数据仓库架构
- 213 次浏览
【大数据仓库】用于医疗保健敏感数据应用程序的大数据仓库
QQ群
视频号

微信

微信公众号

知识星球
School of Computer Science, University College Dublin, Belfield, Dublin 4, Ireland
*Author to whom correspondence should be addressed.
Sensors 2021, 21(7), 2353; https://doi.org/10.3390/s21072353
Received: 8 March 2021 / Revised: 23 March 2021 / Accepted: 25 March 2021 / Published: 28 March 2021
(This article belongs to the Section Intelligent Sensors)
Abstract
肥胖是世界范围内的一个主要公共卫生问题,儿童肥胖的流行尤其令人担忧。预防和治疗儿童肥胖的有效干预措施旨在改变个人、社区和社会层面的行为和暴露。然而,监测和评估这些变化是非常具有挑战性的。欧盟地平线2020项目“儿童肥胖大数据(BigO)”旨在使用不同的传感器技术收集大量儿童的大规模数据,以创建全面的肥胖流行率模型,用于数据驱动的社区特定政策预测。它进一步提供了对人口反应的实时监测,并得到了有意义的实时数据分析和可视化的支持。由于BigO涉及监控和存储与潜在弱势群体行为相关的个人数据,因此数据表示、安全性和访问控制至关重要。在本文中,我们简要介绍了BigO系统架构,并重点介绍了系统中处理数据访问控制、存储、匿名化的必要组件,以及与系统其他部分的相应接口。我们提出了一种三层数据仓库架构:后端层由一个数据库管理系统组成,用于原始数据集的数据收集、去标识和匿名化。基于角色的权限和安全视图在访问控制层中实现。最后,控制器层调节用于任何数据访问和数据分析的数据访问协议。我们进一步提出了考虑隐私和安全机制的数据表示方法和存储模型。数据隐私和安全计划是根据收集的个人类型、用户类型、数据存储、数据传输和数据分析制定的。我们详细讨论了在这个大型分布式数据驱动应用程序中隐私保护的挑战,并实现了新的隐私感知数据分析协议,以确保所提出的模型保证数据集的隐私和安全。最后,我们介绍了BigO系统架构及其集成了隐私感知协议的实现。
Keywords:
big data representation; healthcare data; big data security; privacy-aware models
1. Introduction
随着全球收入流行率的上升,2016年,近7.8%、7.8%的男孩和5.6%、5.6%的女孩患有儿童肥胖[1]。由于肥胖是一个主要的全球公共卫生问题[2],对个人和整个社会都有重大的成本影响,因此必须采取强有力的措施来干预儿童肥胖。肥胖儿童容易经历一系列身体和心理社会健康问题[3]。肥胖也会导致儿童时期出现的2型糖尿病和冠心病等严重健康问题[4]。
在过去的二十年里,肥胖的病因在生物医学科学中得到了彻底的研究,即基因变异。然而,人们发现,人与人之间的基因变异可以解释近1.5%的体重指数(BMI)个体间变异[5]。现有的流行病学方法在很大程度上探讨了肥胖问题作为非传染性疾病的风险因素,但没有将其作为肥胖环境中行为的结果进行研究[6]。由于药物干预的可靠性和外科手术的侵入性不足,人们越来越依赖行为疗法。
针对儿童行为模式的各个方面的干预措施,如他们如何进食、如何移动、如何在环境中互动以及如何睡眠[7],可以对儿童肥胖产生积极影响[8,9]。不幸的是,大多数全球公共卫生行动仅限于不分青红皂白的“一揽子政策”,严重缺乏共同的监测和评估框架也于事无补[10]。
在过去的十年里,移动和可穿戴设备领域的进步催生了新一代的创新医疗保健研究[11]。SPLENDID欧盟项目[12]等创新努力突破了在日常生活中使用技术的界限,以筛查、监测和规范与肥胖进展相关的行为。与此同时,大数据收集、处理和分析领域的新成就使这些工作能够在更大范围内扩大,使公民能够积极参与重塑地区层面的卫生政策。大数据收集旨在探索行为、建筑环境和肥胖之间的因果关系。
可以利用行为改变科学、公共卫生、临床儿科、信息通信技术、公民科学和大数据分析领域的最新发展来实施多学科研究项目,以解决在人口层面预防和治疗儿童和青少年肥胖的问题。H2020项目“BigO:对抗儿童肥胖的大数据”(http://bigoprogram.eu,于2021年3月21日访问)就是此类研究工作的一个例子。BigO项目旨在重新定义欧洲社会针对儿童肥胖流行率的战略部署方式。这些新策略使用公民科学家数据收集方法,使用不同的移动技术(智能手机、腕带、测力计)收集大规模数据[13]。主要目标是创建肥胖流行率依赖矩阵的综合预测模型,以研究特定政策对社区的有效性和对人口反应的实时监测。公民科学家将数据上传到BigO云基础设施上,用于聚合、分析和可视化。BigO的大规模数据采集使研究人员能够通过与社区行为模式和当地肥胖率的关联,创建分析行为风险因素和预测肥胖率的模型。
由于BigO涉及监控和存储与潜在弱势群体(即儿童和青少年)行为相关的个人数据(膳食、饮料、食品和饮料广告的照片以及GPS数据),因此数据表示、安全和访问控制具有挑战性。在这项研究中,我们首先开发了BigO系统中处理数据访问和存储的必要组件,包括它们与其他系统组件接口的定义和实现。这大大促进了数据聚合、数据分析和可视化,同时维护了个人的数据隐私和整个系统的安全。更确切地说,我们为BigO开发了一个三层数据仓库体系结构。其包括后端层、访问控制层和控制器层。后端层由用于数据收集、去标识和匿名化的数据库管理系统组成。基于角色的权限和安全视图在访问控制层中实现。最后,控制器层对数据访问协议进行规范。
医疗保健部门的敏感个人数据共享受欧盟95/46/EC指令和美国HIPAA等规则和法律的监管[14,15]。两种常见的隐私保护方法:(a)征得患者同意,以及(b)个人数据的匿名化。第一种方法保持了分析结果的正确性,但耗时、不灵活,而且在从大量患者中收集数据时更容易发生数据泄露[16]。然而,匿名化方法更灵活,但会影响数据质量和分析;尤其是在高维数据的情况下[17]。
考虑到BigO数据的高度复杂性,我们首先介绍了考虑隐私和安全的数据表示模式和存储模型。数据隐私和安全计划是根据数据存储、数据传输和数据访问协议中收集的个人数据类型制定的。我们详细讨论了隐私保护的挑战,并为儿童隐私实施了高效的隐私感知数据分析协议。请注意,该系统旨在识别和忽略冗余的个人信息。最后,我们实现了集成了隐私感知协议的BigO系统架构。
本文的其余部分组织如下:第2节介绍了医疗保健数据分析的数据匿名化挑战和系统要求,以及现有的隐私意识架构。随后分别在第3节和第4节中概述了BigO系统和数据收集方法以及基于用户类型的数据流。在第5节中,我们介绍了BigO数据仓库体系结构和存储系统中的大数据表示。第6节讨论了BigO的安全和隐私考虑以及隐私感知数据分析协议。第7节专门讨论了系统实现以及隐私感知协议如何集成到系统体系结构中。在第8节中,我们讨论了我们工作的利弊,并强调了未来的研究方向。最后,第9节对论文进行了总结。
2. Healthcare Data Privacy
我们首先简要概述了数据驱动医疗系统中的数据匿名挑战,然后列出了医疗系统中个人数据监控、共享和分析的必要隐私和安全要求。我们进一步简要回顾了现有系统,并根据这些要求对其进行了评估。
2.1数据匿名和共享
典型医疗保健数据集中的数据属性(或维度)可根据其敏感性及其与受试者的关系分为四类;(1) 敏感、(2)非敏感、(3)可识别和(4)准可识别。表1显示,除了明确的敏感和可识别属性外,还有许多被称为准标识符的特征,可以组合起来识别特定的个体。保护敏感、可识别或准可识别数据的隐私是一项关键挑战。数据匿名化保持了将敏感信息与个人联系起来的低置信度阈值[18]。
表1.电子健康记录中的信息类型(I:可识别,Q-I:准可识别,S:敏感)。

