在一个组织中,数据不会从左到右移动,而是通过失败者、无线索者和反社会者移动。
去谷歌搜索“现代数据堆栈”一词,然后搜索图像。你看到了什么?这是一个又一个体系结构图,数据从左到右在各个系统中流动,这意味着除了购买5到100个不同的供应商解决方案来帮助移动数据之外,什么都没有。
从根本上说,从左到右的流动是有缺陷的,因为它是技术流动的伪装,而不是组织内的决策流动或资本分配流动。
最终,现代数据堆栈图通常是供应商、风险投资公司或员工扩充公司对当前对他们最经济有利的东西的看法。
今年早些时候,有一次,我把头砸在桌子上,问自己为什么不选择一个更高尚、更诚实的职业,比如土地投机、政治游说或碳抵消管理,我根据谷歌上这些荒谬图表的图像编制了《现代数据堆栈的现代数据堆栈》。
但是,如果我们反过来看看信息和资本实际上是如何在组织中流动的呢?如果我们从垂直轴而不是水平轴上的组织的病理性质来看待数据流,会怎么样?
进入“热尔韦原则”
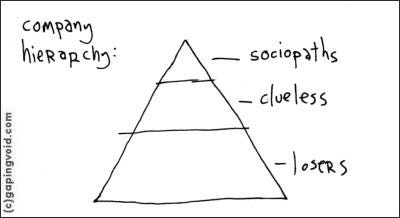
Hugh MacLeod’s Company Hierarchy
文卡特什·拉奥的六部分《热尔韦原理》为数据堆栈问题提供了完美的背景。数据只是信息的一个子集,信息在组织中上下流动。
根据该范式,公司的组织如下:
- 反社会者是推动组织运作的资本主义奋斗者、权力意志者。这是大多数企业主、创始人和一些高管等。拉奥指出,该办公室的大卫·华莱士和简·莱文森是其成员。
- 无线索者是Kool Aid的饮酒者,他们被企业咒语所束缚,被经营模式所束缚,这些模式给了他们一个小小的帮助,比如承诺忠诚的薪酬或头衔的增加。最有效地将纸张、数据和信息打乱,他们构建叙事和宏大的故事,赋予自己的生活和劳动意义。拉奥指出,Andy Bernard、Dwight Schrute和Michael Scott是“无线索小组”的成员。
- 失败者是那些放弃了资本主义的奋斗,转而在组织层级中选择复选框的人,就像在结账和“我来这里只是为了薪水”的人群中一样。斯坦利·哈德森和凯文·马龙是失败者。
当然,这些标题/分类有些开玩笑。社会病学家不是临床反社会者,尽管人们确实认为这是许多临床反社会者随着时间的推移聚集的地方。失败者并不是不冷静的人,而是那些与雇主讨价还价的人,只要他们勾选了为他们准备的方框,就不会被打扰太多。
正如拉奥所指出的,麦克劳德公司遵循一个自然循环。一个有想法的Sociopath招募了足够多的失败者来启动这个循环并构建版本1。不可避免的是,随着版本1的开始,引入了一个无线索层来管理由越来越多的失败者创造的产量增长。这一无线索层起到了资本持有人/决策者和最接近生产的人之间的缓冲作用。
随着公司在周期中的成长,无线索层变得如此之大,以至于公司无法持续。最终,无线索层接管并摧毁了公司,因为Sociopath和Losers都退出了,因为他们生活得更接近现实,可以在组织之间最自由地流动。
