
在本文中,我们将向读者介绍推荐系统。我们还将用Python构建一个简单的推荐系统。该系统没有接近行业标准的地方,只是作为推荐系统的介绍。我们假设读者对科学软件包(如熊猫和numpy)有经验。
什么是推荐系统?
推荐系统是一种简单的算法,其目的是通过发现数据集中的模式,向用户提供最相关的信息。该算法对项目进行评分,并向用户显示他们将要评分的项目。推荐活动的一个例子是,当您访问Amazon时,您注意到一些项目正在向您推荐,或者Netflix向您推荐某些电影。Spotify和Deezer等音乐流应用程序也使用它们来推荐您可能喜欢的音乐。
下面是一个非常简单的例子,说明推荐系统如何在电子商务网站的上下文中工作。
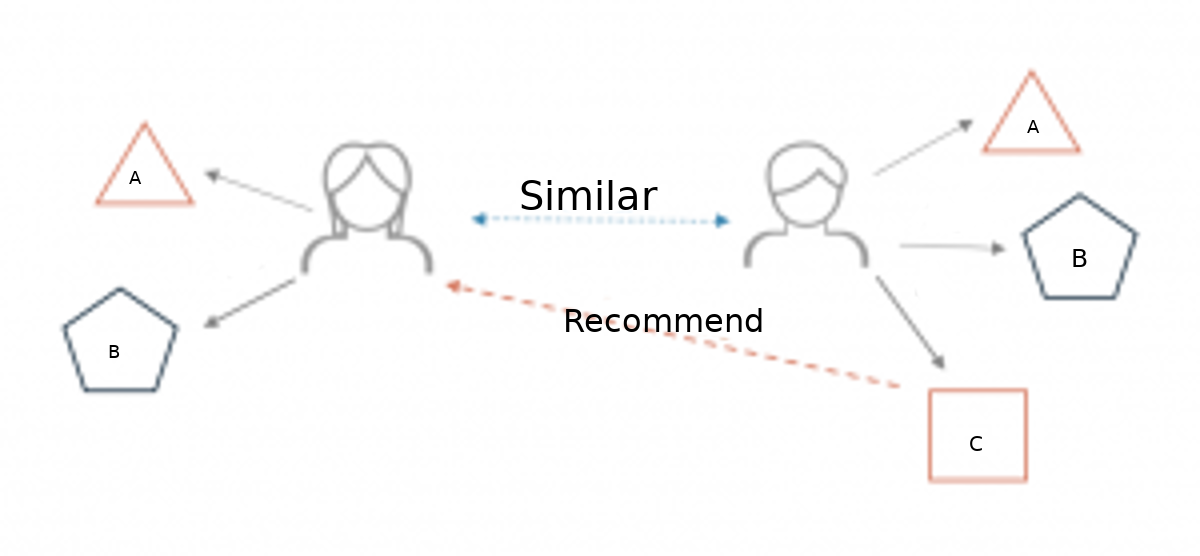
两个用户从电子商务商店购买相同的商品A和B。当这种情况发生时,将计算这两个用户的相似性索引。根据得分,系统可以向另一个用户推荐C项,因为它检测到这两个用户在购买的项目方面是相似的。
不同类型的推荐引擎
最常见的推荐系统类型是基于内容的和协同过滤的推荐系统。在协同过滤中,一组用户的行为被用来向其他用户提出建议。推荐基于其他用户的偏好。一个简单的例子是基于朋友喜欢电影的事实向用户推荐一部电影。有两种类型的协作模型基于内存的方法和基于模型的方法。基于内存的技术的优点是它们易于实现,并且由此产生的建议通常易于解释。它们分为两部分:
- 基于用户的协同过滤:在这个模型中,产品推荐给用户是基于产品已经被与用户相似的用户所喜欢。例如,如果德里克和丹尼斯喜欢同一部电影,而且有一部新电影是德里克喜欢的,那么我们可以向丹尼斯推荐这部电影,因为德里克和丹尼斯似乎喜欢同一部电影。
- 基于项目的协作过滤:这些系统根据用户以前的评分识别相似的项目。例如,如果用户A、B和C对图书X和Y的评级为5星级,那么当用户D购买图书Y时,他们也会得到购买图书X的建议,因为系统根据用户A、B和C的评级将图书X和Y识别为相似。
基于模型的方法是基于矩阵分解的,并且更擅长处理稀疏性。它们是使用数据挖掘、机器学习算法来预测用户对未评级项目的评级而开发的。该方法采用降维等技术来提高精度。基于模型的方法包括决策树、基于规则的模型、贝叶斯方法和潜在因素模型。
基于内容的系统使用诸如流派、制作人、演员、音乐家等元数据来推荐电影或音乐等项目。例如,这样一个建议就是推荐《无穷无尽的战争》(Infinity War),这部电影的主角是文·迪西尔(Vin Disiel),因为有人关注并喜欢《愤怒》的命运。同样,你可以从某些艺术家那里得到音乐推荐,因为你喜欢他们的音乐。基于内容的系统是基于这样一个想法:如果你喜欢某个项目,你很可能会喜欢与之类似的东西。
用于构建推荐系统的数据集
在本教程中,我们将使用MovieLes数据集。这个数据集是由明尼苏达大学的Grouplens研究小组整理的。它包含1,10,和2000万的收视率。Movielens还有一个网站,你可以在那里注册,发表评论和获得电影推荐。您可以从Dataquest的数据资源中找到更多用于各种数据科学任务的数据集。
建立推荐系统的演练
我们将使用movielens来构建一个简单的基于项目相似性的推荐系统。我们要做的第一件事就是进口熊猫和小熊猫。
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
接下来,我们使用pandas read_csv()实用程序加载数据集。数据集以制表符分隔,因此我们将\t传递给sep参数。然后使用names参数传入列名。
df = pd.read_csv('u.data', sep='\t', names=['user_id','item_id','rating','titmestamp'])
现在让我们检查一下数据的头部,看看我们正在处理的数据。
df.head()
如果我们能看到电影的片名,而不仅仅是处理ID,那就太好了。让我们加载电影标题并将其与此数据集合并。
movie_titles = pd.read_csv('Movie_Titles')
movie_titles.head()
由于item_id列相同,我们可以在此列上合并这些数据集。
df = pd.merge(df, movie_titles, on='item_id') df.head()
让我们看看每一列代表什么:
- user_id-对电影进行分级的用户的id。
- item_id-电影的id。
- rating-用户对电影的评分,介于1到5之间。
- timestamp-电影分级的时间。
- title-电影的片名。
使用“描述”或“信息”命令,我们可以获得对数据集的简要描述。这一点很重要,以便我们能够理解我们正在使用的数据集。
df.describe()
我们可以看出平均评分是3.52,最高是5。我们还看到数据集有100003条记录。