由于数据共享,记录链接[18]和属性链接[19]是两种常用的主要攻击类型。这两种情况都可以使用隐私模型来防止,例如k-匿名[20]和ℓ-多样性[19]。这些隐私模型的一些扩展版本,包括(X,Y)−匿名、LKC−隐私
,和t−接近度[18]; 可以使用各种匿名操作来实现,如噪声添加、泛化、混洗和扰动(perturbation )[21]。然而,其中一些操作,包括扰动和单元泛化,会影响数据集的质量及其用于知识发现(通过挖掘算法)或信息检索的可用性。
2.2.医疗保健数据要求
以下是医疗保健数据集的必要要求,一方面应保护和保密,另一方面应能够进行分析,以提取有用的知识,从而推进医疗保健研究和实践。关键思想是创造一个环境,在不透露个人身份的情况下分析私人和敏感数据。
- 隐私:这主要在医疗保健领域至关重要。患者的记录及其数据属性非常容易受到攻击。因此,在共享医疗数据集时,必须建立保护机制,以保护患者和个人的隐私。
- 数据质量:高质量的数据对于数据挖掘和分析至关重要(因为没有质量的数据就没有质量的结果)。因此,共享数据应该保持良好的属性值,这些值足够详细,可以用于挖掘和分析的目的。人们还必须仔细考虑高维度的诅咒[17],并在个人记录水平上保持真实性。
- 灵活性:对于各种分析任务和挖掘技术,隐私保护应该足够灵活。理想的方法是实现独立于挖掘算法和研究目的的隐私保护解决方案。
- 兼容性:隐私保护模型应符合并支持系统参考体系结构。
- 实用性:提供一定程度的支持,使研究人员能够按照适当的访问控制和道德机制重新访问患者数据。
2.3. Existing Data Privacy-Enhancing Techniques
数据隐私是一个复杂而多维的概念,在现代已经成为一个严重的威胁。它是在法律、哲学和技术背景下定义的。个人信息隐私技术旨在解决有关个人隐私信息及其暴露的问题。图1提供了现有数据隐私技术的分类视图,这些技术处理数据匿名化和随机化,以确保敏感信息的隐私。
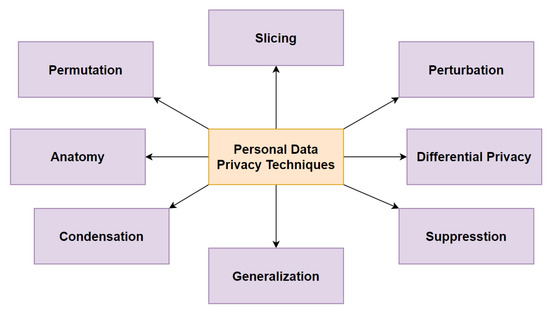
Figure 1. A taxonomy of personal data-privacy techniques. Adopted from [22].
现有的医疗保健系统(第2.4节)在存储、传输和处理等三个主要方面缺乏隐私感知协议的集成。一些理论框架引入了数据匿名化方法来维护个人隐私,但它们降低了数据分析任务的质量。
在下文中,我们将根据上述要求对现有框架进行审查和评估。
2.4.现有最先进医疗保健系统的比较分析
我们首先回顾了最近欧洲关于预防肥胖的研究项目。ToyBox[23]项目提出了全面、成本效益高、家庭参与的计划,以支持儿童早期的肥胖预防。MOODFOOD项目[24]通过观察患者的饮食、饮食行为和肥胖,探讨了抑郁症的预防。该项目研究了来自荷兰、英国、德国和西班牙的990多名参与者。该项目对患者的抑郁症病史和饮食习惯进行了相关性研究。研究结果表明,不健康的饮食活动是导致抑郁症的主要因素。欧盟项目SPOTLIGHT[25]进行了一项系统研究,以确定个人层面的肥胖干预因素。该项目审查了与肥胖相关的社会和环境因素的作用,并对多层次干预措施进行了定性分析,考虑了干预措施的范围、有效性、实施和采用。Daphne项目[26]开发了一个数据即服务的医疗保健平台,通过将技术平台与临床支持联系起来,解决健康、体重、体育活动和生活方式问题。应该注意的是,上述涉及肥胖预防的项目都没有提供隐私和安全意识协议来处理患者的敏感个人信息。
使用传感器技术收集个人数据对于理解和治疗肥胖等各种医疗保健问题很有价值。然而,随着传感器技术的快速增长,用户的活动和特征等敏感个人数据受到隐私威胁。《通用数据保护条例》(GDPR)[27]等一系列规则为公司如何通过实施隐私保护解决方案来收集和共享欧盟公民的个人数据提供了指导。为了遵守GDPR协议,获得用户同意至关重要,尤其是在医疗保健行业。Rantos等人[28]提出了ADvoCATE,以帮助用户控制与访问从传感器和可穿戴技术收集的个人数据相关的同意。所提出的解决方案还指导数据控制器和处理器满足GDPR的要求。Larrucea等人[29]介绍了适用于医疗保健行业的符合GDPR的架构参考模型和同意管理工具。作者在架构模型中发现了潜在的安全和隐私威胁,并使用数据隐藏工具来确保共享健康记录时的隐私。Mustafa等人[30]在GDPR的背景下对移动健康应用程序的隐私要求进行了全面审查,并评估了支持慢性阻塞性肺病(COPD)患者异常情况监测、早期诊断和检测的系统的隐私要求。
也进行了一些理论研究,提出在医疗保健环境中开发数据仓库架构。Sahama等人[31]提出了一种解决数据集成问题的数据仓库体系结构。作者强调,需要探索对数据仓库模型的安全访问,同时通过使用循证、基于案例和基于角色的数据结构来尊重医疗保健决策支持系统。Ali Fahem Neamah[32]提出了一种灵活且可扩展的数据仓库,用于构建电子健康记录架构。作者强调了该系统支持移动应用程序开发的一些问题,包括与大型平台和设备的兼容性。Poenaru等人[33]提出了用于医疗信息存储的数据仓库形式的高级解决方案,以解决一些问题,如复杂的数据建模特征、分类结构和数据集成。上述所有数据仓库解决方案都不考虑数据存储、访问和分析的任何隐私和安全问题。
除了通过获得GDPR投诉患者的同意来改进医疗系统中的数据收集和集成协议外,同样重要的是以安全和隐私意识的方式存储个人数据,而不会干扰执行定期分析任务的数据质量。因此,数据匿名化协议已经在许多医疗保健框架中实现。然而,在大数据领域;由于有几个属性,也可以被视为准标识符,数据匿名化变得不平凡,并导致大量信息丢失[17]。Sweeney等人[34]提出的Datafly使用数据接收器的配置文件和全球数据要求来执行数据匿名化。然而,由于Datafly是一个独立的程序,因此在医疗保健系统中的集成很困难。此外,它没有考虑属性链接攻击和高维诅咒。[35]中提出的Datafly扩展解决了隐私问题,但兼容性和数据质量保持不变。Agarwal等人[36]通过提供数据披露管理协议和服务提出了Hippocratic。该框架支持访问控制、匿名化和审计,但缺乏灵活性、隐私意识、数据质量和兼容性。当对各种分析任务进行评估时,由于匿名操作,如扰动和细胞泛化,Hippocratic在记录级别上失去了真实性,并导致错误的挖掘结果[18]。Prasser等人[37]提出了一种ARX框架,该框架通过实现隐私感知模型来解决隐私问题,但由于没有考虑高维度的影响而缺乏数据质量。
Nguyen等人[38]提出了电子健康记录(EHR)系统的隐私感知协议,该协议使用安全视图和高级中间件架构。Tran等人[39]提出了一种模型驱动的分布式体系结构,用于医疗保健数据存储和分析的安全性,该体系结构控制敏感数据的访问权限和分布式节点之间的传输控制。这两种策略是有效的,需要进一步研究。
2.5. Summary
医疗保健部门最近的研究重点是以数据收集的同意管理系统的形式开发符合GDPR的协议。现有最先进的医疗保健数据仓库系统解决了各种问题,如灵活性、可扩展性、数据集成和软件系统兼容性。然而,这些系统缺乏用于数据存储、访问和分析的隐私和安全感知协议的集成。许多框架已经引入了数据匿名化方法来维护个人隐私,但当对分析任务进行评估时,会产生不正确的挖掘结果。如果不考虑高维度的影响,数据质量会进一步降低。一些工作通过实现用于存储EHR的安全视图和访问控制,提出了隐私感知协议,但它们需要在现实世界的医疗环境中进行进一步调查。
总之,医疗保健数据仓库体系结构应该实现用于监控和存储个人数据的隐私感知协议。构建健康医疗数据集的主要目标包括数据保护和隐私,以及分析和挖掘有见地的知识以改进医疗研究和实践的适用性。换言之,数据驱动的医疗保健平台应努力开发一种环境,在这种环境中,可以在不透露个人身份的情况下分析私人和敏感数据。
BigO项目旨在收集学校和诊所25000多人的大规模数据,以制定有效的肥胖预防政策。这种大规模的个人数据收集、存储和处理需要进行研究和开发,以便在数据仓库架构中实现强大的隐私和安全协议和框架。在这项工作中,我们提出了一种三层数据仓库体系结构,包括:
- 具有数据库管理系统的后端层,用于原始数据集的数据收集、去标识和匿名化。
- 基于角色的权限和安全视图在访问控制层中实现。
- 控制器层调节用于任何数据访问和数据分析的数据访问协议。
我们进一步介绍了考虑隐私和安全机制的数据表示方法和存储模型。数据隐私和安全计划是根据收集的个人类型、用户类型、数据存储、数据传输和数据分析制定的。最后,我们介绍了BigO系统架构及其集成了隐私感知协议的实现。
3. BigO System—Overview
本节介绍了BigO的目标、数据来源和测量,以及相关的利益相关者,以了解儿童肥胖的原因。
BigO努力提供一个创新的系统,使公共卫生当局(PHA)能够根据其肥胖流行风险评估其社区,并根据客观证据采取当地行动。图2提供了BigO平台的概述。学校和诊所的儿童或青少年以公民科学家的身份参与,通过移动设备(手机或智能手表)的传感器提供数据。他们通过手机和/或智能手表应用程序、学校门户(通过教师)、临床门户(通过临床医生)和在线社区门户与系统交互。在线门户网站从BigO平台收集的数据中提供见解。他们还让学生们可视化数据的简单摘要,量化他们对BigO倡议的贡献,以及如何对抗肥胖。移动应用程序和门户网站既是数据收集器,也是参与机制,帮助用户贡献他们的数据,并了解他们的数据在这种情况下为什么以及如何有用。他们的数据用于测量与儿童肥胖相关的环境的行为指标和局部外在条件。为了测量LEC,数据还从公开的外部来源收集,如地图、地理信息系统(GIS)和统计机构服务。收集的信息使用BigO分析、可视化和模拟引擎进行处理,这些引擎提取描述行为、环境及其关系模型的有意义的指标。由此产生的测量结果支持系统的政策顾问、政策规划师以及学校和临床顾问服务的运行。
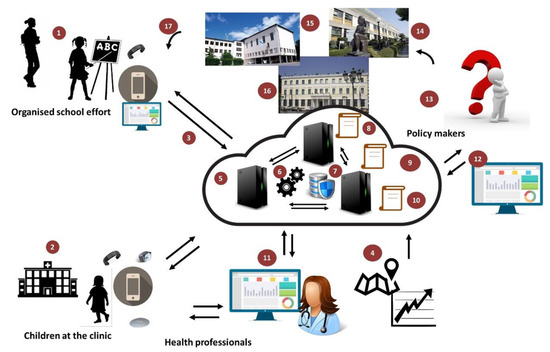
图2.BigO系统概述。(1) 公民科学家。(2) 诊所通过智能手表和移动应用程序对儿童进行监控。(3) 匿名和加密数据传输。(4) 外部数据源(地图、POI、区域统计)。(5) BigO云数据聚合和处理。(6) 数据分析和可视化库和工具。(7) 安全的分布式数据库存储。(8) 政策顾问服务。(9) 政策规划服务。(10) 学校和临床顾问服务。(11) 临床医生使用网络工具来监测和指导儿童。(12) 用于决策者决策支持的Web工具。(13) 政策制定者确定儿童肥胖状况。(14、15、16)政策适用于医院、学校、社区或地区层面。(17) 应用政策影响公民科学家,结束循环并启动另一轮数据收集和分析。
总之,从技术角度来看,BigO测量和研究了两个主要因素:(1)当地外在条件和(2)个人行为模式。从这些因素中收集的数据由下面列出的BigO用户进行解释:
1.作为数据提供者的年龄段(9-18岁)内的儿童和青少年:
- 在校学生,通过学校有组织地开展体育活动、饮食和睡眠项目。
- 参加肥胖诊所的患者。
- 个人志愿者。
2.老师们与学生一起组织学校活动。
3.在诊所治疗病人的临床医生。
4.公共卫生官员(研究人员或政策制定者)结合与肥胖相关的当地外在条件(LEC)评估地理区域内的儿童/青少年行为指标。
5.学校、诊所和整个BigO平台的管理员。
Figure 3 总结了基于上述用户组的数据流。最初,教师和临床医生将数据插入系统(初始用户注册)。孩子们主动(通过记录食物广告或用餐)和被动(通过自动运动检测)通过将数据发送到系统中来共享数据。所有这些数据都在数据库管理系统(DBMS)中组织和表示,并上传到服务器,在那里可以在门户网站中立即查看、处理和分析。
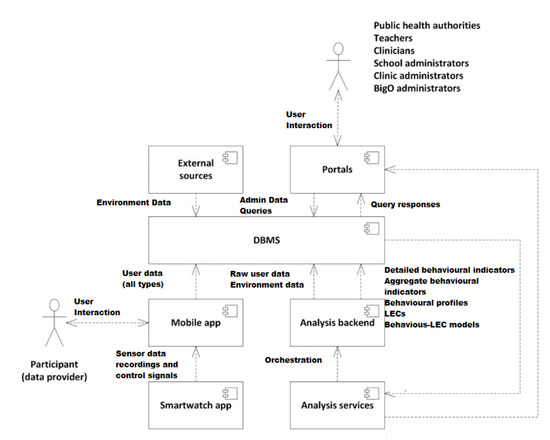
Figure 3. BigO information flow.
4. BigO Data Collection
Figure 4显示了BigO收集的四大类数据;(1) 个人或行为数据源,(2)人口数据源,,(3)区域数据源,以及(4)地图数据源。下文将对这些问题进行简要讨论。
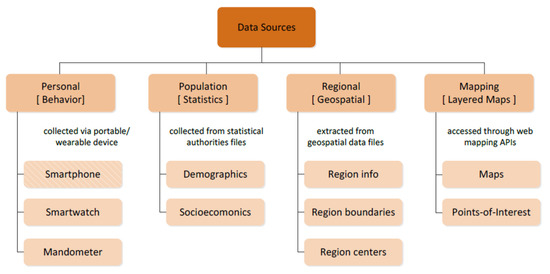
Figure 4.
BigO所需原始数据源的分层分类。这款智能手机在视觉上与同类产品不同,因为它是一个混合原始数据源(由于食品广告照片)。
- 个人数据来源(行为):这些原始数据是从公民科学家那里收集的,涉及与BigO研究相关的行为模式(例如,一个人如何移动、进食、睡眠)。这一类别的原始数据是从个人便携式和/或可穿戴设备中收集的。根据移动感官数据采集设备对这些来源进行进一步分类;(即,(a)智能手机、(b)智能手表和(c)Mandometer)。我们根据BigO系统的要求,将设备组合在三种设置中,这需要数据收集和外围传感器的可用性(表2)。
- 人口数据来源(统计):原始数据来源包含居住在特定地区(农村、城市等)的人口特征信息。数据提供商包括参与BigO的国家统计机构。根据人口统计的类型,原始数据源进一步分为(a)人口数据源和(b)与感兴趣城市及其行政区域的人口有关的社会经济原始数据源。
- 区域数据源(地理空间):这些数据包含与感兴趣的BigO区域(国家、城市或行政城市区域)链接的地理空间数据。
- 映射数据源(分层映射):网络映射数据由第三方API提供。根据数据类型,这些来源进一步分类为a)地图(即交互式地形图)和(b)兴趣点(PoI)。
表2.在BigO系统中部署的数据收集模式。所有模式都包括使用智能手机。缩写:智能手机(SP)、腕带(WB)和下颌测量仪(MM)。
5. Big Data Warehouse Architecture
本节介绍了考虑到数据安全和隐私的大数据仓库体系结构和BigO中实现的数据表示方法。BigO数据仓库(DW)体系结构如图5所示。DW由各种存储系统组成,具体取决于BigO系统中数据生命周期任何阶段所需的敏感度和访问类型。它是按照三层体系结构设计的。这三层(在本例中为层)是后端层、访问控制层和控制器层。
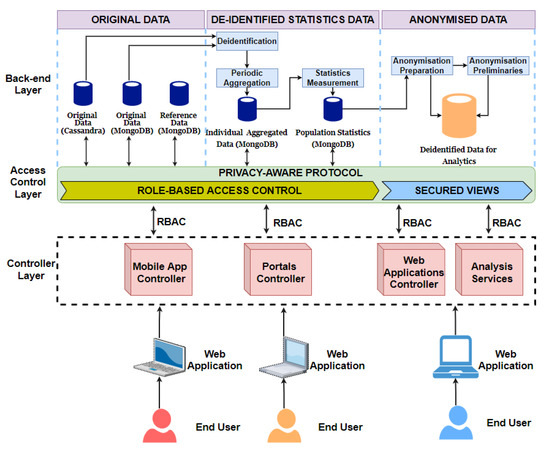
Figure 5.
BigO数据仓库体系结构。
- 原始数据:在BigO系统中,原始数据按照两个主要模式存储。这些模式是使用两个现代数据库实现的;MongoDB和Cassandra。出于两个不同的原因,我们创建了两个模式:第一个是出于安全和隐私的原因。分离降低了数据访问违规和故意操纵的风险。第二个原因是,在分析过程中,这两个模式的使用方式不同,而且来自不同的角色。例如,Cassandra用于存储时间序列数据,而MongoDB用于其他数据。此外,在分析过程中还使用了外部数据源,包括权威数据库和国家统计数据库。
- 取消标识的统计数据:将删除所有有关用户身份的信息。这包括个人汇总数据和人口统计数据,即根据原始数据和参考数据得出和计算的统计数据。
- 匿名数据:除了去识别之外,我们还使用数据挖掘算法对数据进行了进一步的匿名化,以便无法从数据分析过程中提取的知识中恢复原始数据。
5.1. Access Control Layer
该层包括基于角色的访问控制和安全视图。基于角色的访问控制在控制器请求访问原始数据和基于其角色取消标识的统计数据时检查控制器的权限。基于角色的访问控制只接收来自移动应用程序控制器或门户控制器的数据请求。而安全视图控制着从匿名数据中提取的知识。安全视图仅接收来自web应用控制器和分析服务的数据请求。
5.2. Controller Layer
有四种类型的控制器,即移动应用程序控制器、门户控制器、web应用程序控制器和分析服务。该层接收来自用户或系统的其他组件的数据请求。每当收到用户的数据请求时,他们都会使用令牌和组件的角色来检查用户的权限。
5.3. Data Storage and Integration
为实现BigO数据仓库而定义的存储系统使用MongoDB和Cassandra。MongoDB是主要的应用程序数据库,而Cassandra用于存储大量的时间序列数据。Mobile、Web门户和Web应用程序控制器仅通过RESTAPI以书面形式直接访问存储系统。此外,这些API实现了数据集成和整合需求,从而将从不同来源收集的数据存储在数据仓库中的统一表示中。图6显示了不同系统模块之间的数据流。
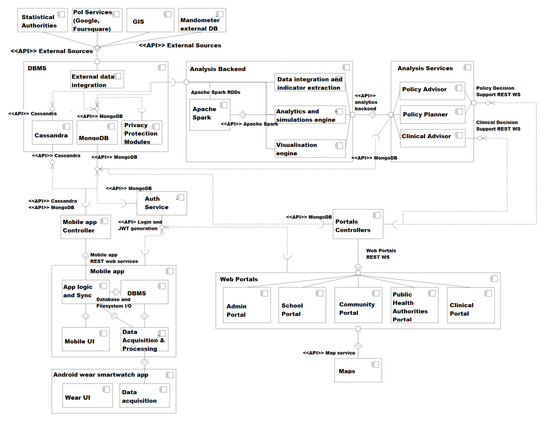
Figure 6.
BigO系统的组件图。
除了核心数据库之外,BigO还提供了对分布式文件系统的访问,该系统是Hadoop的HDFS。其目的是以方便的格式保存可以直接从数据库中提取的大型数据集文件,供数据分析算法(模块)使用。定期过程每天以固定的时间间隔更新数据库中的文件内容。附录A.1和附录A.2提供了核心数据库的详细模式。在下文中,我们将讨论存储在每个核心数据库中的数据。
5.3.1. MongoDB Data
存储在MongoDB中的数据是从四个不同的来源收集的,如下所述:
- 入口控制器:BigO系统中有五个入口;管理门户、学校门户、社区门户、公共卫生当局门户和临床门户。数据是从所有这些门户网站收集的,并在存储MongoDB数据库之前进行集成。
- 移动控制器:该控制器处理从手机或智能手表收集的数据。数据经过预处理、集成,然后传输到MongoDB。这些数据特别重要,因为它很敏感,应该小心处理。
- 分析服务:数据分析组件处理存储在两个数据库中的整个数据集。分析组件使用Spark计算环境。分析结果存储回MongoDB数据库中。
- 后端分析服务:该服务访问存储在两个数据库中的数据,以提取行为指标。然后将这些新的数据属性存储在MongoDB中。后端分析服务是在Spark环境中执行的。
5.3.2. Cassandra Data
该数据库主要存储从外部来源和移动应用程序收集的原始数据。
- 外部来源:外部数据来源包括个人行为数据和外部人口数据。这些数据集通过外部数据集成模块直接传输到数据库(图6)。例如,关于个人设备的数据。
- 移动应用程序控制器:通过智能手机或智能手表收集的移动应用程序数据使用移动应用程序内容提供商存储在移动应用程序的数据库中。然后将存储的数据与Cassandra数据库同步。(图6)。
6. Data Security and Privacy
隐私和安全是任何信息系统的基本要求。尽管数据安全和数据隐私是相关的,但它们处理的问题不同,需要采取不同的对策。数据安全旨在保护机密性、完整性、可用性和不可否认性。而数据隐私防止共享数据泄露其相应所有者的敏感信息。在BigO中实现了以下数据安全方法。
- 安全存储:BigO系统架构使用主流平台实现,如Cassandra、MongoDB、SQLite数据库管理系统、Hadoop、Android和iOS的HDFS文件系统。这些标准系统采用内置加密技术来保护系统组件及其包含的数据。第6.1节提供了有关每种类型存储的更多详细信息。
- 安全通信:当数据在系统的各个模块之间传输时,必须确保数据的安全。BigO模块之间的通信使用安全协议,如SSL、TLS或HTTPS(有关更多详细信息,请参阅第6.1节)。
- 数据访问控制:访问控制在大型系统中是一个复杂的问题,如BigO。因此,我们实现了一个完整的访问控制解决方案,包括一致的策略、清晰而强大的注册、身份验证和授权机制。它们总结如下:
- 移动应用程序存储:在BigO中,移动应用程序数据存储只能由该手机的后端访问,并且只包含其所有者的个人数据。因此,在这种情况下不需要细粒度的访问控制。它使用基于用户名和密码的简单访问控制。
- 辅助文件存储:这是一种用于处理原始数据的临时存储,由移动后端通过其控制器使用。与移动应用程序存储一样,它只需要一个带有用户名和密码的基本访问控制。
- 数据库服务器:这些是主存储器,包含所有用于分析的BigO数据。这些数据可供各种最终用户使用,具体取决于他们的角色。基于角色的访问控制(RAC)机制与用于授予角色和权限的特定策略一起使用。每个数据库都是通过RESTful API访问的。(详见第6.2节)。
BigO数据隐私保护基于个人数据的类型(表2)。这些数据类型如下所示:
- 惯性传感器、运动和Mandometer数据:这些数据类型被收集并存储在个人设备(智能手表、手机、Mandometer)上。只提取统计和概括数据并将其提交给BigO服务器。这些类型的数据不会增加隐私风险。
- 照片:所有照片均由BigO管理员审核。任何被认为不相关、不雅或暴露用户身份的照片都会从系统中删除。
- 可识别数据:在将数据存储到数据仓库之前,会删除所有属性,如用户名、设备ID等。删除此类属性的操作称为取消标识(第6.3节)。
- 准可识别数据:所有数据属性,如国家、地区、学校、诊所、身高、体重、性别、出生年份、自我评估答案、照片位置等,都通过匿名处理。然而,由于对数据质量的不利影响,采用了隐私保护协议来考虑这类数据(第6.3节)。
6.1. Data Protection
移动应用程序:该移动应用程序是为Android和iOS构建的。这两个操作系统都具有内置的安全功能。我们利用这些功能来保护应用程序收集的数据,即使在使用默认系统和文件权限的情况下也是如此[17]。例如,Android操作系统的核心安全功能包括Android应用程序沙盒,它将应用程序数据和代码执行与其他应用程序隔离开来。iOS也提供了相同的功能。
BigO应用程序将所有数据(包括SQLite DB数据、应用程序内获取的照片和共享偏好)存储在设备的内部存储中。所有这些数据在同步/上传到BigO服务器后立即被删除。
- 数据库服务器:MongoDB和Cassandra系统包含了非常有趣的安全模型。例如,MongoDB安全模型分为四个主要部分:身份验证、授权、审计和加密。我们在下面简要解释了MongoDB和Cassandra如何支持数据安全保护功能。
- 身份验证:MongoDB集成了外部安全机制,包括轻型目录访问协议(LDAP)[40]、Windows Active Directory、Kerberos[41]和x.509 PKI[42]证书,以重新实施对数据库的访问控制。
- 授权:可以在MongoDB中定义用户定义的角色,根据用户或应用程序所需的权限为其配置细粒度权限。此外,可以定义只公开给定集合中数据子集的视图。
- 审核:为了遵守法规,MongoDB安全模型记录本机审核日志,以跟踪对数据库的访问和操作。
- 加密:MongoDB安全系统提供网络、磁盘和备份上的数据加密数据。通过加密磁盘上的数据库文件,可以消除外部加密机制的管理和性能开销。
- 监控和备份:MongoDB提供了各种工具,包括Mongostat、Mongotop和MongoDB管理服务(MMS)来监控数据库。主机系统的CPU和内存负载的突然峰值以及数据库中的高操作计数器可能表示拒绝服务攻击。
ApacheCassandra是一个NoSQL数据库系统,它不是基于共享架构,例如MongoDB。它依赖于DataStax Enterprise(DSE)[43]来提供安全功能,如飞行中和静止中的数据加密、身份验证、授权和数据审计。DataStax Enterprise(DSE)[43]与现有技术紧密集成,包括对Active Directory(AD)、轻型目录访问协议(LDAP)、Kerberos、公钥基础设施(PKI)和密钥管理互操作性协议(KMIP)的支持。下文将对此进行解释。
- 加密:它保持数据的机密性。通常,数据库数据加密分为两类:静止加密和飞行加密。第一种是指对存储在持久性存储器上的数据的保护。第二种是指数据在节点或客户端与DSE集群内的节点之间的网络上移动时的加密。
- DSE透明数据加密(TDE):是负责DSE系统中静态数据加密的功能。DSE TDE使用本地加密密钥文件或远程存储和管理的密钥管理互操作性协议(KMIP)加密密钥来保护敏感的静态数据。
- 身份验证:是指建立对数据库执行操作的人员或系统的身份的过程。DSE统一身份验证有助于连接到以下四种主要身份验证机制。它将相同的身份验证方案扩展到数据库、DSE搜索和DSE分析。
- 授权:在DSE中,授权决定了连接实体可以读取、写入或修改哪些资源(即表、密钥空间等),以及它们的连接机制。它使用GRANT/REVOKE范式进行授权,以防止对数据的任何不当访问,并使用三种机制进行用户授权:基于角色的访问控制(RBAC)、行级访问控制(RLAC)和代理身份验证。
- 审核:数据审核允许跟踪和记录在数据库上执行的所有用户活动,以防止未经授权访问信息并满足法规遵从性要求。使用DSE,将记录在DataStax集群上发生的活动的全部或子集,以及用户的身份和执行活动的时间。DSE中的高效审计是通过平台中内置的log4J机制实现的。
- 驱动程序:DataStax为C/C++、C#、Java、Nodejs、ODBC、Python、PHP和Ruby提供了驱动程序,这些驱动程序适用于任何集群大小,无论是部署在本地还是云数据中心。这些驱动程序配置了一些功能,例如SSL,以确保用户安全可靠地与DSE集群进行交互。
6.1.1. Auxiliary File Storage
辅助文件存储在BigO中用于存储用于开发目的的原始加速度计和陀螺仪数据。这种惯性测量数据不能用于识别用户,并且不会造成任何隐私风险。数据以自定义二进制格式存储在安全的Unix服务器中。
6.1.2. Data Transmission
数据在(a)智能手表和移动电话之间传输,(b)用户移动电话和BigO服务器之间传输,以及(c)在BigO的不同服务器之间传输。智能手表和手机之间的通信通过加密的蓝牙信道进行,潜在的攻击者必须靠近用户。此外,数据只能通过手机上的BigO应用程序访问;手机上运行的所有其他应用程序都无法接收传输的数据。移动电话和BigO服务器之间的通信使用2048位SSL进行加密。最后,考虑到所有BigO服务器都是同一数据中心的一部分,服务器之间的传输并不重要。
6.2. Data Access Control
6.2.1. Registration
注册过程取决于用户类型。不同的程序是:
- BigO管理员:这是由BigO开发人员创建的,并且是固定的。BigO管理员可以注册学校和诊所管理员。同样也可以审查提交的图片,以删除不合适的图片或损害个人隐私的图片。
- 学校管理员可以添加/编辑学校详细信息并注册教师。
- 诊所管理员可以添加/编辑诊所详细信息并注册临床医生。
- 教师可以创建组、编辑学生组和个别学生的详细信息,如BMI、学校锻炼计划等,还可以为学生创建注册码。
- 临床医生可以为患者创建注册代码,并编辑个人患者详细信息,如BMI。
- 学生可以使用老师提供的注册码通过BigO手机应用程序进行注册。当教师创建学生帐户时,会生成注册代码并将其存储在数据库中。学生在第一次使用应用程序时输入注册码。一旦注册码被“兑换”,学生将在系统中注册,注册码将不再有效。
- 患者使用临床医生提供的注册码进行注册;和学生们一样。
6.2.2. Authentication:
用户身份验证通过JSON Web令牌在专用的身份验证服务器上进行。过程如下:
- 每个用户都有一个用户名和密码(对于学生和患者,这些都是自动生成并存储在手机上的,没有用户的参与)。密码经过加盐和散列处理,编码后的密码存储在数据库中。
- 当移动电话需要访问受限制的REST端点时,它首先通过提供用户凭据向身份验证服务器请求JSON Web令牌(JWT)。凭据也被加盐(用同样的盐)和散列,身份验证服务器比较编码的密码。如果它们匹配,它将为用户提供一个有效的JWT。
- 使用JWT,移动应用程序和门户网站/应用程序可以访问受限制的REST端点,直到其过期。过期后,移动应用程序会向身份验证服务器请求新的JWT,并重复此过程。
6.2.3. Authorization:
BigO角色包括BigO管理员、学校管理员、诊所管理员、教师、临床医生、学生和患者、公共卫生当局角色以及志愿者学生。访问控制由BigO控制器(移动应用程序控制器、门户网站控制器、web应用程序控制器)在应用层实现。我们还在数据库层包括基于角色的集合级访问控制(MongoDB本机支持),作为额外的安全和数据保护机制。
6.3. Data Privacy Protection
在BigO中,数据存储在移动应用程序存储(包括移动文件系统和SQLite数据库)、辅助文件存储、Cassandra数据库和MongoDB数据库中。除了MongoDB数据库中的数据外,其他地方的数据都由数据所有者和内部模块访问和使用。MongoDB数据库很少直接共享用于分析。这是为了防止共享数据泄露数据所有者的敏感信息。因此,本节重点讨论了在出于分析目的共享这些数据时MongoDB数据库的隐私保护。
我们将在接下来的章节中首先讨论隐私保护的挑战。然后,我们进一步讨论了如何使用隐私感知协议来减轻这些挑战的影响。
6.3.1. Deidentification and Pseudonymisation
取消识别通过删除所有可以直接识别个人的字段,如姓名、电话号码和电子邮件,来隐藏数据所有者的真实身份。在我们的案例中,去标识不会影响数据分析结果的质量。
当数据被去标识和共享时,一个新的随机标识符被用来命名个人。在某些情况下,需要保持新旧标识符之间的关系,以便更新未识别的数据。因此,假名被用来为个人创建伪ID,并加密真实ID和伪ID之间的联系。然而,在BigO系统中,“username”和“display_id”用于与最终用户的接口,而子id仅由内部模块使用。因此,当孩子的数据被共享时,我们不需要为他们创建伪ID。可以保留孩子的ID,以区分共享数据集中的个人,而不透露他们的身份。
此外,可以同时删除不需要进行分析的字段。必须澄清的是,数据库集合“照片”不被视为可识别的信息来源。这是因为上传的照片会经过人脸识别算法和BigO管理员的检查,以确保它们只包含食品广告和餐食。
6.3.2. Anonymisation
实际上,由于准标识符的存在,去标识和假名化不足以保证数据集的安全。与可识别字段不同,删除准标识符会影响数据分析的质量。用于防止记录和属性链接攻击的隐私模型,如k-匿名、l-diversity和LKC隐私,使用了各种匿名操作,如泛化、抑制、混洗、扰动和添加噪声。然而,一些操作(例如,混洗、单元泛化和扰动)仅适用于特定的分析,并且可能使数据集不可用于挖掘算法。
BigO是一个具有高维数据集的大数据系统,尤其是当多个数据库集合组合在一起时。因此,在高维数据集上使用k-匿名及其扩展版本的匿名化会导致严重的数据失真,导致数据分析质量低下。
6.3.3. Privacy-Aware Data Analysis Protocol
所提出的隐私感知协议如图7所示。该协议旨在处理共享数据进行分析时的可识别和准可识别属性问题,并考虑了高维问题。
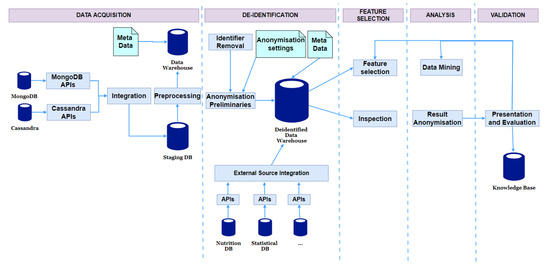
Figure 7. Privacy-aware data analysis protocol.
在传统方法中,分析任务被应用于质量下降的匿名数据。该协议的总体思想是对数据进行去识别,但不是匿名化。我们没有对数据进行匿名化并共享数据进行分析,而是为数据科学家提供了特殊的安全视图,以检查数据集,然后在未识别但未匿名的数据集上运行分析。特殊的视图使这些最终用户能够从不同的角度检查数据,但不会揭示敏感信息与患者之间的联系。数据科学家可以选择在去识别但非匿名的数据上运行的特征选择方法和分析算法。由于数据不包含标识符,因此所发现的结果具有高质量。此外,这个运行过程由系统管理,科学家无法访问非匿名数据。在公布之前,对结果进行检查,以确定是否存在未披露的意外信息。对生成的模型的一些细节进行了过滤,以保证儿童的隐私。协议的步骤如下:
取消标识:在此步骤中,将删除可识别的属性和用于分析的非重要属性。
匿名化准备:一些属性需要一些小的处理,以支持生成安全视图。这种情况通常发生在日期和数字属性上,但不是分类属性。例如,通常不需要保留详细的高度值。所以我们将它们四舍五入到范围内。这种转换不是一种匿名操作,它只是稍微改变了数据内容,用于分析的数据中的信息几乎被保留了下来。因此,我们将此步骤视为匿名化准备。这项任务的另一项重要工作是创建用于生成安全视图的匿名化预备(包括准可识别属性的分类树)。
安全视图生成:创建安全视图是为了帮助数据科学家从各种角度检查和理解数据集,但不能揭示患者与其敏感信息之间的联系。有三种类型的安全视图:
- -统计视图:它为自动计算的属性提供度量,如标准偏差、域范围和值统计。
-
-匿名视图:这提供了共享数据集的完整视图。为了保护隐私,我们应用了信息安全中的隐私和匿名(PAIS)算法[44]来实现LKC隐私模型[45]。LKC隐私防止高维数据集的记录和属性链接攻击。PAIS在分类树上使用自上而下的搜索策略来寻找记录的次优泛化。对于一般分析任务,可辨别成本被用作选择最佳专业化的衡量标准。
-
-分析观点:由于k-匿名是LKC隐私的一个条件,PAIS的结果存在高维问题。因此,匿名视图可能会提供关于准标识符的过于笼统的视图。还使用解剖技术提供了详细的或解剖的视图。
- 特征选择:在检查了具有不同视图的数据集后,数据科学家可以选择适当的转换、特征选择和提取方法,为其特定应用的分析任务生成适当的输入数据。处理是在去标识和非匿名数据集上完成的。
- 数据挖掘和结果匿名:数据科学家可以选择各种分析方法。在某些情况下,返回的结果可能过于详细。例如,决策树(上述分类算法的输出)具有链接到几个特殊个体的详细叶节点。因此,为了保证儿童的隐私,研究人员在发布挖掘结果之前必须对其进行检查和过滤。
- 演示和评估:对生成的模型进行评估,必要时可以从检查步骤重新启动数据分析师的分析。
7. Implementation for Privacy-Aware BigO System Architecture
7.1. Description of Architectural Changes
为了将图7中描述的隐私感知协议应用到BigO体系结构中(图6),我们更新了如图8所示的体系结构。可以看出,在去标识和匿名准备步骤之间添加了一些中间模块。这些模块支持定期汇总和人口统计预计算。架构的主要更新如下所示:
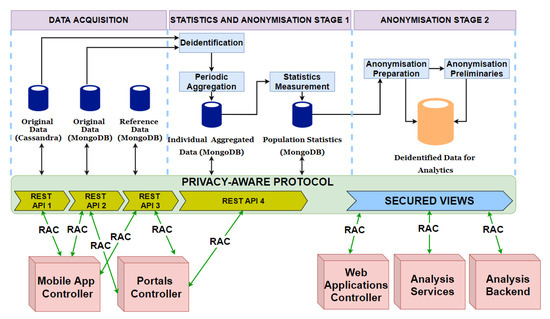
Figure 8. Privacy-aware BigO architecture.
- MongoDB数据库的分离:与BigO组件图(图6)中的一个MongoDB数据库不同,该数据库的集合被分离为三个数据库:
- -第一个MongoDB数据库(原始数据):该数据库包含管理数据和收集/测量的数据,包括集合USERS、CHILDREN、MEALS、TIMELINES、FOOD_ADVERTISEMENTS、DAILY_NSWERS和PHOTOS。
- -第二个MongoDB数据库(参考数据):该数据库存储与个人无关的数据,用于参考。该列表由集合SCHOOLS、CLINICS、GROUPS、REGIONS和PUBLIC_POIS组成。
- -第三个MongoDB数据库(包括个人聚合数据和人口统计):个人聚合数据包括定期汇总个别儿童行为数据的集合,如DAILY、WEEKLY和Statistics。人口统计数据包括集合COUNTERS、PUBLIC_POIS_VOTES、GEOHASH_VOTES、GEOHAS_ATTRIBUTES和HISTOGRAMS。
- API分离:更新后的BigO架构支持四种不同的API来访问Cassandra数据库和三个MongoDB数据库。
- 去识别模块:该模块删除可识别字段以及不需要分析的字段,并且不需要假名。
- 定期汇总模块:该模块定期汇总儿童的行为数据。
- 统计测量模块:该模块预先计算一些群体的统计数据,用于可视化特征和生成统计视图。
- 匿名准备模块:该模块执行上述隐私保护协议的匿名准备步骤中描述的任务。该模块的输出是匿名化准备和用于分析的去识别数据。
- 匿名准备:这些内容以JSON或XML的格式保存。
- 用于分析的去标识数据:该数据存储不应存储离散集合,如个人汇总数据和人口统计数据库中的集合。用于分析的数据应该是以便于生成安全视图和挖掘算法的格式组合的数据集。一个不错的选择是将CSV文件存储在Hadoop的文件系统存储中。
- 安全视图:用于分析的数据通过安全视图访问。有一些模块负责生成安全视图,并对未识别的数据运行特征选择/挖掘算法进行分析。
7.2. Process of Updating Data Changes
当原始数据存储发生更改时,进行检查是很重要的。在实践中,有两种可能的数据更新:
- 管理数据的更改:管理数据(如电子邮件、姓名、地址)是手动输入的,因此有时会出现需要更新的错误。由于该数据类型不会被提取以存储在其他数据库中,因此同步不是问题。
- 插入新措施:行为措施经常从移动应用程序上传到原始数据库。经过一定时间后,为了反映原始数据的变化,新的汇总数据被添加到单独的汇总数据存储中,现有的统计数据被更新到人口统计存储中。还重新计算了用于分析的匿名化预备数据和去识别数据。
8. Current Picture, Recommendations, and Future Directions
在本节中,我们回顾了我们在实施隐私意识大数据仓库架构方面的经验教训和建议,以及进一步研究方向的步骤。
我们首先强调了现有数据仓库体系结构中的一些主要问题,包括缺乏应对高维诅咒的能力。在传统框架中,分析任务被应用于数据质量下降的匿名数据。我们的工作提出了BigO数据仓库架构,并进一步集成了一种新的隐私感知协议,以处理可识别和准可识别数据属性的问题,同时共享用于分析任务的数据。我们在两个不同的级别,即应用程序级别和数据库级别,介绍了数据采集、集成和评估的安全协议。我们还介绍了注册、身份验证和授权等阶段的数据访问控制协议。
关键的想法是去识别个人数据,但不应该是匿名的。BigO数据仓库体系结构使用安全视图供数据科学家挖掘数据集。特殊的视图使最终用户能够执行我们的探索任务,而不会揭示敏感信息与相应患者之间的联系。
BigO系统中实现的隐私和安全协议可以应用于除医疗保健部门以外的任何数据驱动应用程序,在执行分析任务的过程中,在数据采集、存储、传输和访问过程中存在敏感个人信息丢失的风险。这些协议的本质是,在不降低数据质量的情况下,应该能够对数据执行挖掘和分析任务,而不会有敏感信息丢失的威胁。
作为未来的工作,我们计划制定适当和准确的数据治理政策和程序,以避免任何数据泄露、侵犯任何个人隐私,并为社会及其公民的利益产生高质量的结果。数据治理很重要,因为BigO项目处理敏感的个人和儿童数据,这些数据需要以高度的谨慎和信任进行管理和操作。因此,数据治理生命周期方法必须确保数据的机密性、质量和完整性。
9. Conclusions
由于肥胖已成为一个严重的全球公共卫生问题,对个人和整个社会都有影响,因此必须考虑行为干预和环境社区因素来干预儿童。BigO使用公民科学家的数据收集方法和不同的技术(智能手机、腕带、Mandometer)来创建肥胖流行率的综合模型。BigO的数据采集使研究人员能够创建模型,通过与社区行为模式和当地肥胖流行率的关联,分析行为风险因素并预测肥胖流行率。
个人数据的监控和存储使得数据表示、安全和访问控制成为一项具有挑战性的任务。本文首先实现了BigO的数据访问和存储组件,包括与其他系统组件的接口,以实现平稳运行的数据聚合、数据分析和可视化。我们为BigO提供了一个三层灵活的数据仓库体系结构,包括后端层、访问控制层和控制器层。
考虑到隐私和安全方面,我们在BigO数据库和存储模型中进一步实现了数据表示和共享协议。数据隐私和安全计划是根据收集的个人数据的类型,在数据存储、数据传输和数据访问方面制定的。我们提出了隐私保护方面的挑战,并实施了新的隐私感知数据分析协议,以确保由此产生的模型保证儿童的隐私。最后,我们实现了集成了上述隐私感知协议的BigO系统架构。
Author Contributions
Conceptualization, A.S., T.-A.N.N. and M.-T.K.; data curation, T.-A.N.N. and M.-T.K.; formal analysis, A.S., T.-A.N.N. and M.-T.K.; funding acquisition, M.-T.K.; Investigation, A.S., T.-A.N.N. and M.-T.K.; methodology, A.S., T.-A.N.N. and M.-T.K.; project administration, A.S., and M.-T.K.; resources, A.S., T.-A.N.N. and M.-T.K.; software, A.S., M.-T.K.; supervision, M.-T.K.; validation, A.S., T.-A.N.N. and M.-T.K.; visualization, A.S., T.-A.N.N. and M.-T.K.; writing—original draft, A.S.; writing—review and editing, A.S., and M.-T.K. All authors have read and agreed to the published version of the manuscript.
Funding
The work leading to these results was part of the EU H2020 project: BigO: Big data against childhood Obesity (Grant No. 727688, https://BigOprogram.eu, accessed on 21 March 2021). This project was part of the European Community’s Health, demographic change and well-being Programme of EU H2020. This work is also supported by Science Foundation Ireland under grant number SFI/12/RC/2289_P2.
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki, and approved by the Institutional Human Research Ethics Committee of University College Dubin (2 September 2019).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Data sharing is not applicable to this article.
Acknowledgments
The research team wishes to acknowledge the research collaborators Anastasios Delopoulos, Eirini Lekka, Ioannis Ioakeimidis, Christos Diou, Isabel Perez, Daniel Ferri, and all the BigO Project Consortium Members; the W82GO clinical and administrative team, and the physiotherapy department at Children’s Health Ireland, Temple Street, Dublin; and participating patients and their parents.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:| BigO | Big Data for Obesity |
| GPS | Global Positioning System |
| HIPAA | Health Insurance Portability and Accountability Act |
| EHR | Electronic Health Records |
| PHA | Public Health Authorities |
| LEC | Local Extrinsic Conditions |
| GIS | Geographic Information System |
| DBMS | Database Management System |
| API | Application Programming Interface |
| JWT | JSON Web Tokens |
Appendix A. Schema Design
This section present schema design for the core database in BigO.
Appendix A.1. MongoDB Schema
Figure A1, Figure A2, Figure A3, Figure A4 and Figure A5 show the schema of MongoDB. The schema is organized in collections as follows:
- 区域:此集合存储管理区域的有趣特征,以表示所有类型的地理或管理区域。因此,一个地区可以是一个城镇、一个城市、一个省甚至一个国家。每个区域都有一系列形成其边界的坐标。边界信息将由公共当局提供。根据区域类型,可以稍后添加区域特征字段。
- 地理散列:由于其层次结构和易于存储在数据库中等特殊特性,地理散列在BigO系统中用于表示地理信息。记录了一些地区儿童活动的数据。但是,只有匿名和统计数据存储在集合Geohash_attributes和Geohash_votes中。
- 公共POI:两个集合Public_POIs和Public_POIs_votes在公共兴趣点存储儿童的聚合活动信息。因此,集合Geohash_votes和Public_pois_votes的结构几乎相同。
- 学校和诊所:这些集合存储有组织的学校和诊所的信息。
- 小组:通过组织的学校参加BigO系统的学生被分成小组。每组由一名教师管理。
- 用户和儿童:BigO系统有许多类型的用户,但只收集儿童数据进行研究。因此,Users集合用于管理管理字段,而Children集合包括记录用于研究的字段。用户的可用字段取决于他/她的角色。一些特殊字段是共享的,因为它们对于两个集合上的流行查询是必需的。这种复制在插入新子项时需要少量的额外成本,但可以提高许多操作的性能。
- 照片:前一版本中的集合Meals和Food_Advertisements中的字段“照片”被分离以存储在集合Photos中。将特定集合中的所有照片分组可以使照片的管理和验证更加顺畅。
- 时间线和移动性:旧版本中的集合移动性被替换并扩展到集合时间线。新的收藏品不仅包括参观的地点,还包括儿童的旅行活动。
- Daily_awsers:这个新集合包含了日常问题的答案。
- 计数器:为子项(在集合Users中)生成显示ID是必需的。这些ID是通过调用函数getNextChildDisplayId(“children”)的自动递增序列生成的。一旦被调用,这个简单的函数就会将1添加到集合计数器中具有“_id”=“children”的文档的字段“child_seq”中,并返回新值作为新的显示id。类似的技术和集合计数器可以用于创建其他自动递增序列。
- 睡眠、行动、膳食和食品广告:这些集合存储了儿童日常活动的数据。特别是,餐食和食品广告中包含了儿童拍摄的照片。
- 饮食习惯:此集合包含可以从膳食中提取和汇总的饮食习惯信息。
- 统计信息:该集合用于存储统计信息,例如照片的数量。
- 每日和每周:活动的数据可以每日和每周汇总,然后存储在这些集合中。

