

表现是避免不必要工作的艺术。这些是我关于优化MongoDB查询的发现,你可以滚动下面的性能测试和结果。
1. 对GET操作使用精益查询
这可能是提高查询性能的最好方法。Mongoose允许您在查询的末尾添加.lean(),通过返回纯JSON对象而不是Mongoose文档,可以极大地提高查询的性能。
默认情况下,Mongoose 查询返回一个Mongoose 文档类的实例。文档比普通的JavaScript对象要重得多,因为它们有很多内部状态需要跟踪更改。启用lean option将告诉Mongoose跳过实例化完整的Mongoose文档,而只给您POJO。
精益选项告诉Mongoose 跳过补水的结果文件。这使得查询速度更快,内存消耗更少,但是结果文档是普通的旧式JavaScript对象(pojo),而不是Mongoose 文档。
然而,这是有代价的,这意味着精益文档没有:
- 更改跟踪
- 铸造和验证
- getter和setter
- 虚拟(包括“id”)
- save()函数
因此,对于不使用.save()或virtuals的GET端点和.find()操作通常是最优的。
2. 为您的查询创建自定义索引
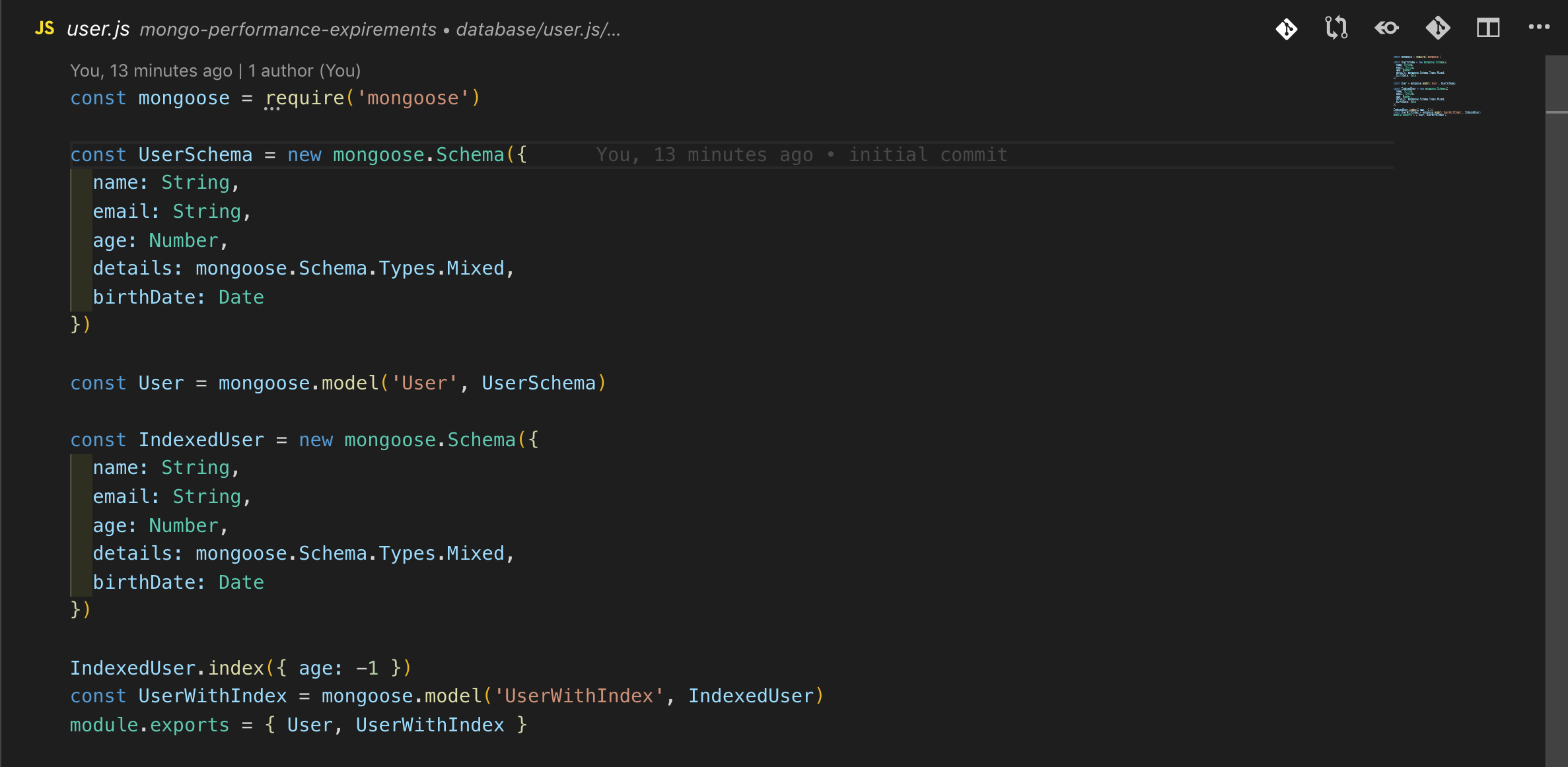
MongoDB允许您在模式中的其他属性上创建索引,而不是默认的“_id”索引。这样,您的文档就可以根据您在数据库中定义的属性建立索引,以便更快地访问。
您还可以创建多个属性的复合索引。如果您要查询多个字段,这将非常有用。假设你有一些数据库,你想找到所有灭绝的动物,你可能会写一个查询模型这样。Model.find({type: “Animal”, status: “extinct"})
MongoDB将不得不查看所有的文档来找到符合这个条件的,为了优化这个查询,你可以通过添加ModelSchema为“type”和“status”创建一个复合索引。ModelSchema.index({type: 1, status: 1}).MongoDB现在会去哪里查找相关文档。
“1”或“-1”表示属性的排序顺序。字段添加到索引中的顺序很重要。有关索引的更详细说明,请参见
https://mongoosejs.com/docs/guide.html#indexes and https://docs.mongodb.com/manual/indexes/