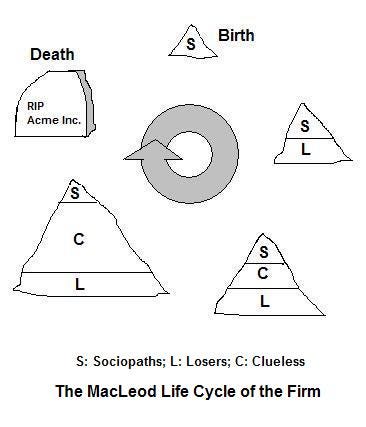
我认为,我们现在看到的云数据仓库/现代数据堆栈和支持它的高员工团队是公司麦克劳德生命周期第四阶段的表现,在这个阶段,Cluless的中间件层变得如此无利可图、如此臃肿,与生产和有意义的决策都相距甚远,在许多科技公司,它已经做好了自我崩溃的准备。
以下是我对麦克劳德公司的现代数据堆栈/团队的看法。
- 失败者是数据生产者——应用程序团队和产品工程团队的任务是运行一组产生数据的应用程序、系统或服务。
- 无线索是现代数据堆栈数据团队,其任务是处理这些数据供Sociopath使用。
- Sociopath是数据消费者,即管理损益表并分配资本以增加或减少增量预算以支持数据在整个组织中的持续移动的商业化数据的高管、部门负责人和买家。
根据供应商的说法,以下是现代数据堆栈的理想工作方式。它有所有的经典标志。
来源->摄入层->多表的存储/仓库->BI或操作或AI/ML。
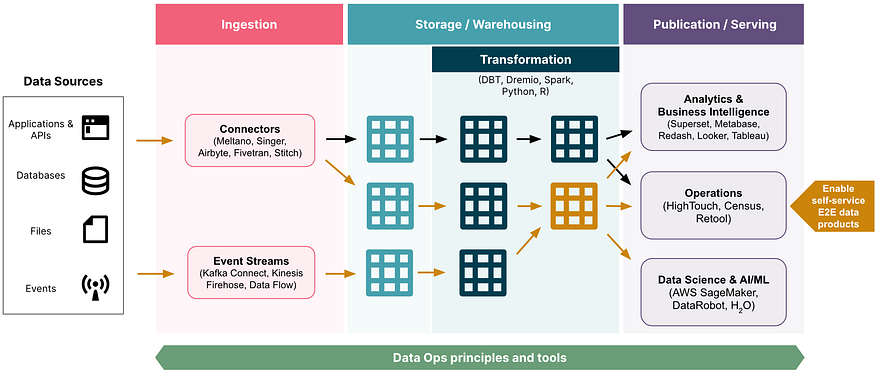
但我还没有在任何供应商/VC/员工aug公司图中看到的是相关人员的细分。
首先,与现代层次结构相比,现代数据堆栈旋转了90度。
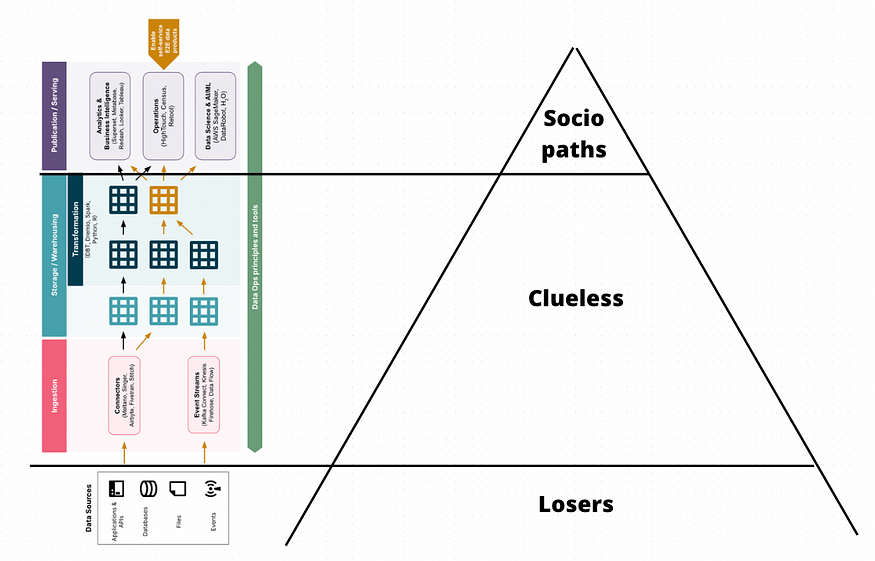
恭喜你,你已经建立了一个越来越复杂的人工中间件层,在一个集中的云数据仓库上制作表、表和表,为业务(Sociopath)追求KPI,但依赖于那些没有动机关心他们产生的数据质量的应用程序所有者(失败者)。
一旦数据流被垂直呈现,各阶段与结果相关,组织固有的病理性质就有了很大的揭示。
这些阶段中的每一个都代表着从一个组到另一个组的转移,即数据保管的转移。然而,真正了解膨胀是如何累积的,需要了解这些群体之间的数据传递。
数据合同
理解和检查“失败者到无线索”切换
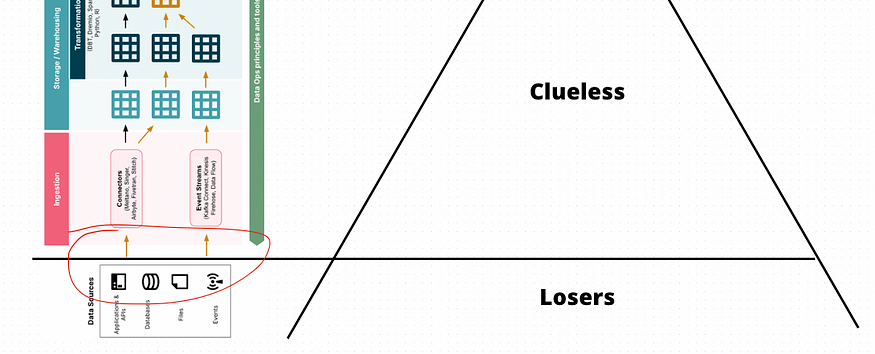
询问任何一位现代数据堆栈领导者他们的前三大问题,我向你保证,前三大(如果不是第一大的话)之一是应用程序和数据团队之间的切换。
从根本上讲,这是一个垃圾进垃圾出的问题。最简单地说,如果数据源中的数据质量不高,或者它的定义或结构发生了变化——无论是RevOps团队拥有的Salesforce对象,还是应用程序团队拥有的一组Postgres表——这些数据都会被复制、复制、集成或其他任何形式的集中存储,如Snowflake、BigQuery或类似的存储,它将导致不正确的数据,而这些数据并不能反映它应该代表的现实。
失败者,应用程序团队,做出了一个改变,勾选了他们的功能部署框。
Sociopaths的高管们注意到仪表板或数据产品坏了。