Figure A1. MongoDB Schema—Part 1.

Figure A2. MongoDB Schema—Part 2.
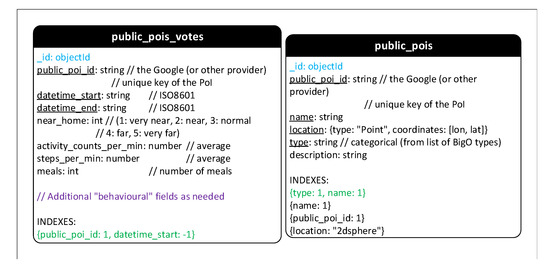
Figure A3. MongoDB Schema—Part 3.
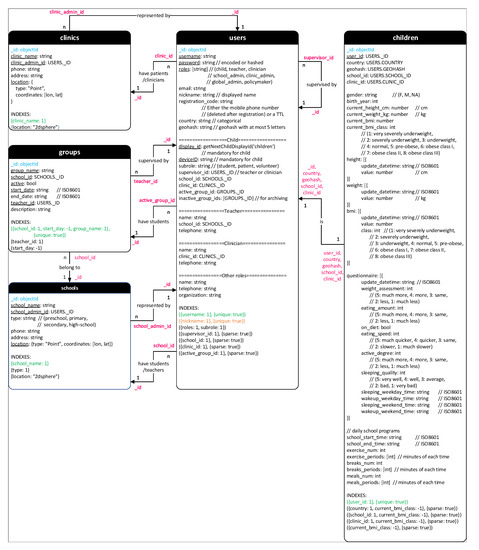
Figure A4. MongoDB Schema—Part 4.

Figure A5. MongoDB Schema—Part 5.
Appendix A.2. Cassandra Schema
Figure A6 shows collections in Cassandra. We now list them below:
-
Physical_activity_by_user: stores the data of activities (i.e., walking, standing, sitting, running, etc.) for each user.
-
Physical_activity_by_date: stores the data of activities (i.e., walking, standing, sitting, running, etc.) of users for each specific date and time.

Figure A6. Cassandra database Schema.
References
- Abarca-Gómez, L.; Abdeen, Z.A.; Hamid, Z.A.; Abu-Rmeileh, N.M.; Acosta-Cazares, B.; Acuin, C.; Adams, R.J.; Aekplakorn, W.; Afsana, K.; Aguilar-Salinas, C.A.; et al. Worldwide trends in body-mass index, underweight, overweight, and obesity from 1975 to 2016: A pooled analysis of 2416 population-based measurement studies in 128 · 9 million children, adolescents, and adults. Lancet 2017, 390, 2627–2642. [Google Scholar] [CrossRef][Green Version]
- Dobbs, R.; Manyika, J. The obesity crisis. Cairo Rev. Glob. Aff. 2015, 5, 44–57. [Google Scholar]
- Macaulay, E.; Donovan, E.; Leask, M.; Bloomfield, F.; Vickers, M.; Dearden, P.; Baker, P. The importance of early life in childhood obesity and related diseases: A report from the 2014 Gravida Strategic Summit. J. Dev. Orig. Health Dis. 2014, 5, 398–407. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Bhave, S.; Bavdekar, A.; Otiv, M. IAP national task force for childhood prevention of adult diseases: Childhood obesity. Indian Pediatr. 2004, 41, 559–576. [Google Scholar] [PubMed]
- Collaborators, G.O. Health effects of overweight and obesity in 195 countries over 25 years. N. Engl. J. Med. 2017, 377, 13–27. [Google Scholar] [CrossRef]
- Di Cesare, M.; Sorić, M.; Bovet, P.; Miranda, J.J.; Bhutta, Z.; Stevens, G.A.; Laxmaiah, A.; Kengne, A.P.; Bentham, J. The epidemiological burden of obesity in childhood: A worldwide epidemic requiring urgent action. BMC Med. 2019, 17, 1–20. [Google Scholar] [CrossRef][Green Version]
- Daumit, G.L.; Dickerson, F.B.; Wang, N.Y.; Dalcin, A.; Jerome, G.J.; Anderson, C.A.; Young, D.R.; Frick, K.D.; Yu, A.; Gennusa, J.V., III; et al. A behavioral weight-loss intervention in persons with serious mental illness. N. Engl. J. Med. 2013, 368, 1594–1602. [Google Scholar] [CrossRef][Green Version]
- Katzmarzyk, P.T.; Barreira, T.V.; Broyles, S.T.; Champagne, C.M.; Chaput, J.P.; Fogelholm, M.; Hu, G.; Johnson, W.D.; Kuriyan, R.; Kurpad, A.; et al. The international study of childhood obesity, lifestyle and the environment (ISCOLE): Design and methods. BMC Public Health 2013, 13, 900. [Google Scholar] [CrossRef][Green Version]
- Blake-Lamb, T.L.; Locks, L.M.; Perkins, M.E.; Baidal, J.A.W.; Cheng, E.R.; Taveras, E.M. Interventions for childhood obesity in the first 1000 days a systematic review. Am. J. Prev. Med. 2016, 50, 780–789. [Google Scholar] [CrossRef][Green Version]
- Briggs, A.D.; Mytton, O.T.; Kehlbacher, A.; Tiffin, R.; Rayner, M.; Scarborough, P. Overall and income specific effect on prevalence of overweight and obesity of 20% sugar sweetened drink tax in UK: Econometric and comparative risk assessment modelling study. BMJ 2013, 347, f6189. [Google Scholar] [CrossRef][Green Version]
- Yang, H.J.; Kang, J.H.; Kim, O.H.; Choi, M.; Oh, M.; Nam, J.; Sung, E. Interventions for preventing childhood obesity with smartphones and wearable device: A protocol for a non-randomized controlled trial. Int. J. Environ. Res. Public Health 2017, 14, 184. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Maramis, C.; Diou, C.; Ioakeimidis, I.; Lekka, I.; Dudnik, G.; Mars, M.; Maglaveras, N.; Bergh, C.; Delopoulos, A. Preventing obesity and eating disorders through behavioural modifications: The SPLENDID vision. In Proceedings of the 2014 4th International Conference on Wireless Mobile Communication and Healthcare-Transforming Healthcare Through Innovations in Mobile and Wireless Technologies (MOBIHEALTH), Athens, Greece, 3–5 November 2014; pp. 7–10. [Google Scholar]
- Delopoulos, A. Big Data Against Childhood Obesity, the BigO Project. In Proceedings of the 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS), Cordoba, Spain, 5–7 June 2019; pp. 64–66. [Google Scholar]
- Berman, J.J. Confidentiality issues for medical data miners. Artif. Intell. Med. 2002, 26, 25–36. [Google Scholar] [CrossRef]
- Elger, B.S.; Iavindrasana, J.; Iacono, L.L.; Müller, H.; Roduit, N.; Summers, P.; Wright, J. Strategies for health data exchange for secondary, cross-institutional clinical research. Comput. Methods Programs Biomed. 2010, 99, 230–251. [Google Scholar] [CrossRef]
- Ponemon, I. Sixth Annual Benchmark Study on Privacy & Security of Healthcare Data; Technical Report; Ponemon Institute LLC: Traverse City, MI, USA, 2016. [Google Scholar]
- Aggarwal, C.C. On k-anonymity and the curse of dimensionality. In Proceedings of the VLDB, Trondheim, Norway, 30 August–2 September 2005; Volume 5, pp. 901–909. [Google Scholar]
- Fung, B.C.; Wang, K.; Fu, A.W.C.; Philip, S.Y. Introduction to Privacy-Preserving Data Publishing: Concepts and Techniques; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy Beyond K-anonymity. ACM Trans. Knowl. Discov. Data 2007, 1, 3-es. [Google Scholar] [CrossRef]
- Sweeney, L. K-anonymity: A Model for Protecting Privacy. Int. J. Uncertain. Fuzziness-Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef][Green Version]
- Nelson, G.S. Practical Implications of Sharing Data: A Primer on Data Privacy, Anonymization, and De-Identification; Technical Report; ThotWave Technologies: Chapel Hill, NC, USA, 2015. [Google Scholar]
- Kanwal, T.; Anjum, A.; Khan, A. Privacy preservation in e-health cloud: Taxonomy, privacy requirements, feasibility analysis, and opportunities. Clust. Comput. 2021, 24, 293–317. [Google Scholar] [CrossRef]
- Manios, Y.; Grammatikaki, E.; Androutsos, O.; Chinapaw, M.; Gibson, E.; Buijs, G.; Iotova, V.; Socha, P.; Annemans, L.; Wildgruber, A.; et al. A systematic approach for the development of a kindergarten-based intervention for the prevention of obesity in preschool age children: The ToyBox-study. Obes. Rev. 2012, 13, 3–12. [Google Scholar] [CrossRef]
- Paans, N.P.; Bot, M.; Brouwer, I.A.; Visser, M.; Roca, M.; Kohls, E.; Watkins, E.; Penninx, B.W. The association between depression and eating styles in four European countries: The MooDFOOD prevention study. J. Psychosom. Res. 2018, 108, 85–92. [Google Scholar] [CrossRef]
- Lakerveld, J.; Glonti, K.; Rutter, H. Individual and contextual correlates of obesity-related behaviours and obesity: The SPOTLIGHT project. Obes. Rev. 2016, 17, 5–8. [Google Scholar] [CrossRef][Green Version]
- Gibbons, C.; Del Pozo, G.B.; Andrés, J.; Lobstein, T.; Manco, M.; Lewy, H.; Bergman, E.; O’Callaghan, D.; Doherty, G.; Kudrautseva, O.; et al. Data-as-a-service platform for delivering healthy lifestyle and preventive medicine: Concept and structure of the DAPHNE project. JMIR Res. Protoc. 2016, 5, e222. [Google Scholar] [CrossRef]
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, p. 3152676. [Google Scholar]
- Rantos, K.; Drosatos, G.; Demertzis, K.; Ilioudis, C.; Papanikolaou, A.; Kritsas, A. ADvoCATE: A consent management platform for personal data processing in the IoT using blockchain technology. In Proceedings of the International Conference on Security for Information Technology and Communications, Bucharest, Romania, 14–15 November 2018; pp. 300–313. [Google Scholar]
- Larrucea, X.; Moffie, M.; Asaf, S.; Santamaria, I. Towards a GDPR compliant way to secure European cross border Healthcare Industry 4.0. Comput. Stand. Interfaces 2020, 69, 103408. [Google Scholar] [CrossRef]
- Mustafa, U.; Pflugel, E.; Philip, N. A novel privacy framework for secure m-health applications: The case of the GDPR. In Proceedings of the 2019 IEEE 12th International Conference on Global Security, Safety and Sustainability (ICGS3), London, UK, 16–18 January 2019; pp. 1–9. [Google Scholar]
- Sahama, T.; Croll, P. A data warehouse architecture for clinical data warehousing. In Proceedings of the ACSW Frontiers 2007: Proceedings of 5th Australasian Symposium on Grid Computing and e-Research, 5th Australasian Information Security Workshop (Privacy Enhancing Technologies), and Australasian Workshop on Health Knowledge Management and Discovery, Victoria, Australia, 30 January–2 February 2007; pp. 227–232. [Google Scholar]
- Neamah, A.F. Flexible Data Warehouse: Towards Building an Integrated Electronic Health Record Architecture. In Proceedings of the 2020 International Conference on Smart Electronics and Communication (ICOSEC), Tamilnadu, India, 10–12 September 2020; pp. 1038–1042. [Google Scholar]
- Poenaru, C.E.; Merezeanu, D.; Dobrescu, R.; Posdarascu, E. Advanced solutions for medical information storing: Clinical data warehouse. In Proceedings of the 2017 E-Health and Bioengineering Conference (EHB), Sinaia, Romania, 22–24 June 2017; pp. 37–40. [Google Scholar]
- Sweeney, L. Datafly: A system for providing anonymity in medical data. In Database Security XI; Springer: Berlin/Heidelberg, Germany, 1998; pp. 356–381. [Google Scholar]
- Chiang, Y.C.; Hsu, T.s.; Kuo, S.; Liau, C.J.; Wang, D.W. Preserving confidentiality when sharing medical database with the Cellsecu system. Int. J. Med. Inform. 2003, 71, 17–23. [Google Scholar] [CrossRef]
- Agrawal, R.; Johnson, C. Securing electronic health records without impeding the flow of information. Int. J. Med. Inform. 2007, 76, 471–479. [Google Scholar] [CrossRef] [PubMed]
- Prasser, F.; Kohlmayer, F.; Lautenschläger, R.; Kuhn, K.A. ARX—A comprehensive tool for anonymizing biomedical data. In Proceedings of the AMIA Annual Symposium Proceedings. American Medical Informatics Association, Washington, DC, USA, 19–21 May 2014; Volume 2014, p. 984. [Google Scholar]
- Nguyen, T.A.; Le-Khac, N.A.; Kechadi, M.T. Privacy-aware data analysis middleware for data-driven ehr systems. In Proceedings of the International Conference on Future Data and Security Engineering, Ho Chi Minh City, Vietnam, 29 November–1 December 2017; pp. 335–350. [Google Scholar]
- Tran, N.H.; Nguyen-Ngoc, T.A.; Le-Khac, N.A.; Kechadi, M. A Security-Aware Access Model for Data-Driven EHR System. arXiv 2019, arXiv:1908.10229. [Google Scholar]
- Zeilenga, K. Lightweight Directory Access Protocol (LDAP): Technical Specification Road Map; Technical Report, RFC 4510, June; OpenLDAP Foundation: Minden, NV, USA, 2006. [Google Scholar]
- Sun, J.; Gao, Z. Improved mobile application security mechanism based on Kerberos. In Proceedings of the 2019 4th International Workshop on Materials Engineering and Computer Sciences, Bangkok, Thailand, 17–19 May 2019; pp. 108–112. [Google Scholar]
- Tewari, H.; Hughes, A.; Weber, S.; Barry, T. X509Cloud—Framework for a ubiquitous PKI. In Proceedings of the MILCOM 2017—2017 IEEE Military Communications Conference (MILCOM), Baltimore, MD, USA, 23–25 October 2017; pp. 225–230. [Google Scholar]
- US, I.C. Secure and Protect Cassandra Databases with IBM Security Guardium. Available online: https://www.ibm.com/developerworks/library/se-secure-protect-cassandra-databases-ibm-security-guardium-trs/index.html (accessed on 5 October 2020).
- Xiong, L.; Truta, T.M.; Fotouhi, F. Report on international workshop on privacy and anonymity in the information society (PAIS 2008). ACM SIGMOD Rec. 2009, 37, 108–111. [Google Scholar] [CrossRef]
- Rafiei, M.; Wagner, M.; van der Aalst, W.M. TLKC-privacy model for process mining. In Proceedings of the International Conference on Research Challenges in Information Science, Limassol, Cyprus, 23–25 September 2020; pp. 398–416. [Google Scholar]
- 9 次浏览
【数据仓库】Spark让数据仓库现代化

