hadoop生态
- 169 次浏览
「大数据」Hadoop生态系统:分布式文件系统
Apache HDFS
Hadoop分布式文件系统(HDFS)提供了一种在多台计算机上存储大型文件的方法。 Hadoop和HDFS源自Google文件系统(GFS)文件。 在Hadoop 2.0.0之前,NameNode是HDFS集群中的单点故障(SPOF)。 使用Zookeeper,HDFS高可用性功能通过提供在具有热备用的主动/被动配置中的同一群集中运行两个冗余NameNode的选项来解决此问题。
- hadoop.apache.org
- 谷歌文件系统 - GFS文件
- Cloudera为何选择HDFS
- Hortonworks为何选择HDFS
Red Hat GlusterFS
GlusterFS是一个横向扩展的网络附加存储文件系统。 GlusterFS最初由Gluster,Inc。开发,然后由Red Hat,Inc。在2011年购买Gluster后开发。2012年6月,Red Hat Storage Server被宣布为商业支持的GlusterFS与Red Hat Enterprise Linux的集成。 Gluster文件系统,现在称为Red Hat Storage Server。
- www.gluster.org
- Red Hat Hadoop插件
Quantcast文件系统
QFS QFS是一个开源的分布式文件系统软件包,适用于大规模MapReduce或其他批处理工作负载。它被设计为Apache Hadoop HDFS的替代品,旨在为大规模处理集群提供更好的性能和成本效益。它是用C ++编写的,具有固定占用内存管理。 QFS使用Reed-Solomon纠错作为确保可靠访问数据的方法。
Reed-Solomon编码在大容量存储系统中被广泛使用以校正与介质缺陷相关的突发错误。 QFS不是存储每个文件的三个完整版本(如HDFS),而是需要三倍的存储空间,因此它只需要1.5倍的原始容量,因为它会跨九个不同的磁盘驱动器对数据进行条带化。
- QFS网站
- GitHub QFS
- HADOOP-8885
Ceph Filesystem
Ceph是一个免费的软件存储平台,旨在从单个分布式计算机集群中呈现对象,块和文件存储。 Ceph的主要目标是完全分发,没有单点故障,可扩展到exabyte级别,并且可以自由使用。数据被复制,使其具有容错能力。
- Ceph文件系统站点
- Ceph和Hadoop
- HADOOP-6253
Lustre文件系统
Lustre文件系统是一种高性能的分布式文件系统,适用于大型网络和高可用性环境。传统上,Lustre被配置为管理存储区域网络(SAN)内的远程数据存储磁盘设备,SAN是通过小型计算机系统接口(SCSI)协议进行通信的两个或多个远程连接的磁盘设备。这包括光纤通道,以太网光纤通道(FCoE),串行连接SCSI(SAS)甚至iSCSI。
使用Hadoop HDFS,该软件需要一个专用的计算机集群来运行。但是,为其他目的运行高性能计算集群的人通常不会运行HDFS,这会使他们拥有一堆计算能力,这些任务几乎肯定会受益于一些地图缩减,并且无法将这些功能用于运行Hadoop的。英特尔注意到了这一点,并且在其上周悄然发布的Hadoop发行版2.5版本中增加了对Lustre的支持:用于Apache Hadoop *软件的英特尔®HPC分发,这是一款将英特尔分布式Apache Hadoop软件与英特尔®结合的新产品适用于Lustre软件的企业版。这是与Lustre集成的唯一Apache Hadoop发行版,Lustre是许多世界上最快的超级计算机1使用的并行文件系统.
- wiki.lustre.org /
- 带有Lustre的Hadoop
- 英特尔HPC Hadoop
Alluxio
Alluxio是世界上第一个以内存为中心的虚拟分布式存储系统,它统一了数据访问并桥接了计算框架和底层存储系统。应用程序只需与Alluxio连接即可访问存储在任何底层存储系统中的数据。此外,Alluxio以内存为中心的架构使数据访问速度比现有解决方案快几个数量级。
在大数据生态系统中,Alluxio介于计算框架或作业(如Apache Spark,Apache MapReduce或Apache Flink)和各种存储系统(如Amazon S3,OpenStack Swift,GlusterFS,HDFS,Ceph或OSS)之间。 Alluxio为堆栈带来了显着的性能提升;例如,百度使用Alluxio将其数据分析性能提高了30倍。除了性能之外,Alluxio还将新工作负载与存储在传统存储系统中的数据相结合。用户可以使用其独立群集模式运行Alluxio,例如在Amazon EC2上运行,或者使用Apache Mesos或Apache Yarn启动Alluxio。
Alluxio兼容Hadoop。这意味着现有的Spark和MapReduce程序可以在Alluxio之上运行而无需更改任何代码。该项目是开源的(Apache License 2.0),并在多家公司部署。它是增长最快的开源项目之一。 Alluxio拥有不到三年的开源历史,吸引了来自50多家机构的160多名贡献者,包括阿里巴巴,Alluxio,百度,CMU,IBM,英特尔,NJU,红帽,加州大学伯克利分校和雅虎。该项目是Berkeley Data Analytics Stack(BDAS)的存储层,也是Fedora发行版的一部分。
- Alluxio网站
GridGain
GridGain是在Apache 2.0下获得许可的开源项目。该平台的主要部分之一是内存中的Apache Hadoop加速器,旨在通过将数据和计算都带入内存来加速HDFS和Map / Reduce。这项工作是通过GGFS-Hadoop兼容的内存文件系统完成的。对于I / O密集型作业,GridGain GGFS的性能比标准HDFS快近100倍。从GridGain Systems转述Dmitriy Setrakyan谈论有关Tachyon的GGFS:
GGFS允许对底层HDFS或任何其他Hadoop兼容文件系统进行直读和写入,而无需更改代码。从本质上讲,GGFS完全从集成中删除了ETL步骤。
GGFS能够选择和保留内存中的文件夹,光盘上的文件夹,以及同步或异步与底层(HD)FS同步的文件夹。
