
无状态任务被广泛用于服务大规模数据处理系统。许多请求都是由依赖Apache Helix的系统提出的,因为无状态任务管理功能将被添加到Apache Helix中。最近,我们的团队决定探索管理无状态任务的新方法,以及我们正在进行的支持Helix的工作。这些努力的结果是Helix Task Framework,一个为无状态任务的分布式执行提供动力的引擎。在这篇文章中,我们将介绍Helix任务框架,它在Helix中作为高级功能提供。
关于Helix
Apache Helix是一种通用的集群管理框架,用于自动管理托管在节点集群上的分区和复制分布式系统。在节点故障恢复,群集扩展和重新配置的情况下,Helix会自动调整和替换分区及其副本。
Helix通过声明状态机表示应用程序的生命周期,将集群管理与应用程序逻辑分开。 Apache Helix网站详细描述了Helix的体系结构以及如何使用它来管理分布式系统。还有一些公开的博客文章提供了Helix内部的演练。
Helix最初是在LinkedIn开发的,目前管理关键基础设施,如Espresso(No-SQL数据存储),Brooklin(搜索即服务系统),Venice(派生数据服务平台)以及离线数据基础设施存储和处理。有关这些系统的更多信息,请点击此处。
任务框架上的分布式任务
任务框架
Helix Task Framework支持短期运行和长期运行任务的分布式执行。任务框架将作业划分为任务并安排它们在集群中的Helix Participants(节点)上执行。实际调度是通过将任务分配给可用的参与者节点来完成的,并且这些任务经历执行阶段并且相应地用Helix Task StateModel中的相应状态标记。
任务框架随后可以并行地触发任务的执行或调度任务。 Helix Controller监控集群中的所有任务执行,避免裂脑问题,并通过Helix定义的有限状态机和约束启用故障恢复。
概念
任务有三个抽象级别:工作流,工作和任务。工作流由一个或多个作业组成。作业由一个或多个任务组成。任务被定义为最小的,相互独立的可执行工作单元,其逻辑由用户实现。以下小节深入研究了这些抽象的实际用例。
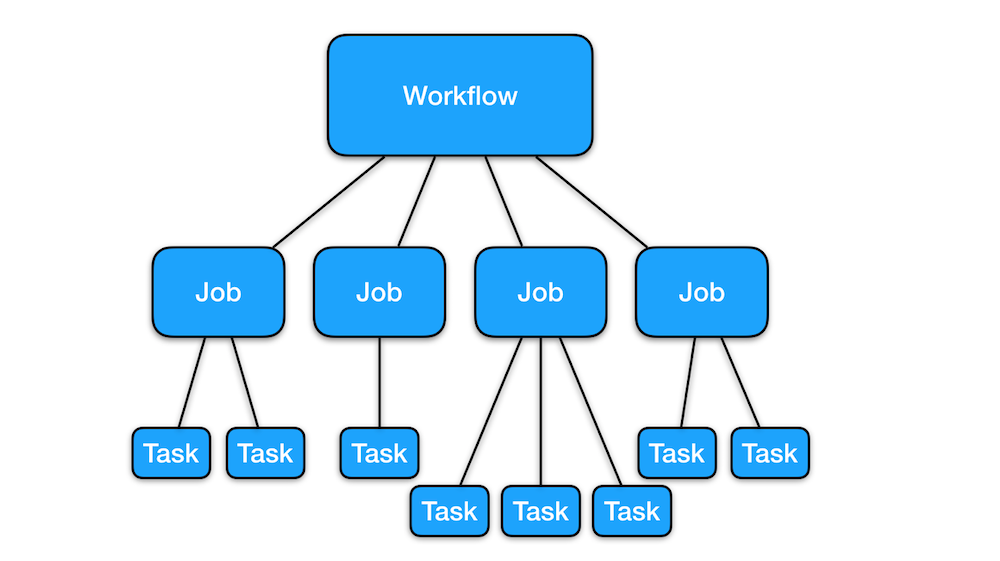
工作流程
有两种类型的工作流:通用工作流和作业队列。
通用工作流是作业之间依赖关系的有向无环图(DAG)表示。 这些依赖关系明确定义了必须运行作业的顺序。 根据DAG,可能存在多种可能的排序。