自从十年前在加州大学伯克利分校成立以来,Apache Spark已经起火了。这种分布式内存数据处理平台扼杀了面向批处理,基于磁盘的MapReduce,作为Hadoop,云对象存储数据湖和Kafka流平台的首选引擎。更令人惊讶的是,它正在成为数据仓库领域的一个固定装置,取代传统的提取,转换,加载(ETL)工具,作为填充现代云数据仓库的手段。
主要原因是性能。通过主要处理内存中的数据,Spark避免了不必要的I / O往返磁盘,与之前的产品相比,延迟了几个数量级。另一个原因是开发人员友好。 Spark对Scala,Java,Python和R编程语言的灵活支持鼓励了许多编码团队将其构建到数据湖和流媒体环境中,以便解决机器学习等高级分析用例。对于批处理或流式工作负载,Spark越来越成为首选引擎,由第三个或更多企业部署。
许多EDW团队现在在Spark上运行ETL作业,以提高性能并满足业务的新分析要求。这对于新的云选项特别有吸引力,例如Snowflake的SQL数据仓库,它与Spark平台和Botebook提供商Databricks有着密切的合作关系。当您需要快速,高效地分析大型和不断增长的数据集时,其中一些符合ACID标准,Spark-EDW组合才有意义。
与任何计划一样,Spark-EDW的推出需要严格的规划和执行。本文根据众多企业部署的成功经验和教训提供了一些指导原则。我欢迎你的想法和反馈。
仔细定义您的业务用例。
要回答的第一个问题不是如何设计数据架构,或者是否以及如何使用Spark,而是要准确了解业务用户想要做出的决策。他们是否需要为在线购物者量身定制下一个最佳报价建议,降低欺诈风险或支持运营报告仪表板?指定您的分析问题会形成以下所有内容 - 架构设计,实施过程,Spark配置参数等。(有关“业务发现”与您的数据策略之间相互作用的见解,请查看Dave Well的新博客“The Scope and Complexities of数据战略。“)
清点必要的数据集。
上面的每个用例都很好地映射到数据仓库结构,每个用例都需要数据集和数据类型的独特组合。由购买事件触发的下一个最佳商品推荐的输入可能包括该客户的在线和店内购买历史,他们在供应商网站上的点击流历史以及具有类似简档的客户的预先建立的购买模式。 Spark可以将这些部分加载并转换为统一的,通常格式化的数据集,以便在像雪花这样的EDW中实时推荐或定期分析。在混合中添加其他输入,例如实时跟踪客户的移动购买或应用程序使用情况,可能需要新的收集器或其他组件。
考虑高级算法的作用。
机器学习可以通过自学来改进基于所选择的,经常调整的特征或可变输入的预测来提高上述每个用例的准确性。您输入ML的数据和处理能力越多,它就越有效,这对整体架构设计和规划具有重要意义。 (另请参阅我在Jordan Martz撰写的文章“机器学习数据管理最佳实践”。)
选择您的数据仓库。
Spark可以叠加到传统系统上,以加快您现有的速度。但是现有的基于云的EDW(例如Snowflake和Azure SQL DW)可能会带来更多好处,许多企业已经开始采用这些EDW来更好地吸收快速增长的数据量,种类和速度。这些平台在资源弹性,解耦计算存储可扩展性和经济定价方面具有优势,可以非常有效地为大型Spark友好型工作负载提供服务。
在ETL中定义Spark的角色。
对于具有大型数据集的ETL,Spark性能和吞吐量优势是理想的选择。 Spark可以加速ETL处理,例如通过使用一组编码命令在内存中组合和执行这三个任务(提取,转换和加载)。它还可以简化ELT,这意味着数据一旦到达目标就被提取,加载然后转换。此外,Spark可以帮助发现大数据源,识别数据模式和分类,在提取之前和/或它们在目标上进行整合。所有这些都有助于在EDW环境中更有效地构建和管理新数据类型。
尽可能外包整合工作。
您还可以考虑预先打包的选项,例如Azure Databricks,它可以为您提供开箱即用的许多云,EDW和Spark集成步骤。虽然供应商 - Spark分发版本可能缺少Apache社区的最新功能,但额外的测试通常会使它们更稳定。 Databricks提供经过审查的Spark解决方案,开发人员笔记本,ML框架,管道生产力工具,与各种环境的培训和API集成。 (另请查看我的文章“使用变更数据捕获和Spark的实时数据管道的最佳实践。”)
计划分阶段实施。
与任何雄心勃勃的数据计划一样,Spark EDW项目(内部部署或基于云计算)需要基于陡峭学习曲线的有条理的迭代方法。如果选择在基于云的DW平台上进行现代化,则可能需要将本地数据和元数据迁移到新的DW中,然后创建,调整或移植现有的ETL框架。许多组织从测试试点开始,然后随着时间的推移扩展其云数据集和用例。机器学习需要多个测试阶段,其中软件从训练数据中学习,然后逐步将预测应用于生产数据。这些步骤中的每一步都需要资源和时间要求。
定义您的技能和培训要求。
大多数数据仓库经理都具有ETL和SQL脚本编写工作的长期经验,因此可以更轻松地使用Spark SQL模块执行SQL查询。但是这些传统的DW类型不太熟悉Java,Scala,Python和R,它们是开发Spark作业所需的主要语言。在许多情况下,他们需要新的培训或新的人员(如数据科学家)将Spark应用于数据仓库。
很难低估使用Spark实现数据仓库环境现代化的优势,这就解释了为什么有这么多企业走这条路。 他们在这里总结的经验教训可以成为那些刚开始的人的有用标志。
原文:https://www.eckerson.com/articles/sparking-data-warehouse-modernization
微信公众号:
- 53 次浏览
【数据仓库】数据仓库是否仍然相关?
QQ群
视频号
微信
微信公众号
知识星球
在过去几年中,企业数据架构发生了重大变化,以适应现代企业不断变化的数据需求。 云计算、数据中枢、数据湖等先进数据存储技术的出现,让我们质疑传统数据仓库在现代数据架构中的作用。
数据仓库于 1990 年代作为决策支持系统的关系数据存储空间首次引入; 然而,多年来,它们已经发生了相当大的变化,以支持商业智能 (BI) 和数据驱动的决策制定。
它们对今天的现代企业是否仍然适用? 我们必须回到基础来寻找这个问题的答案。
数据仓库的目的
数据仓库 (DWH) 是一个集中式存储库,它整合和存储来自不同来源的历史数据,以提供组织数据的整体视图。 它包含结构化和标准化的数据,可以有效地满足业务报告的需求。
DWH 包含来自内部来源的数据,例如 CRM、ERP、财务系统和外部系统,例如合作伙伴计划。 从技术上讲,数据随后会根据 DWH 的配置进行结构化和处理,然后以统一形式存储并可用于 BI 报告。
使用数据仓库的好处
数据仓库的主要目的是为组织提供一个用于其他异构源的集中存储库,并使数据可访问以进行快速准确的 BI 报告。
它是怎么做到的?
- 充当单一事实来源:如上所述,数据仓库充当所有数据的中央平台,否则这些数据以分布式 Excel 工作表和不同的事务系统的形式分散在各处。 功能性数据仓库依靠数据建模和 ETL/ELT 流程将异构数据集成到一个地方。 通过这种集成,公司可以同时查看来自不同职能和交易领域(例如运营、销售、财务和营销)的数据,从而获得其组织的 360 度全方位视图。
- 消除数据孤岛:数据存在于孤岛中,被困在不同的数据库中,使其更容易出现差异和歧义。 如果没有数据仓库,业务分析师和决策者将难以手动或通过查询管理来自不同来源的相关数据。 单一事实来源(以数据仓库的形式)消除了数据孤岛并提高了 BI 决策制定的整体质量。
- 提供预定义结构以满足报告需求:数据仓库以结构化格式存储数据。 它使用数据建模(例如维度建模)来根据特定的报告用例定义数据点和实体之间的关系。 数据仓库架构针对更快的数据检索和查询进行了优化。
此外,数据在加载到数据仓库之前会被清理、分析和转换。 这种结构化数据已准备好进行分析,可以被 BI 软件(例如 PowerBI)无缝使用,以实现商业智能。
在数据仓库中拥有结构化数据和模式,而不是数据湖,最终可以更轻松地构建报告查询,尤其是在复杂的关系和转换中。
数据仓库是否仍然相关?
现代数据架构技术已经改变了我们在组织内与数据交互的方式。 大数据、数据湖、数据结构、人工智能和机器学习的出现让我们有更多机会有效地利用数据进行分析和决策。
这会影响数据仓库在现代架构中的相关性吗? 绝对不! 事实上,在数据管道中包含数据湖等平台有助于数据仓库和数据集市满足组织的数据需求。
最重要的是,组织仍然需要一个集中的存储库来维护异构系统中存在的历史数据。 此外,他们仍然需要访问有组织的、结构化的数据,这些数据可以轻松查询以获得及时的 BI 报告。 这表明数据仓库仍然非常重要。
到 2028 年,数据仓库市场预计将以 24.5% 的复合年增长率增长到 76.9 亿美元也就不足为奇了。大多数数据驱动的组织仍然使用数据仓库作为其数据架构的一个组成部分,并将继续这样做 可以预见的将来。
- 6 次浏览
【数据仓库】比以往任何时候都快Apache Doris在Orange Connex中的数据仓库实践
QQ群
视频号
微信
微信公众号
知识星球
简介:为了满足快速增长的需求,Orange Connex于2022年正式引入了Apache Doris,并与Apache Doris构建了新的数据仓库架构。在此过程中,对服务稳定性、查询稳定性和数据同步等各个方面进行了优化。同时,建立了一个基于Apache Doris的数据平台。同时,在使用和优化方面积累了很多经验,我将与大家分享。
作者|付帅| Orange Connex大数据部首席开发者。
背景
简介:为了满足快速增长的需求,Orange Connex于2022年正式引入了Apache Doris,并与Apache Doris构建了新的数据仓库架构。在此过程中,对服务稳定性、查询稳定性和数据同步等各个方面进行了优化。同时,建立了一个基于Apache Doris的数据平台。同时,在使用和优化方面积累了很多经验,我将与大家分享。
Orange Connex(新三板:870366)是一家服务于全球电子商务的科技公司。致力于通过市场分析、系统研发和资源整合,为客户提供物流、金融、大数据等服务产品,提供高质量、全方位的解决方案。作为易趣的合作伙伴,Orange Connex的易趣履行提供了一种特殊的交付方式,包括次日交付、当天处理和延迟截止时间。
随着公司业务的发展,早期基于MySQL的传统数据仓库架构已经无法应对公司数据的快速增长。业务和决策对数据仓库的数据及时性和实时性有着强烈的要求。为了满足快速增长的需求,Orange Connex于2022年正式引入了Apache Doris,并与Apache Doris构建了新的数据仓库架构。在此过程中,对服务稳定性、查询稳定性、数据同步等方面进行了优化。同时,已经建立了一个以Apache Doris为核心的数据平台,并积累了大量的使用和优化经验,我将与大家分享。
数据架构演进
|早期数据仓库架构
公司刚起步时,业务规模相对较小,只有少数数据团队成员。对数据的需求仅限于少量的T+1定制报告。因此,早期的数据仓库架构相当简单。如下图所示,MySQL直接用于构建DM(Data Mart),以开发需要来自需求侧的T+1数据的报告。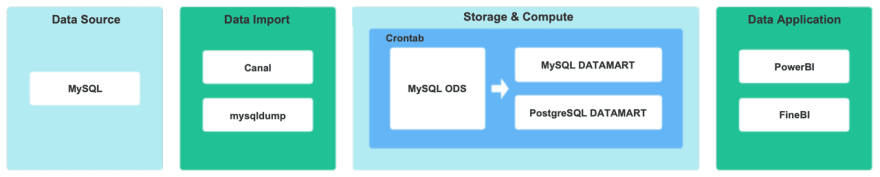
存在的问题
使用MySQL进行数据分析越来越无法满足公司扩张、数据量爆发和数据及时性的要求。
没有数据仓库的划分。烟囱式开发模型数据可重用性差,开发成本高,不能快速响应业务需求。
缺乏对数据质量和元数据管理的控制。
|新的数据仓库基础架构
为了解决旧架构日益突出的问题,适应快速增长的数据和业务需求,Apache Doris于今年正式推出,用于构建新的数据仓库基础设施。
选择Apache Doris的原因:
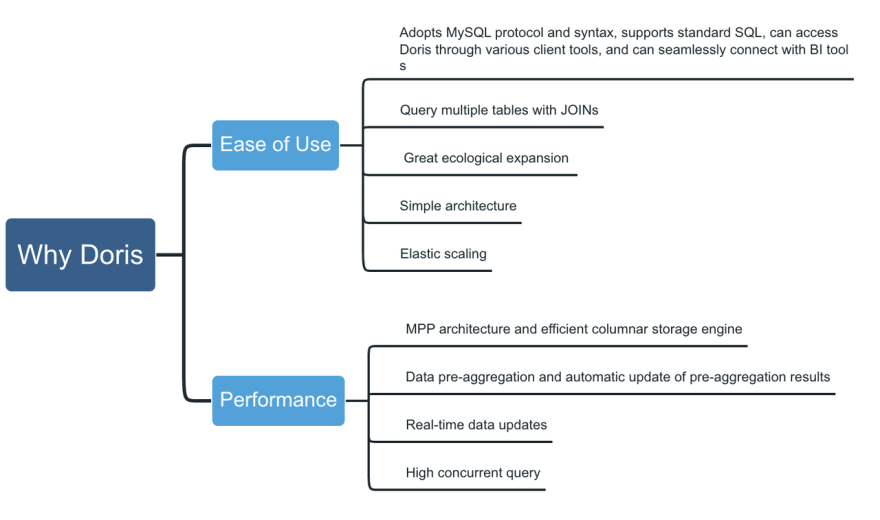
- 易用性-在当前的应用程序中,新技术的引入将面临大量的迁移问题,因此必须考虑产品的可用性问题。Apache Doris对新用户非常友好,迁移成本和维护成本都很低:
- 它采用MySQL协议和语法,支持标准SQL,可以通过各种客户端工具访问Doris,并可以与BI工具无缝连接
- 它可以使用JOIN查询多个表,并在不同的场景中为JOIN提供各种优化
- 生态扩张是巨大的。它既可以有效地批量导入离线数据,也可以实时导入在线流数据。
- 与业界其他流行的OLAP数据库相比,Apache Doris的架构更简单,只有FE(前端)和BE(后端)两个进程。而且它不依赖于任何第三方系统或工具。
它支持弹性伸缩,对部署、操作和维护非常友好。
性能-多表中有很多JOIN操作,对多表JOIN操作和实时查询的查询性能要求极高。Apache Doris基于MPP架构实现,并配有高效的柱状存储引擎,可支持:
- 数据预聚合和预聚合结果的自动更新
- 实时更新数据
- 高并发查询基于上述原因,我们最终选择使用ApacheDoris构建一个新的数据仓库。
架构简介

Apache Doris的数据仓库架构非常简单,不依赖Hadoop组件,并且建设和维护成本较低。
如上面的架构图所示,我们有4种类型的数据源:业务数据MySQL、文件系统CSV、事件跟踪数据和第三方系统API;对于不同的需求,使用了不同的数据导入方法,例如:我们使用Doris Stream Load进行文件数据导入;我们使用DataX Doriswriter进行数据初始化;我们使用Flink Doris连接器进行实时数据同步;在数据存储和计算层,我们使用Doris。当我们为Doris设计层时,我们采用ODS(操作数据存储数据,也称为源层)、细节层DWD、中间层DWM、服务层DWS、应用层ADS作为我们的层设计思想。ODS之后的分层数据通过Dolphin Scheduler调度Doris SQL进行增量和完整的数据更新。最后,上层数据应用程序使用一站式数据服务平台,该平台可以与Apache Doris无缝连接,提供自助分析报告、自助数据检索、数据dashbord和用户行为分析等数据应用服务。
基于Apache Doris的数据仓库架构解决方案可以支持离线和实时应用场景,实时Apache Doris数据仓库可以覆盖80%以上的业务场景。这种架构大大降低了研发成本,提高了开发效率。
当然,在建筑施工过程中也存在一些问题和挑战,我们已经对这些问题进行了相应的优化。
Apache Doris元数据管理和数据行实现方案
在没有元数据管理和数据沿袭之前,我们经常会遇到一些问题。例如,我们想找到一个指标,但不知道指标在哪个表中。我们只能找到相关的开发人员来确认。当然,也有一些开发人员忘记了指标。位置和逻辑案例。因此,只能通过层层筛选来确认,这是非常耗时的。
以前,我们将表格的层次划分、指标和负责人等信息放在Excel表格中。这种维护方法很难保证其完整性,同时也很难维护。当数据仓库需要优化时,无法确认哪些表可以重用,哪些表可以合并。当需要更改表结构或修改指标的逻辑时,无法确定更改是否会影响下游表。
我们经常收到用户的投诉。接下来,我们将介绍如何通过元数据管理和数据沿袭分析解决方案来解决这些问题。
|解决方案
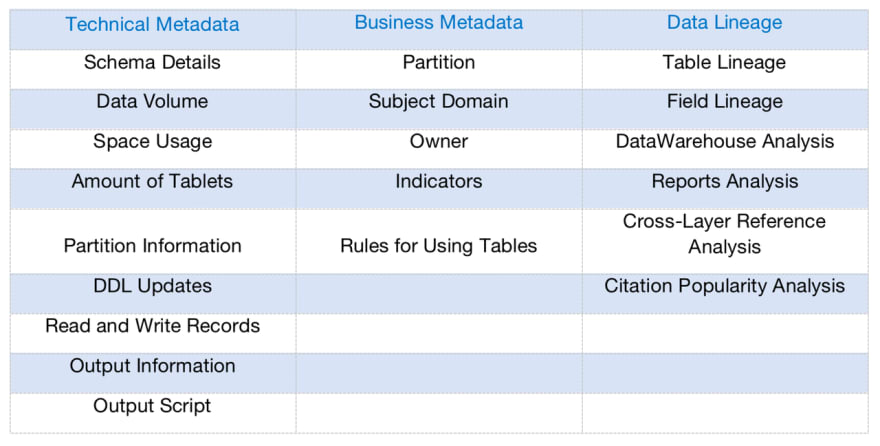
元数据管理和数据沿袭围绕ApacheDoris展开,同时集成DolphinSchedur的元数据。在上图中,右表是技术元数据业务,可以提供元数据指标和数据沿袭分析的数据服务。
我们将元数据分为两类:技术元数据和业务元数据:
- ·技术元数据维护表的属性信息和调度信息
- ·业务元数据维护数据应用过程中约定的口径和规范信息
- 数据沿袭实现了表级沿袭和字段级沿袭:
- ·表级沿袭支持粗略的表关系和跨层引用分析
- ·字段级沿袭支持细粒度影响分析
接下来,我们将介绍元数据管理和数据沿袭的架构和工作原理。
|架构
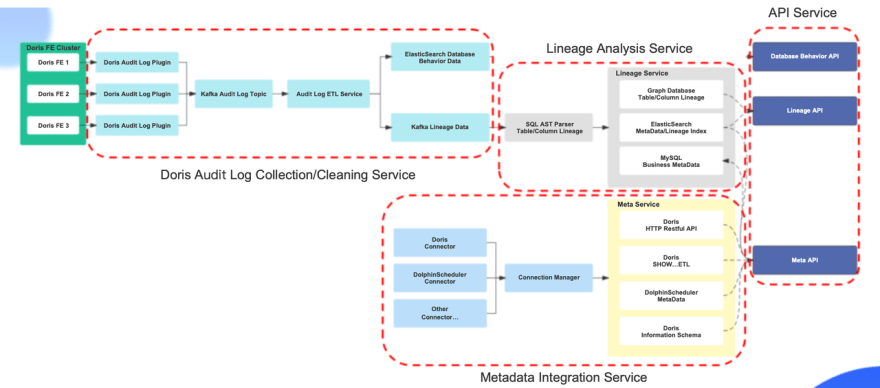
元数据管理和数据行实现解决方案
- ·数据收集:使用Apache Doris提供的审计日志插件Doris audit Plugin进行数据收集
- ·数据存储:定制开发审计日志插件,使用Kafka存储Doris审计日志数据
- ·血统解析:使用Druid进行Doris SQL解析
- ·血缘关系存储:使用星云图存储血统数据
- ·业务元数据:由于业务元数据经常发生CRUD,MySQL用于存储业务元数据信息
- ·搜索数据:使用ElasticSearch存储数据沿袭查询索引和表的搜索索引数据
接下来,我们将介绍该架构的四个组件:审计日志收集和清理服务、数据沿袭分析服务、元数据信息集成服务和应用程序接口服务。
Apache Doris审核日志的收集/清理服务
考虑到如果将数据清理逻辑放在审计日志插件中,当数据清理逻辑发生变化时,可能会出现数据遗漏,从而影响血统分析和元数据管理。因此,我们将审计日志插件的数据收集和数据清理过程解耦。转换后,审计日志插件可以格式化审计日志数据,并将数据发送给Kafka。数据清理服务首先在清理逻辑中添加数据重排逻辑,并对多个审计日志插件发送的数据进行重新排序,以解决数据无序的问题。其次,将非标准SQL转换为标准SQL。尽管Apache Doris支持MySQL协议和标准SQL语法,但仍有一些表构建语句和SQL查询语法与标准SQL不同。因此,我们将非标准SQL转换为MySQL标准语句。最后,数据可以发送到ES和Kafka。
数据谱系分析服务
数据沿袭分析服务使用Druid解析DorisSQL,并通过Druid抽象语法树逐层递归地获取表和字段之间的数据。最后,数据谱系被封装并发送到图形数据库,线性分析查询索引被发送到ES。在分析过程中,技术元数据和业务元数据被发送到相应的存储位置。
元数据信息集成服务
元数据信息集成服务借鉴了Metacat的架构实现。
- ·连接器管理器负责在Apache Doris和Dolphin Scheduler之间创建元数据链接,并支持其他类型数据源访问的后续扩展。
- ·元数据服务负责元数据信息获取的具体实现。Apache Doris元数据信息主要从信息Schema库、Restful API和SHOW SQL的查询结果中获取。DolphinSchedur的工作流元数据信息和调度记录信息是从DolphinSheedur元数据库中获得的。
API服务
我们提供3种类型的API,数据沿袭API、元数据API和数据行为API。
- ·数据沿袭API为表、字段、数据行和影响分析提供查询服务。
- ·元数据API提供元数据查询和字段搜索服务。
- ·数据行为分析API为表结构更改记录、数据读写记录和输出信息提供查询服务。
以上是元数据管理和数据谱系分析架构总体方案的全部内容介绍。
总结
今年,我们使用Apache Doris完成了实时数据仓库的构建。经过半年的使用和优化,Apache Doris已经变得稳定,可以满足我们的生产要求。
新的实时数据仓库极大地提高了数据计算效率和数据及时性。以准时交付业务场景为例,要计算1000w单轨节点的老化变化,在使用Apache Doris之前需要2个多小时的计算,并且计算消耗了大量资源。非峰值计算只能在空闲时段期间执行;Doris之后,只需3分钟即可完成计算。每周更新一次的全链路物流时效表,现在可以每10分钟更新一次最新数据,实现数据实时时效。
得益于Apache Doris的标准化SQL,入门难度小,学习成本低,所有员工都可以参与表的迁移。原始表格是使用PowerBI开发的,这需要对PowerBI有非常深入的了解。学习成本很高,而且开发周期非常长。此外,PowerBI不使用标准SQL,代码可读性差;现在它是基于Doris SQL和自主开发的拖放。表的开发成本直线下降,大多数需求的开发周期从几周下降到几天。
未来计划
未来,我们还将继续推进基于Apache Doris的数据平台建设,并继续优化元数据管理和数据谱系的解析率。考虑到数据沿袭是每个人都想要的应用程序,我们将考虑在优化后将其贡献给社区。
与此同时,我们正在开始构建一个用户行为分析平台,我们也在考虑使用Apache Doris作为核心存储和计算引擎。目前,Apache Doris在一些分析场景中支持的功能还不够丰富。例如,在有序窗口漏斗分析场景中,尽管Apache Doris支持window_funnel函数,但尚未支持计算每一层漏斗变换所需的Array相关计算函数。幸运的是,即将推出的Apache Doris 1.2版本将包括Array类型和相关功能。相信Apache Doris将在未来越来越多的分析场景中实现。
作者简介:傅帅,Orange Connex(中国)有限公司有限公司数字团队大数据研发经理,负责数字团队的数据平台和OLAP引擎的应用。
- 37 次浏览
【数据仓库】现代数据仓库坏了吗?