Cluless,即集中式数据团队成员,四处奔波,要么在云数据仓库中对SQL进行某种“修补”或“变通”,要么回到应用程序团队,指控他们未能遵守制定的联合问责标准。
后者几乎从未发生过。现代数据堆栈数据团队自然地处于这一动态的中间位置,进行定点并累积技术债务、增加的人力资本和采取这些行动的云成本。
他们在Sociopaths面前失去了部分信誉。
他们成为了修补技术债务的推动者,并在云数据仓库中制作更多的表。编译和运行从源到存储再到仪表板的增量SQL模型的时间增加了。为了在基线上交付,需要消耗更多的计算量。
失败者并不在乎。Sociopaths只想修复他们的仪表盘。
当迭代超过2、3、10、20、50次或更多次时,这会导致在无线索层中雇佣更多的人。正如麦克劳德组织中的中层管理人员膨胀一样,数据团队也膨胀了,出于同样的原因,Sociopath和Losers之间固有的脱节。
这开启了一个永无止境的循环。
工作申请书已经写好了。需要:数据/分析工程师;必须熟悉dbt和Airflow,并了解云数据仓库$每年180000英镑外加福利。
然后,由于仓库中人头和表的数量增加了,无线索层可能需要一个可观察性工具来帮助他们对/at/around中发生的事情不那么一无所知,因为他们已经制作了越来越多的表和SQL。
他们可能还需要一个目录,一个与他们运行DAG的方式分开的沿袭工具,以及一个测试工具,以确保他们创建的PR能够产生经过适当测试的新表。
在某种程度上,根据我的经验,通常早在4-5个人的时候,现在你只是在添加人头和越来越复杂的DAG。每一次招聘都涵盖了之前为在云数据仓库上绘制SQL图而增加的主管所带来的技术债务和通信挑战。
据说,解决方案是强制执行数据合同。这至少限制了从“失败者”到“无线索”切换所导致的停机时间和修补。
许多运行过数据平台团队的人至少已经提出了数据合同的问题,并提供了一些解决方案的框架,包括实际的例子和建议。
James Densmore在这里提出了一个深思熟虑的方法。
Chad Sanderson非常详细地阐述了这个问题,并在这里提供了类似的解决方案。
这些都是朝着正确方向迈出的步骤,我认为它们至少形成了一个可以应用于多个组织的范式。
但这两者都错过了当合同被违反时会发生什么的胡萝卜或大棒。
从根本上说,数据合同是一个中间件无线索团队必须如何激励失败者团队遵守无线索团队希望建立的规则的问题,以便无线索团队安抚Sociopath数据消费者,他们没有时间也没有技术知识来处理同一公司的技术团队之间的合同谈判,其中合同是在Github PR或类似平台上表现为接受标准或“完成定义”的数据模式。
在我的职业生涯中,我多次看到这种情况的发生,我真的相信,只有那些直接出售或以其他方式利用数据的组织,通过向数据经纪人、对冲基金、希望了解其销售的供应链完整销售情况的制造商等提供数据。
