得更容易,但也使创建管道变得更容易。
微软Azure ML的设计师
Lobe
Lobe是微软于2018年收购的一项服务,它也提供交互式画布和自动功能,但也允许用户处理图像功能。它提供了一个易于使用的环境来自动建立神经网络模型,通过一个可视化的界面。模型是由可以完全控制的构件组成的(波瓣建立在TensorFlow和Keras之上);一些构建模块是预先训练的,这允许迁移学习。培训可以通过实时的交互式图表进行监控。训练好的模型可以通过开发人API提供,或者导出到Core ML和TensorFlow文件,在iOS和Android设备上运行。
图像和数字特征的ML模型的一系列操作的可视化编辑
自托管工作室
其他一些工作室也提供了不同名称的设计器——DataRobot称其为“蓝图”,Rapidminer和Dataiku称其为“工作流”——以及自动化功能。这里提到的ML开发平台被认为比以前的平台级别更低,因为它们不是“作为服务”提供的,需要安装并托管在我们自己的(集群)机器上。但是,它们具有在MLaaS产品中没有的有趣功能。
这些平台共有的一个共同点是它们都基于标准的开源ML库,并允许用户使用定制库和定制代码。它们允许用户将ML工作流/管道导出为Python脚本,并将经过训练的模型导出为各种开放格式,从而避免锁定。注意,上面提到的一些供应商还提供单独的部署和模型服务解决方案。
Dataiku
大泰库的数据科学工作室(DSS)有以下优势:
- 连接到许多类型的数据库。例如,数据源可以从CSV文件更改为Hadoop文件系统(HDFS) URI,而不需要更改ML管道的其余部分
- 可视化数据角力、特征工程和特征丰富,以改进数据,并帮助它在使用学习算法之前做好准备
- 提供内置算法的不同ML后端。例如,后端可以从scikit-learn更改为Spark MLlib,而不需要更改ML管道的其余部分
- 内置的聚类和异常检测算法
在Dataiku的数据科学工作室中比较MLlib模型的性能
DataRobot
DataRobot有以下优点:
- 自动功能工程
- 模型检查特征和预测解释的可视化
- 高级时间序列预测:几个内置算法(ARIMA, Facebook Prophet,梯度增强),回溯测试评估方法,平稳性自动检测,季节性,时间序列特征工程。
在DataRobot中的预测解释
H2O
H2O的无人驾驶人工智能与DataRobot类似。两者都有Python API。下面是对H2O Python API的start_experiment_sync方法的调用,它在精神上类似于BigML的HTTP API的OptiML方法:
params = h2oai.get_experiment_tuning_suggestion(
dataset_key=train.key,
target_col=target,
is_classification=True,
is_time_series=False,
config_overrides=None)experiment = h2oai.start_experiment_sync(
dataset_key=train.key,
testset_key=test.key,
target_col=target,
is_classification=True,
scorer='AUC',
accuracy=params['accuracy'],
time=params['time'],
interpretability=params['interpretability'],
enable_gpus=True,
seed=1234, # for reproducibility
cols_to_drop=['ID'])
云机器学习IDE
我们最后一种类型的模型开发平台可以看作是托管在云上的用于机器学习的集成开发环境(IDE)。这些平台不提供以前提供的ML studio的高级功能,但是它们可以从云计算中获益。对于机器和深度学习从业者来说,使用云平台提供的强大的、配置了gpu的虚拟机(VMs)进行实验是一种常见的做法。这些云vm在创建特定于ml的云平台之前就已经可用了。这些平台使得实验运行速度更快,而且如果需要的话,也很容易24/7地进行。这些平台还可以对多核cpu、具有大量RAM的强大gpu和已经配置好的集群(例如,用于分布式学习、并行调优超参数和使用深度神经网络)进行大规模实验。用户只为他们使用的东西付费;无需预付购买昂贵硬件的费用。
新的特定于ml的云平台允许在预先配置的基础设施上访问Jupyter实验室环境,即基于web的ide。它们为云vm提供所有公共开放源码ML库。通常包括TensorBoard web服务器,用于监控基于tensorflow的实验的进程。Cloud ML ide的目标是使vm的可用速度比其他云服务更快(通常从几分钟到几秒),并使在这些(短期)vm上完成的工作更方便持久化。
Floyd
Floyd是一个很好的入门平台,因为它使用起来没有竞争对手那么复杂,但是仍然提供了一些不同的选项来运行ML实验。它提供了两种类型的cpu和两种类型的gpu的访问,根据我们的需要进行选择。实验可以通过两种不同的方式进行:
- 工作区,这是一个基于Jupyter实验室的IDE,用于交互式实验。它还提供了对TensorBoard的访问,以及一个类似的称为Metrics的特性,可以与任何ML库(不一定是TensorFlow)一起使用,以监视模型训练的进度