作业队列是一种特殊类型的工作流。 作业队列与常规工作流程的不同之处在于作业之间的依赖关系是线性的。 因此,在队列中的所有其他作业运行并成功完成之前,不会安排作业。 但是,请注意,任务框架允许用户更改此行为 - 例如,通过修改配置参数,您可以允许作业运行,即使在依赖关系链中的某个位置之前存在失败的作业。
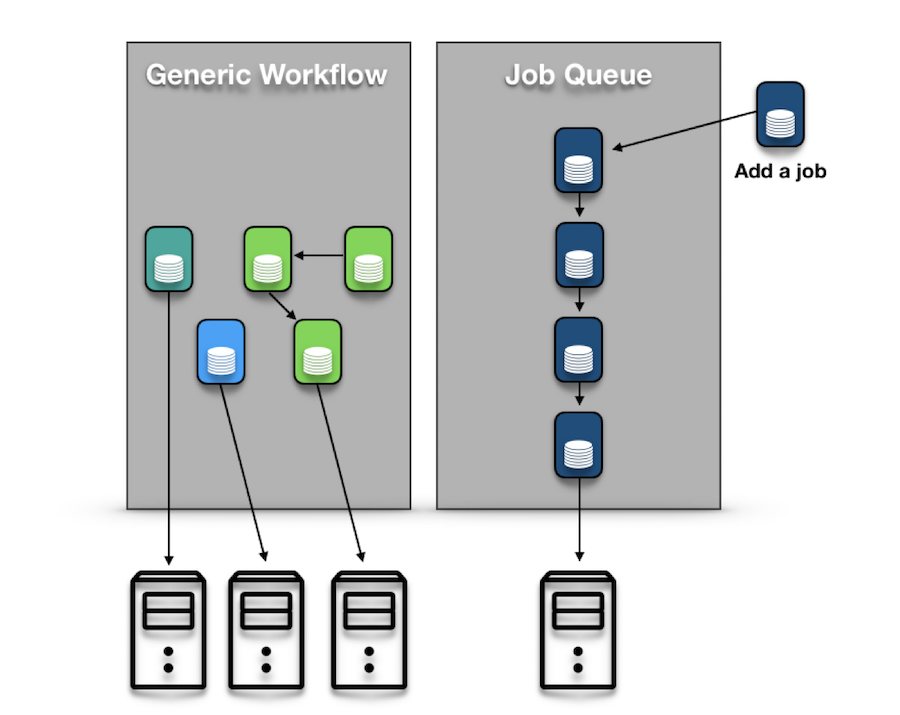
任务框架还允许工作流程是一次性的或经常性的。上面描述的通用工作流默认是一次性的,并且在完成时将从Task Framework的元数据存储中丢弃。但是,循环工作流或作业队列适用于需要定期运行业务逻辑的用例。要创建循环工作流,用户必须创建所谓的“模板”。此模板包含用于创建工作流的一次性实例的信息和参数(例如频率,开始时间,任务逻辑等)。然后,任务框架将按照给定模板的定义自动创建和提交工作流,从而消除了用户使用其他调度工具(例如cron)的需要。
工作
作业是任务框架中的下一级抽象。工作可以有许多相同或不相同的任务。工作是否成功完成取决于其任务的状态;例如,如果其任务未在超时阈值内完成或因任何原因失败,则作业将被标记为超时或失败。只有在所有任务成功完成后,作业才会标记为已完成。
任务框架中支持两种类型的作业:通用作业和目标作业。默认情况下,作业是通用作业。它由一个或多个任务组成,每个任务由Helix Controller生成的分配分布在多个节点上。但是,目标作业绑定到“目标”,它是非任务Helix资源的分区(此处的“Helix资源”表示由Helix管理的实体,例如数据库分区)。假设在Helix上运行的分布式数据库系统想要运行备份作业。这意味着必须在“目标”数据库分区所在的节点上安排并精确运行备份任务。有针对性的工作完全实现了这一点;它有一个“目标”资源(本例中为分布式数据库),其任务将在为该目标资源的分区提供服务的所有计算机上运行。也可以指定目标的状态(由Helix的StateModel定义),这意味着目标任务将仅在指定目标分区的副本处于目标状态的机器上运行。
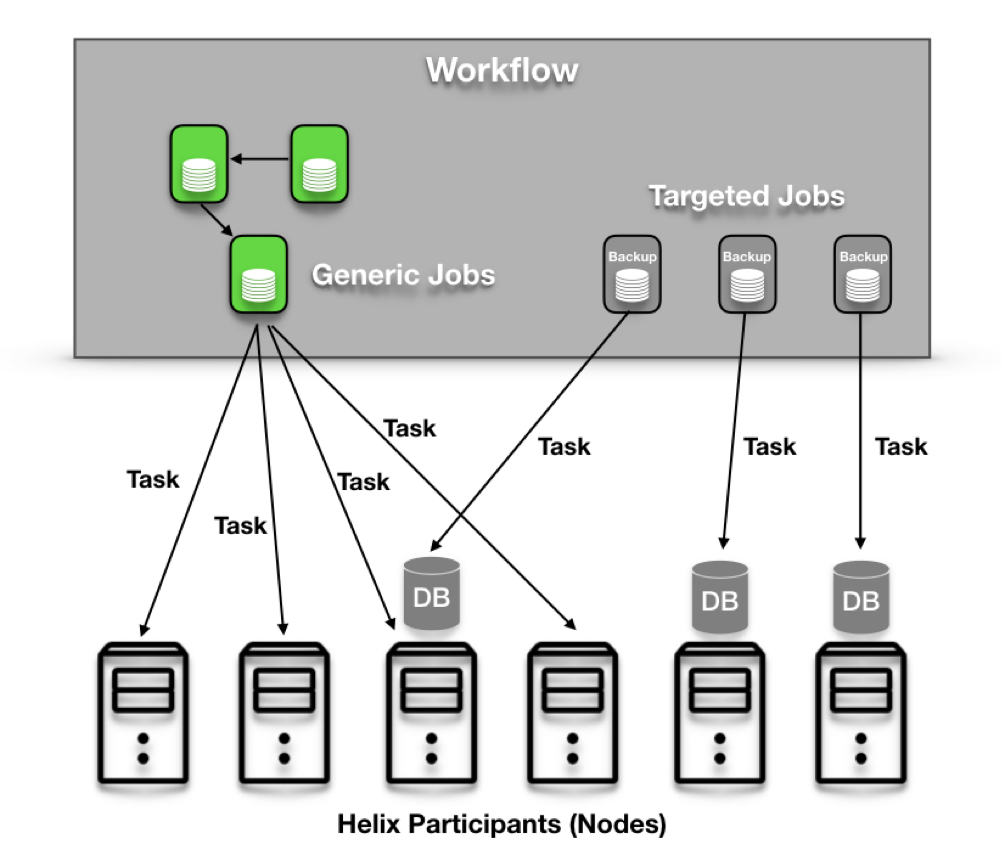
任务
任务是最小的独立工作单元,其逻辑由用户实现。 在内部,每个单独的任务都遵循Helix定义的Task StateModel。 任务框架中的分配和调度以任务粒度进行。 以下是Task接口的代码片段:

强大分布式系统:任务框架的应用
在Espresso中管理分布式数据库作业
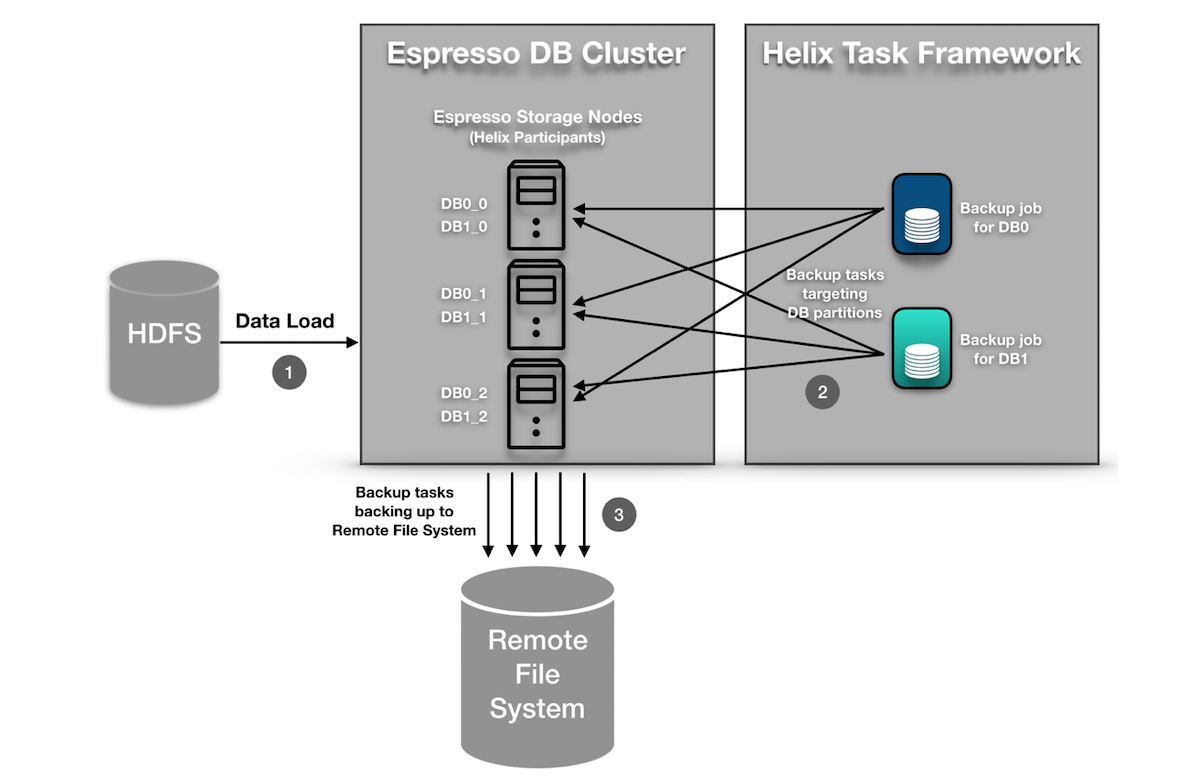
Espresso曾经有一种传统的备份方法,每个节点在本地运行备份调度程序,备份它托管的每个分区。这种方法有以下两个限制。
- 缺乏集中,协调的调度程序:由于备份是在每个节点上独立调度的,并且每个节点都不知道其他节点正在备份,因此对于分区的每个副本,存在大量相同分区的重复备份。虽然节点彼此发送异步消息以跟踪正在备份的分区,但由于竞争条件,这是不可靠的。更糟糕的是,有时候我们看不到分区的备份了!
- 缺少任务进度监控:备份调度程序将消息发送到存储节点以触发备份任务。但是,此消息仅启动备份任务 - 我们需要一种方法来跟踪其进度。为了跟踪,我们经常向Helix发送getStatus消息,Helix在Zookeeper中创建了一个新节点。然而,这种方法很快就被证明是有问题的,因为它产生的大量消息试图备份数百个分区。
Espresso现在在Task Framework上运行其备份作业。这很有用,因为Espresso已经在其数据库分区中使用了Helix的通用资源管理功能。 Helix Controller了解数据库分区周围发生的状态变化,因此能够轻松确定哪些任务需要绑定到哪些数据库分区。此外,Helix Controller充当集中式调度程序,可以控制并发任务的数量并确定何时应运行备份任务(以避免高峰时段)。以下部分提供了更详细的演练。
Espresso如何在Task Framework上运行备份任务
任务框架要求用户实现两个Java接口:Task和TaskFactory。 Helix将使用TaskFactory在运行时生成Task的实例。下一步是告诉Espresso的节点(由Espresso称为存储节点,Helix称为Participants),我们将在其上运行任务。这是通过将TaskFactory注册到StateMachineEngine(通过HelixManager访问)来完成的。然后,Espresso的中央控制器/调度程序已准备好使用TaskDriver中的一组API创建和提交任务。 TaskDriver提供了一组易于使用的API,允许用户创建,运行,停止和删除工作流。此外,用户可以通过TaskDriver检索每个工作流的状态信息。