如果Loser到Cluless切换导致数据集直接大写或以其他方式反映为资产,那么它可以工作。未能遵守数据合同是对收入的风险,因此责任开始存在。
如果在一个无线索数据团队是纯粹成本中心的组织中存在“失败者到无线索”的切换,请忘记它。
全能的仪表板
理解和审视无线索到社会病态的切换
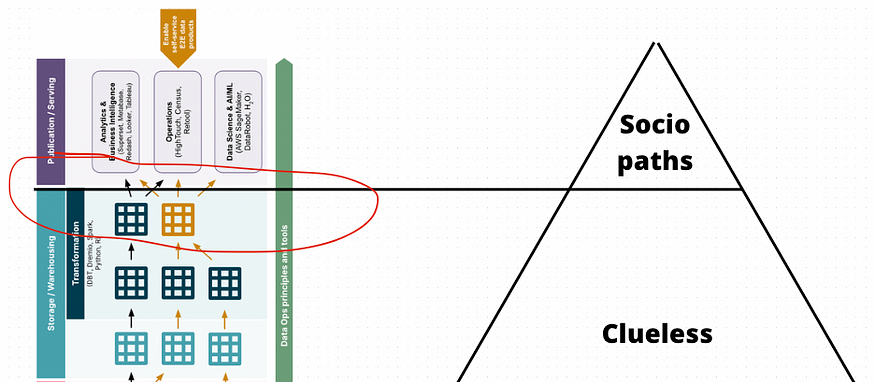
祝贺
您已制定好数据合同。
但是谁制造仪表盘呢?
在现代数据堆栈上创建仪表板时会发生以下几件事之一,因为必须有人制作或收集仪表板、分析或可视化。
一种途径是分析师(仪表板制造商)向特定的业务部门报告。通过这种方式,这些人向Sociopaths管理的损益表报告。对于许多渴望有朝一日进入Sociopath班的年轻人来说,这是一个巨大的垫脚石机会。
一种方法是让分析师向Cluless报告,该团队正在Snowflake(或其他什么)中制作表、表、表,在SQL上写SQL。对于那些渴望随着时间的推移“获得更多技术”并可能希望与无线索层保持一致的人来说,这是一块很好的垫脚石。
然而,作为一名分析师,如果你想走Sociopath路线,这通常是非常糟糕的职业选择。你的简历将填写供应商和语言的名称,并且不太可能包含有关商业成果的信息。这本身没有错,只是一个根本不同的结果,年轻或新的数据专业人员在评估机会时应该理解这一点,评估他们将向哪种类型的分析师或数据科学家团队报告。
另一条途径是让各种业务人员让他们的操作人员制作仪表板。这通常被认为是“自助分析”,但实际上大多数Sociopath不会做太多自助服务。
这一个很好,通常是最没有意义的。
很多时候,同一个人既是应用程序所有者(例如,Salesforce Ops、Customer Service Ops等),现在也是仪表板制造商,其中一层是Cluess团队,在中间运行数据仓库,应用程序所有者和操作人员兼任数据生产者和数据消费者。
正在扩展的人类中间件层
大多数数据基础设施和数据工程工作的核心是,这些团队和组成他们的人员都被夹在中间,默认情况下,一旦他们在第一天开始新的工作,他们就注定会陷入现代无线索状态。他们通常不是数据生产者,而是为数据消费者服务,数据消费者实际上是负责管理技术中间件的人类中间件,即系统之间的集成、模式、数据合同和互操作性。
事实上,即使是这些团体的领导人也经常失败。许多首席数据官都失败了。哈佛商学院已经写过这方面的文章。Gartner在2019年表示,只有一半成功。
在当今的科技组织中,许多组织没有定义的CDO,但在副总裁或总监头衔中有一些功能性的“数据主管”,我们也看到了许多问题,主要是人类中间件变成了人类膨胀软件。
就在过去的几周里,有几篇文章谈到了现代数据堆栈中的挑战。
