category
停止尝试构建更好的数据鼠标陷阱
公司向数据驱动和人工智能嵌入式企业转型的最大问题之一是,“数据思维”专注于构建“更好的数据仓库”。重点是呈现某种形式的“规范视图”的“黄金”数据。
这会毁了你的公司
这种心态假设报告实际上很重要,为报告构建数据是数据架构应该做的事情,因为历史上没有一个数据仓库能够实现“以每个人都能以一致的方式使用的方式为业务提供所有信息”的目标,所以构建更好的捕鼠器的循环仍在继续。问题是,报告可能是老鼠,但人工智能是老虎。

数据没有“奖章表”
首先要打消的想法是,数据中有一些神话般的奖牌表。坦率地说,这源于这样一个现实,即构建应用程序的人过去并不关心数据,因此系统中的数据充满了问题,主要是因为应用程序不需要对数据进行任何“智能”处理,只需要为事务提供服务。
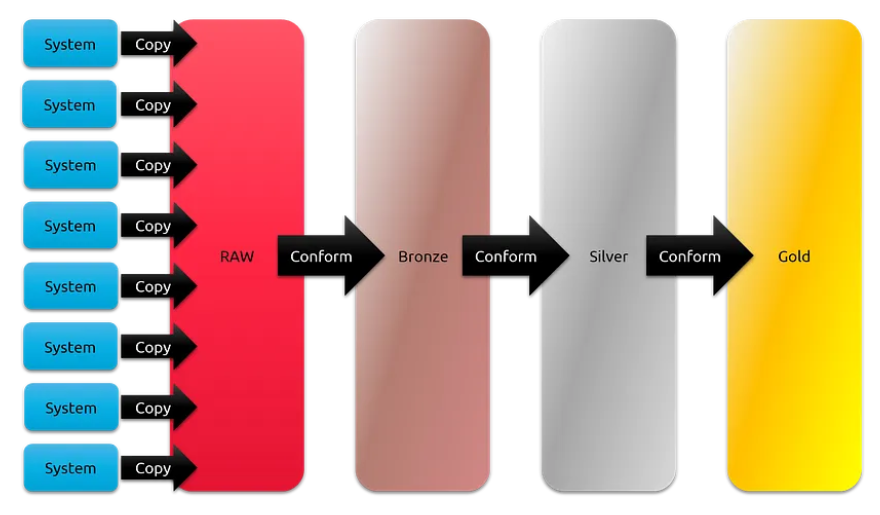
这导致了这样一种想法,即初始数据是“脏的”,没有实际用途,需要一个昂贵且耗时的过程才能将其转化为有用的数据。因此,“原始”数据被视为有效地隐藏在任何用途之外。然后,它有一个最初的策展,将其变成“青铜”,然后越来越多的策展直到它成为每个人都可以依赖的“黄金”数据。
你的“黄金”是黄铁矿(Pyrite)
这种心态假设你无法对数字现实进行操作控制。它让你在缺乏控制的情况下感到舒适,并将控制权投入到神话般的数据质量管道中。
如果你不能对数字现实进行操作控制,那么你的人工智能愿景就注定要失败
人们坐在会议上达成一致的“黄金”观点,即每个人都同意“质量”和清理规则,然后转化为转化管道,提供会议认为正确的观点。
然后,您会发现企业将这些数据下载到Excel或本地报告解决方案中,添加其他数据,通常是“不干净”的运营数据,然后做出业务决策。
怪财务,但他们有原因
这种心态的主要驱动因素之一是财务团队,因为他们向市场报告并安排审计,然后他们有特定的时间点,数据必须“正确”,不需要一直正确,只需要在正确的时间正确。财务团队将所有这些糟糕的数据整理、重述、应用市场规则,然后将其出版在一本书中,这本书就是公司的业绩。
因此,当你把金标准出版成书时,这种管道思维是有道理的,因为它不是一个移动的“东西”,它不是可操作的,它是对业务的高级视图,是在特定时刻创建的,用于监管目的。
可悲的是,数据人不仅采用这种财务方法,还接受这样一种观点,即以某种方式出版成书是信息的黄金标准,因此每个人都应该遵守以书为标准的出版。
你不是在写数据书

数据就是你的数字现实,这意味着运营就是数据现实
这种数据仓库的思维方式粉碎了一个简单的事实:
人工智能要想产生真正的影响,就需要基于对现实的准确看法做出反应
这一现实只有两部分:
- 现在是什么
- 曾经的一切都是什么
如果你不能为人工智能创建一个准确的决策上下文,那么它就不会做出一个好的决策。如果你对人工智能的训练是基于对你的历史的稀疏和不准确的看法,那么人工智能将从根本上存在缺陷。谷歌的DeepMind已经显示出了强力应对天气等随机挑战的能力。这种学习和训练是基于准确的历史,比传统模型更好地预测的能力是基于精确的数字现实。谷歌并不是为了将天气数据出版在书中而通过委员会来推动天气数据的通过,而是利用当前的准确现实来推动更准确的结果。
这就是挑战:现实
现实的商业问责制,或者只是为遗产而建
人工智能世界中的数据心态是:
数据主要由人工智能使用和消费
人工智能的大部分影响将以运行速度完成。或者回到我们的奖牌数据表…

因此,所有为创建数据之书而设计的漂亮架构实际上对人工智能并不有用。你需要改变你的架构,使其适应人工智能驱动的世界,而不是数据只用于报告的流程驱动的传统。
你需要关注构建数字现实的治理,而不是旨在编写数据书的治理。你需要考虑的是控制而不是质量。
我们不是生活在报告和数据书的世界里,我们生活在一个人工智能驱动的世界,数据是你的数字现实,这是数据反转,数据引导而不是跟随。
这意味着改变我们构建系统的方式,使其成为数据驱动的,并以最能使人工智能参与驱动决策的方式构建数据。
数据参与而非参与奖杯
事实是,传统的数据仓库思维及其神话般的“完美”后交易数据集的想法之所以存在,是因为历史上的数据并不重要,除了财务法规。IT产业的重要部分是事务系统,而数据的最重要部分是业务委托的解决方案,很多时候意味着Excel或临时业务报告。除了结账之外,“黄金”数据被简单地视为这些商业观点的另一个因素。
未来是不同的,人工智能对未来至关重要,人工智能以运营速度工作,可以参与运营决策。这是数据在业务中的参与,是业务的日常、逐分钟运行,而不仅仅是事后报告。
它的核心是一句简单的话:
商业成功取决于人工智能依赖数字现实的能力
因此,您处理数据的方法不是报告,而是数字现实,并确保企业负责。越来越多的业务线效率将由人工智能驱动,越来越多的商业领袖需要在其业务领域内理解和控制人工智能。如果你的数据体系结构没有解决这个问题,那么你所要做的就是向你的数据沼泽倾倒技术债务。
报道数字现实很容易
现在,对于那些传统思想家来说,这种转变有一个积极的方面,这是他们一直抱怨的事情,即使他们的架构回避了解决这个问题。如果你有一个准确的数字现实,那么报告它很简单,你的“原始”数据在操作上是准确的,而这种操作控制要求他们还生产出推动人工智能跨业务合作所需的协作数据产品,所有这些都意味着报告是基于对现实的准确看法。对于几乎所有的业务来说,这是足够且简单的。在金融领域,他们可能仍然需要在出版书籍之前操纵一些信息:税收规则、等级制度、许可证等可能需要一些调整,但对于销售、供应链、制造业、人力资源等,能够报告现实是他们一直想要的。

如果你对我认为你应该做的事情感兴趣,那么Data Mullet是一个很好的起点