无服务器架构
- 134 次浏览
【无服务器架构】节俭 Kubernetes operator 第一部分:简介
什么是Operator?
Kubernetes平台是围绕控制器的软件设计模式构建的,该控制器是管理两个实体之间数据流的软件组件。 在Kubernetes中,控制器监视在一个资源中发现的声明状态的更改,然后通过创建或更改其他下游资源来响应状态更改请求。 由于控制器对帐过程连续发生,因此此过程称为“主动对帐”。 如图1所示。

创建部署时,可以观察到此行为的一个示例。创建新的部署资源后,将向部署控制器通知资源更改,并通过创建新的副本集做出反应。反过来,副本集控制器对副本集资源做出反应,并导致创建一个或多个Pod。稍后,如果您要修改部署的图像属性,则部署控制器将使用新的图像属性创建新的副本集,同时逐步淘汰旧的副本集。尽管对下游资源采取的操作根据资源而有所不同,但其他控制器的行为类似。
像其他控制器一样,操作员也要注意Kubernetes资源的修改。但是,与Kubernetes平台概念(如部署,状态集和服务(在许多类型的软件中通用))不同,操作员将特定于软件的知识体现在控制器中。考虑一个复杂的工作负载,例如集群数据库,其中需要按照该软件独有的精确顺序来组织常见的操作活动。
实践中的Operator
让我们考虑一个例子。也许升级数据库需要先启动数据格式的先决条件步骤,然后再启动最新版本的容器软件,并且所有吊舱都需要在数据迁移之前停止。或者,可能需要按特定顺序启动Pod,以确保共识算法可以识别所有群集成员。操作员负责协调这些活动,同时利用最终用户可以编辑的资源模型中的声明性或所需状态。
将声明的状态与特定于实现的活动分开,使用户可以在没有特定于软件的知识的情况下控制软件的实例。知识被编码到操作员提供的控制器中。同时,另一软件的操作特性以其自己的方式是独特的,因此具有自己的运算符。
规模化Operator
如果单独部署operator,他们将消耗很少的资源。实际上,我们通过使用Kube Builder SDK和golang语言生成控制器来进行一些分析。然后,我们分析了生成的控制器的实际CPU和内存使用情况,以及对生成的资源请求和限制进行自省。下表中汇总了此信息:

这些数目是针对单个控制器容器的,集群中容器的总数由以下各项确定:
软件包中特定于软件的运算符的数量(Redis的一个运算符,Postgres的一个运算符)。
单个运算符的唯一实例数。 为了隔离起见,Redis运算符可能安装在一个命名空间中,而Redis运算符实例的另一个实例存在于另一个命名空间中。
上面的指标是针对每个Pod的,但是出于冗余的考虑,每个操作员部署可能会部署3次。
如果我们要计划由10个名称空间隔离的10个运算符,并且冗余为3,这将导致以下资源消耗:
我们可以对这些数据进行一些重要的观察:
- 在上述规模下,一个以上的内核将专门用于保持空闲操作员的运行。
- 除了实际的资源消耗外,operator还计入集群的资源配额。
- 您选择安装哪些操作程序,以及在什么作用范围内(例如名称空间或群集范围)进行大规模安装。
我们可以无服务器吗?
当然,许多操作员实例的资源利用率可能会影响集群资源需求,但是它是否非常适合无服务器?现实情况是,许多控制器的需求并不恒定,尤其是当单个操作员实例的范围已限于特定的名称空间时。
Kubernetes资源修改事件通常源于两个用户修改单个资源以及通过机器驱动或批处理作业。单个用户可能会强烈地操纵资源一段时间,然后一段时间不会。例如,您可以创建一个Redis集群,然后在根据自己的特定需求微调该集群时编辑各个参数,但是在此之后,您将继续编辑应用程序的其他部分。对于机器驱动的作业,其中一些按计划运行,而另一些则由源更改事件驱动,这些事件通常在工作日左右聚集。
单一资源或资源种类上的活动集群趋向于倾向于无服务器模型。在此模型中,容器进程仅在工作到达时才保持活动状态,但是可以在活动停止的时间段内停止这些容器。
请继续关注有关现有operator部署和新设计模式的更多帖子
随着operator继续在Kubernetes生态系统中获得关注,并且自定义控制器变得越来越普遍,这些容器流程的资源需求值得注意。在本系列的第2部分中,我们将考虑一些既适用于现有operator部署又适用于利用Knative提供无服务器功能的新设计模式的特定技术方法。
原文:https://www.ibm.com/cloud/blog/new-builders/being-frugal-with-kubernetes-operators
本文:http://jiagoushi.pro/node/873
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 30 次浏览
【无服务器架构】Apache Openwhisk 概览
Apache OpenWhisk是什么?
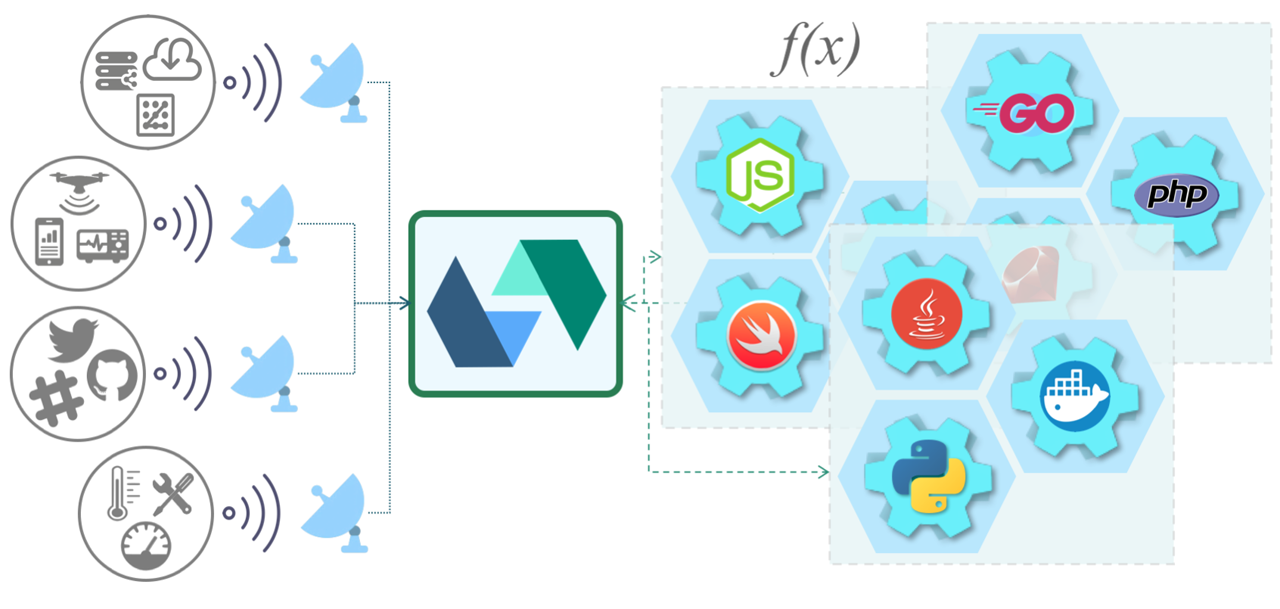
Apache OpenWhisk是一个开放源代码的分布式无服务器平台,该平台可以执行功能(fx)以响应各种规模的事件。 OpenWhisk使用Docker容器管理基础架构,服务器和扩展,因此您可以专注于构建出色而高效的应用程序。
OpenWhisk平台支持一种编程模型,在该模型中,开发人员可以使用任何受支持的编程语言编写功能逻辑(称为“动作”),该逻辑可以动态地调度和运行,以响应来自外部源(Feed)或HTTP请求的关联事件(通过触发器) 。 该项目包括基于REST API的命令行界面(CLI)以及其他支持打包,目录服务和许多流行的容器部署选项的工具。
部署到任何地方
由于Apache OpenWhisk使用容器构建其组件,因此可以轻松地支持本地和Cloud基础架构中的许多部署选项。 选项包括当今许多流行的Container框架,例如Kubernetes和OpenShift,Mesos和Compose。 总的来说,社区支持使用Helm图表在Kubernetes上进行部署,因为它为Devloper和Operator都提供了许多简便的实现。

用任何语言编写函数
与您所知道和所爱的人一起工作。 OpenWhisk支持越来越多的您喜欢的语言,例如NodeJS,Go,Java,Scala,PHP,Python,Ruby和Swift,以及Ballerina,.NET和Rust的最新添加。
如果需要当前不支持“即用即用”运行时的语言或库,则可以使用Docker SDK将自己的可执行文件创建并自定义为Zip Actions,并在Docker运行时上运行。 如何使用Docker Actions支持其他语言的一些示例包括Rust的教程和Haskell的完整项目。
编写函数后,请使用wsk CLI定位到Apache OpenWhisk实例,并在几秒钟内运行您的第一个操作。

与许多受欢迎的服务轻松集成
OpenWhisk使开发人员可以轻松地使用Packages将其Actions与许多流行的服务集成在一起,这些Packages作为OpenWhisk系列下的独立开发项目或作为我们默认目录的一部分提供。
软件包提供与常规服务(例如Kafka消息队列,包括Cloudant的数据库,移动应用程序的推送通知,Slack消息传递和RSS feed)的集成。 开发管道可以利用与GitHub,JIRA的集成,或轻松连接Weather公司的自定义数据服务。
您甚至可以使用“警报”程序包来安排时间或重复间隔来运行操作。