现在让我们创建一个数据帧,其中包含每部电影的平均分级和分级数。我们稍后将使用这些评分来计算电影之间的相关性。相关性是一种统计度量,表示两个或多个变量一起波动的程度。相关系数高的电影是彼此最相似的电影。在我们的例子中,我们将使用皮尔逊相关系数。这个数字介于-1和1之间。1表示正线性相关,-1表示负相关。0表示没有线性相关性。因此,零相关性的电影根本就不相似。为了创建这个数据框架,我们使用pandas groupby功能。我们按标题列对数据集进行分组并计算其平均值,以获得每部电影的平均评分。
ratings = pd.DataFrame(df.groupby('title')['rating'].mean())
ratings.head()
接下来我们想看看每部电影的收视率。我们通过创建多个“评级”列来实现这一点。这一点很重要,这样我们就可以看到电影的平均收视率和电影的收视率之间的关系。一部五星级的电影很有可能只被一个人评价过。因此,将这部电影归类为五星级电影在统计学上是不正确的。因此,当我们建立推荐系统时,我们需要为最小的评级数量设置一个阈值。为了创建这个新列,我们使用pandas groupby实用程序。我们按标题列分组,然后使用count函数计算每部电影的收视率。之后,我们使用head()函数查看新的数据帧。
ratings['number_of_ratings'] = df.groupby('title')['rating'].count()
ratings.head()
现在让我们使用pandas绘图功能绘制一个柱状图,以可视化评级的分布
import matplotlib.pyplot as plt
%matplotlib inline
ratings['rating'].hist(bins=50)
我们可以看到大多数电影的评分在2.5到4之间。接下来,让我们以类似的方式来可视化“收视率”列的数量。
ratings['number_of_ratings'].hist(bins=60)
从上面的柱状图可以清楚地看出,大多数电影的收视率都很低。收视率最高的电影是那些最有名的电影。
现在让我们检查一下电影的收视率和收视率之间的关系。我们使用seaborn绘制一个散点图。Seaborn使我们能够使用jointplot()函数来实现这一点。
import seaborn as sns
sns.jointplot(x='rating', y='number_of_ratings', data=ratings)
从图表中我们可以看出,他们是一部电影的平均收视率和收视率之间的积极关系。图表表明,电影的收视率越高,平均收视率就越高。这一点很重要,尤其是在为每部电影的收视率选择阈值时。
现在让我们快速前进,创建一个简单的基于项的推荐系统。为此,我们需要将数据集转换为一个矩阵,其中电影标题为列,用户id为索引,收视率为值。通过这样做,我们将得到一个数据帧,列作为电影标题,行作为用户id。每列代表所有用户对电影的所有分级。评分显示为NAN,用户没有对某部电影进行评分。我们将使用这个矩阵来计算一部电影的收视率和矩阵中其他电影的收视率之间的相关性。我们使用pandas pivot_table实用程序创建电影矩阵。
movie_matrix = df.pivot_table(index='user_id', columns='title', values='rating')
movie_matrix.head()
接下来,让我们看看最受欢迎的电影,并在这个简单的推荐系统中选择其中两部。我们使用pandas sort_values实用程序,并将ascending设置为false,以便根据最高评分排列电影。然后我们使用head()函数查看前10个。
ratings.sort_values('number_of_ratings', ascending=False).head(10)
假设用户已经观看了空军一号(1997)和Contact(1997)。我们希望根据此观看历史向此用户推荐电影。我们的目标是寻找类似于Contact(1997)和Air Force One(1997)的电影,我们将推荐给这个用户。我们可以通过计算这两部电影的收视率和数据集中其他电影的收视率之间的相关性来实现这一点。第一步是根据我们的电影矩阵创建一个包含这些电影评级的数据帧。
AFO_user_rating = movie_matrix['Air Force One (1997)']
contact_user_rating = movie_matrix['Contact (1997)']
现在我们有了显示用户id和他们给这两部电影的评分的数据框。让我们看看下面的。
AFO_user_rating.head() contact_user_rating.head()
为了计算两个数据帧之间的相关性,我们使用pandas corwith功能。Corrwith计算两个数据帧对象的行或列的成对相关性。让我们使用这个功能来获得每部电影的评分和空军一号电影的评分之间的相关性。