监测和操作
为了增强可操作性和用户体验,Helix提供轻量级REST服务Helix REST 2.0和Helix UI。 Helix UI与Helix REST交谈以掌握所有配置并跟踪任务框架状态。
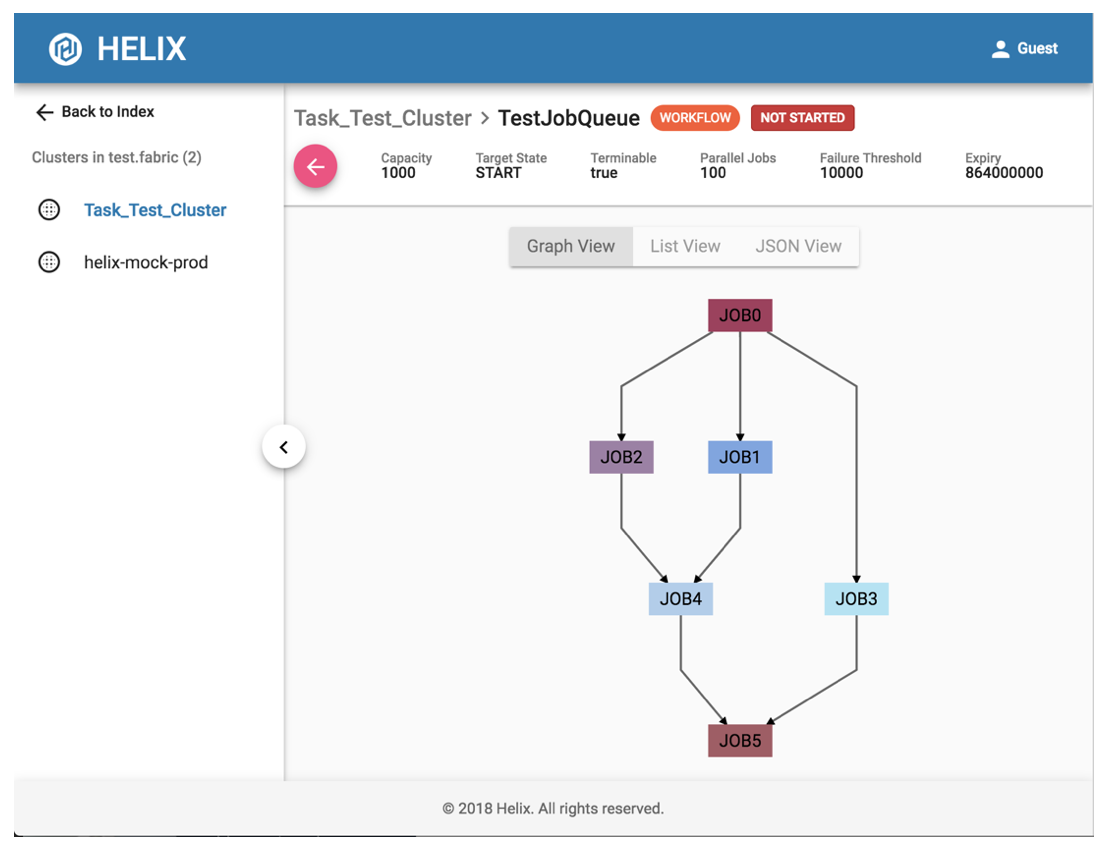
如上所述,Espresso使用目标作业进行备份。 Helix UI对于发现作业执行中的任何异常非常有用。用户可以轻松访问Helix UI以监控现有工作流和作业的状态并执行简单操作。此外,Helix UI支持身份验证,操作授权和审计日志记录,这为使用Helix构建的分布式应用程序添加了一层安全性。
最近的性能和稳定性改进
最小化冗余ZNode创建
IdealState和ExternalView是反映Helix定义的资源的未来状态和当前状态的元数据信息。在较旧的Task Framework实现中,作业被视为Helix资源,例如DB分区。这意味着在创建时为每个作业生成IdealState ZNode和ExternalView ZNode。这是有问题的,因为Task Framework作业和通用Helix资源本质上是不同的:作业往往是短暂的,经常创建和删除的瞬态实体,但是通用Helix资源往往是持久且继续为请求提供服务的持久实体。因此,创建和删除如此多的ZNode被证明是昂贵的,不再适合工作。这些ZNode将保留在ZooKeeper中,直到指定的数据到期时间(通常为一天或更长时间)。对于循环作业来说更糟糕的是 - 正在为原始作业模板创建一组IdealState / ExternalView ZNode,并且将为作业的每个计划运行创建另一组IdealState / ExternalView ZNode。进行了一项改进,以便作业的IdealState ZNode仅在计划运行时生成,并在作业完成后立即删除。实际上,每个工作流程应该只有少数作业同时运行,因此在任何给定时间每个工作流程只会存在少量的IdealState ZNode。此外,默认情况下将不再创建作业的ExternalView ZNode。
安排重复工作的问题