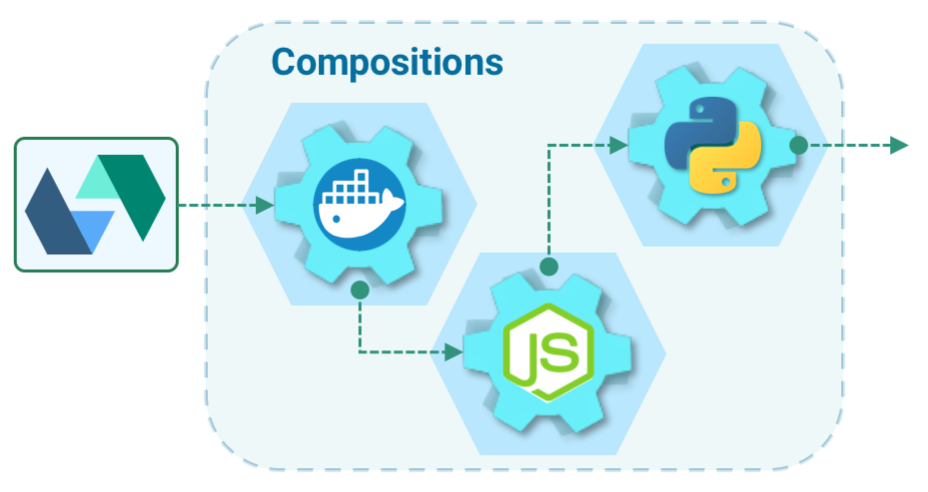
将您的功能组合成丰富的组合
使用JavaScript / NodeJS,Swift,Python,Java等不同语言编写的代码,或者通过与Docker打包代码来运行自定义逻辑。 同步,异步或按计划调用代码。 使用诸如序列之类的高级编程构造将多个动作声明式链接在一起。 使用参数绑定可以避免在代码中对服务凭据进行硬编码。 并且,使用各种开发工具实时调试代码。
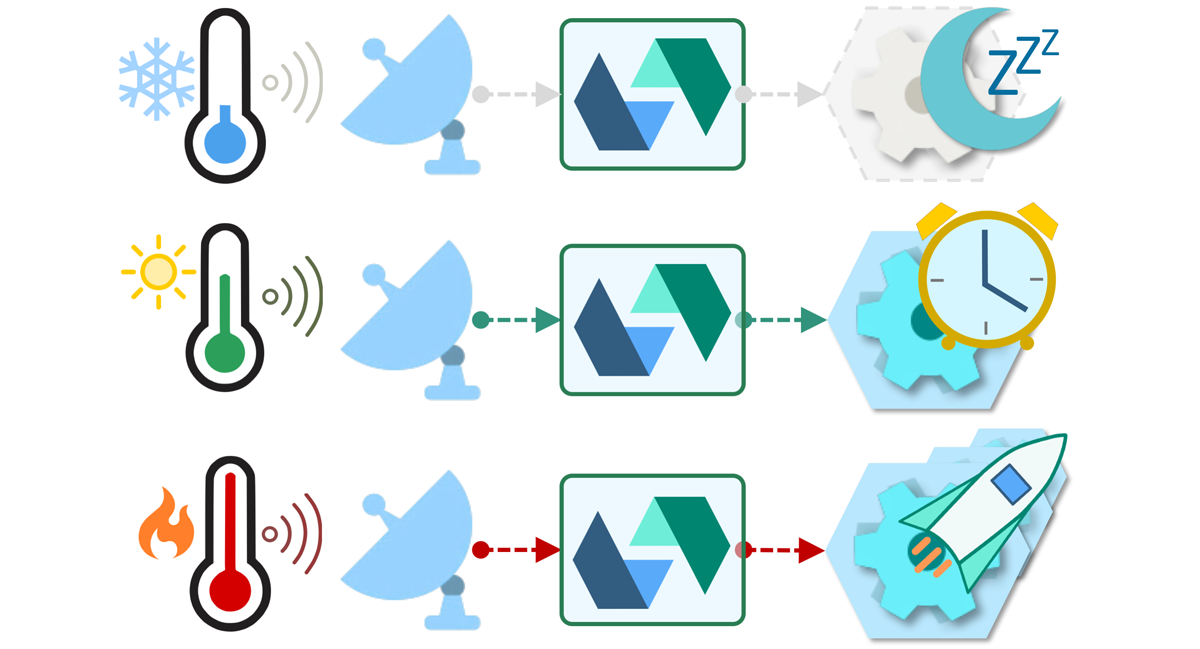
按需扩展规模和最佳资源利用
在不到一秒的时间内,即可一次执行一万次,或者每周一次。 动作实例可以根据需要进行扩展以满足需求,然后消失。 在不为空闲资源付费的情况下,享受最佳利用率。
原文:http://openwhisk.apache.org/
本文:http://jiagoushi.pro/node/900
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 48 次浏览
【无服务器架构】Knative Eventing 介绍
Knative Eventing是一个旨在满足云原生开发的常见需求的系统,并提供可组合的原语以启用后期绑定事件源和事件使用者。
设计概述
Knative Eventing是围绕以下目标设计的:
- 原始事件服务是松散耦合的。这些服务可以在各种平台上(例如Kubernetes,VM,SaaS或FaaS)独立开发和部署。
- 事件生产者和事件消费者是独立的。任何生产者(或源)都可以在有活动的事件使用者监听之前生成事件。在有生产者创建事件之前,任何事件消费者都可以对事件或事件类别表示兴趣。
- 可以将其他服务连接到Eventing系统。这些服务可以执行以下功能:
- 创建新的应用程序而无需修改事件生产者或事件使用者。
- 从生产者那里选择事件的特定子集并将其作为目标。
- 确保跨服务的互操作性。 Knative Eventing与由CNCF Serverless WG开发的CloudEvents规范一致。
事件消费者
为了能够交付到多种类型的服务,Knative Eventing定义了两个通用接口,可以由多个Kubernetes资源实现:
- 可寻址对象能够接收和确认通过HTTP发送到其status.address.url字段中定义的地址的事件。作为一种特殊情况,核心的Kubernetes Service对象还实现了Addressable接口。
- 可调用对象能够接收通过HTTP传递的事件并转换该事件,从而在HTTP响应中返回0或1个新事件。可以以与处理来自外部事件源的事件相同的方式来进一步处理这些返回的事件。
事件经纪人和触发器
从v0.5开始,Knative Eventing定义了Broker和Trigger对象,使过滤事件更加容易。
代理提供了一系列事件,可以通过属性选择事件。它接收事件并将其转发给由一个或多个匹配触发器定义的订户。
触发器描述了事件属性的过滤器,应将其传递给可寻址对象。您可以根据需要创建任意数量的触发器。

事件注册表
从v0.6开始,Knative Eventing定义了一个EventType对象,以使消费者更容易发现可以从不同的Broker消费的事件类型。
注册表包含事件类型的集合。注册表中存储的事件类型包含(全部)必需的信息,供消费者创建触发器而不使用某些其他带外机制。
若要了解如何使用注册表,请参阅事件注册表文档。
事件频道和订阅
Knative Eventing还定义了事件转发和持久层,称为Channel。每个通道都是一个单独的Kubernetes自定义资源。使用订阅将事件传递到服务或转发到其他渠道(可能是其他类型)。这使群集中的消息传递可以根据需求而变化,因此某些事件可能由内存中的实现处理,而其他事件则可以使用Apache Kafka或NATS Streaming持久化。
请参阅渠道实施清单。
更高级别的事件构造
在某些情况下,您可能希望一起使用一组协作功能,对于这些用例,Knative Eventing提供了两个附加资源:
- 序列提供了一种定义功能的有序列表的方法。
- 并行提供了一种定义事件分支列表的方法。
未来的设计目标
下一个Eventing版本的重点是使事件源的易于实现。源使用Kubernetes Custom Resources管理来自外部系统的事件的注册和传递。在Eventing工作组中了解有关Eventing开发的更多信息。
安装
目前,Knative Eventing要求安装的Istio版本> = 1.0或Gloo版本> = 0.18.16的Knative Serving。按照说明在您选择的平台上进行安装。
架构
事件基础结构目前支持两种形式的事件传递:
- 从源直接传递到单个服务(可寻址端点,包括Knative服务或核心Kubernetes服务)。在这种情况下,如果目标服务不可用,则源负责重试或排队事件。
- 使用渠道和订阅从源或服务响应向多个端点进行扇出交付。在这种情况下,通道实现可确保将消息传递到请求的目标,并且如果目标服务不可用,则应缓冲事件。
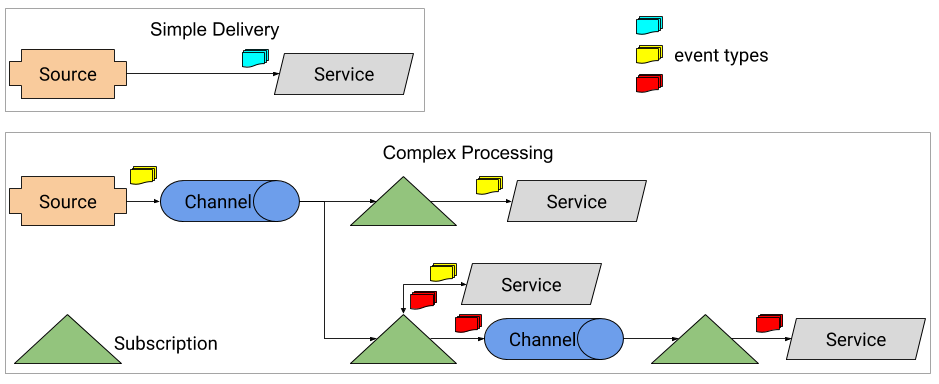
实际的消息转发是由多个数据平面组件实现的,这些组件提供可观察性,持久性以及不同消息传递协议之间的转换。
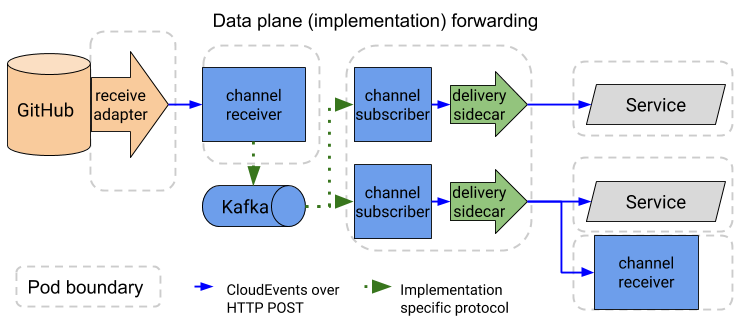
来源
每个源都是一个单独的Kubernetes自定义资源。这允许每种类型的Source定义实例化Source所需的参数和参数。 Knative Eventing在sources.eventing.knative.dev API组中定义了以下Sources。以下类型以golang格式声明,但在YAML中可以表示为简单列表等。所有源都应属于源类别,因此您可以使用kubectl get源列出所有现有源。当前实现的源描述如下。
除了核心资源(如下所述)外,您还可以安装其他资源。
如果您需要可用的Source实现中未涵盖的Source,则提供有关编写自己的Source的教程。
如果您的代码需要将事件作为其业务逻辑的一部分发送,并且不适合源模型,请考虑将事件直接馈送给Broker。
KubernetesEventSource
每当创建或更新Kubernetes事件时,KubernetesEventSource都会触发一个新事件。
规格字段:
- namespace:string要监视事件的名称空间。
- serviceAccountname:string用于连接到Kubernetes apiserver的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
请参阅Kubernetes事件源示例。
GitHub源
GitHubSource为选定的GitHub事件类型触发一个新事件。
规格字段:
- ownerAndRepository:string从中接收事件的GitHub所有者/组织和存储库。该存储库可以保留下来以接收来自整个组织的事件。
- eventTypes:[]字符串“ Webhook事件名称”格式的事件类型列表(lower_case)。
- accessToken.secretKeyRef:包含用于配置GitHub Webhook的GitHub访问令牌的SecretKeySelector。必须设置此之一或secretToken。
- secretToken.secretKeyRef:SecretKeySelector,其中包含用于配置GitHub Webhook的GitHub秘密令牌。必须设置其中之一或accessToken。
- serviceAccountName:string用来运行容器的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
- githubAPIURL:字符串可选字段,用于指定API请求的基本URL。如果未指定,则默认为公共GitHub API,但可以将其设置为要与GitHub Enterprise一起使用的域端点,例如https://github.mycompany.com/api/v3/。应始终在该基本URL后面加上斜杠。
参见GitHub Source示例。
GcpPubSubSource
每次在Google Cloud Platform PubSub主题上发布消息时,GcpPubSubSource都会触发一个新事件。
规格字段:
- googleCloudProject:字符串拥有该主题的GCP项目ID。
- topic:字符串PubSub主题的名称。
- serviceAccountName:字符串用于访问gcpCredsSecret的ServiceAccount的名称。
- gcpCredsSecret:ObjectReference对Secret的引用,其中包含用于与PubSub对话的GCP刷新令牌。
- sink:ObjectReference对应该接收事件的对象的引用。
请参阅GCP PubSub来源示例。
AwsSqsSource
每次在AWS SQS主题上发布事件时,AwsSqsSource都会触发一个新事件。
规格字段:
- queueURL:从中提取事件的SQS队列的URL。
- awsCredsSecret:用于轮询AWS SQS队列的凭证。
- sink:ObjectReference对应该接收事件的对象的引用。
- serviceAccountName:字符串用于访问awsCredsSecret的ServiceAccount的名称。
ContainerSource
ContainerSource将实例化一个容器映像,该映像可以生成事件,直到ContainerSource被删除。例如,可以使用它来轮询FTP服务器上的新文件,或在设定的时间间隔内生成事件。
规格字段:
- image(必填):字符串要运行的容器的docker镜像。
- args:[] string命令行参数。如果未提供--sink标志,则将添加一个并用接收器对象的DNS地址填充。
- env:map [string] string要在容器中设置的环境变量。
- serviceAccountName:string用来运行容器的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
-
CronJobSource
CronJobSource根据给定的Cron时间表触发事件。
规格字段:
- schedule(必填):字符串Cron格式的字符串,例如0 * * * *或@hourly。
- data:字符串发送到下游接收器的可选数据。
- serviceAccountName:string用来运行容器的ServiceAccount的名称。
- sink:ObjectReference对应该接收事件的对象的引用。
请参阅Cronjob源示例。
Kafka资
KafkaSource从Apache Kafka集群读取事件,并将事件传递给Knative Serving应用程序,以便可以使用它们。
规格字段:
- ConsumerGroup:字符串Kafka消费者组的名称。
- bootstrapServers:字符串用逗号分隔的Kafka Broker主机名:端口对列表。
- topic:字符串,用于吸收消息的Kafka主题的名称。
- net:可选的网络配置。
- sasl:可选的SASL身份验证配置。
- enable:布尔值如果为true,则使用SASL进行身份验证。
- user.secretKeyRef:包含要使用的SASL用户名的SecretKeySelector。
- password.secretKeyRef:包含要使用的SASL密码的SecretKeySelector。
- tls:可选的TLS配置。
- enable:布尔值如果为true,则在连接时使用TLS。
- cert.secretKeyRef:包含要使用的客户端证书的SecretKeySelector。
- key.secretKeyRef:包含要使用的客户端密钥的SecretKeySelector。
- caCert.secretKeyRef:包含要验证服务器证书时使用的服务器CA证书的SecretKeySelector。
参见Kafka Source示例。
CamelSource
CamelSource是事件源,可以代表提供用户端并允许将事件发布到可寻址端点的任何现有Apache Camel组件。每个Camel端点都具有URI的形式,其中方案是要使用的组件的ID。
CamelSource要求将Camel-K安装到当前名称空间中。
规格字段:
- 来源:有关应创建的骆驼来源类型的信息。
- component:默认类型的源,可通过配置单个Camel组件来创建EventSource。
- uri:字符串包含应用于将事件推送到目标接收器的骆驼URI。
- 属性:键/值映射包含Camel全局选项或特定于组件的配置。每个现有的Apache Camel组件的文档中都提供了选项。
- serviceAccountName:字符串,可用于运行源容器的可选服务帐户。
- image:字符串(可选)用于源pod的可选基本图像,主要用于开发目的。
参见CamelSource示例
原文:https://knative.dev/docs/eventing/
本文:
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 369 次浏览
【无服务器架构】Knative Serving 介绍
Knative Serving建立在Kubernetes和Istio之上,以支持无服务器应用程序和功能的部署和服务。服务易于上手,并且可以扩展以支持高级方案。
Knative Serving项目提供了中间件原语,这些原语可实现:
- 快速部署无服务器容器
- 自动放大和缩小到零
- Istio组件的路由和网络编程
- 部署的代码和配置的时间点快照
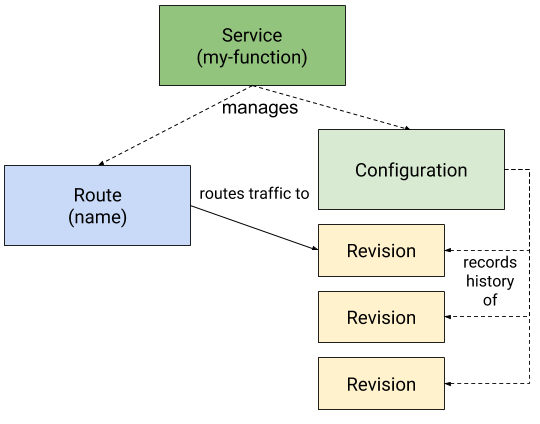
服务资源
Knative Serving将一组对象定义为Kubernetes自定义资源定义(CRD)。这些对象用于定义和控制无服务器工作负载在集群上的行为:
服务:
service.serving.knative.dev资源自动管理您的工作负载的整个生命周期。它控制其他对象的创建,以确保您的应用为服务的每次更新都具有路由,配置和新修订版。可以将服务定义为始终将流量路由到最新修订版或固定修订版。
路由:
route.serving.knative.dev资源将网络端点映射到一个或多个修订版。您可以通过几种方式管理流量,包括部分流量和命名路由。
配置:
configuration.serving.knative.dev资源维护部署的所需状态。它在代码和配置之间提供了清晰的分隔,并遵循了十二要素应用程序方法。修改配置会创建一个新修订。
修订版:
revision.serving.knative.dev资源是对工作负载进行的每次修改的代码和配置的时间点快照。修订是不可变的对象,可以保留很长时间。可以根据传入流量自动缩放“服务提供修订”。有关更多信息,请参见配置自动缩放器。

