
随着公司开始考虑推出实时消息传递系统,查看总体硬件成本是很重要的。通过一些前瞻性的规划,公司可以节省高达85%的总体存储成本。
在我们开始进行成本比较之前,让我简要地说明apache kafka和apache pulsar是如何存储数据的,它们有什么不同,以及为什么这些不同很重要。
数据存储在Kafka
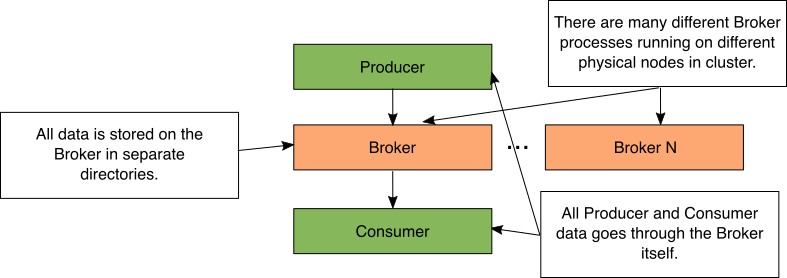
Figure 1: Simple Kafka storage diagram
在Kafka中,代理进程执行所有数据移动和存储。当生产者发送数据时,它被发送到代理进程。当使用者轮询数据时,将从代理检索数据。当代理进程接收数据时,它将数据存储在单独的本地目录中。
在Kafka集群中,有许多不同的代理进程正在运行。这些代理进程中的每一个都在物理上独立的计算机或容器上运行。
数据存储在Pulsar
有几种不同的方法可以建立一个Pulsar集群。这种级别的可扩展性是我们优化存储成本的方法。
简单Pulsar设置
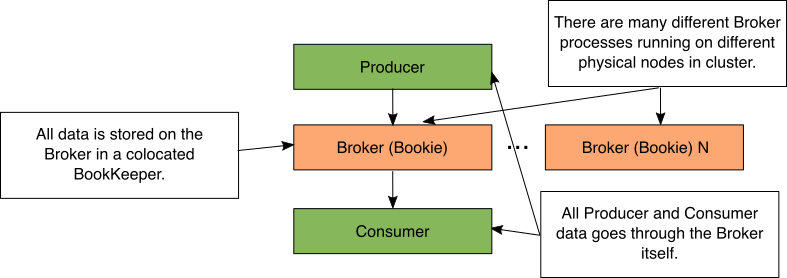
Figure 2: Simple Pulsar storage diagram
在Pulsar中,代理进程执行所有数据移动。当生产者发送数据时,它被发送到代理进程。当消费者将数据推送到代理时,数据来自代理。当Broker进程接收数据时,它将数据存储在一个并置的bookeeper Bookie中。BookKeeper Bookie是BookKeeper中存储数据的进程的名称。
在Pulsar集群中,有许多不同的代理进程在运行。这些代理进程中的每一个都在物理上独立的计算机或容器上运行。
带Bookkeeper的Pulsar集群
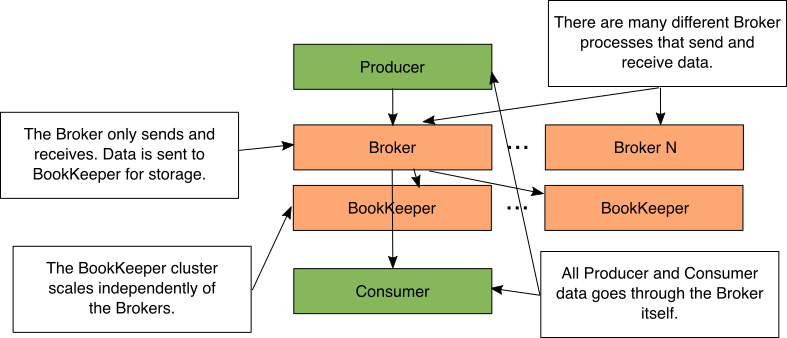
Figure 3: Pulsar with separate BookKeeper cluster
正如您刚才看到的,数据不是直接由Pulsar代理存储的。相反,Pulsar代理使用ApacheBookKeeper来存储他们的数据。数据的发送/接收和存储的这种解耦允许您让BookKeeper在另一台物理上独立的计算机或容器上运行。
当代理保存消息时,它将简单地将数据发送到BookKeeper流程。这允许BookKeeper集群和Pulsar集群彼此独立缩放。您可以发送/接收大量短时间内存储的消息(许多Pulsar经纪人和很少的预订)。你可以收到很少的信息并长期存储(很少的Pulsar经纪人和许多预订)。