3.最小化DB请求(如果可能,避免.populate())
请求越多,应用程序的响应时间就越慢。尽可能地将数据库查询最小化,并将它们组合在一起,或者通过消除重复或不必要的db操作来完全避免它们。你也可以在redis中缓存你的数据库结果。
尝试以不需要过多依赖.populate()和模型之间的双向关系的方式定义模式。因为这是NoSQL数据库不是很理想的地方。在模型中添加的每个属性都将从查询中返回,因此,如果在这些字段中有数组或嵌套对象,那么文档将很容易极大地降低查询的性能。
如果你的文档包含一个数组的引用其他模型,你使用.populate()之间加入数据集合,使用.populate()将需要运行额外的查询来获取数组的实际文档里面,所以它类似于运行额外的每个id为每个文档查询。如果确实需要,最好使用.aggregate()而不是.populate()。
4. 使用.select()选择要返回的特定属性
当查询数据库中的文档时,查询将返回整个文档,但有时您有带有大量字段的大型文档,而字段是如上所述的数组/对象,因此您实际上不需要使用所有返回的属性。
为了防止数据库做额外的工作来返回这些字段增加返回文档的大小,你可以使用mongoose .select()来包括/排除你想要你的查询返回的字段,具体如下:
Model.find({type: "Animal"}).select({name: 1})
Protip:如果您使用的是GraphQL,那么它的工作效果非常好,这样您就可以确切地知道客户机请求的字段,并且可以从数据库中选择这些字段。我在这里写了另一篇文章
https://itnext.io/graphql-performance-tip-database-projection-82795e434b44
5. 并行运行数据库操作
当人们使用异步/等待时,我在NodeJS代码中看到的一个常见错误是人们在不需要的时候一个接一个地运行操作。例如:
const user = new User({name: "bob"})
const post = new Post({title: "hello"})
await user.save()
await post.save()