GridGain正致力于添加原生MapReduce组件,该组件将提供本机完整的Hadoop集成而无需更改API,就像Spark目前强迫您做的那样。基本上,GridGain MR + GGFS将允许以即插即用的方式将Hadoop完全或部分内存,而无需任何API更改。
- GridGain网站
XtreemFS
XtreemFS是一个通用存储系统,可满足单个部署中的大多数存储需求。它是开源的,不需要特殊的硬件或内核模块,可以安装在Linux,Windows和OS X上.XtreemFS运行分布式并通过复制提供弹性。 XtreemFS卷可以通过FUSE组件访问,该组件提供与POSIX类似语义的正常文件交互。此外,还包含Hadoops FileSystem接口的实现,使XtreemFS可以与Hadoop,Flink和Spark一起使用。 XtreemFS根据新BSD许可证授权。 XtreemFS项目由柏林Zuse研究所开发。该项目的开发由欧盟委员会自2006年以来根据拨款协议No. FP6-033576,FP7-ICT-257438和FP7-318521以及德国项目MoSGrid,“First We Take Berlin”,FFMK, GeoMultiSens和BBDC。
- XtreemFS站点
- 在XtreemFS上进行Flink。
- Spark XtreemFS
- 77 次浏览
「大数据」Hadoop生态系统:分布式计算系统
Apache Ignite
Apache Ignite In-Memory Data Fabric是一个分布式内存平台,用于实时计算和处理大规模数据集。它包括分布式键值内存存储,SQL功能,map-reduce和其他计算,分布式数据结构,连续查询,消息和事件子系统,Hadoop和Spark集成。 Ignite是用Java构建的,提供.NET和C ++ API。
- Apache Ignite
- Apache Ignite文档
Apache MapReduce
MapReduce是一种编程模型,用于在群集上使用并行分布式算法处理大型数据集。 Apache MapReduce源自Google MapReduce:大群集上的简化数据处理。当前的Apache MapReduce版本是基于Apache YARN Framework构建的。 YARN代表“Yet-Another-Resource-Negotiator”。它是一个新的框架,有助于编写任意分布式处理框架和应用程序。 YARN的执行模型比早期的MapReduce实现更通用。与原始的Apache Hadoop MapReduce(也称为MR1)不同,YARN可以运行不遵循MapReduce模型的应用程序。 Hadoop YARN试图将Apache Hadoop超越MapReduce进行数据处理。
- Apache MapReduce
- 谷歌MapReduce论文
- 编写YARN应用程序
Apache Pig
Pig提供了一个在Hadoop上并行执行数据流的引擎。它包括一种用于表达这些数据流的语言Pig Latin。 Pig Latin包含许多传统数据操作(连接,排序,过滤等)的运算符,以及用户开发自己的读取,处理和写入数据的功能。猪在Hadoop上运行。它利用了Hadoop分布式文件系统,HDFS和Hadoop的处理系统MapReduce。
Pig使用MapReduce来执行其所有数据处理。它编译Pig Latin脚本,用户将其写入一系列一个或多个MapReduce作业,然后执行它们。 Pig Latin看起来与您看到的许多编程语言不同。 Pig Latin中没有if语句或for循环。这是因为传统的过程和面向对象的编程语言描述了控制流,而数据流是程序的副作用。 Pig Latin专注于数据流。
- 1. pig.apache.org/
- 2.Pig examples by Alan Gates
JAQL
JAQL是一种功能性的声明性编程语言,专门用于处理大量结构化,半结构化和非结构化数据。顾名思义,JAQL的主要用途是处理存储为JSON文档的数据,但JAQL可以处理各种类型的数据。例如,它可以支持XML,逗号分隔值(CSV)数据和平面文件。 “JAQL中的SQL”功能允许程序员使用结构化SQL数据,同时使用JSON数据模型,该模型的限制性比结构化查询语言对应项更少。
具体来说,Jaql允许您选择,加入,分组和过滤存储在HDFS中的数据,就像Pig和Hive的混合一样。 Jaql的查询语言受到许多编程和查询语言的启发,包括Lisp,SQL,XQuery和Pig。
JAQL由IBM研究实验室的工作人员于2008年创建,并发布给开源。虽然它继续作为Google Code上的项目托管,其中可下载的版本在Apache 2.0许可下可用,但围绕JAQL的主要开发活动仍然以IBM为中心。该公司提供查询语言作为与InfoSphere BigInsights及其Hadoop平台相关联的工具套件的一部分。与工作流协调器一起使用,BigInsights中使用JAQL在存储,处理和分析作业之间交换数据。它还提供外部数据和服务的链接,包括关系数据库和机器学习数据。
- Google Code中的JAQL
- 什么是Jaql?byIBM
Apache Spark
数据分析集群计算框架最初是在加州大学伯克利分校的AMPLab中开发的。 Spark适用于Hadoop开源社区,构建于Hadoop分布式文件系统(HDFS)之上。但是,Spark为Hadoop MapReduce提供了一种更易于使用的替代方案,并且在某些应用程序中,其性能比Hadoop MapReduce等上一代系统快10倍。
Spark是一个用于编写快速分布式程序的框架。 Spark解决了与Hadoop MapReduce类似的问题,但具有快速的内存方法和干净的功能样式API。凭借其与Hadoop和内置工具集成的交互式查询分析(Shark),大规模图形处理和分析(Bagel)以及实时分析(Spark Streaming)的能力,它可以交互式地用于快速处理和查询大型数据集。