一个常见的问题是,如果在单独的机器上有经纪人和簿记会导致性能问题。代理保留最近消息的内存缓存。事实上,99.9%的消息将是缓存命中,因为大多数消费者只是接收最新消息。
卸载至S3
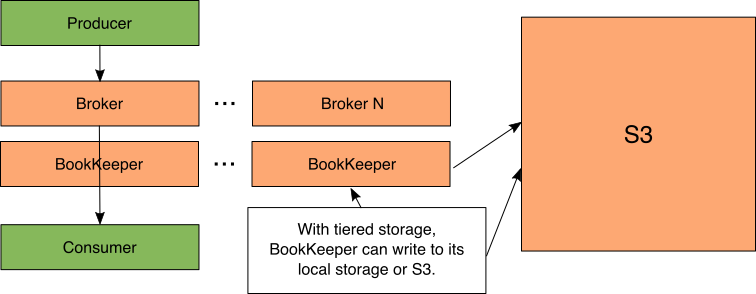
Figure 4: Pulsar with separate BookKeeper cluster that is offloading to S3
Pulsar的解耦存储体系结构在Pulsar中有一个新特性,称为分层存储,这一特性非常出色。这允许BookKeeper根据管理员配置的策略自动将数据从存储在簿记台上移动到存储在S3中。
注意:虽然我把S3作为赌注者的一个选择,但它并不是唯一受支持的技术。目前支持Google云存储,即将支持Azure Blob存储。您可以将S3看作是您所选择的支持云存储选项的缩写。
尽管数据存储在S3中,但经纪人仍然可以访问S3中的数据,因为赌注经纪人负责数据移动。S3的IO比本地存储的数据慢。
存储的关键区别
如你所见,Kafka和Pulsar在存储方面的主要区别在于耦合。在Kafka中,存储耦合到代理。在Pulsar中,存储与簿记分离。
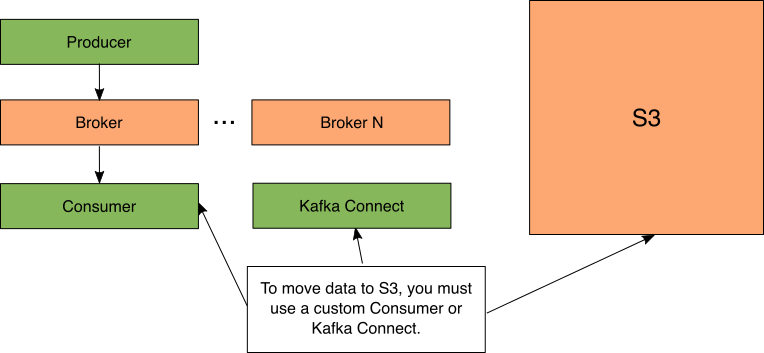
Figure 5: Kafka Offload
你可能知道,Kafka确实有能力将数据放入S3。这可以通过设置Kafka Connect或编写自定义使用者手动完成。
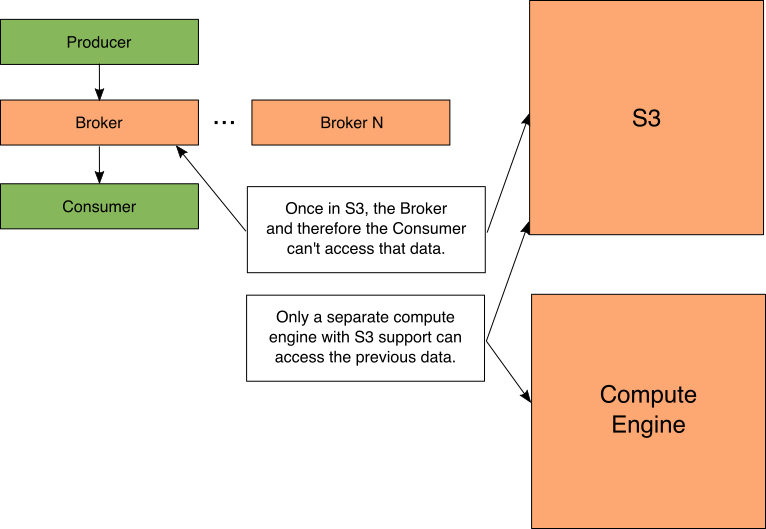
Figure 6: Kafka access
这种对S3的卸载确实带来了一个重要的警告,如图6所示。现在,数据的所有后续处理或消耗都必须使用另一个支持S3的计算引擎来完成,否则数据必须重新流回到Kafka主题并进行处理。
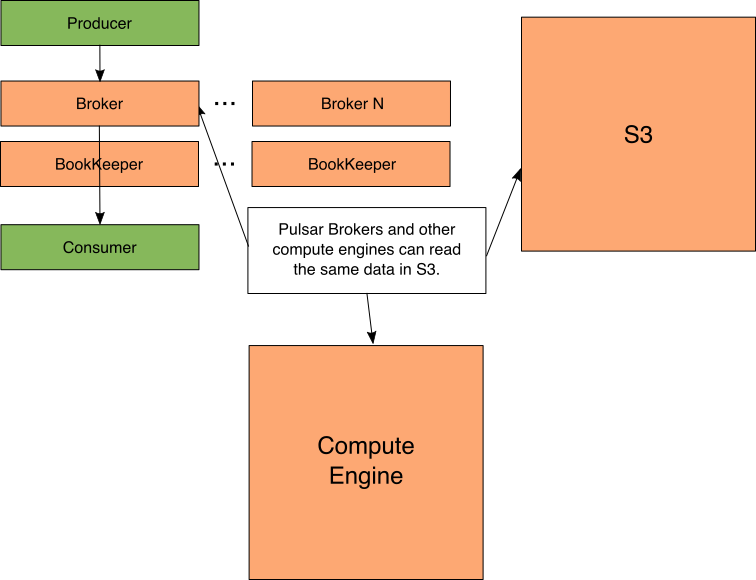
Figure 7: Pulsar access
使用Pulsar,数据可以与计算引擎共享。这两方面都是最好的,因为代理仍然可以访问旧消息,而计算引擎也可以。
例如,Spark可以处理存储在S3中的旧消息,同时Pulsar用户可以请求这些消息。请注意,在其他计算引擎中读取Pulsar的数据需要一个能够理解Pulsar磁盘格式的自定义输入格式。在撰写本文时,Pulsar支持Spark和Presto的连接器。
计算成本