The modern data warehouse architecture creates problems across many layers. Image courtesy of Chad Sanderson.
数据仓库是现代数据堆栈的基础,所以当我们看到 Convoy 数据负责人 Chad Sanderson 在 LinkedIn 上宣称“数据仓库坏了”时,它引起了我们的注意。
当然,Chad 指的不是技术,而是它的使用方式。
在他看来,数据质量和可用性问题源于传统的最佳实践,即在仓库中“转储”数据,然后对其进行操作和转换以满足业务需求。这与 Snowflake 和 Databricks 等提供商为确保其客户在存储和消费方面的效率(换句话说,节省资金和资源)所做的一般努力并不不一致。
无论您是否同意下面详述的 Chad 的方法,无可争议的是他的观点如何引发大量辩论。
“一个阵营生我的气,因为他们认为这不是什么新鲜事,它需要长期的手动流程和具有 30 年经验的数据架构师。另一个阵营生我的气,因为他们的现代数据堆栈从根本上不是这样设置的,这也不是他们构建数据产品的方式,”Chad 说。
我会让您自己决定“不可变数据仓库”(或主动与被动 ETL)是否适合您的数据团队。
无论哪种方式,我都强烈支持推动我们的行业向前发展,不仅需要对数据仓库和数据可观察性平台等技术的概述,还需要就如何部署它们进行坦诚的讨论和独特的视角。
我们会让乍得从这里拿走它。
不可变数据仓库如何结合规模和可用性
乍得桑德森的观点
现代数据堆栈有许多排列,但数据仓库是一个基础组件。过度简化:
- 数据通过被动管道(实际上只是 ETL 中的“E”)提取并转储到……
- 一个数据仓库,在它被处理和存储之前……
- 转换为数据消费者所需的格式……
- 特定用途,例如分析仪表板、机器学习模型或在 Salesforce 或 Google Analytics 等记录系统中的激活……
- 借助跨堆栈运行的技术或流程,例如数据可观察性、治理、发现和编目。
在深入探讨这种方法的挑战和建议的替代方案之前,值得探索一下我们是如何得出我们所定义的“现代数据堆栈”的。
我们是怎么来到这里的?
在数据的早期,在 Bill Inmon 等先驱者的带领下,最初的 ETL(提取、转换、加载)过程涉及从源中提取并在进入数据仓库之前对其进行转换。
许多企业今天仍然以这种方式运作。对于数据质量至关重要的大型公司,此过程涉及手动、密集的治理框架,数据工程师和嵌入不同领域的数据架构师之间紧密耦合,以便快速利用数据获得运营洞察力。
谷歌、Facebook 等科技巨头放弃了这一过程,开始将几乎所有内容都倾倒在数据仓库中。对于快速成长的初创公司来说,逻辑组织数据的投资回报率并没有这个更快、更具可扩展性的过程那么高。更不用说,加载(ELT 中的“L”)变得更容易集成到云中。
一路走来,流行的转换工具使仓库中的数据转换比以往任何时候都容易。模块化代码和显着减少的运行时间使 ETL 模型从根本上不那么痛苦……以至于流行的转换工具的使用从数据工程师扩展到数据消费者,如数据科学家和分析师。
似乎我们找到了一个新的最佳实践,我们正在走向事实上的标准化。如此之多,以至于提出替代方案会引起迅速而强烈的反应。
被动 ETL 或仓库转换的挑战
一旦数据进入数据仓库,严重依赖于转换数据的架构和流程存在几个问题。
- 第一个问题是数据消费者(分析师/数据科学家)和数据工程师之间产生的脱节,真正的鸿沟。
项目经理和数据工程师将在分析师的上游建立管道,分析师的任务是回答内部利益相关者提出的某些业务问题。不可避免地,分析师会发现数据并不能回答他们所有的问题,并且项目经理和数据工程师已经继续前进。
- 当分析师的反应是直接进入仓库并编写一个脆弱的 600 行 SQL 查询以获得他们的答案时,就会出现第二个挑战。或者,数据科学家可能会发现他们构建模型的唯一方法是从生产表中提取数据,这些生产表作为服务的实现细节运行。
生产表中的数据不适用于分析或机器学习。事实上,服务工程师经常明确声明不要对这些数据采取关键依赖关系,因为它可能随时发生变化。然而,我们的数据科学家需要完成他们的工作,所以无论如何他们都会这样做,当表格被修改时,一切都会在下游中断。
- 第三个挑战是,当您的数据仓库成为垃圾场时,它就会变成数据垃圾场。
Hadoop 时代的一项较早的 Forrester 研究发现,企业内 60% 到 73% 的所有数据未用于分析。希捷最近的一项研究发现,企业可用的数据中有 68% 未被使用。
结果,数据科学家和分析师花费了太多时间在过度处理的生产代码大海捞针中搜索上下文。作为数据工程师,除了数据质量,我们还需要强调数据的可用性。
如果您的用户无法在您当前的数据仓库中可靠地找到和利用他们需要的东西,那有什么意义呢?
另一种方法:引入不可变数据仓库
不可变数据仓库概念(也称为活动 ETL)认为,仓库应该是通过数据来表示现实世界,而不是乱七八糟的随机查询、损坏的管道和重复信息。
有五个核心支柱:
- #1 映射业务并分配所有者。为了让企业真正从他们拥有的大量数据中获得价值,团队需要退后一步,在通过代码定义实体和事件之前对他们的业务进行语义化建模,以用于明确的分析目的。这可以是一个迭代过程,从业务中最关键的元素开始。
实体关系图 (ERD) 是基于真实世界的业务图,而不是当今数据仓库或生产数据库中存在的图。它定义了关键实体、它们的关系(基数等)以及表明它们已经交互的真实世界动作。为每个实体和事件建立一个工程所有者。端到端自动化沿袭可以帮助建立 ERD 并使其可操作。
- #2 数据消费者预先定义他们的需求并创建合同。也许最有争议的租户是数据应该从业务需求中冒出来,而不是从非结构化管道中涓涓细流。不是数据分析师和科学家在仓库的尘土飞扬的货架上梳理,看看是否有足够接近他们需要的数据集,除非数据消费者首先直接请求和定义数据,否则不会有数据进入仓库。
没有业务问题、流程或驱动问题的数据进入仓库。一切都是为完成任务而设计的。
这个过程必须设计得简单,因为数据需求总是在变化,增加的摩擦将威胁采用。在 Convoy,实施新合同需要几分钟到几小时,而不是几天到几周。
接下来,是时候起草数据合同了,这是业务和工程主管之间关于事件/实体的架构应该是什么以及该资产最有效最需要的数据的协议。例如,现有的 inboundCall 事件可能缺少 OrderID,这使得很难将电话呼叫与已完成的订单联系起来。
SLA、SLI 和 SLO 是一种数据合同类型,您可以将其应用于这种变更管理和利益相关者对齐模型。
- #3 在活跃环境中同行评审的文档。同样,我们需要对投入生产的代码 (GitHub) 或 UX (Figma) 进行同行评审,数据资产也应该有一个等价物。但是,本次审查的正确抽象级别不是代码,而是语义。
该审查过程应该具有与 GitHub 拉取请求相同的结果——版本控制、相关方的签署等——所有这些都通过云处理。通过应用基于云的现代技术,我们可以加速旧流程,使其在增长最快的互联网业务中更加可行。
数据目录可以作为数据仓库定义前的表面,但挑战在于数据消费者要保持元数据最新,没有胡萝卜也没有大棒。对于使用 ELT 流程并完成模型返回并记录其工作的数据科学家的动机是什么?
- #4 数据通过管道传输到合同中定义的预先建模的仓库。转换发生在消费层的上游(最好是在服务中)。然后,工程师在他们的服务中实施数据合同。数据通过管道传输到数据仓库,理想情况下,元数据可以通过建模自动加入和分类。
- #5 重点放在防止数据丢失以及确保数据的可观察性、完整性、可用性和生命周期管理上。事务发件箱模式用于确保生产系统中的事件与数据仓库中的事件匹配,而日志和偏移处理模式(我们在 Convoy 广泛使用)可防止数据丢失。这两个系统一起确保数据以完整的完整性保存,因此不可变数据仓库是整个业务中发生的事情的直接表示和真实来源。
数据质量和可用性需要两种不同的心态。 数据质量在很大程度上是一项技术挑战。 想想“后端”工程。 另一方面,数据可用性是一项“前端”工程挑战,需要用于创造出色客户体验的相同技能。 最后,不可变数据仓库不适用于 PB 测量竞赛和大数据统计。 弃用和维护与配置一样重要。
这种方法利用技术的优势来实现两全其美。 传统方法的治理和业务驱动方法,具有与现代数据堆栈相关的速度和可扩展性。
不可变数据仓库的工作原理。 像 API 一样处理数据。
The layers of an immutable data warehouse. Image courtesy of Chad Sanderson
让我们先回顾一下围绕不可变数据仓库的完整堆栈。
- 1. 描述层:与传统仓库不同,描述层将业务逻辑移至服务层之上,并将数据消费者置于驾驶座上。消费者能够提供他们的要求而无需技术技能,因为数据工程师是代码翻译的关键要求。这些合同可以保存在数据目录甚至通用文档存储库中。
- 2. 数据仓库:仓库主要用作“数据展示”和底层计算层。
- 3. 语义层:数据消费者构建经过验证并与业务共享的数据产品。语义层中的资产应该被定义、版本化、审查,然后通过 API 提供给应用层使用。
- 4. 应用层:这是使用数据完成某些业务功能的地方,例如实验、机器学习或分析。
- 5. 端到端支持:支持跨数据堆栈的数据操作的解决方案,例如数据可观察性、目录、测试、治理等。理想的情况是一旦数据进入仓库就拥有完美的、预先建模的、高度可靠的数据,但您仍然需要涵盖现实世界可能向您抛出的所有排列(并在流程超出范围时具有强制机制)。
不可变数据仓库本身是为流式设计的——从流式数据到批处理数据比反之更容易——因此由三种不同类型的 API 提供。
- 语义事件 API:此 API 用于作为公司核心构建块的语义真实世界服务级别事件,而不是来自前端应用程序的事件。例如,在 Convoy 的情况下,这可能是在创建货件或暂停货件时。来自现实世界的事件构建在服务代码中,而不是 SQL 查询中。
- CRUD 抽象 API:数据消费者不需要查看所有生产表,特别是当它们只是他们用来生成洞察力或权力决策的数据服务的实现细节时。相反,当更新生产表中数据资产的属性时,API 包装器或抽象层(例如 dbt)将公开对仓库中的数据消费者有意义的 CRUD 概念——例如,无论是否数据是新的或行量在预期的阈值内。
- 前端 API:已经有许多工具可以处理前端事件定义和发射,例如 Snowplow、Mixpanel 和 Amplitude。话虽如此,一些前端事件非常重要,团队需要能够使用长偏移管道来确保其交付和完整性。在某些情况下,前端事件对于机器学习工作流程至关重要,而“足够接近”的系统无法解决它。
随着事情的变化(也许一项服务需要变得很多),或者如果数据科学家心目中的模式与现实世界中发生的事情不相符,还需要一个位于仓库外部的映射层。
映射应该通过流式数据库在仓库上游或在仓库本身中处理。这一层是 BI 工程师将工程中的内容与数据消费者需要的内容相匹配的地方,可以自动化生成 Kimball 数据集市。
不可变数据仓库也面临挑战。以下是一些可能的解决方案。
我并不认为不可变数据仓库是灵丹妙药。与任何方法一样,它也有其优点和缺点,而且肯定不是每个组织都适用。
与数据网格和其他崇高的数据架构计划一样,不可变数据仓库是一种理想状态,很少成为现实。实现一个——或试图实现一个——是一个旅程,而不是一个目的地。
应该考虑和缓解的挑战是:
- 定义描述层的前期成本
- 处理没有明确所有权的实体
- 实施新方法以实现快速实验
虽然定义描述层是有成本的,但它可以通过软件大大加速,并通过优先考虑最重要的业务组件来迭代完成。
这需要包括数据工程师在内的协作设计工作,以防止数据质量责任在分布式数据消费者之间分散。如果你第一次没有做对也没关系,这是一个迭代过程。
处理没有明确所有权的实体可能是一个棘手的治理问题(并且经常困扰数据网格支持者)。在业务方面对这些问题进行分类通常不在数据团队的职权范围内。
如果有一个跨多个团队的核心业务概念是由单体而不是微服务生成的,那么最好的前进方式是建立一个强大的审查系统和一个专门的团队随时待命以进行更改。
仍然可以允许数据工程师进行实验并给予灵活性,而不会限制工作流程。一种方法是通过单独的暂存层。但是,不应允许下游或跨外部团队使用来自这些暂存区域的 API 数据。
关键是,当你从实验转移到生产或让边境团队可以访问时,它必须经过相同的审查过程。就像在软件工程中一样,你不能仅仅因为你想更快地移动而在没有审查过程的情况下进行代码更改。
祝您在数据质量之旅中好运
现代数据堆栈有许多排列,作为一个行业,我们仍在经历一个实验阶段,以了解如何最好地铺设我们的数据基础设施。
很明显,我们正在迅速迈向未来,在这个未来,更多的关键任务、面向外部和复杂的产品都由数据仓库“提供支持”。
无论选择何种方法,这都要求我们作为数据专业人士提高标准,并加倍努力以实现可靠、可扩展、可用的数据。无论类型如何,数据质量都必须是所有数据仓库的核心。
从我的角度来看,底线是:当你建立在一个巨大的、无定形的基础上时,东西会破裂并且很难找到。当你找到它时,很难弄清楚那个“东西”到底是什么。
不可变与否,也许是我们尝试新事物的时候了。
原文:https://towardsdatascience.com/is-the-modern-data-warehouse-broken-1c9c…
- 31 次浏览
【数据仓库技术】怎么选择现代数据仓库
构建自己的数据仓库时要考虑的基本因素