入门
要开始使用Serving,请查看您好世界示例项目之一。这些项目使用服务资源,该资源为您管理所有详细信息。
使用服务资源,已部署的服务将自动创建匹配的路由和配置。每次更新服务时,都会创建一个新修订。
有关资源及其交互的更多信息,请参阅Knative Serving存储库中的“资源类型概述”。
更多样本和演示
本地服务代码示例
设置日志记录和指标
- 安装日志记录,度量和跟踪
- 访问日志
- 访问指标
- 访问跟踪
- 设置日志记录插件
调试基本服务问题
- 调试应用程序问题
- 调试性能问题
配置和网络
- 配置集群本地路由
- 使用自定义域
- 在Google Kubernetes Engine上为Knative分配静态IP地址
已知的问题
- 有关已知问题的完整列表,请参见“服务问题”页面。
原文:https://knative.dev/docs/serving/
本文:http://jiagoushi.pro/knative-eventing-introduction
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 66 次浏览
【无服务器架构】openwhisk 系统概览
OpenWhisk是一个事件驱动的计算平台,也称为无服务器计算或功能即服务(FaaS),用于响应事件或直接调用而运行代码。 下图显示了高级OpenWhisk体系结构。

事件的示例包括数据库记录的更改,超过特定温度的IoT传感器读数,将新代码提交到GitHub存储库或来自Web或移动应用程序的简单HTTP请求。来自外部和内部事件源的事件通过触发器进行传递,并且规则允许操作对这些事件做出反应。
操作可以是小的代码片段(支持JavaScript,Swift和许多其他语言),也可以是嵌入在Docker容器中的自定义二进制代码。每当触发触发器时,OpenWhisk中的操作就会立即部署并执行。触发次数越多,调用的动作越多。如果没有触发触发器,则不会运行任何操作代码,因此没有成本。
除了将动作与触发器相关联之外,还可以通过使用OpenWhisk API,CLI或iOS SDK直接调用动作。一组动作也可以链接在一起,而无需编写任何代码。依次调用链中的每个动作,并将一个动作的输出作为输入传递到序列中的下一个动作。
对于传统的长期运行的虚拟机或容器,通常的做法是部署多个VM或容器以抵御单个实例的故障。但是,OpenWhisk提供了一种替代模型,没有与弹性相关的成本开销。按需执行操作可提供固有的可伸缩性和最佳利用率,因为正在运行的操作数始终与触发率匹配。此外,开发人员现在只关注代码,而不必担心监视,修补和保护基础服务器,存储,网络和操作系统基础结构。
与其他服务和事件提供程序的集成可以随包一起添加。一揽子计划是一堆提要和操作。提要是一段代码,用于配置外部事件源以触发触发事件。例如,使用Cloudant变更Feed创建的触发器将配置服务,以在每次文档被修改或添加到Cloudant数据库时触发该触发器。包中的动作表示服务提供者可以提供的可重用逻辑,以便开发人员不仅可以将服务用作事件源,还可以调用该服务的API。
现有的软件包目录提供了一种快速的方法来增强具有有用功能的应用程序,并访问生态系统中的外部服务。启用了OpenWhisk的外部服务的示例包括Cloudant,The Weather Company,Slack和GitHub。
OpenWhisk的工作方式
作为一个开源项目,OpenWhisk站在Nginx,Kafka,Docker,CouchDB等巨头的肩膀上。所有这些组件共同构成了“无服务器基于事件的编程服务”。为了更详细地解释所有组件,让我们跟踪动作在系统发生时的调用。无服务器引擎的核心工作是OpenWhisk中的调用:执行用户输入到系统中的代码,并返回执行结果。
创建动作
为了提供一些上下文说明,我们首先在系统中创建一个动作。 我们将在稍后浏览系统时使用该操作来解释概念。 以下命令假定已正确设置OpenWhisk CLI。
首先,我们将创建一个包含以下代码的action.js文件,该代码会将“ Hello World”打印到标准输出,并在键“ hello”下返回一个包含“ world”的JSON对象。
function main() { console.log('Hello World'); return { hello: 'world' }; }
我们使用创建该动作。
wsk action create myAction action.js
做完了 现在我们实际上要调用该动作:
wsk action invoke myAction --result
内部处理流程
OpenWhisk幕后实际上发生了什么?