为了加快编程速度,Spark在Scala,Java和Python中提供了简洁,简洁的API。您还可以从Scala和Python shell以交互方式使用Spark来快速查询大数据集。 Spark也是Shark背后的引擎,Shark是一个完全与Apache Hive兼容的数据仓库系统,运行速度比Hive快100倍。
- Apache Spark
- Mirror of Spark on Github
- RDDs - Paper
- Spark: Cluster Computing... - Paper Spark Research
Apache Storm
Storm是一个复杂的事件处理器(CEP)和主要以Clojure编程语言编写的分布式计算框架。是一种分布式实时计算系统,用于处理快速,大量的数据流。 Storm是一种基于主工作者范式的架构。因此,Storm集群主要由主节点和工作节点组成,由Zookeeper协调完成。
Storm使用zeromq(0mq,zeromq),这是一个先进的可嵌入网络库。它提供了一个消息队列,但与面向消息的中间件(MOM)不同,0MQ系统可以在没有专用消息代理的情况下运行。该库旨在具有熟悉的套接字式API。
该项目最初由Nathan Marz和BackType团队创建,该项目在被Twitter收购后开源。 Storm最初是在2011年在BackType开发和部署的。经过7个月的开发,BackType于2011年7月被Twitter收购.Storm于2011年9月开源。
Hortonworks正在开发Storm-on-YARN版本,计划在2013年第四季度完成基础级集成。这是Hortonworks的计划。 Yahoo / Hortonworks还计划在不久的将来将github.com/yahoo/storm-yarn上的Storm-on-YARN代码转移到Apache Storm项目的子项目中。
Twitter最近发布了一款名为“Summingbird”的Hadoop-Storm Hybrid.Summingbird将这两个框架融合为一体,允许开发人员使用Storm进行短期处理,使用Hadoop进行深度数据潜水。旨在通过将批处理和流处理组合成混合系统来减轻批处理和流处理之间的权衡的系统。
- Storm Project/
- Storm-on-YARN
Apache Flink
Apache Flink(以前称为Stratosphere)在Java和Scala中具有强大的编程抽象,高性能运行时和自动程序优化。它具有对迭代,增量迭代和由大型DAG操作组成的程序的本机支持。
Flink是一个数据处理系统,是Hadoop MapReduce组件的替代品。它带有自己的运行时,而不是构建在MapReduce之上。因此,它可以完全独立于Hadoop生态系统工作。但是,Flink还可以访问Hadoop的分布式文件系统(HDFS)来读取和写入数据,以及Hadoop的下一代资源管理器(YARN)来配置群集资源。由于大多数Flink用户使用Hadoop HDFS来存储他们的数据,因此它已经提供了访问HDFS所需的库。
- Apache Flink incubator page
- Stratosphere site
Apache Apex
Apache Apex是一个基于Apache YARN的企业级大数据动态平台,它统一了流处理和批处理。它以高度可扩展,高性能,容错,有状态,安全,分布式和易于操作的方式处理大数据。它提供了一个简单的API,使用户能够编写或重用通用Java代码,从而降低编写大数据应用程序所需的专业知识。
Apache Apex-Malhar是Apache Apex平台的补充,它是一个运营商库,可实现希望快速开发应用程序的客户所需的通用业务逻辑功能。这些运营商提供对HDFS,S3,NFS,FTP和其他文件系统的访问; Kafka,ActiveMQ,RabbitMQ,JMS和其他消息系统; MySql,Cassandra,MongoDB,Redis,HBase,CouchDB和其他数据库以及JDBC连接器。该库还包括许多其他常见的业务逻辑模式,可帮助用户显着减少投入生产所需的时间。易于与所有其他大数据技术集成是Apache Apex-Malhar的主要任务之一。
GitHub上提供的Apex是DataTorrent商业产品DataTorrent RTS 3以及其他技术(如数据摄取工具dtIngest)所基于的核心技术。
- Apache Apex from DataTorrent
- Apache Apex main page
- Apache Apex Proposal
Netflix PigPen
PigPen是针对Clojure的map-reduce,它编译为Apache Pig。 Clojure是Rich Hickey创建的Lisp编程语言的方言,因此是一种功能通用语言,可在Java虚拟机,公共语言运行时和JavaScript引擎上运行。在PigPen中,没有特殊的用户定义函数(UDF)。定义Clojure函数,匿名或命名,并像在任何Clojure程序中一样使用它们。该工具由美国按需互联网流媒体提供商Netflix公司开源。
- GitHub上的PigPen
AMPLab SIMR
Apache Spark是在Apache YARN中开发的。但是,到目前为止,在Hadoop MapReduce v1集群上运行Apache Spark相对比较困难,即没有安装YARN的集群。通常,用户必须获得在某些机器子集上安装Spark / Scala的权限,这个过程可能非常耗时。 SIMR允许任何有权访问Hadoop MapReduce v1集群的人开箱即用。用户可以直接在Hadoop MapReduce v1之上运行Spark,而无需任何管理权限,也无需在任何节点上安装Spark或Scala。
- GitHub上的SIMR
Facebook Corona
“Map-Reduce的下一个版本”,基于自己的Hadoop分支。当前的MapReduce技术的Hadoop实现使用单个作业跟踪器,这会导致非常大的数据集出现扩展问题.Apache Hadoop开发人员有他们正在创建他们自己的下一代MapReduce,名为YARN,由于公司部署Hadoop和HDFS的高度定制化特性,Facebook工程师对此进行了评估,但是折扣也很明显。像YARN一样,Corona产生了多个工作跟踪器(每个工作一个,在Corona的案例中.