没有理由等待用户被保存后再保存post。相反,可以使用Promise并行运行数据库操作。所有的如下:
const [user, post] = await Promise.all([user.save(), post.save()])
虽然这可以提高API级别上的性能,但我们仍然要对数据库执行两个请求,所以如果您想批量执行多个操作,使用insertMany()或bulkwrite()会更好。
6. 缓存/重用mongoose 连接
确保不要在每次想要从数据库插入/查询内容时或每次端点被触发时连接和断开与数据库的连接。相反,您应该在应用程序开始时连接一次,然后重用该连接。
这是因为建立一个新的TCP连接在时间、网络请求和内存方面都很昂贵,而且新的连接还意味着MongoDB要使用数据库上的内存创建一个新线程。
让我们编写一些性能测试来查看结果
这些技巧能在多大程度上提高您的查询性能?让我们通过编写一些脚本来测试这些差异。
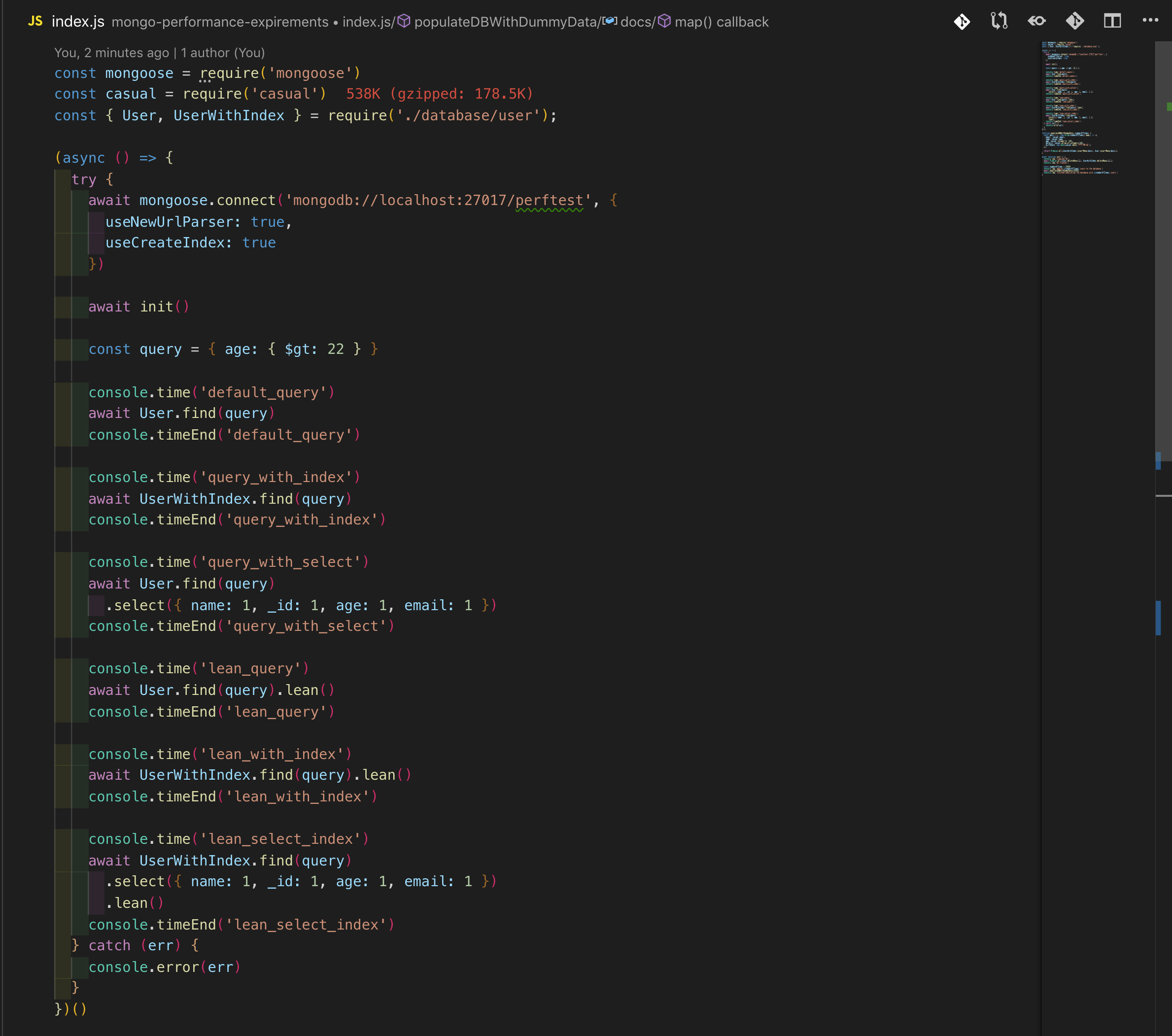
我运行了MongoDB的本地安装,并编写了一个NodeJS脚本,该脚本使用随机生成的用户列表填充数据库。目标是找到年龄超过22岁的用户。
我结合上面提到的方法以不同的方式编写查询,并在使用相同数据集填充的两个不同的数据库集合上尝试它们。一个集合对“age”属性有索引,而另一个没有。使用console.time() API测量结果,使用NodeJS (v12.7.0)和mongoose (v5.6.7)的最新当前版本运行测试。
首先让我们从out模式开始,这里我对用户集合/模式进行了定义,其中一个在age属性上有索引,而其他没有。
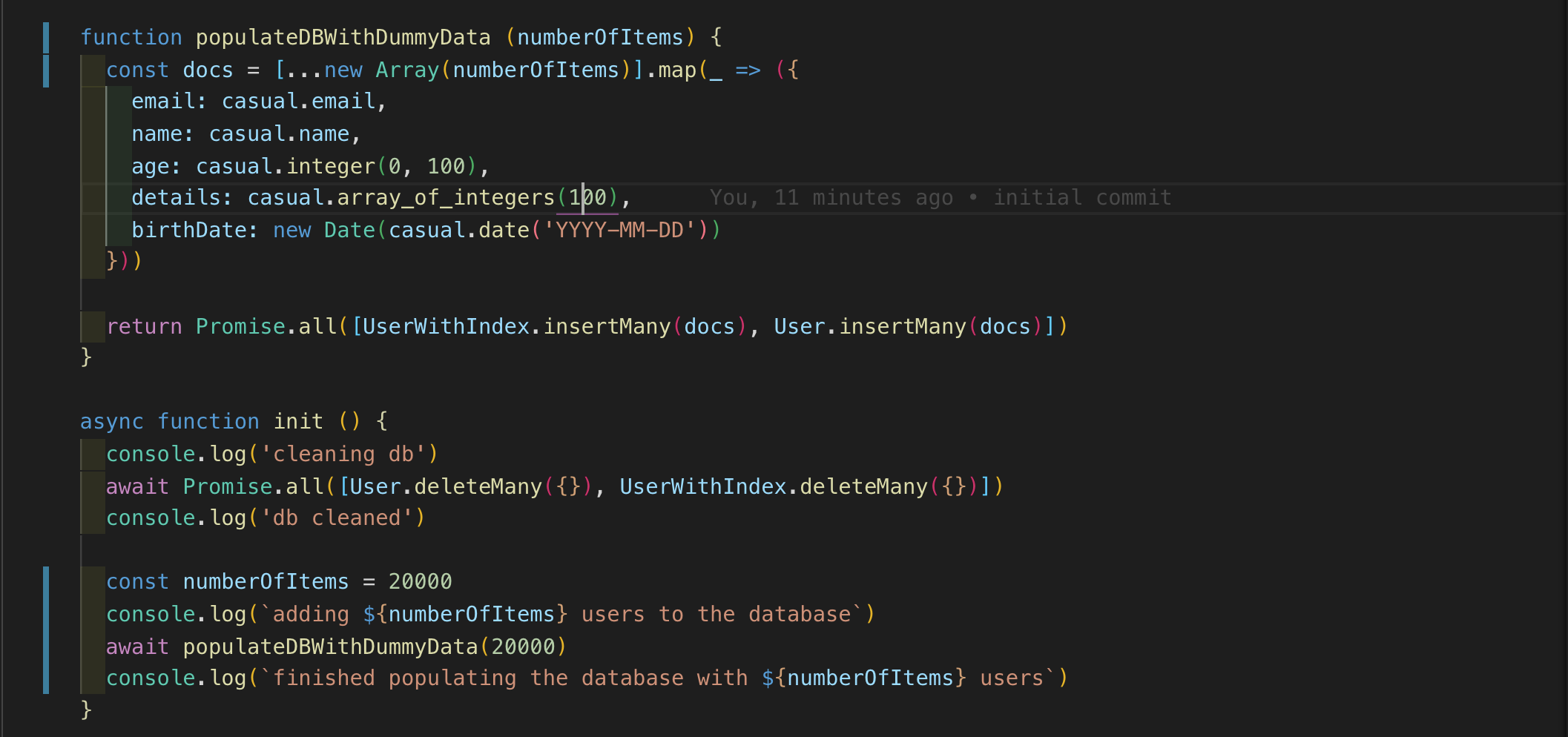
现在让我们编写一些代码来用随机数据填充数据库。我使用了临时库,它非常方便地生成语义模拟数据
既然数据库已经准备好了,让我们来编写查询
Performance Results & Observations
With 1k users
default_query: 135.646ms
query_with_index: 168.763ms
query_with_select: 27.781ms
query_with_select_index: 55.686ms
lean_query: 7.191ms