进入系统:nginx
第一:OpenWhisk的面向用户的API完全基于HTTP,并采用RESTful设计。 因此,通过wsk CLI发送的命令实际上是针对OpenWhisk系统的HTTP请求。 上面的特定命令大致翻译为:
POST /api/v1/namespaces/$userNamespace/actions/myAction Host: $openwhiskEndpoint
注意这里的$ userNamespace变量。用户可以访问至少一个名称空间。为了简单起见,假设用户拥有放置myAction的名称空间。
进入系统的第一个入口是通过nginx,“ HTTP和反向代理服务器”。它主要用于SSL终止并将适当的HTTP调用转发到下一个组件。
进入系统:控制器
对我们的HTTP请求没有做很多事情,nginx将其转发到Controller,这是我们通过OpenWhisk进行的下一个组件。它是实际REST API(基于Akka和Spray)的基于Scala的实现,因此可以用作用户可以做的所有事情的接口,包括在OpenWhisk中对实体的CRUD请求和动作的调用(这就是我们的现在正在做)。
控制器首先消除用户要做什么的歧义。它基于您在HTTP请求中使用的HTTP方法来执行此操作。根据上面的翻译,用户向现有动作发出POST请求,控制器将其转换为动作的调用。
鉴于控制器的中心作用(因此得名),以下步骤在一定程度上都会涉及它。
身份验证和授权:CouchDB
现在,控制器将验证您的身份(身份验证),以及您是否有权对实体执行您想做的事情(授权)。将根据CouchDB实例中的所谓主题数据库验证请求中包含的凭据。
在这种情况下,将检查用户是否存在于OpenWhisk的数据库中,并检查该用户是否有权调用动作myAction,我们假设该动作是用户拥有的命名空间中的动作。后者有效地赋予了用户调用该操作的特权,这是他希望执行的操作。
一切正常后,门打开,进入下一阶段的处理。
采取行动:再次CouchDB…
由于Controller现在确定允许用户进入并具有调用其操作的特权,因此它实际上是从CouchDB的拂数据库中加载了此操作(在本例中为myAction)。
动作记录主要包含要执行的代码(如上所示)和要传递给动作的默认参数,并与实际调用请求中包含的参数合并。它还包含执行时对其施加的资源限制,例如允许使用的内存。
在这种特殊情况下,我们的操作没有任何参数(该函数的参数定义是一个空列表),因此我们假设我们没有设置任何默认参数,也没有向该操作发送任何特定的参数,从这个角度来看,最琐碎的情况。
谁来执行该操作:负载均衡器
作为控制器一部分的负载均衡器通过连续检查其运行状况来全局查看系统中可用的执行器。这些执行者被称为祈求者。知道哪些可用的调用程序的负载均衡器会选择其中之一来调用请求的操作。
请排队:Kafka
从现在开始,您发送的调用请求可能主要发生两件事:
- 系统可能崩溃,丢失您的调用。
- 系统可能会承受如此沉重的负担,以至于调用需要先等待其他调用才能完成。
两者的答案都是Kafka,“一个高吞吐量,分布式,发布-订阅消息系统”。 Controller和Invoker仅通过Kafka缓冲和保留的消息进行通信。这样就减轻了控制器和调用者的内存缓冲负担,并冒出OutOfMemoryException的风险,同时还确保在系统崩溃的情况下不会丢失消息。
为了调用该动作,控制器将消息发布到Kafka,其中包含要调用的动作和传递给该动作的参数(在本例中为无)。该消息发送给控制器从上方从可用调用者列表中选择的调用者。
Kafka确认收到消息后,将使用ActivationId响应对用户的HTTP请求。用户稍后将使用它来访问此特定调用的结果。请注意,这是一个异步调用模型,在该模型中,一旦系统接受了调用某个动作的请求,HTTP请求就会终止。可以使用同步模型(称为阻塞调用),但本文不会介绍。
实际上已经在调用代码了:调用者
调用程序是OpenWhisk的心脏。调用者的职责是调用一个动作。它也在Scala中实现。但是还有更多的东西。为了以隔离和安全的方式执行操作,它使用Docker。
Docker用于为我们以快速,隔离和受控的方式调用的每个动作设置一个新的自封装环境(称为容器)。简而言之,对于每个动作调用,都会产生一个Docker容器,该动作代码被注入,并使用传递给它的参数执行该操作代码,获得结果,该容器被销毁。这也是进行大量性能优化以减少开销和缩短响应时间的地方。
在我们的特定情况下,由于手头有一个基于Node.js的操作,Invoker将启动一个Node.js容器,从myAction注入代码,不带任何参数运行它,提取结果,保存日志并销毁再次使用Node.js容器。
存储结果:再次CouchDB
由于调用者获得了结果,因此将其存储为激活数据库,作为上面进一步提到的ActivationId下的激活。激活数据库位于CouchDB中。
在我们的特定情况下,Invoker从操作中获取返回的JSON对象,获取Docker编写的日志,将它们全部放入激活记录中并将其存储到数据库中。大致如下所示:
{ "activationId": "31809ddca6f64cfc9de2937ebd44fbb9", "response": { "statusCode": 0, "result": { "hello": "world" } }, "end": 1474459415621, "logs": [ "2016-09-21T12:03:35.619234386Z stdout: Hello World" ], "start": 1474459415595, }
注意记录如何包含返回的结果和写入的日志。 它还包含操作调用的开始时间和结束时间。 激活记录中有更多字段,为简化起见,这是简化版本。
现在,您可以再次使用REST API(再次从步骤1开始)以获取激活,从而获得操作结果。 为此,您可以使用:
wsk activation get 31809ddca6f64cfc9de2937ebd44fbb9
摘要
我们已经了解了一个简单的wsk动作如何调用myAction贯穿OpenWhisk系统的不同阶段。 系统本身主要仅包含两个自定义组件,即Controller和Invoker。 其他一切都已经存在,由开源社区中如此众多的人开发。
您可以在以下主题中找到有关OpenWhisk的其他信息:
- 实体名称
- 动作语义
- 限度
- REST API
原文:https://github.com/apache/openwhisk/blob/master/docs/about.md
本文:http://jiagoushi.pro/node/899
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 68 次浏览
【无服务器架构】openwhisk 通用使用案例
OpenWhisk提供的执行模型支持各种用例。以下各节包括典型示例。有关无服务器体系结构,示例用例,优缺点讨论和实现最佳实践的更详细讨论,请阅读Martin Fowler博客上的Mike Roberts优秀文章。
微服务
尽管具有微服务的优势,基于微服务的解决方案仍然难以使用主流的云技术来构建,通常需要控制复杂的工具链以及独立的构建和运营管道。小型而敏捷的团队花费大量时间来处理基础架构和操作复杂性(容错,负载平衡,自动缩放和日志记录),尤其希望使用一种方式来开发精简的,增值的代码,这些代码已经使用了已知的编程语言。爱,最适合解决特定问题。
OpenWhisk具有模块化和固有的可伸缩性,因此非常适合在操作中实现细粒度的逻辑。 OpenWhisk动作彼此独立,可以使用OpenWhisk支持的多种不同语言来实现,并可以访问各种后端系统。每个动作都可以独立部署和管理,并且可以独立于其他动作进行扩展。 OpenWhisk以规则,序列和命名约定的形式提供动作之间的互连性。这对于基于微服务的应用程序来说是个好兆头。
Web应用
尽管OpenWhisk最初是为基于事件的编程而设计的,但它为面向用户的应用程序提供了许多好处。例如,将其与较小的Node.js存根结合使用时,可以使用它为相对容易调试的应用程序提供服务。而且,由于与在PaaS平台上运行服务器进程相比,OpenWhisk应用程序的计算强度要低得多,因此它们的价格也要便宜得多。
可以使用OpenWhisk构建和运行完整的Web应用程序。将无服务器API与用于站点资源的静态文件托管相结合,例如HTML,JavaScript和CSS意味着我们可以构建整个无服务器的Web应用程序。与站起来并操作Node.js Express或其他传统服务器运行时相比,操作托管OpenWhisk环境的简单性(或者因为它托管在IBM Cloud上而根本不需要操作任何东西)是一个巨大的好处。
其中一项有用的功能是使用OpenWhisk CLI wsk工具(称为“ --annotation web-export true”)的选项,该工具可从Web浏览器访问代码。
以下是一些有关如何使用OpenWhisk构建Web应用程序的示例:
Web操作:具有OpenWhisk的无服务器Web应用程序。
使用IBM Cloud Functions和Node.js构建面向用户的OpenWhisk应用程序
使用OpenWhisk的无服务器HTTP处理程序
物联网
当然可以使用传统的服务器架构来实现物联网应用,但是在许多情况下,不同服务和数据桥的结合需要高性能和灵活的管道,从物联网设备到云存储和分析平台。通常,预配置的网桥缺乏实现和微调特定解决方案体系结构所需的可编程性。鉴于可能的管道种类繁多,并且一般而言,尤其是在IoT中,围绕数据融合的问题缺乏标准化,因此在许多情况下,管道需要自定义数据转换(用于格式转换,过滤,扩充等)。 OpenWhisk是一种出色的工具,可以以“无服务器”方式实现这种转换,其中自定义逻辑托管在完全托管且具有弹性的云平台上。
物联网场景通常固有地是传感器驱动的。例如,如果需要对超过特定温度的传感器做出反应,则可能会触发OpenWhisk中的操作。物联网交互通常是无状态的,在发生重大事件(自然灾害,重大天气事件,交通拥堵等)的情况下,可能会产生非常高的负载水平。这产生了对弹性系统的需求,该系统的正常工作量可能很小,但需要具有可预测的响应时间,能够迅速扩展,并且能够处理大量事件,而无需事先向系统发出警告。使用传统的服务器体系结构来构建满足这些要求的系统非常困难,因为它们要么功率不足,无法处理流量高峰,要么配置过度且极其昂贵。
这是一个使用OpenWhisk,NodeRed,Cognitive和其他服务的示例IoT应用程序:使用OpenWhisk对IoT实时数据进行无服务器转换。