- 在Github上的Corona
Apache REEF
Apache REEF™(可保留评估程序执行框架)是一个用于为Apache Hadoop™YARN或Apache Mesos™等集群资源管理器开发可移植应用程序的库。 Apache REEF通过以下功能大大简化了这些资源管理器的开发:
集中控制流程:Apache REEF将分布式应用程序的混乱转变为单个机器中的事件,即作业驱动程序。事件包括容器分配,任务启动,完成和失败。对于失败,Apache REEF尽一切努力使任务抛出的实际“异常”可用于驱动程序。
任务运行时:Apache REEF提供名为Evaluator的Task运行时。评估器在REEF应用程序的每个容器中实例化。评估者可以将数据保存在任务之间的内存中,从而在REEF上实现高效的管道。
支持多个资源管理器:Apache REEF应用程序可以轻松地移植到任何受支持的资源管理器。此外,REEF中的新资源管理器很容易支持。
.NET和Java API:Apache REEF是在.NET中编写YARN或Mesos应用程序的唯一API。此外,单个REEF应用程序可以自由混合和匹配为.NET或Java编写的任务。
插件:Apache REEF允许插件(称为“服务”)扩充其功能集,而不会向核心添加膨胀。 REEF包括许多服务,例如任务MPI启发的组通信(广播,减少,收集,...)和数据入口之间基于名称的通信。
- Apache REEF网站
Apache Twill
Twill是ApacheHadoop®YARN的抽象,它降低了开发分布式应用程序的复杂性,使开发人员能够更专注于业务逻辑。 Twill使用一个简单的基于线程的模型,Java程序员会发现它很熟悉。 YARN可以被视为集群的计算结构,这意味着像Twill这样的YARN应用程序可以在任何Hadoop 2集群上运行。
YARN是一个开源应用程序,它允许Hadoop集群变成一组虚拟机。 Weave由Continuuity开发,最初位于Github上,是一个互补的开源应用程序,它使用类似于Java线程的编程模型,可以轻松编写分布式应用程序。为了消除与Apache上类似命名的项目(名为“Weaver”)的冲突,Weave的名称在转移到Apache孵化时更改为Twill。
斜纹作为扩展代理。 Twill是YARN和YARN上任何应用程序之间的中间件层。在开发Twill应用程序时,Twill处理YARN中的API,类似于Java熟悉的多线程应用程序。在Twill中构建多处理的分布式应用程序非常容易。
- Apache Twill Incubator
Damballa
Parkour图书馆使用LISP语言Clojure开发MapReduce程序。 Parkour旨在为Hadoop提供深入的Clojure集成。使用Parkour的程序是普通的Clojure程序,使用标准的Clojure函数而不是新的框架抽象。使用Parkour的程序也是完整的Hadoop程序,可以在原始Java Hadoop MapReduce中完全访问所有可能的内容。 1.跑酷GitHub项目
Apache Hama
Apache顶级开源项目,允许您在MapReduce之外进行高级分析。许多数据分析技术(如机器学习和图形算法)都需要迭代计算,这就是批量同步并行模型比“普通”MapReduce更有效的地方。
- Hama site
Datasalt Pangool
一种新的MapReduce范例。用于MR作业的新API,其级别高于Java。
- Pangool
- GitHub Pangool
Apache Tez
Tez是一个开发通用应用程序的提案,该应用程序可用于处理复杂的数据处理任务DAG,并在Apache Hadoop YARN上本机运行。 Tez将MapReduce范例概括为基于将计算表示为数据流图的更强大的框架。 Tez并不直接面向最终用户 - 实际上它使开发人员能够以更好的性能和灵活性构建最终用户应用程序。传统上,Hadoop是一个用于处理大量数据的批处理平台。但是,查询处理的近实时性能有很多用例。还有一些工作负载,例如机器学习,它们不适合MapReduce范例。 Tez帮助Hadoop解决这些用例问题。 Tez框架构成了Stinger计划的一部分(基于Hive的Hadoop基于低延迟的SQL类型查询接口)。