在开发一个开源分析框架立方体时。js,我们用过很多数据仓库。当我们的客户问我们,对于他们成长中的公司来说,最好的数据仓库是什么时,我们会根据他们的具体需求来考虑答案。通常,他们需要几乎实时的数据,价格低廉,不需要维护数据仓库基础设施。在这种情况下,我们建议他们使用现代的数据仓库,如Redshift, BigQuery,或Snowflake。
大多数现代数据仓库解决方案都设计为使用原始数据。它允许动态地重新转换数据,而不需要重新摄取存储在仓库中的数据。
在这篇文章中,我们将深入探讨在选择数据仓库时需要考虑的因素。在这里,他们是:
- 数据量
- 专门负责人力资源的支持和维护
- 可伸缩性:水平与垂直
- 定价模型
数据量
您需要知道将要处理的数据量的估计。如果您使用的数据集的范围是数百tb或pb,那么强烈建议使用非关系数据库。这类数据库的架构支持与庞大的数据集的工作是根深蒂固的。
另一方面,许多关系数据库都有非常棒的经过时间验证的查询优化器。只要您的数据集适合于单个节点,您就可以将它们视为分析仓库的选项。
让我们看看一些与数据集大小相关的数学:
将tb级的数据从Postgres加载到BigQuery
- Postgres、MySQL、MSSQL和许多其他RDBMS的最佳点是在分析中涉及到高达1TB的数据。如果超过此大小,则可能会导致性能下降。
- Amazon Redshift、谷歌BigQuery、SnowflPBake和基于hadoop的解决方案以最优方式支持最多可达多个PB的数据集。
本地和云
要评估的另一个重要方面是,是否有专门用于数据库维护、支持和修复的资源(如果有的话)。这一方面在比较中起着重要的作用。
如果您有专门的资源用于支持和维护,那么在选择数据库时您就有了更多的选择。
您可以选择基于Hadoop或Greenplum之类的东西创建自己的大数据仓库选项。这些系统确实需要大量的安装、维护工程资源和熟练的人员。
但是,如果您没有任何用于维护的专用资源,那么您的选择就会受到一些限制。我们建议使用现代的数据仓库解决方案,如Redshift、BigQuery或Snowflake。作为管理员或用户,您不需要担心部署、托管、调整vm大小、处理复制或加密。您可以通过发出SQL命令开始使用它。
可伸缩性
当您开始使用数据库时,您希望它具有足够的可伸缩性来支持您的进一步发展。广义上说,数据库可伸缩性可以通过两种方式实现,水平的或垂直的。
水平可伸缩性指的是增加更多的机器,而垂直可伸缩性指的是向单个节点添加资源以提高其性能。
Redshift提供了简单的可伸缩选项。只需单击几下鼠标,就可以增加节点的数量并配置它们以满足您的需要。在一次查询中同时处理大约100TB的数据之前,Redshift的规模非常大。Redshift集群的计算能力将始终依赖于集群中的节点数,这与其他一些数据仓库选项不同。
这就是BigQuery这样的解决方案发挥作用的地方。实际上没有集群容量,因为BigQuery最多可以分配2000个插槽,这相当于Redshift中的节点。另外,由于这种多租户策略,即使当客户的并发性需求增长时,BigQuery也可以与这些需求无缝伸缩,如果需要,可以超过2000个插槽的限制。
BigQuery依赖于谷歌最新一代分布式文件系统Colossus。Colossus允许BigQuery用户无缝地扩展到几十PB的存储空间,而无需支付附加昂贵计算资源的代价。
ETL vs ELT:考虑到数据仓库的发展
Snowflake构建在Amazon S3云存储上,它的存储层保存所有不同的数据、表和查询结果。因为这个存储层被设计成完全独立于计算资源的可伸缩性,它确保了可以毫不费力地为大数据仓库和分析实现最大的可伸缩性。
除此之外,Snowflake还提供了几乎任何规模和并发性的多个虚拟仓库,可以同时对相同的数据进行操作,同时完全强制执行全局系统范围的事务完整性,并保持其可伸缩性。
定价
如果您使用像Hadoop这样的自托管选项,那么您的定价将主要由VM或硬件账单组成。AWS提供了一种EMR解决方案,在使用Hadoop时可以考虑这种方案。
再深入研究Redshift、BigQuery和Snowflake,他们都提供按需定价,但每个都有自己独特的定价模式。
亚马逊红移提供三种定价模式:
- 按需定价:无需预先承诺和成本,只需根据集群中节点的类型和数量按小时付费。这里,一个经常被忽略的重要因素是,税率确实因地区而异。这些速率包括计算和数据存储。
- 频谱定价:您只需为查询Amazon S3时扫描的字节付费。
- 保留实例定价:如果您确信您将在Redshift上运行至少几年,那么通过选择保留实例定价,您可以比按需定价节省75%。
谷歌BigQuery提供可伸缩、灵活的定价选项,并对数据存储、流插入和查询数据收费,但加载和导出数据是免费的。BigQuery的定价策略非常独特,因为它基于每GB存储速率和查询字节扫描速率。此外,它提供了成本控制机制,使您能够限制您的每日成本数额,您选择。它还提供了一个长期定价模式。
Snowflake提供按需定价,类似于BigQuery和Redshift Spectrum。与BigQuery不同的是,计算使用量是按秒计费的,而不是按扫描字节计费的,至少需要60秒。Snowflake将数据存储与计算解耦,因此两者的计费都是单独的。
标准版的存储价格从40美元/TB/月开始,其他版本的存储价格也一样。另一方面,对于计算来说,标准版的价格为每小时2.00美元,企业版为每小时4.00美元。
结论
我们通常向客户提供的关于选择数据仓库的一般建议如下:
- 当数据总量远小于1TB,每个分析表的行数远小于500M,并且整个数据库可以容纳到一个节点时,使用索引优化的RDBMS(如Postgres、MySQL或MSSQL)。
- 当数据量在1TB到100TB之间时,使用现代数据仓库,如Redshift、BigQuery或Snowflake。也可以考虑使用Hadoop和Hive、Spark SQL或Impala作为解决方案,如果你有相关的专业知识,你可以分配专门的人力资源来支持它。
- 当数据量超过100TB时,使用BigQuery、Snowflake、Redshift Spectrum或自托管的Hadoop等效解决方案。
原文:https://statsbot.co/blog/modern-data-warehouse/
本文:http://jiagoushi.pro/node/1212
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 62 次浏览
【数据仓库架构】云数据仓库基准:Redshift、Snowflake、Azure、Presto和BigQuery
Fivetran数据仓库基准比较了Azure、BigQuery、Presto、Redshift和Snowflake的价格、性能和差异化功能。
2018年9月更新
Fivetran是一个数据管道,它将来自应用程序、数据库和文件存储的数据同步到我们客户的数据仓库中。我们经常被问到的问题是,“我应该选择什么数据仓库?“为了更好地回答这个问题,我们对五个最流行的数据仓库的速度和成本进行了基准比较:
- Amazon Redshift
- Snowflake
- Azure Synapse
- Presto
- Google BigQuery
基准测试都是为了做出选择:我将使用什么样的数据?多少钱?什么样的问题?如何做出这些选择非常重要:更改数据的形状或查询的结构,最快的仓库可能成为最慢的仓库。我们试图以一种代表典型Fivetran用户的方式做出这些选择,因此结果将对使用Fivetran的公司有用。
典型的Fivetran用户可能会将Salesforce、Zendesk、Marketo、Adwords及其生产MySQL数据库同步到数据仓库中。这些数据源并没有那么大:一个典型的数据源将包含数十到数百千兆字节。它们很复杂:它们在规范化模式中包含数百个表,我们的客户编写复杂的SQL查询来汇总这些数据。
此基准测试的源代码可以在https://github.com/fivetran/benchmark上找到。
我们查询了哪些数据?
我们以100GB和1TB的规模生成了TPC-DS[1]数据集。TPC-DS在雪花模式中有24个表;这些表表示虚拟零售商的web、目录和商店销售。最大的事实表在100GB级别上有4亿行,在1TB级别上有40亿行[2]。
我们运行了哪些查询?
2018年8-9月,我们运行了99个TPC-DS查询[3]。这些查询很复杂:它们有很多连接、聚合和子查询。我们只运行每个查询一次,以防止仓库缓存以前的结果。
因为每个查询只运行一次,所以这些时间包括编译查询和运行查询的时间。Redshift尤其对这种假设非常敏感;它编译这些查询所花费的时间比运行它们所花费的时间要多。我们将在深入研究中进一步探讨这个问题。
我们是如何配置仓库的?
我们以100GB和1TB的大小配置设置每个仓库:
| 100 GB | 1TB | |||
|---|---|---|---|---|
| Configuration | Cost / Hour | Configuration | Cost / Hour | |
| Redshift | 8x dc2.large | $2.00 | 4x dc2.8xlarge | $19.20 |
| Snowflake | X-Small | $2.00 | Large | $16.00 |
| Azure [4] | DW200 | $2.42 | DW1500c | $18.12 |
| Presto [5] | 4x n1-standard-8 | $1.23 | 32x n1-standard-8 | $9.82 |
| BigQuery [6] | On-demand | On-demand |
我们是如何调整仓库的?
这些数据仓库都提供高级功能,如排序键、集群键和日期分区。我们选择在基准测试中不使用这些特性。我们确实在Redshift中应用了列压缩编码;Snowflake、Azure和BigQuery自动应用压缩;Presto在HDFS中使用了ORC文件,这是一种压缩格式。
我们在深入研究中探索了各种优化调整:
https://get.fivetran.com/datawarehouse-benchmarks.html
结果
哪个数据仓库最快?
所有的仓库都有很好的执行速度,适合于特别的、交互式的查询。
Redshift的速度较慢主要是因为它的查询规划器较慢;在重复运行类似查询的情况下,第二个查询将快得多。
Azure在100GB级别上的速度较慢是因为使用了Gen1架构;Gen2架构在较小的仓库中还不可用。
哪个数据仓库最便宜?
BigQuery对每个查询收费,因此我们将显示Google云计算的实际成本。为了计算其他仓库的每个查询的成本,我们假设了一个典型的仓库空闲的时间。例如,如果您以每小时2美元的价格运行一个Snowflake X小型仓库1小时,并且在此期间运行一个查询需要30分钟,则该查询将花费您2美元,并且您的仓库在50%的时间内处于空闲状态。另一方面,如果您运行两个30分钟的查询,而仓库将0%的时间闲置,则每个查询只花费1美元。我们查看了一个拥有Redshift仓库的Fivetran用户示例的实际使用数据。中位数Redshift集群在82%的时间内处于空闲状态[8]。
这种比较在很大程度上取决于我们关于懒惰的假设[9]。如果您的工作负载非常“尖细”,那么BigQuery将比其他仓库便宜得多。如果您有一个非常“稳定”的工作负载,那么BigQuery将要昂贵得多。
哪个仓库是“最好的”?
速度和成本并不是唯一的考虑因素;这些仓库有着重要的质量差异。根据我们与真实客户的经验,我们认为有5个关键特征可以区分数据仓库:
- 弹性:数据仓库能够以多快的速度增加和减少容量以响应不断变化的工作负载?
- 可用性:仓库如何提供高正常运行时间?
- JSON支持:可以存储和查询JSON数据吗?
- 你能通过划分数据来调整WHERE子句吗?
- 可以通过指定数据分布来优化联接吗?
我们总结了Redshift、Snowflake和BigQuery在这些标准上的比较;我们还没有足够的Azure和Presto客户将它们纳入定性比较:
比较数据仓库及其特性
为什么我们的结果与以前的基准不同?
Amazon’s Redshift vs. BigQuery benchmark
2016年10月,亚马逊在BigQuery和Redshift上运行了一个TPC-DS查询版本。亚马逊报告称,Redshift的速度提高了6倍,BigQuery的执行时间通常超过1分钟。他们的基准和我们的基准之间的主要区别是:
他们使用了10倍大的数据集(10TB比1TB)和2倍大的Redshift集群(38.40美元/小时比19.20美元/小时)。
他们使用sort和dist键调整了仓库,而我们没有。
BigQueryStandardSQL在2016年10月仍处于测试阶段,到2018年底运行这个基准测试时,速度可能会更快。
那些声称自己的产品是最好的供应商所提供的基准应该是小菜一碟。亚马逊的博客文章中有很多细节没有具体说明。例如,他们使用了一个巨大的Redshift集群——他们是否将所有内存分配给一个用户,以使这个基准测试完成得超级快,即使这不是一个实际的配置?我们不知道。如果AWS能够发布必要的代码来重现它们的基准测试,那么我们就可以评估它的真实性。
Periscope’s Redshift vs. Snowflake vs. BigQuery Benchmark
同样在2016年10月,Periscope 数据使用每小时聚合查询的三种变体来比较Redshift、Snowflake和BigQuery,这三种变体将一个10亿行的事实表与一个小维度表连接起来。他们发现Redshift的速度和BigQuery差不多,但是SnowFlake的速度慢了两倍。他们的基准和我们的基准之间的主要区别是:
- 他们多次运行相同的查询,这就消除了Redshift编译速度慢的问题。
- 他们的查询比我们的TPC-DS查询简单得多。
使用“easy”查询进行基准测试的问题是,每个仓库在这个测试中都会做得很好;Snowflake快速执行简单查询,Redshift快速执行简单查询并不重要。重要的是你是否能足够快地完成硬查询。
Periscope也比较了成本,但是他们使用了不同的方法来计算每个查询的成本。和我们一样,他们查看客户的实际使用数据;但他们没有使用空闲时间百分比,而是查看每小时的查询数。他们确定大多数(但不是所有)潜望镜客户会发现Redshift 更便宜,但这并不是一个巨大的区别。
Mark Litwintschik’s 1.1 Billion Taxi Rides Benchmark
Mark Litwintshik于2016年4月对BigQuery进行了基准测试,并于2016年6月对Redshift进行了基准测试。他对一个拥有11亿行的表运行了4个简单的查询。他发现BigQuery的速度和Redshift集群差不多,大约是我们的两倍(41美元/小时)。两个仓库都在1-3秒内完成了他的查询,因此这可能代表了“性能下限”:即使是最简单的查询也有最短的执行时间。
结论
这些仓库的价格和性能都很好。我们不必惊讶它们是相似的:自从C-Store论文在2005年发表以来,快速列式数据仓库的基本技术已经众所周知。这些数据仓库无疑使用了标准的性能技巧:列存储、基于成本的查询规划、流水线执行和实时编译。我们应该对任何声称一个数据仓库比另一个数据仓库快几个数量级的基准表示怀疑。
仓库之间最重要的区别在于它们的设计选择所导致的质量差异:一些仓库强调可调性,另一些则强调易用性。如果您正在评估数据仓库,您应该演示多个系统,并选择一个适合您的平衡点。
笔记
[1] TPC-DS is an industry-standard benchmarking meant for data warehouses. Even though we used TPC-DS data and queries, this benchmark is not an official TPC-DS benchmark, because we only used one scale, we modified the queries slightly, and we didn’t tune the data warehouses or generate alternative versions of the queries.
[2] This is a small scale by the standards of data warehouses, but most Fivetran users are interested data sources like Salesforce or MySQL, which have complex schemas but modest size.
[3] We had to modify the queries slightly to get them to run across all warehouses. The modifications we made were small, mostly changing type names. We used BigQuery standard-SQL, not legacy-SQL.
[4] The DW1500c configuration for Azure uses Microsoft's Gen2 architecture; the Gen2 architecture is not yet available in a small warehouse size appropriate for the 100 GB scale, so we used the Gen1 DW200 configuration at that scale.
[5] Presto is an open-source query engine, so it isn't really comparable to the commercial data warehouses in this benchmark. But it has the potential to become an important open-source alternative in this space. We used v0.195e of the Starburst distribution of Presto. Cost is based on the on-demand cost of the instances on Google Cloud.
[6] BigQuery is a pure shared-resource query service, so there is no equivalent “configuration”; you simply send queries to BigQuery, and it sends you back results.
[7] If you know what kind of queries are going to run on your warehouse, you can use these features to tune your tables and make specific queries much faster. However, typical Fivetran users run all kinds of unpredictable queries on their warehouses, so there will always be a lot of queries that don’t benefit from tuning.
[8] Some readers may be surprised these data warehouses are idle most of the time. Fivetran users tend to use their warehouses for interactive queries, where a human is waiting for the result, so they need queries to return in a few seconds. To achieve this performance target, you need to provision a large warehouse relative to the size of your data, and that warehouse is going to be idle most of the time. Also, note that this doesn’t mean these warehouses are doing nothing for hours; it means that there are many small gaps of idleness interspersed between queries.
[9] The formula for calculating cost-per-query is [Query cost] = [Query execution time] * [Cluster cost] / (1 — [Cluster idle time])
[10] Redshift takes minutes-to-hours to restore a cluster; in practice this means you will run your cluster 24/7, even if you only use it for part of each day.
[11] Snowflake bills per-second, with a minimum of 1 minute, so you can save money by configuring your cluster to turn off during periods of inactivity.
[12] BigQuery bills per-query, so you only pay for exactly what you use.
[13] Redshift automatically backs up to S3, but in the event of a node failure you will lose a few hours of data and experience downtime while you wait for a restore.
[14] Redshift doesn't have an UNNEST or FLATTEN operator, so it's impractical to work with nested JSON arrays.
[15] Snowflake supports JSON data natively via its VARIANT type
[16] You can convert JSON to typed STRUCT/ARRAY types by writing a user-defined-function in Javascript.
[17] BigQuery only allows partitioning on date columns, and date-partitioning limits how you can use DML operations; but it works well for event tables.
原文:https://fivetran.com/blog/warehouse-benchmark
本文:http://jiagoushi.pro/node/941
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 336 次浏览
【数据仓库架构】数据仓库-星型模式与平面表
问题
我试图设计一个数据仓库,用于存储从财务系统、项目调度系统到无数科学系统等常见的数据。 许多不同的数据集市。
我一直在阅读数据仓库和流行的方法,如星型模式和Kimball方法等,但有一个问题我找不到答案:
为什么将DW数据集市设计为星型模式而不是单个平面表更好?
当然,事实和属性/维度之间没有连接比所有维度表都有许多小连接更快、更简单吗?磁盘空间不是问题,如果需要的话,我们将向数据库抛出更多的磁盘。现在的星型模式是稍微过时了,还是仍然是数据架构师的教条?
答案1:
你的问题很好:维度建模的Kimball mantra是提高性能和可用性。
但我不认为这是过时的,或教条-这是一个合理的,实用的方法,为许多情况和平台。
关系数据库存储数据的方式意味着在表的数量和类型、典型查询到数据的路由、数据之间关系的易维护性和描述、连接的数量、连接的构造方式、列的可索引性等方面需要平衡。
3NF(或更进一步)是频谱的一端,适用于OLTP系统,一个表是频谱的另一端。维度模型居中,适合于报告,至少在使用某些技术时是这样。
性能并不完全与“连接数”有关,尽管星型模式在报告工作负载方面比完全标准化的数据库性能更好,部分原因是连接数减少。维度通常非常宽。如果您在每个事实的每一行中都包含所有这些维度字段,那么实际上您有非常大的行,并且找到进入这些行的方法对于典型的查询将执行非常糟糕的操作。
事实是很多的,所以如果你能使这些表变得紧凑,并且“更冗长”的维度是可过滤的,那么你就达到了一个性能上的最佳点,除非索引很重,否则一个表是不匹配的。
是的,对于一个事实来说,一个表在表的数量上更简单,但它真的更容易导航吗?维度和事实是很容易理解的概念,如果您想跨事实交叉查询呢?您有许多不同的数据集市,但首先拥有数据仓库的好处之一是,这些集市并不明显—它们是相关的,可以跨数据仓库进行报告。一致的维度使之成为可能。
答案2
如果将事实和维度合并到一个表中,则可能会丢失从未使用过的维度属性的可见性,或者通过为未使用的维度属性包含虚拟事件而放弃度量。
例如,餐厅菜单是一个维度,购买的食物是一个事实。如果你把这些东西放在一张桌子上,你会如何确定哪些食物从未被点过?因此,在您第一次点餐之前,您如何确定菜单上有哪些食物?
维度代表可能性,事实代表可能性的实现。
原文:https://stackoverflow.com/questions/44517192/data-warehousing-star-schema-vs-flat-table
本文:
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 34 次浏览
【灾难恢复】AWS上数据库的灾难恢复策略 -- 目标业务成果
QQ群
视频号
微信
微信公众号
知识星球
本节讨论与定义和构建AWS数据库灾难恢复(DR)计划相关的预期结果。
遏制财务损失
如果您为存储应用程序数据的数据库提供了一个设计良好的灾难恢复解决方案,您可以更快地从灾难事件中恢复,并且数据丢失最少或没有。这将最大限度地减少因应用程序长时间不可用或在最坏的情况下永久丢失数据而可能造成的财务损失。
减少对关键业务流程的影响
当您确定第0层服务和流程,并规划灾难恢复战略以快速恢复这些服务和流程时,您将能够减少对这些服务和过程的重大影响,并处理相关流程的恢复。
减少真实事件期间的手动协调(自动化)
如果您选择自动化灾难恢复解决方案,则可以减少在发生事件时运行灾难恢复解决解决方案所需的手动协调。即使在测试业务连续性计划(BCP)时,自动化也是有益的,BCP规定了在计划外中断期间如何维持标准业务运营。
留住您的客户
在竞争激烈的市场中,您的灾难恢复战略会影响您赢得客户忠诚度和留住客户的方式。如果您的组织有能力从灾难中快速恢复,您可以与客户建立信任。
增强安全性
精心规划的跨地区灾难恢复策略可以帮助将勒索软件攻击的影响限制在一个AWS地区,并使您能够在另一个地区自由使用数据,而不会丢失数据。
提高员工生产力
如果您的员工非常了解灾难恢复流程,并对其感到满意,灾难恢复事件不会引起恐慌。您可以遵循定义明确的运行手册来实施灾难恢复解决方案,您的员工可以充分利用他们的时间让您的业务恢复正常。
- 7 次浏览
【数据仓库架构】数据仓库的模式建模技术
以下主题提供有关数据仓库中架构的信息:
数据仓库中的模式
- 第三范式
- 星型模式
- 优化星形查询
数据仓库中的模式
模式是数据库对象的集合,包括表、视图、索引和同义词。
在为数据仓库设计的模式模型中,有多种安排模式对象的方法。一个数据仓库模式模型是星型模式。示例模式(本书中大多数示例的基础)使用星型模式。但是,还有其他模式模型通常用于数据仓库。这些模式模型中最流行的是第三范式(3NF)模式。另外,一些数据仓库模式既不是星型模式也不是3NF模式,而是共享这两种模式的特性;这些模式被称为混合模式模型。
Oracle数据库旨在支持所有数据仓库模式。一些特性可能特定于一个模式模型(例如在“使用星型变换”中描述的星型变换特性,它特定于星型模式)。然而,Oracle的绝大多数数据仓库特性同样适用于星型模式、3NF模式和混合模式。所有模式模型都实现了关键的数据仓库功能,如分区(包括滚动窗口加载技术)、并行性、物化视图和分析SQL。
应该根据数据仓库项目团队的需求和偏好来确定数据仓库应该使用哪个模式模型。比较其他模式模型的优点不在本书的讨论范围之内;相反,本章将简要介绍每个模式模型,并建议如何针对这些环境优化Oracle。
第三范式
尽管本指南在示例中主要使用星型模式,但您也可以使用第三种标准格式来实现数据仓库。
第三范式建模是一种经典的关系数据库建模技术,通过规范化来最小化数据冗余。与星型模式相比,由于这种规范化过程,3NF模式通常具有更多的表。例如,在图19-1中,orders和order items表包含的信息与图19-2中star模式中的sales表相似。
3NF模式通常用于大型数据仓库,特别是具有重要数据加载需求的环境,这些环境用于提供数据集市和执行长时间运行的查询。
3NF模式的主要优点是:
- 提供中立的模式设计,独立于任何应用程序或数据使用注意事项
- 可能比更规范化的模式(如星型模式)需要更少的数据转换
图19-1给出了第三个标准格式模式的图形表示。
图19-1第三范式模式

优化第三范式查询
对3NF模式的查询通常非常复杂,涉及大量的表。因此,在使用3NF模式时,大型表之间的连接性能是一个主要考虑因素。
3NF模式的一个特别重要的特性是分区连接。应该对3NF架构中最大的表进行分区,以启用分区连接。这些环境中最常见的分区技术是针对最大表的组合范围哈希分区,其中最常见的连接键被选为哈希分区键。
在3NF环境中,并行性经常被大量使用,通常应该在这些环境中启用并行性。
星型模式
星型模式可能是最简单的数据仓库模式。之所以称之为星型模式,是因为该模式的实体关系图类似于星型,点从中心表辐射。星的中心由一个大的事实表组成,星的点是维度表。
星型查询是事实表和许多维度表之间的联接。每个维度表都使用主键到外键的联接连接到事实表,但维度表不会彼此联接。优化器识别星形查询并为它们生成高效的执行计划。
典型的事实表包含键和度量。例如,在sh示例架构中,事实表sales包含度量quantity_salled、amount和cost,以及键cust_id、time_id、prod_id、channel_id和promo_id。维度表是customers、times、products、channels和promotions。例如,products维度表包含事实表中显示的每个产品编号的信息。
星型联接是维度表与事实表的外键联接的主键。
星型模式的主要优点是:
- 在最终用户分析的业务实体和模式设计之间提供直接直观的映射。
- 为典型的星形查询提供高度优化的性能。
- 被大量的商业智能工具广泛支持,这些工具可能预期甚至要求数据仓库模式包含维度表。
星型模式用于简单的数据集市和非常大的数据仓库。
图19-2给出了星型模式的图形表示。

雪花模式
雪花模式是比星型模式更复杂的数据仓库模型,是星型模式的一种。它被称为雪花模式,因为模式的图表类似于雪花。
雪花模式规范化维度以消除冗余。也就是说,维度数据已分组到多个表中,而不是一个大表中。例如,星型架构中的产品维度表可以规范化为雪花架构中的产品表、产品类别表和产品制造商表。虽然这样可以节省空间,但会增加维度表的数量,并需要更多的外键联接。结果是查询更加复杂,查询性能降低。图19-3展示了雪花模式的图形表示。
图19-3雪花模式