既然我们了解了Kafka如何存储数据以及Pulsar存储数据的各种方法,我们就可以开始计算成本了。为了让这个过程更简单更具体,我们将根据亚马逊网络服务的美国东部(俄亥俄州)地区2019年1月的定价来确定我们的数字。对于S3,每个GB月的成本为0.023美元;对于EBS Amazon EBS通用SSD,每个GB月的配置存储成本为0.10美元。
在这个场景中,假设我们每天存储500 GB的消息。我们需要将这些消息存储14天。大约有7000 GB的原始事件消息。在Kafka和Pulsar中,数据被保存了3次以实现冗余。这使我们的存储需求高达21000 GB。对于Kafka和Pulsar(没有S3),光是存储成本每年就要25200美元。
有了Pulsar和S3,我们不需要在BookKeeper那里存储14天。我们只需要在Pulsar中存储一天,在S3中存储另外13天(您消耗的大部分时间都是几分钟前的数据)。这意味着我们需要1500 GB的EBS(500 GBx3副本)和6500 GB的S3(请记住,S3不直接收取冗余费用)。EBS和S3每年的成本分别为1794美元和1800美元,总计3594美元。这显然不包括S3请求的成本,但这些成本每年应该在50-300美元之间。
这两者的价格相差85.7%,数据可用性没有损失。这显然是一个例子。为了帮助您估计成本差异,我创建了一个Pulsar存储节省电子表格。只要输入你的数据,它会给你的价格差异。
更多关于成本的信息
对于云用户来说,S3中数据的存档存储已经纳入预算。这可能使节省更高。
还有其他更便宜的S3层。它们的sla更低,但成本更低。你也许可以走得更低,像冰川Glacier这些S3层。冰川Glacier的价格从0.023美元一路下跌到0.004美元。
考虑到您的用例和集群需求,您可以通过选择正确数量的Pulsar代理和bookeeper Bookie节点来进一步优化成本。您的EC2成本通常比存储成本高得多。
通过了解Kafka和Pulsar的存储差异,您可以真正优化您的存储开销。这使您能够灵活地交付业务所需的内容,同时仍能降低IT开销。
完全披露:这篇文章得到了Streamlio的支持。Streamlio提供了一个由apache pulsar和其他开源技术支持的解决方案。
原文:https://www.splunk.com/en_us/blog/it/saving-money-with-apache-pulsar-ti…
本文:http://jiagoushi.pro/node/1508
讨论:请加入知识星球【首席架构师圈】或者微信【csa_cea_cto】或者QQ【2808908662】