- Apache Tez孵化器
- Hortonworks Apache Tez页面
Apache DataFu
DataFu基于它提供了更高级语言的Hadoop MapReduce作业和函数的集合,以执行数据分析。它提供常见统计任务(例如分位数,采样),PageRank,流会话以及集合和包操作的功能。 DataFu还为MapReduce中的增量数据处理提供Hadoop作业。 DataFu是最初在LinkedIn开发的Pig UDF(包括PageRank,会话,集合操作,抽样等等)的集合。
- DataFu Apache孵化器
Pydoop
Pydoop是一个用于Hadoop的Python MapReduce和HDFS API,它基于C ++管道和C libhdfs API,允许编写具有HDFS访问权限的完整MapReduce应用程序。 Pydoop与Hadoop内置的Python编程解决方案相比有几个优点,即Hadoop Streaming和Jython:它是一个CPython包,它允许您访问所有标准库和第三方模块,其中一些可能不可用。
- SF Pydoop网站
- Pydoop GitHub项目
Kangaroo
来自Conductor的Kangaroo开源项目,用于编写消耗Kafka数据的MapReduce作业。介绍性帖子通过使用HFileOutputFormat的MapReduce作业解释了Conductor从Kafka到HBase的用例加载数据。与其他限制为每个Kafka分区的单个InputSplit的解决方案不同,Kangaroo可以在单个分区的流中以不同的偏移量启动多个消费者,以提高吞吐量和并行性。
- Kangaroo Introduction
- Kangaroo GitHub Project
TinkerPop
用Java编写的TinkerPop Graph计算框架。提供图形系统供应商可以实现的核心API。有各种类型的图形系统,包括内存中的图形库,OLTP图形数据库和OLAP图形处理器。实现核心接口后,可以使用图形遍历语言Gremlin查询基础图形系统,并使用启用TinkerPop的算法进行处理。对于许多人来说,TinkerPop被视为图形计算社区的JDBC。
- Apache Tinkerpop提案
- TinkerPop网站
Pachyderm MapReduce
Pachyderm是一款全新的MapReduce引擎,构建于Docker和CoreOS之上。在Pachyderm MapReduce(PMR)中,作业是Docker容器(微服务)中的HTTP服务器。您为Pachyderm提供Docker镜像,它将自动在整个群集中将其分发到您的数据旁边。数据通过HTTP发布到容器,结果存储回文件系统。您可以使用您想要的任何语言实现Web服务器并提取任何库。 Pachyderm还为系统中的所有作业及其依赖项创建DAG,并自动调度管道,使得每个作业在依赖关系完成之前不会运行。 Pachyderm中的所有东西都“在差异中说话”,因此它确切地知道哪些数据已经改变以及管道的哪些子集需要重新运行。 CoreOS是一个基于Chrome OS的开源轻量级操作系统,实际上CoreOS是Chrome OS的一个分支。 CoreOS仅提供在软件容器内部署应用程序所需的最少功能,以及用于服务发现和配置共享的内置机制
- Pachyderm站点
- Pachyderm介绍文章
Apache Beam
Apache Beam是一个开源的统一模型,用于定义和执行数据并行处理管道,以及一组特定于语言的SDK,用于构建管道和运行时特定的Runner以执行它们。