我们发现在从循环工作流调度重复作业时,计时器不稳定。这主要是因为我们为每个作业添加到周期性作业队列时设置了一个计时器,并且因为为所有当前和未来的作业维护大量计时器容易出错。此外,在Helix Controller的领导交接期间,这些计时器未被正确转移到新的领导者控制器。通过使任务框架为每个工作流而不是作业设置计时器来解决这个问题。现在Helix需要跟踪的定时器要少得多,而且在Helix Controller的领导交接过程中,新的领导者Controller将扫描所有现有的工作流程并适当地重置定时器。
任务元数据累积
我们观察到,当Task Framework负载繁重时,任务元数据(ZNodes)很快就会堆积在ZooKeeper中,不断将任务分配给节点。这会影响性能和可扩展性。提出并实施了两个修复:定期清除作业ZNode和批量读取元数据。删除终端状态中的作业会定期有效地缩短元数据保留周期,从而减少任何给定执行点上存在的任务元数据的数量。批量读取有效地减少了读取流量的数量和频率,解决了Zookeeper冗余读取的开销问题。
任务框架的后续步骤
重构ZooKeeper中的元数据层次结构
正如本文前面部分所讨论的,任务框架的性能直接受ZooKeeper中存在的Zookeeper存储结构(ZNodes)数量的影响。 Helix将工作流和作业配置以及上下文(工作流/作业的当前状态)的ZNode存储在一个展平目录中。这意味着理论上每次数据更改都会触发目录中所有ZNode的读取,当目录下的ZNode数量很高时,这可能会导致灾难性的减速。尽管批量读取等小改进缓解了这个问题,但我们发现问题的根源在于存储ZNode的方式。在不久的将来,将向Helix引入新的ZNode结构,以便任务框架ZNode将反映工作流,作业和任务的层次结构特性。这将大大减少ZooKeeper的读写延迟,使Task Framework能够更快地执行更多任务。
更先进的分配算法和策略
任务框架使用Consistent Hashing来计算可用节点的任务分配。有两种方法可以改进任务分配。首先,Helix Controller当前计算其管道的每次运行中的任务分配。请注意,此管道在Helix的通用资源管理中共享,这意味着管道的某些运行可能与任务框架无关,导致Helix Controller计算任务分配无效。换句话说,我们观察到了相当多的冗余计算。此外,Consistent Hashing可能不是任务的适当分配策略。直观地说,将任务与节点匹配应该很简单:只要节点能够承担任务,它就应该尽快完成。使用Consistent Hashing,您可能会看到一些节点忙于执行任务,而其他节点将处于空闲状态。