这一次来自该领域的供应商dbt实验室,表明在他们自己的dogfooded dbt项目中,他们在Snowflake中有1700多个SQL模型,并且一直在昂贵的云数据仓库计算周期上运行全窗口函数表扫描,每天4次,不必要地每年为他们的云账单增加数万美元,并严重影响吞吐量。此外,他们还拥有一支自己的内部分析工程师团队,随着时间的推移,规模不断扩大。
这张来自忠诚度平台ShopBack的一名数据员工的照片显示,为分析目的创建的头部数量不断增加,从6个月增加到18个,SQL序列数量也在增加,在6个月内增加了约700个。
在这两种情况下,两家公司都不仅仅是风险投资支持的,而且在短时间内经历了几轮大额融资。
这种循环几乎每次都以类似的方式在这类公司中上演。
注入现金。这意味着雇佣了更多的各类员工。更多的员工增加了对更多报告和分析的需求。更多的需求意味着,当您采用现代数据堆栈范式,将所有内容放入您选择的云数据仓库时,将在无线索层中创建更多的人工中间件。
更多无线索的人类中间件创建了更多的表、表、表到更多的报告、KPI和度量。他们不得不购买新产品并雇佣新人来管理复杂性。然后,新一轮融资开始了。数据团队雇佣了更多的人员和产品。组织雇佣了更多的人员,这就产生了对更多KPI和指标的更多需求,并产生了更多的报告、KPI和指标。
这个循环一直重复到钱用完为止。
所有这些有效地做的就是把人体扔到问题上,拼凑出一些解决方案,其中一些可能一开始就不必发生。
这方面的超额成本会转嫁给云供应商及其周围的服务,越来越多的无线索层员工制作了越来越多的表和SQL序列,以根据越来越多的失败者拥有更多的应用程序并生成更多的数据,为越来越多的Sociopath寻找越来越多的指标和KPI以及报告。
在风险资本一次又一次的涨价推动下,麦克劳德周期在时间上压缩了。

组织内部不断增加的人工中间件和中层管理不再需要几年的时间,而是需要数月或一两年的时间。
虽然一家自筹资金或传统企业将员工增长视为盈利能力和潜在债务的函数(“在受伤之前不要雇佣”),但许多风险投资支持的数字公司更快地完成了这一生命周期(“始终在雇佣”)。大量现金一轮又一轮地投向这些企业,有时只需几个月的间隔支票。
在过去几年中,美国延长了量化宽松政策,实际上实现了零利率,这导致一家又一家企业创建了数据功能,并有效地免费提供资金,在组织内拍摄数据。
数据集中实际上是敌人吗?
现代数据堆栈最大的骗局之一是,所有数据都需要通过一个集中的存储库,到达一个集中化的团队,才能产生某种结果。
事实上,大多数业务决策都是在业务线级别做出的,这些数据可能在团队内部保持孤立或“孤立”,并由负责这些数据的应用程序所有权负责。
为什么销售运营团队需要一份通过Snowflake或类似程序运行的报告,而他们所需要报告的只是每个SDR的拨号或活动归属,已经在他们使用的联合集成的Salesforce和Marketo中了?