Beam背后的模型源于许多内部Google数据处理项目,包括MapReduce,FlumeJava和Millwheel。 该模型最初被称为“数据流模型”,最初实现为Google Cloud Dataflow,包括用于编写管道的GitHub上的Java SDK和用于在Google Cloud Platform上执行它们的完全托管服务。
2016年1月,Google和许多合作伙伴以Apache Beam(统一批量+ strEAM处理)的名义提交了数据流编程模型和SDK部分作为Apache孵化器提案。
- Apache Beam Proposal
- DataFlow Beam和Spark Comparasion
- 83 次浏览
【大数据】Hadoop死了吗?大数据分析的未来及其替代
QQ群
视频号

微信

微信公众号

知识星球
作为一个完整的开源大数据套件,Apache Hadoop在过去十年中深刻影响了整个大数据世界。然而,随着各种新兴技术的发展,Hadoop生态系统发生了巨大的变化。Hadoop真的死了吗?如果是,哪些产品/技术将取代它?大数据分析的未来前景如何?
本文将分析:
1.Hadoop的历史及其开源生态系统
2.云原生趋势下的新兴技术选择
3.未来10年大数据分析的未来展望
理解Hadoop:大数据简史及其作用
在过去的二十年里,我们一直生活在一个数据爆炸的时代。订单和仓储等传统业务中创建的数据量增长相对缓慢,在数据总量中的比例逐渐下降。
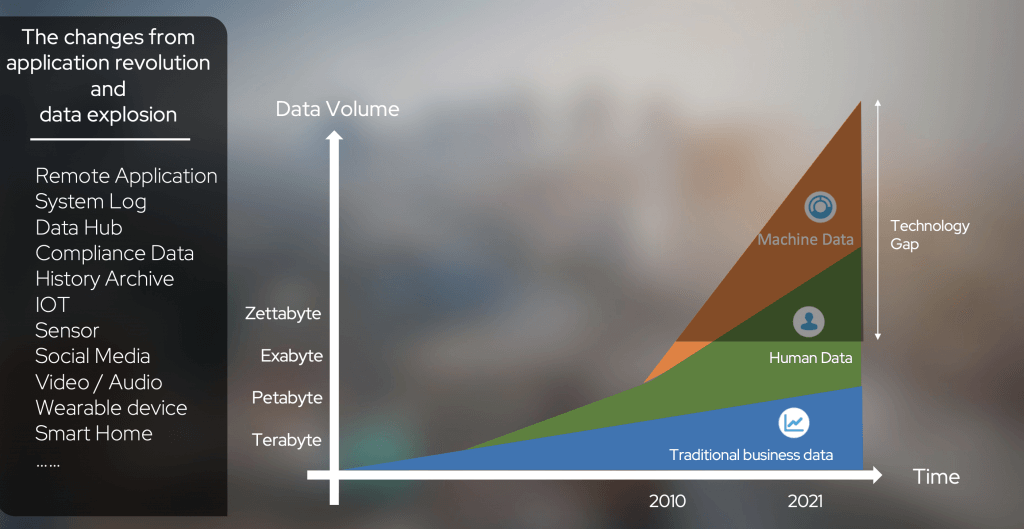
相反,大量的人类数据和机器数据(日志、物联网设备等)被收集和存储的数量远远超过了传统的商业数据。海量数据与人类能力之间存在着巨大的技术差距,催生了各种大数据技术。在这种背景下,我们所说的大数据时代已经形成。
2006年:Apache Hadoop在大数据处理领域的崛起
得益于“大数据”和有影响力的Apache开源软件项目社区,Hadoop迅速流行起来,并涌现出许多商业公司。
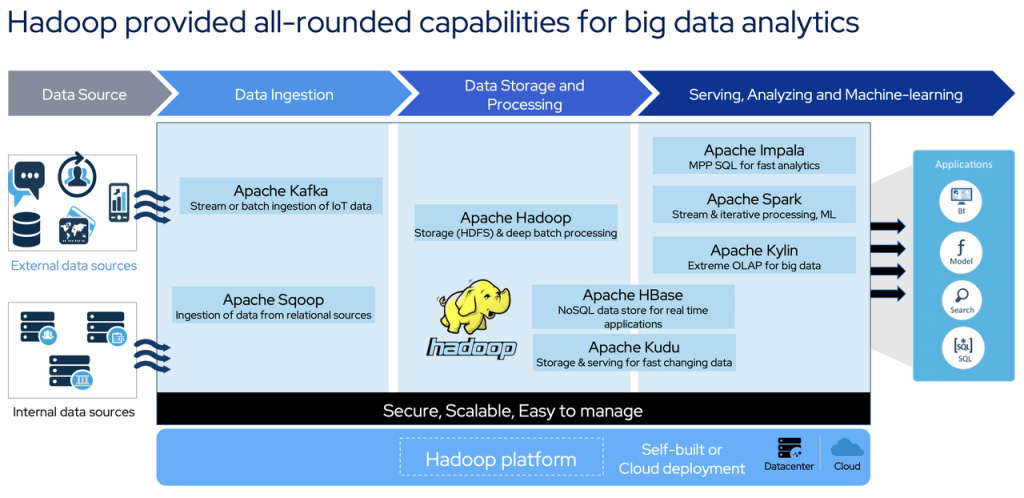
Hadoop就是这样一个功能齐全的大数据处理平台。它包含各种组件,以满足不同的功能要求,例如:
- 用于数据存储的HDFS
- 资源管理Yarn
- MapReduce和Spark用于数据计算和处理
- 用于关系数据收集的Sqoop
- 实时数据管道的Kafka
- 用于在线数据存储和访问的HBase
- 用于在线特别查询等的Impala。
Hadoop在诞生后不久就使用集群进行并行计算,打破了超级计算机保持的排序记录。它已被实力雄厚的公司和各种组织广泛采用。
市场上排名靠前的Hadoop分销商包括Cloudera、Hortonworks和MapR这三家供应商。此外,公共云供应商还在云上提供托管Hadoop服务,如AWS EMR、Azure HDinsight等,这些服务占据了Hadoop的大部分市场份额。
2018年:随着Cloudera和Hortonworks的合并,市场发生了变化
然而,在2018年,市场经历了剧烈的变化。一则震惊Hadoop生态系统的重大消息:Cloudera和Hortonworks合并。

Chirs Preinenerger和Daniel Newman的新闻
换句话说№1和№2 两个市场参与者相互拥抱以在市场中生存。随后,HPE宣布收购MapR。这些并购表明,尽管Hadoop非常受欢迎,但这些公司在运营中面临困难,很难赚钱。
在合并Hortonworks后,Cloudera宣布将对所有产品线收费,包括以前的开源版本。开源产品不再对所有用户开放,而是只对付费用户开放。
HDP发行版过去是免费的,现在不再维护和下载。它将来将合并为一个统一的CDP平台。
2021:观察Hadoop开源生态系统的衰落
2021年4月,Apache软件基金会宣布13个大数据相关项目退役,其中10个是Hadoop生态系统的一部分,如Eagle、Sentry、Tajo等。
现在,肩负着管理Hadoop集群使命的Apache Ambari成为2022年退役的第一个Apache项目。