- 作业,用于作为脚本运行较长的实验。作业是从安装在我们自己机器上的命令行接口(CLI)工具启动的,与本地执行脚本的方式相同,但它们是在Floyd平台上运行的。CLI还允许用户标记作业和下载输出。浏览作业的历史记录、使用标记进行筛选以及查看历史记录中的结果摘要,这些功能都满足了实验跟踪器的功能。
- 另一个有用的特性是能够在云平台上存储大型数据集并与整个团队共享,因此不需要在本地下载数据集并保持同步。Floyd的基础设施建立在亚马逊北美的公共云之上,但Floyd也可以安装在私有云和本地云上,这是它区别于谷歌和亚马逊产品的一个方面。
谷歌AI平台笔记本
谷歌AI平台笔记本类似于Floyd工作区。它使用了该平台的深度学习VM映像和它的云TPUs(张量处理单元)。它内置了Git支持,并与谷歌AI Hub集成。谷歌AI Hub可以帮助发现其他人在组织内构建的内容(比如笔记本、管道和模型),在开始新的开发之前应该检查这些内容。由于笔记本是谷歌云产品,它提供了访问预配置/预安装的谷歌云平台库,如Dataflow和Dataproc来进行数据争论。GPU可以添加到平台使用的云VM中,也可以从云VM中移除,而Floyd被限制为每个VM只有1个GPU。
AWS SageMaker
SageMaker是Amazon的ML平台,它提供了类似的开发环境,便于在分布式模型训练和分布式超参数调优实验中使用集群计算。SageMaker允许用户通过其Python API和字典数据结构定义用于训练和验证的数据集,用于训练算法的超参数值,以及用于运行作业的资源,来定义模型训练作业。
training_params = \
{
"AlgorithmSpecification": {
"TrainingImage": image, # specify the training docker image
"TrainingInputMode": "File"
},
"RoleArn": role,
"OutputDataConfig": {
"S3OutputPath": 's3://{}/{}/output'.format(bucket)
},
"ResourceConfig": {
"InstanceCount": 1,
"InstanceType": "ml.p3.2xlarge",
"VolumeSizeInGB": 50
},
"TrainingJobName": "model_a",
"HyperParameters": {
"image_shape": "3,224,224",
"num_layers": "18",
"num_training_samples": "15420",
"num_classes": "257",
"mini_batch_size": "128",
"epochs": "2",
"learning_rate": "0.2",
"use_pretrained_model": "1"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 360000
},
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": 's3://{}/train/'.format(bucket),
"S3DataDistributionType": "FullyReplicated"
}
},
"ContentType": "application/x-recordio",
"CompressionType": "None"
},
{
"ChannelName": "validation",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": 's3://{}/validation/'.format(bucket),
"S3DataDistributionType": "FullyReplicated"
}
},
"ContentType": "application/x-recordio",
"CompressionType": "None"
}
]
}
sagemaker.create_training_job(**training_params)
该平台还为各种ML任务提供了项目模板,包括一些高级任务,如序列到序列学习和强化学习。
Databricks
Databricks统一分析平台允许用户访问亚马逊或微软云平台上的集群计算。Databricks维护Apache Spark,这是一个领先的开源集群计算框架。该平台还允许访问Databricks的另一个开源框架MLflow,它有一个实验跟踪组件。MLflow被设计成可伸缩到大型数据集、大型输出文件(例如模型)和大量实验。它支持并行地启动多个运行(例如超参数调优)和在Spark上执行单独的运行。它可以从分布式存储系统中获取输入,并向分布式存储系统写入输出。
接下来的内容是:更多类型的ML平台和限制
我希望这篇文章使您相信模型开发平台的强大功能,并使您知道哪种类型最适合您。
在下一篇文章中,我将介绍其他类型的ML平台(部署的、垂直的、预先培训过的),我将提供一些技巧来帮助您为您的组织选择最佳的ML平台,我还将讨论这些平台的不足之处,以便构建真实的ML系统。跟随我得到通知!
原文:https://medium.com/@louisdorard/an-overview-of-ml-development-platforms-df953060b9a9
本文:http://jiagoushi.pro/node/1137
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】