lean_with_index: 7.341ms
lean_with_select: 4.226ms
lean_select_index: 7.881ms
With 10k users in the database
default_query: 323.278ms
query_with_index: 355.693ms
query_with_select: 212.403ms
query_with_select_index: 183.736ms
lean_query: 92.935ms
lean_with_index: 92.755ms
lean_with_select: 36.175ms
lean_select_index: 38.456ms
With 100K Users in the database
default_query: 2425.857ms
query_with_index: 2371.716ms
query_with_select: 1580.393ms
query_with_select_index: 1583.015ms
lean_query: 858.839ms
lean_with_index: 944.712ms
lean_with_select: 383.548ms
lean_select_index: 458.000ms
如您所见,使用.lean() .select()和Schema.index({})的优化版本的查询比默认查询快了10倍,这是一个巨大的胜利!
.lean()似乎对性能的影响最大,其次是.select(),这是因为我的自定义索引在这种情况下不起作用,因为索引的选择性不够,因为它只减少了50%的扫描文档。
您可以找到用于这些测试的脚本,您甚至可以自己在https://github.com/khaledosman/mongo- performanceexpirequirements中试用它
原文:https://itnext.io/performance-tips-for-mongodb-mongoose-190732a5d382
本文:http://jiagoushi.pro/node/1175
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】