2022年及以后:展望大数据的后Hadoop时代
Hadoop最终会被抛弃吗?我相信这不会很快发生。毕竟,Hadoop拥有大量用户,这意味着平台和应用程序迁移的成本过高。
因此,当前用户将继续使用它,但新用户的数量将逐渐减少。这就是我们所说的“后Hadoop时代”。

就Apache Hadoop的潜在增长而言,上述路线图取自Hadoop社区的一次会议。3.0之后,Hadoop的新特性显然不再那么好了。它们主要是关于与K8s和Docker的集成,这对大数据从业者来说没有那么大的吸引力。
是什么导致了Hadoop的衰落?
谷歌趋势显示,2014年至2017年,人们对Hadoop的兴趣达到了顶峰。在那之后,我们看到Hadoop的搜索量明显下降。Hadoop逐渐失去光环也就不足为奇了。任何技术都会经历发展、成熟和衰落的循环,任何技术都无法逃脱客观规律。
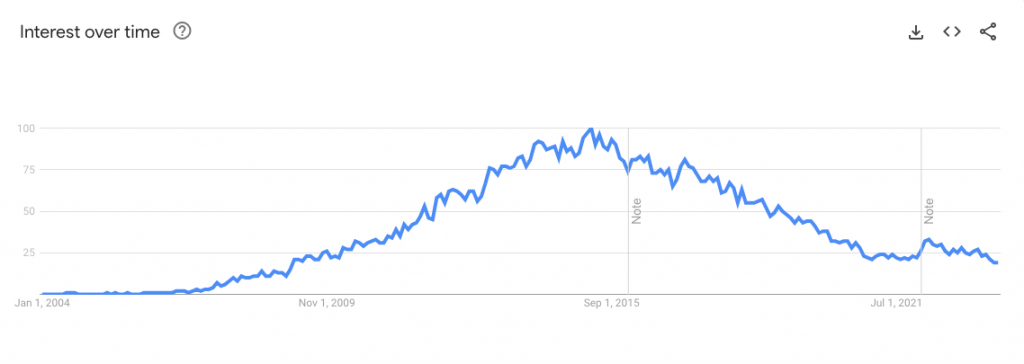
从Apache Hadoop及其生态系统的现状来看,有几个关键因素表明它最终会消亡。
数据分析和新兴技术的新市场需求
回顾Hadoop的发展历史,可以看出,软件框架的出现是因为对大数据存储的强烈需求。然而,在今天,用户对数据管理和分析有了新的需求,例如在线快速分析、存储和计算分离,或用于人工智能和机器学习的AI/ML。
在这些方面,Hadoop只能提供有限的支持。在这方面,它不能与一些新兴技术相比。比如Redis、Elastisearch、ClickHouse,这些都可以应用到大数据分析中。
对于客户来说,如果一项技术能够满足他们的需求,就不需要部署复杂的Hadoop平台。
快速增长的云供应商和服务对Hadoop相关性的影响
从另一个角度来看,云计算在过去十多年中发展迅速,不仅击败了IBM、HP等传统软件供应商,而且在一定程度上侵占了Hadoop的大数据市场。
早期,云供应商只在IaaS上部署Hadoop,例如AWS EMR(号称是世界上部署最多的Hadoop集群)。对于用户来说,云上托管的Hadoop服务可以随时启动和停止,数据可以在云供应商的数据服务平台上安全备份,使用方便,节省成本。
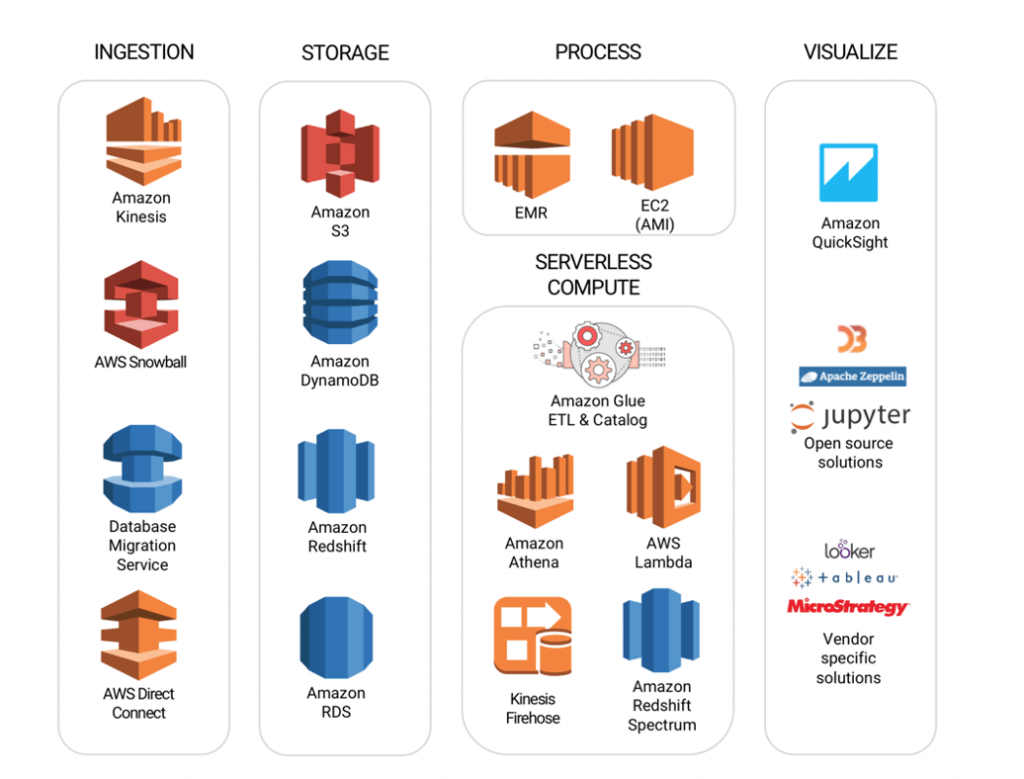
此外,云供应商为特定场景提供了一系列大数据服务,以形成一个完整的生态系统,如AWS S3实现的持久且低成本的数据存储、KV数据存储,以及Amazon DynamoDB实现的低延迟访问、分析大数据的无服务器查询服务Athena等。
检查Hadoop生态系统日益复杂的情况
除了不断提供新服务的新兴技术和云供应商,Hadoop本身也逐渐表现出“疲劳”。积木是一个不错的选择。然而,这增加了用户使用Hadoop生态系统组件的难度。
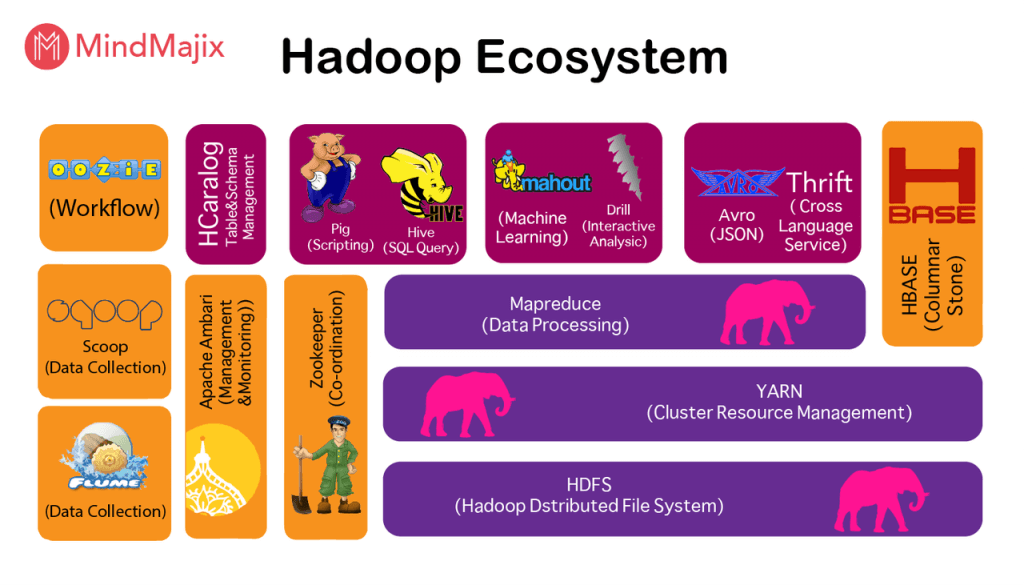
从上图中可以看出,Hadoop中已经有13个(如果不是更多的话)常用组件,这对Hadoop用户的学习和运维构成了巨大的挑战。
Cloudera和Hortonworks战略对Hadoop流行的影响

技术供应商Cloudera/Holtonworks无法在市场上发布高质量的免费产品。事实证明,他们早期的“免费版+付费版”双管齐下的方法行不通。Cloudera未来将只提供付费版的CDP,这标志着免费午餐的结束。目前还不知道其他制造商是否愿意提供免费产品。即使有这样一家制造商,其产品的稳定性和先进性仍然未知。毕竟,Hadoop的核心开发人员大多在Cloudera和Hortonworks工作。
Hadoop开源生态系统的不一致性分析
不要忘记Hadoop是Apache基金会托管的一个开源项目。Apache是为公共利益而设计的,公众可以免费获得、使用和分发。因此,如果你不想为此付费,有一个名为ApacheHadoop的选项可以免费使用。毕竟,大量的互联网公司仍然使用Apache Hadoop(按照他们的规模,只能使用开源版本)。如果他们可以,为什么我不能?