similar_to_air_force_one=movie_matrix.corrwith(AFO_user_rating)
我们可以看到,空军一号电影和《有你在》(1997)之间的相关性是0.867。这表明这两部电影非常相似。
similar_to_air_force_one.head()
让我们继续计算Contact(1997)收视率和其他电影收视率之间的相关性。程序与上述相同。
similar_to_contact = movie_matrix.corrwith(contact_user_rating)
我们从计算中了解到,接触(1997)和有你(1997)之间有非常强的相关性(0.904)。
similar_to_contact.head()
如前所述,我们的矩阵有很多缺失的值,因为并不是所有的电影都被所有的用户评分。因此,我们删除这些空值,并将相关结果转换为数据帧,以使结果看起来更吸引人。
corr_contact = pd.DataFrame(similar_to_contact, columns=['Correlation']) corr_contact.dropna(inplace=True) corr_contact.head() corr_AFO = pd.DataFrame(similar_to_air_force_one, columns=['correlation']) corr_AFO.dropna(inplace=True) corr_AFO.head()
上面的两个数据框分别向我们展示了与Contact(1997)和Air Force One(1997)电影最相似的电影。然而,我们面临的挑战是,有些电影的收视率很低,最终可能仅仅因为一两个人给了他们5星级的收视率而被推荐。我们可以通过设置收视率的阈值来解决这个问题。从之前的柱状图来看,我们看到评级数量从100个急剧下降。因此,我们将此设置为阈值,但这是一个数字,你可以玩,直到你得到一个合适的选择。为此,我们需要将这两个数据帧与ratings数据帧中的number_ratings列连接起来。
corr_AFO = corr_AFO.join(ratings['number_of_ratings'])
corr_contact = corr_contact.join(ratings['number_of_ratings'])
corr_AFO .head()
corr_contact.head()
我们现在将获得最类似于空军一号(1997)的电影,将其限制为至少有100条评论的电影。然后按相关列对它们进行排序,并查看前10个。
corr_AFO[corr_AFO['number_of_ratings'] > 100].sort_values(by='correlation', ascending=False).head(10)
我们注意到空军一号(1997)与自身有着完美的关联,这并不奇怪。下一部与空军一号(1997)最相似的电影是《寻找红色十月》(Hunt for Red October),这部电影的关联度为0.554。很明显,通过改变评论数量的阈值,我们可以得到与以前不同的结果。限制收视率会给我们带来更好的效果,我们可以自信地向看过《空军一号》(1997)的人推荐上述影片。
现在让我们对Contact(1997)电影做同样的操作,看看与之最相关的电影。
corr_contact[corr_contact['number_of_ratings'] > 100].sort_values(by='Correlation', ascending=False).head(10)
我们再次得到不同的结果。最相似的电影接触(1997年)是费城(1993年),相关系数为0.446,收视率为137。所以如果有人喜欢Contact(1997),我们可以向他们推荐上述电影。
显然,这是一种非常简单的建立推荐系统的方法,并没有接近行业标准的地方。
如何完善推荐制度
通过构建基于内存的协同过滤系统,可以对系统进行改进。在这种情况下,我们将数据分为训练集和测试集。然后我们将使用诸如余弦相似性之类的技术来计算电影之间的相似性。另一种方法是建立一个基于模型的协同过滤系统。这是基于矩阵分解的。矩阵分解比矩阵分解更擅长处理可伸缩性和稀疏性。然后,您可以使用诸如均方根误差(RMSE)之类的技术来评估您的模型。
进一步阅读
建立推荐系统还有其他技术。深入学习是其中一种方法,特别是当你有大量的数据集时。一些用于构建高级推荐系统的算法包括自动编码器和受限的Boltzmann机器
原文:https://towardsdatascience.com/how-to-build-a-simple-recommender-system-in-python-375093c3fb7d
本文:http://jiagoushi.pro/node/950
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 登录 发表评论
- 61 次浏览