注:
Oracle建议您选择星型模式而不是雪花型模式,除非您有明确的理由不这样做。
优化星形查询
在使用星形查询时,应考虑以下几点:
- 调整星形查询
- 使用星变换
调整星形查询
要获得星形查询的最佳性能,必须遵循一些基本准则:
- 位图索引应该建立在事实数据表的每个外键列上。
- 初始化参数STAR_TRANSFORMATION_ENABLED应设置为TRUE。这为星型查询提供了一个重要的优化器特性。默认情况下,为了向后兼容,它被设置为FALSE。
当数据仓库满足这些条件时,数据仓库中运行的大多数星型查询将使用称为星型转换的查询执行策略。星型转换为星型查询提供了非常高效的查询性能。
使用星变换
star转换是一种强大的优化技术,它依赖于隐式重写(或转换)原始star查询的SQL。最终用户永远不需要知道关于星型转换的任何细节。Oracle的查询优化器会在适当的地方自动选择星型转换。
星型转换是一种查询转换,旨在有效地执行星型查询。Oracle使用两个基本阶段处理star查询。第一个阶段从事实表(结果集)中准确地检索所需的行。因为这种检索利用位图索引,所以非常有效。第二个阶段将此结果集连接到维度表。一个最终用户查询的例子是:“过去三个季度,西部和西南销售区的杂货店的销售额和利润是多少?”这是一个简单的星号查询。
带位图索引的星型变换
星型转换的一个先决条件是事实表的每个联接列上都有一个单列位图索引。这些联接列包括所有外键列。
例如,sh sample schema的sales表在time_id、channel_id、cust_id、prod_id和promo_id列上有位图索引。
考虑以下星形查询:
SELECT ch.channel_class, c.cust_city, t.calendar_quarter_desc,
SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c, channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = 'CA'
AND ch.channel_desc in ('Internet','Catalog')
AND t.calendar_quarter_desc IN ('1999-Q1','1999-Q2')
GROUP BY ch.channel_class, c.cust_city, t.calendar_quarter_desc;
此查询分两个阶段处理。在第一阶段中,Oracle数据库使用事实表外键列上的位图索引来标识和检索事实表中的必要行。也就是说,Oracle数据库将使用以下查询从事实表中检索结果集:
SELECT ... FROM sales
WHERE time_id IN
(SELECT time_id FROM times
WHERE calendar_quarter_desc IN('1999-Q1','1999-Q2'))
AND cust_id IN
(SELECT cust_id FROM customers WHERE cust_state_province='CA')
AND channel_id IN
(SELECT channel_id FROM channels WHERE channel_desc IN('Internet','Catalog'));
这是算法的转换步骤,因为原始的星型查询已转换为此子查询表示。这种访问事实表的方法利用了位图索引的优点。直观地说,位图索引在关系数据库中提供了一种基于集合的处理方案。Oracle已经实现了执行集合操作的非常快速的方法,例如AND(标准集合术语中的交集)或(集合联合)、MINUS和COUNT。
在这个星型查询中,time_id上的位图索引用于标识事实表中与1999-Q1年销售额相对应的所有行的集合。此集合表示为位图(1和0的字符串,指示事实表的哪些行是集合的成员)。
检索与sale from 1999-Q2对应的事实表行的类似位图。位图或操作用于将这组第一季度销售额与这组第二季度销售额结合起来。
将对客户维度和产品维度执行其他集合操作。此时在星型查询处理中,有3个位图。每个位图对应于一个单独的维度表,每个位图表示满足该单独维度约束的事实表的行集合。
这三个位图使用位图和操作组合成一个位图。最后一个位图表示事实表中满足维度表上所有约束的一组行。这是结果集,是事实表中计算查询所需的行的精确集合。注意,事实表中的实际数据都没有被访问。所有这些操作都只依赖于位图索引和维度表。由于位图索引的压缩数据表示,基于位图集的操作非常高效。
一旦识别出结果集,就可以使用位图来访问sales表中的实际数据。仅从事实表中检索最终用户查询所需的行。此时,Oracle已经使用位图索引将所有维度表有效地连接到事实表。这种技术提供了优异的性能,因为Oracle使用一个逻辑连接操作将所有维度表连接到事实表,而不是单独将每个维度表连接到事实表。
此查询的第二个阶段是将这些行从事实表(结果集)连接到维度表。Oracle将使用最有效的方法来访问和连接维度表。许多维度非常小,表扫描通常是这些维度表最有效的访问方法。对于大型维度表,表扫描可能不是最有效的访问方法。在上一个示例中,位图索引产品部可用于快速识别杂货部的所有产品。Oracle的优化器根据优化器对每个维度表的大小和数据分布的了解,自动确定哪个访问方法最适合给定维度表。
每个维度表的特定连接方法(以及索引方法)也将由优化器智能地确定。哈希连接通常是连接维度表的最有效算法。一旦所有维度表都已联接,最终答案将返回给用户。只从一个表中检索匹配行,然后连接到另一个表的查询技术通常称为半连接。
带位图索引的星型转换的执行计划
“带位图索引的星型转换”可能会导致以下典型的执行计划:
SELECT STATEMENT
SORT GROUP BY
HASH JOIN
TABLE ACCESS FULL CHANNELS
HASH JOIN
TABLE ACCESS FULL CUSTOMERS
HASH JOIN
TABLE ACCESS FULL TIMES
PARTITION RANGE ITERATOR
TABLE ACCESS BY LOCAL INDEX ROWID SALES
BITMAP CONVERSION TO ROWIDS
BITMAP AND
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CUSTOMERS
BITMAP INDEX RANGE SCAN SALES_CUST_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CHANNELS
BITMAP INDEX RANGE SCAN SALES_CHANNEL_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL TIMES
BITMAP INDEX RANGE SCAN SALES_TIME_BIX
在这个计划中,事实表是通过基于位图和三个合并位图的位图访问路径访问的。这三个位图是由位图合并行源生成的,该行源从其下的行源树中获取位图。每个这样的行源树都包含一个位图键迭代行源,该行源从子查询行源树获取值,在本例中,子查询行源树是一个完整的表访问。对于每个这样的值,位图键迭代行源从位图索引检索位图。使用此访问路径检索相关事实数据表行后,它们将与维度表和临时表联接,以生成查询的答案。
带位图连接索引的星型转换
除了位图索引之外,还可以在星形转换期间使用位图连接索引。假设您有以下附加索引结构:
CREATE BITMAP INDEX sales_c_state_bjix ON sales(customers.cust_state_province) FROM sales, customers WHERE sales.cust_id = customers.cust_id LOCAL NOLOGGING COMPUTE STATISTICS;
使用位图连接索引处理同一个星形查询与前面的示例类似。唯一的区别是,Oracle将在star查询的第一阶段使用连接索引而不是单表位图索引来访问客户数据。
带位图连接索引的星型转换的执行计划
以下典型的执行计划可能来自“带位图连接索引的星型转换的执行计划”:
SELECT STATEMENT
SORT GROUP BY
HASH JOIN
TABLE ACCESS FULL CHANNELS
HASH JOIN
TABLE ACCESS FULL CUSTOMERS
HASH JOIN
TABLE ACCESS FULL TIMES
PARTITION RANGE ALL
TABLE ACCESS BY LOCAL INDEX ROWID SALES
BITMAP CONVERSION TO ROWIDS
BITMAP AND
BITMAP INDEX SINGLE VALUE SALES_C_STATE_BJIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL CHANNELS
BITMAP INDEX RANGE SCAN SALES_CHANNEL_BIX
BITMAP MERGE
BITMAP KEY ITERATION
BUFFER SORT
TABLE ACCESS FULL TIMES
BITMAP INDEX RANGE SCAN SALES_TIME_BIX
与前一个计划相比,此计划的区别在于,客户维度的位图索引扫描的内部没有子选择。这是因为customer.cust_省可以满足位图连接索引sales_c_state_bjix。
Oracle如何选择使用星型转换
优化器生成并保存不需要转换就可以生成的最佳计划。如果启用了转换,优化器将尝试将其应用于查询,如果适用,则使用转换后的查询生成最佳计划。根据查询的两个版本的最佳计划之间的成本估计值的比较,优化器将决定是对转换版本还是未转换版本使用最佳计划。
如果查询需要访问事实表中很大一部分行,最好使用完整的表扫描,而不要使用转换。但是,如果维度表上的约束谓词具有足够的选择性,只需要检索事实表的一小部分,那么基于转换的计划可能会更好。
请注意,优化器只有在确定基于多个条件这样做是合理的情况下才会为维度表生成子查询。无法保证将为所有维度表生成子查询。优化器还可以根据表和查询的属性决定转换不适合应用于特定查询。在这种情况下,将使用最佳的常规计划。
恒星转换限制
具有以下任何特征的表不支持星形转换:
- 带有与位图访问路径不兼容的表提示的查询
- 包含绑定变量的查询
- 位图索引太少的表。事实表列上必须有位图索引,优化器才能为其生成子查询。
- 远程事实表。但是,在生成的子查询中允许使用远程维度表。
- 反连接表
- 已用作子查询中维度表的表
- 实际上是未合并视图的表,它们不是视图分区
对于以下情况,优化器可能不会选择星型转换:
- 具有良好的单表访问路径的表
- 太小而不值得转换的表
此外,在下列情况下,star转换将不使用临时表:
- 数据库处于只读模式
- 星形查询是处于可序列化模式的事务的一部分
原文:https://docs.oracle.com/cd/B19306_01/server.102/b14223/schemas.htm
本文:
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 63 次浏览
【数据仓库架构】数据保管库建模的数据仓库方法
数据仓库建模的数据仓库方法应运而生。数据仓库项目通常要处理较长的实现时间。这意味着业务需求更可能在项目过程中发生变化,从而危及项目目标实现时间和成本的实现。
为了提高实现时间,Dan Linstedt引入了核心仓库的数据仓库建模方法。关键设计原则涉及将业务键、上下文和关系分离到不同的表中,如hub、satellite和link。
由于数据保险库提供了许多好处,因此它目前是为核心数据仓库建模而建立的建模标准。其中包括:
数据仓库的好处
- 易于扩展,支持灵活的项目方法
- 创建的模型具有高度可扩展性
- 加载过程可以最佳并行化,因为几乎没有同步点
- 模型易于审核
但是,除了许多好处之外,数据保险库项目也带来了一些挑战。包括但不限于以下内容:
数据仓库缺陷
- 数据对象(表、列)的数量大幅增加,这是由于将信息类型分开,并用元数据丰富它们以供加载
- 这导致更大的建模工作,包括许多简单的机械任务
如何使用标准的数据建模工具来应对这些挑战?
模型的高度示意结构为生成模型提供了理想的先决条件。这使得建模过程中相当大的一部分可以自动化,从而大大加快了数据保险库项目的进度。
什么是数据建模?
选择正确的数据建模工具
自动化数据仓库的潜力
模型的哪些特定部分可以自动化?
数据仓库的标准体系结构包括以下层:
- 源系统:运营系统,如ERP或CRM系统
- 暂存区:这是从运营系统传递数据的地方。数据模型的结构通常对应于源系统,并增强了对加载的文档记录。
- 核心仓库:这里集成了各个系统的数据。该层根据数据保管库进行建模,并细分为原始保管库和业务保管库区域。这涉及到在业务保险库中实现所有业务规则,以便仅在原始保险库中使用非常简单的转换。
- 数据集市:数据集市的结构基于分析需求,并被建模为星型模式。

暂存区和原始保险库都非常适合自动化,因为可以从前一层建立明确定义的派生规则。
自动化应该使用标准建模工具还是使用专门的数据仓库自动化工具来实现?
通常可以使用特殊的自动化工具来利用自动化潜力。
支持使用标准工具(如erwin数据建模器)的理由是什么?
使用标准建模工具有许多好处:
- erwin数据建模器通常已经包含了可以继续使用的模型(例如,源系统)
- 建模功能非常复杂,例如,用于比较模型和模型内的标准化
- 标准支持多种数据库
- 有大量接口可用于从其他工具导入模型
- 通常,该工具已经用于对源系统或其他仓库建模
- 模型范围可用于对整个企业体系结构建模,而不仅仅是
- 数据仓库(erwin门户网站)
- 业务词汇表允许集成(现有的)语义信息
到现在为止,一直都还不错。但是erwin数据建模器能生成模型吗?
专门为erwin数据建模器开发了一个特殊的插件:MODGEN。这使erwin的自动化潜力得到充分利用。
它无缝地集成到erwin用户界面中,在操作方面,主要基于比较模型(complete compare)。
MODGEN功能
MODGEN中实现了以下特定功能:
- 基于前一层模型的分段和原始保险库模型生成
- 生成是通过使用元信息丰富特定的前一个模型来控制的,元信息存储在UDPs中
- 单个对象可以从生成过程中永久排除,或者交互地
- 使用模板可以很容易地集成元列的规范
为了支持可重复多次的建模过程,在该过程中创建或增强迭代模型,生成过程必须具有往返能力。
为了实现这一点,生成总是在源模型和目标模型之间执行比较,并指出任何差异。这些可以由用户选择并在生成过程中复制。
生成过程不仅将所有表和列作为一个过程(水平建模)考虑在内,还创建垂直模型信息。
这意味着在记录数据源时,每个生成的目标列与其源列的关系。因此,使用该模型可以非常容易地生成源到目标的映射。
将源和目标模型集成到web门户中会自动提供完整的影响和沿袭分析功能。
原文:https://erwin.com/blog/data-vault-for-the-data-warehouse/
本文:
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 54 次浏览
【数据仓库架构】数据建模:星型模式
数据建模是现代数据工作流中的一个关键步骤,其目的是将原始数据组织成方便、高效的形式。如果一个可用的数据集易于访问,数据分析师和科学家将发现他们的工作更加容易。更快的分析和预测将导致更快的商业决策洞察力。
建模的第一步通常是规范化数据,这是一个组织过程,通过减少不一致的依赖性和冗余来提高数据库的灵活性。如果你不熟悉的话,我建议你读一下这个和/或看一些视频!规范化数据库的问题是,任何真正有意思的数据洞察都需要许多连接,随着数据库大小的增加,这些连接会大大降低查询的速度。例如,查看下面的模式,大多数表都不是直接相关的。这意味着要连接订单和位置等两个表中的信息,我们至少需要4个连接(Orders -> Employment -> Person -> Phone_Number -> Location是到达那里的一种方式)

https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-relational-modeling.html
如果在4部分连接之后我们需要更多表的数据呢?那将是疯狂。更不用说,如果只编写查询而不出现任何错误,那将是一个绝对头疼的问题。
此外,实际数据库中的表可能比上面示例中显示的表多得多。正如您可以想象的那样,随着模式的增长,甚至越来越难以理解表之间的关系。
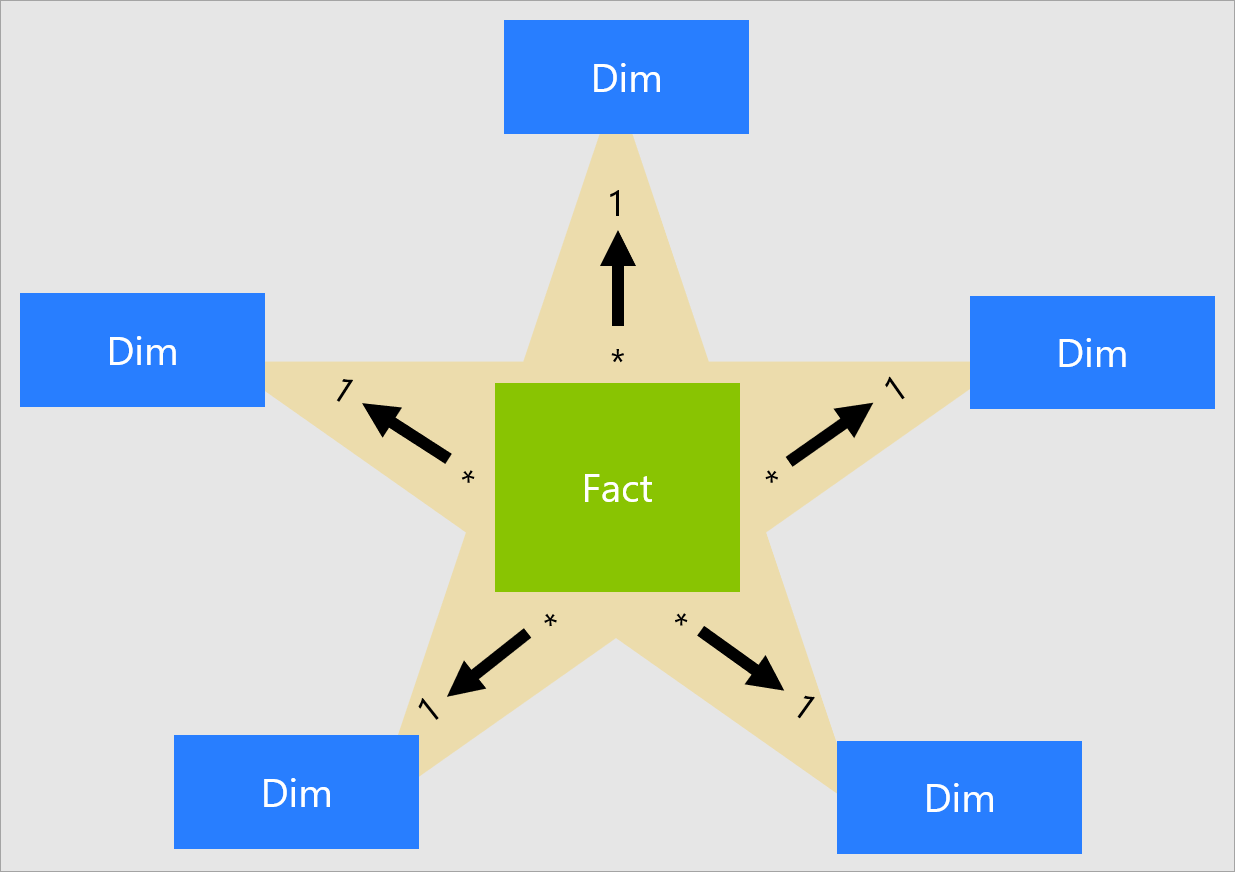
星型模式
解决这个问题的一个方法是执行数据建模的非规范化步骤,以创建一个更简单、易于理解的为ceratin查询优化的模式。创建星型模式的过程包括将完整的模式提取为特定分析过程的相关特性。星型模式的总体结构如下:
https://docs.microsoft.com/en-us/power-bi/guidance/star-schema
星型模式由两种类型的表组成:
- 事实:业务流程的度量。这些通常是数字和加法(例如发票金额或发票数量)或数量。事实表还包含指向相关维度表的键。在星型模式的中心只有一个事实表。
- 维度:地点、时间、内容等(如日期/时间、地点、销售商品)。它们通常包含定性信息。数据模式中有多个维度表,它们都与事实表相关。
优势
- 一个简化的模式意味着我们不必每次想要从数据库中获得一些信息时都编写冗长的查询。
- 我们对阅读进行了优化。现在我们可以编写更少的连接,结果将更快地返回。
- 而且,它将业务逻辑用于报告。我们不必向涉众解释所有用于创建模式的疯狂连接,只是可能。
缺点
- 对数据进行非规范化意味着数据异常可能是一次性插入或更新引起的。在实践中,星型模式是通过“涓流喂养”(trickle feeds)或批处理来实现的,以弥补这个问题。
- 我们的分析灵活性有限。星型模式通常是为特定目的而设计的。由于星型模式中的特性比完整数据库中的少,因此我们仅限于此星型模式包含的内容。
例子
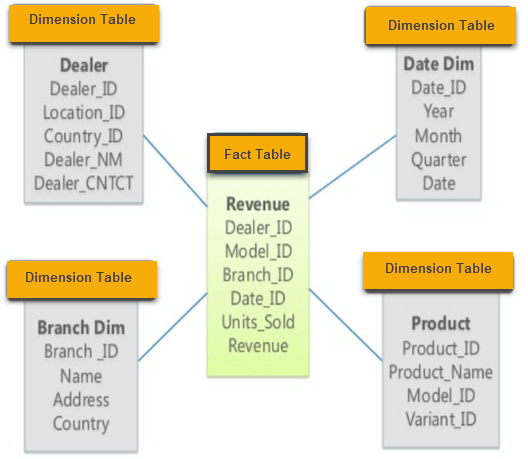
https://www.guru99.com/star-snowflake-data-warehousing.html
让我们考虑一个商店的销售数据库。我们在模式的中心有一个事实表Revenue和四维表。
事实表由复合主键组成,复合主键是维度表主键的组合。事实表非主键Units_Sold和Revenu是我们感兴趣的事实,Product_Name和Name (分支名称)等维度使我们能够了解有关销售商品的更多信息。
例如,以下查询将允许我们计算2010年按产品列出的总收入:
SELECT
p.Product_Name AS product,
SUM(r.Revenue) AS total_revenue
FROM
Revenue r
JOIN
Product p ON (r.Model_ID = p.Model_ID)
JOIN
DateDim d ON (r.Date_ID = d.Date_ID)
WHERE
d.Year = 2010
GROUP BY
p.Product_ID
星型模式被广泛使用,对业务应用程序非常有用。它有助于我们加快可能经常运行的查询,并清理可能非常混乱的查询等。
还有其他模式,如雪花模式和星系模式,它们是恒星模式的简单扩展。如果你喜欢星型模式,我建议你也检查其他的!
原文:https://medium.com/@marcosanchezayala/data-modeling-the-star-schema-c37e7652e206
本文:http://jiagoushi.pro/node/1025
讨论:请加入知识星球或者微信圈子【首席架构师智库】
- 360 次浏览
【数据仓库架构】维基百科数据仓库建模
数据仓库建模是一种数据库建模方法,旨在为来自多个运营系统的数据提供长期的历史存储。它也是一种查看历史数据的方法,处理诸如审核、数据跟踪、加载速度和对更改的弹性等问题,并强调需要跟踪数据库中所有数据的来源。这意味着数据保管库中的每一行都必须附带记录源和加载日期属性,从而使审计员能够将值跟踪回源。
数据保管库建模不区分好数据和坏数据(“坏”是指不符合业务规则)。[1]数据保管库存储“事实的单一版本”(Dan Linstedt也将其表示为“所有数据,所有时间”)与其他数据仓库方法中存储“真理的单一版本”的做法不同[2],其中不符合定义的数据被删除或“清除”。
通过显式地将结构信息与描述性属性分离,建模方法被设计成能够适应存储数据的业务环境的变化。[3]数据保险库被设计成尽可能支持并行加载,[4]这样非常大的实现就可以扩展而无需进行重大重新设计。
历史与哲学
在数据仓库建模中,有两个著名的竞争选项用于对存储数据的层进行建模。要么你按照拉尔夫·金博尔(Ralph Kimball)的标准化维度和企业数据总线建模,要么你按照比尔·因蒙(Bill Inmon)的标准化数据库(需要引用)建模。这两种技术在处理向数据仓库提供数据的系统的变化时都有问题[需要引用]。对于一致的维度,您还必须清理数据(以使其一致),这在许多情况下是不可取的,因为这将不可避免地丢失信息[需要引用]。数据保险库存储旨在避免或最小化这些问题的影响,方法是将它们移动到数据仓库中历史存储区域之外的区域(在数据集市中进行清理),并将结构化项(业务键和业务键之间的关联)与描述性属性分离。
该方法的创建者Dan Linstedt对生成的数据库进行了如下描述:
“数据保险库模型是一个面向细节、历史跟踪和唯一链接的规范化表集,支持一个或多个业务功能领域。它是一种混合方法,包含了第三范式(3NF)和星型模式之间的最佳品种。该设计灵活、可扩展、一致且可适应企业的需求“[5]
Data vault的理念是,所有数据都是相关数据,即使它不符合既定的定义和业务规则。如果数据不符合这些定义和规则,那么这是业务的问题,而不是数据仓库的问题。确定数据“错误”是对数据的一种解释,这种解释源于一种特定的观点,这种观点可能对每个人或在每个时间点都无效。因此,数据存储库必须捕获所有数据,只有在报告或从数据存储库提取数据时,才会解释数据。
data vault的另一个响应问题是,越来越多的人需要对数据仓库中的所有数据进行完全的可审计性和可跟踪性。由于美国的Sarbanes-Oxley要求和欧洲的类似措施,这是许多商业智能实现的相关主题,因此任何数据保险库实现的重点都是所有信息的完全可跟踪性和可审核性。
数据保险库2.0是一个新的规范,它是一个开放的标准。[6]新规范包含定义实现最佳实践、方法(SEI/CMMI、六西格玛、SDLC等)、体系结构和模型的组件。Data Vault 2.0专注于包含新组件,如大数据、NoSQL,同时也关注现有模型的性能。旧规范(这里大部分都有文档记录)高度关注数据保险库建模。这在书中有记录:用Data Vault 2.0构建一个可扩展的数据仓库。
为了使EDW和BI系统与当今企业的需求和愿望保持同步,有必要对规范进行改进,使其包括新的组件和最佳实践。
历史
Data vault建模最初是由Dan Linstedt在20世纪90年代构思的,2000年作为一种公共领域建模方法发布。在《数据管理通讯》的一系列五篇文章中,对数据存储方法的基本规则进行了扩展和解释。其中包括一个概述,[7]组件概述,[8]关于结束日期和联接的讨论,[9]链接表,[10]和一篇关于加载实践的文章。[11]
该方法的另一个(而且很少使用)名称是“通用基础集成建模体系结构”
数据保险库2.0[13][14]已于2013年面世,并带来了大数据、NoSQL、非结构化、半结构化无缝集成,以及方法、体系结构和实施最佳实践。
替代解释
根据Dan Linstedt的说法,数据模型的灵感来源于(或模式化的)对神经元、树突和突触的简单看法——神经元与中枢和中枢卫星相关联,链接是树突(信息的载体),其他链接是突触(相反方向的载体)。通过使用一组数据挖掘算法,可以用置信度和强度等级对链接进行评分。它们可以根据对目前不存在的关系的了解,在飞行中创建和删除。模型可以在使用和馈送新结构时自动变形、调整和调整。[15]
另一种观点认为,数据保险库模型提供了企业的本体论,因为它描述了企业领域(集线器)中的术语及其之间的关系(链接),并在必要时添加了描述性属性(卫星)。
将数据保险库模型视为图形模型的另一种方法。数据保险库模型实际上提供了一个“基于图”的模型,其中包含关系数据库世界中的集线器和关系。通过这种方式,开发人员可以使用SQL来获得基于图的关系以及次秒级响应。
基本概念