然而,开源软件质量一般,没有服务,也没有SLA保证。用户只能自己发现并解决问题。他们必须在社区中发布问题并等待结果。如果你对此没意见,那就雇佣几个工程师来尝试一下。顺便说一句,Hadoop开发或运维工程师很难雇佣,而且成本高昂。
超越Hadoop:探索大数据的替代解决方案
在后Hadoop时代,用户应该如何面对转型,他们可以选择什么?这完全取决于你有多少预算和你的技术能力。
后Hadoop市场技术供应商的关键成功因素
Hadoop生态系统中的供应商应该如何应对新时代?Apache Kylin和Kyligence的进化史就是一个很好的例子。
ApacheKylin项目和Kyligence都诞生于Hadoop时代。最初,所有Kyligence产品都运行在Hadoop上。大约4年前,Kyligence预见到客户需求正在慢慢转向云原生以及存储和计算的分离。
看到了这样的行业趋势,Kyligence对其原有的平台系统进行了大规模的改造。
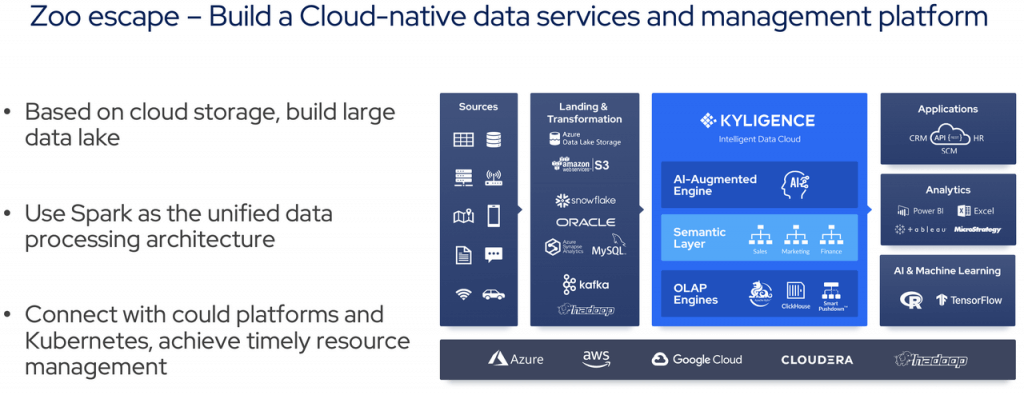
2019年,Kyligence推出了Kyligence Cloud,并宣布脱离Hadoop平台。Kyligence Cloud在底层使用云原生架构,云供应商的对象存储服务,如AWS S3、ADLS等用于存储,Spark+容器化用于计算。它的资源可以直接连接到云平台上的IaaS服务和ECS。Kyligence不断扩展到多个云,并对架构进行微调,并于2021年宣布将ClickHouse等新技术合并到架构中。
改造后的体系结构带来了巨大的灵活性、可维护性和低TCO,并得到了市场的积极反馈。
技术供应商的关键成功因素(KSF)是在捕捉趋势和产品转型方面都要非常快速、敏感和大胆。
大数据和分析市场,尤其是在北美,已经成为一个非常热门和竞争激烈的市场,拥有其他行业无法与之竞争的非常敬业的投资者。供应商始终关注市场趋势,倾听用户的意见,观察他们的新需求,并根据这些输入不断迭代您的产品,这是非常重要的。
大数据和分析的未来趋势
技术将不断进步,肩负新使命的初创公司可能会来来去去,大公司仍有韧性。我写了一篇关于7个必知数据流行语的博客,并讨论了2022年的新兴趋势。为了简短起见,我只列出一些(而不是全部)研究过的有趣趋势,并与您分享一些关于它们的好文章:
- Metrics Store will rise as the ultimate solution to keep the “single source of truth” - The missing piece of the modern data stack
- The design concept of Data Mesh will continue to influence IT decision-makers - Whitepaper: The Data Mesh Shift
- Data API/Data-as-a-product is an abstract but real demand from the market - Every product will be a data product; Big Data, Cloud, AI, and Data Analytics Predictions for 2022
大数据分析中Apache Hadoop常见问题解答
我们涵盖了客户在Hadoop上分析大数据时经常提出的关键问题
Hadoop在大数据分析中的用途是什么?
Apache Hadoop是一个开源软件框架,用于大型数据集的分布式存储和处理。Hadoop在大数据分析中的主要作用包括高效处理大量数据,提供可扩展性、容错性和经济高效的解决方案。Hadoop还可以促进高级分析,如预测分析、数据挖掘和机器学习。
Apache Hadoop的核心组件和用例是什么?
Apache Hadoop的核心组件包括用于数据存储的Hadoop分布式文件系统(HDFS)、用于处理的MapReduce和用于资源管理的YARN。其主要用例涉及处理和存储海量数据集,进行大规模数据分析,以及支持医疗保健、金融、零售和电信等行业的高级数据驱动应用程序。
- 45 次浏览