现在,叙述中说,从每个单独的应用程序或上游数据库中引入所有原始数据,然后在云数据仓库中的SQL中将它们折叠在一起。
然后,雇佣一个团队来管理云数据仓库中的所有SQL联接。
然后,数据在云数据仓库过程结束时被认为是正确的。
然后,聘请分析师进行报告和BI的输出。
这一切都是极其低效的资本。
考虑到许多软件行业面临倒闭和裁员,许多消费/消费金融行业已经承担债务或可能很快不得不承担债务,大多数采用这种运营模式的公司都无法继续大规模为此买单。
员工成本太高,员工追踪第n个KPI或指标、分析或报告所产生的增量云成本太高。
从根本上说,现代数据堆栈/云数据仓库的故事是2010年末/2020年初的故事之一,基本上是免费的,增长-增长-增长的心态,很少关注盈利能力。
就在几年前,dbt还被作为“Casper、InVision、Away Travel等公司”使用的工具进行营销
- 卡斯珀甚至从未盈利过,它以其峰值估值的一半进行了首次公开募股,并最终在首次公开募股后以另一次降价被私有化,正如许多纸上谈兵的MBA在无数视频和文章中所指出的那样。
- InVision今年夏天解雇了50%的员工。
- 在过去的两年里,Away经历了各种各样的戏剧表演。
列表不断。请随时在他们的档案或Wayback Machine上查找您最喜欢的现代数据堆栈点解决方案工具,并查看2018-2019年左右的公司现在的表现。
控制人类中间件膨胀必须成为前进的道路
在我咨询过的任何一家现代数据堆栈公司中,几乎没有一家公司的“数据主管”因其预算管理而获得有意义的补偿。这种情况会发生,但很少发生,尽管这是许多大型企业的经营方式。
市场营销在11月至12月发送的电子邮件和短信数量是原来的10倍,然后人们会挠头,想知道为什么他们的Fivetran(或类似)信用卡被烤了,企业必须再花2万至3万美元才能提前恢复。这是因为Fivetran和类似的基于行的定价模型根据摄入的数据量收费。如果你已经连接了所有的电子邮件系统,并且产生的数量是原来的10倍,那么基于数量的模型的成本就会上升。
新的物联网或日志数据被纳入一个集中的数据仓库,用于新的计划。这些数据被快速地组合、吸收、存储,现在每天都有5亿新行(而且还在增长!)开始填充表格。当然,这也加入了SQL现有的DAG,就像现在一样,云数据仓库的账单在第一个月每月上涨了7000美元,今年可能会增加10万美元,这取决于它在SQL图表中的位置以及由此产生的报告和分析。
所有这些问题(我能说出更多的问题)从根本上讲都是由这些数据团队缺乏财政责任和运作纪律造成的。
作为一种解决方案,为了在即将到来的经济衰退压力面前保持领先,我建议如下:
- 高管领导层围绕其数据团队的支出制定了严格的预算,数据领导层根据其管理的预算进行补偿。如果数据领导者总薪酬的25-30%取决于保持在支出限额内,这将立即建立一种成本管理文化。作为一种权衡,这可能意味着向数据团队提问的人提供的请求更少,也可能意味着进入云数据仓库的系统更少。这是一件好事,因为较低级别的请求将贯穿运营团队,并且只提供方向性的重要请求。
- 确保数据团队的个人贡献者能够理解构建第n个管道或编写额外SQL的财务影响。事实上,我可以说,在我合作过的大约50%的组织中,在云上构建管道、SQL和分析的个人贡献者员工由于角色限制或各种用户权限配置而无法了解他们的操作成本。我认为这是一个错误,我从其中许多人那里听说,他们至少想知道自己努力的代价。如果你的牙齿里有菠菜,最好有人让你知道,而不是你整天带着菠菜走来走去,却不知道。
- 开发一种“解雇”仪表板、DAG节点和管道的文化,这些节点和管道不起作用或服务有限,或在其他方面未使用。事实上,在大多数云成本呈螺旋式上升的组织中,这可能是一个主要的成本节约,尤其是当与提供大量日常查询使用的适当物化DAG节点相结合时。
- 最后,成本的最大驱动因素之一,如果不是员工成本中的云支出,就是通过云数据仓库为财务请求提供服务。我已经一次又一次地看到与VC支持的数字公司合作,而这种“影子金融”以及如何避免它完全值得另一篇文章。不应该有数据工程师、分析工程师或分析师或任何其他有头衔的人将云数据仓库中SQL中的不同事务和订单系统数据连接在一起,然后将这些数据转储到BI仪表板上,供财务人员下载,甚至更糟——当它一开始没有正确进入仓库时,将其反向ETLing到财务记录系统中。这可能是一些公司数据团队成本的主要驱动因素,专门的数据员工在云上使用SQL来清理和连接数据,并创建用于结账、纳税或执行任何其他类型财务操作的数据集。让金融部门在自己的系统中解决自己的实体,然后根据需要将其纳入云数据仓库,而不是相反。
- 最终,将数据从系统A铲到系统B并对其进行规范化和非规范化几乎没有内在价值。随着我们进入经济衰退,数据膨胀持续爆发,请记住,最好的团队是那些推动最直接影响的团队,而不是那些构成配置大绑定的团队。