具有两个集线器(蓝色)、一个链路(绿色)和四颗卫星(黄色)的简单数据保险库模型
Data vault试图通过将业务键(由于它们唯一标识一个业务实体,所以不会经常发生变异)和这些业务键之间的关联与这些键的描述性属性分离,来解决处理环境变化的问题。
业务键及其关联是结构属性,构成数据模型的骨架。数据保险存储方法的一个主要原则是,真正的业务键只有在业务发生变化时才会发生变化,因此是从中派生历史数据库结构的最稳定的元素。如果将这些键用作数据仓库的主干,则可以围绕它们组织其余的数据。这意味着为集线器选择正确的键对于模型的稳定性至关重要。[16]键存储在表中,表中对结构有一些限制。这些关键表称为集线器。
集线器
集线器包含一个具有低更改倾向的唯一业务键列表。集线器还包含每个集线器项的代理项键和描述业务键来源的元数据。中心信息的描述性属性(例如键的描述,可能是多种语言)存储在称为附属表的结构中,下面将讨论这些结构。
集线器至少包含以下字段:[17]
- 代理项键,用于将其他结构连接到此表。
- 一个业务键,这个中心的驱动程序。业务键可以由多个字段组成。
- 记录源,可用于查看哪个系统首先加载了每个业务键。
- 也可以选择使用元数据字段,其中包含有关手动更新(用户/时间)和提取日期的信息。
一个集线器不允许包含多个业务键,除非两个系统传递相同的业务键,但具有不同含义的冲突。
- 集线器通常应该至少有一颗卫星
集线器示例
这是一个包含汽车的hub表的示例,称为“Car”(H_Car)。驾驶钥匙是车辆识别号。
| Fieldname | Description | Mandatory? | Comment |
|---|---|---|---|
| H_CAR_ID | Sequence ID and surrogate key for the hub | No | Recommended but optional[18] |
| VEHICLE_ID_NR | The business key that drives this hub. Can be more than one field for a composite business key | Yes | |
| H_RSRC | The record source of this key when first loaded | Yes | |
| LOAD_AUDIT_ID | An ID into a table with audit information, such as load time, duration of load, number of lines, etc. | No |
链接
业务键之间的关联或事务(例如通过购买事务将客户和产品的中心相互关联起来)使用链接表进行建模。这些表基本上是多对多联接表,带有一些元数据。
链接可以链接到其他链接,以处理粒度上的更改(例如,向数据库表添加新键将更改数据库表的粒度)。例如,如果客户和地址之间存在关联,则可以添加对产品和运输公司集线器之间链接的引用。这可能是一个称为“交付”的链接。在另一个链接中引用链接被认为是一种不好的做法,因为它引入了链接之间的依赖关系,这使得并行加载更加困难。由于指向另一个链接的链接与来自另一个链接的集线器的新链接相同,因此在这些情况下,在不引用其他链接的情况下创建链接是首选解决方案(有关详细信息,请参阅加载实践部分)。
链接有时会将集线器链接到本身不足以构建集线器的信息。当链接关联的一个业务键不是真正的业务键时,就会发生这种情况。例如,以“订单号”为键的订单,以及用半随机数键控的订单行使其唯一。比如说,“唯一的数字”。后一个键不是真正的业务键,因此它不是集线器。但是,我们确实需要使用它来保证链接的正确粒度。在这种情况下,我们不使用具有代理键的集线器,而是将业务键“唯一编号”本身添加到链接中。只有在不可能将业务键用于另一个链路或用作卫星中属性的键时,才能执行此操作。丹·林斯特德(Dan Linstedt)在他(现在已经失效)的论坛上把这个结构称为“钉腿链接”。
链接包含链接的集线器的代理项键、它们自己的链接代理项键和描述关联来源的元数据。关联信息的描述性属性(如时间、价格或金额)存储在称为附属表的结构中,下面将讨论这些结构。
链接示例
这是汽车(HúCAR)和人(HúPERSON)两个集线器之间的链接表的示例。该链接称为“Driver”(L_Driver)。
| Fieldname | Description | Mandatory? | Comment |
|---|---|---|---|
| L_DRIVER_ID | Sequence ID and surrogate key for the Link | No | Recommended but optional[18] |
| H_CAR_ID | surrogate key for the car hub, the first anchor of the link | Yes | |
| H_PERSON_ID | surrogate key for the person hub, the second anchor of the link | Yes | |
| L_RSRC | The recordsource of this association when first loaded | Yes | |
| LOAD_AUDIT_ID | An ID into a table with audit information, such as load time, duration of load, number of lines, etc. | No |
卫星
集线器和链接构成了模型的结构,但没有时间属性,也没有描述性属性。它们分别存储在称为卫星的表中。它们包括将它们链接到其父集线器或链接的元数据、描述关联和属性起源的元数据,以及带有属性开始和结束日期的时间线。当集线器和链路提供模型的结构时,卫星提供模型的“肉”,即集线器和链路中捕获的业务流程的上下文。这些属性既与事件的细节有关,也与时间线有关,范围从相当复杂(描述客户完整配置文件的所有字段)到相当简单(链接上只有有效指示器和时间线的卫星)。
通常,属性按源系统在卫星中分组。但是,诸如大小、成本、速度、数量或颜色等描述性属性可以以不同的速率更改,因此您还可以根据这些属性的更改速率将它们拆分到不同的卫星中。
所有的表都包含元数据,至少至少描述了源系统和此条目生效的日期,给出了数据进入数据仓库时的完整历史视图。
卫星示例
这是一个关于汽车和人的枢纽之间的司机连接的卫星的例子,称为“司机保险”(S_Driver_insurance)。这颗卫星包含特定于汽车与驾驶人之间关系保险的属性,例如,指示这是否是主要驾驶员,这辆车和人的保险公司名称(也可以是一个单独的枢纽)以及涉及这类车辆和驾驶员组合的事故数量摘要。还包括对一个名为R_RISK_CATEGORY的查找或引用表的引用,该表包含被视为属于该关系的风险类别的代码。
| Fieldname | Description | Mandatory? | Comment |
|---|---|---|---|
| S_DRIVER_INSURANCE_ID | Sequence ID and surrogate key for the satellite on the link | No | Recommended but optional[18] |
| L_DRIVER_ID | (surrogate) primary key for the driver link, the parent of the satellite | Yes | |
| S_SEQ_NR | Ordering or sequence number, to enforce uniqueness if there are several valid satellites for one parent key | No(**) | This can happen if, for instance, you have a hub COURSE and the name of the course is an attribute but in several different languages. |
| S_LDTS | Load Date (startdate) for the validity of this combination of attribute values for parent key L_DRIVER_ID | Yes | |
| S_LEDTS | Load End Date (enddate) for the validity of this combination of attribute values for parent key L_DRIVER_ID | No | |
| IND_PRIMARY_DRIVER | Indicator whether the driver is the primary driver for this car | No (*) | |
| INSURANCE_COMPANY | The name of the insurance company for this vehicle and this driver | No (*) | |
| NR_OF_ACCIDENTS | The number of accidents by this driver in this vehicle | No (*) | |
| R_RISK_CATEGORY_CD | The risk category for the driver. This is a reference to R_RISK_CATEGORY | No (*) | |
| S_RSRC | The recordsource of the information in this satellite when first loaded | Yes | |
| LOAD_AUDIT_ID | An ID into a table with audit information, such as load time, duration of load, number of lines, etc. | No |
(*)至少有一个属性是必需的。(**)如果需要在同一集线器或链路上强制多个有效卫星的唯一性,则序列号将成为必需的。
参考表
参考表是正常的数据保险库模型的正常部分。它们是为了防止重复存储大量引用的简单引用数据。更正式地说,Dan Linstedt定义参考数据如下:
用于解析代码中的描述或以一致的方式将键翻译为(sic)所需的任何信息。这些字段中的许多在本质上是“描述性的”,它们描述了其他更重要信息的特定状态。因此,参考数据与原始数据保险库表位于不同的表中。[19]
引用表是从卫星引用的,但从不与物理外键绑定。参考表没有规定的结构:使用在特定情况下最有效的结构,从简单的查找表到小型数据存储库甚至星星。它们可以是历史的,也可以是没有历史的,但是在这种情况下,建议您坚持使用自然键,而不要创建代理键。[20]通常情况下,数据保险库有很多引用表,就像任何其他数据仓库一样。
参考示例
这是一个带有车辆驾驶员风险类别的参考表示例。它可以从数据保险库中的任何卫星上引用。目前,我们从卫星S U驱动程序保险公司处获得参考。参考表为风险类别。
| Fieldname | Description | Mandatory? |
|---|---|---|
| R_RISK_CATEGORY_CD | The code for the risk category | Yes |
| RISK_CATEGORY_DESC | A description of the risk category | No (*) |
(*)至少有一个属性是必需的。
装载实践
更新数据保险库模型的ETL相当简单(请参见数据保险库系列5-加载实践)。首先必须加载所有集线器,为任何新的业务键创建代理ID。这样做之后,如果查询集线器,现在可以将所有业务键解析为代理ID。第二步是解析集线器之间的链接,并为任何新关联创建代理项ID。同时,还可以创建连接到集线器的所有卫星,因为可以将键解析为代理项ID。使用代理项键创建所有新链接后,可以将卫星添加到所有链接。
由于集线器除了通过链接之外没有相互连接,因此可以并行加载所有集线器。由于链接不是直接相互连接的,因此也可以并行加载所有链接。由于卫星只能连接到集线器和链路,因此也可以并行加载这些集线器和链路。
ETL非常简单,易于自动化或模板化。只有与其他链接相关的链接才会出现问题,因为解决链接中的业务键只会导致另一个链接也必须解决。由于这种情况等同于连接到多个集线器,因此可以通过重新设计这种情况来避免这种困难,这实际上是建议的做法。[11]
除非在加载数据时出现技术错误,否则不会从数据保管库中删除数据。
数据仓库与维度建模
数据保险库建模层通常用于存储数据。它没有针对查询性能进行优化,也不容易通过知名的查询工具(如Cognos、SAP Business Objects、Pentaho等)进行查询,因为这些最终用户计算工具希望或希望其数据包含在维度模型中,所以通常需要进行转换。
为此,可以将这些集线器上的集线器和相关卫星视为尺寸,将这些链路上的链路和相关卫星视为尺寸模型中的事实表。这使您能够使用视图从数据保管库模型中快速创建维度模型的原型。出于性能原因,维度模型通常在批准后在关系表中实现。
请注意,虽然将数据从数据保管库模型移动到(干净的)维度模型相对简单,但考虑到维度模型事实表的非规范化性质(与数据保管库的第三种正常形式有根本不同),反向移动就不那么容易了。
数据仓库方法
数据仓库方法基于SEI/CMMI 5级最佳实践。它包括CMMI级别5的多个组件,并将它们与六西格玛、TQM和SDLC的最佳实践相结合。特别是,它关注的是Scott Ambler的构建和部署敏捷方法。数据保险库项目有一个短的、范围受控的发布周期,应该每2到3周发布一次产品版本。
使用data vault方法的团队应该很容易适应CMMI级别5预期的可重复、一致和可测量的项目。流经EDW数据保险库系统的数据将开始遵循长期以来从BI(商业智能)项目中丢失的TQM(全面质量管理)生命周期。
原文:https://en.wikipedia.org/wiki/Data_vault_modeling
本文:http://jiagoushi.pro/node/945
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 68 次浏览
【数据架构】3种类型的数据架构组件:应用程序、仓库和湖泊
QQ群
视频号
微信
微信公众号
知识星球
有什么区别,为什么重要?
当我刚开始涉足分析领域时,数据架构非常令人生畏。这些术语对我来说是陌生的,人们会把“ETL”和“数据湖”之类的术语扔来扔去,我会点头同意,对他们在说什么只有模糊的感觉,然后把它放在“太难了”的框里。
今天,我想简单地描述数据架构的三个部分;应用程序、数据仓库和数据湖。我会把重点放在你作为一个企业内部的人需要知道的事情上(而不是分析),为了保持实用性,我会举一个我们大多数人可能至少每周都会做的例子,用信用卡买东西。
应用程序数据库
应用程序是生成数据的地方。
比方说,我每周都去乐购购物。当我交出我的卡付款时,卡申请将登记我在4月19日下午5点05分向乐购支付了45.50英镑(有一些中间步骤,但对于本文来说,这并不重要)。但卡应用程序只生成和保存卡的数据,没有关于你是否也持有抵押贷款、你的地址、你的营销偏好等的信息。现在说,你想了解客户每月的交易总数,根据客户是否也有抵押贷款来划分。仅仅使用卡应用程序数据是不可能的,这就是为什么我们需要一个数据仓库。
数据仓库
数据仓库是真相的单一版本。将不同的应用程序数据组合在一起并重新格式化,以便以相同的方式定义和结构化来自不同应用程序的数据。
按照我的Tesco示例,卡应用程序中的交易数据被传输到数据仓库。来自抵押贷款应用程序的数据也会传输到数据仓库,以查看哪些客户持有抵押贷款及其未偿余额。我们还从第三方获取数据;每个月我们都会收到来自信贷机构的报告,其中包括每个客户的信用评分。数据移动的频率取决于数据的类型。客户的信用评分仅每月可用,而信用卡交易数据则是分分钟发生的。这就是数据架构师的用武之地,他们定义了移动数据的最佳频率。
现在,有了不同的来源,我们可以对客户每月的交易数量进行分析,根据客户是否持有抵押贷款进行划分。
数据仓库保存一定程度的历史数据(我们的数据仓库通常保存2-3年),这就是数据湖的来源。
数据湖
数据湖基本上是一个巨大的停车场。数据湖主要用于需要访问数据的机会下降的老化数据。
回到我的例子,你可以想象英国每天发生的卡交易数量(数百万!)。将这些数据长期保存在数据仓库中是不现实的,因为这会减慢速度,而且保存这些数据可能会很昂贵。固定时间后,卡交易数据将从数据仓库转移到数据湖。它仍然可以访问,但不在分析师日常使用的表格中。
作为一个商业人士或产品所有者,我需要了解多少?
事实是,不多,但有一些“注意”领域可能会影响工作的可行性或完成请求的时间长度。
如果我们需要的数据不在数据仓库或数据湖中,数据和分析团队将需要与应用程序所有者接触,以建立将数据传输到数据仓库的流程。这可能需要时间,并且可能涉及数据共享协议。
如果数据很旧并且在数据湖中,则数据是可用的,但分析师可能需要更多的时间来提取数据,因此您可能希望在项目计划中留出更多的时间。
在本文中,我们没有考虑数据是存储在物理服务器上还是存储在云中的区别,但这是另当别论的!
谢谢你的阅读,如果有任何反馈,请告诉我。
参考文献:
Inmon,W.H.(2019)数据架构:数据科学家的入门读物。第2版。加利福尼亚州圣地亚哥:爱思唯尔。
- 8 次浏览
【数据架构】数据保管库基础知识
数据保管库基础知识
在这里,我们为您的企业集成需求提供一流的混合数据建模解决方案。现在加入不断发展的社区,并与data vault社区进行交互。学习如何更快、更便宜、更可靠地满足企业的需求。
数据保险库体系结构为业务问题和技术问题提供了独特的解决方案。它专注于企业间的数据集成工作,并建立在坚实的基础概念之上。了解数据保险库的关键是了解业务。一旦制定了业务计划,并且实践者对业务的运作方式有了明确的掌握,那么就可以开始构建数据仓库的过程。
作为基础工程的副产品,数据仓库具有许多优点。坚持数据仓库的基本规则和标准将有助于快速、轻松地完成任何集成项目。在进入社区/论坛之前,我们希望您先了解数据保险库的几个区域。如果您感兴趣,还可以阅读从事数据保管库建模的人员所面临的一些问题。
很容易将第三范式和星型模式转换为数据保险库模型体系结构,下面我们将展示如何从第三范式转换为数据保险库模型体系结构。在社区内部,我们将经历从星型模式到数据保险库模型的转换步骤。
数据仓库建模的业务好处
- 在您的企业数据仓库中管理和强制执行对sarbanes-oxley、hippa和basil ii的遵从性
- 发现以前从未发现的业务问题
- 快速缩短实施更改的业务周期时间
- 迅速将新的业务单位并入组织
- 快速投资回报率和向新的星型模式提供信息
- 整合不同的数据存储,即:主数据管理
- 快速实现和部署soa。
- 扩展到数百兆字节或千兆字节
- sei cmm 5级兼容(可重复、一致、冗余架构)
- 将所有数据跟踪回源系统
以下是我们在本网站上介绍的概念:
- 数据仓库的定义
- 数据保险存储的好处
- 从业务案例到数据仓库
- 5个简单步骤中的数据保险存储
- 图片资料库
- sei/cmm/合规性
定义:
data vault是一个面向细节、历史跟踪和唯一链接的规范化表集,支持一个或多个业务功能领域。它是一种混合方法,包含了第三范式(3nf)和星型模式之间的最佳品种。该设计具有灵活性、可扩展性、一致性和适应企业需求的特点。它是一个专门为满足当今企业数据仓库需求而构建的数据模型。
- 数据归属的广泛可能性。
- 所有数据关系都是键驱动的。
- 可以随时删除和创建关系。
- 数据挖掘可以发现元素之间的新关系
- 人工智能可用于对关系与用户配置结果的相关性进行排序。
从商业角度讲,它是一种快速适应、准确建模业务并根据业务需求进行扩展的能力——将it和业务融合在一起,以实现公司的目标。数据保险库是一种数据集成架构;一系列标准和定义元素或方法通过信息的方式连接在rdbms数据存储中,以便理解它。
在组织内构建数据保管库可获得以下业务好处:
- 数据保险库是一种高度可扩展、灵活的体系结构,它允许业务增长和更改,而不必经历“变更影响列表扩大和成本支出”的痛苦和痛苦。通常,当业务请求更改数据模型(由于业务更改)时,它会带来高成本、长时间的实施和测试周期和整个“企业仓库”的影响的长列表。有了数据保险库,情况就不同了,通常新的业务功能区会快速而容易地添加,对现有架构的更改所需的时间不到传统架构的1/2,而且通常对下游系统的影响要小得多。
技术优势:
- 近实时负载
- 传统批量装载
- 数据库数据挖掘
- 兆字节到兆字节的信息(大数据)
- 增量构建
- 非结构化数据的无缝集成(nosql)
- 动态模型自适应-自愈
- 业务规则更改(轻松)
由于数据保险存储在很大程度上基于业务流程,因此了解业务模型如何表示数据保险库存储,以及如何从一个业务模型过渡到另一个业务模型非常重要。下面是一系列描述和转换,它们将您从业务案例模型的一种状态转换到表示它的物理数据保险存储数据模型。它还指出了体系结构与业务本身的紧密联系。它还指示了当业务发生变化时,模型的变化速度。
在本例中,让我们考察一家公司,该公司的营销部门希望建立一个销售活动来销售移动缓慢的产品。希望客户能看到这个活动,像新的低价产品一样,向公司购买。当分析员重复他们在用户访谈中听到的内容时,分析员对业务用户说,他听到他们说:“营销产生销售发票”。业务用户很快纠正他(和案例模型)并声明财务部门生成发票。当然,在本例中,希望客户能够向公司提供有关营销活动和公司友好性的反馈。
在更正的业务案例中,我们将模型从上面的表示更改为下面的表示。变化不大,只是部门的不同。希望在财务和营销之间有沟通(本例中没有显示)。
当我们继续讨论业务模型的实现时,我们开始对项目的范围进行配对,以便在预算内、准时和有限的资源下完成它。在这种特殊情况下,公司决定我们可以在以后添加营销、财务和企业(公司),从而使其超出范围。他们告诉我们,我们应该把重点放在活动、发票、产品和客户的实施上。所有这些都是独立的业务元素,并有自己的“跟踪号码”。换句话说,是活动 mkt-1、发票号码、客户帐户和产品号码将所有这些数据联系在一起。
经进一步调查,我们发现该公司希望跟踪活动的有效性评级、日期(活动的时间长度)、发票和行项目上的日期和金额、产品及其可用性日期、说明、库存数量和缺陷原因;最后,我们发现他们已经有客户地址、联系人,以及其他人口统计细节。我们构建的下一个模型基于数据保险库的概念,并直接与数据粒度和键控信息的业务描述联系起来。出于作用域和本例的目的,我们将逻辑数据模型限制为红色区域。
下面是我们的第一个切割逻辑数据保险库数据模型的外观。我们获取业务Key,如发票号和产品号,并将它们构建到自己的中心。然后,我们采用发票和产品之间的交互,并构建一个名为link invoice line item的链接表。行项目不能“独立”。它们依赖于其他关键信息来定位和描述它们属于什么。但是,此模型中存在错误(请参阅链接发票行项目中嵌入的中心客户id)。
这个错误是由于把颗粒度移到错误的位置造成的。正确的做法是:发票与客户联系在一起(通常是1到1封信函),客户可以拥有许多发票。一个企业在同一张发票(这是上面所说的谷物)上,每一个商品都有不同的客户,这是非常罕见的(尽管确实发生了)。正确的行项目链接表将不包含客户id。更正后的模型将在中心发票和中心客户之间具有附加链接,以表示客户和发票之间的交互。
数据仓库是简单的还是复杂的?实施起来容易吗?是的,它既简单又易于实现。它基于一组冗余结构和可审计原则。通过使用数据保险库标准,您的项目将自动获得可审核性、可伸缩性和灵活性的好处。以下一组网页将指导您以5个简单步骤完成构建数据保险库的过程。
- 步骤1:建立业务键、hubs
- 步骤2:建立业务键、链接之间的关系
- 步骤3:围绕业务键、卫星建立描述
- 步骤4:添加独立组件,如日历和代码/说明,以便在数据集市中解码
- 步骤5:调整查询优化,添加性能表,如桥表和时间点结构
建立你的数据集市,你的ETL加载过程,然后离开。构建数据保险库变得越来越容易,最终取代了企业集成体系结构中常用的“邦迪”方法。该模型是以这样一种方式构建的,可以在需要时方便地进行扩展。客户说,世界上最小的数据仓库由一个中心和一个卫星组成。这种灵活性被嵌入到链接表的概念中。
对于希望查看数据保险库示例的用户,我们提供了一些不同模型的示例。这些是用于查看的,是可以自定义以满足您需要的通用模型。northwind数据保险库的ddl在论坛中可用。这是一个标准的数据模型,可根据要求提供全尺寸图像。
我们从一个简化的3nf数据模型开始,通常情况下,源数据模型代表了当前的业务——至少它代表了收集信息的业务流程。当然,我们也希望纠正业务流程中出现的一些错误。
Northwind 3NF 数据模型:
以下是上述5个系列的第一步。识别业务密钥,并将它们放置在标准中心结构中。如果业务密钥是“智能密钥”,或由多个可识别关系组成的组合密钥,则这可能是一个挑战。尽管不鼓励标准化到第n级,但最好标识和记录这些N组合键的元数据。
northwind数据保险库模型,识别Hub
步骤2,识别业务密钥之间的链接或关系。这个过程有时可能有点棘手,特别是如果数据集说业务密钥是“弱”的,不能独立存在,或者不可识别(不唯一)。在这些情况下,我们最终可以使用单腿链接表,这是我们在建模过程中要解决的问题。同样,链接表表示关系、事务、层次结构,并定义交集上的数据粒度。
请注意在订单、员工、发货人和客户之间定义谷物的重要性。这种关系(链接表)的粒度是由源系统定义的,但是它很微妙,很容易丢失。
Northwind数据保险库 模型、集线器和链接
下面的最后一张图片显示了一个完整的数据存储库,其中包含所有可用的集线器、链路和卫星。虽然白皮书定义了时间点表和桥表,但是体系结构并不需要它们。由于查询性能的原因,这些备用表被严格使用。有些mpp数据库可以在不使用“查询辅助表”的情况下执行,例如时间点表和桥表。这就是说,许多现有的数据保险库并没有在mpp系统上实现,因此需要这些表来减少连接的数量。
完成:northwind数据保险库模型、集线器、链路和卫星
数据保险库附带了规则或标准,这些规则或标准使设计具有可重复性和冗余性。sei/cmm(软件工程研究所,能力成熟度模型)的一部分是让组织达到一个业务流程的层次,即:文档化、可重复、冗余、容错,最终:自动化。它还为组织定义了风险分析、kpa(关键流程领域)和kpi(关键流程指标-指标),通过这些指标,他们可以衡量这些业务流程的改进和准确性。这些等同于iso900x、pmbok、其他学科的六西格玛实践。
在私营部门,合规已经存在多年,当政府授权所有政府承包商将成为sei/cmm 5级合规者时,合规就有了一个全新的含义。数据可跟踪性达到了顶峰,业务用户发现并解决自己业务问题的责任也上升到了顶峰。
法规遵从性本身有许多含义,但就萨班斯-奥克斯利协议和巴兹尔ii/iii协议以及其他法规遵从性计划而言,它对数据可跟踪性和业务责任制造成了沉重打击。必须通过使用it人员的模型(无论是否为数据保险库)来启用it人员,以便在创建数据时跟踪数据。在数据仓库的情况下,我们已经让它变得更容易了。数据存储库提供了一系列标准字段,这些字段按日期和数据的来源跟踪数据更改,并且数据存储库始终建模为保存来自源系统的尽可能低的数据粒度。也就是说:数据是集成的,但在存储在数据保险库中时不会修改。卫星按数据类型和变化率进行划分,从而减少存储需求,提高可追踪性。
业务规则通常是在“进入”数据仓库的过程中实现的,它们会在“从仓库到数据集市的过程中”被移动、移动和实现。因此,允许将单个活动数据仓库(数据保险库模型)构建为事实陈述,并且每个数据集市都可以基于单个来源点表示自己的“真相版本”。
当遵循将信息加载到数据存储库中的标准时,it人员会自动继承“数据遵从性和可跟踪性”。业务部门可以指向数据集市,声称它今天是“错误的”,明天是“正确的”,但它始终可以显示数据从何而来、何时进入,以及在更改/转换、聚合和清理之前的样子,从而更容易满足合规性计划。
sei/cmm过程被定义为标准的一部分,并被构建到体系结构中,使加载过程、查询过程和发现过程可重复、冗余和容错。
原文:https://danlinstedt.com/solutions-2/data-vault-basics/
本文:http://jiagoushi.pro/node/943
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 34 次浏览