已经确定生产者 - 消费者模式是用于在一组节点上分配任务的更合适的模型 - 生产者是Controller,并且可用节点的集合是消费者。我们相信这种新的分发策略将极大地提高任务框架的可扩展性。
任务框架作为一个独立的框架
Helix最初是作为通用资源/集群管理的框架,而任务框架是通过将作业作为具有自己的状态模型的特殊资源来开发的。但是,我们现在只有LinkedIn用户使用Helix的任务框架功能。任务框架已经看到了其增长份额,为了满足用户不断增长的可扩展性需求,我们决定将其与通用资源管理分离是不可避免的。
分离工作有三个方面:1)减少资源竞争; 2)删除不必要的冗余; 3)删除部署依赖项。任务框架和通用资源管理框架的工作由单个中央调度程序:Helix Controller管理。这意味着单个Controller在一个JVM中运行而没有隔离,我们无法阻止资源管理的减速影响任务的分配和调度,反之亦然。换句话说,两个实体之间存在资源竞争。从这个意义上讲,我们需要将一个Helix控制器分成两个独立运行的独立控制器 - 一个Helix控制器和一个Task Framework Controller。
这种分离自然解决了管道中出现冗余计算的问题,如上一节所述。通用资源的更改将不再触发任务框架控制器中不必要的管道运行。此外,我们计划将此分离扩展到部署/存储库级别,以便新部署/回滚不会相互影响。我们相信这不仅可以提高两个组件的整体性能,还可以改善开发人员的体验。
结论
在这篇文章中,我们探讨了Task Framework,它是Apache Helix中不断增长的组件,可帮助您管理分布式任务。我们还讨论了系统的当前局限性以及我们正在进行的改进,以便将Helix的任务框架定位为LinkedIn以及开源社区中其他人的可靠分布式基础架构。
致谢
我们要感谢我们的工程师Jiajun Wang和Harry Zhang以及我们的SRE,Eric Blumenau。另外,感谢Yun Sun,Wei Song,Hung Tran,Kuai Yu以及来自LinkedIn数据基础架构的其他开发人员和SRE,感谢他们对Helix的宝贵意见和反馈。此外,我们要感谢Kishore Gopalakrishna,Apache Helix社区的其他提交者,以及校友Eric Kim,Weihan Kong和Vivo Xu的贡献。最后,我们要感谢雷管,Ivo Dimitrov和Swee Lim的管理层的不断鼓励和支持。