API后端
无服务器计算平台为开发人员提供了一种无需服务器即可快速构建API的方法。 OpenWhisk支持自动生成用于操作的REST API,并且很容易将您选择的API管理工具(例如IBM API Connect或其他)连接到OpenWhisk提供的这些REST API。与其他用例相似,适用于可伸缩性和所有其他服务质量(QoS)的所有注意事项。
这是使用Serverless作为API后端的示例和讨论。
移动后端
许多移动应用程序需要服务器端逻辑。对于不想管理服务器端逻辑而宁愿专注于设备或浏览器上运行的应用程序的移动开发人员,使用OpenWhisk作为服务器端后端是一个很好的解决方案。此外,对Swift的内置支持使开发人员可以重用其现有的iOS编程技能。移动应用程序通常具有不可预测的负载模式,并且托管的OpenWhisk解决方案(例如IBM Cloud Functions)可以扩展以满足几乎任何工作负载需求,而无需提前配置资源。
数据处理
由于现在可用的数据量很大,因此应用程序开发需要具有处理新数据并可能对其做出反应的能力。此要求包括处理结构化数据库记录以及非结构化文档,图像或视频。可以通过提供的系统或自定义提要来配置OpenWhisk,以对数据更改做出反应并自动对传入的数据提要执行操作。可以对动作进行编程以处理更改,转换数据格式,发送和接收消息,调用其他动作,更新各种数据存储,包括基于SQL的关系数据库,内存中的数据网格,NoSQL数据库,文件,消息传递代理和各种其他系统。 OpenWhisk规则和序列提供了无需编程即可灵活地更改处理管道的灵活性-只需通过配置更改即可。这使得基于OpenWhisk的系统具有高度的灵活性,并易于适应不断变化的需求。
认知应用
认知技术可以与OpenWhisk有效结合,以创建功能强大的应用程序。例如,IBM Alchemy API和Watson Visual Recognition可与OpenWhisk一起使用,以自动从视频中提取有用的信息,而无需实际观看。
这是一个示例应用程序Dark vision,它就是这样做的。在此应用程序中,用户使用Dark Vision Web应用程序上载视频或图像,该应用程序将其存储在Cloudant DB中。视频上传后,OpenWhisk通过听Cloudant更改(触发)来检测新视频。然后,OpenWhisk触发视频提取器操作。在执行过程中,提取器将生成帧(图像)并将其存储在Cloudant中。然后使用Watson Visual Recognition处理帧,并将结果存储在同一Cloudant DB中。可以使用Dark Vision Web应用程序或iOS应用程序查看结果。除Cloudant外,还可以使用对象存储。这样做时,视频和图像元数据存储在Cloudant中,媒体文件存储在对象存储中。
原文:https://github.com/apache/openwhisk/blob/master/docs/use_cases.md
本文:http://jiagoushi.pro/openwhisk-common-use-cases
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 42 次浏览
【无服务器架构】什么时候无服务器架构是应用程序的正确选择?考虑利弊
在适当的情况下,我们喜欢无服务器架构。但这些情况是什么呢?
在前一篇关于web开发中的无服务器架构的文章中,我们讨论了为什么我们相信无服务器将是云原生开发的未来。不可否认的是,重点是无服务器架构的优势。在我们的无服务器系列的这一期中,我们将通过概述无服务器的缺点以及在哪些情况下它可能不是你的下一个应用的最佳方法来增加更多的平衡。
当然,没有任何技术或架构是适用于所有情况的完美解决方案。在无服务器的web开发中,可以感知到的弱点在某种程度上得到弥补,这意味着它们不会拖累技术解决方案或业务案例,以达到优势被削弱的程度?
我们还将把无服务器web开发的优缺点理论应用于示例应用程序。这将说明在何种情况下,serverless的优点和缺点的平衡使得它成为技术堆栈的最佳选择,而在哪些情况下它可能不是最佳选择。
为了平衡我们上一篇文章中略显夸张的pro-serverless的立场,让我们从这次无服务器web开发的缺点开始:
Serverless缺点
那么,采用无服务器开发方法可能存在哪些问题和缺点呢?
厂商锁定
在与我们自己的架构师和客户讨论serverless是否是一个新的开发项目的正确方式时,我们经常会看到对供应商锁定的担忧。有一种看法认为,一旦应用程序的无服务器架构由一家云供应商(通常是GCD、AWS和Azure)建立起来,如果环境发生变化,那么要迁移到另一家云供应商就非常困难(昂贵且耗时)。
在现实中,如果从一个新的应用程序项目开始就提供正确的方法,供应商锁定不一定是无服务器开发的缺点。至少对大多数应用程序来说不是这样。对于真正的大型应用程序来说,供应商之间的迁移不可避免地会非常复杂。
例如,你正在设计一个具有以下功能的web应用程序:
- 安全的用户标识
- 收集及储存一些个人资料
- 应用程序功能的用户界面
让我们比较一下传统web开发和无服务器开发方法所需要的技术栈。
传统的web开发:
- 身份识别:Spring安全框架(Java)
- 数据存储:NoSQL更适合这里,因为不需要事务(MongoDB)
- 通知:带有Websockets的Spring
- 支付方式:第三方服务
- 业务逻辑核心:带有REST端点的Spring框架(Java)
无服务器web开发与AWS:
- 标识:AWS Cognito
- 数据存储:AWS DynamoDB
- 通知:AWS简单通知服务
- 支付方式:第三方服务
- 业务逻辑核心:AWS Lambda
许多不同的应用程序都需要用户标识、数据存储、通知和支付。除此之外,只有应用程序的“核心”才能被认为是“独特的”。
传统的web开发需要对用户标识、数据存储、通知和支付进行自定义配置和编码。因此,任何改进、开发或修复应用程序中的问题的改变都需要一个新的软件开发迭代周期。这意味着任何改变都需要大量的资源(时间和金钱)。
另一方面,无服务器的web开发允许您使用“即插即用”技术来实现应用程序涉及的常见功能——用户识别、支付等。上面列出的AWS工具(Cognito、DynamoDB等)只需要配置,然后就可以在测试和生产环境之间快速、轻松地进行更改。
这意味着在最初的开发阶段以及在需要引入任何后续更改或更新时,无服务器开发可以节省大量的时间和金钱。
但是,上面所说的与围绕无服务器开发的“供应商锁定”问题有什么关系呢?假设您想将您的应用程序从AWS移动到谷歌云。在您的应用程序中使用了几种AWS技术。这在使用AWS云时非常棒。但现在就有问题了,对吧?是的。将它们转换成谷歌云的等价物将是一个痛苦的过程。这就是对无服务器开发的供应商锁定批评的症结所在。
但事实并非如此。如果从一开始就采用无服务器框架,那么无服务器应用程序可以构建为“云供应商不可知论”。无服务器框架解决方案允许您使用一个常见的配置文件来设置无服务器架构,在这个配置文件中,您只需更改云供应商的名称,就可以将AWS技术转换为谷歌云(或任何其他主要供应商的云)的对等产品。不需要任何其他操作,你的应用程序将在新的云home中像以前一样工作。
正确的无服务器开发应该意味着在云供应商之间迁移就像改变移动运营商而保持你的旧号码在最近几年变得一样容易。支持无服务器开发的框架正在迅速成熟,并且解决了供应商锁定等明显的弱点。企业越来越确信,无服务器技术栈的主要缺点正在被消除,使其优势不受损害。
可口可乐公司的方案架构师Patrick Brandt最近表示:
无服务器框架是可口可乐公司降低IT运营成本和更快部署服务计划的核心组成部分。
太积极了?我们是不是把缺点滑向了无服务器?,Serverless?在我看来只有一件事可能意味着厂商锁定是一种担心,可能阻止你为您的下一个项目采用serverless开发——常见的组件需要使用功能需要独特的代码完全控制没有商量的余地。
无服务器的运行成本是骗局吗?
反对新应用程序的无服务器开发方法的另一个常用论据是潜在的计算成本。我多次听说云资源很昂贵,用户无法控制成本。
这是部分正确的。传统的发展意味着可以准确地预测计算资源的开销。一个企业确切地知道一个应用程序需要多少服务器,它们的位置等等。预算是很容易的。
如果您选择一个没有云服务器的环境,您会在月底收到账单,并且很难预测准确的成本。尾巴上的刺是可能的。这种对管理费用缺乏控制的情况经常阻碍公司投资于无服务器的技术。
从商业的角度来看,不能准确地控制或预测成本会导致交易失败。这是否会成为瓶颈,意味着未来的无服务器开发将无法与当前的炒作相匹配?
我不这么想。首先,如果您知道自己在做什么,那么准确预测无服务器应用程序的云资源成本其实并不困难。你只需要定义你的应用将使用什么云资源,以及这些资源如何适应供应商的定价结构。是的,您可能无法准确地预测应用程序的需求和使用水平。如果它像病毒一样传播开来,你会不会被云计算供应商的发票所咬,从而毁掉你的公司?
这是一个需要考虑的问题,但在绝大多数情况下,它不会真正影响Serverless是否是合适的技术。事实上,初创企业之所以经常青睐Serverless,正是因为成本被重新加载了。运行一个应用程序是非常便宜的,直到它有大量的用户,在这一点上额外的成本是合理的。这也使得Serverless成为MVPs和新产品的理想架构。
首先,如果一个应用程序是直接盈利的,那么在需求激增的情况下,收入应该随着云资源成本的增加而增加。如果一个应用程序不能直接变现,那么它可能会增加另一种商业价值,间接代表公司的经济收益。
可能会出现意想不到的高云资源成本会对业务现金流产生负面影响的情况,尽管应用程序的正面需求高于预期。但从一开始就应该清楚,这种情况是否有可能出现。除了简单地拒绝Serverless及其作为技术堆栈的优势之外,可能还有其他解决方案。
在大多数场景中,应用程序在需求高峰期间保持一致的性能将是压倒一切的业务考虑。您是否曾经因为门户运行缓慢或在使用高峰期崩溃而离开门户?上周给亲戚买礼物时,我就是这么做的。
三个电子市场以同样的价格提供同样的产品。其中两个明显比第三个慢(过滤慢2-4秒)。是的,也许缓慢的应用程序只是低劣的架构的结果。但是,如果他们有相同的代码,他们如何有效地扩展以满足需求?
如果您使用硬件连接服务器容量,如何知道峰值需求可能需要哪些资源?您的服务器很少接近最佳容量。它们要么提供了太多的容量,而你已经为此付费,90%的时间都处于闲置状态,要么在高峰时刻容量不足,要么速度变慢,要么崩溃,失去你的业务。
有了Serveless,你就不需要‘hard plan’的能力了。它将无缝地扩展以满足需求。有很多方法可能会让您失去业务,但服务器容量运行在您需要的水平不是其中之一。
如果您真的不知道应用程序可能会有什么需求,Serverless是一个特别好的选择。你只会为你使用的东西付费,这让你能够感受事情的真相。这并不意味着成本计划在Serverless中不重要。组件成本应努力研究和技术优化的数据查询规划,lambda内存和时间消耗规划。
总之,如果您的应用程序是成熟的,并且需求趋势和服务器容量需求可以准确地长期预测,那么Serverless可能不是您可用的最便宜的选择。选择自己的固定服务器资源可能是有意义的。但是,即使在这种情况下,能够适应任何意想不到的需求高峰的混合云解决方案仍然值得考虑。
复杂的集成/迁移,从当前的非无服务器解决方案
我同意将现有体系结构迁移到无服务器体系结构或混合解决方案是具有挑战性的。然而,根据我的经验,问题的关键在于依赖于缺乏相关专业知识的开发人员。向云计算转型需要对新技能进行投资。这可能意味着为内部开发专业人员提供培训,或者引入有经验的外部帮助。
无服务器开发和传统开发之间的一个根本区别是,无服务器开发人员需要考虑并能够准确计算与他们如何构建应用程序相关的成本。所使用的技术组件、数据库请求、计算时间和性能成本有多少?这些成本是否与应用程序的业务案例和计划相匹配?传统的web开发人员不必担心这些问题。这不是他们的工作。
对于我个人来说,作为一个已经从传统开发过渡到无服务器开发的开发人员,这是工作性质中最难掌握的变化之一。组织向无服务器的转变,无论是完全的还是特定的应用程序,都应该考虑到这一点。开发人员需要接受再教育,他们的工作现在涉及在其业务案例的上下文中管理应用程序的运行成本。
什么时候无服务器开发是应用程序的最佳选择?
让我们总结一下业务考虑和应用程序的技术质量,广泛地说,这意味着它通常会受益于无服务器:
- 中小型应用程序
- 市场尚未建立,负荷难以预测
- 应用程序需要进行大量快速(快速失败)试验
- 公共模块(身份识别、通知)无独特主张
- 团队准备利用没有服务器的优势
当Serverless可能不是一个应用程序的最佳技术堆栈:
- 大型应用程序
- 确定和可预测的市场需求和高峰负荷时间
- 应用程序的特点是迭代和缓慢-实验不受欢迎
- 在公共模块中需要细粒度控制,并且它们包含唯一的流
- 团队没有做好准备,没有采用云服务器思维
在下一篇关于无服务器开发的文章中,我们将概述AWS提供的常见“即插即用”组件的优势和好处。
原文:https://kruschecompany.com/serverless-pros-and-cons/
本文:http://jiagoushi.pro/node/1278
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 35 次浏览
【无服务器架构】接触Knative -第1部分
我最近一直在研究Knative。在这个由三部分组成的博客系列中,我想解释一下我的收获,并展示一些我在GitHub上发布的Knative教程中的例子。
Knative到底是什么?
Knative是运行在Kubernetes上的无服务器容器的开源构建块集合。
此时,您可能会想:“Kubernetes,没有服务器,这是怎么回事?”但是,当你仔细想想,这是有道理的。Kubernetes是非常流行的集装箱管理平台。应用程序开发人员希望使用Serverless来运行他们的代码。Knative用一套积木将两个世界连接在一起。
谈到积木,它由3个主要组成部分:
- Knative Serving 用于快速部署和自动调整无服务器容器。
- Knative Eventing用于松散耦合、事件驱动的服务的Knative事件处理。
- Knative Build,用于注册表中的无痛苦的代码到容器的工作流。
让我们从本地服务开始。
什么是 Knative Serving ?
简而言之,Knative服务允许快速部署和自动调整无服务器容器。您只需指定要部署什么容器,而Knative负责如何创建该容器并将流量路由到它的详细信息。一旦您将您的无服务器容器部署为Knative服务,您将获得诸如自动扩展、针对每个配置更改的修订、不同修订之间的流量分割等功能。
Hello World服务(Serving)
要将你的代码部署为Knative服务,你需要:
将代码装入容器并将映像推入公共注册中心。
创建一个服务yaml文件,告诉Knative在哪里可以找到容器映像及其所有配置。
在我的Knative教程的Hello World服务部分中,我详细描述了这些步骤,但是在这里重述一下,这是一个最小的Knative服务定义service-v1的方式service-v1.yaml的样子:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: helloworld-csharp
namespace: default
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# replace {username} with your DockerHub
image: docker.io/{username}/helloworld-csharp:v1
env:
- name: TARGET
value: "C# Sample v1"
runLatest意味着我们希望立即使用指定的容器和配置部署最新版本的代码。部署服务:
kubectl apply -f service-v1.yaml
此时,您将看到创建了许多东西。首先,创建一个Knative服务及其pod。其次,创建一个配置来捕获Knative服务的当前配置。第三,将修订创建为当前配置的快照。最后,创建一个路由将流量导向新创建的Knative服务:
kubectl get pod,ksvc,configuration,revision,route
NAME READY STATUS RESTARTS
pod/helloworld-csharp-00001-deployment-7fdb5c5dc9-wf2bp 3/3 Running 0
NAME
service.serving.knative.dev/helloworld-csharp
NAME
configuration.serving.knative.dev/helloworld-csharp
NAME
revision.serving.knative.dev/helloworld-csharp-00001
NAME
route.serving.knative.dev/helloworld-csharp
改变配置
在Knative服务中,每当您更改服务的配置时,它都会创建一个新的修订,这是代码的时间点快照。它还创建了一个新的路线,新的修订将开始接收流量。
在我的Knative教程的更改配置一节中,您可以看到更改Knative服务的环境变量或容器映像如何触发新修订的创建。
流量分裂
在Knative中,您可以很容易地在服务的不同版本之间分配流量。例如,如果您想推出一个新的修订版本(0004)并将20%的流量路由到它,您可以执行以下操作:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: helloworld-csharp
namespace: default
spec:
release:
# Ordered list of 1 or 2 revisions.
# First revision is traffic target "current"
# Second revision is traffic target "candidate"
revisions: ["helloworld-csharp-00001", "helloworld-csharp-00004"]
rolloutPercent: 20 # Percent [0-99] of traffic to route to "candidate" revision
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/helloworld-csharp:v1
env:
- name: TARGET
value: "C# Sample v4"
注意,我们将runLatest模式更改为release模式,以分割服务的流量。
我的Knative教程的流量分割部分有更多的例子,比如如何在现有的版本之间分割流量。
与其他服务集成
Knative服务可以很好地与其他服务集成。例如,您可以使用Knative服务作为外部服务(如Twilio)的webhook。如果您有一个暮光之城号码,您可以回复短信发送到该号码从Knative服务。
整合暮光部分我的Knative教程有详细的步骤,但它本质上归结为创建代码处理暮光的消息:
[Route("[controller]")]
public class SmsController : TwilioController
{
[HttpGet]
public TwiMLResult Index(SmsRequest incomingMessage)
{
var messagingResponse = new MessagingResponse();
messagingResponse.Message("The Knative copy cat says: " + incomingMessage.Body);
return TwiML(messagingResponse);
}
}
定义一个Knative服务:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: twilio-csharp
namespace: default
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/twilio-csharp:v1
然后指定Knative服务为Twilio短信的一个webhook:

原文:https://medium.com/google-cloud/hands-on-knative-part-1-f2d5ce89944e
本文:http://jiagoushi.pro/node/880
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 22 次浏览
【无服务器架构】接触Knative -第二部分
在上一篇文章中,我讨论了Knative用于快速部署和自动调整无服务器容器。如果您希望您的服务由HTTP调用同步触发,那么Knative服务是很好的选择。然而,在没有服务器的微服务世界中,异步触发器更加常见和有用。这时,Knative三项赛就开始发挥作用了。
在Knative系列的第2部分中,我将介绍Knative事件并展示一些来自我的Knative教程的示例,这些示例介绍了如何将它与各种服务集成在一起。
什么是Knative Eventing?
Knative事件处理与Knative服务密切相关,它为松散耦合的事件驱动服务提供了基元。典型的Knatives事件架构是这样的:
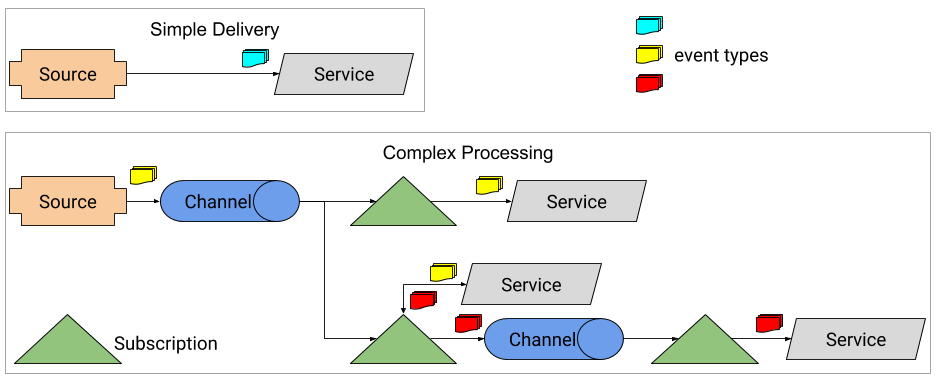
主要有4个组成部分:
- Source(也称为Producer)从实际的源中读取事件,并将事件向下转发到一个通道,或者直接转发到一个服务,这种情况比较少见。
- Channel从源接收事件,保存到其底层存储(稍后详细介绍),并向所有订阅者展开。
- 订阅连接一个通道和一个服务(或另一个通道)。
- 服务(也称为消费者)是使用事件流的Knative服务。
让我们更详细地看看这些。
来源,渠道和订阅
Knative事件的最终目标是将事件从源路由到服务,这是通过我前面提到的原语实现的:源、通道和订阅。
Source从实际源读取事件并将它们转发到下游。到目前为止,Knative支持从Kubernetes、GitHub、谷歌云发布/订阅、AWS SQS主题、容器和CronJobs读取事件。
一旦事件被拉入Knative,它就需要保存到内存中,或者保存到更持久的地方,比如Kafka或谷歌云发布/订阅。这发生在通道上。它有多个实现来支持不同的选项。
从Channel将事件传递给所有感兴趣的Knative服务或其他通道。这可以是一对一的,也可以是扇出的。订阅决定了这种交付的性质,并充当通道和Knative服务之间的桥梁。
现在我们已经了解了Knative三项赛的基础知识,让我们来看一个具体的例子。
Hello World事件
对于Hello World事件,让我们读取来自谷歌云发布/订阅的消息并在Knative服务中注销它们。我的你好世界三项赛教程有所有的细节,但在这里重述,这是我们需要设置:
- 从谷歌云发布/订阅读取消息的GcpPubSubSource。
- 将消息保存在内存中的通道。
- 链接频道到Knative服务的订阅。
- 接收消息并注销的Knative服务。
gcp-pubsub-source。yaml定义了GcpPubSubSource。它指向一个名为测试的发布/订阅主题,它有访问发布/订阅的凭证,并指定应该像这样转发哪个频道事件:
apiVersion: sources.eventing.knative.dev/v1alpha1
kind: GcpPubSubSource
metadata:
name: testing-source
spec:
gcpCredsSecret: # A secret in the knative-sources namespace
name: google-cloud-key
key: key.json
googleCloudProject: knative-atamel # Replace this
topic: testing
sink:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
name: pubsub-test
接下来,我们使用Channel .yaml定义通道。在这种情况下,我们只是在内存中保存消息:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
metadata:
name: pubsub-test
spec:
provisioner:
apiVersion: eventing.knative.dev/v1alpha1
kind: ClusterChannelProvisioner
name: in-memory-channel
继续创建源和通道:
kubectl apply -f gcp-pubsub-source.yaml
kubectl apply -f channel.yaml
你可以看到源和通道被创建,有一个源pod也被创建:
kubectl get gcppubsubsource NAME AGE testing-source 1mkubectl get channel NAME AGE pubsub-test 1mkubectl get pods NAME READY STATUS gcppubsub-testing-source-qjvnk-64fd74df6b-ffzmt 2/2 Running
最后,我们可以创建Knative服务,并使用订阅服务器中的订阅将其链接到subscriber.yaml文件:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: message-dumper-csharp
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/message-dumper-csharp:v1---
apiVersion: eventing.knative.dev/v1alpha1
kind: Subscription
metadata:
name: gcppubsub-source-sample-csharp
spec:
channel:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
name: pubsub-test
subscriber:
ref:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
name: message-dumper-csharp
如您所见,message-dump -csharp只是一个普通的Knative服务,但它是通过其订阅的Knative事件异步触发的。
kubectl apply -f subscriber.yamlservice.serving.knative.dev "message-dumper-csharp" created subscription.eventing.knative.dev "gcppubsub-source-sample-csharp" configured
一旦你kubectl apply所有的yaml文件,你可以使用gcloud发送消息到发布/订阅主题:
gcloud pubsub topics publish testing --message="Hello World"
你应该可以看到pods 的服务创建:
kubectl get pods
NAME READY
gcppubsub-testing-source-qjvnk-64fd74df6b-ffzmt 2/2 Running 0 3m
message-dumper-csharp-00001-deployment-568cdd4bbb-grnzq 3/3 Running 0 30s
服务将Base64编码的消息记录在Data下面:
info: message_dumper_csharp.Startup[0]
C# Message Dumper received message: {"ID":"198012587785403","Data":"SGVsbG8gV29ybGQ=","Attributes":null,"PublishTime":"2019-01-21T15:25:58.25Z"}
info: Microsoft.AspNetCore.Hosting.Internal.WebHost[2]
Request finished in 29.9881ms 200
查看我的Hello World事件教程,了解更多关于步骤和实际代码的细节。
与云存储和Vision API集成
当您试图以无缝的方式连接完全不相关的服务时,Knative事件就会真正地发挥作用。在我的集成与视觉API教程中,我展示了如何使用Knative事件连接谷歌云存储和谷歌云视觉API。
云存储是一种全球可用的数据存储服务。可以将bucket配置为在保存映像时发出发布/订阅消息。然后,我们可以使用Knative事件侦听这些发布/订阅消息,并将它们传递给Knative服务。在服务中,我们使用图像进行一个Vision API调用,并使用机器学习从中提取标签。所有的细节都在教程中进行了解释,但是我想在这里指出一些事情。
首先,在Knative中,所有的出站流量在缺省情况下都会被阻塞。这意味着在默认情况下,您甚至不能从Knative服务调用Vision API。这最初让我感到惊讶,所以请确保配置了网络出站访问。
其次,无论何时将图像保存到云存储中,它都会发出CloudEvents。Knative三项赛通常与CloudEvents一起使用。你需要将传入的请求解析为CloudEvents,并提取你需要的信息,如事件类型和图像文件的位置:
var cloudEvent = JsonConvert.DeserializeObject<CloudEvent>(content); var eventType = cloudEvent.Attributes["eventType"]; var storageUrl = ConstructStorageUrl(cloudEvent);
有了这些信息,很容易为图像构造存储URL并使用该URL进行Vision API调用。完整的源代码在这里解释,但这里是相关的部分:
var visionClient = ImageAnnotatorClient.Create();
var labels = await visionClient.DetectLabelsAsync(Image.FromUri(storageUrl), maxResults: 10);
一旦代码准备好了,我们就可以通过定义一个ubscriber.yaml将服务挂接到Knative事件上。它和以前很相似。我们正在重用现有的源和通道,所以我们不必重新创建它们。我们只是创建一个新的订阅指向我们新的Knative服务与愿景API容器:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: vision-csharp
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
# Replace {username} with your actual DockerHub
image: docker.io/{username}/vision-csharp:v1
---
apiVersion: eventing.knative.dev/v1alpha1
kind: Subscription
metadata:
name: gcppubsub-source-vision-csharp
spec:
channel:
apiVersion: eventing.knative.dev/v1alpha1
kind: Channel
name: pubsub-test
subscriber:
ref:
apiVersion: serving.knative.dev/v1alpha1
kind: Service
name: vision-csharp
一旦使用kubectl apply创建了所有内容,无论何时将映像保存到云存储桶中,都应该看到该映像的Knative服务日志标签。
例如,我有一张我最喜欢的地方的照片:
当我把图片保存到桶里时,我可以在日志中看到Vision API中的以下标签:
info: vision_csharp.Startup[0]
This picture is labelled: Sea,Coast,Water,Sunset,Horizon
info: Microsoft.AspNetCore.Hosting.Internal.WebHost[2]
Request finished in 1948.3204ms 200
可以看到,我们使用Knative事件将一个服务(云存储)连接到另一个服务(Vision API)。这只是一个例子,但可能性是无限的。在本教程的翻译API集成部分中,我展示了如何将发布/订阅连接到翻译API。
这就是Knative三项赛。在本系列的下一篇也是最后一篇文章中,我将讨论Knative构建。
原文:https://medium.com/google-cloud/hands-on-knative-part-2-a27729f4d756
本文:http://jiagoushi.pro/hands-knative-part-2
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 14 次浏览
【无服务器架构】无服务器架构的特点
每当新技术出现时,技术专家的首要任务就是理解采用它的含义。无服务器架构就是一个很好的例子。
不幸的是,目前很多关于无服务器体系结构的文献只关注它的优点。许多文章(以及使用的例子)都是由云提供商驱动的,因此,毫不意外地提到了积极的一面。本文试图更好地理解无服务器体系结构的特性。
我特意选择了trait这个词,而不是characteristic,因为这些是无服务器体系结构中无法更改的元素。性格是可塑的,性格是与生俱来的。性格也是中性的,因此它既不是积极的也不是消极的。在某些情况下,我将描述的性格类型可能有积极的含义,但我将保持中立的态度,这样你就会明白你将要面对的是什么。
性格也是与生俱来的,因此你必须接受它们,而不是与之抗争,因为这样的尝试很可能代价高昂。另一方面,性格特征需要花费精力去塑造,但你仍然可能犯错误。
我还应该指出Mike Robert撰写的这篇文章——他还探讨了无服务器服务的特性(https://blog.symphonia.io/defining-serverless-part-1-704d72bc8a32)。尽管我们在这里共享相同的术语,但值得注意的是,本文讨论的是体系结构的特性,而不是您使用的服务。
本文的目的不是帮助您深入理解所有的主题,而是为您提供一个大致的概述。这些是本文定义的无服务器架构的特征:
- 低的壁垒
- Hostless
- 无状态的
- 弹性
- 分布式
- 事件驱动的
低的壁垒
开始在无服务器体系结构中运行代码相对简单。您可以按照任何教程开始并让您的代码在生产级生态系统中运行。在许多方面,与典型的DevOps技能相比,学习无服务器体系结构的过程并没有那么困难——当您采用无服务器体系结构时,许多DevOps的元素并不是必需的。例如,您不必学习服务器管理技能,比如配置管理或补丁。这就是为什么低进入壁垒是无服务器体系结构的特征之一。
这意味着最初,开发人员的学习曲线比许多其他体系结构样式要低。这并不意味着学习曲线会保持在较低的水平,实际上,随着开发人员继续他们的旅程,整个学习曲线会变得更陡。
由于这种架构特性,我已经看到许多新开发人员非常快地加入到项目中,并且他们能够有效地为项目做出贡献。开发人员能够快速地达到最新的速度,这可能是无服务器项目具有更快的上市时间的原因之一。
正如我们所注意到的,事情确实变得更加复杂。例如,将基础设施作为代码、日志管理、监视,有时还包括网络,这些仍然是必需的。您必须了解如何在没有服务器的世界中实现它们。如果您来自不同的开发背景,那么您需要了解许多无服务器体系结构特性(本文将介绍这些特性)。
尽管最初进入门槛很低,但开发人员不应该假设他们可以忽略重要的体系结构原则。
我注意到的一件事是,一些开发人员倾向于认为无服务器架构意味着他们不必考虑代码设计。理由是它们只是处理函数,所以代码设计无关紧要。事实上,像SOLID这样的设计原则仍然适用——您不能将代码可维护性外包给您的无服务器平台。尽管您可以打包并将代码上传到云中以使其运行,但我强烈反对这样做,因为在无服务器体系结构中,持续交付实践仍然是相关的。
Hostless
无服务器体系结构的一个明显特征是您不再直接处理服务器。在这个时代,有各种各样的主机可以安装和运行服务——无论是物理机器、虚拟机、容器等等——用一个词来描述这一点很有用。为了避免使用已经重载的术语serverless,我将在这里使用host1,因此特性的名称为hostless。
无主机的一个优点是,您在服务器维护上的操作开销将显著减少。您无需担心升级服务器,安全补丁将自动为您应用。没有主机还意味着您将监视应用程序中不同类型的指标。这是因为您使用的大多数底层服务不会发布CPU、内存、磁盘大小等传统指标。这意味着您不再需要解释体系结构的底层操作细节。
但是不同的监视指标意味着您必须重新学习如何调优您的体系结构。AWS DynamoDB为您提供了监视和调优的读和写能力,这是一个您必须理解的概念,并且这种学习不能转移到其他没有服务器的平台上。您使用的每个服务都有其局限性。AWS Lambda有并发执行的限制,而不是CPU内核的数量。更奇怪的是,改变Lambda的内存分配大小将会改变CPU内核的数量。如果您共享一个AWS帐户用于性能测试和生产环境,那么如果性能测试意外地消耗了您的整个并发执行限制,您可能会降低生产。AWS很好地记录了这些服务的限制,所以一定要检查它,以便做出正确的体系结构决策。
由于安全补丁被自动应用到底层服务器,所以普遍存在一种误解,认为没有服务器的应用程序更安全。这是一个危险的假设。
由于无服务器体系结构具有不同的攻击载体,传统的安全保护将不适用。您的应用程序安全实践仍然适用,在代码中存储秘密仍然是一个很大的禁忌。AWS在其共享责任模型中概述了这一点,例如,如果数据包含敏感信息,您仍然需要保护数据。我强烈建议您阅读OWASP Serverless Top 10以获得关于这个主题的更多见解。
虽然您的操作开销显著减少,但值得注意的是,在极少数情况下,您仍然需要管理底层服务器更改的影响。您的应用程序可能依赖于本机库,您需要确保在升级底层操作系统时它们仍然在工作。例如,在AWS Lambda中,操作系统最近已升级到AMI 2018.03。
无状态的
函数即服务(或FaaS)是短暂的,因此不能在内存中存储任何东西,因为运行代码的计算容器将被平台自动创建和销毁。因此,无状态是无服务器体系结构中的一个特性。
无状态是横向扩展应用程序的一个好特性。无状态的概念是不鼓励在应用程序中存储状态。通过在应用程序中不存储状态,您将能够在不考虑应用程序状态的情况下水平伸缩更多实例。我在这里发现的有趣之处在于,您实际上是被迫成为无状态的,因此错误的空间大大减少了。是的,有一些注意事项:例如,计算容器可能被重用,您可以存储状态,但是如果采用这种方法,一定要小心处理。
在应用程序开发方面,您将无法使用需要状态的技术,因为状态管理的负担是强加给调用者的。例如,不能使用HTTP会话,因为您没有具有持久文件存储的传统web服务器。如果您想使用需要WebSockets这样的状态的技术,您必须等待,直到它被相应的后端作为服务支持,或者应用您自己的解决方案。
弹性
由于您的体系结构是无主机的,所以您的体系结构也具有弹性的特性。您使用的大多数无服务器服务都设计为高度弹性的,您可以从0扩展到允许的最大值,然后再回到0,大部分服务都是自动管理的。弹性是无服务器体系结构的一个特性。
弹性的好处对于可伸缩性是巨大的。这意味着您不必手动管理资源伸缩。资源配置的许多挑战消失了。在某些情况下,弹性可能只意味着您将只为您所使用的东西付费,因此如果您的使用模式较低,您将降低运行成本。
您可能不得不将您的无服务器体系结构与不支持这种灵活性的遗留系统集成在一起。当这种情况发生时,您可能会破坏下游系统,因为它们可能无法像您的无服务器体系结构那样伸缩。如果您的下游系统是关键系统,那么考虑如何缓解这个问题是很重要的——可能通过限制AWS Lambda并发性或使用队列与下游系统通信。
尽管如此高的弹性会让“拒绝服务”变得更加困难,但相反,你很容易受到“拒绝钱包”攻击。这就是攻击者试图破坏应用程序的地方,他们强迫您通过增加资源分配来超过云帐户限制。为了防止这种攻击,您可能会发现在应用程序中使用DDoS保护(如AWS Shield)很有帮助。在AWS中,设置AWS预算也很有用,这样当您的云账单飙升时,您就会得到通知。如果高弹性不是您在这里所期望的,那么在您的应用程序上设置约束也是很有用的—例如通过限制AWS Lambda的并发性。
分布式
由于无状态计算是一种特性,所以您拥有的所有持久性需求都将作为服务(BaaS)存储在后端,通常是它们的组合。一旦您更多地使用FaaS,您还会发现您的部署单元(即功能)比您所习惯的要小。因此,默认情况下,无服务器体系结构是分布式的——而且有许多组件必须通过网络集成。您的体系结构还包括将服务连接在一起,比如身份验证、数据库、分布式队列等等。
正如我们前面讨论过的,分布式系统有很多好处,包括灵活性。分布式还为您的体系结构带来了一个区域,即默认情况下的高可用性。在没有服务器的上下文中,当您的云供应商所在的区域中的一个可用性区域出现故障时,您的体系结构将能够利用仍在运行的其他可用性区域——从开发人员的角度来看,所有这些可用性区域都是不透明的。
在选择体系结构时总是要进行权衡。在这个特性中,您正在用可用性来交换一致性。通常在云计算中,每个没有服务器的服务也有自己的一致性模型。例如,在AWS S3中,对于S3桶中放入的新对象,您将获得写后读一致性。对于对象更新,S3最终是一致的。对于您来说,必须决定使用哪个BaaS是非常常见的,所以要注意它们一致性模型的行为。
另一个挑战是要熟悉分布式消息传递方法。您需要熟悉并准确理解一次性交付的难题,例如,因为分布式队列的常见消息交付方法是至少一次交付。由于这种交付方法,AWS Lambda可以被调用不止一次,因此您必须确保您的实现是幂等的(理解FaaS重试行为也很重要,其中AWS Lambda可能在失败时被执行不止一次)。您需要了解的其他挑战包括分布式事务的行为。然而,随着微服务的普及,构建分布式系统的学习资源一直在改善。
事件驱动
您的无服务器平台提供的许多BaaS自然会支持事件。对于第三方服务来说,这是一个向用户提供可扩展性的好策略,因为您无法控制它们的服务的代码。由于您将在您的无服务器体系结构中使用大量BaaS,所以您的体系结构是由trait驱动的。
我也认识到,即使您的体系结构是由trait驱动的,但这并不意味着您需要完全接受一个事件驱动的体系结构。然而,我注意到团队倾向于采用事件驱动的体系结构,当它自然地提供给他们时。这是一个类似的想法,将弹性作为特性,您仍然可以关闭它。
事件驱动带来了很多好处。您的体系结构组件之间的耦合程度很低。在无服务器架构中,很容易引入一个新函数来侦听blob存储中的更改:

图1:添加新的无服务器函数
注意,当您添加函数B时,函数A是如何不变的(参见图1)。具有高度内聚功能有很多好处,其中之一是,当一个操作失败时,可以很容易地重试它。当函数B失败时,重新尝试它意味着您不需要运行昂贵的函数A。
特别是在云环境中,云供应商将确保您的FaaS很容易与他们的BaaS集成。FaaS可以通过设计通过事件通知触发。
事件驱动体系结构的缺点是,您可能开始失去系统作为一个整体的整体视图。这使得对系统进行故障排除非常困难。分布式跟踪是您应该研究的一个领域,即使它在无服务器体系结构中仍然是一个成熟的领域。AWS X-Ray是一项可以在AWS中开箱即用的服务。x射线也有它自己的局限性,如果你已经超越了它,你应该关注这个领域,因为有第三方产品正在出现。这就是为什么日志关联id的实践是必不可少的,特别是当您在事务中使用多个BaaS时。所以一定要实现相关id。
结论
我在本文中介绍了六个无服务器体系结构特性:低进入壁垒、无主机、无状态、弹性、分布式和事件驱动。我的意图是尽可能广泛,以便您能够很好地采用无服务器体系结构。无服务器架构带来了一个有趣的范例转换,它使许多软件开发方面变得更好。但它也带来了技术人员必须适应的新挑战。还有一些关于如何处理每个特性带来的挑战的简短建议,希望这些挑战不会阻止您采用无服务器体系结构。
原文:https://www.thoughtworks.com/insights/blog/traits-serverless-architecture
本文:
讨论:请加入知识星球或者小红圈【首席架构师圈】
- 26 次浏览
【无服务器架构】节俭Kubernetes Operator 第2部分:将控制器缩放到零
在本系列博客的第1部分中,我们介绍了这样一种想法,即Kubernetes运营商(在大规模部署时)可以消耗大量资源,无论是实际资源消耗还是可调度容量的消耗。我们还介绍了一种想法,即无服务器技术可以通过在活动控制器部署空闲时减少其规模来减少对Kubernetes集群的影响。在本文中,我们将基于闲置时将Pod实例的数量缩放为零的想法,介绍一种无需进行源修改即可减少现有控制器的资源开销的技术。
将控制器缩放至零
除了核心的Kubernetes平台之外,大多数运营商和其他通用控制器都使用Deployments或StatefulSets进行部署。这两种构造都具有将标度设置为特定值的能力。然后,Kubernetes平台添加或删除吊舱以实现所需的价值。但是,将控制器扩展到一个以上的实例通常仅提供冗余。这是由于内置的一致性检查所致,该检查可确保控制器容器不会相互干扰。以下是许多控制器和操作员所特有的部署:

如果将此类部署的规模设置为0,Kubernetes控制器管理器将终止任何正在运行的Pod,从而使我们没有任何活动的控制器实例来处理资源事件。实际上,在更改比例时,我们将禁用当前控制器的事件处理。
在最简单的情况下,控制器停止时不会发生资源修改,并且在修改监视的资源之前会恢复控制器规模。在这种情况下,只需将部署规模设置为大于零的标量值,即可将控制器恢复到之前的状态。但是,当控制器停止时发生资源修改的情况又如何呢?
Kubernetes中的和解是基于称为“级别触发”的概念构建的。在级别触发的系统中,对帐是针对整个状态进行的,而不是依赖于单个事件或自上次对帐以来发生的那些事件的顺序。当进行扩展时,我们的控制器将仅查看要监视的资源,并将其状态与目标资源协调一致,而不管过渡期间发生了多少个人更改。要了解有关Kubernetes中的电平触发的更多信息,请查看James Bowes的文章“ Kubernetes中的电平触发和对帐”。
自动缩放到零
如果Kubernetes控制器部署可以容忍从零扩展到零并且可以再次备份,那么这可以根据实际活动自动完成吗?绝对是,这是控制器零缩放器的目标。
控制器零缩放器本身就是一个Kubernetes控制器,它监视Kubernetes API的活动,一旦它们变得空闲,就会自动按比例缩小控制器,稍后在发生相关资源修改后恢复缩放。由于它是由各个控制器部署上的注释完全驱动的,因此可以在现有Kubernetes部署中启用零标度控制器而无需进行源代码修改。
图2显示了控制器零缩放器如何针对正在运行的控制器部署进行工作。

启动时,控制器零缩放器开始监视具有一组批注的部署。这些注释将部署标识为控制器零缩放器应对其执行操作的控制器。一旦确定部署正在管理中,控制器零缩放器便开始监视与该控制器相关的API服务器活动。一旦在一段时间内没有发生任何资源修改,就确定该单个控制器为空闲,并且其规模设置为零。
同时,控制器零缩放器会继续监视控制器需要处理的任何Kubernetes API服务器活动。如果确实发生资源更改,将恢复规模,这将对控制器吊舱做出反应。最终结果是,在发生诸如“ kubectl apply”之类的操作之后的几分钟内,下游资源修改将完成。
让我们来看一个使用Banzai Cloud中Istio Operator的示例。我们将执行以下顺序:
- 安装Istio操作员。
- 安装控制器零缩放器。
- 以零比例标注并观察Istio Operator。
- 创建一个Istio资源,并观察Istio Operator扩大规模并处理资源修改。
首先,将通过克隆项目并利用makefile来安装相关的“自定义资源定义”(CRD)和用于部署控制器容器的StatefulSet,来安装Istio Operator:
git clone git@github.com:banzaicloud/istio-operator.git
cd istio-operator
make deploy
通过查看正在运行的实例数(应为1)来验证此部署是否成功。 您可能需要等待片刻才能激活控制器,因为首先需要拉动图像。
kubectl get statefulsets -n istio-system istio-operator-controller-manager
NAME DESIRED CURRENT AGE
istio-operator-controller-manager 1 1 8s
现在,让我们部署控制器零缩放器。 由于Docker映像尚未公开可用,因此我们需要首先构建该映像。
再次,我们将验证控制器部署实际上已经开始:
|
现在,让我们来看看自动缩放的作用。 首先,我们需要在这个特定的控制器上启用零缩放,我们将使用一组注释来做到这一点。
kubectl annotate -n istio-system statefulset -l \
controller-tools.k8s.io='1.0'\
controller-zero-scaler/idleTimeout='30s'\
controller-zero-scaler/watchedKinds='[{"apiVersion": "istio.banzaicloud.io/v1beta1", "Kind": "Istio"}]'
statefulset.apps/istio-operator-controller-manager annotated
这将添加两个与零标度活动相关的注释:
- idleTimeout:定义将控制器确定为空闲状态的速度。 在这种情况下,我们需要至少等待30秒才能观察Istio控制器的当前状态
- watchedKinds:指示哪些API对象对该控制器有意义。 对于Istio运算符,它对名称为“ Istio”的自定义资源定义感兴趣。
等待至少30秒后,您应该看到Istio控制器容器已停止:
|
|
到目前为止,我们已成功将Istio控制器缩放为零。 现在,我们来看看更改Istio资源时会发生什么。 让我们使用istio-operator目录中提供的示例:
|
|
现在,我们可以通过查看Istio控制器的容器数量来验证放大是否成功。 我们还可以检查下游操作员动作是否发生。 对于Istio Operator,将安装一些自定义资源定义(CRD)(以及多个部署)。
|
|
博客系列的第3部分
控制器零标度解决方案非常适合现有的控制器实现,因为可以在单个集群上启用它而无需进行任何源修改。 这意味着您可以直接购买操作员,并带有正确的注释,即可立即受益。
Knative是另一种在运营商和Kubernetes控制器之外具有广泛吸引力的无服务器技术。 在本系列的最后一篇博文中,我们将探讨如何将Knative事件(使用Kubernetes API Server作为事件源)用作构建Kubernetes控制器和运算符的基础。
原文:https://www.ibm.com/cloud/blog/new-builders/being-frugal-with-kubernetes-operators-part-2
本文:http://jiagoushi.pro/node/874/
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 21 次浏览
【无服务器架构】跨平台的无服务器计算Knative 简介
Knative(发音为kay-nay-tiv)扩展了Kubernetes,以提供一组中间件组件,这些组件对于构建可在任何地方运行的现代,以源代码为中心和基于容器的应用程序必不可少:本地,云端或什至是第三方数据中心。
Knative项目下的每个组件都试图识别常见的模式,并整理成功的,真实的,基于Kubernetes的框架和应用程序共享的最佳实践。关键组件专注于解决平凡而又困难的任务,例如:
-
部署容器
-
通过蓝/绿部署路由和管理流量
-
自动缩放并根据需求调整工作负载
-
将运行中的服务绑定到事件生态系统
Knative上的开发人员可以使用熟悉的习惯用法,语言和框架来部署功能,应用程序或容器工作负载。
组件
Knative由服务和事件组件组成:
- 事件-事件的管理和交付
- 服务-可扩展至零的请求驱动计算
听众
Knative专为不同的角色而设计:
该图显示了Knative的不同受众

开发者
Knative组件为开发人员提供了Kubernetes本机API,用于将无服务器风格的功能,应用程序和容器部署到自动扩展运行时。
要加入对话,请转到Knative用户Google组。
运维者
Knative组件旨在集成到更精美的产品中,大型企业的云服务提供商或内部团队可以操作这些产品。
任何企业或云提供商都可以在自己的系统中采用Knative组件,并将收益传递给客户。
贡献者
通过明确的项目范围,轻量级的治理模型以及可插拔组件之间清晰的分隔线,Knative项目建立了有效的贡献者工作流程。
Knative是一个多元化,开放且包容的社区。 要参与其中,请参阅贡献并加入Knative社区。
您自己成为Knative贡献者的道路可以从以下任何组件开始:
- 服务
- 事件
- 文件资料
本文:http://jiagoushi.pro/node/876
讨论:请加入知识星球【首席架构师圈】或者微信圈子【首席架构师圈】
- 33 次浏览